
基于GRU神经网络多标签多分类的焦炭质量预测模型
2023-11-22 02:01郝晓东乔星星原靖超张泽晖张国杰张永发
煤炭转化 2023年6期
郝晓东 乔星星 王 影 原靖超 张泽晖 张国杰 张永发
(1.太原理工大学省部共建煤基能源清洁高效利用国家重点实验室,煤科学与技术教育部重点实验室,030024 太原;2.陕西煤业化工技术研究院有限责任公司,710000 西安;3.太原理工大学机械与运载工程学院,030024 太原)
0 引 言
炼焦是指炼焦煤在高温隔绝空气条件下生产焦炭、焦炉煤气和其他炼焦化学产品的工艺过程。炼焦配煤通过配合不同种类的入炉混煤得到满足质量要求的焦炭,而配煤过程直接影响焦炭的生产成本、质量和利润。因此,配煤是炼焦过程中重要环节之一。目前,各焦化企业所用的配合煤种类和数量都大不相同,有的企业使用了多煤种[1]甚至全煤种完成炼焦配煤过程,降低主焦煤和肥煤使用量容易造成焦炭质量波动。因此在保证焦炭质量情况下,如何获得更高的回报就成为炼焦企业必须考虑的问题。
入炉混煤的各项指标虽与其热解后的焦炭指标具有一定相关性,但是仍需进行40 kg小焦炉等实验验证后才可以真正进行入炉操作。为了解决入炉煤对焦炭指标波动的影响,并缩短验证时间,需建立从入炉煤指标(硫分质量分数(w(S))、挥发分质量分数(w(Vdaf))、灰分质量分数(w(Ad))、黏结指数(G)、热强度和胶质层厚度(d)等)到焦炭指标(硫分质量分数(w(S))、灰分质量分数(w(Ad))、反应后强度(coke strength after reaction,CSR)等指标)的质量预测模型。
传统焦炭质量模型依靠人工经验与计算能较好地保证焦炭质量,但却未必是最优解。近年来国内外学者提出了多种焦炭质量预测模型。胡涛等[2]提出一种基于火电厂发电量预测的多目标配煤方法,建立基于Elman神经网络的火电厂发电量滚动预测模型,不仅充分考虑耗煤量和煤质特性约束情况,还将整个模型应用于实际配煤过程,提高了配煤结果的可靠性、实用性和灵活性;李颖等[3]详细地分析了不同BP(back propagation)神经网络模型的预测效果以及制约其预测效果的主要因素 (网络结构、学习样本数量、隐层节点数、学习精度),发现学习样本数量是影响BP神经网络性能的关键;刘春梅[4]利用最小二乘法原理将所用原煤的质量因子与配煤的质量因子进行关联,建立了单种原煤与配煤之间的线性逼近模型,最后利用配煤的质量因子去预测和控制焦炭的质量;刘文丽等[5]对配合煤各指标进行回归分析,提出了用多元线性回归方法建立焦炭质量预测模型,当用配合煤挥发分质量分数(w(Vdaf))、黏结指数(G)和灰分质量分数(w(Ad))为自变量,焦炭的抗碎强度和耐磨强度作为预测值的相关系数分别为0.852 0和0.679 5,用配合煤挥发分质量分数(w(Vdaf))、黏结指数(G)以及催化指数(MCIY)作为自变量对焦炭的反应性和反应后强度进行预测,相关系数分别为0.927 8和0.931 4,此方法是通过MATLAB环境中的回归(regress)、拟合(robustfit)等函数对各指标进行分析,对于非线性相关的数据预测性较差;沈坤等[6]在焦炭质量预测中对实际炼焦生产过程中煤、焦、工况数据进行匹配、分析、提取,采用BP神经网络建模对焦炭质量进行预测,并且对比分析了工况对预测模型精度的影响,结果表明炼焦工况的合理性对焦炭质量预测精度的影响较小,而精准的数据匹配更有利于焦炭质量预测,且依据实际炼焦生产数据的分析与匹配可以降低模型要求,该模型选用传统的BP神经网络,收敛速度慢,网络结构选择太多,容易出现过拟合现象以及容易陷入局部极值等问题;陶文华等[7]将差分算法运用到BP神经网络优化中,建立了基于DE-BP(differential evolution back propagation)神经网络焦炭预测模型,利用差分优化算法减少了初始值和阈值的随机性,使得焦炭各指标预测值与真实值的相对误差控制在4%以内,该模型由于BP神经网络中的参数众多,每次都需要更新数量较多的阈值和权值,会导致收敛速度过慢等问题;卢建文等[8]在配煤炼焦优化方法中利用多层神经网络以及模拟退火算法优化单种配煤质量比,并将模型预测误差控制在5%以内;郭一楠等[9]利用神经网络进行建模,通过遗传算法(genetic algorithm,GA)对权重进行训练,再采用遗传算法来实现配煤质量比的定量计算,且焦炭质量预测的精度稳定在96%±1%范围内,该模型将配煤计算分成两部分,预测时间将很难控制;程泽凯等[10]将分类回归树、梯度提升、缩减组成的梯度提升决策树运用于焦炭质量预测模型中,其精度和误差相比于线性回归等其他方法的精度和误差分别有了提高和减小,但是梯度提升决策树算法调节参数不灵活,预测时间较长。
焦化企业为了保证生产的稳定,实际生产的配煤方案是稳定的小样本数据(每年通常小于100个配方),因此需要解决小样本数据下从配煤指标到焦炭指标预测的准确率,即模型预测得到的数据与实际数据相比,预测正确的结果占总样本的百分比。
小样本下部分数值出现频次较低,直接均方根处理结果得到的误差较大。鉴于冶金焦炭往往都参照国标规定进行买卖,因此一级焦、准一级焦、二级焦的部分指标是相对数量较少的固定值,例如焦炭的硫分质量分数分别为0.6%(一级焦),0.7%(准一级焦),0.8%(二级焦),1.0%(三级焦)等,焦炭中硫分的质量分数出现结果大幅缩减到5种~7种的可能性,对应的硫标签分类方法降低到5种~7种,此时小样本数据的预测结果就会更加准确。因此,本研究基于小样本数据采用多标签多分类进行预测,即分别以硫分质量分数、灰分质量分数、CSR等各个指标为标签依次进行多分类预测,而预测结果用sigmoid函数判断其准确率(accuracy rate)。
相比以往模型,GRU(gate recurrent unit)模型构建简单,参数量相对较少,训练速度快,训练准确率高,可扩展性强,并且提高了模型在小样本下的预测准确率,能有效抑制梯度消失或爆炸, 效果都优于传统循环神经网络(recurrent neural network,RNN),GRU模型计算复杂度相比长短期记忆网络(long short-term memory,LSTM)计算复杂度要小。因此,本研究提出了基于小样本的GRU神经网络多标签多分类焦炭质量预测模型。
1 基本原理
人工神经网络(artificial neural network,ANN)[11-12],是一种模仿动物中枢神经系统结构和原理的计算模型,实际上是一个由大量的神经元两两相互联接而成的复杂网络,具有很强的非线性,能够进行复杂的逻辑操作和非线性关系实现。神经网络由大量的节点彼此连接形成,每个节点通过激活函数(activation function)进行非线性优化,并根据反向传播完成权重值的调节,学习规则主要的作用就是利用特殊的函数规则在神经网络训练过程中不断地改变参数,使得模型达到最优化。考虑到BP神经网络模型的缺点,本研究选择可以有效克服BP神经网络模型不足的门控循环单元(gated recurrent unit,GRU)[13-16]神经网络模型。
门控循环单元是一种特殊的循环神经网络,可用于解决非线性的可变时间序列预测问题,在长时间序列预测问题处理中有独特的优势[17-18],在自然语言处理[19]、煤矿工作面瓦斯浓度预测[20]、机器翻译、语音识别等方面已经有很多应用[21-23]。传统RNN容易出现梯度消失或者梯度爆炸,而GRU神经网络巧妙地利用记忆门控制运算,使得网络计算过程始终处在动态变化中,避免了梯度消失或者梯度爆炸问题[24-31]。GRU神经网络内部结构如图1所示。由图1可以看出,GRU神经网络模型的神经元主要由更新门和重置门两个部分组成。图中:xt表示当前节点的输入;yt表示输出新的候选态;ht表示当前的节点信息态;ht-1表示上一个节点信息态;rt表示重置门层;zt表示更新门;Nt表示候选隐藏态;σ表示sigmoid函数。

图1 GRU神经网络内部结构Fig.1 Internal structure of GRU neural network
GRU神经网络的模型训练计算过程如式(1)~式(5)所示。
zt=σ(wz·[ht-1,xt])
(1)
rt=σ(wr·[ht-1,xt])
(2)
Nt=tanh(w·[rt×ht-1,xt])
(3)
ht=(1-zt)×ht-1+zt×Nt
(4)
yt=σ(wo×ht+by)
(5)
式中:w,wz,wr,wo表示权重矩阵;by表示偏移量。
神经网络中另一个重要的选择就是误差分析函数,通常在数值结果预测下用均方误差(mean squared error,MSE)、均方根误差(root mean squared error,RMSE)和平均绝对误差(mean absolute error,MAE)。MSE和MAE适用于误差相对明显的时候,大的误差也有比较高的权重,但是由于MSE是一个线性的指标,当真实值和预测值的差大于1时,会放大误差;当真实值和预测值的差小于1时,则会缩小误差。MAE在0点处不可导,且其梯度保持不变,这就使得很小的损失值其梯度也很大。而RMSE则是针对误差不是很明显的时候,其缺点就是很容易受到极端值的影响,对于实验中的小数据影响太大。
为了解决小样本数值预测不准确问题,需要引入多标签多分类预测方法。多标签学习任务是学习一个有效的模型,对于给定有N个样本的数据集D={(X,Y)}N,其中X=[x11,…,xnm]表示样本的特征向量,Y=[y1,y2,…,yn]表示带有n个样本的标签空间,N是数据集的样本数量。多标签数据的结构如表1所示。多标签学习的目的就是构建一个多标签分类函数f:x→2y,该函数为每个输入的样本序列x∈X,分配一组可能的类标签f(x)⊆Y(见表1)。最终利用该函数对未分类的实例样本进行正确的预测。
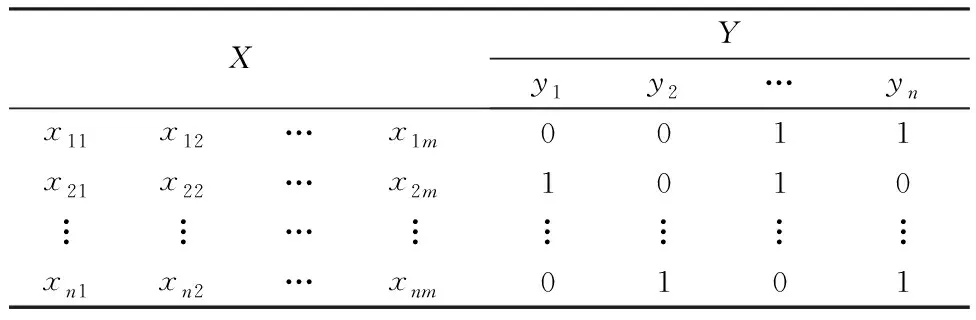
表1 多标签数据的结构Table 1 Structural of multi-label data
实验模型独热(one-hot)编码标签化实例如图2所示。由图2可以看出,以硫分质量分数分别为0.65%,0.7%,0.8%和1.0%为例,一级焦硫分质量分数为0.7%时,对应标签0.7位置变为1,其他标签都为0,即(0,1,0,0,…);当硫分质量分数为0.8%时,对应标签0.8位置变为1,其他标签都为0,即(0,0,1,0,…)。如果选用灰分质量分数作为第二个指标时,只需将标签进行拼接结合。例如硫分质量分数为0.7%和灰分质量分数为13%的标签为(0,1,0,0,…,0,1,0,0,…),同理可将模型参数扩大到硫分质量分数、灰分质量分数、黏结指数、膨胀度、流动度等其他配合煤指标进行独热编码。

图2 标签化实例Fig.2 Labeled instance
多标签分类问题函数对比如表2所示。由表2可以看出,多标签分类中一般用softmax函数或者sigmoid函数作为激活函数进行结果输出。softmax函数是一个概率函数,主要用来计算各个类别占全部类别的概率,其输出每个元素值为softmax函数计算出的被取到类别的概率。而sigmoid函数则是将神经网络的输出进行转换,可以使数值压缩到(0,1)之间,得到的结果可以理解为分类成目标类别的概率P,而不能分类到该类别的概率为(1-P),这也是典型的两点分布的形式,它多用于二分类问题中。而本研究是基于多分类和多标签同时存在,因此将多标签多分类问题进行转换,将其转换为n个二分类问题,即判断每个类别是否存在,因此选择了sigmoid函数。

表2 分类问题对比Table 2 Comparison chart of classification problems
2 焦炭预测模型
2.1 数据的预处理
2.1.1 输入层与输出层参数确定
为了搞清楚各变量之间相关程度,引入了线性相关的热图分析。将若干单种煤按照一定的比例掺混得到入炉配合煤,其多标签数据集标签共生矩阵如图3所示。图3可以看出,配合煤中的灰分质量分数(w(Acoal))、硫分质量分数(w(Scoal))与焦炭中的灰分质量分数(w(Acoke))、硫分质量分数(w(Scoke))存在着很强的线性相关性,分别达到0.72与0.94,而焦炭中的CSR主要受到配合煤中胶质层厚度(d)的影响,线性相关性最大达到0.40。输入层与输出层参数如表3所示。由表3可以看出,输入层参数主要由硫分质量分数(w(Scoal))、灰分质量分数(w(Acoal))、黏结指数(G)、挥发分质量分数(w(Vcoal))和热强度组成,输出层中参数主要是硫分质量分数(w(Scoke))、灰分质量分数(w(Acoke))及焦炭的反应后强度(CSR)。有些指标的线性相关虽然低,但实际确实关联性较高的,比如胶质层厚度(d)和CSR。因此需要解决非线性相关方面的焦炭质量预测问题。
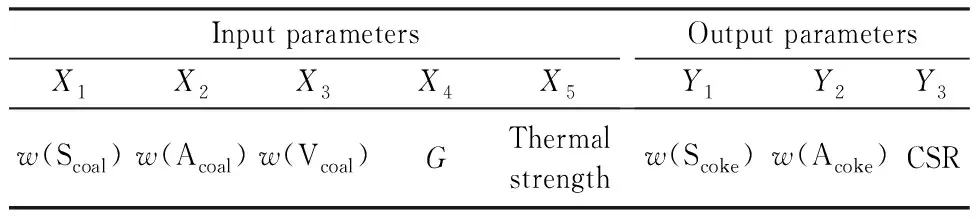
表3 输入参数与输出参数Table 3 Input and output parameters
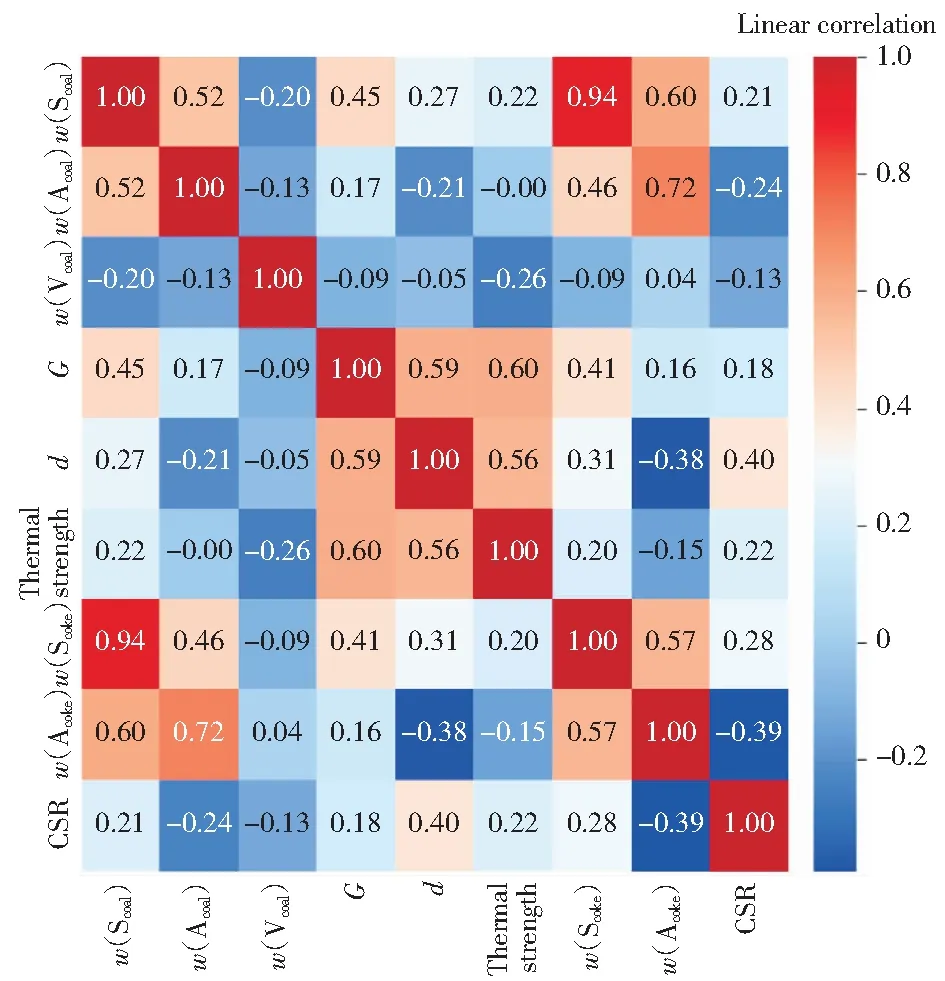
图3 多标签数据集标签共生矩阵Fig.3 Multi label dataset label symbiosis matrix
2.1.2 数据归一化处理
为了消除量纲不同、自身变异或者数值相差较大所引起的结果误差,需要对原始数据进行预处理。本研究用截断高斯分布对数据进行归一化,标准化预处理过的原始数据在模型训练中可以更快的收敛,并且有效的防止梯度爆炸。原始数据经过标准化处理之后值域分布在[-1,1]之间。本研究用标准差标准化对数据集进行预处理,其高斯计算公式如式(6)所示。
(6)

根据生产实际提供的焦炭指标数据和配合煤指标数据,对于出现概率较低的小样本数据,为使其达到最好的训练效果,通过一定倍数的复制操作,提升小样本数据出现的概率,即接近每种分类的平均概率。从最终得到有效数据样本共820组中随机选取80%数据样本作为训练样本数据集,其他的20%数据样本用于模型的测试集。
2.2 模型的建立
Adma优化器能够自动调节学习速率,其收敛速度更快,因而一般在复杂网络中优化性能更好。本研究选择Adma优化器,主体选用GRU网络加全连接层,全连接层中激活函数为sigmoid函数,正则化值选取0.01。对于学习率来说,若初始学习率设置过大,会导致偏离值较大且到后期无法拟合。若初始学习率设置过小,收敛速度会很慢[18,32]。设置不同学习率并观察迭代次数下损失的变化情况,选定最适合迭代率。根据已经确定的输入层与输出层,利用多标签函数将数据输入模型中,然后GRU神经网络开始进行训练并不断地调整参数值使其训练效果达到最佳。GRU神经网络模型以及GRU神经网络模型整体网络结构分别如图4和图5所示。

图4 GRU神经网络模型Fig.4 GRU neural network model
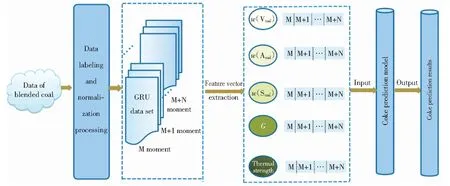
图5 GRU神经网络模型整体网络结构Fig.5 Overall network structure of GRU neural network model
3 影响模型的主要超参数
影响GRU神经网络模型预测准确率的超参数主要有神经网络层数、神经元数量、学习率、训练的批次大小(batch_size)和样本训练次数(training frequency)等。神经网络模型性能的好坏由预测的准确率来体现。因此,模型需要在训练中不断地调节超参数以提高预测准确率。为了避免模型过拟合,需要参考F1-score分数中的精确率和召回率。
网络层数包括输入层、隐藏层、输出层。隐藏层是模型的核心层,它的意义就是把输入数据的特征抽象到另一个维度空间来展现其更抽象化的特征,这些特征能更好地进行划分。
神经元是神经网络中的最基本的单位,具有输入、输出与计算功能。神经元本质上是一个函数(多输入单输出),它有两部分:一部分为线性运算;一部分为激活函数。线性运算是设置每个输入量对结果影响的权重,激活函数是将线性运算的结果转化成需要的信息。在模型中使用过少的神经元将会导致欠拟合的情况,但是,神经元数量太多又会导致过拟合的情况,所以选择一个合适的隐藏层神经元数量是至关重要的。
学习率是训练神经网络的重要超参数之一,表示在迭代过程中梯度向损失函数最优解移动的步长,其大小决定网络学习速度的快慢。
美国历史游径标识充分体现了在引导步行线路方面的连续性和实用性。选择稳重颜色,以纯色快为主体,配以图文并茂的表达形式,在保持整体风格协调的同时,对每一块标识牌编号,当游人迷路或需要寻求帮助时,借助标识上的序号即可准确定位,同时也将各个标识牌有机联系起来,构成标识系统网络,为管理和维护标识提供便利。另一方面,标识系统结合周边环境对内容和功能进行了扩展,如提供地图定位、旅游指引等功能,将标识进一步融入整个旅游服务体系。
训练的批次大小是一次训练选取的样本个数,可以一次性将整个数据集都给神经网络,让神经网络利用全部样本来计算迭代时的梯度(即传统的梯度下降法),也可以一次只利用一个样本(即随机梯度下降法,也称在线梯度下降法)给神经网络,也可以取折中方案,即每次利用部分样本给神经网络让其完成本轮迭代(即batch梯度下降法)。批次大小对模型的优化和速度都很有影响,而且批次大小的正确选择是为了在内存效率和内存容量之间寻找最佳平衡。
样本训练次数也是需要考虑的因素,每个样本训练次数表示所有的数据分批次送入网络中,完成了一次前向计算反向传播的过程(相当于做实验重复的次数),其循环次数较少时,容易欠拟合,泛化能力较弱;循环次数越多,训练准确率越高,同时也容易发生过拟合,但测试准确率却受到模型参数、结构的巨大影响。
在训练过程中,当模型参数太多而训练样本太少,模型训练结果很容易产生过拟合的现象。因此利用Dropout预防过拟合。在训练阶段,以概率P对每个神经元进行随机失活,然后将数据输入该神经网络,对未失活节点的权重与偏置进行训练。在测试阶段,将所有神经元激活,但是其输出的结果要乘以(1-P),P是其在训练阶段失活的概率。这样,在测试阶段,可以认为综合了很多个不同的模型进行投票,从而防止单一模型容易产生过拟合的情况,在一定程度上达到正则化的效果。
因此,神经网络模型通过调节神经元数量、训练的批次大小、样本训练次数、神经元丢弃率等超参数可以得到更好的预测准确率。
4 结果与讨论
4.1 神经网络层数的影响
不同层数下GRU神经网络的准确率和损失率对比如图6所示。GRU隐藏层整体网络结构如图7所示。GRU隐藏层内部网络结构如图8所示。

图6 不同层数下GRU神经网络的准确率和损失率对比Fig.6 Comparison of accuracy and loss rate of GRU neural network under different layersa—Accuracy rate;b—Loss rate
由图6a可以看出,主体网络分别考虑了用1层~5层GRU进行比对,1层~3层GRU的验证集准确率随样本训练次数的增加急速上升到95.12%左右后保持平缓,其中3层GRU准确率最为突出,接近97.55%,而4层GRU的验证集准确率则是先平缓过渡后直线拉升到95.05%左右后趋于平缓。由图6b可以看出,GRU的损失率随样本训练次数的增加整体先急速下降到35.03%后保持平缓,3层GRU损失率是下降最为明显的(到21.05%左右),1层、4层和5层下降基本保持一致(在35.07%左右)。因此,模型选择3层GRU加1层全连接层作为隐藏层。
4.2 神经元数量
3层GRU神经元数量分别取(n,2n,4n),(4n,2n,n)和(n,n,n)时GRU神经网络的准确率分别如图9,图10和图11所示。

图9 GRU神经元数量为(n,2n,4n)时的准确率Fig.9 Accuracy rate when the number of GRU neurons is (n, 2n, 4n)

图10 GRU神经元数量为(4n,2n,n)时的准确率Fig.10 Accuracy rate when the number of GRU neurons is (4n, 2n, n)

图11 GRU神经元数量为(n,n,n)时的准确率Fig.11 Accuracy rate when the number of GRU neurons is (n,n,n)
由图9可以看出,当3层GRU网络的神经元个数调整时,会产生不同的准确率,最后达到一个平缓状态,说明模型在不断的调整最后达到相对稳定,随着神经元数量不断增加,准确率在下降,当神经元数量为(32,64,128)时,准确率达到最大,约为90.34%。
由图10可以看出,当神经元数量为(4n,2n,n)时,随着神经元数量的减少,准确率随训练次数的增加整体呈先升后降趋势,当神经元数量为(256,128,64),准确率达到最大,约为85.71%。
由图11可以看出,当神经元数量为(n,n,n)时,随着n不断地增加,准确率逐渐增大,当神经元数据为(64,64,64),准确率达到最大,约为97.04%。
经过这三种最佳情况的对比之后,将模型的3层GRU神经网络的神经元数量设置为(64,64,64)。
4.3 学习率的影响
不同学习率条件下GRU神经网络的准确率和损失率对比如图12所示。
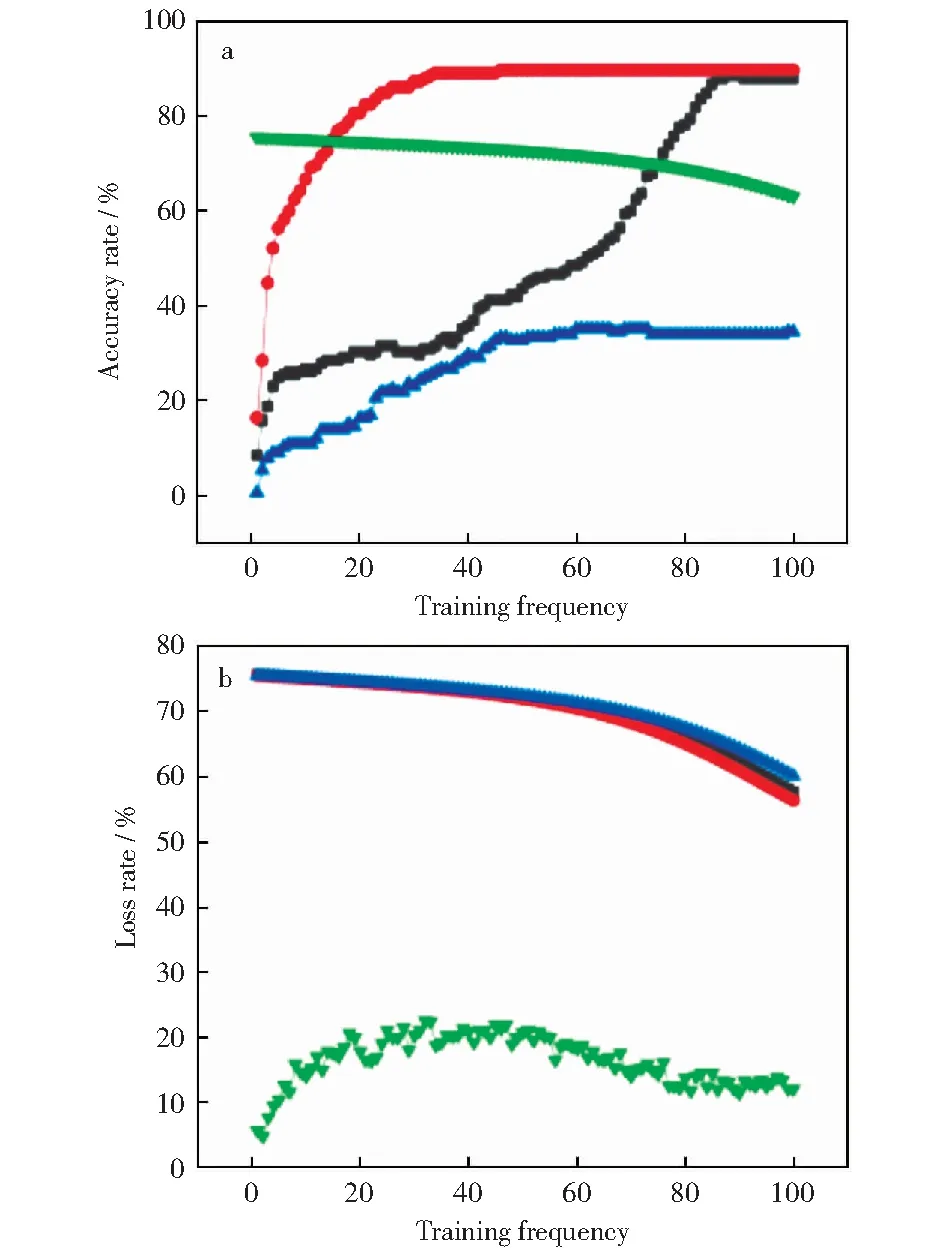
图12 不同学习率下GRU的准确率和损失率对比Fig.12 Comparison of accuracy rate and loss rate of GRU at different learning ratea—Accurary rate;b—Loss rate
选择学习率分别为0.1,0.01,0.001,0.0001进行对比,由图12可以看出,整体的准确率均随训练次数的增加先急速上升后保持平缓,随着学习率的增大,准确率先增大后变小,且当学习率为0.01时,准确率达到最大,约为85.08%。而整体的损失率则是随训练次数的增加不断下降,学习率为0.01时,损失率与其他学习率有明显的差别,且学习率为0.01时,损失率达到最小,约为15.03%。因此将模型的学习率设置为0.01。
4.4 训练样本的批次大小和样本训练次数
不同样本批次大小下GRU神经网络的准确率对比如图13所示。不同样本训练次数在样本批次大小为64时GRU神经网络的准确率对比如图14所示。
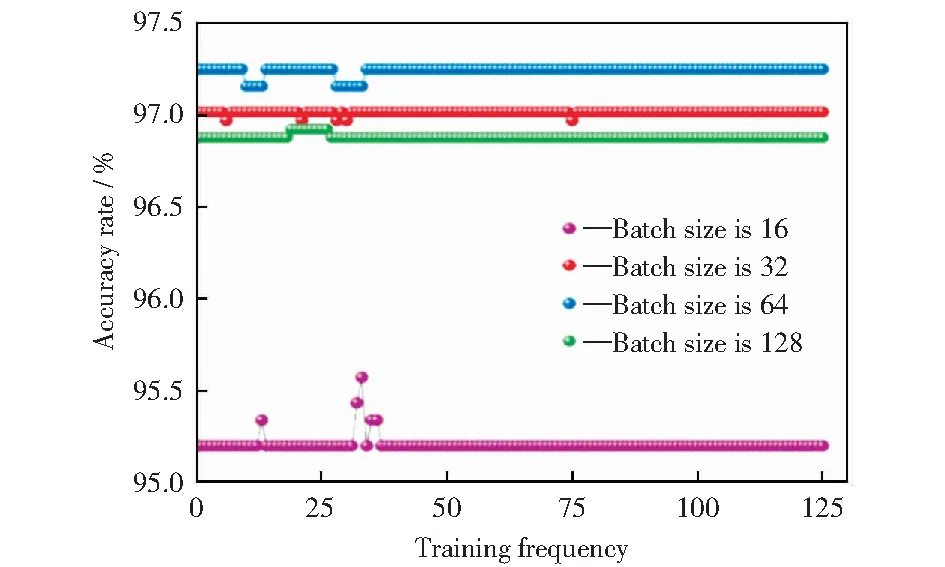
图13 不同样本批次大小下GRU的准确率对比Fig.13 Comparison of GRU accuracy rates at different batch_size
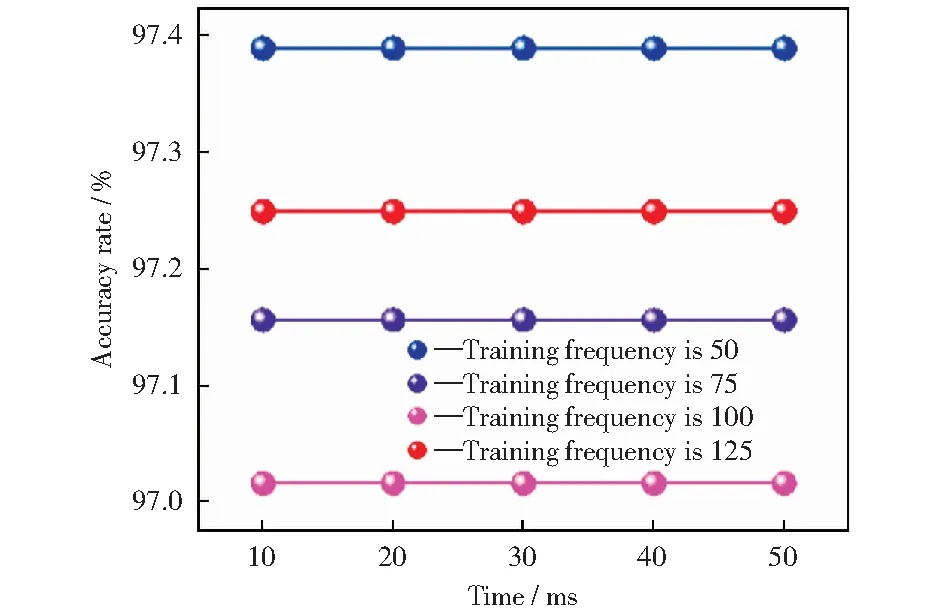
图14 不同样本训练次数在样本批次大小为64时GRU的准确率对比Fig.14 Comparison of GRU accuracy rates at different sample training frequency when batch_size is 64
由图13可以看出,样本批次大小(Batch_size)分别为16,32,64,128,当样本批次大小为64时准确率达到最高,约为97.25%,此时模型的拟合效果达到最优。因此将模型的样本批次大小设置为64。
由图14可以看出,样本训练次数为50时准确率达到最高,为97.25%,因此将模型的样本训练次数设置为50。
4.5 丢弃率
不同丢弃率下GRU神经网络的准确率对比如图15所示。分别将丢弃率设为0.1,0.2,0.3,0.4,0.5进行比对。由图15可以看出,随着丢弃率不断地增大,准确率先增大后变小,在丢弃率为0.3时准确率达到最高,约为65.04%,拟合效果最佳,因此将模型的丢弃率设置为0.3。

图15 不同丢弃率下GRU的准确率对比Fig.15 Comparison of accuracy rate of GRU at different dropouts rate
最终得出当训练模型三层隐藏层神经元个数为(64,64,64),样本批次大小为64,学习率为0.01,样本训练次数为50,丢弃率为0.3时,拟合程度最符合预定要求。经过不断地训练和预测以及其他参数的不断调节,最终GRU神经网络预测准确率达到97%。
5 结 论
1) 利用多标签多分类方法,分别将配合煤中硫分质量分数、灰分质量分数、挥发分质量分数等重要因素以及焦炭中的硫分质量分数、灰分质量分数等每个因素进进行独热编码标签化,有利于结果预测。
2) 模型采用最优的3层GRU隐藏层和1层全连接层的组合,当3层GRU神经元数量为(64,64,64)时,其对应的准确率最高,约为97.04%。
3) GRU神经网络模型学习率为0.01时,模型准确率达到最高,约为85.08%。
4) GRU神经网络模型样本训练次数为50时可认为收敛,模型准确率达到最大,为97.25%。
5) GRU神经网络模型训练样本批次大小为64时,模型优化效果达到最佳,模型准确率约为97.25%。
6) GRU神经网络模型丢弃率为0.3时,模型的拟合效果最好,模型预测准确率约为65.04%。
本研究基于GRU神经网络实现多标签多分类焦炭预测,模型具有高精度特点,给定输入数据,得到焦炭质量预测数据,与实际炼焦数据进行比对,准确率可以达到97%,因此可以利用该模型进行配煤炼焦工作,得到理想的焦炭质量,从而节约人力和物力,对焦化企业具有理论参考意义。
猜你喜欢
自然杂志(2021年6期)2021-12-23
矿山安全信息(2021年3期)2021-11-30
中国特种设备安全(2021年9期)2021-03-02
车迷(2018年11期)2018-08-30
现代装饰(2018年5期)2018-05-26
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
电源技术(2015年5期)2015-08-22
计算机工程(2015年8期)2015-07-03
弹箭与制导学报(2015年1期)2015-03-11
