
Prefix-LSDPM:面向小样本的在线学习会话退出预测模型
2023-11-06 12:34王占全
华东理工大学学报(自然科学版) 2023年5期
陈 芮, 李 飞, 王占全
(华东理工大学信息科学与工程学院, 上海 200237)
在智慧教育领域中,学生辍学预测(Student Dropout Prediction, SDP)[1]研究被广泛重视,研究者们使用定量和定性方法分析学生的整体学习过程,并预测其课程辍学概率。然而目前针对在线学习会话退出预测(Learning Session Dropout Prediction, LSDP)任务的相关研究仍然较少[2]。Lee 等[3]在2020年经调研发现当时还未有关于MOOC 中学习环节退出的预测研究,因此对移动学习环境下的学习环节辍学预测问题进行了定义。LSDP 旨在预测学习者在智能辅导系统(Intelligent Tutoring System, ITS)中的学习退出行为,能够挖掘学习者退出学习的具体时机。与SDP 相比,LSDP 能够提供更细粒度的结果,有助于智能辅导系统及时采取干预措施以维持学习者的学习状态,辅助学习者继续完成当前学习项目或推荐学习路径的下一个学习项目,提高学习者的学习效率。已有的LSDP 相关研究中仍存在以下难点:(1)与SDP 相比,LSDP 对预测的即时性和准确率要求更高;(2)LSDP 是基于实时产生的学习行为数据进行预测,缺乏大规模的平行数据,难以训练高质量的模型;(3)学习会话相较于课程,退出频率更高,学习行为数据更具有碎片性,预测难度更高。
本质上,LSDP 任务属于学习序列分析问题。在近期研究中,同属于该类问题的知识追踪[4-5]、教育资源推荐[6-7]等任务在基于预训练-微调范式的方法中取得了较好的效果。微调(Fine-tuning)是在大型预训练模型的基础上训练下游任务的主流范式[8],需要在预训练的基础上进一步更新和存储模型的所有参数,需要为每个任务存储完整的模型参数副本。即使预训练模型已经能够获得不错的词向量表示能力,在不同的下游任务中也需要通过对应的训练数据进行微调。为了在下游任务上获得优异的性能,Fine-tuning 需要的数据规模与预训练模型的参数规模成正相关。因此,预训练-微调范式模型训练所需的参数量和数据量是巨大的,例如基础的BERT 模型需要108 M 参数[9],经过大幅度降参优化后基础的ALBERT(A Lite BERT)模型也需要12 M 参数[10]。在缺乏足够平行数据的情况下,基于预训练-微调范式的模型难以达到理想的预测效果。而在实际的ITS(Intelligent Tutoring System)场景中,学习者的在线学习行为的平行数据往往很少,导致通过微调的方法训练得到的模型的准确率较低。
最近,基于提示学习的训练范式[11]在多个任务上展现了出色的小样本性能。提示学习冻结预训练模型的部分参数并添加极少量的可训练参数用于适配不同的下游任务,从而大幅减少了训练下游任务时需要更新的参数量,降低了对训练数据量的要求,即使在极少的训练数据情况下也能够达到较好的效果。因此,基于提示学习的训练范式更能够适应在线教育平台的小样本学习要求。由于LSDP 任务将学习者在线学习会话行为特征序列化后作为输入,无需采用自然语言形式的提示模板,因此,采用连续提示向量的前缀提示(Prefix-tuning)[12]是提示学习范式中最适合LSDP 任务的方法。Prefix-tuning 在原始输入的词中嵌入向量和在预训练模型中的Query 和Key 向量之前添加额外的连续提示向量,从而影响后面的向量表示。与微调全部预训练模型的参数相比,Prefix-tuning 只需训练额外添加的提示参数,能够保证小样本条件下的预测效果。
为了解决现实场景中因训练数据不足导致的在线学习会话退出预测准确率较低的问题,本文提出了一种基于Prefix-tuning 的小样本学习会话退出预测模型(Prefix-Learning Session Dropout Prediction Model,Prefix-LSDPM)。该模型利用Prefix-tuning 学习框架在大规模预训练语言模型的基础上挖掘并建模同一学习行为特征间的关系和连续学习行为间的上下文隐含关联,实现了小样本场景下高准确率的在线学习会话退出预测。
1 基于Prefix-tuning 的在线学习会话退出预测模型
1.1 任务定义
在LSDP 任务中,不仅要关注学习者执行同一动作的特征上下文,也要注意学习者前后动作上下文。在此设置下,将学习者在线学习会话相关属性进行形式化定义。学习者Un在学习过程中会产生多个学习会话Sm(m∈{1,2,···,M} ),在一个学习会话过程中,学习者连续参与学习活动,对在线教育平台中各模块进行访问和交互,进行连续请求动作。每个Sm由多个学习行为At(t∈{1,2,···,T} )组成。每个学习行为At包含多个学习行为特征fi(i∈{1,2,···,I} )。
在每个学习阶段中,当学习者在足够长的时间内不出现新的学习动作和活动时,代表发生了学习中途退出,标志着学习会话的结束,记为学习会话退出。Halfaker 等[13]研究了各个领域的用户行为数据,提出了一种用于识别用户活动集群的方法,研究得出对用户行为聚类效果最好的时间阈值为1 h。本文引用其研究结果作为学习会话退出的阈值,即当用户最后一次交互行为发生后1 h 内仍未发生新的交互时,则标记该交互行为为退出行为。LSDP 任务即对学习者在线学习过程中执行当前行为时退出概率的估计,如式(1)所示。
其中dt表示会话退出状态。当学习者Un在当前发生行为At时退出当前会话,则At对应的dt取值为1,否则取值为0。将学习者连续学习行为特征以键值对的形式序列化为x,由k个行为组成的序列x包含k组学习行为特征,其中以键值对的形式输入,如式(2)所示。
由θ参数化的LSDP 模型建模为Pθ(dt|x)。当输入为x时,取Pθ(dt|x)最大时的dt作为输出。
1.2 Prefix-tuning
Fine-tuning 与Prefix-tuning 框架对比如图1 所示。其中:X、Y分别为模型的输入和输出序列,eX为输入向量经过3 种嵌入转换的嵌入向量,e[P+X]为提示序列与输入序列的组合序列经过3 种嵌入转换的嵌入向量,P为提示序列。在预训练参数权重的基础上,Fine-tuning 针对下游任务训练并重新调整所有参数。与Fine-tuning 模式不同的是,Prefix-tuning 冻结预训练权重参数,仅通过调优前缀向量Prefix 以适应下游任务,大幅降低调优训练所涉及的参数量。

图1 微调和前缀提示框架对比Fig.1 Comparison of fine-tuning and prefix-tuning frameworks
Transformer 是预训练-微调范式与预训练-提示范式的基本结构,它由L层堆叠块组成,每层包含多头注意(Multi-Head Attention, MHA)和全连接前馈网络(Feed-Forward Network, FFN),注意函数由查询Q∈Rn×dk和键值对K∈ Rm×dk、V∈ Rm×dk映射得到,如式(3)所示,其中n和m分别是查询Q和键值对K、V的数量。
Prefix-tuning 将r个可调前缀向量Pk、Pv∈Rr×e与Transformer 本身的K、V连接,设置于每一层Multi-head 的键K和值V之前,对新的向量K'、V'进行多头注意,如图2 所示。
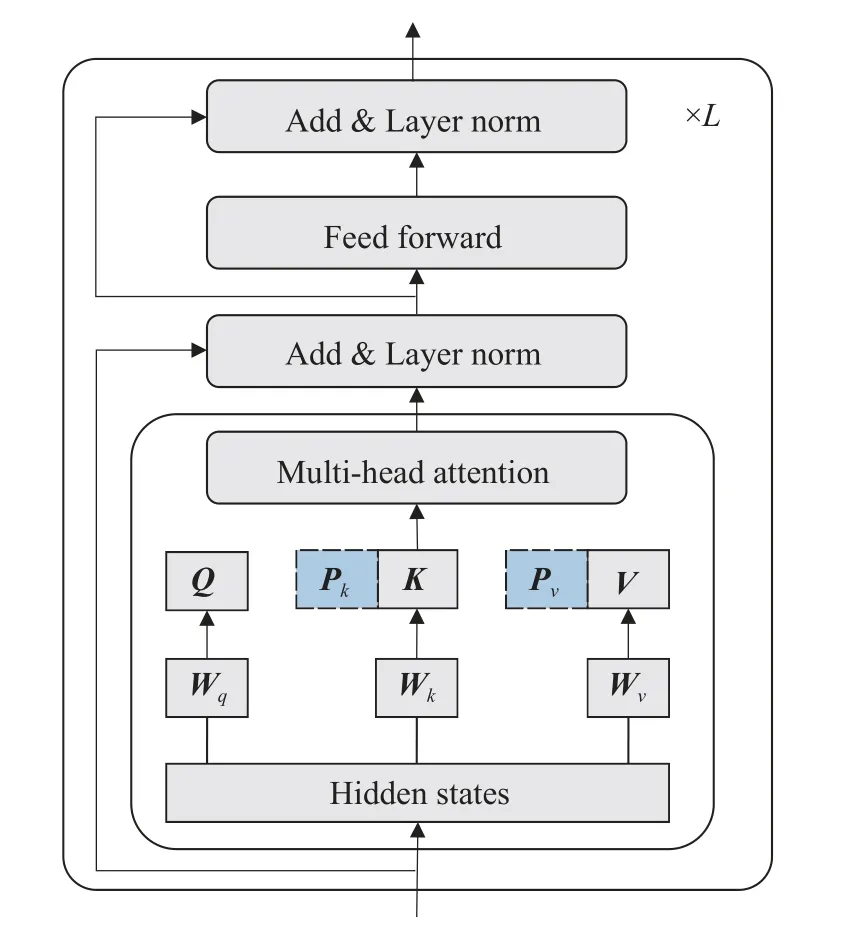
图2 Prefix-tuning 在Transformer 结构上的优化Fig.2 Optimization of Prefix tuning on Transformer structure
式(4)中headi的计算优化为式(6),其中和表示第i个头部提示向量,Concat 表示矩阵拼接。
1.3 Prefix-LSDPM
Prefix-LSDPM 的主要架构如图3 所示。Prefix-LSDPM 将提示序列作为前缀设置于学习行为特征输入序列之前,将学习会话退出状态目标序列设置于输入序列之后。冻结预训练模型参数权重,在改进的Transformer 网络中通过双向、单向混合注意模式对合成序列进行掩码,充分挖掘学习者单个学习行为内部特征及连续学习行为之间的隐含关联,生成激活函数后以最大化退出状态预测正确概率为目标更新迭代前缀提示参数。以下分别从提示模板设置、小样本掩码学习、退出状态预测映射三方面对Prefix-LSDPM 进行详细描述。

图3 Prefix-LSDPM 主要架构Fig.3 Main framework of Prefix-LSDPM
1.3.1 提示模板设置 将连续学习行为特征组以键值对的形式序列化为x,提示序列记为Prefix,x对应的学习会话退出状态目标序列记为dt。将Prefix 作为前缀序列与输入序列x和目标序列dt依序串联为序列z= [Prefix;x;dt],作为Prefix-LSDPM 的输入序列,如图3 中的输入token 所示。其中[SOS]作为起始符添加在每个输入序列前,[ACT]定义为不同行为之间的特殊分隔符,[EOS]用于标记每段序列的结束以分隔三段序列。
将z以token 嵌入(token embeddings)、分段嵌入 (segment embeddings)和位置嵌入 (position embeddings)这3 种方式嵌入embeding。其中token embedding 将各个行为特征值转换成固定维度的token 向量;segment embeddings 将学习行为序列分段标记为向量表示,以区分不同学习行为;position embedding 的向量表示使模型学习到输入序列token 的顺序属性,不同位置上的向量可能存在相同token 内容,但具有不同的含义。嵌入后,得到连续提示序列矩阵Pe、输入序列矩阵Xe和目标序列矩阵De连接组成的输入矩阵[Pe;Xe;De]∈,该合成矩阵框架即为Prefix-LSDPM 的提示模板。其中Pidx、Xidx、Didx分别为Prefix、x、dt的token 索引,|Pidx|、|Xidx|、|Didx|表示对应序列包含的token 数。
1.3.2 小样本掩码学习 合成矩阵[Pe;Xe;De]输入图2 所示的L层Transformer 网络,将一定比例的输入token 随机掩码为[MASK],通过预测这些掩码token 以学习和理解行为特征序列关系。在如图3 所示的L层Transformer 网络中利用多头注意力学习行为特征隐藏向量的深度双向表示。掩码矩阵M决定一对token 是否可以相互关注,如式(7)所示,其中自注意力掩码方式如图4 所示。
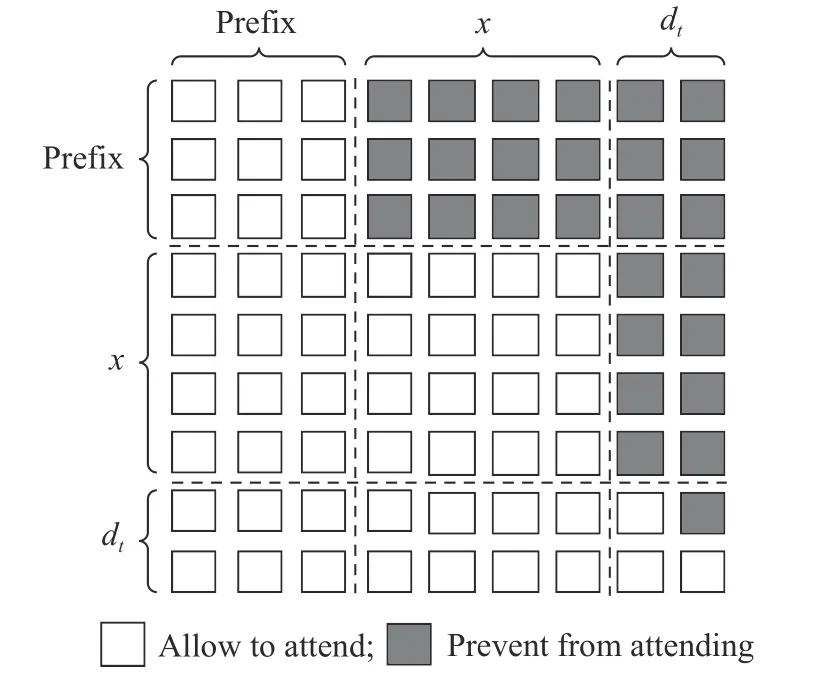
图4 自注意力掩码Fig.4 Self-attention mask
掩码矩阵M的Prefix 列全部设置为0,表示Prefix 内部能够互相关注,且能够注意到后续x和dt的token 内容。x列中,Prefix 行设置为 -∞ ,x行与dt行设置为0,表示x无法关注到Prefix 中的token,x内部向量能够互相关注,且能注意到后序dt的token。dt列中,Prefix 行与x行全部设置为 -∞ ,dt行右上角部分设置为 -∞ ,表示dt无法关注到Prefix 和x中的token,且在dt内部单向注意。基于该掩码矩阵M的注意模式,将dt作为监督信号,冻结预训练参数,仅更新提示参数矩阵Pe以最大化dt的概率。
时间步s对应的激活函数hs∈ Rd,其中,hs=表示时间步s第j层的激活向量。沿用预训练模型的参数权重PLMφ,以z的第s个token 及左侧上下文中的激活函数来计算hs,如式(8)所示:
其中Pθ∈R|Pidx|×dim(hs)为由参数θ形成的前缀激活函数矩阵。PLM 的参数 ϕ 是固定的,只有参数θ为可训练参数。相比于整体微调,前缀提示调优减少了总体训练涉及的参数量,为小样本学习的快速收敛提供了基础。将提示序列设置于序列前端,即使参数ϕ固定不变,提示后序的所有激活函数仍然能够受到前缀提示激活函数的影响。因此,每一个hs均能够影响并训练Pθ。hs的最后一层用于计算下一个token 的概率分布。
其中Wϕ为将激活函数映射至词汇表的矩阵。以最大化当前学习行为对应的学习会话退出状态正确概率Pθ(dt|z)作为目标,优化提示参数θ,训练得到Prefix-LSDPM。
1.3.3 退出状态预测映射 在下游任务进行学习会话退出预测时,模型按照提示模板以前缀形式与输入学习行为特征序列连接,并在输入序列后端进行Mask 掩码,基于参数θ生成激活函数,通过softmax分类器映射生成退出状态预测的概率分布,将概率最大的退出状态映射至[MASK]作为预测输出。例如,给定一组学习特征序列,模型按照提示模板将提示序列p以前缀形式与输入序列连接,将学习退出状态进行Mask 后输入的token序列为[SOS]p[EOS][ACT][EOS][MASK] [EOS]。这些掩码后的token 序列经过多层Transformer 得到的隐藏层向量依次为h[SOS]、hp、h[SOS]、、h[ACT]、,h[EOS]、h[MASK],接着隐藏向量h[MASK]被输入到softmax分类器中进行线性分类,生成退出状态预测的概率分布Pθ(dt|z)。最后,预测概率最大的token 被追加到序列以替换[MASK],序列结尾的[EOS]出现即标志着预测结束,停止生成激活函数,该token 即作为当前学习行为序列中最后一个与行为对应的学习会话退出状态预测结果。
2 实验设置
2.1 数据集
实验基于3 个数据集进行研究,分别为EdNet[14]、XuetangX 1、XuetangX2。其中EdNet 数据来自大型英语在线教育平台Santa,XuetangX 1 和XuetangX2 数据来自目前中国最大的MOOC 平台之一“学堂X”(https://xuetangx.com)。数据集具体描述如下:
(1) EdNet 收集了从2018 年8 月27 日至2019年11 月27 日记录的学习者学习活动最细粒度的交互数据,详细记录了每个学生的行为细节特征,该数据集包含297 915 名学习者共131 441 538 条学习行为记录。
(2) XuetangX 1 收集了39 节教学模式的课程中涉及的 112 448 名学习者的学习行为。该数据集包含 1 319 032 个视频活动、10 763 225 个论坛活动、2 089 933 个作业活动和 7 380 344 个网页活动。
(3) XuetangX 2 收集了 698 节教学模式课程和515 节自学模式课程中涉及的 378 237 名学习者的学习行为。该数据集包含 88 904 266 个视频活动、534 369个论坛活动、10 912 803 个作业活动和 14 727 348 个网页活动。
按照8∶1∶1 的学习者数量比例将预处理后的数据集划分为训练集、验证集和测试集。处理后的数据集统计结果如表1 所示。
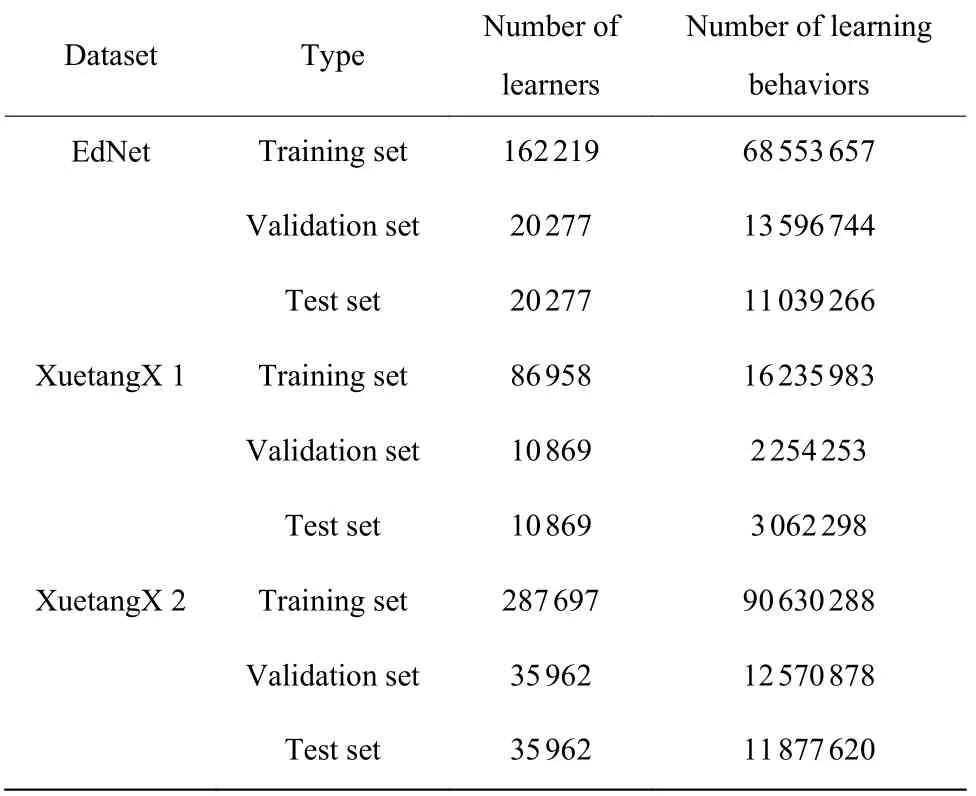
表1 处理后的数据集统计结果Table 1 Statistics results of processed datasets
2.2 预训练模型
Prefix-LSDPM 在预训练模型参数的基础上对针对下游学习会话退出预测任务进行提示调优。为避免不同预训练模型对Prefix-LSDPM 性能的影响,实验基于以下3 个预训练模型进行研究。
(1) BERT[9]谷歌提出的经典预训练模型,使用MLM 任务和NSP 任务进行双向预训练。
(2) ALBERT[10]谷歌在BERT 的基础上提出的改进预训练模型,将BERT 模型通过因式嵌入和跨层参数共享这两种方式进行降参优化,并基于MLM 任务和SOP 任务进行双向预训练。
(3) UniLM[15]微软提出的统一预训练模型,针对单向、双向、序列到序列这3 种模式进行无监督联合预训练。
2.3 参数设置
在训练之前,采用合成少数过采样技术(Synthetic Minority Oversampling Technique,SMOTE)[16]对 dropout 标签进行过采样,将 dropout 标签比例保持在 1∶1 左右。采用MetaPrompting[17]软提示初始化方法,该方法被证明能够自动生成达到最佳性能的提示初始化向量,通过元学习算法自动找到最优的提示初始化向量,以促进快速适应学习会话退出预测的提示任务。
为避免不同预训练模型对Prefix-LSDPM 性能的影响,实验分别在3 种预训练模型BERT、ALBERT和UniLM 的基础上对Prefix-LSDPM 的性能进行测试。其中BERT 和ALBERT 均采用base 版本的模型,3 个预训练模型中的Transformer 网络层数(L)均为12。在每个Transformer 层中,每个多头注意力层均由 8 个头组成。模型采用Adam 优化器,学习率为10-3,超参数β1= 0.9,β2= 0.999。每组实验包含 12个 epoch,其中每个 epoch 包含 100 个 step,batch size设置为8。使用在验证集中获得的最佳曲线下面积(AUC)的模型参数在测试集上进行测试。
3 实验设计与结果讨论
3.1 提示长度消融实验
为了探究提示矩阵Pe维度与不同预训练模型对Prefix-LSDPM 性能的影响,将提示序列长度作为控制变量,对基于BERT、ALBERT、UniLM 这3 种预训练模型的Prefix-LSDPM 进行消融实验,分别记为 BERT+Prefix-LSDPM、 ALBERT+Prefix-LSDPM和UniLM+Prefix-LSDPM 实验组。该消融实验旨在得出能够使Prefix-LSDPM 达到最佳预测性能的提示序列长度,并针对基于不同预训练模型的Prefix-LSDPM 的性能进行对比。本文基于EdNet 数据集对以上模型实验组进行训练,通过ROC 曲线的AUC和预测准确率(ACC)指标对模型效果进行衡量。基于不同预训练模型的Prefix-LSDPM 随着提示长度变化的AUC 和ACC 消融实验结果如图5 所示。
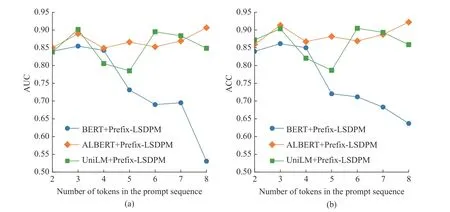
图5 基于不同预训练模型与提示序列长度的AUC 和ACC 消融实验结果Fig.5 AUC and ACC ablation experiment results based on the performance of pre-training model and prompt sequence length
由图5 可知,基于BERT、ALBERT、UniLM 这3 个预训练模型进行提示调优的Prefix-LSDPM 在提示序列长度为3 个token 时达到了局部峰值。当提示序列长度为4 个和5 个token 时, BERT 和UniLM实验组模型性能相比提示序列长度为3 个token 时有较大幅度的下降,ALBERT 实验组模型性能相比提示序列长度为3 个token 时有较小幅度的下降。当提示序列长度为6、7 个和8 个token 时,ALBERT和UniLM 实验组模型相比提示序列长度为4 个和5 个token 时取得了较好的效果,而BERT 实验组随着提示序列长度的增加,预测性能大幅度下降。
基于该消融实验结果可以得出,在3 个预训练模型的参数基础上,能够使Prefix-LSDPM 达到最佳预测性能的最佳提示序列长度均为3 个token。其中基于ALBERT 的Prefix-LSDPM 预测性能受提示序列长度的影响不大,且能保持较好的预测性能。基于BERT 的Prefix-LSDPM 预测性能相比基于ALBERT的Prefix-LSDPM 预测性能较差,原因是ALBERT 采用SOP 任务代替了BERT 中的NSP 任务进行双向训练。SOP任务旨在挖掘句子间的关联性,在LSDP 任务中,ALBERT 在挖掘学习行为特征间关联的基础上,还对学习行为间的隐含关联进行了重点关注,因此基于ALBERT 的Prefix-LSDPM 能够取得较好的预测性能。虽然UniLM 与BERT 采用相同任务进行训练,但UniLM 将单向、双向和序列到序列这3 种注意力掩码方式相结合,为Prefix-LSDPM 中的混合注意力掩码方式提供了更好的预训练基础,因此基于UniLM 的Prefix-LSDPM 也能取得较好的预测性能。
3.2 提示范式与微调范式对比研究
为了探究Prefix-LSDPM 在性能与参数量方面相对于预训练-微调范式模型是否有改进,在消融实验探究的最佳提示长度下,基于BERT、ALBERT、UniLM 这3 种预训练模型将Prefix-LSDPM 与全参数微调预测性能及拟合所需参数量进行对比,实验结果如表2 所示,其中Fine-LSDPM 表示针对学习会话退出预测任务的双向微调。实验结果显示,在同一预训练参数的基础上,Prefix-LSDPM 的预测性能相比Fine-LSDPM 均有一定程度的提升,其中基于BERT、ALBERT 和UniLM的AUC 分别提升了0.003 7、0.005 19 和0.034 0,基于BERT、ALBERT 和UniLM的ACC 分别提升了0.007 9、0.063 4 和0.037 1;在参数量方面,基于BERT、ALBERT 和UniLM 的Prefix-LSDPM 训练参数量分别是Fine-LSDPM 的0.24%、0.56%和0.13%,Prefix-LSDPM 有效降低了调优训练所涉及的参数量,使模型训练的复杂度和训练时长大幅降低。该实验结果表明,Prefix-LSDPM 将预训练参数冻结后仅更新前缀提示参数的训练方式,能使下游任务建模更靠近预训练模式,并将预训练模式中已经学习记忆的知识进行快速检索,在涉及参数量较少的同时,使模型训练更加迅速且准确。
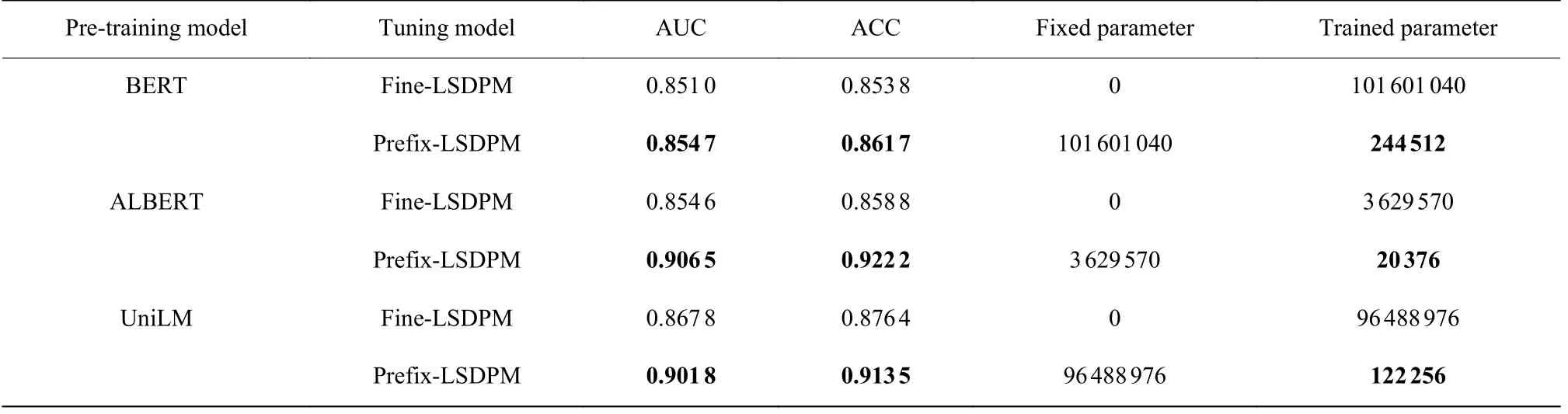
表2 Fine-LSDPM 与Prefix-LSDPM 对比结果Table 2 Comparison between Fine-LSDPM and Prefix-LSDPM
3.3 小样本性能研究
为了探究Prefix-LSDPM 是否能在小样本数据下达到理想效果,随机对EdNet 的训练集进行一定比例的下采样,构造训练集的子集,针对不同数据量分别以Fine-LSDPM 和Prefix-LSDPM 模型进行训练。表3 示出了不同训练数据量下各模型能够达到的最佳AUC,其中百分数表示训练样本数为全部样本数的比例。
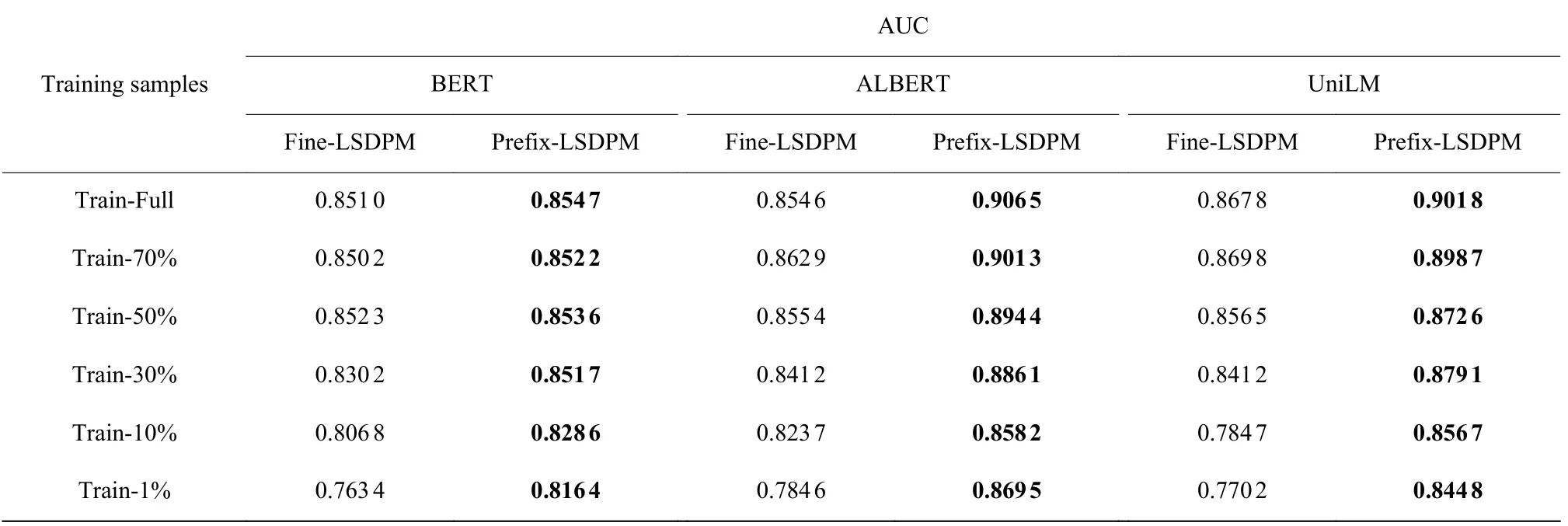
表3 不同训练数据量下各模型的最佳AUCTable 3 Best AUC that each model can achieve under different training data
实验结果显示,在3 种预训练模型的基础上,Fine-LSDPM 在训练样本为30%时AUC 预测性能均有明显的下降,而Prefix-LSDPM 在训练样本减少为10%时AUC 才有小幅度的下降。且在1%训练样本情况下,基于BERT、ALBERT、UniLM 的Prefix-LSDPM 的预测AUC 相比Fine-LSDPM 分别提升了0.053 0、0.084 9 和0.074 6。相当于Prefix-LSDPM 在基于约1 622 名学习者的约685 536 条学习行为样本进行训练即可达到比微调方法性能更好的效果。因此,Prefix-LSDPM 通过冻结预训练参数以减少迭代参数量的模式能够适应小样本学习,且达到较好的预测效果。
3.4 对比实验
本文将Prefix-LSDPM 和以下模型分别在数据集EdNet、XuetangX 1 和XuetangX 2 上进行训练,其中(1)、(2)、(3)为时序挖掘模型,(4)、(5)为最近会话退出研究中性能表现较好的模型。
(1) 长短期记忆网络(Long Short-Term Memory,LSTM) 将LSTM 按照文献[18]的架构进行训练。该模型由3 层组成,每层有 60 个神经元,用 Adam 优化器和交叉熵损失训练了 1 000 个 epoch。
(2) 可变长度马尔可夫链 (Variable Length Markov Chain, VLMC)[19]对学习者交互项目序列进行建模,最大上下文长度设置为 4。
(3) 马尔可夫调制标记点过程模型(Markov Modulated Marked Point Process Model , M3PP)[20]该模型对访问的单个页面的序列和在页面上花费的时间进行建模。形式上,将点击流建模为连续过程。该模型在在线行为序列分析任务上效果较好。
(4) 多层感知器 (Multilayer Perceptron, MLP)[21]该模型为最新研究用于学习会话退出预测任务的有效方法[14]。参考该研究设置,将学习行为数据建模为“句子”形式作为输入,以双矩阵结构建模学习行为特征序列,随着学习行为的增加更新矩阵参数。
(5) 深度注意会话退出预测模型(Deep Attention Session Dropout Prediction Model, DAS)[3]该模型基于单层Transformer 实现了LSDP 任务。在这项研究中,效果最好的序列长度是 5,本文应用该结论进行对比实验。
根据消融实验探究结果,设置提示序列长度为3,将基于ALBERT 预训练模型的Prefix-LSDPM 在3 个数据集上分别进行训练,与以上5 个模型的对比实验结果如表4 所示。
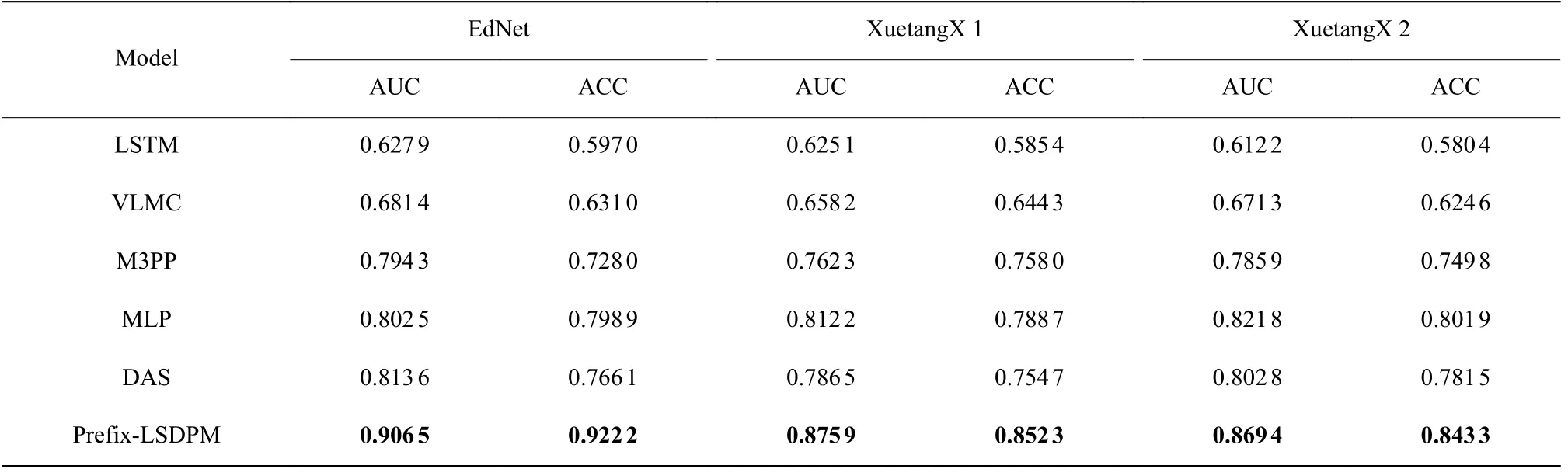
表4 不同模型在不同数据集上的对比实验Table 4 Comparative experiments of different models on different datasets
实验结果显示,基于ALBERT 预训练模型的Prefix-LSDPM 在数据集 XuetangX 1 和 XuetangX 2上进行提示调优预测的最佳 AUC 可以分别达到 0.875 9和0.869 4。在相同数据集上,Prefix-LSDPM的预测性能优于经典的时序挖掘模型LSTM 和VLMC。与在线页面访问时序挖掘模型M3PP 相比,Prefix-LSDPM的最佳AUC 在EdNet、XuetangX1、 XuetangX2 这3 个数据集上分别提升了0.112 2、0.113 6 和0.083 5。目前在LSDP 任务的现有先进模型中,MLP 和DAS模型在会话退出预测任务中是最新且表现最好的。其中与MLP 相比,Prefix-LSDPM 的最佳AUC 在EdNET、XuetangX1、 XuetangX2 这3 个数据集上分别提升了0.104 0、0.063 7 和0.047 6;与DAS 模型相比,分别提升了0.092 9、0.089 4 和0.066 6。实验结果表明,Prefix-LSDPM 在预训练参数基础上对在线学习行为特征进行提示调优的方式,能够更充分地挖掘连续学习行为间及学习特征间上下文隐含关联,准确提取连续学习行为序列与学习会话退出模式。Prefix-LSDPM 具有更好的时序序列挖掘效果,相比现有先进模型具有更高的预测准确率。
4 结 论
本文提出了一种基于前缀提示的小样本在线学习会话退出预测模型Prefix-LSDPM。该模型将预训练-提示-预测范式扩展至在线会话退出预测任务。针对现实场景中因数据不足导致实际预测效果不理想的问题,设计适应于小样本学习行为的前缀提示调优方法。将前缀提示可调向量与Transformer 结构内部键值对连接,固定冻结预训练权重参数,通过会话退出监督信号对前缀提示参数进行调优,相比微调方法能有效降低针对下游任务调优训练所涉及的参数量。针对前缀提示模板,设计多层Transformer网络注意力掩码方式对同一学习行为特征间上下文和连续学习行为间上下文的隐含关联进行掩码学习,为模型的准确预测提供基础。基于3 个预训练模型和3 个数据集对模型进行训练,实验结果表明,Prefix-LSDPM 能够在小样本学习情况下达到较好的预测准确率,且比现有学习会话退出模型具有更好的预测效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
海外华文教育(2016年4期)2017-01-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
浙江大学学报(工学版)(2015年4期)2015-03-01
