
基于迁移学习的小样本事件抽取技术及军事应用展望*
2023-11-20 10:59蒋国权刘姗姗周泽云
火力与指挥控制 2023年10期
刘 涛,蒋国权,刘姗姗,周泽云,陈 涛
(1.国防科技大学第六十三研究所,南京 210007;2.南京信息工程大学计算机学院软件学院网络安全空间学院,南京 210044;3.装备发展部信息中心,北京 100034;4.装备发展部某局,北京 100034)
0 引言
事件抽取分为事件检测和论元抽取两个子任务,源于20 世纪80 年代末期开始的消息理解会议(message understanding conference,MUC)[1],由美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)资助,主要缘由是随着信息战争时代的到来,军方需要利用自动化工具从大量信息源中获取有用信息。由于军事材料的保密性、隐蔽性等原因,相比医学、新闻、金融、法律等领域,军事领域事件抽取相关研究较少。事件(信息)抽取技术在实现大数据知识化[2]、资源化和普适化过程中扮演着重要作用。抽取非结构文本信息进行并以结构化形式展示出来,使得计算机可以直接处理,从而实现对各种非结构化数据的分析、管理、查询、推理等,并进一步为更高层面的任务和应用(如知识库构建、态势分析系统、智能问答系统)提供重要支撑。
军队信息化发展也需要从文档材料中抽取有效的事件信息,从而进行上层应用[3]。目前在各个单位保存有海量的动态信息文件和军事文本资料,传统方式是利用人工对文本信息进行抽取和数据库构建,需要消耗大量人力物力。传统基于机器学习的事件抽取方法面临的首要挑战是需要大量的标注数据,但数据的标注需要领域专家知识和语言学知识,其规模是十分有限的,从而导致可获取的有限特征限制了事件抽取的效果。
近年来,随着深度学习技术的不断突破,研究者开始设计有效的神经网络结构,如卷积神经网络、循环神经网络、图神经网络、注意力机制、预训练语言模型等来自动抽取有用的特征,利用深度神经网络结构可以显著地提升事件抽取效果。但其面临的最大挑战是:现实场景下特别在军事领域标记数据是极度缺乏的,这大大限制了神经网络模型的应用。近年来,有研究者开始利用迁移学习技术来解决事件抽取过程中面临的标记数据缺乏问题,并取得显著成效。
本文研究重点为基于迁移学习的小样本事件抽取及军事应用展望。首先介绍了基于迁移学习小样本事件抽取的研究背景,其次详细阐述了基于迁移学习小样本事件抽取技术方法,接着又对其军事应用作了初步展望,最后给出相关结论及问题与挑战。
1 研究背景
事件抽取的目的是从非结构的文本中抽取出重要的、关键的事件信息并以结构化的形式展现出来,使得相关人员更加清晰、方便、直观地了解并利用相关关键信息。但是自然语言本身具有复杂性,如表达的多样性、模糊性、歧义性等,另外由于其规模庞大和开放等特性,使得对自然语言文本进行事件抽取变得很困难,因此,研究者开始考虑设计灵巧的方法来解决该问题。
早期用于事件抽取的方法主要是基于模式匹配的方式,首先构造预定义的事件模板,并从文本中抽取事件和论元来匹配相关的模板。而模板的构造方法主要包括模板手工构造和自动生成方法。RILOFF 等提出第一个基于模式匹配的事件抽取系统AutoSlog,该系统是用于抽取特定领域的恐怖主义事件,其利用少量语言学模式和一个手工注释的语料库来获得事件模式[4]。但是手工构造的事件模式是耗时耗力的,并且很难扩展到其他领域。YANGARBER 等通过利用机器学习算法基于一小部分种子模式来学习新模式,从而促进自动构造模式,设计了ExDisco 事件抽取系统,利用少数种子模式代替语言学模式来获得潜在的事件模式[5]。
上述基于模式匹配的方法进行事件抽取面对的首要问题是构造大规模的事件模式非常困难。研究者开始使用机器学习方法进行事件抽取,如最大熵(maximum entropy,ME)、支持向量机(support vector machine,SVM)等模型。机器学习方法主要是通过利用训练数据的特征(如语法特征、句法特征、语义特征和标签等)学习一个分类器,并利用分类器进行事件抽取。于江德等利用ME 模型对日报新闻事件进行事件分类或元素的抽取。针对管道分类模型在进行事件抽取时产生的错误传播问题,研究者设计了联合分类模型[6]。LI 等提出同时建模全部和局部特征来联合抽取事件触发词和事件元素[7]。机器学习方法需要大量的标准训练语料,而手工标注是耗时耗力的,因此,其在实际应用时会面临较为严重的数据缺乏问题,而特征工程对于机器学习方法来说是很重要的。
随着深度学习时代的到来,研究者开始设计深度神经网络来自动学习深层次特征,主要包括卷积神经网络、循环神经网络、图神经网络、注意力机制等来充分建模文本信息。随着研究的深入,研究者开始设计大规模预训练语言模型,如BERT(bidirectional encoder representations from transformers)通过微调范式来执行下游任务,最近有人设计提示(Prompt)学习来指导预训练语言模型[8],从而提升事件抽取的效果。
但机器学习、深度学习技术严重依赖于特征工程。因此,在标注数据缺乏时,其性能会受到严重影响。研究者开始探索新的方式来解决小样本事件抽取问题,实验表明,通过迁移学习技术可以有效地提升进行事件抽取时面临的标注数据缺乏问题。
2 迁移学习小样本事件抽取技术
基于迁移学习的小样本事件抽取技术在零样本、少样本场景下具有明显的优势,有效地解决了传统事件抽取方法在标注数据缺乏时性能骤降的问题。标注数据缺乏的问题在小语种、特殊领域上是很常见的。另外由于人工标记数据是耗时耗力的,导致当前数据集的规模很小,难以覆盖大规模的事件类型,因此,事件类型的分布呈现出长尾状。还有一些情形是利用任务之间的相关信息来提升事件抽取的效果。因此,本文的技术方法主要从跨语言迁移学习、跨领域迁移学习、长尾事件迁移学习、多任务学习方面展开叙述。
2.1 跨语言迁移学习
事件抽取面临最重要的问题是在跨语言时可以获得的训练数据数量是不充分、不平衡的,特别是对于一些小语种语言(如西班牙语、乌克兰语、阿拉伯语等)来说,其注释数据是严重缺乏的。另外,由于复杂性和注释耗时耗力等问题,目前已经存在的事件抽取数据集的数量以及覆盖面是有限的。因此,有研究者开始探索将已经存在的丰富的语言资源迁移到训练数据稀缺的语言上,从而改善小样本语言事件抽取的效果。
SUBBURATHINAM 等提出利用关系和事件相关的语言共性特征,即使用分布式信息(如:类型表示和上下文表示)和符号信息(如词性(POS)标记和依赖路径)来进行跨语言结构的迁移[9]。通过将所有的实体提及、事件触发词、上下文等表示到一个复杂的和结构化的多语言通用空间上,使用图卷积神经网络从源语言注释中训练一个关系或事件抽取器,将其应用到目标语言上,可以取得不错效果。不同于上述采用传统分类方式进行事件抽取,HUANG 等提出了一个跨语言事件论元抽取器(cross-lingual generative event argument extractoR,X-GEAR)模型,其采用生成式方法进行论元抽取[10]。如图1 所示,通过给定一个输入片段和一个包含事件触发词和相关语言未知的模板提示,X-GEAR 生成相关句子并使用论元来填充该语言未知的模板,其继承了基于生成语言模型的优势可以捕获事件结构和实体之间的依赖关系,在源语言上训练之后可以直接用于目标语言的事件论元抽取任务。由于BERT 模型在自然语言处理领域的各项任务上都取得优异的效果,因此,最近有研究者开始探索利用BERT 模型来改善跨语言迁移时事件抽取的效果。CASELLI 等探索了利用BERT 模型在意大利语和英语两种语言上微调时对于触发词检测和分类的效果,同时也验证了通过在微调阶段添加用于评估语言的数据,使得模型可以具备更强大的迁移能力[11]。上述进行跨语言迁移任务时采用的源语言数据大都是基于单语言,ZHU 等提出利用中文和英文合并的双语信息来解决中文事件抽取数据稀缺的问题[12],并且从单语言和双语言两个角度,来解决触发词定位困难的问题。

图1 X-GEAR 模型结构Fig.1 Model structure of X-GEAR
2.2 跨领域迁移学习
事件抽取在多个社会领域都扮演者重要的角色。如在工业领域,主要的工业事件对于社会和政治的影响很大,大型工业事故会给人们生命财产造成不可挽回的损失,通过抽取工业领域的典型事件可以帮助政策制定者设计措施来预防突发事件的发生。在金融领域事件抽取可以帮助人们直观、清晰地了解当前金融形势如股票趋势、金融风险等。在生物医学领域,生物医学事件抽取旨在抽取细粒度生物实体之间的多元语义关系,对药物研发和疾病防治等具有重大意义。类似于跨语言时面临训练数据缺乏的问题,很多特定领域可以获得的训练数据也是很少的,这使得研究者开始转向跨领域的迁移学习方法来提升小样本事件抽取的效果。
针对工业领域注释数据集获取困难的问题,RAMRAKHIYANI 等提出使用通用领域的事件标记数据预训练一个双向长短期记忆网络条件随机场(bi-directional long short-term memory-conditional random field,Bi-LSTM-CRF)模型[13],该模型可以学习到基于动词和名词事件的相关特质,然后将其迁移到一个小规模工业领域事件标记数据集上,来提供更多丰富的工业事件标记数据。除了上述采用传统神经网络的方法外,LEE 等提出在商品新闻语料库上预训练的BERT 模型得到ComBERT 模型[14],该模型不仅可以在金融和经济领域事件抽取中取得显著成效,同时ComBERT 模型的嵌入特征还可以提升在上下文子树上使用图卷积神经网络进行事件抽取的效果。类似于上述方法,在生物医学领域,HUANG 等提出利用一个以边为条件的图注意力网络(graph edge-conditioned attention networks,GEANet)来编码一个分层的图表示[15],如图2 所示。模型下方用一个预训练语言SciBERT 模型来整合领域相关的知识,最后将知识图谱的表示和SciBERT 表示整合起来作为最终的知识表示,从而提升生物医学事件抽取的效果。

图2 SciBERT 模型框架Fig.2 Model framework of SciBERT
2.3 长尾事件迁移学习
事件抽取现有的标准数据集,如ACE2005 的规模较小,只有8 个类型和33 个子类型。传统的机器学习、深度学习事件抽取方式需要大量注释事件提及的特征并且不能泛化到新事件类型上。而在现实场景下会面临大规模无标注数据,当模型面临没有任何注释数据的新事件类型时其性能会急剧下滑,主要原因在于这些方法通过测量注释事件提及和测试事件提及之间编码特征的相似性,将事件抽取视为分类问题。因此,研究者开始探索迁移学习的模型来提升零样本的事件抽取效果,可以很好地解决没有任何注释数据的新事件类型场景。
HUANG 等提出一个可迁移的神经结构,利用已存在的人工构造事件模式和少量可见事件类型的手工注释,将已存在事件类型的知识迁移到未见的类型上,来提升事件抽取的泛化能力[16]。不同于上述基于弱监督的方法,LAI 等提出一种基于特征的注意机制与卷积神经网络结合的模型架构,通过几个关键词来描述事件类型以匹配文档中的上下文,使得模型可以操作新事件类型[17]。上述方法在匹配阶段不可避免地会引入噪声,最近,有研究者提出使用机器阅读理解来解决事件抽取时面临的数据缺乏问题。LIU 等提出将事件抽取视为机器阅读理解(machine reading comprehension,MRC)范式[18]。该方法首先采用一个无监督问题生成策略,将事件模式迁移为一组自然语言问题,通过将BERT 模型引入到MRC 中来强化事件抽取的推理过程,通过引入机器阅读理解有关的大规模数据集来削减数据缺乏的问题。不同于上述方法通过引入MRC 相关数据集进行数据扩充,熊孟等提出以BERT 模型为框架构造单轮问答模型[19],首先进行触发词问题生成,将生成的触发词问题和事件句组合输入到BERT 模型中,并将先验知识库中的知识融到模型中,通过问答的形式抽取上下文中的触发词并对其分类获得事件类型,如图3 所示。

图3 典型机器阅读理解事件检测模型举例Fig.3 An example for typical event detection model of machine reading understanding
2.4 多任务迁移学习
先前事件抽取的方法主要遵循管道模式,但以管道方式执行事件抽取的子任务不能捕获子任务之间的依赖关系,还会引起错误传播问题。多任务学习能够充分利用各个子任务之间的相互关系,通过少量的标注数据就能学习出更加鲁棒的模型,因此,多任务迁移学习也越来越受到研究者的广泛关注。
WADDEN 等提出一个多任务学习框架DY GIE++[20],如图4 所示。通过枚举、精炼、评分文本范围来捕获局部(句内)和全局(跨句子)的上下文信息,并利用BERT 的上下文嵌入来捕获一个句子或者相邻句子中实体之间的关系,通过动态范围图的更新来建模长范围跨句子之间的关系。LU 等提出通过训练同一个网络结构的两个不同版本分别用于事件检测和词义消歧,通过表示匹配的方法促使两个版本之间的知识迁移,从而提升深度学习模型用于事件检测的效果[21]。段绍杨等提出一个基于多任务学习的中文事件抽取联合模型,来挖掘不同子类别事件之间的关联信息,通过引入高斯核函数和多项式核函数评估任务之间的关联程度,从而强化事件抽取的联合模型[22]。实验表明,该方法可以很有效地提升事件抽取的效果。
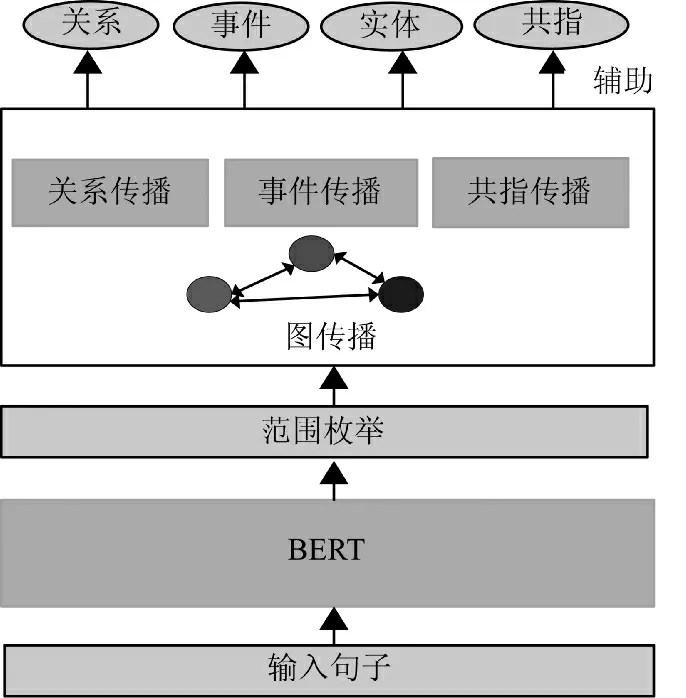
图4 DYGIE++模型框架Fig.4 Model framework of DYGIE++
下文总结对比了上述技术方法所针对的问题和方法思想,并列出了研究者相关的工作,如下页表1 所示。
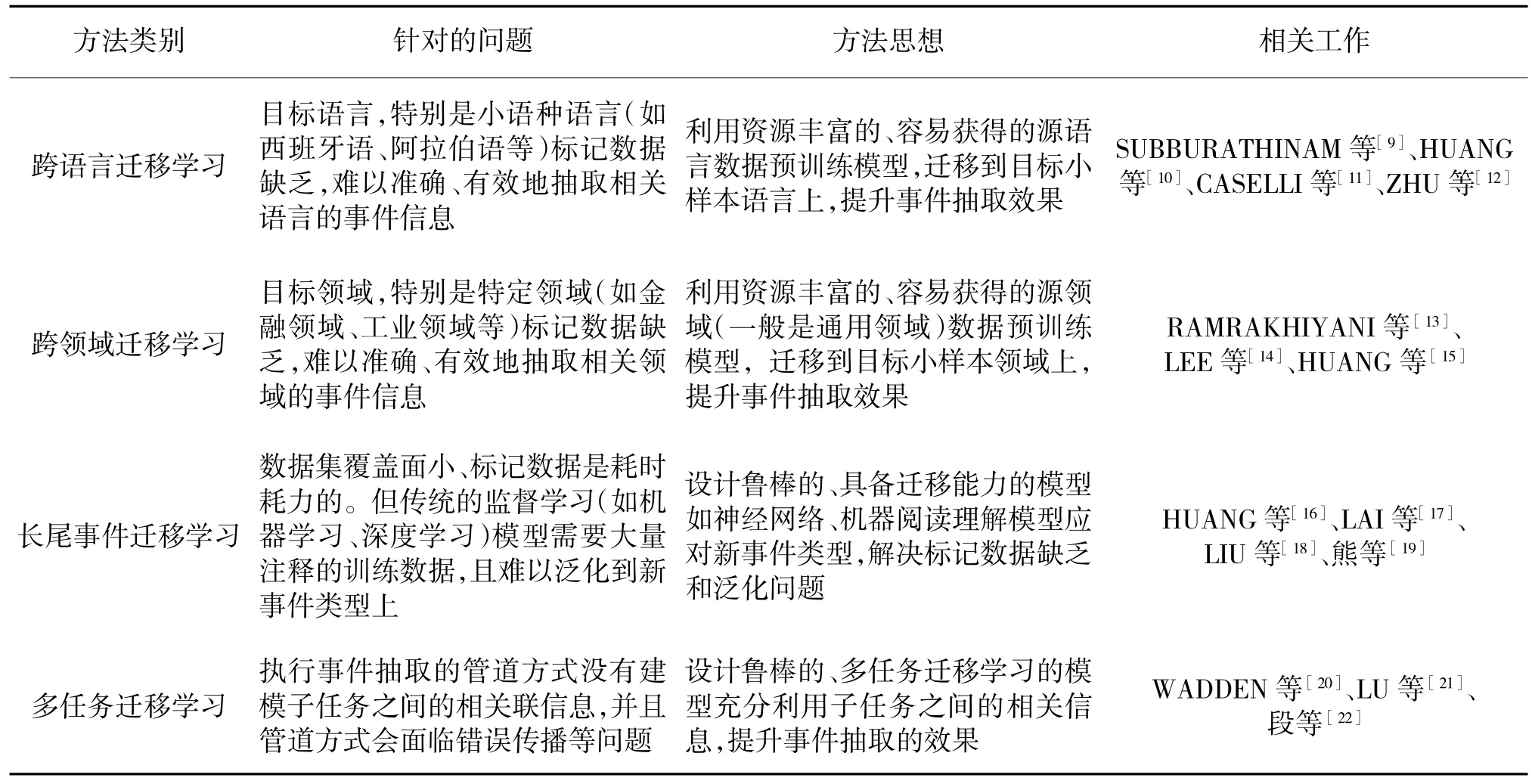
表1 基于迁移学习小样本事件抽取技术方法总结与对比Table 1 Summary and comparison of small sample event extraction techniques based on transfer learning
3 军事应用展望
3.1 军事事件抽取技术现状
事件抽取作为信息抽取的子任务,在军事领域信息的获取与处理中是至关重要的。传统用于军事事件抽取的方法主要是利用本体和规则推理。利用深度学习技术进行事件抽取,大大提升了对于军事文本信息的特征获取能力,从而提升军事事件抽取的效果。对于军事领域事件抽取的研究,目前主要包括战场元素建模、军事实体事件抽取、作战文书事件等方面。
战场元素建模主要利用传统的方法,沈大川等提出利用本体和规则推理捕获战场“关键事件”的方法[23],构建了战场态势核心本体和领域本体,并基于战场领域本体来抽取出战场“关键事件”,通过建模战场元素的概念并添加相应的约束,结合相关的规则和知识,从而将战场要素及要素间的基本关系聚合成“关键事件”。不同于先前方法将事件论元的抽取视为模式匹配和标注的任务,游飞提出利用常规的神经网络模型对军事武器装备实体识别[3],之后采用Bi-LSTM 网络来识别触发词,结合触发词网络的结果和状态输出,利用单词局部和句子全局的特征,构建一个softmax 分类器输出的前向传播网络,来抽取事件相关论元。将事件触发词和论元的识别视为多分类任务,并利用触发词任务的输出结果来协助事件论元的识别任务,从而充分利用了不同事件类型触发词和论元之间的关系。高鸿博等提出一个双向门控循环单元条件随机场(bi-gated recurrent unit,conditional random field,Bi-GRU- CRF)框架来从创建的百科数据库中进行军事事件触发词和论元的抽取[24],如图5 所示。具体地,首先将BERT 字向量输入Bi-GRU 中提取上下文信息,并利用注意力机制将事件论元信息作为查询(query),Bi-GRU 的输出作为键(key)、值(value),旨在利用实体信息提升事件触发词的抽取效果,最后经过线性变换和CRF 模型得到最后的输出。事件论元的抽取与触发词抽取类似,不同的是其输入段额外添加了装备、任务、单位、战争名称4 种实体的结尾部分词生成的后缀特征,将其与BERT 字向量一起输入用于事件论元的抽取。王学锋等提出一种基于深度学习的作战文书事件抽取方法[25]。由于Bi-LSTM对于长句子的上下文信息具有很强的记忆能力,另外动态字向量(embedding from language models of character,ELMo)采用不同的方式表示汉字语义信息,条件随机场(conditional random field,CRF)可以学习标注的规则,通过利用三者的优势,提出了基于ELMo+Bi-LSTM+CRF 的作战文书事件抽取模,实验结果表明,该方法可以有效地从大规模作战文书文本中抽取事件。采用一系列方法从数据中抽取事件并以作战行动脉络、军事知识图谱、作战过程描述等方式来展示[26],可以应用到问答系统、情报分析、检索系统上等,从而让指挥员更明确地了解作战脉络和演练过程,更全面地实施指挥决策并总结经验教训,同时帮助导演部更及时地掌握演习态势发展并进行讲解与评估。如图6 所示。
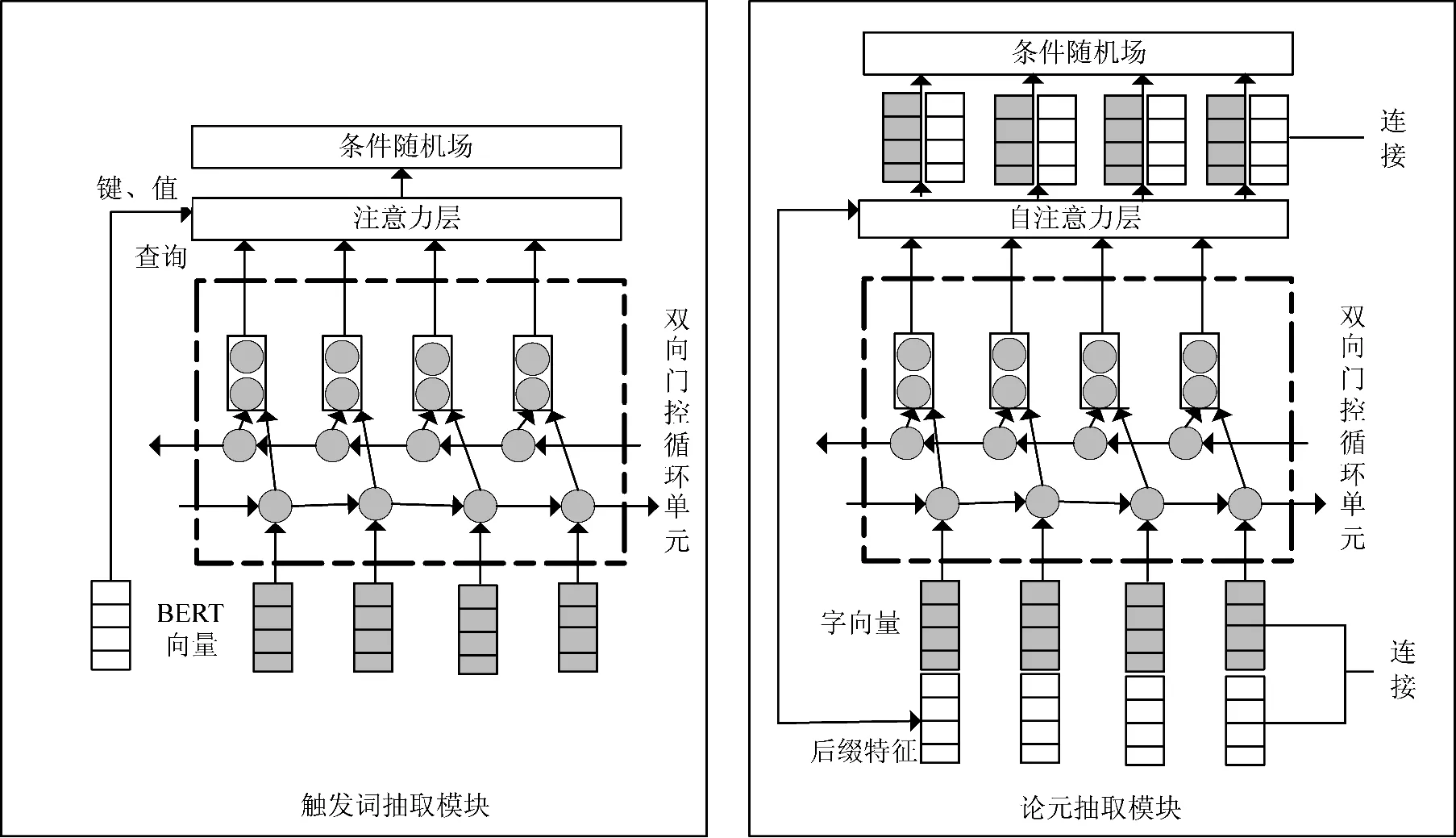
图5 Bi-GRU-CRF 模型框架Fig.5 Model framework of Bi-GRU-CRF
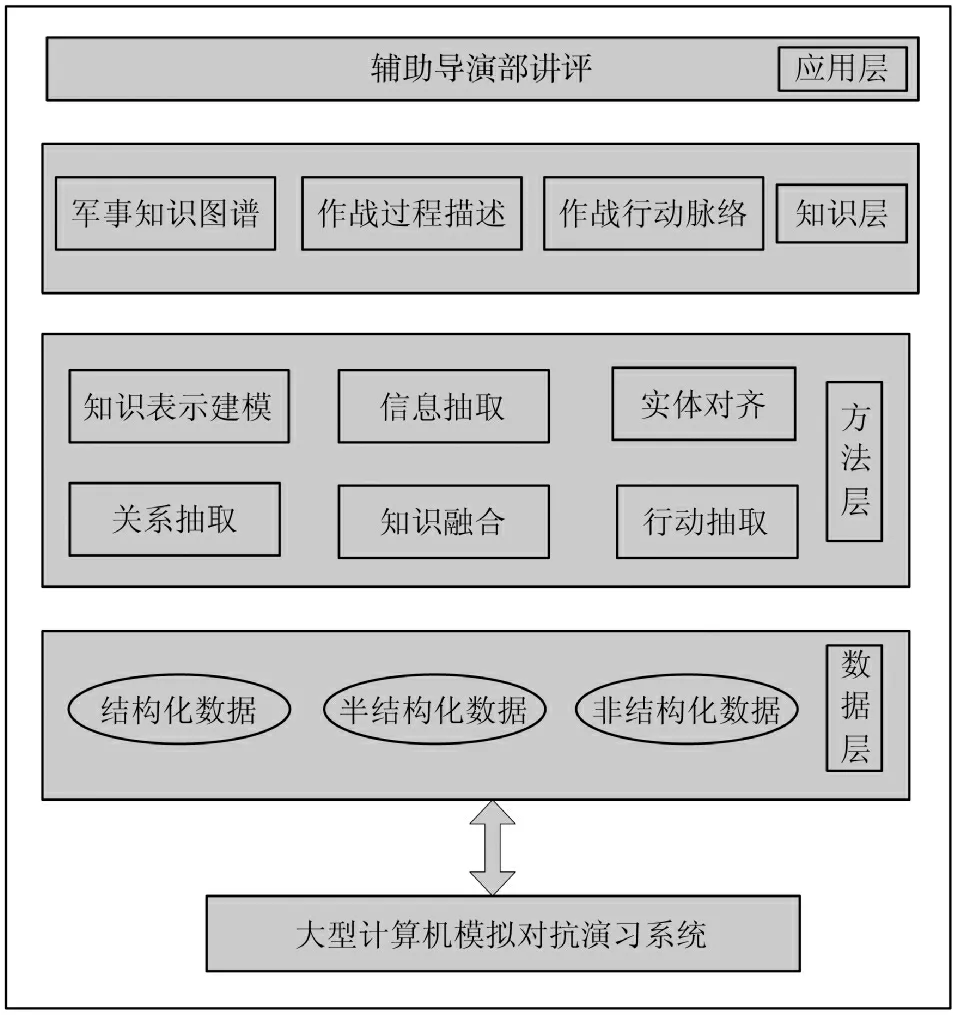
图6 面向辅助演习讲评的事件抽取方法应用框架Fig.6 An application framework of event extraction method for auxiliary exercise evaluation
3.2 迁移学习事件抽取军事应用展望
基于本体、规则、字典等用于军事事件抽取的方法,主要集中在人工设计的模式上,但是设计相应的模式与标注规则耗时耗力,很难扩展。有研究者开始利用基于条件随机场等统计学习的识别方法,将实体识别任务视为序列标注任务,从而避免了制定海量的字典和规则,该方法可以有效地提示实体识别的效果,并进一步进行事件抽取。但是该方式很依赖于特征工程,特征表达会影响事件抽取效果。随着深度学习技术的发展,对于特征的抽取能力得到大幅度提升,事件抽取效果也得到显著改善。
利用深度学习技术进行事件抽取目前面临的最大问题是缺乏高质量标注数据集。深度学习方法对数据的质量和数量要求高,但目前很多领域数据集规模较小且数量不多,特别是军事领域可以获得的公开语料库极其有限,因此,基于深度学习的事件抽取技术在军事领域的应用受到很大限制。
近年来,研究者开始利用迁移学习技术来解决低资源场景下事件抽取的难题,通过设计更鲁棒的迁移学习模型,提升了零样本、少样本的场景下对于事件抽取的效果,并取得显著的成效。但是很少有研究者将迁移学习技术应用到军事事件抽取中,只有少量工作将迁移学习技术用在军事命名实体识别中,如徐建等提出了基于领域迁移和任务迁移相结合的军事文本命名实体识别模型[27]。刘卫平等提出了基于BERT、双向长短期记忆网络(Bi-LSTM)和条件随机场(CRF)的军事命名实体识别框架(BERT-Bi-LSTM-CRF),有效提升了小样本情况下的命名实体识别效果[28]。
军事文本材料中包含的主题有人员和装备的部署情况、部队轨迹动态记录、武器编队相关配置等信息,公开的信息往往具有隐蔽性、保密性、伪装性,很难获得上述原始语料并对其进行注释,而在紧张激烈的战场中可获得的有效样本更是少之又少。因此,在实际场景下通常会面临大规模无标注、低质量的军事文本材料。
此时,将前述通用方法运用到军事领域,很大程度上缓解数据缺乏的问题,并提升事件抽取的效果。其中一种最典型的方式就是采用预训练微调范式。具体地,首先训练预训练语言模型(如具备强大上下文建模能力的BERT 模型及其变体)得到一个通用领域的迁移表示模型,上述策略可视为一个目标军事材料自适应的预处理步骤,其得到的模型具备强大的军事文本材料识别能力,当面对大量无标注以及质量低下的军事文本材料时,可迅速准确地抽取出重要的信息。
另外,还可以利用已掌握的军事相关数据或易获得的大规模语料(如维基百科、推特等),使模型提前学习得到与军事主题有关的源语言/领域的训练字向量,采用跨语言/跨领域迁移的方式,将其迁移运用到目标语言或特定的军事领域中(如武器装备实体识别),来精确判断目标部队的装备实力。
此外,还可以采用多任务学习的方式抽取战场关键事件,对多个与事件抽取的子任务(如关系抽取)的模型参数进行联合学习,挖掘其中的共享信息,来判断部队实力损耗、飞机航油量消耗的情况以及敌方坦克是否进入我方攻击范围,同时上述方法还可以在复杂战场环境里快速、精准、高效地对多种敌方目标进行侦察判别,并且将获取的目标特征信息反馈给我方其他装备。通过对战场关键事件抽取,可动态更新战场态势,有效提升作战效能。
通过迁移学习技术能够有效地解决军事领域事件抽取面临的训练数据缺乏的难题。因此,迁移学习技术用在军事事件抽取中必将是未来研究的热点之一。
4 问题与挑战
迁移学习用于小样本事件抽取具有巨大的潜力,也能增强现有学习算法。然而,和迁移学习相关的一些问题尚有待更多研究和探索。迁移学习除了集中在迁移什么、何时迁移、如何迁移等问题之外,负迁移和迁移界限是当前迁移学习应用在小样本事件抽取中面临的主要挑战。
负迁移挑战:是指从源领域(任务)迁移知识到目标领域(任务)没有带来任何改善,反而导致目标任务的总体表现下降的情况。在这些情况下,迁移学习反而会影响事件抽取效果。出现负迁移的原因有很多,如源任务和目标任务关联不大、迁移方法使用不当,导致没有很好地利用源任务和目标任务之间的关系等。特别是利用迁移学习技术进行军事事件抽取时,要保证所利用的源材料的质量(避免引入过多噪声)以及与目标军事材料的相关性,否则会导致抽取的军事事件质量低下甚至出现错误,将会对军方造成不可估量的损失,因此,如何避免负迁移或降低负迁移带来的影响是未来研究的热点。
迁移界限的估量:量化迁移学习过程中影响迁移质量和可行性的迁移量也很重要。特别是在军事领域中,对抽取事件的质量要求很高,抽取的关键事件会进一步影响军事指挥决策。因此,如何设计有效措施,来分析迁移学习和测量任务相关性的特定理论界限来估计迁移量,从而最大限度地提升使用迁移学习技术进行事件抽取的效果,这也是在未来值得探索的。
5 结论
本文全面梳理了基于迁移学习小样本事件抽取的技术方法及军事应用。通过梳理事件抽取技术的起源与发展,介绍了基于迁移学习小样本事件抽取的研究背景及通用的技术方法,之后重点对当前军事研究现状进行分析并对通用技术方法在军事上的应用作了展望,旨在利用通用的迁移学习技术来缓解军事领域事件抽取面临的难题,最后,结合具体的军事领域应用,阐述了基于迁移学习技术进行事件抽取面临的困难与挑战,旨在推动军事领域事件抽取技术的研究与发展。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
青年生活(2019年23期)2019-09-10
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
中共南宁市委党校学报(2015年4期)2015-02-28
中国音乐教育(2014年7期)2014-02-06
杭州科技(2013年5期)2013-03-11
军事文摘(2009年9期)2009-07-30
全国新书目(2009年24期)2009-07-17
