
基于多尺度特征融合和双注意力网络的遥感影像地物提取*
2023-11-20 11:02王舒洋韩卫华范春艳
火力与指挥控制 2023年10期
王舒洋,贺 浩,韩卫华,范春艳
(火箭军士官学校,山东 青州 262500)
0 引言
随着航天技术的发展,如今有大量的遥感图像源源不断地发回到地面,形成了名副其实的遥感图像大数据。若仅仅依靠人力来分析这些遥感图像是不现实的。影像地物提取的目标是将遥感图像中的不同地物类别,如建筑物、道路、农田、河流、湖泊等,按照类别区分开来[1]。遥感影像的地物信息提取在许多遥感应用中发挥着重要作用。与传统实地调查相比,通过分析遥感影像来获取地物信息,可以显著降低人力和时间成本,具有广泛的应用前景[2]。
从遥感影像中自动提取地物信息可视为一个语义分割任务[3]。传统的遥感数据分类方法包括最大似然分类、聚类或logistic 回归等,之后又出现许多更先进的方法用于遥感图像的分割,如k 近邻、决策树、随机森林、SVM 等[4-7]。近年来,卷积神经网络与传统的机器学习方法相比,显示出强大的特征提取和表示能力[8]。因此,大量的深度语义分割模型被广泛用于遥感影像的地物提取,典型的有全卷积网络和编解码网络框架,如U-net、SegNet 等[9-10]。然而,卷积网络固有的结构使得其受局部感受野的约束,只能获得较小范围内的上下文信息,这使得其无法充分利用整个图像中的长距离依赖关系。但是,高分辨率遥感影像中的数据有时会表现出较强的类内异质性和类间同质性特征,需要建立远程上下文关系来增强不同地物的特征表示。
为增强像素间的上下文联系,PSPNet 利用金字塔池化模块将特征映射划分为多个区域,通过汇聚不同区域的上下文信息,提升对全局上下文信息的获取能力[11]。CHEN 等提出一种具有多尺度扩张率的空洞空间金字塔池化来聚合上下文信息[12]。MOU等提出一个关系增强的FCN,引入空间关系模块和通道关系模块,以学习任意两个位置之间的关系[13]。此外,注意力机制也可以有效整合局部和全局特征,建立长距离的上下文依赖,被广泛应用于机器翻译、视频分类、目标检测和语义分割等任务中。WANG 等提出将非局部操作作为一种空间注意力来捕获远程依赖关系[14]。PSANet 从信息流角度来理解注意力机制,设计了逐点的空间注意力模型,通过两点的位置关系和语义信息来推断它们之间的上下文依赖关系[15]。LI 等提出金字塔注意力网络框架,通过特征金字塔注意力和全局注意力上采样,获得全局上下文信息[16]。DANet 引入了双重注意力模块来丰富特征表示[17]。这些注意力网络被整合到自然场景的语义分割网络中,提高了网络分割的精度。
遥感影像数据具有独特的复杂性。遥感数据中的地物分布具有分散分布的特性,经常存在远程的地物空间分布关系,且其语义特征往往具有多尺度特性。
针对以上情况,本文提出一种结合多尺度特征融合和双注意力网络的遥感影像地物提取网络。针对不同地物类别的多尺度特征,引入多尺度特征融合(mutil-scale feature fusion,MFF)模块,有效地整合局部的纹理特征和较大范围的边缘特征;针对地物空间分布特性,引入双注意力网络,建立远程上下文依赖。双注意力网络包含两个并行的自注意力机制,分别对空间关系和通道依赖进行建模,称之为空间注意力模块以及通道注意力模块。本文提出的方法在提取多尺度特征的基础上,引入双注意力网络,可获取更加丰富的特征映射关系,得到更加精准的地物提取结果。
1 方法
1.1 网络的整体架构
本文提出的结合多尺度特征融合和双注意力网络的遥感影像地物提取网络,其整体架构如图1所示。
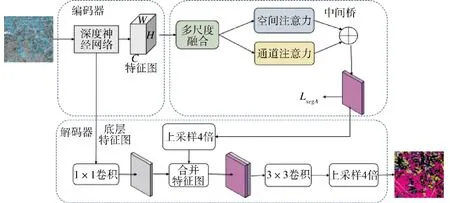
图1 地物提取网络的总体结构Fig.1 The overall architecture of the ground object feature extraction network
为使地物提取网络具备足够的细节辨识能力,整个网络采用编解码网络的设计思路。整个模型可以分为三大部分:编码器、解码器和中间桥。
编码器部分采用一个经典的CNN 来实现,本文选用在ImageNet 数据集上预训练后的ResNet 101作为模型的编码器网络。ResNet 101 是一个著名的深度卷积神经网络[18],由何凯明提出,被广泛应用于图像分类任务中。
中间桥由多尺度特征融合模块和双注意力网络组成,用来更好地捕获全局上下文信息以及远程依赖关系,以增强特征表示。首先,将编码器产生的特征映射送入多尺度特征融合模块,捕获多尺度特征,然后,将输出特征图送入两个并行的双注意力网络,建立远程的地物空间分布依赖关系模型。
解码器需要将在空间上压缩的语义特征图的分辨率逐步还原到输入图像大小。
1.2 多尺度特征融合模块
多尺度特征融合模块采用空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)实现。ASPP 结合了空洞卷积与空间金字塔池化,能够在多个不同尺度上,捕获上下文信息,实现多尺度的特征提取[19]。
本文使用的多尺度特征融合模块,参照Deep Lab v3 中的ASPP 模块来设计[12],如图2 所示。ASPP最早在DeepLab v2 网络中引入,DeepLab v3 又对ASPP 模块进行了改进,在每个分支中都使用不同扩张率的空洞卷积。

图2 多尺度特征融合模块结构示意图Fig.2 Schematic diagram of Structure of the multi-scale feature fusion module
多尺度特征融合模块是一个由多个分支组成的并行结构,这些分支对同一个特征映射进行操作,并最终融合输出。不同分支分别为1 组1×1 的卷积,3 组不同扩张率的3×3 空洞卷积,扩张率分别为2、4 和8,此外,还有1 组全局平均池化分支以合并全局上下文信息。而后,利用双线性插值将以上各分支产生的特征图统一至输入特征图的大小。最后,将这些特征图合并后再通过一组1×1 卷积,使输出的特征图与原特征图的通道数保持一致。
1.3 双注意力网络
经过多尺度特征融合模块后,特征图获得了不同尺度的特征,然后引入双注意力网络(attention module,AM),来建模更广泛和更丰富的上下文表示。双注意力网络由并行的空间注意力模块以及通道注意力模块组成,分别从空间和通道这两个不同的维度对特征的语义关联进行建模。注意力模块采用矩阵转置相乘的方式来计算各特征图或通道的相关性,构造注意力图。空间注意力模块通过对所有位置特征加权求和来聚合特征,捕捉特征图内任意两个位置的空间依赖关系,无论空间位置的远近,相似的特征会在该特征空间中获得较近分布距离。通道特征图可被视为对不同类的特定响应,不同的通道与不同类别的语义信息相关。因此,增强特定语义的特征表示可以通过通道注意力模块改进通道映射之间的依赖关系来实现。
1.3.1 空间注意力模块
为了在局部特征上建立更丰富的上下文关系模型,引入空间注意力模块,来建模不同像素之间的位置联系,提高特征的表示能力[16]。对于每个位置特征,通过对所有位置加权求和来更新特征,其权重可依据相似性来确定。此时,无论空间维度上距离的远近,任意两个具有相似特征的像素都能相互促进。空间注意力模块如图3 所示。

图3 空间注意力模块结构示意图Fig.3 Schematic diagram of the spatial attention module
给定一个特征图X∊RC×H×W,其中C、W、H 分别代表特征图的通道、宽度和高度。首先将其送入卷积层,产生两个新的特征图A 和B,分别有{A,B}∊RC×H×W。将其形变为RC×H,其中N=H×W;而后,将B的转置和A 做矩阵相乘,再对计算结果进行一个Softmax 计算来得到空间注意力特征图S∊RN×N。
其中,sji体现了i 位置的像素对j 位置像素的影响。两者之间特征越相似,越能体现之间的相关性。
同时,将X 送入另外的卷积层来产生一个新的特征图D∊RC×H×W,并将其形变为RC×H。而后将特征图D 与S 的转置做矩阵相乘,并将其重构至空间RC×H×W。最后,将其乘以系数μ 并与原特征图X 求和,得到输出E∊RC×H×W:
其中,μ 为空间注意力参数,初始化为0,可通过网络训练进行学习更新。
从以上公式可以看出,结果特征图E 是所有空间像素的特征加权后合并到原始特征中。因此,它既具有全局上下文特征,也有根据空间注意力特征图得到的选择性统计特征。相似的语义特征之间能够互相增益,这可以增强类内的语义一致性。
1.3.2 通道注意力模块
通道注意力模块能够模拟通道间的依赖关系,利用不同通道图之间的相互依赖关系,突出相互依赖的特征映射,从而改善特定语义的特征表示。通道注意力模块的设计与空间注意力模块相似,其结构如图4 所示。
对于特征图X∊RC×H×W,首先将X 形变为RC×N,再将形变后的结果X 与其自身的转置进行矩阵相乘,然后应用一个Softmax 层,此时可以得到通道注意力映射M∊RC×C。
其中,mji表示第i 个通道对第j 个通道的影响。
同样,将通道注意力映射M 与X 进行矩阵乘法,并将结果形变为RC×H×W,得到的结果乘以系数υ,并与X 进行逐元素求和运算,得到最终输出F∊RC×H×W:
其中,υ 为通道注意力参数,从0 开始学习更新。式(4)将所有通道的特征加权后合并到原始特征中。因而,得到的特征图F,突出了类相关特征映射,提高了类之间的特征可分辨性。
最后,空间注意力模块得到的特征图E 与通道注意力模块输出的特征图F 进行逐元素求和运算,输出结果为整个双注意力网络的输出。
1.4 损失函数
训练的损失函数采用多类交叉熵损失函数:
此外,在双注意力网络后的特征图上使用额外的监督LsegA,来促进双注意力网络得到更具语义区分性的特征图。LsegA用来评估双注意力网络后得到的特征图所得的分割结果,同样使用预测和标签之间的多类交叉熵作为分割损失。因此,最终的损失函数可以表示为:

2 实验与分析
2.1 实验数据集
本文选用高分图像数据集(gaofen image dataset,GID)作为实验数据[20]。GID 是一个用于遥感影像地物提取的大型数据集,包含150 张大小的高分2 号(GF-2)遥感影像及其标注,覆盖506 km2的地理区域。
图5 展示了高分图像数据集中的一些样本及其对应的标注。

图5 高分图像数据集及其标注示例Fig.5 Some examples of gaofen image datasets and their labels
2.2 实验相关配置
受限于计算机显存大小,训练数据被裁剪至512×512 大小。为提高数据的泛化能力,对裁剪后的训练数据进行数据增强操作,包括:水平翻转、垂直翻转、随机缩放(从0.5 到2.0)和随机裁剪。为提高网络训练过程的稳定性,对输入图片进行规范化处理。首先,将输入图片进行0-1 标准化,然后取均值,这使得图片的输入值限定在[-0.5,0.5]范围内。
实验在Pytorch 的深度学习下框架进行,利用一块GTX 1080Ti 进行加速。
实验选用Adam 优化器来优化网络[21],配置学习率为α=10-3,衰减系数β1=0.9,β2=0.999,小值常数ε=10-8。该参数设置已在大量深度学习问题上得到了验证,证明了其具有良好的性能。
2.3 评价标准
为评估网络对遥感影像地物提取的效果,使用混淆矩阵(confusion matrix,CM)、总体精度(overall accuracy,OA)、平均交并比(mean intersection over union,mIoU)来进行评价。
CM 是评价算法分类性能的一种标准格式,以n行n 列的矩阵来表示,n 为类别数。总体精度是指正确分类的像素在所有像素中的百分比。
交并比(intersection over union,IoU)也可以称为Jaccard 相似系数。mIoU 是计算每一类的IoU 之后,取平均值,得到的平均交并比就是基于全局的评价。
2.4 实验与结果分析
实验随机选取了GID 数据集20 张高分-2 号卫星图像中的5 张图像作为测试数据,其余15 张图像作为训练数据。训练数据按照前文进行预处理后,进行训练。用于测试的5 张7 200×6 800 的高分-2 号卫星图像被切割为512×512 大小,得到1 050 张不同的测试图像。
首先,将本文提出的方法与其他典型的语义分割模型(SegNet[10]、U-net[9]、DeepLab v3+[17]、DANet[16])进行对比,所得的实验结果如表2 所示。
表1 显示了各个方法在GID 数据集上的实验结果指标。结果表明,本文提出的方法得到的OA 和mIoU 分别为84.1%、62.3%,两个指标均优于其他方法。总体而言,在对照组中,U-net 和SegNet 的分割指标相对较低,而DANet 和DeepLab v3+ 相较于U-net 和SegNet 分割效果更好。DeepLab v3+网络与U-net 和SegNet 相比,最大的不同就是利用了图像多尺度特征来聚集上下文信息。而DANet 则使用了注意力机制来建立远程信息关联。这也在一定程度上反映出多尺度特征和注意力机制对于语义分割的作用。

表1 不同方法在高分图像数据集上的实验结果对比Table 1 Experiment result comparison of different methods on GID dataset
图6 展示了各方法在高分图像数据集上地物提取结果的可视化示例。可以看出,本文方法能较好地识别混淆区域,并能较好地获取不同地物的轮廓。
为进一步验证多尺度特征融合模块和双注意力网络在遥感影像地物提取中起到的作用,进一步进行了消融实验。以下几组实验的基准网络是相同的,在基准网络的基础上添加MFF 模块,在基准网络的基础上添加双注意力网络,以及在基准网络基础上添加MFF 模块和双注意力网络,所得对比结果如下页表2 所示。

表2 GID 数据集上各模块消融实验结果Table 2 Experiment results of ablation of each module on GID datasets
与基准网络相比,添加了MFF 模块后,总体精度和mIoU 分别提高了1.5%和2.1%。这表明,MFF模块可以有效捕获不同尺度的目标,提高网络对不同地物的提取精度。添加了AM 模块后,总体精度和mIoU 分别提高了1.2%和1.9%。在添加多尺度特征融合模块和双注意力网络后,本文提出的方法相比于基准网络,其OA 提高了3.3%,mIoU 提高了4.4%。这说明了多尺度融合和注意力机制改善了遥感影像地物提取结果,验证了MFF 模块和双注意力网络的有效性。
表2 还显示了每个类别的分割精度,来评估模型对不同类别地物的提取效果。结果表明,对于不同类别,多尺度特征融合模块和双注意力网络,能够捕获全局上下文关系,从而增强特征表示,同时抑制局部信息干扰,能够较好地提高各个类别的分类性能。
下页图7 展示了几个对比实验的可视化结果。图7(a)、图7(b)的河流与湖泊、坑塘具有相似的外观与纹理特征,仅靠局部上下文难以作出准确判断,加入多尺度特征融合模块与双注意力网络后,网络具有了更好的捕获上下文关系的能力,减少了错误分类。图7(c)、图7(d)中的道路宽度较细,属于小尺度的地物类型,基础网络对交通运输类别的提取结果显示道路被划分为离散的路段,通过多尺度融合策略,可以获得相对连续的道路提取结果,有效改善了对此类小尺度目标的检测效果。在地物类型复杂时,部分类别的类间差异小、类内方差大,要将各类地物有效分开就变得尤为困难,如图7(e)~图7(g)所示,本文提出的方法相比基准网络,能有效提取各类地物信息,并且具有较少的孤立点、噪声。
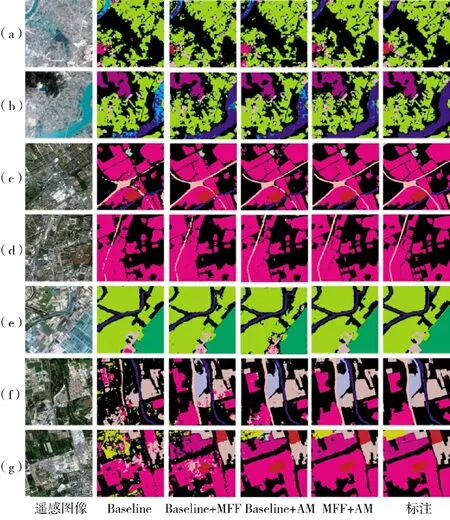
图7 GID 数据集上各模块消融实验的可视化结果Fig.7 Visual results of the ablation experiment of each module on GID dataset
本文所提出的方法在GID 数据集上地物提取结果的混淆矩阵如图8 所示。
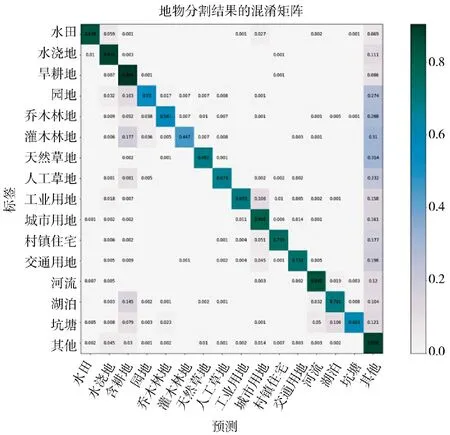
图8 地物提取结果的混淆矩阵Fig.8 Confusion matrix of the ground object feature extraction results
从混淆矩阵中可以看出,类别特征不明显的园地、乔木林地、灌木林地的提取精度最低,湖泊和坑塘均为封闭水域,水域大小不同,容易混淆,因此,提取精度也较低。而田地类、建筑物类特征相对明显,提取精度较高。由于遥感影像分割的标注不可能做到非常精确,存在大量无法标注的背景区域,这使得所有类别在无法准确区分时,都更有可能别分类为“其他”这一类别,这一点也拉低了整体的分割精度。
下页图9 展示了在整幅的高分-2 号卫星图像的地物提取效果,本文提出的方法能较好地从卫星影像中不同地物类型的空间分布,从而更好地理解和分析卫星图像。

图9 整幅高分-2 号图像上的地物提取结果图Fig.9 Ground object feature extraction results of the whole frame of Gaofen 2 images
3 结论
本文提出一种结合多尺度特征融合和注意力机制的遥感影像地物提取方法。为提高地物提取的精度,在传统编解码网络的基础上,引入多尺度融合模块和双注意力网络。多尺度融合模块能够提取图像的多尺度特征,扩大卷积神经网络的感受野,并将多尺度上下文信息融合在一起来捕获全局信息。双注意力网络由空间注意力模块和通道注意力模块组成,能够自适应地捕获空间域的远程上下文关系和通道间的相互依赖。在高分-2 号卫星图像上进行实验,本文提出的方法得到的总体精度为84.1%,mIoU 为62.3%。与其他对比方法相比,本文提出的方法获得了更好的地物提取效果。此外,还通过消融实验验证了多尺度融合模块与双注意力网络的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
河南科技(2014年23期)2014-02-27
