
基于深度强化学习的细粒度5G RAN切片功能复用映射与路由
2023-10-30 12:01蔡晓烽望运武顾家骅
聊城大学学报(自然科学版) 2023年5期
蔡晓烽,望运武,顾家骅,朱 敏
(1.东南大学 信息科学与工程学院,江苏 南京 210096,2.东南大学 移动通信国家重点实验室,江苏 南京 210096)
1 引言
随着5G通信设备数量的急剧增加,传统的无线接入网架构已不能满足设备对计算资源、带宽和延迟的严格要求。下一代无线接入网(NG-RAN)是一种很有前景的解决方案,基带单元被分割为分布式单元(DU)和集中式单元(CU)[1],这为5G发展的灵活性奠定了重要的技术基础。受到NG-RAN中基于虚拟网络功能的服务链启发,有研究人员提出了细粒度的功能分割机制[2]。细粒度功能拆分架构参考了3GPP的功能拆分方式,基带处理单元(BBU)被进一步拆分为一组多个细粒度功能单元(FU)。部署在不同网络节点中处理池(PP)里的FU可通过光路路由相互连接,共同实现基带处理功能。与现有的DU-CU架构相比,FU架构可以进一步提高基带处理的灵活性。因此研究了智能FU部署和路由策略,以进一步优化资源分配,提高资源利用率。
在FU部署过程中,我们引入一种策略,即不同切片请求中相同类型的FU功能可以部署到同一个PP,以共享PP上已经激活的实例。这种功能复用(FR)策略可以显著减少PP上所需激活的实例数量,极大提高计算资源利用率。然而,功能复用FR策略不可避免地引入实例竞争现象[3],增加了FU功能的处理延迟。因此,在基于FU的5G-RAN架构中,需要设计一种有效的功能部署和路由优化方案,利用功能复用策略,不仅可以减少PP中实例资源消耗,还能满足每个切片请求的端到端延迟阈值。
以往的工作研究了基带功能部署和路由问题。文献[4]的作者提出了一种最小化功耗的启发式算法,解决了DU-CU部署问题,达到节能的目的。在文献[2]中,作者证明了基于FU的功能部署策略可以缓解基带集中处理的压力,并能降低传输带宽的需求。但上述工作没有考虑FU的功能复用策略,而且BBU处理时延模型较为简单,仅设置为固定值。
近年来,深度强化学习(DRL)方法被应用于解决多维资源管理问题[5-9]。与启发式算法相比,DRL可以根据当前观察到的网络状态采取自适应策略。与整数线性规划方法相比,DRL方法可以在更短的执行时间内获得性能更优的可行解。文献[10]的作者提出了一种DRL算法,该算法为云无线接入网络(C-RAN)中的BBU池虚拟机的处理需求分配计算资源。在文献[11]中,作者同样采用DRL方法为C-RAN和NG-RAN提供网络功能部署策略。上述文献的结果表明,DRL的性能优于传统的启发式算法。但上述文献没有考虑基于细粒度功能拆分FU的RAN应用场景,也没有考虑功能复用策略。
本文引入功能复用策略,并提出了一种基于DRL算法的FU功能部署和路由解决方案。首先建立了一个以最小化计算资源、带宽资源和切片延迟总成本为目标的MILP模型,以此生成的最优解将作为性能基准,并研究了功能复用FR策略对MILP模型性能的影响。其次,由于MILP模型的不可扩展性,文章提出了一种DRL辅助的功能部署和路由方法,该方法不仅能获得接近最优解方案,而且能在可接受的时间内收敛,得到一种可行解。此外,提出了一种节点驱动策略来帮助DRL进行高效决策,该策略有效缓解了最短路径优先算法中可能出现的局部热点拥塞问题。
2 系统模型与问题建立
2.1 系统模型
如图1所示,弹性光网络(EON)为研究对象。每个节点都配备了EON中带宽可变的光交叉连接(BV-OXC)和可切片带宽可变应答器(S-BVT)。基于EON的5G接入网可以表示为有向图G(V,E),其中V为节点集,E为光纤链路集。所有节点都连接到本地的PP,部分节点连接到射频单元(RU),图中的一个目的节点连接到5G核心(5GC)。每个光纤链路上都有一定数目的频隙(FS)。
图2展示了FU架构的基带处理功能分割方式,其中一个BBU被分为五个FU(FU1 - FU5)[12]。FU1负责解调;FU2负责信道解码;FU3负责媒体访问控制(MAC),用于对来自不同无线电承载的数据进行多路复用;FU4负责无线链路控制(RLC),用来对上一层分割和重组;FU5负责分组数据汇聚协议(PDCP)协议,用于解决安全问题。系统把包含5 个FU的RAN切片请求从RU发送到5GC,这些FU可以被部署在相同或不同的PP中,并按照规定的顺序进行链接:RU, FU1, FU2, FU3, FU4, FU5,从而生成用于基带处理的服务链。一个RAN切片请求可以表示为R[s,(b1, FU1),(b2, FU2),(b3, FU3),(b4, FU4),(b5, FU5),b6,d]。其中s和d分别是切片请求的源节点和目的节点,bk是经过FUk之前的带宽需求,其中b6是经过FU5后的带宽需求。PP中的FU实例在有FU到达时被激活,并且消耗计算资源。从RU到5GC的路由则会导致带宽消耗。简单起见,每一个切片请求都设置了相同的计算资源需求、带宽需求和端到端延迟需求(阈值),而不考虑服务请求的类型区别。本文假设上述需求是由给定的公式和参数[13]得到的固定值。下文探索一种有效的策略来管理网络切片的FU部署和路由,以最小化资源消耗和延迟,而不超过端到端延迟和资源容量的阈值。需要考虑的资源有:计算资源、带宽资源和时延。

注:b1=86 016 Mbps; b2=32 256 Mbps;b3=7 140 Mbps;b4=4 500 Mbps;b5=3 024 Mbps;b6=3 000 Mbps。图2 基带处理功能的分割选项
(1)
式中αk为各个FUk的因子,A为天线数,M为调制比特,RTcoding为编码率,L为MIMO层数,PRB为物理资源块数。αk可通过文献[14]中的参数来计算获得。
FU实例是一种可复用的资源,相同类型的FU可以共享一个实例。例如,要将一个FU2部署到一个无已激活实例的PP中,就需要在PP中激活一个FU2实例,从而产生相应的计算资源开销。之后有新的FU2部署到这个PP中时,由于FU2实例复用,就不会产生新的计算资源成本。
每当部署一个FU之后,请求的带宽需求将会改变。所需要的FS数量可以用[bk/(ML·bfs)]表示[2],其中bk是通过FUk前的带宽需求,ML是调制格式的阶数,bfs是每个FS的带宽[3]。在EON中设置光路时,应考虑光谱的连续性、一致性和容量限制。
对于时延,可从五个方面来计算。
处理时延:一个FU在PP中的停留时间定义为FU的处理延迟。假设经过每个FU实例的FU流是一个输入队列,每个实例的计算资源可视为服务于FU的服务器。因此,对应的M/M/1模型为[15]
(2)
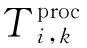
虚拟化时延:假设启动一个FU实例需要的虚拟化延迟为Tv。由于FU实例是一种可复用的资源,当PP中已经启动了相同类型的FU实例时,系统不会启动新实例,因此FU实例复用方案可以节省相应的虚拟化时延。
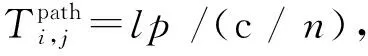
封装时延:细粒度分割采用了通用接口(GI)。GI时延包括处理PP中最后一个FU后的封装时延和PP中第一个FU前的解封装时延。
光电切换时延:切片请求的光信号在PP中进行FU处理之前需要切换到电子域,这就造成了Toeo时延。请求离开此PP时,信号需要进行反向切换。
因此,请求r的端到端总时延为
(3)
式中Xi,j,r,k是二进制变量,表示前k个FU处理完毕后的请求r是否在链路e(i,j)上传输。Hr,i是二进制变量,表示请求r是否在节点i上处理。Zr,k,i是二进制变量,表示FUk是否为请求r在节点i上处理的最后一个FU。Or,k,i是二进制变量,表示请求r的FUk是否在节点i上处理。SVr,k是二进制变量,表示请求r的FUk是否激活了新的实例。
2.2 MILP模型
本文提出了一个MILP模型来管理的FU的部署和路由,目标函数设计为使计算资源、带宽容量和时延三种资源的总成本最小化。
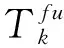
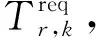
目标函数Minimize:
(4)
MILP的目标是同时最小化计算资源、带宽资源和请求的端到端延迟。目标函数中第一项是所需PP的数量,第二项是MFSI,第三项是请求的端到端延迟。权重α,β,γ用于平衡每个资源对目标函数的贡献。
限制条件
FU部署限制
(5)
(6)
(7)
式(5)确保请求从起点出发,到终点5GC结束。式(6)确保每个请求中的每个FU选择且仅选择一个PP进行部署。式(7)保证了Di值为1时,有FU在PPi上处理,值为0时则无。
(8)
(9)
式(8)保证了Qk,i值为1时,有FUk在PPi上处理,值为0时则无。式(9)保证了PP的计算工作量不超过其计算能力限制。
路由限制
(10)
(11)
(12)
式(10)确保了请求在部署过程中不会回到起点,同时保证最终到达5GC。式(11)确保建立了从起点到5GC的光路。式(12)保证了一个链路不能被一个请求重复使用。
(13)
(14)
式(13)表示如果节点i是请求r的起点,并且请求r在这里处理了FUk,请求r将会以FUk已处理的状态离开节点i。式(14)表示如果请求b的FUk在节点nd被处理,请求r将以FUk未处理的状态到达这个节点,并以FUk已处理的状态离开节点nd。
XFi,j,0,r,k=0,∀i,j(j≠i),r,k,
(15)
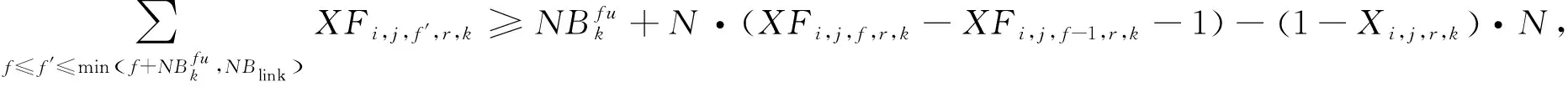
(16)
式(15)确保FS的索引从1开始,而不是从0。式(16)确保处理完FUk后,为请求r选择一组连续的FS。
(17)
MFSI≥f·UFi,j,f,∀i,j(j≠i),f,
(18)
MFSI≤NBlink
(19)
式(17)保证了频谱不重叠。式(18)计算网络的MFSI,式(19)保证MFSI不能超过每条链路上的FS数量。
时延限制
(20)
式(20)为频谱的连续性约束。
(21)
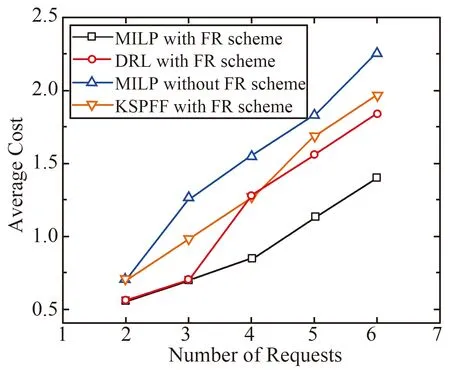
(22)
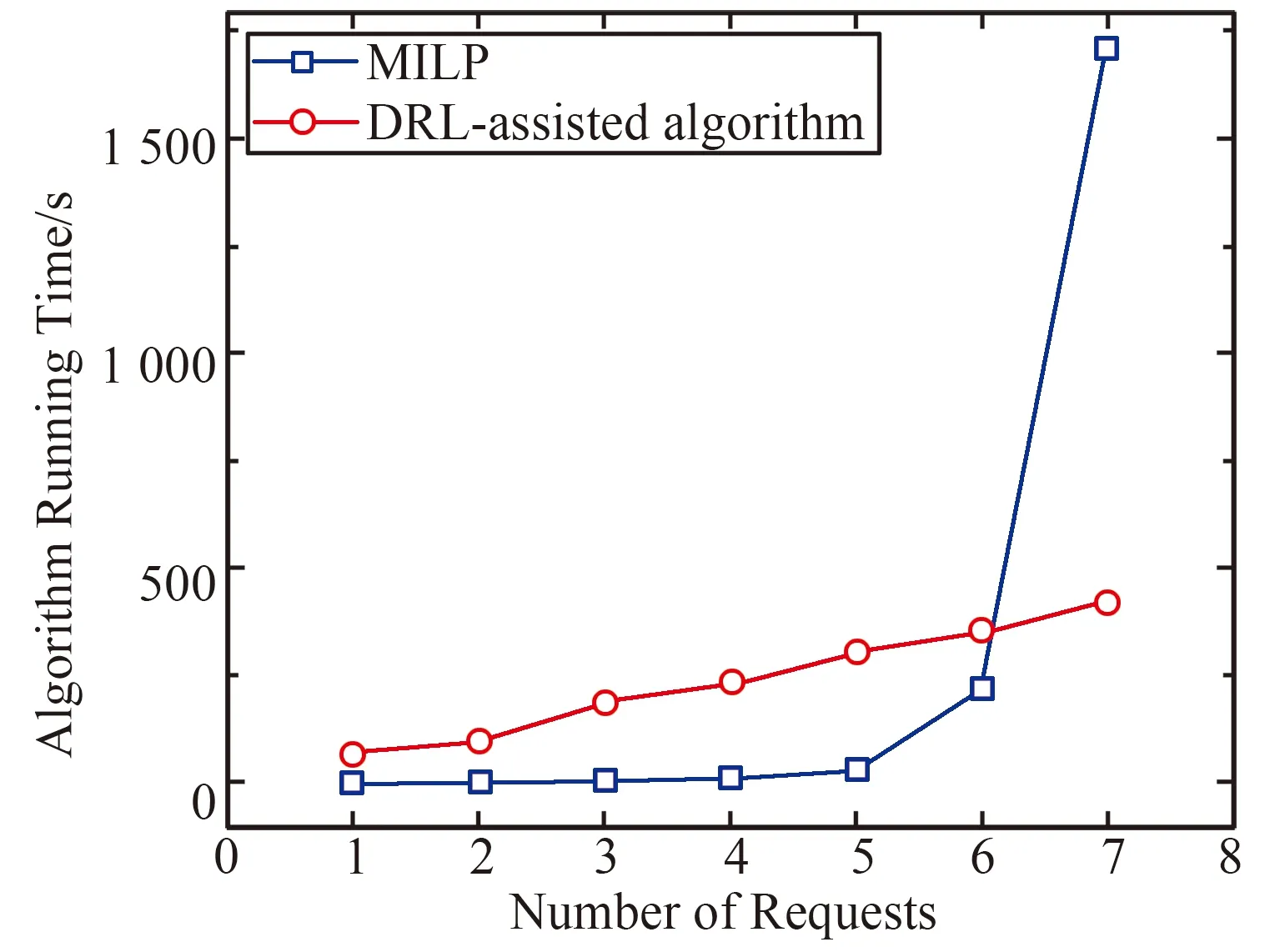
2·Zr,k,i≤Or,k,i-Or,k+1,i+1≤Zr,k,i+1,∀r,2 (23) 式(21)计算了FUk在PPi上的复用次数。式(22)确保了请求r在节点i上处理时Hr,i值为1,否则为0。式(23)确保了FUk为请求r在节点i上处理的最后一个FU时Zr,k,i值为1,否则值为0。 (24) 式(24)计算了节点i上每个FUk的处理延迟,属于非线性约束。这里引入一个辅助变量Gk,i来线性化。 (25) (26) (27) (28) 式(25~28)列出了变量Gk,i的约束条件,其中有一个新的非线性约束条件(27),该约束条件也需要线性化。式(26)确保FU处理延迟的计算只与实际参与处理的节点有关。 Pr,k,i=Gk,i·Lr,k,i,∀r,k,i, (29) Pr,k,i≤Gk,i,∀r,k,i, (30) Pr,k,i≥Gk,i+N·(Lr,k,i-1),∀r,k,i, (31) Pr,k,i≤N·Lr,k,i,∀r,k,i, (32) (33) 式(29~33)列出了变量Pr,k,i的约束条件。 (34) 式(34)计算了请求r中每个FUk的处理时延,属于非线性约束。这里引入一个辅助变量ab,k,r来线性化。 (35) (36) (37) ar,k,i≤N·Or,k,i,∀r,1≤k<|K|,i, (38) (39) 式(35)为ar,k,i的定义式,其约束条件为式(36~38)。式(39)为线性化的结果。 (40) 式(40)确保满足延迟要求。简单起见,所有的限制都加入了虚拟化延迟。 值得一提的是,上述提出的混合整数线性规划MLIP模型仅仅适用于规模网络小,请求较少的情况,虽然可求得最优解,但不适用于大网络场景,缺乏可扩展性。因此,本文设计一种深度强化学习DRL模型,它可以适用于网络规模大,请求较多的情况,而且从后面仿真中可以看出,性能优于启发式算法,可求得近似最优解,具有较好的可扩展性。 图3展示了DRL如何通过与基于FU的RAN环境进行迭代交互来学习和做出决策。在每个决策时刻,DRL从环境接收更新的状态。深度神经网络(DNN)将状态输入和切片请求的需求映射为多个Q值。每个Q值分别与一个动作相关。DRL会选择执行Q值最大的动作。在动作执行后,DRL从RAN环境中获得奖励。至此,DRL执行了一个循环,并且从这次经历中学习如何行动,以有效地解决BBP&R问题。 图3 基于DRL的资源分配 与传统的最短路径优先映射方案不同,算法1提出了DRL辅助的节点优先映射方案。算法的第1,2行初始化要部署的切片请求的状态。在第3,4行中,为方便DRL进行决策,算法将一个请求R分解为5 个单元,即(b1, FU1),(b2, FU2),(b3, FU3),(b4, FU4),(b5, FU5,b6),分5 步来部署一个请求。FUk与第k(k≠5)个频谱资源需求bk组合为R中的第k个元素,其中R中的第5 个元素(b5, FU5,b6)包括第5 个计算资源需求FU5,第5个和第6个频谱资源需求(即b5和b6)。该方案主要由节点映射来驱动。首先DRL选择一个PP节点来部署FU。然后在所选节点和上一个已选节点之间路由,以此来选择光路。 在第5 行,DRL在第t个时间步中获得将要部署第r个切片请求的第k个FU时的环境状态,状态信息由第k个FU的信息和当前基于FU的RAN信息组成。状态定义为 在第6~9行中,DRL通过ε-greedy策略[11]的来选择动作。动作空间包括|Snode| 个动作,其中|Snode|是RAN中的节点总数。每个动作都与一个候选PP节点对应。在第10~12行中,如果选择了可行的动作,FU将被部署到指定的节点中。然后,计算所选节点和上一个所选节点之间的K个最短路径。在第13~16行中,Ik定义为部署所需FS的最小起始索引。选择具有最小Ik的路径,并在光路中的光纤上分配所需的FS。在部署切片请求的最后一个FU时,应该在所选节点和上一个所选节点以及5GC节点之间分别分配两条光路。 如果发生以下三种情况,动作选择了同一个请求的前几个FU(上一个FU除外)已经选择的某个PP,可用资源不足,或者超过请求的延迟阈值,动作就不可行。在第18~19行中,如果这个动作是不可行的,则给DRL一个较大的惩罚。在第17 行中,当行动可行时,根据式(3)设置负值作为每一步的奖励。 在第20~24行中,经验数据以(st,at,rt,st+1)的方式记录下来。为了训练DRL模型,DNN的参数通过loss=E{[rt+ζmaxQ(st+1,at+1) -Q(st,at)]2}进行更新,其中rt+ζmaxQ(st+1,at+1)为理想Q值,Q(st,at)表示更新前的Q值。当损失函数收敛到一个较小的固定值时,DNN的输出很好地拟合了动作的最优Q值。 本节通过仿真来评估MILP和DRL辅助算法的性能,这两种算法将和启发式算法K最短路径首次匹配(KSPFF)相比较,同时也比较了FR方案的优劣。仿真采用了9节点网络,如图4所示。节点1设置为请求1~4的起点,节点2设置为请求5~7的起点。节点9作为5GC的所在点,是所有请求的目的地。本仿真中MILP和DRL均运行在的Intel i7-10750H CPU 2.60 GHz 16G RAM环境,其中MILP在GUROBI 9.1.2(https:∥www.gurobi.com/)上编程并执行,DRL神经网络的搭建和训练使用了Theano优化编译器。详细仿真参数如下:天线个数为32,PRB个数为500,调制比特为6 bit,MIMO层数为2 层,光路存在100 个FS,学习率为10-4,衰减因子为0.9,训练批次大小为32,经验回放池容量为4×104,探索率为0.8。 图4 拓扑图 图5给出了代表不同算法消耗的总资源的平均成本。随着请求数量的增加,这几种算法都会消耗更多的资源,因为更多的请求会带来更多的资源需求。需要注意的是,三种使用FR方案的算法比不使用FR方案的MILP消耗的资源更少,这是由于多个切片请求之间实现了PP上的FU实例资源共享。除此以外,DRL与KSPFF相比,节省了更多的平均资源成本。 图5 总成本 图6的(a)和(b)中,使用的PP和MFSI数量随着请求数量的增加而增加。有FR方案的算法比没有FR方案的算法使用更少的PP和MFSI。这是因为一个FU实例可以由来自不同请求的相同类型的FU共享,从而开启更少的FU实例,使用更少的PP。较低的MFSI是由于FU在地理位置上的集中节省了FU之间的带宽。而KSPFF虽然所选择的节点较为集中,需要最少的PP,但不同请求路径的选择也由于首次匹配的规则而过于集中,导致了高MFSI。从图6(c)中可以看出,三种算法都能满足时延要求,时延性能相近。FR方案虽然会带来排队延迟,但通过复用FU实例,避免了虚拟化延迟和光电切换延迟。因此,使用FR方案不会带来太大的额外延迟。 图7为DRL的训练过程。图7显示,DRL的损失在500回合内迅速下降,之后收敛到0。在1 300个回合内,总奖励会因为探索过程而随机变化。在1 300个回合之后,总奖励收敛到一个较高的值,约为-0.7。结果表明,本文基于DRL的算法具有较快的收敛速度,从而达到近似最优解。 图7 DRL算法的训练过程 图8对比了MILP和DRL算法的运算时间。在小于6 个请求的情况下,MILP比DRL算法消耗的运行时间更短,因为小规模的情况下,GUROBI中的数学运算只需几步就能精确求解,而DRL算法需要足够的迭代来进行训练。但是,在超过6 个请求的情况下,MILP的运行时间明显多于DRL算法的运行时间,并且MILP的运行时间随着请求数目增加而呈指数级增长,而DRL算法运算时间呈线性增长趋势。因此,在大规模场景下,基于DRL的细粒度功能部署和路由算法在运行时间方面优于MILP模型。在请求较少的情况下,例如切片业务请求的低谷期,使用MILP能够快速地给出最优FU部署方案,而在请求较多的场景下,例如切片业务请求的高峰期,使用DRL是更好的选择。 图8 DRL算法和MILP算法的处理时间 本文提出了一种DRL辅助的资源优化分配方法,高效地解决了基于功能复用机制的FU基带功能部署和路由的问题。首先采用MILP模型,对问题进行建模分析。从MILP仿真结果中可以看出,功能复用策略大大提升的资源利用率,验证其有效性;在DRL仿真中,DRL算法比不采用功能复用策略的MILP具有更好的性能。可见,DRL算法能够充分发挥资源复用的潜力,有效提高系统性能。而且,DRL算法在总成本上优于KSPFF启发性算法,这体现了DRL算法在不同网络状态下能够灵活地做出有效决策。另一方面,在大规模请求情况下,DRL算法比MILP花费的时间要少得多,更具扩展性。因此,我们提出的DRL辅助方法,有望为5G RAN架构中细粒度功能布局和路由算法提供出色的性能。3 深度强化学习模型

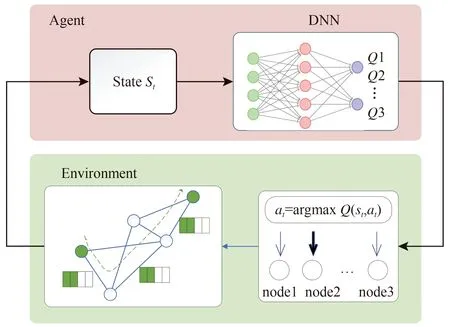
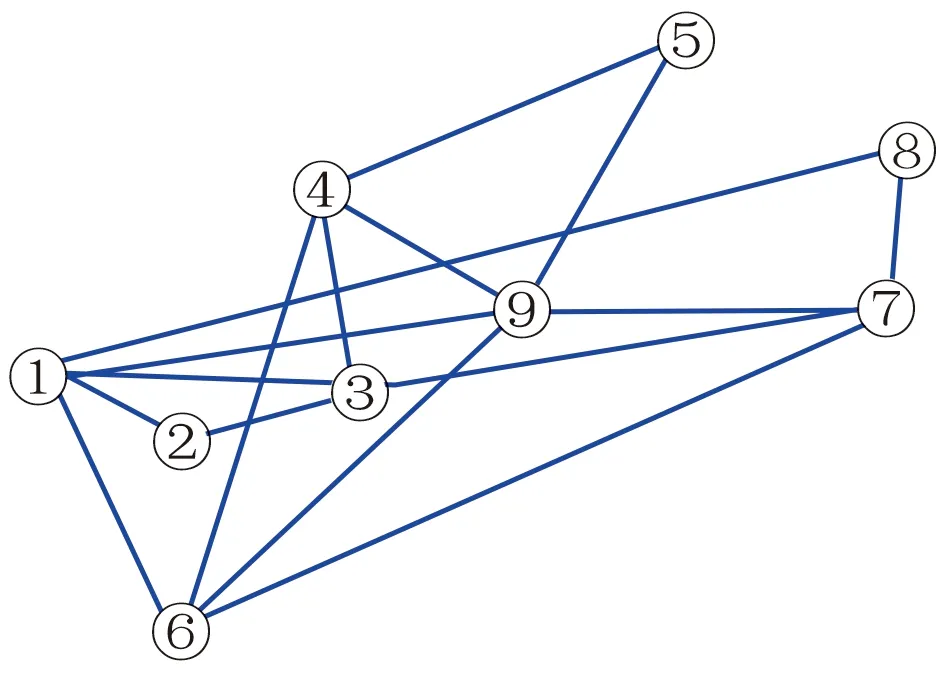
4 实验结果

5 结论
猜你喜欢
科学技术创新(2021年18期)2021-06-23
微型电脑应用(2019年10期)2019-10-23
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
电信科学(2016年11期)2016-11-23
中国组织化学与细胞化学杂志(2016年3期)2016-02-27
中国当代医药(2015年17期)2015-03-01
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
河北医科大学学报(2010年10期)2010-03-25
