
在线分布式优化研究进展
2023-10-30 13:37袁德明张保勇夏建伟
聊城大学学报(自然科学版) 2023年5期
袁德明,张保勇,夏建伟
(1. 南京理工大学 自动化学院,江苏 南京 210094;2. 聊城大学 数学科学学院, 山东 聊城 252059)
1 引言
近年来,多智能体系统技术作为改变未来社会生活方式和战争规则的颠覆性技术在世界范围内得到快速发展,不仅成为当前国际学术界和产业界的研究热点,而且已经上升为我国国家战略的核心内容。多智能体系统(Multi-Agent Systems)是由一群具备一定的感知、通信、计算和执行能力的智能体通过通讯等方式关联成的一个网络系统[1,2]。而分布式优化是通过多智能体之间的协调合作有效地实现优化的任务。与传统集中式优化相比,分布式协同优化是一种“去中心”的优化算法,不需要一对一的全局通信,每个智能体只需与其相邻智能体进行信息交换。因此,可以用来解决许多传统集中式算法难以胜任的大规模复杂的优化问题。近十年来,因在机器学习、智能电网、传感器网络等诸多领域的广泛应用,分布式优化研究得到了越来越多国内外学者的广泛关注,是当今系统控制重要前沿发展方向之一[3-12]。
分布式优化问题在优化领域由来已久。早在20世纪80年代,麻省理工学院John N. Tsitsiklis,Dimitri P. Bertsekas 等教授在文献[3]中提出了分布式优化理论的计算框架。基于此开创性工作,Angelia Nedic教授和Asuman Ozdaglar教授首次在多智能体系统一致性框架下研究分布式优化问题,并提出了著名的分布式次梯度算法[4]。此算法由两部分构成:局部优化和一致性计算,前者是每个智能体使用次梯度算法来优化其自身的目标函数,而后者是用一致性算法来协调每个智能体和其相邻智能体的信息,以保持状态一致。基于此工作,近年来国内外学者在分布式优化上取得了大量重要的研究成果,并见刊于系统控制领域国内外权威刊物和会议上[5-12]。
在线分布式优化的研究近年来得到了国内外学者的广泛关注。与离线分布式优化不同的是,在线分布式优化具有如下特征:(1) 优化目标不同:在线分布式优化中,智能体的目标函数是时变的,其产生甚至可以基于智能体历史的决策信息和损失函数信息;而离线分布式优化中,智能体的目标函数是固定不变的;(2) 性能指标不同:在分析在线分布式优化算法的性能时,通常将网络中的任意一个智能体的决策序列在所有损失函数上产生的损失与最优决策所产生的损失相比较,其差值称为遗憾(Regret);而离线分布式优化是最小化智能体的状态序列与最优值之差。因此,在线分布式优化是离线分布式优化的延伸和拓展。在线分布式优化根据决策空间类型可以分为一般凸集约束和不等式约束;根据信息反馈模型的不同可以分为完全信息下在线分布式优化和Bandit信息下在线分布式优化。本文将从决策空间、信息反馈模型这两个角度对在线分布式优化算法的最新研究成果进行总结,着重讨论算法的设计思路、参数设计以及收敛性分析结果,并对不同算法的优势和不足进行剖析。
本文结构安排如下:第2节介绍了在线分布式优化问题的模型和性能指标;第3节梳理了现有在线分布式优化相关的代表性算法及其收敛性结果;第4节简单讨论了在线分布式优化算法的应用;第5节对全文进行总结并浅析未来可能的研究方向。
2 模型与性能指标
2.1 模型
在线分布式优化以多智能体系统为框架。多智能体系统是一群具有一定感知、计算和通信能力的个体组成的网络系统。一般地,多智能体系统在t时刻的拓扑结构或信息分享模型可以由有向图Gt=(V,Et,Pt)表示,其中V={1,2,…,N}为顶点(智能体)集合,Et⊂V×V为t时刻的边集,Pt=([Pt]ij)N×N为t时刻的权重矩阵,它刻画了t时刻智能体之间的信息分享关系。下面介绍两种经典的网络拓扑,它们广泛地应用于在线分布式优化算法的设计和研究中。
(1) 无向连通固定拓扑[7,12]:G=(V,E,P)为无向图,其中E为固定边集,P=([P]ij)N×N为固定的权重矩阵。无向图意味着对于任意的两个智能体i,j∈V,(i,j)∈E当且仅当(j,i)∈E;而图是连通的意味着对于任意的两个智能体i和j之间都存在一条路径。一般对权重矩阵做如下假设
(i) 对任意的i,j∈V,[P]ij≥0;
(ii) 当(i,j)∈E有[P]ij>0;当(i,j)∉E有[P]ij=0;
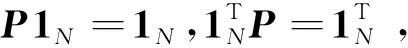
在此假设下,权重矩阵P的第二大奇异值小于1,即σ2(P)<1,它决定了一致性收敛速度的快慢。
(2) 一致联合强连通切换拓扑[4,9]:存在一个固定的正整数B使得对于所有的k≥0有(V,EkB∪EkB+1∪…∪E(k+1)B-1)是强连通的,即图中的任意两个顶点之间存在有向路径。针对此拓扑,一般对权重矩阵做如下假设
(i) 对任意的i∈V有[Pt]ii≥β>0;
(ii) 当(i,j)∈Et有[Pt]ij≥β>0;当(i,j)∉Et有[Pt]ij=0;
(iii)Pt为双随机矩阵。
定义矩阵Qt→s=PtPt-1…Ps+1Ps,∀t≥s≥1,且Φt→t=Pt,有
在线分布式优化可视为多智能体系统和环境/对手的博弈。一般来说,它由以下几步构成
(1) 智能体i∈V在t(t=1,2,…,T)时刻做出决策xi(t)∈X⊆Rd;
(2) 环境/对手透露关于损失函数li,t(x):X→R的信息并遭受损失li,t(xi(t));
(3) 智能体i与其相邻智能体进行信息交互并基于环境/对手反馈的信息做出下一步决策xi(t+1)。
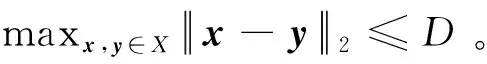
(1) 完全信息反馈[13,14]:智能体i∈V在t时刻做完决策后,环境/对手将损失函数li,t(x)的完全信息反馈给智能体i。因此,在算法设计时可以使用损失函数li,t(x)的梯度甚至Hessian矩阵,即∇2li,t(x)。
(1) 单点梯度估计器(One-Point Gradient Estimator)[15]
(2) 两点梯度估计器(Two-Point Gradient Estimator)[16,17]
式中εt>0为探索参数,ui(t)∈Rd为服从某种概率分布的随机探索向量。
2.2 性能指标
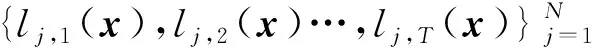
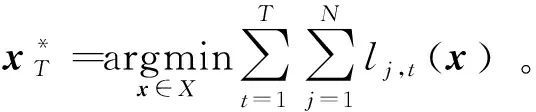
2.2.2 动态遗憾。动态遗憾是一种更严格的性能指标[18-21],它要求每个时刻智能体的决策向量与当前时刻网络所有损失函数的最优决策相比较,其形式为
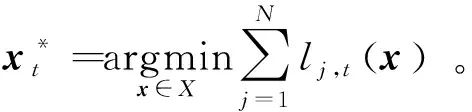
2.2.3 复合遗憾。当智能体i∈V在t时刻的目标函数由损失函数li,t(x)和正则项ri(x):X→R组成时,需要引入复合遗憾来刻画算法的性能,即
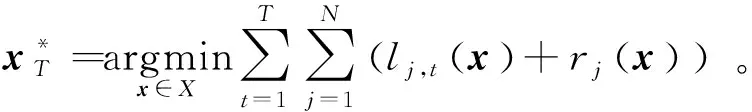
2.2.4 累加约束违反度。当决策空间是一组不等式约束时,即X={hs(x)≤0,s=1,…,M},其中hs(x)是凸函数。智能体无法在每一个时刻计算决策向量到决策空间X的精确投影。因此,需要引入累加约束违反度(Cumulative Constraint Violation)来刻画所有智能体的决策向量在所有不等式约束上产生的偏差值
式中[z]+=max{0,z}。CCV存在正负相抵消的情况,因此考虑一种更严格的指标,即累加绝对约束违反度(Cumulative Absolute Constraint Violation)
相较于凸集决策空间情形,不仅要求所设计的算法的遗憾是次线性增长的,而且累加(绝对)约束违反度也需要是次线性增长的,即CCV(T)=o(T)或CACV(T)=o(T)。
3 算法设计
本节回顾现有经典的在线分布式优化算法,并对算法的设计思路和收敛性结果进行总结。
3.1 在线分布式次梯度算法
文献[22]提出了完全信息反馈下的在线分布式次梯度算法,它可视为分布式次梯度法[4]的在线版本,也可视为在线学习中在线梯度下降法[14]的分布式版本
(1)
在算法中,智能体的初始决策设置为xi(1)∈X,∀i∈V;P为权重矩阵;gi,t(xi(t))∈∂li,t(xi(t))为损失函数li,t(x)在xi(t)点任意一个次梯度,当损失函数可微时有∂li,t(xi(t))={∇li,t(xi(t))};ηt是t时刻的学习率。
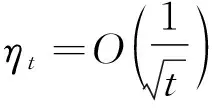
3.2 在线分布式对偶平均算法
文献[23,24]提出了完全信息反馈下的在线分布式对偶平均算法,它是经典的分布式对偶平均算法[12]的在线推广
(2)

3.3 在线分布式镜面下降算法
文献[25]提出了时变切换拓扑下的离线分布式镜面下降算法,在此基础上,文献[26]考虑了在线分布式复合优化问题并设计在线分布式复合镜面下降算法。下面首先给出在线分布式镜面下降算法的具体形式以及相关理论结果
(3)
在算法中,智能体的初始决策设置为xi(1)∈X,∀i∈V;Φ:Rd→R为距离产生函数,满足可微性和强凸性;DΦ(x‖y)=Φ(x)-Φ(y)-∇Φ(y)T(x-y)为Bregman散度。算法(3)前两行亦可以写成
下面给出两种经典的距离产生函数选取方案以及相应的算法。
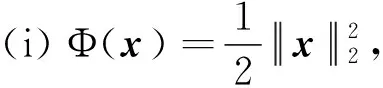
其形式和在线分布式次梯度算法(1)极为相似,其区别在于一致性算法和在线局部优化算法的先后顺序不同。
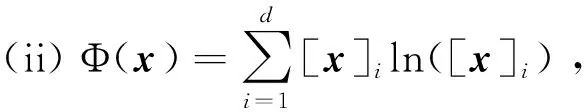
式中exp(s)=es。
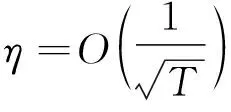
文献[26]进一步地研究了在线分布式复合优化问题并提出了如下完全信息反馈下的在线分布式复合镜面下降算法
(4)
(5)
式中(1-ξ)X={(1-ξ)x:x∈X}为收缩的决策空间,其作用是保证观测点xi(t)±εtui(t)在决策空间X内。值得注意的是,在Bandit信息反馈下一般对决策空间X做如下进一步的假设
B(0,r)⊆X⊆B(0,R),0 可见复合遗憾不仅与决策变量维数相关,还与所选取的范数相关,这是Bandit信息反馈下在线分布式优化算法的共性。 (6) 基于欧几里得距离产生函数的算法涉及点到凸集的欧几里得投影,当决策空间X形式复杂或不具有特殊结构时,求解投影问题本身就是一个凸优化问题[30,31],这无疑对智能体的计算能力提出了挑战。基于此考虑,文献[32]提出了基于Frank-Wolfe法(又称条件梯度法)的在线分布式优化算法,其基本思想是将欧氏投影转化为一个线性优化问题: (7) 当决策空间是一组不等式约束时,即X={hs(x)≤0,s=1,…,M},欧氏投影无法计算。因此,算法设计一般基于对偶域方法。文献[34]引入了正则拉格朗日(Regularized Lagrangian)函数: 式中λ=([λ]1,…,[λ]M)T∈RM为拉格朗日乘子,θt为正则参数。文献[34]在M=1和决策空间满足假设X⊆B(0,R)的前提下,设计了一种在线分布式原始-对偶次梯度算法: (8) 式中αt和βt分别为原始和对偶变量更新的学习率;∇xLi,t(xi(t),λi(t))和∇λLi,t(xi(t),λi(t))分别是拉格朗日函数Li,t对于原始和对偶变量在点(xi(t),λi(t))处的次梯度和超梯度 文献[35]对算法(8)进行了改进并得到了更优的上界。具体地讲,提出了如下形式的正则拉格朗日函数 并在此基础上设计了如下算法 (9) 本节简要介绍在线分布式优化算法的应用。 比如,当选取预测函数h(xk,w)=wTxk并采用平方损失函数时,上述问题变为经典的线性回归问题 随着数据库规模的日益增大,在单个处理器上对所有K个样本进行训练将不切实际,因此可行的方法是在多处理器上进行分散训练后再进行综合,此即为分布式优化问题。进一步考虑在一些机器学习问题中样本是在线产生的,比如垃圾邮件过滤,而在线分布式优化可以作为工具解决这类问题[53],其目标函数为 式中K=MN。我们可以利用第3节中的算法有效的解决此类问题。 考虑如下学习问题:N个决策者重复的在k个选项或动作中进行选择。每次做出选择之后,每个决策者会得到一定数值的收益,收益由决策者选择的动作决定的平稳概率分布产生。每个决策者的目标是在总的T轮迭代内最大化总收益的期望[54]。具体地讲,智能体i希望最小化如下遗憾 式中μj为第j个选项或动作的期望收益,并假设μ1≥μ2≥…≥μk;ai(t)为智能体i在t时刻选择的选项或动作。智能体之间的交互方式由网络拓扑决定,它可以是固定拓扑或切换拓扑。智能体根据邻居的奖励信息进行信息综合,然后根据经典的MAB算法做出自己的决策,再将自己的奖励信息反馈给相邻智能体。多智能体Multi-Armed Bandit问题在强化学习、推荐系统、信息检索、动态定价、异常检测等诸多领域有着广泛的应用[55,56]。 本文从决策空间、性能指标、信息反馈模型等角度对当前在线分布式优化算法的研究热点进行了梳理和总结,着重对算法的设计思路和收敛性分析结果进行了剖析。近年来,在线分布式优化的研究得到了国内外学者的广泛关注,但相关研究仍处于起步阶段,尚有许多重要的基本问题值得深入研究。一些未来可能的研究方向包括但不限于: (1) 非凸优化。在很多实际问题中,目标函数往往是非凸的。比如,稀疏回归问题,虽然目标函数是凸函数,而约束条件是非凸的;比如,推荐系统问题常常伴随着非凸秩约束。非凸优化问题往往存在局部解,同时非凸优化问题的定义形式多样、研究方法各异,这使得非凸优化问题比凸优化问题更具有挑战性。因此,如何针对非凸损失函数,定义相应的性能指标并给出相应的在线分布式优化算法设计方案是极具挑战的。 (2) 遗憾下界。目前,现有工作大多致力于推导算法的遗憾上界,而对于此上界是否为最优的讨论极少。而我们知道,算法的遗憾下界决定了算法的收敛性能极限,这对深入研究在线分布式优化算法的收敛性质是极为关键的。因此,借助凸优化理论刻画算法的遗憾下界甚至证明遗憾上界和下界是阶次一致的,是一个值得深入研究的课题。 (3) 自适应学习率。现有部分工作在设计学习率时要么用到总的迭代轮数的信息,要么用到所有损失函数的次梯度的共同范数上界,而算法在更新当前时刻的决策时是无法知道未来损失函数的信息。在分布式环境中,自适应学习率的设计尤为关键,它可以减少智能体之间协调学习率的次数,从而降低通信成本。因此,这些设计都存在局限性,如何设计一类只基于历史信息的自适应学习率是一个值得继续探索的方向。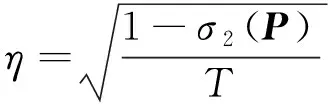
3.4 在线分布式Frank-Wolfe算法
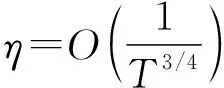
3.5 在线分布式原始-对偶次梯度算法
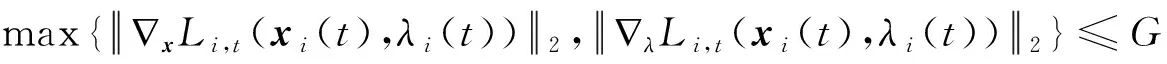
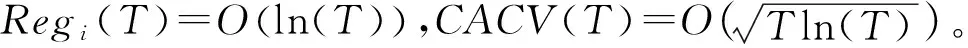
3.6 其它算法
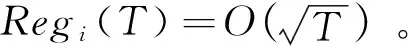
4 在线分布式优化算法的应用
4.1 分布式机器学习
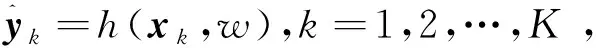
4.2 多智能体Multi-Armed Bandit问题
5 总结与展望
猜你喜欢
纺织科学研究(2021年9期)2021-10-14
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
学周刊(2016年23期)2016-09-08
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
知识窗(2009年1期)2009-09-24
知识窗(2009年5期)2009-06-23
军事历史(1997年5期)1997-08-21
