
TextRail:复杂自然场景下的不规则文本检测算法
2023-11-20 10:58郭小宇
计算机工程与应用 2023年21期
马 静,薛 浩,郭小宇
南京航空航天大学 经济与管理学院,南京 211106
随着智能手机和智能摄像头的广泛使用,阅图时代已经到来。图片数量爆发式增涨,信息量更加丰富,人们希望从海量图片数据中快速、准确获取信息,因此图片理解成为当前亟待解决的一个关键问题。图片文本携带着丰富而精确的高级语义信息,同时亦具有形态不规则的特点,如文字的颜色、大小、方向、语言、字体、形状等有较大差异。复杂自然场景下的图片文本的识别具有重大实用价值,如图1 所示印章识别、广告牌信息读取、产品查询和检索、拍图识字等,都离不开自然场景图片文本的识别。Google Glass通过快速、精准识别佩戴者目光所及之处的文字,结合知识图谱等技术将关联信息推送给用户。另外,自然场景中的文本识别也是元宇宙上游视觉理解认知的一项重要技术。因此,自然场景下文本的检测和识别逐渐成为计算机视觉领域的研究热点。本文重点研究自然场景下不规则文本的检测方法。

图1 自然场景文本检测场景Fig.1 Scene text detection in nature senarios
相较于扫描图像文本,自然场景文本具有以下特点:(1)文本以任意四边形文本、水平形状文本以及不规则文本的形式存在;(2)图像背景复杂,信号灯、指示标、栅栏、屋顶、窗户、砖块、花草等会和文本具有相似的纹理信息,从而干扰检测识别;(3)图像自身的成像过程亦包含多种干扰因素,如所拍摄的图像存在噪声、模糊、光照不均匀(强反光、阴影)、低分辨率、局部遮挡等问题,使得文字的检测更加困难。当下自然场景不规则文本检测面临的挑战是:自然场景中的文本因形状不规则、背景复杂、成像干扰,使得对其的分析难度远高于传统图像文本,对于高弯曲度文本场景,则更具挑战性。如何设计一种表示方式,既能够让模型学习到不规则文本的几何变化,又能准确表示出不规则文本的边界,即尽可能少地包含非文本实例区域。
在传统的计算机视觉领域中,自然场景文本检测方法主要有基于连通域的方法和基于滑动窗口的方法[1]。基于连通域的代表方法有最大稳定极值区域(maximally stable extremal regions,MSREs)[2]、笔画宽度变换(stroke width transformation,SWT)[3]、基于边缘和基线[4]等方法,该类方法通过颜色、边缘、笔画宽度等特征得到字符候选框,进而组成文本连通域,后接文本分类器得到最终的结果[5];基于滑动窗口的方法[6]利用纹理特征训练分类器,得到滑动窗口中文本区域的概率响应值,通过结果分析等步骤获取文本框位置。这两种方法都是基于人工特征提取,若直接用于自然场景,则容易丢失特征或提取到错误的特征,从而导致文本定位不准确[7],难以满足复杂自然场景下不规则文本检测需求。
随着深度学习技术和人工神经网络研究的不断发展,越来越多的研究者将深度学习技术和文本检测相结合,自动提取不规则文本的复杂特征,通过深度神经网络模型检测不规则文本实例[8],取得了一些成果。依据检测模型的技术特点,基于深度学习的自然场景文本检测研究可分为两个方向:基于回归技术和基于分割技术的文本检测。Gupta等人[9]首次提出了一种基于区域建议的全卷积回归网络(fully convolutional regression network,FCRN)模型,该模型首先根据全卷积网络提取特征图,后对特征图进行卷积操作,回归预测每个栅格位置所属文本区域的中心坐标偏移、宽高和角度信息。Liao 等人[10]针对尺寸比例不同的文本检测提出Text-Boxes网络结构,使用规则矩形文本表示文本框,根据不同卷积层的多尺度特征有效检测不同尺寸文本。在此基础上Liao 等人[11]进一步提出了能够检测自然场景中任意朝向文本的TextBoxes++。TextBoxes 以及Text-Boxes++都是对预先设定的候选框进行微调,难以适应自然场景中形状各异的不规则文本。CTPN(connection text proposal network)[12]引入循环神经网络RNN 进行文本检测,该方法将文本区域视为由多个字符或者字符的一部分构成的文本组件序列,通过预测固定宽度、不同高度的文本组件候选框的位置偏移实现文本区域的检测,该方法提升了锚点方法的适应性和水平文字的检测效果。Shi 等人[13]在CTPN 模型的基础上提出了面向任意朝向文本的分段链接检测模型SegLink。SegLink、CTPN 等方法利用连续候选框间接回归检测文本,耗时较长,为了进一步提升自然场景下不规则文本检测的性能,Zhou 等人[14]基于直接边框回归方法,提出了任意四边形文本检测模型EAST(an efficient and accurate scene text detector),但是直接边框回归感受野的限制使得在检测长单词和文本行时定位准确率不高、文本框短边的回归误差较大,因此四边形或矩形的检测方法不能适用于任意形状的文本检测。Baek 等人[15]提出了CRAFT 检测方法(character region awareness for text detection),将一个字符视为一个检测对象,对文本图像进行像素级回归,CRAFT 方法中字符连接在像素级进行,挖掘每个字符之间的亲和度用以检测文本区域,使用小感受野预测长文本,这样在检测任意朝向、弯曲文本等复杂场景文本图像时提高了灵活性。
基于边框回归的方法在轴对齐的文字检测中取得了较好的效果,但边框的表征方法难以适用检测任意形状的文本;同时,基于回归技术的文本框分类和边框回归方法不易于训练学习,在针对任意形状文本检测时的准确率、效率难以突破。Zhang 等人[16]首次将基于语义分割的文本像素分类预测引入到文本检测中,并基于全卷积网络进行多朝向文本检测。Deng等人[17]提出Pixel-Link检测模型,将连通像素链接在一起用于分割文本实例,根据分割结果直接获取文本边界框,不再需要进行位置回归,取得了不错的效果,但在处理文字间距较小的文本实例时,容易产生文本粘连。PSENet[18]采用对文本实例进行多级预测的渐进式扩展方法,有效缓解了文本区域粘连问题。TextSnake[19]采用了一种灵活表征不规则文本实例的新方式,该模型借鉴了文本组件先检测再连接的思路,引入一系列圆盘和文本中心线来表示文本区域,利用多级融合特征分类预测每个像素位置是否为文本域、中心线,通过回归预测圆盘半径和角度,重新构建得到文本实例预测结果,在长文本和不规则文本检测方面取得了较好的效果,但其后续还需用圆盘和轨迹角恢复文字区域,整体处理环节多、耗时长、过程相对复杂。DB(differenttiable binarization module)[20]提出了可微分的二值化操作获取文本边界,并简化了分割后的处理步骤,提升了检测的性能和速度。基于分割的方法虽然可以更好地适应任意形状的文字检测,但文字区域的提取一般还是采用外接矩形裁剪的方式,因此依然会将多余的背景噪声带入下游任务中,同时多边形的表征方式也不能直接用于矫正算法。为了更好地表征任意形状的文字,Wang 等人[21]提出了利用上下边界基准点来表征文字区域,取得了不错的效果,但由于采用两阶段模型,需要RoI(region of interest)对齐操作,因此在推理和训练上,耗时较多。TextRay[22]将文字轮廓点采用极坐标序列的方式来表示,但该方法在文字高度弯曲的场景下表现欠佳。ABCNet(adaptive Bezier-curve network)[23]利用3阶贝塞尔曲线方程表示文本的上下边界,灵活、简便地实现任意形状的矫正。由于贝塞尔曲线控制点的设置,在文字间距较小或文字附近有干扰的场景下容易误检或漏检。FCENet(Fourier contour embedding network)[24]通过傅里叶变换将文字轮廓点转换成复数域的傅里叶系数,在高弯曲文字等场景中取得了较好的效果。但是,FCENet 的文字区域最终的表征方式仍然是多边形,同样不便于文字区域的精确提取与矫正。
实际应用场景中存在着大量的不规则文本,如金融风控中所需识别的合同印章,包含了许多弯曲、变形的不规则文字。不规则文本的检测不但需要较高的检测准确率、召回率和速度,还需要为下游文本矫正任务提供便利,以此提高整体的检测与识别性能。现有基于矩形框检测的方法难以适用不规则文本检测,其他检测方法如TextSnake[19]、TextRay[22]、FSENet[24]等虽能检测不规则文本,但不便于下游任务实现文本矫正。为了解决上述问题,本文针对复杂自然场景下的不规则文本检测,提出了一种简单有效的方法:基于文本边轨模型(TextRail)的不规则文本检测。TextRail 模型通过预测不规则文本上下边界的基准点来表征文本区域几何属性,该表示方式不仅适用于不规则文本检测,而且为下游任务提供了便利,可以非常方便地应用薄板样条插值方法(thin plate spline,TPS)[25]进行文本矫正,有效地提升下游文字识别任务的准确率。
实验结果表明,TextRail 模型在自然场景下不规则文字检测中获得较高的准确率,提升了不规则文本的检测性能。
本文的主要创新点为:
(1)提出了一种通过一阶段像素级密集预测文本上、下边界基准点的文本检测方法。
(2)将分割、基准点预测、文本框大小、偏心率四个检测任务有机结合,采用多任务联合优化策略有效解决文本粘连问题,并进一步提升模型的性能。
(3)提出一种基于文本上、下边界基准点文本检测和矫正的端到端流程,简化了任意形状文本区域的提取与矫正的流程。
1 模型方法
本文提出的TextRail 模型的核心是预测文本上、下边界的基准点。模型采用全卷积网络架构,并采用一阶段像素级密集预测的方式实现基准点的预测,从而避免了全连接网络尺寸固定和候选区域网络二阶段速度慢的缺点,在保证精度的前提下,提升模型推理速度并且可适应任意尺寸的图像。预测基准点之后,基于TPS[25]实现弯曲文字的自动矫正,从而降低下游识别任务的难度,提升识别的鲁棒性和准确性。
为了解决文本区域尺寸不统一对基准点预测准确度产生的影响,模型增加一个回归分支,实现对文本区域外包箱矩形大小的预测,根据文本实例区域外包箱矩形大小实现对其相应关键点坐标的归一化。
文本区域边缘部分预测的结果一般精确度较差,为了提高预测的精确度,本文增加了一个偏心率分支。借助偏心率来提高文字区域中心位置的权重,降低边缘部分的权重,在提升模型精度的同时,也能减轻粘连文字间的相互影响。
1.1 基于TextRail的文本检测流程
文本检测的整体处理流程如图2所示,首先文本图片经过全卷积网络(full convolutional network,FCN)及特征金字塔网络(feature pyramid network,FPN)提取特征;然后将特征分别送入三个检测头实现基准点的初始预测;基准点的初始预测结果经过位置感知非极大抑制LNMS(locality-aware non-maximum suppression)得到最终的基准点预测结果;最后,基准点坐标应用TPS[25]方法实现文本实例的提取和矫正。

图2 文本检测流程Fig.2 Text detection process
整体检测流程对应的网络有三个主要部分:FCN主干网络、特征提取网络和检测头网络,如图3 所示。ResNet-50 有着良好的特征提取能力,在计算机视觉领域已经得到了广泛应用;在文本检测领域,RestNet-50也常被用来作为主干网络[20,22,24]。FCN 主干网络采用ResNet-50,其借助残差学习和1×1 卷积,在网络层数增加的同时,既能保证精度,又能够防止梯度消失。为了更好地提取不规则文本的特征,本文将ResNet-50 中的Conv3、Conv4 和Conv5 的3×3 卷积都采用了调制可变形卷积[26]。
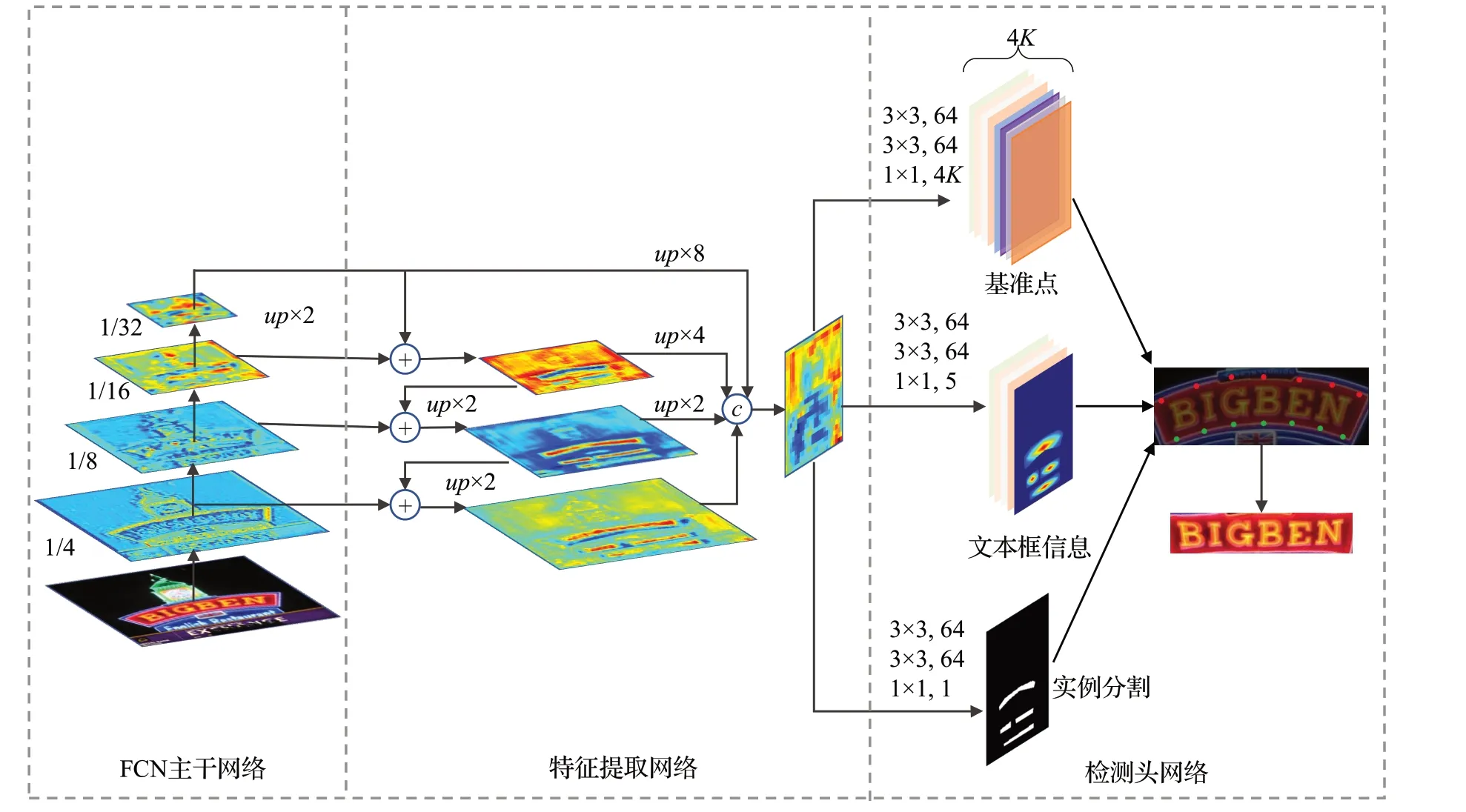
图3 文字检测网络结构Fig.3 Network structure of text detection
特征提取网络采用了FPN。自然场景下的图像存在文字大小不一的问题,采用FPN做特征融合处理可以兼顾到不同大小的文字。如图3 中FCN 主干网络部分1/4,1/8,1/16,…,1/32表示相对于输入图片大小的缩放比例;up×n表示以n为比例的上采样;n×n表示以n为卷积核大小,输出为c个通道的卷积。
检测头网络由三个分支构成:实例分割、文本框信息检测和基准点检测。实例分割分支采用sigmoid作为激活函数,输出为一个通道,表示特征图上每个像素是否为文本区域的概率值;文本框信息检测分支输出五个通道,也采用sigmoid作为激活函数,其中四个通道为文本框大小,这四个通道分别表示当前位置距离文本外包箱四条边的距离,另一个通道为偏心率,表示当前位置偏离文本区域中心点的概率;基准点检测分支在1×1卷积后采用tanh激活函数,输出1/4原图大小的4K个通道的特征图,特征图上每个像素对应2K个基准点相对当前位置的偏移量P,P=[P1,P2,…,P2k]∈R2,K为上、下边每条边上的基准点数量。实验室环境下,K值取[7,16]效果最佳,真实应用场景视文字的平均长度决定,如果不规则文字较长,可适当增加K的数值。
模型设计的核心包括基准点生成、损失函数设计、文本矫正及采样。
1.2 TextRail基准点的生成流程
基准点生成流程如图4所示,首先获取文字区域概率图,将输入图像的宽和高记为w和h,通过前馈神经网络分别得到实例分割图Ob、偏心率图Oc、基准点Of、文本大小Ot。如公式(1)所示,Ob和Oc做内积,得到有效文字区域Oe。
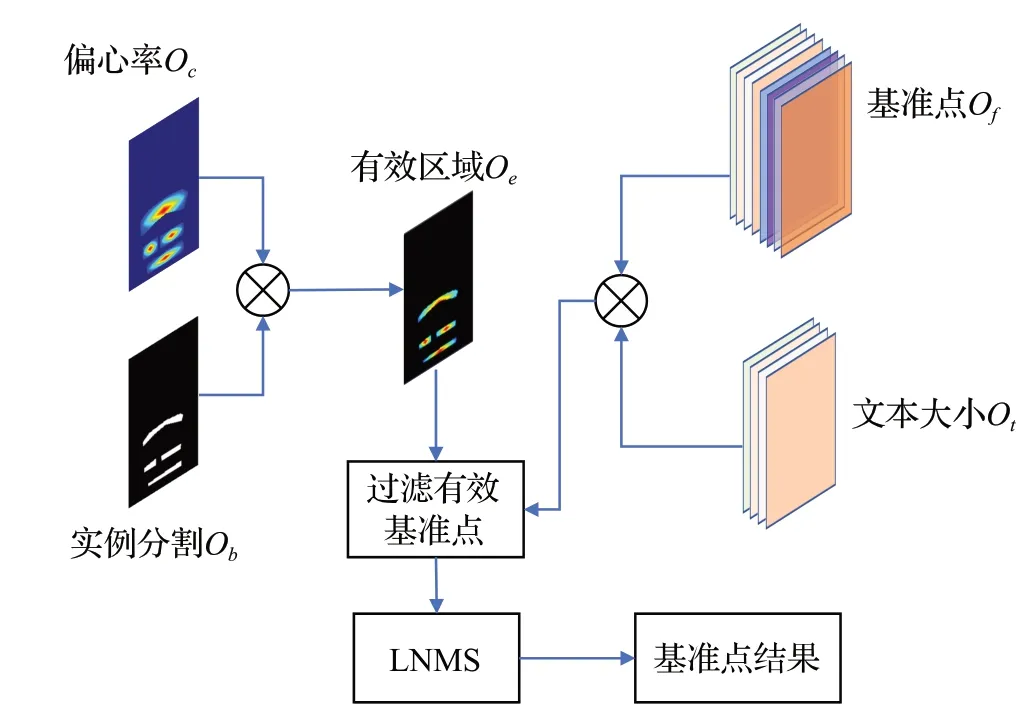
图4 基准点生成流程Fig.4 Process of fiducial points being created
接着,获取文字区域大小,如公式(2)~(4)所示:
其中,Si,j为特征图上坐标为(i,j)的点对应的文字区域大小,(i,j)是文字区域大小输出图Ot上的位置坐标,ti,j、bi,j、li,j、ri,j分别Ot预测的当前位置距文本外包箱上、下、左、右四条边的距离。最后生成基准点,如公式(5)所示:
其中,fi,j表示基准点预测图坐标为( )i,j的点对应的基准点预测结果,threshold为是否为文本区域的阈值(经验值取0.5)。将F经过LNMS得到最终的输出。
1.3 损失函数
损失函数包括了实例分割损失函数、基准点预测损失函数、偏心率损失函数及文字区域大小损失函数组成。本文采用多任务学习联合优化策略,其中实例分割任务是为了得到文本区域,即分割文本区域与背景,这一操作可以过滤掉背景部分无效的基准点预测,减少整体处理流程计算量的同时,也提升了模型性能。主任务为基准点预测,即预测当前点到文本区域上、下边基准点的偏移量。为了进一步提升模型准确率,减少互相粘连文本区域的互相干扰,TextRail 模型引入了偏心率任务,目的是降低文本区域边缘部分的预测权重。文本框大小任务是输出当前文本区域的最小外包矩形大小,利用外包矩形的大小对基准点进行归一化处理,避免文字大小不一致导致的损失偏差。为了使总体损失函数更容易求导计算,本文采用各子任务损失函数相加求和的方式得到总体损失函数,从而四个任务间互相补充、互相促进。损失函数求解使用梯度下降法,向损失函数当前点对应梯度的反方向进行搜索,以此找到损失函数的极小值点。
1.3.1 实例分割损失函数
实例分割输出表示每个像素是否属于文本区域,因此损失函数使用二分类交叉熵损失(binary crossentropy),计算如公式(6)所示:
其中,yi表示样本i的类别,文本区域为1,非文本区域为0;xi表示样本i预测为文本区域的概率。
为了克服正负样本不均衡问题,采用困难负样本采样方法,对负样本只取最大损失的K个参与计算。因此最终的损失如公式(7)所示:
其中,Pi为正样本区域,Psi为负样本区域中TopK区域。
1.3.2 基准点和偏心率损失函数
基准点损失和偏心率的输出是数值回归结果,有鉴于此,此处采用Smooth-L1 损失,如公式(8)和公式(9)所示:
其中,Lc为偏心率的损失,Rs为文字实例膨胀区域内的点。Lf为基准点损失,Ns为文字实例内缩区域内的点数,K为每条边上基准点个数,2表示有上、下两条边。
1.3.3 文字区域大小损失函数
不同大小的文字出现在同一张图片较常见,为避免文字尺寸不同对loss 值造成的偏差,此处采用IoU 来计算文字区域外包箱大小的损失,参考EAST[14]的方法,其计算公式如公式(10)所示:

其中,d1、d2、d3、d4分别为当前位置到文字区域到外包箱矩形左、上、右、下四条边的距离。
1.3.4 总体损失函数
将实例分割损失函数、基准点及偏心率损失函数、文字区域大小损失函数汇总,形成总体损失函数,如公式(14)所示:
α、β、γ、θ为平衡各损失之间的系数,Ls、Lc、Lf、Lt分别为实例分割损失、偏心率损失、基准点损失、文本区域大小损失函数。参考TextSnake[19]与DB[20]的经验,由于各子任务损失函数的数值尺度基本一致,将α、β、γ、θ取值均为1。
1.4 文本矫正及采样
如图5所示,采用矩形或旋转矩形对文本区域进行采样会引入背景干扰,从而影响下游文字识别准确率。为了更有效地提取文本区域,本研究基于STN网络[27]的思想实现文本矫正与采样,称之为基准点采样。基准点采样不但可以有效减少背景干扰,而且能同时实现文本的自动矫正。

图5 采样矫正方法的比较Fig.5 Comparison between previous sampling methods
STN可以通过预测TPS变换参数,将输入图片I校正成I′,STN网络由定位网络(localization network)、网格生成器(grid generator)和采样器(sampler)三部分组成。参考RARE[28]文本矫正方法,将基准点检测网络替代其中的定位网络,结合网格生成器和采样器实现文本的自动矫正。文字矫正流程如图6所示,原始图像通过基准点检测得到文字轮廓的基准点,然后通过网格生成器得到校正图上的像素与原始图像像素上的映射关系,最后根据像素映射关系在原图上采用插值采样的方式得到矫正后的图像。
1.4.1 网格生成器
网络生成器根据基准点坐标估算TPS的变换参数,从而得到采样网格。假设矫正后的图像为水平,且基准点等距分布,据此定义矫正后图像上的基准点C′:
K为基准点的个数,由于矫正后的图像尺寸经过归一化处理,因此C′是恒定的,据此便可以根据预测的基准点和矫正后的基准点来估算TPS 变换参数T,如公式(16)所示:
迭代I′ 上所有的点即可得到采样网格p={Pi}i=1,2,…,N。
1.4.2 插值采样
通过网格生成器得到原图上的坐标会出现小数,而图像上某一像素点的位置坐标只能是整数。因此,在原图点P附近采用双线性插值的方式得到矫正图坐标点P′,如公式(20)所示:

其中,P为网格生成器得到P′对应的原图上的坐标,I为原图,V为双线性插值采样。
借助TPS的灵活变换能力,将弯曲或不规则排列的文字矫正成标准水平的文字,从而降低下游识别任务的难度。
2 模型实验验证
2.1 数据集准备
本文实验数据集来源于三份公开的文本图像数据集(IC15、TotalText 和CTW1500)及一份企业采集的印章数据集(AI Seals 2022)。
IC15(ICDAR 2015 Incidental Text):IC15 是ICDAR2015 Robust Reading 竞赛任务中使用的数据集。图片由Google Glasses 随机拍摄,不刻意干涉视角、对焦、位置等拍摄条件。因此,图像中的文字方向、尺寸、清晰度等参差不齐。IC15 的检测数据集包含1 000 张训练图片和500 张测试图片,采用单词级别标注,每个单词标注了四个角点的坐标。
TotalText[29]:Totaltext除了包括水平、多朝向文字还包括了弯曲文字,有一半以上的图片具有2个以上朝向的文字。TotalText数据集包含了1 255张训练图片,300张测试图片,采用单词级别标注,每个单词采用多边形包围箱进行标注。
CTW1500[30]:CTW1500图片来自互联网,包括3 530个弯曲文本,同时也包含一些水平和多朝向的文本。CTW1500共包括1 000张训练图片和500张测试图片。
AI Seals 2022:本研究采集的企业印章数据集。印章上的文字不规则度非常大,同时由于拍摄或文件不平整的原因,有些印章上的文字通常是不完全规则的排列,如图7 所示。因此,印章符合自然场景下不规则文本的特点,同时在企业日常工作中存在实际识别困难的问题。利用企业采集的印章数据集对模型进行验证。本文共收集1 318枚印章。

图7 不规则形状印章Fig.7 Seals of irregular shapes
对采集的印章图片,进行了自动标注并进行了人工校对,如图8 所示,首先将业务单上的印章通过印章检测模型将印章区域提取出来,采用多边形的标注方式对印章中的文字进行标注,根据标注的多边形,利用本文基准点生成方法将多边形标注转换成训练所需要的标注。
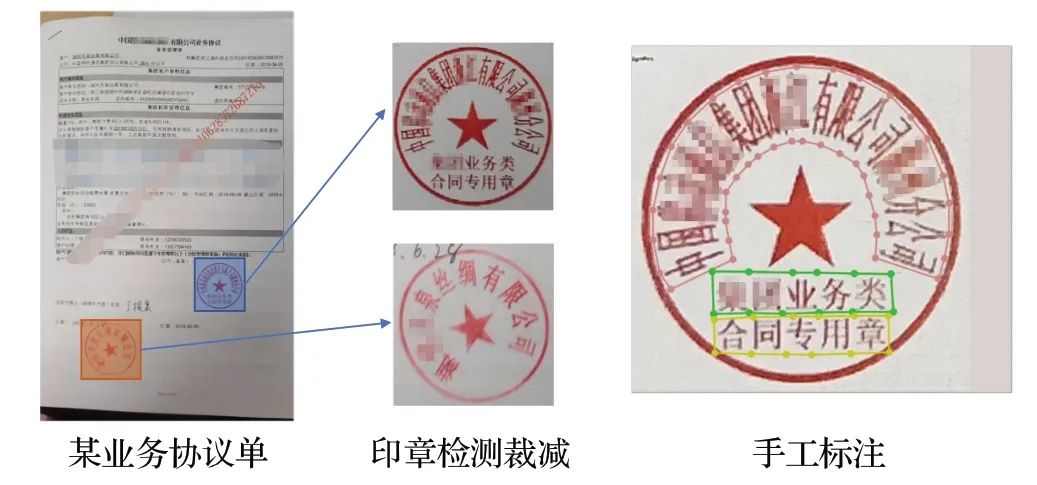
图8 印章数据集Fig.8 AI seals
2.2 数据集标注生成
2.2.1 实例分割
文本区域生成的方法参考DB 的方式,文本区域将原标注区域内缩一定距离,以减少文字粘连造而成分割不清的情况。具体方法如下:
(1)将文本区域标注视为生成多边形,每个多边形由n个顶点组成,数据集不同,n也不同:
(2)为了得到内缩的文本区域Rs,如图9 所示,黄色虚线为标注多边形,粉红色区域即是内缩区域。采用Vatti裁剪算法[31],内缩距离D通过公式(23)计算得到:

图9 Score map生成Fig.9 Created score map
其中,A为多边形面积,L为多边形周长,r为缩放系数。
2.2.2 文本框大小及偏心率
为了得到准确的文字区域大小,参考EAST 的方法,文本框大小表示由四个通道组成,四个通道分别表示到外接矩形四个边的距离,并做归一化处理,将当前位置到文字外包矩形左、上、右、下的距离分别记为l、t、r、b,图片的宽和高分别为Iw、Ih。归一化方法如公式(24)~(27)所示:
为了提高文字中心位置的权重,降低边缘部分的权重,使用偏心率的方法,参考FCOS[32],偏心率表达的是当前位置到文字中心的归一化距离,计算方法如公式(28)所示:
文本框大小及偏心率生成示意图如图10,(a)部分绿色矩形为原始外接矩形,蓝色矩形为内缩后矩形;(b)部分为四通道的文本大小,四个通道分别对应内缩矩形内的点相对原始矩形上、下、左、右四条边归一化后的偏移量;(c)部分为一个通道的偏心率,表示内缩矩形内每个点的偏心率值。
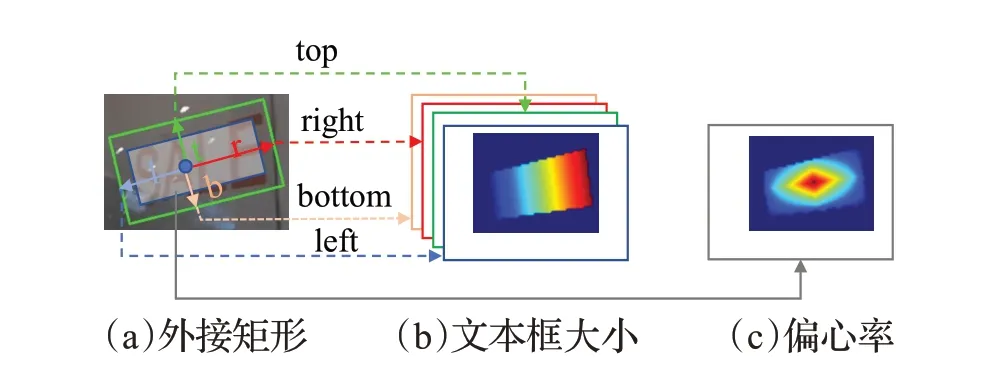
图10 文本框大小及偏心率生成Fig.10 Size of bounding box and centerness being created
2.2.3 基准点Map
在多边形的上、下长边上分别进行等距采样得到等距点,将这些等距点定义为基准点。如图11所示,在文字内缩区域内,计算当前位置到各基准点的偏移量,每个基准点的偏移量分别对应一个通道。如果上、下边各有K个基准点,则共产生2×2×K个通道(上下两条边,每个点的偏移量包括x,y)。
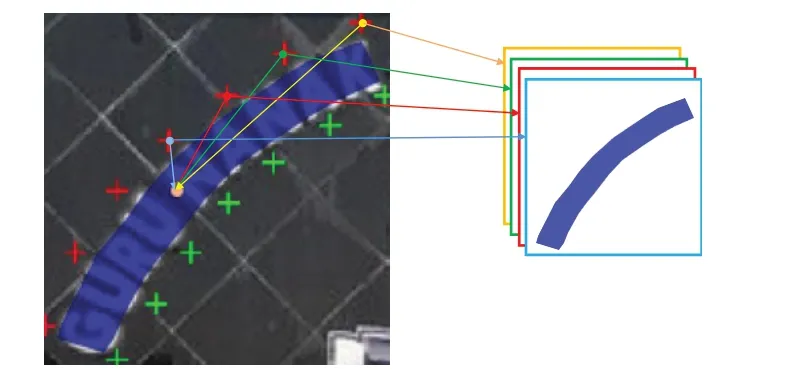
图11 生成基准点MapFig.11 Map of fiducial points being created
为了能使模型更易收敛,对偏移量做归一化处理。计算方法如公式(29)和公式(30)所示:
其中,w和h分别文字区域外包箱矩形的宽和高,Δx′为x轴偏移量归一化值,Δx为当前位置距某一基准点的x轴方向的偏移量,Δy′为y轴偏移量归一化值,Δy为当前位置距某一基准点y轴方向的偏移量。
2.3 模型训练细节
在采用以上数据集训练之前,本文采用SynthText数据集做预训练,使模型更好地学习文字区域特征。设置batch_size 为16,初始学习率为0.001,并采用线性学习率衰减进行训练,衰减系数为0.000 1,动量为0.9。
本文采用了随机裁减、旋转(-10°,10°)、水平翻转的方式、随机颜色扰动和随机对比度扰动进行数据增强,并将处理后的图片采用保持纵横比的方式统一缩放到800×800。
2.4 实验结果
本文提出的方法聚焦自然场景下不规则文本的检测问题,依据上述模型训练细节,在IC15、TotalText、CTW1500和AI Seals 2022据集得到实验结果,使用准确率、召回率、F1 值3 项评价指标,与其他算法作为对比,进行综合评价。在IC15数据集上实验的结果如表1所示,对比现有方法,本文提出的方法在F1上达到最高水平,F1提升1.0个百分点。在TotalText数据集上实验评估结果如表2 所示,对比现有方法,本文提出的方法F1 分数与最高水平相当。如表3 所示,在CTW1500 数据集上,召回率和F1 都达到了最高水平,分别提升0.2和0.9个百分点。
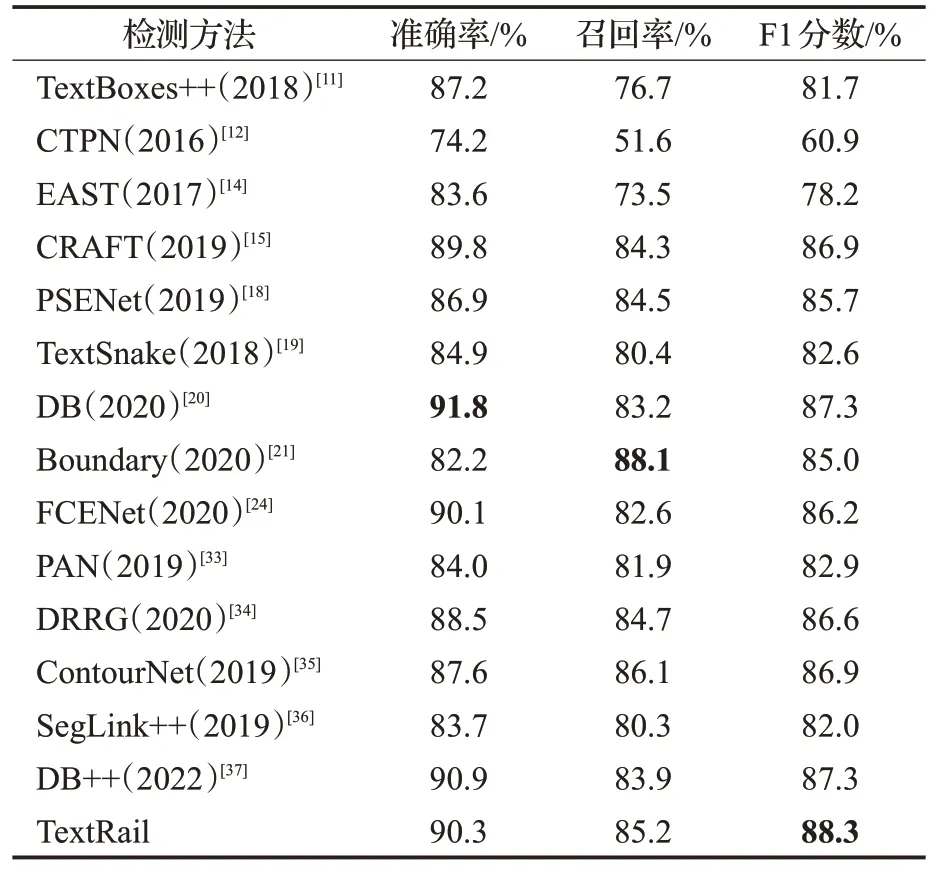
表1 IC15数据集结果Table 1 Experimental results on IC15

表2 TotalText数据集结果Table 2 Experimental results on TotalText
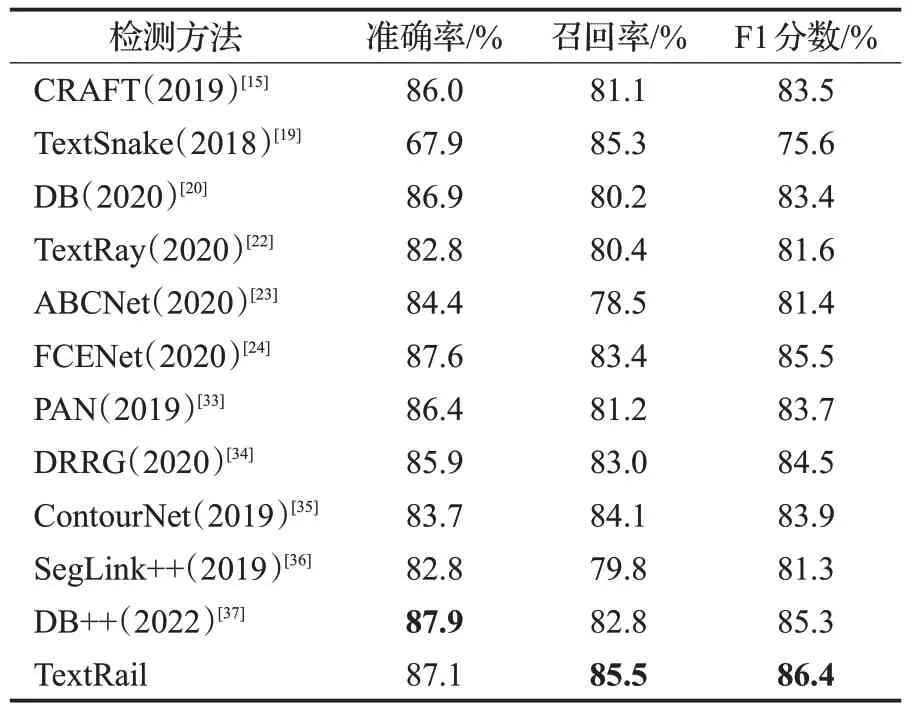
表3 CTW1500数据集结果Table 3 Experimental results on CTW1500
另外,使用印章数据集(AI Seals 2022)评估模型在实际场景中的效果。值得注意的是,并非所有的基线模型都公开了代码,因此,本研究仅测试了具有公开代码的基线模型。结果如表4所示,F1分数达到92.0%,取得了较好的应用效果。该实验结果总体上性能准确率均高于上述公开数据集上的效果,主要由数据集本身特点决定:(1)印章数据集背景干扰相对其他自然场景较少,主要是背景文字干扰较大;(2)印章数据集的标注经过了精细化的人工校正,有较高的标注质量。

表4 AI Seals 2022数据集结果Table 4 Experimental results on AI Seals 2022
2.5 消融实验
为了验证TextRail 文本框信息检测分支的有效性,在TotalBox 和CTW1500 上做了消融实验,实验结果如表5所示,其中TBN表示采用文本框大小对基准点坐标做归一化,CN 表示偏心率。结果显示根据文本框大小进行归一化处理能显著提升性能。同时偏心率对性能的提升也有一定帮助。
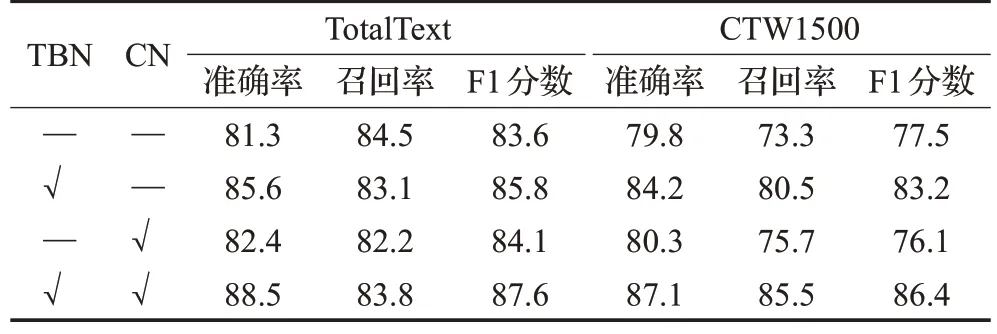
表5 消融实验结果Table 5 Ablation studies result单位:%
2.6 实验结果分析
本文提出的方法准确率及性能综合比现有方法有所提升,通过消融实验证明:(1)偏心率损失函数的使用可以过滤掉边缘部分无关的预测结果,降低相互粘连文本区域的影响,从而提升模型的性能。(2)采用文本区域的各自外包箱矩形大小作对各文本区域基准点进行归一化,可以更好地降低由于文本区域大小引起的误差不均衡。
其他对性能提升可能有帮助的原因:(1)基准点的表示方式可以较好地表达任意形状的文字轮廓。(2)采用多个相关任务的训练方式,多个任务间通过共享特征表达来互相分享、互相补充学习到的领域相关的信息,互相促进学习,提升泛化的效果。(3)采用像素级密集预测的方式,文本框大小和基准点的预测类似集成模型投票的方法,对模型的效果提升有一定帮助。
2.7 实验效果展示
以下场景中,红色点表示文字的上基准点,绿色为下基准点。图12 为IC15 的检测效果,可以观察到模型可以有效地检测出各种朝向的文字,对于间距比较小的文字也能有效的分隔。图13 为TotalText 的检测效果,对于弯曲、透视、水平等不规则文本,模型都表现出了较好的鲁棒性。图14 中的印章朝向随机,且有背景文字干扰,模型可以有效的区分上、下边及其基准点,帮助印章文字识别达到较高的准确度。图15 是TextRail、TextRay、ABCNet 在CTW1500 数据集上的效果对比样例,从图中可以看出,TextRay对于高弯曲文本的检测效果不佳,而ABCNet则会存在文本区域漂移和漏检的情况。

图12 IC15文字检测效果样例Fig.12 Result of text detection on IC15 database

图13 TotalText文字检测效果样例Fig.13 Result of text detection on TotalText database

图14 印章效果样例Fig.14 Result model of seals detection

图15 TextRail与TextRay、ABCNet及真实效果比较Fig.15 Comparison of TextRail with TextRay,ABCNet and Gound truth
3 结束语
本文针对复杂自然场景下的不规则文本检测,提出一种基于文本边轨模型的检测方法TextRail。该方法采用多任务联合优化策略将文本实例分割、基准点预测、文本外包箱矩形大小和偏心率四个相关任务有机结合,采用像素级密集预测的方式预测文本区域上、下边界基准点,实现不规则文本的检测,有效提升了文本检测的的精度。同时,基准点的文本区域表示方法可以很方便地利用TPS 实现文本矫正,降低下游识别任务的难度。在多个实验数据集上的实验进一步验证了本文检测方法在不规则文本检测上具有良好的效果和性能。
由于模型采用文字实例分割的方式来选取有效的文本区域,因此模型不能适用于小文字包含于大文字的场景,即大的文字区域中出现比较小的文字区域。这种场景下,文字分割时小的文字区域将会被大的文字区域完全覆盖,因此不能得到独立的文本实例而出现漏检。
未来将对以下方向进行探索:(1)基于TextRail 模型,将文本检测、文本矫正和文本识别融合成一个端到端模型,实现高效、简洁的自然场景文字检测和识别。(2)结合其他轻量化的主干网络,研究更快捷有效的文本上、下边基准点的检测方法。(3)寻求更好的文本区域表达方式,解决大小文本区域重叠不能有效检测的问题。
猜你喜欢
华中建筑(2022年4期)2022-04-14
天文学报(2021年5期)2021-10-09
新一代信息技术(2021年2期)2021-07-23
现代测绘(2021年1期)2021-04-28
中国自行车(2018年2期)2018-05-09
福建人(2016年6期)2016-10-25
钢管(2016年1期)2016-05-17
Coco薇(2015年7期)2015-08-13
中国医疗美容(2015年2期)2015-07-19
空间控制技术与应用(2015年4期)2015-06-05
