
跨语种多模态信息分拣技术与应用*
2023-11-20 10:59赵勤博范昕煜魏才越
火力与指挥控制 2023年10期
赵勤博,邹 烨,栾 真,范昕煜,张 峰,魏才越
(1.北京计算机技术与应用研究所,北京 100854;2.国防科技大学大数据与决策实验室,长沙 410073;3.解放军31201 部队,广州 510000;4.国防科技大学系统工程学院,长沙 410073)
0 引言
信息分拣技术是指从大规模、复杂多样且散乱的数据中,根据一定的规则和标准,对信息进行分类、筛选和整理。在大数据时代,由于数据量庞大且多样化,高价值信息的挖掘方法可以提升信息获取的效率,信息分拣变得尤为重要。在军事领域,信息分拣技术在战场态势感知、社交媒体监测、多语种情报分析、恐怖主义情报分析等多种应用场景中都有着重要的价值,能够帮助情报人员从跨语种、跨模态的情报源中快速提取和分类关键信息,并自动对情报信息进行分拣和整理,为指挥员进行战略和战术决策提供重要参考依据。
大数据时代,随着社交网络和自媒体的兴起,互联网上涌现出大量的数据。这些海量而多样的数据为跨语种和跨模态的信息分拣研究提供了丰富的语料,同时也对跨语种多模态信息分拣技术提出了更为严峻的挑战。
随着国际局势日趋紧张以及反恐形势愈加严峻,军事任务呈多样化发展,军事分拣任务的复杂程度也显著增加。情报人员为获取有效信息,需要收集和分析不同形式的跨语种情报。然而,传统信息分拣研究主要集中在单一语种上,无法处理跨语种的语义信息。因此,如何将跨语种情报快速归类,并理解多模态的复杂信息,以及最终如何用于不同任务场景,是信息分拣技术研究当前面临的重要难题。
多样化军事任务催生了海量的多语种数据,亟需进行多语种数据的信息分拣。语言问题与军事安全紧密相关,语言识别理解能力的缺失会妨害军队遂行传统安全任务和非传统安全任务的能力,进而危害军事安全。美军在20 世纪几次重大行动中都遭遇了外语能力缺失影响军事能力的问题。另外,不同语种信息的结构与表达形式差异巨大,缺乏针对性的研究,使得包括算法模型、分析方法、软件工具、应用领域、政策环境等关键要素均比较缺乏。因此,亟需开展跨语种的信息分拣技术研究,将多种语言融入到信息分拣系统中,通过跨语种的语义表示空间辅助相关分拣任务。
信息传播形式的不断演化催生了海量的多模态数据,亟需进行多模态数据的信息分拣。“9·11”事件之后美国就开始利用大数据反恐,2013 年美国反恐局长在国会作证时提到利用语音通话、视频监控等多模态数据,成功地挫败了50 多起恐怖事件。海量、多样的数据为信息分拣研究提供了更多参考依据,但也对信息分拣的研究手段提出了更为严峻的考验。随着互联网迅速发展,网络上数据极速膨胀,从海量多模态数据中获取有效信息变得愈发困难,如何从互联网时代的海量多模态开源情报中掌握追踪多种类型的信息源、如何对组织更加复杂的信息进行分拣、如何将分散的情报数据转化为可用于指挥决策的知识,都是信息分拣研究的难点。当前情报研究工作对语音、图像、视频等情报数据的处理与分析手段不足,亟需跨模态分析技术支持多种类型的信息源识别,并能够对复杂信息进行理解分析,辅助相关分拣任务。
复杂的军事需求催生了多类分拣任务,亟需进行多任务学习的信息分拣。随着多样化的场景需求增多,面临着不同场景的分拣需求。面对多种分拣任务,由于其专业性较强,质量要求较高。针对特定任务需求定制化开发分拣系统的成本过高,采用多任务学习的方式,可以对同种类型的分拣同时训练分拣模型,多样的分拣任务为信息分拣模型提供了更多参考依据,使得分拣效果更加准确,因此,亟需开展多任务学习的信息分拣技术研究,将多类分拣任务融入到信息分拣系统中,通过多任务学习辅助相关分拣任务。
本文主要贡献包括以下3 个方面:
1)针对跨语种的文本形式的数据,基于低资源场景下的跨语种词嵌入模型,解决低资源场景下跨语种模型的预训练问题;基于跨语种词嵌入表示模型的信息分拣,解决多标签分类的多尺度信息抽取、多标签的分类等问题。
2)针对文本、语音形式的数据,构建跨模态的表示学习技术,基于全词掩码预训练语言模型的文本表征技术,解决中文文本差异性大,难以学习词语粒度语义的问题;基于自监督的语音特征表示技术,解决数据复杂多变,标注成本高的问题;基于多模态层次融合技术,解决跨模态信息语义对齐和异构融合的问题;基于跨模态知识迁移技术,解决多模态融合过度依赖平行语义数据的问题;最终形成跨模态的信息表征。
3)针对多种任务形式,构建信息分拣多任务学习模式,本文基于主-辅分类器的多任务学习技术,解决多个任务联合学习的共享参数优化和集成学习的问题;基于迁移学习的多任务学习技术,解决不同任务之间联合训练收敛的问题;最终形成多任务学习的信息分拣方法。
1 相关工作
1.1 跨语种表示学习研究现状
跨语种表示学习是自然语言处理领域的一个重要研究方向,旨在通过机器学习方法将不同语言之间的语义信息进行映射和对齐,实现跨语种的语义表示转换。这一领域的研究对于机器翻译、跨语种信息检索、多语种文本分类等任务具有重要的应用价值,在过去几年中,跨语种表示学习已经取得了许多重要的进展,这些方法可以归结为以下3类:基于词典或知识图谱的监督学习方法、基于无监督学习和自监督学习的方法和基于预训练模型的方法。
基于词典或知识图谱的监督学习方法依赖于已知的语言对齐信息,例如双语词典或跨语种知识图谱。通过利用这些资源,可以将源语言和目标语言之间的词汇进行对齐,并将对齐的词汇用作监督信号进行模型训练。2013 年,MIKOLOV 等探索了基于监督学习的方法,利用语言之间的相似性来改进机器翻译任务,通过构建和利用双语词典实现源语言和目标语言之间的词汇对齐[1]。
基于无监督学习和自监督学习的方法利用大规模的单语语料进行训练,不需要平行语料或词典等外部资源,而是通过设计自监督任务来学习语义表示。例如,可以使用自编码器、语言模型、机器翻译等任务来训练模型,使得源语言和目标语言之间的语义信息得到编码和解码。LAMPLE 等提出了一种自监督学习方法,通过在大规模单语语料上进行预训练,使用自编码器和掩码语言模型等任务来学习源语言和目标语言之间的语义表示,并实现无监督机器翻译[2];CONNEAU 等提出了一种无监督学习方法,在大规模数据上学习跨语种的语义表示,通过自编码器和翻译模型实现源语言和目标语言之间的对齐[3]。
基于预训练模型的方法通过在大规模单语语料上进行预训练,可以学习通用的语义表示。如BERT(bidirectional encoder representations from transformers)和GPT(generative pre-trained transformer)等代表性的预训练模型可以进一步微调用于特定的跨语种任务[4-5],如机器翻译、跨语种情感分析等。PIRES 等提出了一种多语种的预训练模型mBERT,它在单个模型中包含了104 种不同语言的参数[6]。该模型基于BERT 架构,通过在大规模的多语种文本数据上进行预训练,学习通用的语义表示。
1.2 跨模态表示学习研究现状
跨模态表示学习是指在不同的模态数据(如图像、文本、语音等)之间进行学习和建模,以便实现模态之间的语义对齐和转换。这一领域的研究对于图像标注、图像检索、多模态机器翻译等任务具有重要的应用价值。近些年,跨模态表示学习已经取得了显著的进展。这些方法可以归结为:基于深度神经网络的方法、基于注意力机制的方法、基于生成对抗网络的方法[7-8]。
基于深度神经网络的方法通常使用卷积神经网络(CNN)或循环神经网络(RNN)等模型来对图像或文本数据进行特征提取和表示学习,然后通过将不同模态的特征进行对齐和融合学习到模态之间的共享表示。KARPATHY 等提出了基于深度卷积神经网络和循环神经网络的图像描述生成模型,通过将图像编码和文本解码的过程进行协同训练,实现了图像和描述之间的语义对齐和生成[9];JIANG 等提出了一种基于深度神经网络的跨模态哈希方法,通过学习图像和文本之间的共享表示,并使用哈希函数将它们映射到二进制码,实现了高效的图像和文本检索[10]。
基于注意力机制的方法通过计算不同模态之间的注意力权重,将注意力集中在模态之间的相关信息上,例如,可以使用视觉注意力机制将图像的重要区域与文本描述中的关键词对应起来,这样可以实现模态之间的语义对齐和关联建模。YOU 等提出了一种基于注意力机制的图像描述生成模型,通过使用语义注意力权重,将图像的重要区域与生成的描述关联起来,并生成更准确和相关的图像描述[11]。NAM 等引入了双重注意力机制,用于多模态推理和匹配任务。通过同时对图像和文本进行注意力建模,实现了更好的模态对齐和语义匹配[12]。
基于生成对抗网络的方法通过训练生成器和判别器的对抗过程,可以学习到模态之间的映射和转换关系。GAN 可以用于生成逼真的模态数据,例如从文本生成图像或从图像生成文本。ZHANG 等提出了StackGAN++模型,通过堆叠多个生成器和判别器,实现了从文本描述到逼真图像的合成,生成更高分辨率和更真实的图像结果[13]。
1.3 多任务表示学习研究现状
多任务表示学习是指通过共享模型参数来同时学习多个相关任务,以提高模型的泛化能力和效果。在过去几年中,多任务表示学习已经成为机器学习和深度学习领域的热门研究方向,主要分为共享参数、元学习(Meta-Learning)、生成模型三大研究路径。
基于共享参数的多任务学习方法通过在深度神经网络中共享部分或全部的模型参数,同时训练多个任务,共享参数可以捕捉任务之间的共享信息和特征,从而提高模型的泛化能力,并通过任务权重或任务关联矩阵来控制不同任务之间的重要性和关联性。SØGAARD 等提出了利用低级辅助任务来帮助视觉-语言理解的深度多任务学习方法,通过同时训练图像分类、文本生成等任务,提高了模型在视觉和语言领域的表现[14]。
基于元学习(Meta-Learning)的多任务学习方法充分挖掘元学习,可以帮助模型在面对新任务时更快地进行学习和适应的特点,使其在多任务学习中可以学习到任务之间的共享知识,并利用这些知识来快速适应新任务。FINN 等提出了一种模型无关的元学习方法,通过在多个任务上进行迭代训练,学习到任务之间的共享参数和优化策略,从而能够在面对新任务时快速进行适应和学习[15]。
基于生成模型的多任务学习方法通过引入生成模型来进行多任务学习,生成模型可以学习到多个任务之间的关联和共享表示,进而生成具有多模态特性的数据。LIU 等提出了一种基于生成对抗网络的多任务学习方法,通过同时训练多个文本分类任务,并使用生成模型来促进任务之间的信息共享和互补[16]。
1.4 面临的挑战
目前,对于文本和语音的信息分拣模型,国内外均采取了多条技术路线在各自领域开展了部分技术研究,但在跨语种跨模态信息分拣技术上,国内外仍处于研究阶段,还未形成成熟稳定的模型。针对多样化任务的多语种、多模态数据,实现对同一类别体系下不同语种、不同模态的信息分拣,充分发挥多语种信息的价值,就当前的国内外相关技术现状和发展趋势,依然面临一系列的技术挑战:
1)跨语种的信息分拣技术。由于涉外多样化军事任务的增加和国内反恐形势的变化,信息分拣技术需要保障的语种数量大大增多,但大多分拣模型只应用于单一的语言嵌入空间,与迅速增长的信息分拣保障需求相比,单一语言的分拣技术无法实现对多类语言在同一语义空间进行文本的表示学习,难以获得跨语种的文本语义信息。
2)跨模态的信息分拣技术。单模态的信息分拣方法缺乏对信息的理解能力,鲁棒性较差,单个模态的模型输入也难以有效分析军事场景中越来越丰富的多模态数据。但现有的分拣技术很少考虑多模态场景,大多数分拣系统仅从文本角度对信息进行分拣,如何使用各模态上先进的特征提取器提取特征向量,再通过特征融合方法构造整体的语义向量是一项挑战。
3)多任务的信息分拣技术。多任务学习方法共享相关任务之间的表征,可以使模型学习多个任务的表征信息,但这些信息中也同时包含各个任务的噪声信息,通过对这些信息进行学习可以在一定程度上抵消单个任务的噪声。由于跨语种、多模态信息分拣任务的复杂性,多任务学习中需要考虑各个任务之间的相互作用,以提升信息分拣的效果。
2 研究方法
2.1 总体方案
跨语种多模态信息分拣技术总体方案如图1所示,主要包括“跨语种词嵌入表示学习技术”、“跨模态表示学习技术”和“基于多任务学习的信息分拣技术”3 部分组成。

图1 跨语种跨模态信息分拣技术总体方案Fig.1 Overall scheme for cross-language cross-modal information sorting technology
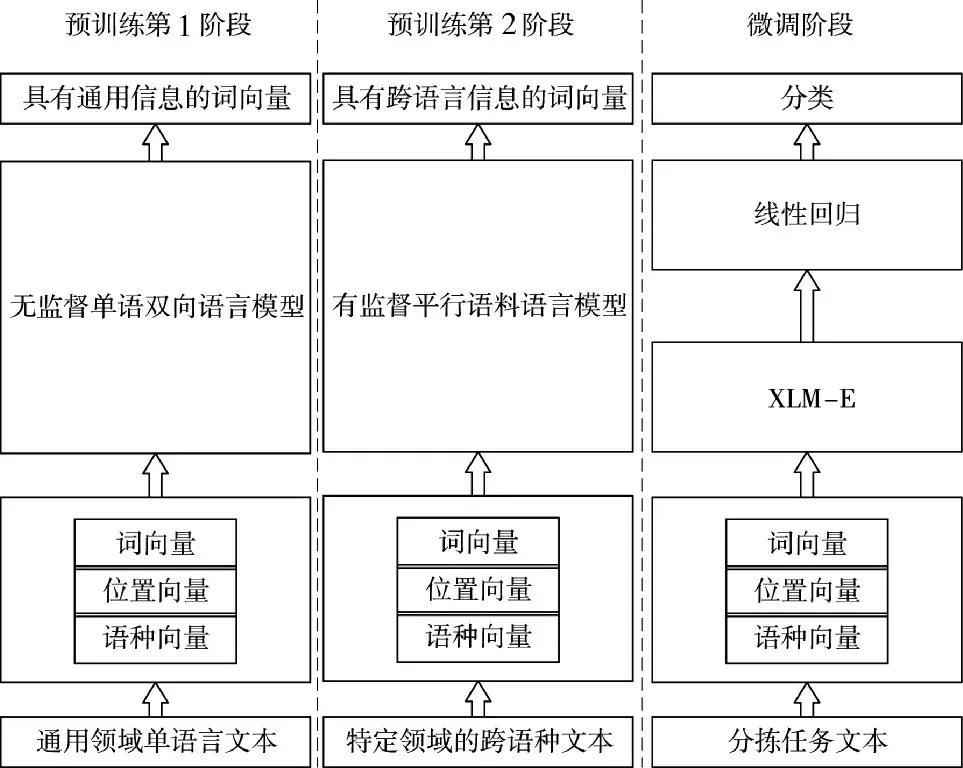
图2 低资源场景跨语种词嵌入学习架构图Fig.2 Cross-language word embedding learning architecture in low-resource scenarios
跨语种词嵌入表示学习技术和跨模态表示学习技术通过预训练方法将海量的文本、语音数据转化为向量表示,为多任务学习的分拣技术提供支持。
具体而言,“多语种嵌入表示学习技术”可以学习不同语种的语料库文本的语法和语义信息,以实现在低资源情境下,基于平行语料库的多语种词嵌入模型训练和信息分类。“跨模态表示学习技术”则采用了基于全词掩码预训练语言模型和基于自监督的语音特征表征技术,实现了在多模态情境下的特征整合和知识迁移。最后,“基于多任务学习的信息分类技术”将多语种嵌入表示学习技术和跨模态表示学习技术相结合,构建了一个多任务学习框架,该框架能够通过参数共享来优化多策略的多任务学习模型,并对多任务学习的效果进行评估和优化。
2.2 跨语种词嵌入表示学习技术
传统的信息分拣技术主要基于单一语种和单一标签的分类方法进行训练。然而面对复杂的文本数据,单一模型往往难以满足信息挖掘的需要。为解决这个问题,跨语种词嵌入表示模型应运而生,通过学习大量平行数据,跨语种词嵌入表示模型能够突破多语种词嵌入的对齐问题,并将多语种之间的映射关系以模型参数的形式保存下来,很好地满足了信息分拣系统对跨语种文本理解的需求。跨语种词嵌入表示学习技术主要包括低资源场景下的跨语种词嵌入模型训练和基于跨语种词嵌入表示模型的信息分拣两个主要组成部分。
2.2.1 低资源场景下的跨语种词嵌入模型训练
由于一些语种的数据量较小,低资源情况下的语种识别技术无法达到良好的识别效果,这对信息分拣的效果产生重大影响。为了解决这个问题,本文采用了预训练的方法,不仅降低了对跨语种数据的需求,而且减少了跨语种词嵌入的训练成本,并且具有很好的迁移性。
首先,在通用的跨语种文本上进行第一阶段的单语言预训练。然后,在平行语料上再次进行预训练,此时使用第1 次预训练的模型权重参数来初始化第2 次预训练的权重参数。
经过两个阶段的预训练,获得了跨语种的语言模型,并且基于特定领域的知识分类任务进行微调。其中,XLM-E 是一种针对低资源情况下的无监督跨语种词嵌入语言模型[17],它在100 种语言的文本上进行了预训练,目前是跨语种分类、序列标注和问答任务中表现最好的模型之一。
XLM-E 使用Transformer 模型用于多语言掩码语言模型(Masked Language Model)训练,采用单语言数据对每种语言的文本流进行采样,并训练模型以预测输入中的Mask Token。在Unigram 语言模型的基础上,使用Sentence Piece 直接在原始文本数据上应用子词Tokenization。本文使用与XLM 模型相同的抽样分布,对包含不同语言文本的批次进行抽样[18],设置α=0.3,最后使用250 K 的单词表和Softmax 训练两种不同的模型,与原始XLM 不同,模型不使用语言嵌入,这使模型能够更好地处理上下文中交替使用两种或多种语言的现象。
2.2.2 基于跨语种词嵌入表示模型的信息分拣
在跨语种词嵌入模型基础上,可以进行跨语种信息分拣模型的训练和调优。考虑到中文训练数据的收集和标注相对方便,同时,由于收集和标注的数据会蕴含丰富的信息,大多数据包含多个标签,标签之间可能相互独立或者相互关联。因而本文使用中文数据来微调训练跨语种信息分拣模型,在训练中综合利用多标签信息,提高信息分拣效果。基于多标签分类的信息分拣模型主要分为两个步骤:首先是基于跨语种词嵌入表达的多尺度信息抽取,然后再基于抽取的特征向量进行多标签的分类和生成。
1)多尺度信息抽取
输入词序列通过跨语种词嵌入表示模型进行特征变换后,获取到各个词的稠密向量表征,若直接拼接这些特征会引入较多的冗余信息,对信息分拣预测造成干扰。因而,本项目尝试用CNN 卷积神经网络对词表征信息进行压缩抽取,如下页图3 中编码器所示。
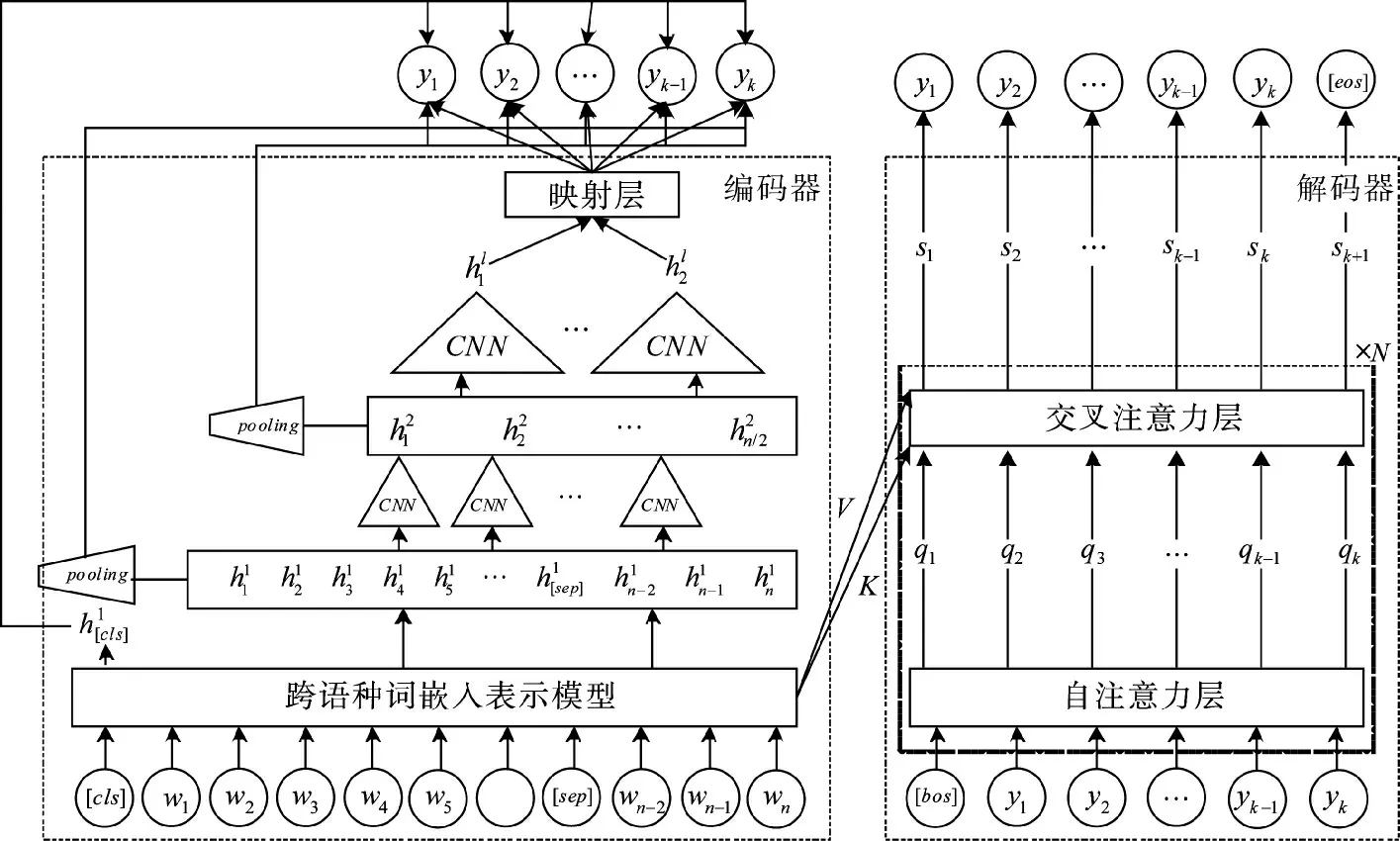
图3 多标签的信息分拣模型Fig.3 Multi-label information sorting model
词表征特征经过不同CNN 卷积层转换后,逐渐抽取出短语、句子等高维度的特征表征。最后在进行信息分拣预测时,低尺度层的特征先经过池化平均,再与高维大尺度特征拼接联合,共同进行多标签的分类预测,此时每个标签的获取都是一个独立的多分类问题。
2)多标签的分类和生成
标注数据的多标签信息存在一定的关联性,如一二级标签体系或前后因果关系等,若直接拆分为各个独立的多分类问题,会弱化或丢失标签间的关联信息。因而,本项目引入编码器-解码器框架,编码器部分是以往的多任务建模方式,先进行多尺度特征抽取后进行不同标签的预测分类,解码器则是利用自回归方式来建模不同标签之间的关联关系。首先,将需要预测的多标签序列y1,y2,y3,…,yk按照各个标签的统计数目由大到小排序,这样一方面能够学习标签间的从属或前后因果关系,另一方面也能尽量避免自回归方式中前文内容预测错误导致的后续内容偏离问题。解码器网络主要使用Transformer 结构,包含多个自注意力层和交叉注意力层。自注意力层建模多标签间的关联关系;交互注意力层结合编码器与解码器的信息,编码器输出的词表征序列作为k、v,与解码器的编码特征q 进行注意力权重计算,抽取输入词表征序列中的关键信息。模型最终的目标函数联合编码器中的多任务预测损失和解码器中的自回归标签预测损失。
最后,在模型推理预测时,联合编码器和解码器的输出概率来共同决策。具体流程是先通过解码器网络进行Beam-Search 解码,获取多个预测的标签候选序列,然后通过编码器上的多任务分类网络,对每个标签序列中的各个标签进行概率预测,最后对多个候选标签序列重新打分排序,选取最优标签作为最终的判断结果。
2.3 跨模态表示学习技术
为了挖掘不同模态下的互补信息和非冗余信息,将多模态的信息融合到一个整体框架中,并通过多模态融合处理来降低或消除音频噪声,本文采用跨模态的表示学习技术,以提升非均衡的多模态数据中信息分拣的效果。跨模态表示学习技术总体方案如图4 所示,总体方案体系结构由基于全词掩码预训练语言模型的文本表征技术,基于自监督的语音表征技术和多模态层次特征融合技术与跨模态知识迁移技术组成。

图4 跨模态表示学习技术总体方案Fig.4 Overall scheme for cross-modal representation learning technology
在第1 阶段,采用全词掩码预训练语言模型和基于自监督的语音表征技术,来实现本文模态和语音模态的知识表示学习。具体来说,在文本表征方面,本文使用全词掩码进行预训练,以便让模型学习到更多词语粒度的知识,从而更好地将中文语料嵌入到表征空间中。此外,还通过多层双向Transformer 来编码底层的词嵌入向量,以捕获句子的语义特征,并获得更高级别的表征。在语音表征方面,首先使用训练数据预处理技术,对有标签和无标签数据进行预处理,以确保候选训练任务的有效性。然后,通过自监督预训练技术,以生成式、对比式或预测式的方式来学习语音表征。最后,考虑到多语种和方言语音数据的知识共享,采用跨语种的音频表征融合技术,以增强模型的鲁棒性。
在第2 阶段,通过多模态特征融合技术和跨模态知识迁移技术,分别从特征融合和知识迁移两种角度实现跨模态表示学习。多模态特征融合技术基于多模态共同注意力机制和残差网络的层级门控单元,将文本和语音向量投影到相同的表征空间,实现语义信息的深度融合。同时,采用对比学习技术以学习更通用的多模态特征并降低噪声的影响。而跨模态知识迁移技术则通过共享模型结构和特征对齐等方式实现多模态的表示,不需要将两种模态的表征向量进行融合。本文首先根据文本序列的最大长度生成位置编码向量,然后利用这些位置编码对语音特征进行总结,以缩小语音表征和本文表征之间的差距。最后,采用迁移学习技术,利用预训练语言模型将文本知识传递到语音表征中,使其具备良好的语义表示能力,以更好地满足下游的信息分拣任务的需求。
2.3.1 基于全词掩码预训练模型的文本表征
传统的信息分拣系统大多采用基于规则和统计学习的方法,或者使用随机初始化的神经网络,因此,模型性能受限于数据本身的质量和分布,且难以针对特定语种优化模型,导致模型的平均精度均值较低。而预训练语言模型,通过在特定语种的大规模无标注数据上进行预训练,可以有效学习通用语言特征,具备丰富的先验知识与高鲁棒的文本表征能力。此外,传统的分词策略,将文本以字符为粒度进行分词,这在一定程度上会破坏中文文本的语义,而采用全词掩码的预训练策略,则让模型学习词语粒度的表征,在面向中文文本时,可以大幅提高模型预测的准确率,为后续跨模态表示学习奠定基础。因此,本文采用基于全词掩码预训练语言模型的文本表征技术,总体方案如图5 所示,由全词掩码预训练技术和基于双向编码的词向量表征技术组成。
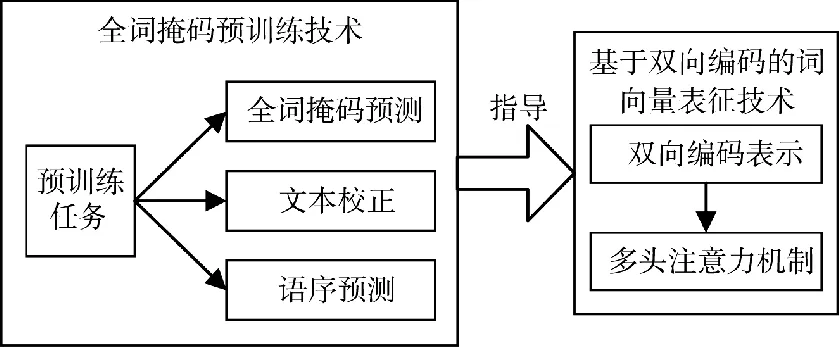
图5 文本表征技术方案Fig.5 Text characterization technology scheme
首先,全词掩码预训练技术为整个模型的预训练设置了3 个任务,包括全词掩码预测、错误词语校正和句子顺序预测。与传统的预训练方法相比,全词掩码预训练技术更具挑战性和效率,可以帮助模型学习更深层次的语义特征。
其次,基于双向编码的词向量表征技术通过多层双向Transformer 同时处理整个输入文本序列,将其编码为上下文嵌入向量序列。与传统的双向循环网络不同,双向词向量编码技术采用多头注意力机制,实现了输入文本序列中每个单词的交互,从而提高了每个Token 的语义表征的丰富程度。
最后,基于全词掩码预训练语言模型的文本表征技术方案,通过设置多个任务和采用双向编码的词向量表征技术,实现了高效通用的文本模态表示学习。这种技术方案可以减轻文本的信息差异性和中文语义复杂性对模型的影响,为后续的跨模态表示学习、多任务联合训练和智能信息分拣提供了基础。
2.3.2 基于自监督的语音特征表示
监督式学习在语音和音频处理方面取得了显著的进展,但它必须为单个任务和应用场景建立专门模型,很难应用于不完全准确或仅有部分样本标签的多语种和方言数据。同时,由于标注数据的成本高和特定领域标注难度大等问题,大批量有标签数据的获取也比较困难。自监督的语音表征学习方法可以利用大量无标签数据,提供一个通用模型,在极大地降低人力标注成本的同时,也能使得模型更加鲁棒,使各种任务和领域都能从中受益,在实现新的性能水平的同时,减少许多下游场景所需的有标签数据量,为后续任务场景的实现奠定良好的基础。
因此,本文采用基于自监督的语音特征表示,首先使用预训练加微调的范式进行自监督的语音特征表示。在预训练的阶段,通过生成式、对比式或预测式的方式来学习语音表征,而在下游任务阶段,使用少量的有标签数据对模型进行微调,充分利用已经学习到的语音表征来解决下游任务。
然后基于语音特征表示,实现跨语种的音频特征融合,实现不同语言音频的表征向量在语义上的融合和统一。首先获取不同语种音频的基础表征,采用预训练技术,通过无标签数据的自监督学习,获得语音的基本特征向量;然后根据语义将不同语种的音频表征统一到同一表征空间。构建Transformer 网络,通过注意力机制计算不同语种音频之间的相似度对特征向量进行重构,最后将重构的特征向量送入对齐模型,通过计算两个向量之间的相似度,判断语音的语义是否相同,从而将不同语种的表征映射到同一空间,减小相同语义特征之间的差距,消除语种带来的差异。
2.3.3 多模态特征融合与知识迁移
深度学习方法的出现为语音识别和自然语言处理领域带来了巨大的变革。当前研究大多专注于某一个特定的模态,即这些任务的输入输出都只涉及单模态,无法同时处理来自多个模态的信息。然而在实际问题中,获取的信息大多数涉及多个模态,特别是情报信息领域,包含大量的语音和文本数据,因此,需要文本和语音双模态的跨模态表示学习技术,以研制通用的信息智能分拣系统。
本文旨在研究灵活通用、快速适应下游任务的多模态学习方法,针对现有方案过度依赖平行语义数据的问题,采用了两种跨模态表示学习方法:多模态层次融合技术和跨模态知识迁移技术。
1)多模态层次融合
在训练阶段,对于输入的属于相同类别的文本语音对,不直接使用真实标签训练,而是将文本作为语音的“语义标签”,促使模型学习语音到文本的映射函数,然后使用层次融合技术构造残差网络,让输入的语音表征序列与自身映射得到的文本表征序列进行融合,避免了直接“硬”融合导致的语义差异。此外,本文对已有的注意力机制进行优化,采用多模态共同注意机制提取文本和语音共同注意的层次特征,包括文本引导的语音注意和语音引导的文本注意,然后使用门控融合用于评估不同模态层次表征的重要性,并将它们融合到最终的跨模态表征中。同时,使用对比学习思想,最小化来自同一样本之间的距离,并最大化不同类别语音文本对之间的距离,来提高多模态表示的质量。
2)跨模态知识迁移
首先使用语音表征模型,得到语音的表征向量,并对语音特征进行多模态层次融合,以缩小语音和文本之间的语义差异,将位置编码作为查询向量,从语音表征向量中得到与Token 位置相对应的潜在表征;然后使用基于多层多头自注意力机制的解码器进一步优化语音表征序列;最后为了进一步将语音表征和文本表征整合成一个稳定的多模态表征,使用基于教师模型的知识转移方法,利用大规模预训练语言模型的知识指导语音表征模型的参数优化。
2.4 基于多任务学习的信息分拣技术
根据不同任务的重要性,定义一个最重要的任务为主任务,其他任务为辅任务。本文中,主任务为多模态融合的信息分拣,辅助任务为各个模态单独进行的信息分拣。主任务利用注意力机制关注多模态间信息的联系和交互,将各模态信息融合,并进行综合性的分类,以提高信息分拣的可靠性。而辅助任务则主要针对单模态独有的重要特征进行分析,弥补主任务对单模态内部信息的关注不足。
2.4.1 基于主辅分类器的多任务学习
基于主-辅分类器的多任务学习框架如图6 所示。首先使用跨模态多头注意力机制同时提取文本特征和语音特征,得到语音引导的文本特征和文本引导的语音特征;然后将这两个特征分别输入到相应的分类器中,计算出文本预测损失Ltext和语音预测损失Lspeech,作为辅助任务(分任务)的预测结果;接着采用自适应门控融合机制将两种特征融合,并输入到softmax 函数中,得到融合了文本特征和语音特征的多模态信息向量,将多模态信息向量输入到主分类器中,得到分拣结果损失L 作为主任务的预测结果;最后,将主任务的损失和两个辅助任务的损失加权求和,得到最终的联合损失,以更新主分类器和辅助分类器的模型参数。
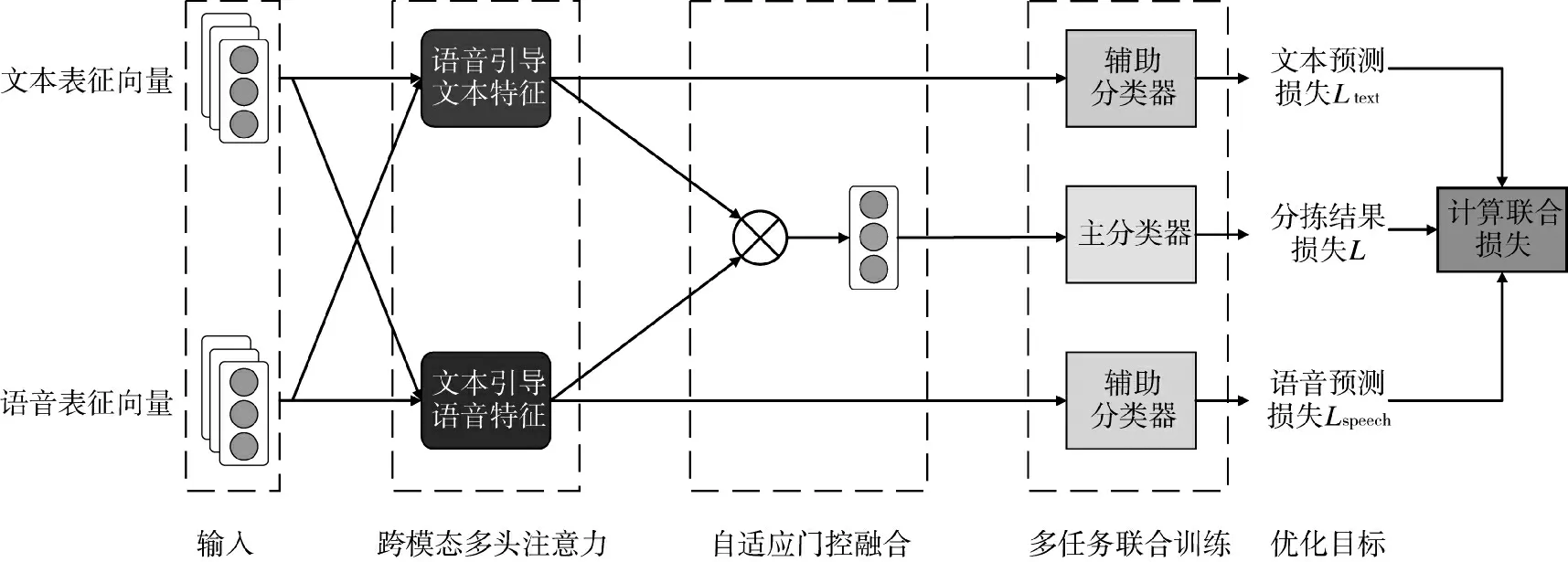
图6 基于主-辅分类器的多任务学习框架Fig.6 Multi-task learning framework based on primary-secondary classifiers

图7 基于知识迁移的多任务学习框架Fig.7 Multi-task learning framework based on knowledge transfer
2.4.2 基于迁移学习的多任务学习
与将文本特征和语音特征进行融合的主辅分类器方法不同,基于迁移学习的多任务学习方法的核心思想是将文本分类模型的知识迁移到语音分类模型中。
具体而言,首先使用编码器-解码器结构对语音数据进行处理,将解码器的最后一层的结果输入到语音分类器中计算语音分类损失;然后在多任务联合训练部分对文本数据进行处理,将文本数据输入到预训练语言模型BERT 中,将预训练语言模型最后一层的结果输入到文本分类器中,计算文本分类损失;为了将文本分类模型的知识迁移到语音模型中,计算文本分类模型中预训练语言模型最后一层输出和语音分类模型中解码器最后一层输出之间的均方差损失,通过最小化这个均方差损失,使得语音模型中解码器的输出分布接近于文本模型中预训练语言模型最后一层的输出;最后将语音分类损失、文本分类损失和均方差损失的加权和作为联合损失,使用联合损失来反向更新两个模型中的所有参数。
3 典型应用
本文从全局和局部角度对齐文本和音频特征,将其编码到一个联合特征空间来度量相似度,首先选取1 000 篇军事新闻,将内容和其译文作为文本数据,同时把对应的新闻摘要转化形成语音数据,经过人工标注构造检索数据集。通过文本检索语音和语音检索文本两种任务检验模型在不同训练阶段的分拣效果,如表1 所示,其中单语种词嵌入阶段和跨语种词嵌入阶段,将语音转换成文本进行检验,在完成跨模态表示之后,再进行端到端的检索方法。
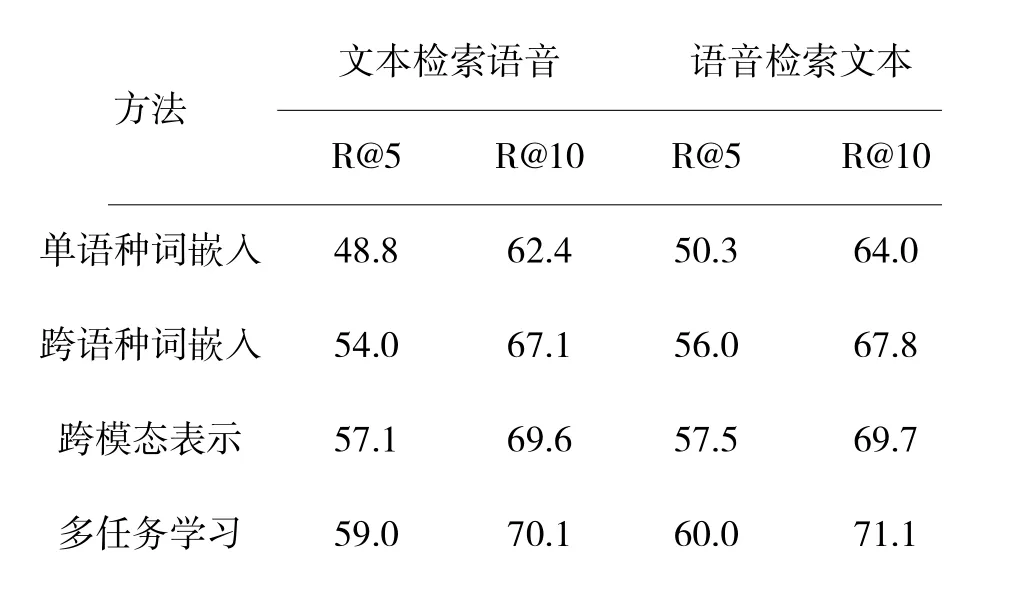
表1 模型在不同阶段的检索结果对比Table 1 Comparison of retrieval results of models at different stages
单语种词嵌入阶段基于通用领域的文本数据进行预训练,并构造检索分类器,实现情报领域的信息检索。跨语种的词嵌入表示学习将不同语种间的语义实体进行对齐,提升了不同语种之间的检索结果比例。跨模态表示阶段将文本和语音中的语义信息进行有效融合,实现了不同模态之间信息的互补。多任务学习阶段考虑了单模态和多模态模型之间侧重关注内容不同的问题,有效提高了多模态之间互相检索的召回率。
跨语种多模态信息分拣技术在情报工作中存在广泛地应用,情报工作涉及收集、分析和处理来自不同来源和多种形式的信息,分拣技术能够有效地帮助情报分析人员分析和运用这些信息。情报工作的信息分拣过程包括数据收集与整合、跨语种表示学习、跨模态表示学习、多任务学习、情报形成5个过程,如图8 所示。
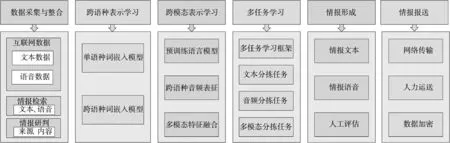
图8 情报工作流程Fig.8 Intelligence processing workflow
3.1 数据收集与整合
通过自动化的语言翻译和多模态分析技术,可以将跨语种的文本、图像、视频等信息进行整合和归类,构建一个更全面、多样化的情报数据集。确定数据整合和储存的统一标准,情报工作者从不同的语言和媒体来源中收集和整理相关信息,将门类庞杂、种类繁多的海量情报数据进行整合。
3.2 跨语种表示学习
情报涉及的语种多样,训练模型以单语种语料库为基础进行自主学习,借助跨语种词嵌入表示学习技术,可以检索到相关多语种的情报信息,建立情报关键词库,进行情报信息的自动识别。
3.3 跨模态表示学习
通过多任务学习的分拣技术提取各个模态数据的高级语义信息,借助跨模态表示学习技术突破文本与语音的界限,建立文本与语音之间的语义联系,将语义特征进行关联融合,从而更全面地挖掘情报线索。
3.4 多任务学习
在文本、语音情报数据中发现语义联系,结合情报信息的复杂性和多样性,调整模型中设定的参数,发挥模型的最大价值,提高情报信息识别发现的准确率。
3.5 情报产品形成
情报线索分拣完成后,通过专家对分拣出的情报资源进行跨源综合分析、评估、预测,汇总关键情报要点,整编为符合需求的情报产品,支撑远海护航、联合军演、国际维和、联合反恐等场景下的情报需求。
4 结论
本文将多语种之间的映射关系以模型参数的形式保存下来,很好地解决了跨语种词嵌入的问题;通过全词掩码预训练语言模型和自监督的语音特征表示技术,处理了中文文本差异和语音数据标注成本高的问题;引入主辅模型以及迁移学习技术,解决了多个任务之间的参数共享、集成学习和知识迁移的问题。这些方法提升了跨语种多模态信息分拣模型的准确性,能够为情报工作中的数据处理、信息分析和决策提供有效的思路和方法。
猜你喜欢
时代邮刊(2021年8期)2021-07-21
开放教育研究(2020年2期)2020-03-31
中国生物医学工程学报(2019年6期)2019-07-16
疯狂英语(双语世界)(2017年3期)2018-01-19
自动化学报(2016年3期)2016-08-23
现代语文(2016年21期)2016-05-25
电测与仪表(2016年5期)2016-04-22
大连民族大学学报(2015年2期)2015-02-27
计算机工程(2014年6期)2014-02-28
外语学刊(2011年1期)2011-01-22
