
时空梯度迭代的声纹对抗攻击算法STI-FGSM
2023-11-20 10:58顾益军
计算机工程与应用 2023年21期
李 烁,顾益军,谭 昊
1.中国人民公安大学 信息网络安全学院,北京 100038
2.广州大学 网络空间先进技术研究院,广州 510006
近年来,随着深度神经网络大力推动了说话人识别技术的发展,说话人识别系统逐渐普及于人们的生产生活中,如声纹门禁、声纹登录、声纹指令等,其安全性能也受到人们的广泛关注。一方面,由于神经网络具有易受对抗攻击的特点,基于深度学习的说话人识别系统也会受到对抗攻击的威胁;另一方面,研究对抗攻击对于防御也有指导意义,掌握最新的对抗攻击方法,才能针对性地采取对抗防御措施。综上,研究说话人识别领域的对抗攻击,对维护说话人识别系统安全具有重要意义。
现有针对说话人识别系统的对抗攻击算法,根据攻击时是否掌握目标模型具体结构和参数可分为白盒攻击和黑盒攻击,根据攻击方式的不同可分为基于梯度迭代的算法[1-4]、基于生成对抗网络的算法[5-6]和基于优化的算法[7-8]等,存在攻击成本较高、梯度信息利用不充分、迁移性较差等问题。对抗样本的迁移性是指对抗样本的跨模型迁移能力,即针对特定模型生成的对抗样本能否欺骗其他模型的攻击泛化能力,可用对抗样本迁移的黑盒攻击成功率进行评价。Dong 等人[3]提出的动量迭代快速梯度符号法算法(momentum iterative fast gradient sign method,MI-FGSM)算法引入动量,生成的对抗样本具有较好的迁移性,可以用于黑盒攻击,常作为迁移攻击的基线方法,但没有充分利用样本梯度信息。为了进一步提高对抗样本的迁移性,本文在MI-FGSM 算法的基础上进行改进,提出一种融合时空梯度信息的对抗攻击算法(space-time iterative fast gradient sign method,STI-FGSM),该算法在动量的基础上,融合语音样本的时序梯度和空间梯度信息,结合扰动集成方法,提高对抗样本迁移攻击的成功率。本文的主要工作和贡献如下:
(1)为了提高对抗攻击迁移性,在MI-FGSM 算法基础上,融合动量和时序梯度信息,稳定梯度更新方向,提出时序迭代快速梯度符号法(time iterative fast gradient sign method,TI-FGSM)。
(2)在TI-FGSM 算法的基础上,引入空间梯度,充分学习语音样本区域信息,提出STI-FGSM 算法,从时序、空间两个层面提高对抗样本迁移性。
(3)将STI-FGSM 算法与扰动集成方法相结合,充分利用现有白盒模型的信息,实现集成模型攻击,大幅提高算法的黑盒攻击成功率。实验证明,该算法对ResNetSE34V2、TDy_ResNet34_half、x-vector、ECAPATDNN 四种说话人识别模型均能实现白盒攻击和黑盒攻击,取得了较好的效果,优于其他算法。
1 相关工作及背景介绍
本章中,简要介绍现今主流的深度学习说话人识别模型,并对当前声纹对抗攻击算法及集成攻击方法进行分析。
1.1 深度学习的说话人识别系统
说话人识别(speaker recognition,SR)模型,是指能够提取输入语音的特征,并对其进行处理分析和比对,从而判断说话人身份的模型。随着深度学习技术逐渐应用于说话人识别模型中,极大地提高了说话人识别系统的性能。目前基于深度学习的说话人识别模型主要可分为两类:一种是基于残差网络(residual networks,Resnet)[9]训练的模型,另一种是基于时延神经网络(time-delay neural network,TDNN)[10]训练的模型。
本文选用四种基于深度学习训练的说话人识别模型作为目标模型开展研究:ResNetSE34V2[11]、TDy_ResNet34_half[12]、x-vector[13]、ECAPA-TDNN[14]。其中,ResNetSE34V2 模型通过ResNet-34 网络训练,为VoxSRC2020声纹识别挑战赛中的基线模型[11]。TDy_ResNet34_half 模型通过融合时域动态卷积(temporal dynamic CNN,TDy-CNN)[12]的ResNet-34网络训练,为基于残差网络训练的说话人识别模型。x-vector模型通过TDNN网络训练,并使用概率线性判别分析(probabilistic linear discriminant analysis,PLDA)[15]后端进行打分,为深度学习说话人识别的经典模型。ECAPA-TDNN模型通过融合一维压缩激励残差模块(squeeze-excitation Res2Block,SE-Res2Block)[16-17]的TDNN 网络训练,同时引入多层特征融合和注意力统计池化[18],为当前性能最佳的说话人识别模型。
1.2 声纹对抗攻击算法
对抗样本最早由Szegedy 等人[19]在图像领域提出,并逐渐应用于说话人识别领域[20-21],说话人识别领域的对抗攻击实现方式如图1所示。

图1 说话人识别的对抗攻击Fig.1 Adversarial attacks for speaker recognition
声纹对抗攻击通过在原始语音中注入人耳无法察觉的轻微扰动,生成相应的对抗样本,使说话人识别模型身份识别错误,从而实现攻击目的。一般情况下,给定分类网络f和真实样本x,对抗样本通过优化以下函数生成:
式(1)中,J为损失函数,x为真实样本,x′为对抗样本,y为真实标签,ε为最大扰动,对抗样本的目标是添加更小扰动的同时,使分类网络错误分类。
对抗攻击算法根据攻击方式的不同可以分为基于梯度迭代的算法,如快速梯度符号法(fast gradient sign method,FGSM)[1]、迭代的快速梯度符号法(iterative fast gradient sign method,I-FGSM)[2]、动量迭代快速梯度符号法(momentum iterative fast gradient sign method,MI-FGSM)[3]、Nesterov accelerateand RMSProp optimization based iterative-fast gradient sign method算法(NRI-FGSM)[4]等;基于生成对抗网络(generative adversarial network,GAN)[22]的算法,如AdvGAN[5]、AdvGAN++[6]等;基于优化的算法,如Carlini and Wagner攻击(C&W)[7]、FAKEBOB攻击[8]等。
其中,基于生成对抗网络的算法,如Xiao 等人[5]提出的AdvGAN,通过生成器映射生成对抗扰动,再由判别器判别是否为对抗样本,二者不断学习构成的生成对抗网络来生成对抗样本,存在训练稳定较为困难、解释性不强的问题;基于优化的算法,如Carlini等人[7]提出的C&W 算法,该算法将对抗样本生成优化为在保证不可感知性的同时找到欺骗分类器最小扰动的问题,这样攻击生成的对抗样本虽然扰动较小,且能实现黑盒攻击,但存在攻击时间成本较高的问题。而基于梯度迭代的算法因其具有攻击成本低、攻击方法多样、攻击效果好等优势,仍占据对抗攻击算法的重要位置,本文在基于梯度迭代的声纹对抗攻击算法的基础上开展研究。
Goodfellow 等人[1]提出的FGSM 算法,快速梯度符号法,通过一步梯度迭代,在最大化损失函数的方向上更新对抗样本,公式如下:

Kurakin 等人[2]提出的I-FGSM 算法,迭代快速梯度符号法,是在FGSM算法的基础上以小步梯度进行多次迭代,公式如下:
式(3)中,Clipεx为裁剪函数,以控制扰动在边界范围内,t为迭代次数,α为步长。
Dong 等人[3]提出的MI-FGSM 算法,动量迭代快速梯度符号法,是在I-FGSM算法的基础上引入动量,以稳定梯度更新方向,公式如下:
式(4)、(5)中,μ为动量衰减因子,gt为前t次迭代的累加梯度。MI-FGSM 算法引入动量,生成的对抗样本具有较好的迁移性,可以用于黑盒攻击,常作为迁移攻击的基线方法。
Tan 等人[4]提出的NRI-FGSM 算法,为基于梯度迭代的声纹对抗攻击算法,该算法将Nesterov Accelerated Gradient 算法(NAG)[23]和Root Mean Squared Propagation 算法(RMSProp)[24]与自适应步长相结合,能够在实现黑盒攻击的同时保持较低的扰动。
上述算法中,FGSM算法能实现白盒攻击,但攻击成功率较低;I-FGSM算法能实现较高的白盒攻击,但迁移性较差;MI-FGSM 算法和NRI-FGSM 算法具有较好的迁移性,可以实现黑盒攻击,缺点是样本的时序梯度信息和空间梯度信息没有得到充分利用。本文考虑在上述算法的基础上进行优化,进一步提高算法的迁移性。
1.3 集成攻击
为了提高对抗样本的迁移性,可以结合集成思想进行对抗攻击。集成的主要思想是充分利用现有的已知模型信息,通过多目标模型融合学习而实现效果最大化。通过集成攻击,生成能够同时欺骗多个白盒模型的对抗样本,提高对抗样本迁移攻击到未知模型即黑盒模型的攻击成功率。
模型集成的方法有很多,如logits 集成、损失集成、预测集成等,Dong等人[3]使用logits集成方法,攻击集成logits 的多个白盒模型,生成了高迁移性的对抗样本,logits集成公式如下:

Zhang 等人[25]提出一种新的集成方式——扰动集成,该方法以梯度迭代的对抗攻击算法为基础,集成多个白盒模型的扰动,公式如下:
式(7)中,δ为集成的扰动,fθ为参数为θ的对抗攻击算法,y为真实标签,L={ }L1,L2,…,Ln为白盒模型集合。扰动集成方法通过最大化白盒攻击成功率,进一步提高对抗样本的黑盒攻击水平。相比logits 集成,扰动集成对攻击的扰动进行集成叠加,不受模型输出维度的影响,且更容易到达黑盒模型的决策边界,进一步提高对抗样本黑盒攻击的成功率。Zhang 等人在说话人验证的伪造检测模型中开展实验,通过在相同条件下比较两种集成方法的黑盒攻击成功率,证明了扰动集成方法优于logits集成方法。
2 对抗攻击算法STI-FGSM
为了解决现有对抗攻击算法梯度信息利用不充分、迁移性较差等问题,本文提出一种时空迭代快速梯度符号法(space-time iterative fast gradient sign method,STI-FGSM)的声纹对抗攻击算法,该算法在MI-FGSM算法的基础上,融合时序梯度信息和空间梯度信息,保证对抗样本的攻击性的同时提高迁移性,最后通过扰动集成进一步提高算法黑盒攻击的成功率。
2.1 融合时序梯度
为了充分利用数据的梯度信息、提高对抗样本的迁移性,本文在MI-FGSM 算法[3]的基础上进行改进,保留动量衰减因子,稳定梯度更新方向,融合时序梯度信息进行迭代。具体做法是,在每次迭代时将损失函数的梯度进行累加,并根据下一步梯度信息来影响未来梯度,即:
(1)若下一步梯度方向与当前梯度方向相同,则将下一步观测梯度与当前梯度进行累加,以加快梯度更新。
(2)若下一步梯度方向与当前梯度方向相反,则使用下一步观测梯度减缓梯度更新,避免陷入局部最佳值。
因为引入时序梯度信息,本文将该算法命名为时序梯度快速迭代符号法(time iterative fast gradient sign method,TI-FGSM),公式可表示为:
式(8)~式(10)中,g′为下一个梯度,gt为前t次迭代的累加梯度,μ为动量衰减因子。TI-FGSM 算法的伪代码如下:
算法1 TI-FGSM算法

相较于MI-FGSM 算法,TI-FGSM 算法融合了样本的时序梯度信息,使对抗样本在迭代过程中能够结合下一步梯度信息加速收敛,进一步稳定了梯度迭代的更新方向,避免对抗样本陷入局部极值导致过度拟合单一目标模型,从而提高了对抗样本的迁移性。
2.2 引入空间梯度
当前算法并未使用语音区域信息之间的关系,考虑到语音数据的连续性,本文尝试利用语音样本不同区域间的信息来稳定梯度更新方向。本节在TI-FGSM算法的基础上,引入语音的空间梯度信息,将该算法命名为STI-FGSM,空间梯度的攻击形式如下:

算法2 STI-FGSM算法

算法的时间复杂度方面,MI-FGSM 算法在每次迭代中只进行一次梯度反向传播的基本运算,时间复杂度可看作O(T),T为迭代次数。与MI-FGSM 算法相比,STI-FGSM 算法主要增加了一项查询梯度的时间,而求均值与加和计算的时间基本可忽略不计,因此STI-FGSM 算法的时间复杂度介于(T,2T)之间,也为O(T)。因此,STI-FGSM 算法的时间效率与MI-FGSM算法基本相同。
2.3 扰动集成攻击
为了充分利用目标模型信息,本文使用扰动集成的方法实现模型集成攻击,以提高对抗样本黑盒攻击的成功率。受通用对抗扰动[26]的启发,扰动集成采用迭代攻击的策略,通过在所有已知模型即白盒模型上扰动叠加实现对抗样本攻击成功率最大化,来提高对抗样本面对未知模型即黑盒模型时的攻击迁移性,效果如图2所示。
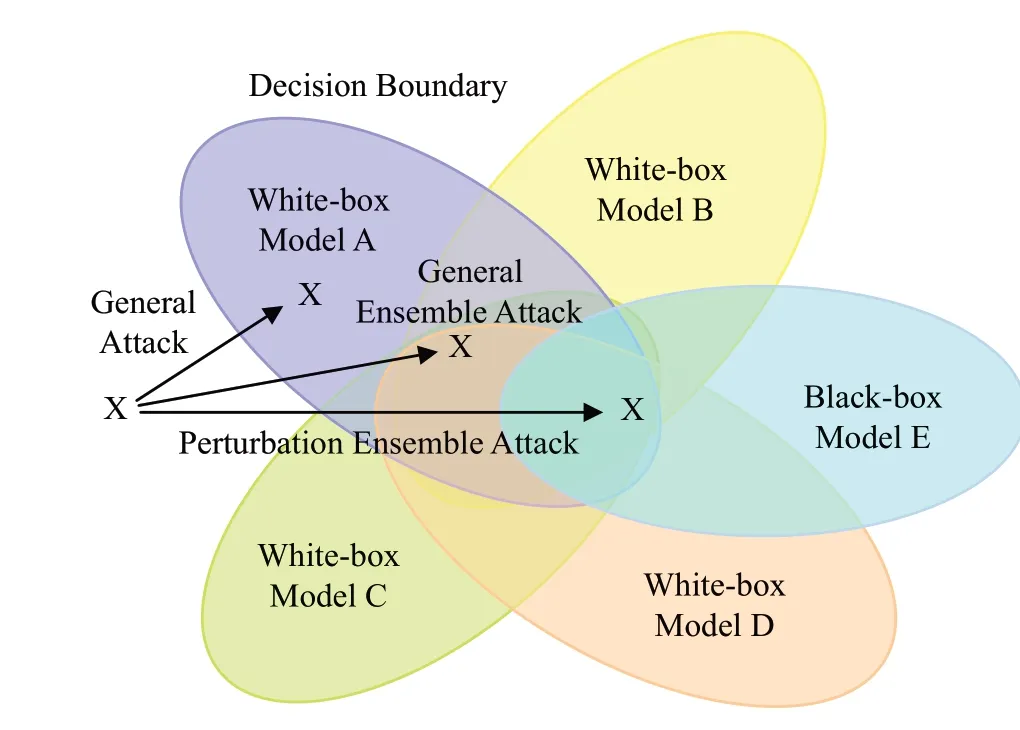
图2 扰动集成攻击示意图Fig.2 Diagram of perturbation ensemble attack
结合图2 可以看出,针对不同的白盒模型,单一攻击生成的对抗样本往往具有局限性,限制在各白盒模型对应的决策空间内,使对抗样本在不同模型间的迁移性较差,如图2 中单一攻击仅到达模型A 的决策空间,无法对模型B、C、D、E 造成攻击;普通的集成攻击由于没有进行扰动叠加,会限制攻击效果,虽然能够实现白盒模型A、B、C、D 的攻击,但往往无法到达黑盒模型E 的决策空间。扰动集成的攻击,可以充分利用现有白盒模型A、B、C、D的信息,将攻击的扰动进行集成叠加,实现攻击最大化,从而能够迁移攻击黑盒模型E,扰动集成算法的伪代码如下:
算法3 扰动集成算法

3 实验结果与分析
3.1 环境设置及数据集
本文实验平台操作系统为Ubuntu18.04.5,处理器为Intel®Xeon®Gold 5218 CPU @ 2.30 GHz,显卡为GeForce RTX 2080 Ti-11 GB。Python 版本为3.7.9,Pytorch版本为1.6.0,CUDA版本为10.2。
实验使用Voxceleb 数据集[27-28],该数据集是最大规模的开源说话人识别语料集,分为Voxceleb1 数据集[27]和Voxceleb2 数据集[28],Voxceleb1 包含 来 自Youtube 视频的1 251位名人的约10万段语音,Voxceleb2包含来自Youtube视频的6 112位名人的约100万段语音。
从Voxceleb1 的测试集中随机选择10 名说话人,包含5 男5 女。选取这10 名说话人的各10 段语音构成注册集;选取注册集10名说话人的各100段语音,共1 000段语音构成测试集。从Voxceleb1的开发集中随机选择10名说话人,包含5男5女,与注册集和测试集的说话人身份不重叠,选取每名说话人各100 段语音,合计1 000段语音构成真实样本集,数据集划分如表1所示。

表1 数据集分布Table 1 Distribution of dataset
其中,注册集和测试集用于目标说话人识别模型的注册和测试,真实样本集用于对抗样本的生成。对抗攻击算法超参数设定如下:迭代次数T=40 ,扰动大小ε=0.002,动量衰减因子μ=1。
3.2 实验目标模型
选用ResNetSE34V2[11]、TDy_ResNet34_half[12]、x-vector[13]、ECAPA-TDNN[14]四种说话人识别模型作为目标模型开展实验,分别记为rv2、rvh、xv、ecapa。这四种模型基本包含了目前主流的深度学习说话人识别模型,其中,rv2和rvh 基于残差网络ResNet 及其改进网络训练,xv 和ecapa基于时延神经网络TDNN及其改进网络训练。
本文使用rv2、rvh、xv和ecapa的预训练模型开展开集说话人识别任务,四种预训练模型使用Voxceleb2 的开发集进行训练。实验使用表1中的注册数据集注册,使用测试数据集对四种说话人识别模型进行测试,四种说话人识别模型的性能如表2所示。

表2 说话人识别模型性能Table 2 Speaker recognition model performance
在开集说话人识别任务中,模型的等错误率(equal error rate,EER)越低,表明模型的识别性能越好;当打分超过阈值(Threshold)时,说话人识别模型才会对目标语音进行识别。
3.3 评价指标
本文使用攻击成功率(attack success rate,ASR)作为对抗攻击算法的评价指标,公式如下:
式(13)中,sumNum()· 为样本数量,x为原始样本,y为真实说话人标签,x′为对抗样本,label()· 为目标模型输出的标签。目标模型针对原始样本x的输出标签均为对应的真实说话人标签y,当目标模型将对抗样本x′识别错误,即输出标签不为真实说话人的标签y时,可视为攻击成功,ASR值越高,说明对抗算法攻击性越强。
3.4 实验结果及分析
3.4.1 白盒攻击实验
为了验证本文所提攻击算法的有效性,使用FGSM、I-FGSM、MI-FGSM、TI-FGSM、STI-FGSM 五种对抗攻击算法分别对rv2、rvh、xv、ecapa 四种说话人识别模型进行白盒攻击,即攻击时能够直接获取目标模型的所有信息,白盒攻击实验能够直观地显示算法的攻击能力。统计各算法的白盒攻击成功率,实验结果如表3所示。
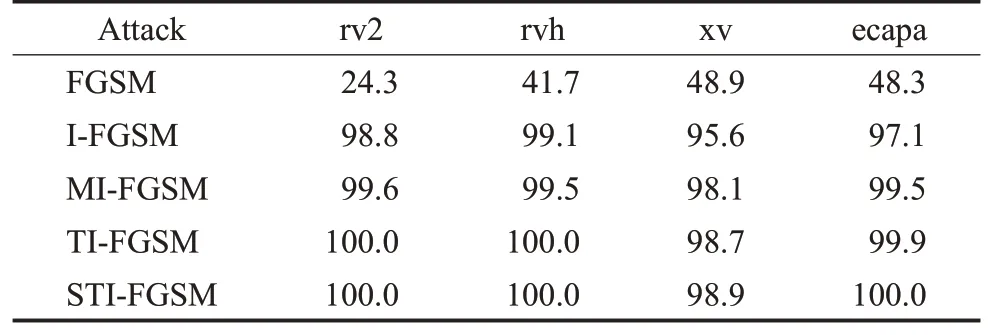
表3 白盒攻击成功率Table 3 White box attack success rate单位:%
从表3 中可以看出,本文所提出的对抗攻击算法TI-FGSM和STI-FGSM对rv2、rvh、xv、ecapa四种说话人识别模型均能实现有效的白盒攻击,攻击成功率最高可以达到100%,其中,STI-FGSM 算法白盒攻击成功率较FGSM、I-FGSM、MI-FGSM 算法平均提升了58.9、2.1、0.6 个百分点,且TI-FGSM 算法白盒攻击成功率与STI-FGSM算法几乎相当,证明了两种算法白盒攻击的可行性。
为了研究迭代次数对算法白盒攻击的影响,分别设置迭代次数T=5,10,20,30,40,以I-FGSM、MI-FGSM、TI-FGSM、STI-FGSM 算法开展实验,目标模型使用rv2模型,统计不同迭代次数下的白盒攻击成功率,结果如图3所示。
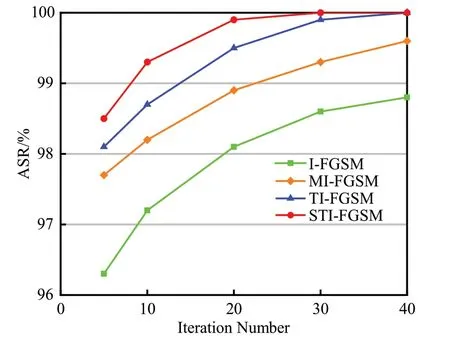
图3 不同迭代次数的白盒攻击成功率Fig.3 White-box attack success rate for different iterations
从图3 可以看出,随着迭代次数的增加,算法的白盒攻击成功率随之提高。在相同迭代次数下,TI-FGSM和STI-FGSM 算法的攻击成功率高于I-FGSM 和MIFGSM,说明本文所提出的两种算法攻击能力更强。与TI-FGSM算法相比,达到相同的攻击成功率,STI-FGSM所需迭代次数更少,说明STI-FGSM算法的攻击性更强。
3.4.2 黑盒攻击实验
为了验证本文所提攻击算法的迁移性,本节使用FGSM、I-FGSM、MI-FGSM、TI-FGSM、STI-FGSM 五种对抗攻击算法对四种说话人识别模型进行黑盒攻击,即每组实验中,使用五种对抗攻击算法分别攻击特定的白盒模型,并用生成的对抗样本攻击其余模型,统计每种算法所生成对抗样本的黑盒攻击成功率,以此评价对抗样本的迁移性。实验结果如表4所示。

表4 黑盒攻击成功率Table 4 Black box attack success rate单位:%
从 表4 可 以 看 出,TI-FGSM 和STI-FGSM 算 法 的黑盒攻击成功率整体较高,证明了两种算法黑盒攻击的可行性。与FGSM、I-FGSM、MI-FGSM 算法相比,TI-FGSM算法的黑盒攻击成功率平均提升了20.7、5.8、1.6 个百分点,证明了时序梯度的有效性。另外,STIFGSM 算法黑盒攻击成功率比TI-FGSM 算法平均提升了3.8个百分点,说明STI-FGSM算法的迁移性优于TIFGSM,证明了空间梯度的有效性。
为了研究迭代次数对算法黑盒攻击的影响,本文分别设置迭代次数T=5,10,20,30,40,以MI-FGSM、STIFGSM算法开展实验,首先对rv2模型进行白盒攻击,然后将生成的对抗样本对rvh、xv、ecapa 模型进行黑盒攻击,统计不同迭代次数下的攻击成功率,实验结果如图4所示,该图中rv2模型为白盒攻击,其余模型为黑盒攻击。

图4 不同迭代次数的攻击成功率Fig.4 Attack success rate for different iterations
从图4 可以看出,随着迭代次数的增加,对抗样本的迁移性会随之提高,但这会消耗更多的时间成本和计算成本。在相同迭代次数下,与MI-FGSM 算法相比,STI-FGSM 算法的黑盒攻击成功率更高,说明STIFGSM 算法的迁移性优于MI-FGSM 算法,验证了时空梯度信息对算法迁移性的提升。
3.4.3 扰动集成实验
为充分利用模型信息,本小节开展扰动集成实验,将rv2、rvh、xv、ecapa四个说话人识别模型每三个依次集成,进行白盒攻击,并将生成的对抗样本对另一个模型实行黑盒攻击,分别使用I-FGSM、MI-FGSM、TI-FGSM、STI-FGSM 四种对抗算法扰动集成进行攻击,实验结果如表5所示。

表5 扰动集成攻击成功率Table 5 Perturbation ensemble attack success rate单位:%
从表5可以看出,当进行扰动集成操作后,I-FGSM、MI-FGSM、TI-FGSM、STI-FGSM 四种算法,白盒攻击取得较好效果,攻击成功率均可达到98.6%以上,验证了扰动集成方法实现最大化白盒攻击的特点。在黑盒攻击中,TI-FGSM和STI-FGSM算法的攻击成功率高于I-FGSM和MI-FGSM算法,说明融合时序梯度和空间梯度信息后算法的迁移性更强。
结合表4 中相关数据,对比集成前的单一模型,TI-FGSM 算法扰动集成后黑盒攻击成功率平均提高了11.3 个百分点,STI-FGSM 算法扰动集成后黑盒攻击成功率平均提高了11.7个百分点,证明扰动集成方法能够提高对抗算法的迁移性,实现更强的黑盒攻击。
3.4.4 与其他算法比较
为了进一步验证本文所提算法的有效性,本小节使用STI-FGSM算法与C&W算法、NRI-FGSM算法开展实验,以白盒攻击rv2模型生成的对抗样本来迁移攻击其他黑盒模型,超参数设定与3.1节一致,实验结果如表6所示。

表6 与其他算法的攻击成功率对比Table 6 Compared with ASR of other methods单位:%
从表6可以看出,与基于优化的对抗攻击算法C&W算法和基于梯度迭代的声纹对抗攻击算法NRI-FGSM算法相比,本文所提的STI-FGSM算法均能取得更好的攻击效果,黑盒攻击成功率分别提升了6.7和3.1个百分点,进一步证明了本文所提方法的有效性。
4 结束语
为解决当前对抗样本算法信息利用不充分、迁移性较差等问题,本文针对说话人识别模型,提出一种时空梯度迭代的声纹对抗攻击算法STI-FGSM。经实验验证,本文提出的方法对ResNetSE34V2、TDy_ResNet34_half、x-vector、ECAPA-TDNN 四种说话人识别模型均能实现有效的白盒攻击和黑盒攻击,优于其他对抗攻击算法。同时,本文使用扰动集成方法,集成现有白盒模型,进一步提高对抗算法黑盒攻击成功率。下一步的研究中,将在本文的基础上,结合元学习的思想,联合多个目标模型、多种攻击算法,进一步提高算法的黑盒攻击水平。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
通信学报(2021年2期)2021-03-09
福建中学数学(2021年2期)2021-02-28
通信产业报(2018年32期)2018-11-24
通信世界(2018年29期)2018-11-21
科教导刊·电子版(2016年35期)2017-04-20
科学与财富(2016年32期)2017-03-04
信息记录材料(2016年4期)2016-03-11
浙江大学学报(工学版)(2015年1期)2015-03-01
电测与仪表(2014年3期)2014-04-04
