
基于深度强化学习的智能对手自主空战决策技术*
2023-11-20 10:59杨凯达杨兴昊
火力与指挥控制 2023年10期
杨凯达,杨兴昊,刘 钊
(1.解放军95808 部队,甘肃 酒泉 735006;2.中国航空研究院,北京 100012)
0 引言
随着航空武器装备的发展,体系对抗逐渐成为未来战争模式的必然选择,要求体系对抗训练具备更加复杂、更加真实的训练场景环境[1]。基于“真实-虚拟-构造”(live virtual construction,LVC)集成框架的“体系作战”训练系统,通过构建一个能在实兵、仿真兵力及虚拟战场之间进行互操作的集成环境,满足体系对抗需求,推进军事训练转型升级。
基于LVC 的空战训练是“体系作战”训练系统的重要组成部分,纵观空战训练模式的演变,已经从20 世纪70 年代的“技术体验型”训练,发展到20世纪末的“战术对抗型”训练,再演变成21 世纪的“联合作战”训练和“分布式任务”训练[2]。更大程度上使用虚拟和构造性的模拟资源,集成真实的飞机、人员在环模拟器(虚拟)和计算机生成的兵力(构造),模拟真实复杂的空战场景来提高飞行员战术技术水平,创新战术战法。
随着人工智能的发展,智能决策系统在航空领域的应用逐步深入,利用智能对手协助飞行员开展对抗训练,有助于提高训练效益、节约训练成本、降低飞行风险。自主空战决策是智能对手战术模拟的核心技术,开发具备自主空战决策能力的智能体,将其作为虚拟敌机或构造性资源应用于LVC 空战训练,可促进受训人员在空战对抗模拟训练中有效提升战术水平[3]。
1 智能对手算法技术
1.1 自主空战决策技术发展现状
第3 代、第4 代先进战斗机的机载传感器、电子战系统、中/远距空空导弹及火控系统发展迅猛,空战态势感知、态势评估、认知资源管理、战术决策、在线求解、编队协同等过程,在时间复杂度和空间复杂度呈爆炸式增长[4],空战对抗的博弈强对抗性、信息不完整性,使得在高维连续状态空间、动作空间的自主空战决策成为博弈对抗领域的难题。
20 世纪50 年代以来美国持续开展自主空战决策算法研究,然而受限于当时人工智能发展水平,自主空战决策算法研究未能获取突破性进展。早期采用基于规则、基于专家系统的自主空战决策算法战术创新不足、适应性差[5]。近年来随着深度学习和强化学习技术的发展,美军取得了突破性进展,典型的有“ALPHA”中远距空战和空战演进项目(air combat evolution,ACE)。
2016 年,基于遗传模糊树(genetic fuzzy tree,GFT)算法的小编队中远距自主空战决策智能体阿尔法(Alpha AI)成功地在战术模拟对抗上击败美空军战术教官吉恩·李上校。阿尔法运用遗传算法学习训练战术规则具有战术自主学习演进的特性,解决了连续实时决策的高维复杂问题;其核心采用遗传模糊树算法,通过类人的模糊逻辑思维,能够生成超视距空战中主动攻击、机动规避等攻防态势下的飞机航路规划、导弹攻击、武器选择等战术策略[6]。
作为人工智能求解空中对抗博弈问题领域的里程碑成果,“阿尔法空战”系统成功将演化计算应用于求解复杂空中对抗问题。利用智能体扮演空战对手,可在博弈对抗仿真环境下训练飞行员战术应变能力,对策略参数研究作出了有力贡献。但该系统的初始策略结构依赖人类先验知识建模,受限于人类对空战机理的认识程度,智能体的解空间搜索能力无法得到充分发挥[5]。
2020 年,基于端到端深度强化学习的空战智能体Falco 在高保真F-16 模拟器的近距空战狗斗人机对抗中以5∶0 战胜资深飞行员教官。该赛事是美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)启动的ACE 计划的一部分,寻求建立和增强飞行员对无人空战系统自主性的信任,并最终以全尺寸飞机的实际飞行演习达到技术巅峰。Falco 采用完全不依赖先验知识、端到端的深度强化学习技术,成为了机机对抗和人机对抗的冠军智能体。空战演进项目的算法在2022年底取得了实机试飞验证的突破,在VISTA X-62A可变稳定性飞行模拟技术验证机上开展了8 个架次科研试飞。
参加阿尔法狗斗试验(Alpha Dogfight Trials,ADT)挑战赛的8 个团队采用从基于规则的系统到完全端到端的机器学习架构,其中,洛克希德-马丁公司(LM)将分层强化学习结构与最大熵强化学习相结合,通过奖励塑造整合专家知识,实现策略模块化,在决赛中取得了第2 名。
传统自主空战决策的应用研究通过将飞机的动作空战抽象为高级战术机动动作,或依赖于低逼真度的仿真环境来降低算法学习难度。针对该问题,本文将立高保真六自由度战斗机仿真模型,构造高维连续状态机动作空间,研究基于深度强化学习自主近距格斗空战智能体构建与训练方法。
1.2 深度强化学习技术
1.2.1 深度强化学习


如果使用函数近似来表示策略π,并且函数近似是深度神经网络,则这种强化学习称为深度强化学习(deep reinforcement learning,DRL)。在强化学习中有不同类型的DNN(deep neural networks),卷积神经网络(convolutional neural network,CNN)适合图像数据学习有用,循环神经网络(recurrent neural network,RNN)或长短时记忆网络(long short-term memory,LSTM)适合处理序列数据,自注意力机制的Transformer 则擅长处理结构化信息[8]。
总之,强化学习智能体关注的是在给定环境的当前状态下,学习采取什么行动来最大化数值奖励信号。奖励信号是由环境提供的,学习是通过试错的迭代方式进行的。强化学习的主要挑战之一是权衡策略的探索(exploration)和利用(exploitation)。为了最大化奖励,智能体应该通过选择导致高奖励的动作来利用它已经学习到的东西。然而,为了发现最优的动作,智能体必须承担风险,探索新的行动,这些行动可能比当前最有价值的行动带来更高的回报。
1.2.2 最大熵学习

1.2.3 SAC 算法
最大熵强化学习算法SAC(soft actor critic)是一种模型无关(model-free)的、离线策略优化(off-policy)的强化学习方法,核心思想结合了策略梯度方法(如DDPG(deep deterministic policy gradient),DQN(deep Q network)等)与熵正则化(entropy regularization)的优点,以实现更稳定的学习过程和更好的探索性能。其主要组成部分有两个:一个是策略网络(actor),负责输出动作;另一个是价值网络(critic),负责评估策略的好坏。
如式(1)所示,SAC 策略网络、价值网络的训练目标是最大化预期累积奖励和特定状态下的动作熵。价值网络是软Q 函数,根据Bellman 方程,表示为:
其中,p 表示状态转移概率;软值函数由Q 函数参数化:
训练软Q 函数以最小化以下目标函数,该目标函数由预测值与观测值之间的均方误差给出:
其中,
D 表示经验回放;V 是目标值函数。更新策略以最小化策略与指数化状态- 动作值函数之间的KL-散度,可以表示为:
SAC 算法结构及流程如下页图1 所示。
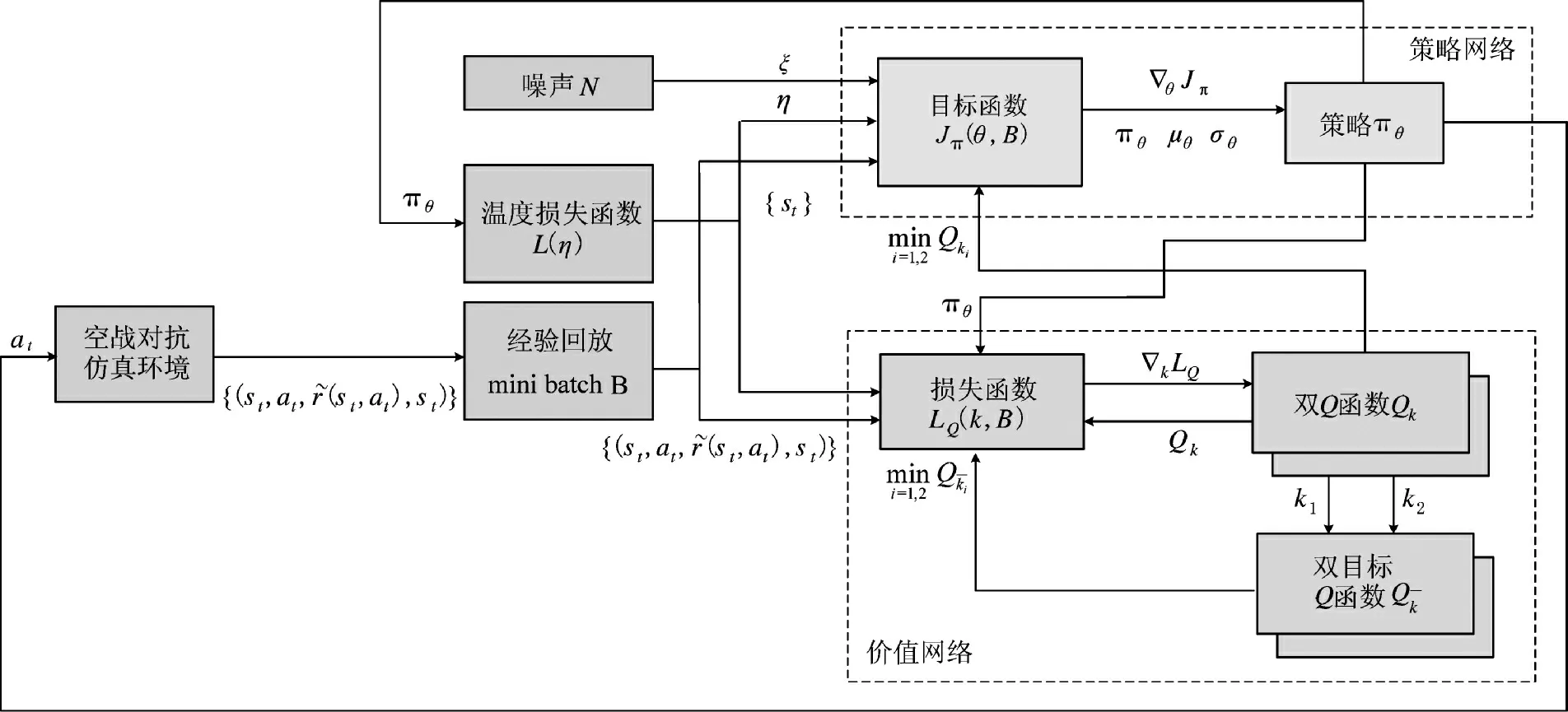
图1 SAC 算法模型结构Fig.1 SAC algorithm model structure
1.2.4 自博弈训练
自博弈是通过与自己或历史版本的策略对抗博弈来提升智能体的决策水平,从完美信息博弈的棋类人工智能Alpha GO、Alpha Zero 到非完美信息博弈的星际争霸2 人工智能Alpha Star,均因为采用自博弈技术而取得了显著进展。
现实世界的博弈具有非传递性博弈和循环策略,自博弈不能产生能很好地泛化到不同类型对手的智能体,自博弈训练的智能体只与自己竞争,导致策略经常陷入局部最优,无法泛化到不同类型的对手。
1.2.5 多智能体种群联盟训练
谷歌DeepMind 在星际争霸2 的人工智能AlphaStar 的强化学习中为了增加策略的多样性和鲁棒性,引入了基于种群联盟训练,这是一种跨各种任务进行超参数调优的有效方法。它并行地训练具有不同超参数的模型族,每个训练过程周期性地交互以进行开发和探索。性能较差的模型可以直接利用(复制)性能较好的模型参数,同时通过干扰探索一个新的超参数用于后续的训练。
1.2.6 自博弈与联盟训练
本文对自博弈与联盟训练进行改进,将自博弈与联盟训练方法相结合对智能体进行训练。首先采用自博弈方法获得用于联盟训练的初始智能体,随后采用联盟训练方法进一步提高智能体性能,获得最终空战智能体。自博弈过程中保留两代智能体,即最新版的空战智能体与上一代版本的空战智能体,训练过程中智能体以最新版空战智能体为权重,其训练对手在两代智能体中随机选择,直至最新版空战智能体对历史版本智能体的胜率高于70%后,将训练方式修改为联盟训练。以最新版空战智能体权重作为初始化权重,生成一个主智能体、一个主利用者和一个联盟利用者,主智能体与主利用者对抗以更新主智能体权重,主利用者与联盟利用者对抗以更新主利用者权重,训练一定轮次后将主智能体权重赋值给联盟利用者,直至主智能体对抗主利用者的胜率高于80%时完成训练。
2 仿真环境与算法设计
2.1 一对一近距格斗空战对抗仿真系统
近距格斗是空战的最基本形式,主要依靠雷达、头盔或者目视发现敌机,使用近距空空导弹和航炮进行尾后攻击,并作出复杂的机动动作,进行攻击和规避。典型一对一近距空战流程包括目标探测与跟踪、机动决策、火控解算与武器发射、武器交战与评估。
本文建立的近距空战仿真系统如图2 所示,平台分系统主要对飞机空气动力特性、发动机特性进行仿真,解算飞机的六自由度非线性全量运动方程并控制飞行机动决策;传感器分系统产生的数据主要为强化学习的观察空间;武器分系统主要用于飞机武器发射与命中的仿真与结算。
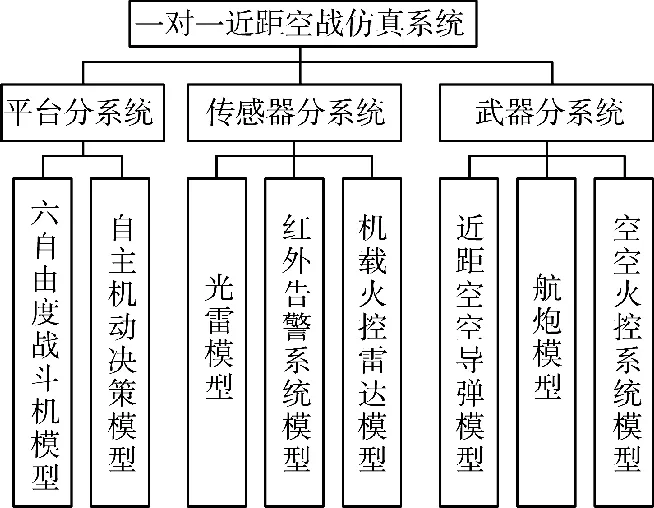
图2 近距空战仿真系统模型Fig.2 Close-range air combat simulation system model
2.2 基于SAC 算法的智能体设计
2.2.1 智能空战对抗框架
本文建立的一对一近距格斗智能空战对抗框架如图3 所示。红蓝空战对抗智能体处理交战状态,输出战斗机的机动控制、雷达使用和武器开关。环境由状态转移模型、终止条件和奖励函数模块组成。
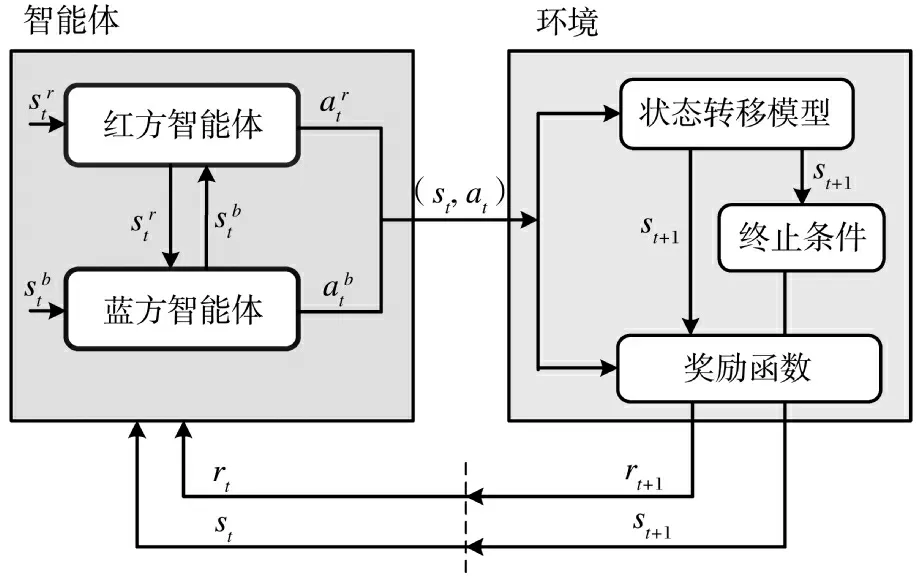
图3 一对一空战决策框架Fig.3 One-to-one air combat decision-making framework
仿真时刻t 环境给出红蓝对抗平台、武器和传感器的仿真参数的观测状态st和奖励值rt,红蓝空战对抗智能体根据状态st、奖励rt预测动作at传递给环境,状态转移模型即近距空战仿真系统,根据智能体当前时刻的动作at和状态st推进到下一仿真时刻的状态st+1。同时,终止函数判断是否达到仿真终止状态,奖励函数根据当前时刻动作at,状态st及下一时刻的状态st+1,给出当前决策的奖励值rt+1。环境将状态st+1、奖励rt+1传递给智能体完成交互。
2.2.2 观测空间
环境的状态空间S,即近距空战仿真系统仿真输出,由红蓝双方仿真飞机的飞行参数、传感器及武器系统的输出参数组成。
仿真飞机飞行参数:本机经度、纬度、高度、三向速度、北天东坐标系加速度、机体系加速度、真空速、马赫数、法向过载、偏航角、俯仰角、滚转角、攻角、侧滑角、偏流角、偏航角速度、俯仰角速度、滚转角速度等。
传感器输出参数:目标距离、方位角、俯仰角、三向速度、三向加速度、目标径向速度。
火控系统输出参数:导弹的最大攻击距离、导弹的不可逃逸攻击距离、导弹的最小攻击距离、目标进入导弹最大攻击距离标志、目标进入导弹不可逃逸攻击距离、武器准备好信号。
告警系统输出:告警目标方位和俯仰。
2.2.3 动作空间
智能体的动作空间A 由仿真飞机的操纵杆控制量、雷达使用和武器开关指令组成,包括纵向杆位移、油门杆位移、脚蹬位移和横向杆位移、雷达开关机操作、天线俯仰扫描行数、方位扫描范围、空空导弹发射指令。
2.2.4 空战奖励设计
1)角度优势
在近距空战中使用视界角δAA和天线偏转角δATA来衡量空战双方的角度优势。视界角δAA为红方飞行器速度矢量与视线的夹角,天线偏转角δATA为蓝方飞行器速度矢量与视线的夹角。根据二者关系设计角度优势奖励函数为:
2)距离优势
为保证训练过程中智能体向对手接近,设置距离奖励,当智能体接近敌方时给予一定奖励,距离优势奖励设置为:
式中,Dt为t 时刻红蓝双方距离;Dt-1为t-1 时刻红蓝双方距离。
3)能量优势
空战过程中的能量包括势能和动能,势能由高度差体现,动能由速度差体现,能量优势奖励设置为:
式中,ΔHt为t 时刻红蓝双方高度差;ΔVt为t 时刻红蓝双方速度差。
4)击杀奖励
当飞行器击杀敌方飞行器,则给予奖励,击杀奖励设置为:
式中,Tkill为二元量,当完成击杀时,其值为1,否则为0。
2.3 算法训练
本文基于Ray 搭建强化学习训练环境,采用SAC 算法进行自博弈训练,相关超参数如表1 所示。训练过程中每架飞行器装备4 枚近距导弹,当满足火控系统发射条件时,即进行导弹发射,导弹命中,即进行胜负判定。

表1 SAC 算法部分超参数Table 1 Some hyperparameters of SAC algorithm
3 仿真结果分析
训练完成后得到空战智能体,将空战智能体依次与专家系统智能体、历史版本空战智能体、空战智能体本身进行对抗。随机设置战场态势,红方为空战智能体,蓝方依次改变对手,红蓝双方的飞行轨迹如下页图4 所示,飞行轨迹俯视图如图5 所示。
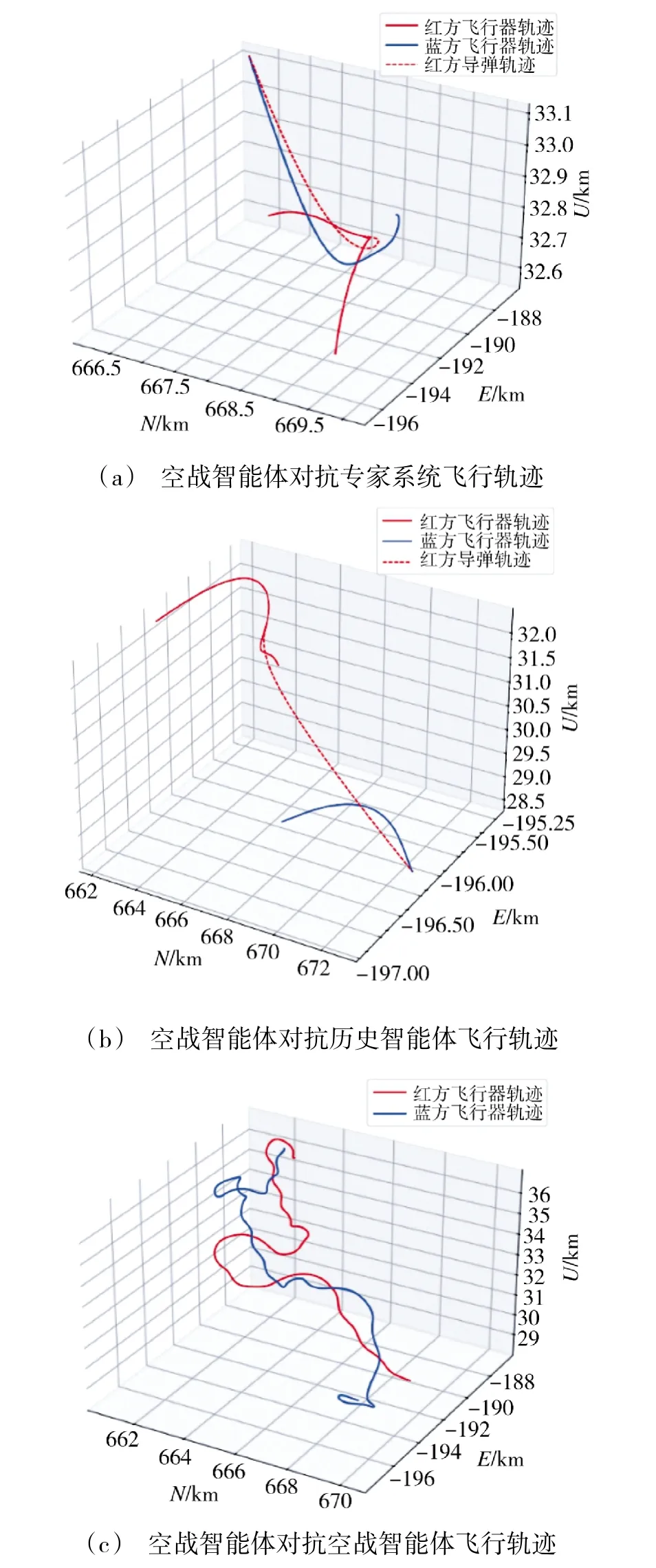
图4 空战对抗飞行轨迹Fig.4 Air combat countermeasure flight path
由图4(a)、图5(a)态势可知,训练所得空战智能体能够战胜专家系统,仿真开始后空战智能体能够迅速机动占位,获得有利态势并形成导弹发射条件,完成对专家系统的击杀,表明空战智能体相较于专家系统在空战训练过程中具有更好的对抗效果。由图4(b)、图5(b)态势可知,训练所得空战智能体能够战胜历史版本智能体,仿真过程与对抗专家系统的仿真过程类似,新版本空战智能体能够迅速完成对历史版本智能体的击杀,表明训练所得空战智能体能够通过训练不断演化,以保持对飞行员的持续训练。由图4(c)、图5(c)态势可知,采用相同版本空战智能体进行对抗时双方保持机动,但在仿真结束前尚未形成导弹发射条件,且机动过程中轨迹波动较大,表明了空战智能体训练的策略具有稳定性,当策略相同时容易产生平局现象,后续可通过进一步训练进行改进。仿真结果表明,训练所得的空战智能体能够实现空中对抗训练的要求,且能够战胜专家系统与历史版本智能体,从而保证训练效果的稳定提升。
4 结论
本文对基于深度强化学习技术的智能对手自主空战技术展开了研究,仿真对抗实验表明,采用多智能体种群联盟训练方法,可实现一对一近距格斗空战机动决策及攻击引导,为开展智能博弈驱动的空战战术训练奠定了技术基础,支持飞行员在地面战术模拟器引入真实的假想敌模拟对抗训练。
1)总结分析自主空战决策技术发展现状,建立了深度强化学习技术在一对一空战的应用框架,探讨了最大熵强化学习及其代表算法SAC 在平衡策略探索与利用方面的优势,引入自博弈和多智能体联盟训练技巧增强策略的鲁棒性。
2)针对一对一近距格斗空战对抗场景建立了以六自由度飞机仿真模型为主的仿真系统,构建了红蓝空战对抗博弈框架,确定动作空间、观测空间并基于角度、距离、能量和击杀目标等因素,构造强化学习的过程奖励函数,设计SAC 算法超参数开展算法学习。
3)基于深度强化学习的自主空战决策具有强博弈对抗性,不依赖先验知识即可训练达到专业飞行员的战术水平,一定程度满足实虚对抗的训练要求,但由于神经网络的不可解释性,空战智能体不可避免地因低级战术行为降低可用性,需进一步研究提升算法的拟人化水平,早日大规模应用于空战模拟训练。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
北京航空航天大学学报(2022年6期)2022-07-02
小哥白尼(军事科学)(2022年1期)2022-04-26
疯狂英语·新策略(2019年2期)2019-07-28
军营文化天地(2017年6期)2017-06-28
物理实验(2017年2期)2017-03-21
宠物世界·猫迷(2016年3期)2016-04-23
百科探秘·航空航天(2015年10期)2015-11-07
同煤科技(2015年4期)2015-08-21
军事历史(1999年3期)1999-08-20
