
基于距离策略的知识图谱图卷积网络推荐算法
2023-11-20 10:58邢长征刘义海郭亚兰郭家隆
计算机工程与应用 2023年21期
邢长征,刘义海,郭亚兰,郭家隆
辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105
随着互联网技术的发展和网络信息的不断增多,用户很难在海量数据中选择自己需要的信息,为了提升用户对信息资源的利用率,精准地为用户提供有效信息,推荐系统已经广泛应用于互联网上各种推荐场景。一个完整的推荐系统一般由用户、物品以及推荐载体共同组成,通过推荐算法分析出用户可能感兴趣的物品,并将推荐结果展示在推荐载体上,同时,推荐算法也可以利用用户获得推荐结果后的反馈信息,对算法参数进行调整,提高后续推荐的质量。
为了更好地解决推荐过程中的数据稀疏及冷启动的问题,近年来将知识图谱作为辅助信息融入推荐算法的方法[1]引起了国内外的关注,知识图谱可以将推荐系统中的实体通过实体之间的关系建立连接,依据数据自身存在的拓扑关系挖掘更多的用户或项目的隐藏特征。现如今,推荐算法中对知识图谱的处理方法可以大体分为设计元路径[2]、使用注意力机制分配节点权重[3]选取固定的节点接受域[4]和设计多图对比学习[5]等方法。设计元路径的方法可以考虑到知识图谱中的多元关系,在个性化推荐方面表现优异,但是元路径设计依赖于对知识图谱结构的考察,不同的知识图谱需要设计不同的元路径,存在元路径设置困难、普适性较差的问题。依赖注意力机制分配权重的方法使用注意力机制区分邻居节点的重要性,普适性相对较强,但是在处理知识图谱和模型训练时复杂度较高,存在模型训练开销过高、训练成本过大的问题。选取固定接受域的方法可以有效控制模型的训练成本,但是接受域设置方面同样存在困难,在接受域设置过大时,会受到过远距离节点产生的噪声干扰从而影响模型性,在接受域设置过小时,会产生知识图谱中的数据资源利用不足的问题,最终影响的推荐结果。建立多图进行对比学习可以将知识图谱细化,在每个图内进行交互对比学习,在知识图谱特征挖掘方面表现优异,但是在多图建立方面复杂度过高,在知识图谱处理方面会耗费大量时间,在规模较大的数据集上并不适用。
针对上述问题,本文提出了一种基于距离策略的知识图谱图卷积推荐算法。该算法将知识图谱中的节点划分为中心节点和辅助信息,使用了距离策略重构知识图谱,通过优化实体、关系邻接矩阵来缩减知识图谱处理和模型训练的开销,并建立了新的邻域聚合结构处理知识图谱中的信息,依据距离-影响力函数缩减知识图谱中远距离邻居节点的影响,不必再进行接受域的相关设置,避免了远距离节点对模型造成的干扰和近距离节点资源利用不足的问题,在知识图谱和模型训练时模型造成的开销远低于其他方法,提高了模型的训练效率和普适性,更具有实际应用的价值。
1 相关工作
1.1 基于知识图谱的推荐算法
知识图谱的嵌入方法分为两类[6]:基于翻译的模型如TransE[7]、TransR[8]、TransH[9]等;语 义 匹 配 模 型,如RESCAL[10]、DistMult[11]等。采用知识图谱嵌入的方法可以在知识图谱内部完成特定的任务,例如推理、预测、分类等,然而推荐领域需要利用已经对项目实体构建好的知识图谱为模型提供更多有效的辅助信息,例如知识图谱中代表辅助信息的节点和代表节点关系的边,以上知识图谱嵌入的方法并不适用。
参考知识图谱嵌入方法对知识图谱中的数据结构处理,目前基于知识图谱辅助的推荐算法可以划分为三种:基于嵌入的方法[12]、基于路径的方法[13]和统一的方法[14]。基于嵌入的方法一般直接利用来自知识图谱的信息,将高维知识图谱中的实体和关系降维,将低维的向量化结果以辅助信息的方式嵌入训练模型,这类方法的优点是数据降维处理简单,训练开销较低,但是该方法忽略了知识图谱的连通性,对知识图谱中关联关系的提取能力较弱,而且对数据噪声的处理能力不足,会影响推荐效果。基于路径的方法通过知识图谱中的图节点连通路径计算模型中用户和项目的相似度完成推荐,利用知识图谱将用户与实体通过不同类型的关系连接,考虑到了知识图内数据关系的问题,有较强的可解释性,但是该方法在建立模型前需要依据知识图谱的结构设计元路径,元路径设置的困难也导致模型通常不具备普适性。统一的方法是前两种方法的融合,有设计接受域、建立多图进行对比学习和用注意力机制分配权重等多种方式,在挖掘用户潜在偏好、提取邻居节点特征信息上有着出色的表现,但是该方法目前也存在接受域设计缺少普适性、建立多图的复杂度较高、模型训练开销过高等问题。本文提出的D-KGCN 是一种基于统一的方法,通过对知识图谱进行重构,解决了知识图谱中过远的辅助信息对实体信息的干扰,同时设计了基于距离策略的邻域聚合结构,通过减少聚合的阶数来达到缩短训练开销的目的。
1.2 基于图卷积网络的推荐算法
随着网络技术的不断发展,能获取到的数据不断增多,这就意味着数据的维度和结构更加复杂化。图卷积神经网络(GCN)模型在处理多维且不规则的空间结构数据上有着出色表现,在推荐领域上,使用GCN模型可以在处理多维数据的同时,考虑到数据之间的语义关联关系,高效学习数据的特征信息和结构信息。一般来说,GCN 可以分为谱方法和非谱方法,谱方法[15]表示图结构并在谱域定义卷积,通过图傅里叶变换和卷积定理定义卷积完成卷积运算,但是由于其卷积滤波未局限于顶点域,所以不适用于推荐领域。非谱方法[16]也叫空间方法,它直接对原始的图进行操作,并在目标顶点上定义节点组进行卷积,在推荐领域上,可以对多维且同构的数据进行充分且高效的利用。为了使用邻居节点包含的信息并且共享节点之间的权值,非谱方法一般从同构图中提取局部连通数区域或是选取固定大小的邻域集合。KGCN 模型[17]是一种非谱方法的知识图卷积推荐模型,它将重点放在对异构图的处理上,使用选取固定接受域的方法在异构图中高效提取信息。然而,类似的做法在处理拓扑结构过于复杂或者过于简单的节点时会造成信息资源的浪费或重复使用,在接受域设置上需要手动设置聚合的阶数和选取聚合的节点数。D-KGCN模型在KGCN模型的基础上进行了改动,在图卷积运算部分重新设计了节点聚合方法,利用经过重构的知识图谱生成用户与项目属性之间的邻接矩阵,在知识图谱利用方面,无论是简单还是复杂的数据集同样适用,与改动之前相比更具有普适性。
2 D-KGCN模型
2.1 问题描述
本文研究的主要问题是:在利用知识图谱作为辅助信息的推荐领域中,如何挖掘用户对实体的某些辅助信息的潜在兴趣,并通过分析用户的潜在兴趣,挖掘用户未直接接触过但与该辅助信息相关联的实体,从而对用户进行推荐。为解决这一问题,首先将用户与其交互过项目之间的隐式反馈作为推荐结果,例如点赞、评分、点击、浏览等行为;其次,根据已有的推荐结果,为该项目实体的辅助信息分配权重;最后,根据辅助信息的权重求出用户选择某个实体的概率,对用户未交互过的实体进行预测。
将M个用户组成的集合U={u1,u2,…,uM}与N个项目组成的集合V={v1,v2,…,vN}之间存在的隐式交互组成一个交互矩阵Y。用户-项目交互矩阵的形式为Y∈RM×N,yuv表示矩阵中用户u与项目v的交互信息,当yuv=1 时表示用户u与项目v存在例如评分、点击、浏览、购买等隐式的交互,不存在交互则yuv=0。
2.2 知识图谱
为了丰富项目实体所包含的信息,将项目实体与其相关的辅助信息通过关联关系联系起来构建成知识图谱G。将G={(v,r,m)|v,m∈E,r∈R}中的数据定义为三元组,其中v代表项目实体,m代表辅助信息,r表示实体与辅助信息的关联关系;E是所有实体组成的集合,R是实体中所有关系组成的集合。
在知识图谱中,节点由实体和辅助信息共同表示,两节点之间的边由实体与辅助信息的关系表示,由于节点之间的关系的多样性,知识图谱中的信息在结构上存在很大差异,导致知识图谱存在异构性。要利用知识图谱中丰富的节点信息和异构的图谱信息,需要为实体生成实体邻接矩阵、关系邻接矩阵,但是直接对知识图谱求邻接矩阵的复杂度为O((v+m)2),在大规模知识图谱的使用中需要耗费大量运算时间。
为解决这一问题,D-KGCN通过重构知识图谱优化生成的邻接矩阵,具体做法是将项目实体节点v视为中心节点,辅助信息m视为邻居节点,依据知识图谱中的信息为每一个中心节点和与其相关联的辅助信息生成一个子图,在子图中,对距中心节点过远的辅助信息进行一个初步的裁剪,最后依据所有子图重新生成邻接矩阵。
对中心节点vx来说,有着最大影响力的信息应该是与其直接相连的一阶邻居节点与边,因为这些信息与vx有着直接的关联关系,并且高阶邻居节点对中心节点的影响力应该随着距离的增加而减弱,例如电影《傲慢与偏见》中,一阶邻居节点包括主演凯拉·奈特莉,当推荐的项目是电影时,主演应该有着较强的影响力,与凯拉·奈特莉直接相连的二阶邻居节点包括其自身信息,如国籍、好友或者搭档等,如果二阶的邻居节点仅与一阶节点有着直接的关联关系,与中心节点并无直接连接,那么演员国籍等二阶节点对中心节点《傲慢与偏见》的影响力就应该小于直接参演电影的凯拉·奈特莉,而三阶以上的节点可能包含与其同国籍的演员、好友的个人信息等信息,这些信息与电影《傲慢与偏见》的交集相对不大,对电影的影响力显然应该小于直接参演的演员和演员自身信息。以此类推,距离中心节点越远的节点对中心节点的影响力就越小,那么在划分子图时,初步截取掉距离中心节点距离过远的节点和边,可以在降低模型复杂度的同时减少无效信息的干扰。
在划分子图时,为了尽可能保留子图的拓扑结构,将子图Gvx依据中心节点vx的一阶关系数划分成n个分支,每个分支包含中心节点、中心节点的某个一阶邻居节点和该一阶邻居节点之后的所有辅助信息节点,用深度优先算法求出子图Gvx在第n个分支上的最大深度maxvxn、最小深度minvxn:

在每个子图中,按照此方式对每个分支进行裁剪,并依照裁剪后的知识图谱构建新的邻接矩阵。
这样做的目的是在对子图进行裁剪的同时,尽可能保留每个子图的拓扑结构,在对信息比较丰富的中心节点进行裁剪时,可以截取掉过远的辅助信息,在对信息数目稀疏的节点进行裁剪时,将lvxn设置为向上取整,确保不会对稀疏的分支进行过度裁剪。知识图谱中的数据以三元组的形式存储,对知识图谱划分和裁剪的复杂度是O(v+m)。在子图上求实体邻接矩阵E~ 和关系邻接矩阵R~ 的复杂度为O(v∑l2),复杂度远小于直接对知识图谱求邻接矩阵O((v+m)2)。
2.3 知识图谱卷积网络
在得到邻接矩阵后,模型按照以下形式进行训练:
其中,Au为邻接矩阵,Du为用户邻接矩阵的三角对称矩阵。在得到实体的向量矩阵后,知识图谱中邻居节点的向量可以通过邻域聚合来表示中心实体的向量。
为了保证推荐系统具有个性化推荐的功能,同时利用知识图谱中节点的边信息,在利用知识图谱中的辅助信息为用户进行推荐的时候首先将用户与实体的关系考虑在内,例如在挑选电影时,有的用户更看重主演,有的用户更看重电影类型,建立用户与实体之间关系的评分来对节点进行监督。
通过一个内积函数f()· 表示用户与实体关系的分数Sru,u表示用户向量,r表示知识图谱中的关系向量,用户-实体关系的分数表示为:

其中,rv,m表示实体v与辅助信息m的关系,R~(v)表示实体v的关系矩阵。
在图卷积中,设计了距离策略来设置邻居节点对中心节点的影响,优先保证一阶邻居节点对中心节点的影响力,对于其他高阶节点,通过设计距离影响力函数来完成知识图谱中特征向量的聚合。
对实体v的聚合操作不再通过设置邻居节点的阶数进行,而是分为两部分。第一部分将中心节点的一阶邻居节点聚合成M1;第二部分将子图中除一阶邻居节点外的节点聚合按照距离影响成M2。
用E1(v)表示中心节点的一阶邻接矩阵,因为一阶邻域对中心节点的影响力最大,M1表示为:
其中,rv,m表示实体节点v与辅助信息m的关系。
子图中除一阶邻域以外的邻居节点,采用根据拓扑结构统一聚合的方式,同时考虑节点影响力与节点自身阶数的关系,通过建立距离影-响力函数P(x)=exp(-x)表示影响力随阶数增加而下降,其中x表示该节点据中心节点的距离,依据已经形成的实体邻接矩阵E,M2可表示为:
节点的影响力设置如图1所示。该图表示,对于中心节点v1来说,其一阶辅助信息节点v2、v3的影响力仅与节点之间的关系r13、r14有关,但是在二阶辅助信息及更高阶辅助信息节点的影响力设置上,除了节点之间的关系,还与该辅助信息节点距离中心节点的位置有关。例如对二阶辅助信息节点v5来说,P135表示该节点在分支v1→v3→v5上与中心节点之间的距离影响力,其对中心节点的实际影响力表示为r35·P135。
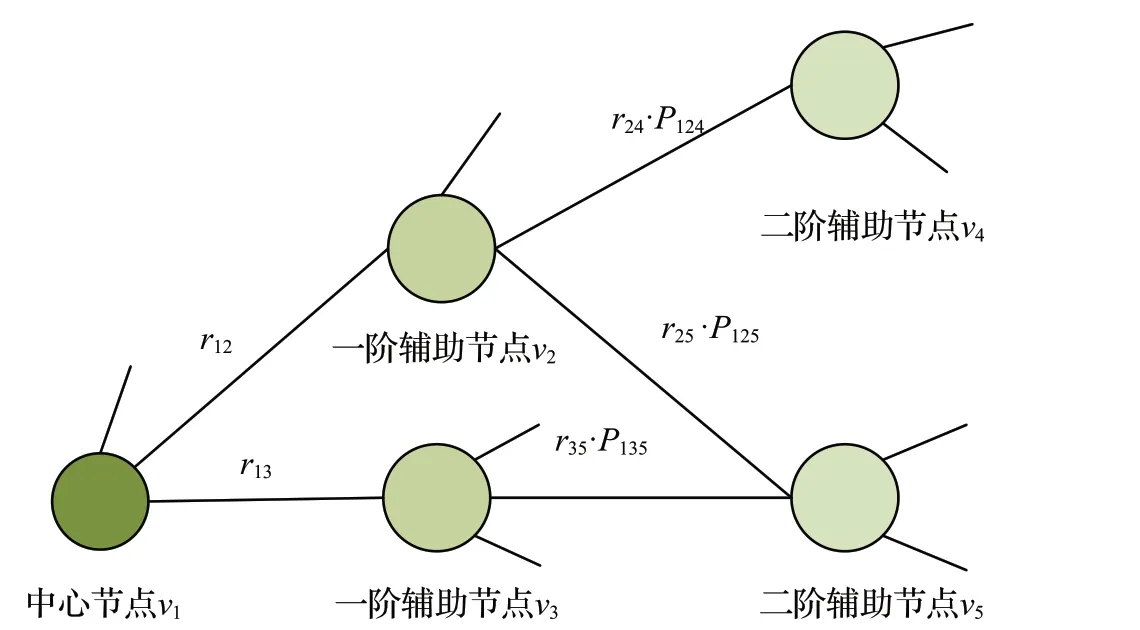
图1 节点影响力设置Fig.1 Node influence setting
与按阶聚合的方式相比,本文在邻域聚合阶段的时间复杂度从O(mk)变成了O(m2),k表示邻域中要聚合的辅助信息节点的最大阶数,这样做的好处是,在进行聚合操作时不必根据知识图谱的拓扑结构调整模型的接受域,无论是结构复杂或结构简单的知识图谱同样可以使用这种聚合方法,不同于KGCN模型需要依据知识图谱设计接受域的方法和其他需要设计元路径的方法,也不必像KGAT 模型在邻居节点之间耗费大量时间使用注意力机制分配权重,使用距离策略的聚合方法无疑更具有普适性。
最后一步是将实体v和其近邻表示M1(v)与M2(v)聚合成单个向量,这需要先计算三个向量的总和,然后对齐进行非线性变化:
其中,W和b分别是训练模型时变换的权重和偏置,σ为非线性激活函数,模型使用的是ReLU函数。模型流程如图2所示。

图2 D-KGCN流程图Fig.2 Flow chat of D-KGCN
2.4 D-KGCN算法
在处理知识图谱G时,通过重构知识图谱优化邻接矩阵的生成(第1~7 行),首先通过DFS 算法求出第k个实体节点的第i分支上的最大和虽小深度(第4 行),然后依据深度属性设置子图裁剪规则(第5行),最后返回所有实体构成子图的集合{G~ }。
在图卷积运算的过程中,首先为每个子图生成关系邻接矩阵和实体邻接矩阵(第12行),设立用户-实体关系的评分,并将其标准化(第13、14行)。在用户-关系评分的监督下将一阶邻居节点聚合成M1(第15行),将子图中除一阶邻居节点以外的邻居节点统一聚合,根据其在实体邻接矩阵中的位置设立了一个模拟影响力和距离之间关系的函数P(x)=exp(-x),将其与邻居节点和用户-关系评分聚合成M2(第16 行),通过聚合函数将该实体节点的向量表示、一阶邻域表示和高阶邻域表示聚合成实体的最终表示vu(第17行),将u和vu一起输入函数f:ℝd×ℝd→ℝ来求得最终的预测概率:


3 实验
3.1 数据集
为了评估模型的有效性,在两种推荐场景下的三个数据集及其对应的知识图谱上进行了实验。分别是两个来源相同,但是规模不同的电影场景:MoveLens-1M、MoveLens-20M;一个音乐场景:Last.FM。
这三个数据集都是公开的,并且在规模大小和数据集的密度方面均不相同,用户-项目交互数据集中的项目实体在知识图谱中都能找到与其关联的实体,知识图谱中的其他实体均视为项目实体的辅助信息,并且每个项目实体在知识图谱中最少存在一个语义关联关系。数据集和知识图谱的具体信息如表1所示。

表1 数据集和知识图谱的基本数据Table 1 Basic data of dataset and KG
三个数据集中:(1)MovieLens-1M 数据集,知识图谱数中的实体关系数目较少,拓扑结构也相对简单,适合验证小规模且知识图谱结构简单情况下模型的效果;(2)MovieLens-20M数据集,知识图谱的信息相对丰富,适合测试模型在大规模数据集中的性能,另外,为了验证在距离策略在缩短训练时间和提升训练效果上的有效性,在该数据集上额外进行消融实验;(3)Last.FM 数据集,知识图谱的关系数目相对较多,形成的拓扑结构相对复杂,以此数据集来验证模型在小规模且知识图谱结构相对复杂的数据集中模型的有效性。
3.2 对比模型
将D-KGCN模型与以下模型进行对比实验:
RippleNet[18]:RippleNet 是一种类似记忆网络的方法,它通过将用户的偏好在记忆网络中传播来获取用户感兴趣的项目属性,将知识图谱节点向量化,进而获取用户与项目的特征向量。
MKR[19]:MKR 设计了一个联系用户与实体之间的交叉压缩单元来完成用户与实体之间的高阶交互,其对知识图谱中的全部信息与用户信息进行考虑。
KGCN:KGCN使用图卷积的形式将知识图谱中的实体与关系考虑到训练模型中,采用固定的接受域进行知识图谱的异构信息特征提取。
KGAT[20]:KGAT 模型使用结合知识图谱的注意力网络模型,通过挖掘知识图谱中的高阶关系,将知识图谱与推荐系统结合,在对知识图谱向量化的过程中使用了TransR模型。
KGIC:KGIC模型在知识感知学习的基础上提出了一种多层次交互式对比学习机制,将知识图谱分为局部信息和非局部信息,并在二者之间使用图神经网络编码器进行交互式对比学习,提出了一种新的知识图谱近邻实体聚合方式。
MCCLK[21]:MCCLK模型同样在知识感知学习的基础上提出,通过将知识图谱划分为全局结构图、局部协作图和语义图三个图进行对比学习完成对知识图谱的向量化表示,语义图。
3.3 实验设置
D-KGCN 模型的代码是在Python 3.6、TensorFlow 1.15.0、Numpy 1.19.5和Scikit-learn 0.24.2下实现的。在D-KGCN模型中,g和f被设置为内积函数,ReLU和tanh分别是∂的非最后一层聚合器和最后一层聚合器。模型的超参数是通过优化验证集的AUC 指标来确定的,D-KGCN模型仅需要调整用户部分的训练超参数,知识图谱部分的超参数,例如知识图谱邻居节点选取数目、节点接受域深度等不必再设置,最后通过RMS 优化器对可训练参数进行优化。每个训练场景的训练集、验证集和测试集的比例都为6∶2∶2,每个实验重复三次,取平均值。
对比实验中,使用原始数据集,依照表2 的超参数进行训练。

表2 对比实验参数设置Table 2 Comparison test parameter setting
消融实验中,以KGCN 模型为基线模型,设计了三个对比实验。第一个实验验证在三个数据集中,通过重构知识图谱生成邻接矩阵与知识图谱部分不作任何处理在两种方式在时间上耗费上的差别。第二个实验验证在同时使用重构知识图谱生成邻接矩阵的情况下,2 阶邻域聚合结构在选取不同数目的节点聚合与M-KGCN 模型的两段式聚合结构在训练时间和推荐效果的差别。第三个实验主要验证使用固定接受域和使用距离策略在训练时间和推荐效果的差别。
3.4 评估指标
在每个实验场景中评估模型:
(1)在实验中采取点击率(CRT)预测,通过已经训练好的模型来预测测试集中数据,为了计算最终推荐结果中正样本在负样本之前的概率,采用AUC 指标来评估模型,其中R为推荐的项目集合:
同时,用模型每轮训练所耗费的平均时间来衡量模型的训练成本。
Time=(total time)/epoch
(2)在Top-K推荐中,对数据集通过已经训练好的模型对测试集中用户选择概率最高的K个项目进行Recall@K评估:
其中K=1,2,5,10,20,50,100。
(3)在消融实验中,第一个实验通过对比三个模型处理知识图谱所耗费的时间评估,第二个和第三个实验通过对比模型的AUC数值和平均每轮训练耗费时间评估。
(4)为了验证不同优化器对模型推荐效果和时间性能的影响,通过建立优化器影响实验测试模型在使用不同优化器时的AUC值和Time值进行评估。
3.5 实验结果及分析
3.5.1 对比实验
本小节将介绍不同模型和D-KGCN 模型的对比结果。表3为模型在数据集的CTR预测结果,图3~图5是模型在三个数据的Top@K召回率折线图。

表3 CTR预测的AUC和Time结果Table 3 Results of AUC and Time in CTR prediction
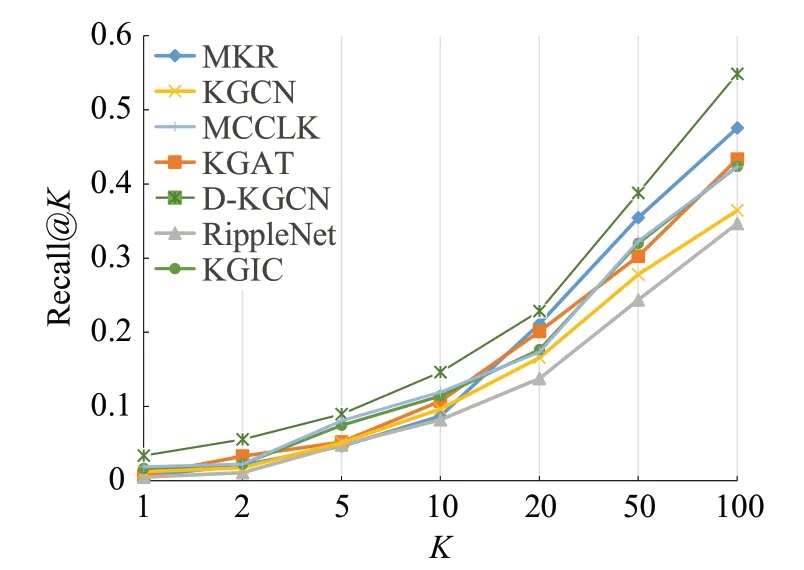
图3 MovieLens-1M的top@K召回率Fig.3 Recall@K in MovieLens-1M
从表3 中可以看出在推荐场景下,D-KGCN 模型模型较其他模型在训练时间上的开销更低,这是因为D-KGCN 模型的时间复杂度主要由处理知识图谱部分和知识图谱卷积部分组成,处理知识图谱部分的开销主要集中在对知识图谱的重构和邻接矩阵的构建上,其时间复杂度为O(v∑l2),其中v是项目实体总数,l是图谱裁剪深度,重构后的知识图谱舍弃了距中心节点过远的辅助信息节点,缩减了邻接矩阵的维度,在处理知识图谱和模型训练时可也节省大量时间;知识图谱卷积部分的复杂度主要集中在邻居节点聚合方面,其复杂度为O(m2),其中m是重构后图谱中辅助信息的总数,m的数目远远小于原知识图谱中辅助信息的数目,在知识图谱卷积部分同样可以节省大量时间开销。与D-KGCN模型相比,RippleNet 模型的复杂度主要在于创建ripple集O(n3)和在ripple集中传播用户偏好O(n3),该模型的训练时间约是D-KGCN模型的30~70倍;KGCN模型的复杂度主要在于图卷积部分的邻居节点的聚合方面,其复杂度依赖于模型的接受域设置,总的时间复杂度为O(nk),其中k是模型的接受域层数超参数,该模型的训练时间约是D-KGCN 模型的2~20 倍;KGAT 模型的训练开销主要集中在协作知识图谱训练和用注意力机制分配邻居节点权重上,模型总的复杂度为O(n3),该模型的训练时间约是D-KGCN 模型的290~20 000 倍;MKR模型的复杂度主要在于其设置的交叉压缩单元低层和高层中的矩阵运算,总的模型复杂度为O(L·n)+O(H·n),其中L和H是模型中低层和高层的层数超参数,该模型的训练时间约是D-KGCN 模型的1.5 倍;KGIC 模型的复杂度主要在于其构造用户潜在实体集O(n4),复杂度过高导该模型其仅能在MovieLens-1M 和Last.FM 两个较小的数据集中取得实验结果,在这两个数据集上的训练时间约是D-KGCN 模型的400~3 000 倍;MCCLK的复杂度主要集中在创建三个协作图及其对比学习中,其复杂度为O(n3),在对MovieLens-20M进行的实验中,因为模型参数需要的存储空间超过40 GB,试验机无法满足条件,在MovieLens-1M 和Last.FM 两个数据集上的训练时间约是D-KGCN模型的90~500倍。
在MovieLens-1M 数据集中,知识图谱中的实体关系数目较少,拓扑结构也相对简单,适合验证小规模数据集下模型的效果,D-KGCN模型在训练时造成的开销不但最低,AUC指数较其他表现最好的KGIC模型还提升了0.008,这是因为D-KGCN 模型在操作知识图谱时,对辅助信息稀疏的节点不会过度裁剪,能够最大可能性保留中心节点的拓扑结构,同时也不会造成额外开销,相比之下,使用注意力机制和网络传播的KGAT和RippleNet 模型在处理知识图谱时操作过于繁琐,抵抗知识图谱中数据产生的噪声能力也相对较差。采用知识感知学习的KGIC 和MCCLK 模型需要创建多个额外的辅助图进行对比训练,训练开销远高于D-KGCN模型。
对于MovieLens-20M 数据集来说,知识图谱的信息相对丰富,适合测试模型在大规模数据集中的性能,从表3 中可以看出D-KGCN 模型在AUC 指标上领先效果第二好的KGAT 模型0.012,同时时间耗费远小于KGAT 模型。MKR 模型虽然训练开销排在第二位,但是其推荐能力最终会完全丧失,这是因为其设计的交叉压缩单元并没有处理噪声的能力,随着数据的增多,产生的干扰会严重影响推荐效果。而D-KGCN 模型通过距离-影响力函数聚合知识图谱上的辅助信息,极大地减少了距离中心节点过远的无用节点带来的干扰,同时,分两段聚合的方式还节省了大量的训练时间。可以看出D-KGCN 模型更能适应大规模的数据集。
对Last.FM 数据集来说,其知识图谱的关系数目相对较多,形成的拓扑结构相对复杂,适合验证小规模且知识图谱结构相对复杂的数据集中模型的有效性。
D-KGCN 在AUC 指标上落后于KGIC 和MCCLK模型,这说明D-KGCN模型在稀疏且关系复杂的数据集中,对关系的提取和应用能力欠佳,仍然存在提升的空间,但是其训练开销远远低于KGIC 和MCCLK 模型。KGCN模型依赖于邻域聚合结构,在数据集中需要考察知识图谱的拓扑结构来设计邻域聚合结构,在Last.FM数据集上表现相对不佳,普适性相对较差,D-KGCN 在KGCN模型基础上做出了改进,在没有增加训练开销的基础上,提升了0.037的AUC值,提高了模型的普适性,且更具有实际应有的价值。
图3、图4分别是模型在MovieLens-1M、MovieLens-20M 数据集上进行Top-K推荐的Recall@K折线图。如图所示,D-KGCN 模型在K为任意值时均处于优势地位,在最终Recall@K的结果上,D-KGCN模型在效果上分别超过效果第二好的其他模型29.70%、12.10%,这说明模型在数据相对密集且关系相对简单和数据相对稀疏且关系相对复杂的模型上都能取得不错的推荐效果,证明了模型的有效性。图5是模型在Last.FM数据集上进行Top-K推荐的Recall@K折线图,D-KGCN 模型模型在最终Recall@K的结果上落后效果最好的MCCLK模型8.9%,说明模型在数据稀疏且关系复杂的数据集中仍然存在提升的空间,需要加强稀疏数据集中的关系提取能力。综合模型在三个数据集上的推荐效果和训练开销来看,本文提出的与距离策略的知识图谱网络图卷积推荐算法是可用的。

图4 MovieLens-20M的top@K召回率Fig.4 Recall@K in MovieLens-20M

图5 Music的top@K召回率Fig.5 Recall@K in Music
3.5.2 消融实验
表4 是在知识图谱处理时是否使用重构生成邻接矩阵在三个数据集上的时间性能耗费,从表中可以看出在三个数据集上,使用知识图谱重构的方法相比未作处理的方法的时间,是其1/3~1/2,证明了重构知识图谱在时间性能上的优势。

表4 知识图谱处理时间耗费Table 4 Knowledge graph processing time consumption单位:s
为了验证模型的距离策略的有效性,在使用重构知识图谱生成邻接矩阵的基础上,将基于距离策略的聚合方式与选取固定节点迭代聚合方式进行对比,用MvieLens-20M 作为实验数据集,选取固定节点的聚合方式的接受域为2,用n表示聚合结构每层选取的节点数目。
表5显示了在选取固定节点进行聚合时,最终的推荐结果和训练耗费时间相差不大,而且在选取固定节点值增大时,模型的推荐效果没有明显提升,这说明了同阶节点对中心节点的影响力有限,聚合的数目对模型的推荐效果影响不大,使用距离策略的D-KGCN模型虽然在聚合时间上略高于选取固定节点聚合的方法,但是最终的AUC 值提升了0.011~0.013,这是由于基于距离策略的聚合结构不但聚合同阶的邻居节点,还将高阶的邻居节点按照距离影响力聚合,考虑的信息更全面,最终的推荐效果也更好。

表5 不同聚合结构的AUC和Time对比Table 5 Results of AUC and Time in different aggregation structures
D-KGCN 模型是在KGCN 模型基础上改动的,表6是在同样使用了裁剪策略优化邻接矩阵生成的情况下,D-KGCN 模型和接受域为固定值时的KGCN 模型的实验结果对比,用H表示接受域设置的值,H=0 时表示模型仅聚合中心节点,不考虑邻居节点带来的影响,此时模型的训练开销最低,推荐的AUC 值达到了0.969,这说明了中心节点对推荐模型的影响力起决定性作用,随着接受域扩大,当接受域H=2 时模型的推荐效果达到了KGCN 模型的最大值,这证明了前两阶辅助信息确实能起到提升推荐效果的作用,当H=3是,推荐的结果开始下降,说明了高阶邻居节点已经对模型的推荐效果产生了干扰,直到H=4 时,数据产生的噪声导致模型完全丧失推荐性能,而D-KGCN 模型依靠距离策略,缩减高阶邻居节点对中心节点的影响力,在推荐的AUC 值上比固定接受域H=2 时提升了0.011,时间也缩短了1/2 以上,足以证明D-KGCN 模型的有效性。
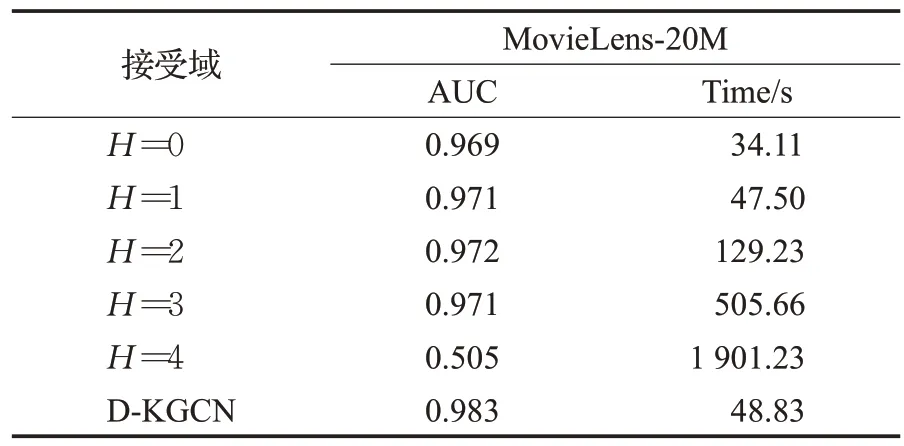
表6 不同接受域的AUC和Time对比Table 6 Results of AUC and Time in different acceptance domains
3.5.3 优化器影响实验
使用四个优化器在三个数据集上进行实验,验证不同优化器对模型AUC 和训练开销的影响,结果如表7所示。

表7 优化器影响实验Table 7 Optimizer influence experiment
通过表7 可以看出模型的训练开销与优化器之间联系不大,但是不同的优化器对模型的推荐效果影响很大,RMS 优化器在处理梯度时用平方梯度的移动均值代替平方梯度的总和,对小批量数据设置更为适应,在优化器实验中的各个数据集上表现最佳。Adam 优化器在处理梯度时不但使用动量作为参数更新方向,而且可以自适应调整学习率,在优化器影响实验的表现上也取得了不错的效果。Adagrad 学习率衰减用了所有的梯度,如果在经过一定次数的迭代依然没有找到最优点时,累加的梯度幅值是越来越大的,导致学习率越来越小,很难再继续找到最优点,在模型中使用Adagrad 优化器会导致模型最终丧失推荐性能。Gradient Descent 优化器的实现非常简单,但是在收敛性方面难以保障,使用该优化器并不能使D-KGCN 模型收敛。
4 结束语
本文提出的D-KGCN 推荐模型,是一种能够依据实体在知识图谱中的拓扑结构,高效地利用知识图谱中异构信息的推荐模型。D-KGCN 模型在时间和性能上取得优势主要有两个原因,第一是依据节点的拓扑结构,对知识图谱进行了初步的裁剪,首先避免了距离过远的节点对中心节点的干扰,优化了知识图谱生成的邻接矩阵和关系矩阵;第二点是依据距离策略提出了新的邻域聚合方式,在聚合操作时,首先聚合中心节点的一阶辅助信息节点,然后将其他辅助信息节点通过距离-影响力衰减函数聚合,依据用户-关系评分、距离-影响力衰减函数完成对知识图谱的向量化处理。最终经过在三个真实数据集上的实验,验证了模型在不同规模、稀疏度的数据集上的推荐质量和训练效率,在MovieLen-20M数据集是进行消融实验,验证了知识图谱重构和使用距离策略的有效性。在未来会进一步改进知识图谱中邻居节点的选择函数和边信息的使用方法,以提升模型在小规模且关系复杂的数据提取能力,进而得到更好的推荐性能和解释性;也会尝试将模型拓展并应用在其他领域,如餐饮、新闻、视频等推荐领域。
猜你喜欢
长春师范大学学报(2022年12期)2023-01-13
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
网络空间安全(2016年3期)2016-06-15
领导科学论坛(2016年9期)2016-06-05
湖南师范大学自然科学学报(2014年3期)2014-09-07
