
DS-YOLOv5:一种实时的安全帽佩戴检测与识别模型
2023-11-28 03:45白培瑞刘庆一杜红萱轩辕梦玉傅颖霞
工程科学学报 2023年12期
白培瑞,王 瑞,刘庆一,韩 超,杜红萱,轩辕梦玉,傅颖霞
1) 山东科技大学电子信息工程学院,青岛 266590 2) 山东科技大学能源与矿业工程学院 ,青岛 266590
在不同行业的施工和生产现场,使用基于视频分析技术对安全帽佩戴情况进行自动检测与识别,是保障人员生命安全的重要措施.但生产现场视频采集环境往往更复杂,目标遮挡、光照不均匀和目标尺度差异大等原因,都会对基于视频的安全帽佩戴情况自动检测与识别提出挑战.安全帽佩戴检测与识别算法分为基于传统机器学习和基于深度学习的方法.传统机器学习方法通常采用背景减法、人体检测和安全帽检测识别等步骤,利用的是手工选定特征或统计特征.刘晓慧和叶西宁[1]提出利用肤色辅助确定安全帽位置,提取 Hu矩特征向量,再用支持向量机对安全帽进行识别分类.Li 等[2]针对位置固定的监控场景下的运动目标,采用Vibe 对运动背景进行分割处理,使用实时的人体分类框架C4 对人体定位,最终通过颜色特征判别实现安全帽检测.
基于深度学习的方法进一步分为“两阶段”方法和“单阶段”方法[3].“两阶段”方法即由算法提取特征后进行候选区域生成,然后使用分类器进行分类回归.Yogameena 等[4]利用Faster R-CNN 检测带标记的摩托车目标,再利用卷积网络模型和空间转换器识别头盔.Ferdous 等[5]设计以ResNet50为主干融合特征金字塔网络(FPN),采用分类和回归模型对安全帽进行分类和定位.“两阶段”方法的优势是可以有效提升检测精度,但是难以满足实时性检测的要求.“单阶段”方法使用端到端策略对图像进行目标位置的检测和分类.SSD(Single shot multibox detector)[6]模型和YOLO(You only look once)[7]模型是“单阶段”算法的典型代表.SSD 模型结合回归和 anchor 思想实现多尺度预测,但密集采样会造成模型难收敛,对小目标检测能力较差.吴等[8]使用结合反向渐进注意机制的SSD 网络对安全帽进行检测,使用H-SVM 对安全帽颜色分类,SSD-RPA512 模型达到了83.89% 的准确率.徐先峰等[9]使用MobileNet 为主干构建MobileNet-SSD 模型,将安全帽检测速度提高了10.2 倍.YOLO模型采用边检测边分类的策略,具有计算效率高的优势,其升级版本得到相关领域的广泛关注.YOLOv3[10]提出Darknet53 网络,使用FPN 架构和多尺度融合策略,提高了对小目标检测的精度.YOLOv4[11]的主干采用具有不同层间交叉的CSPDarknet53,采用Mosaic 数据增强方法和自我对抗训练策略以提高网络的检测与识别性能.YOLOv5[12]通过增加模型检测规模和数据优化处理,采用DIoU-NMS边界盒抑制措施提高小目标的检测精度.YOLOv5模型轻量且易移植,让很多研究在其基础上都得到了良好的检测性能[13-14].针对复杂环境下检测也成为新的研究领域,例如,黄林泉等[15]提出YOLOv3结合Deep SORT 多目标跟踪技术实现跳帧检测,结合可微图像处理模块提高目标检测在恶劣天气的适应性.受到自然语言处理中Transformer[16]应用的启发,使用CNN 的架构与Transformer 结合能对图像中全局信息和局部信息统一建模,得到灵活高效的网络模型.Zhu 等[17]针对无人机采集图片的尺度变化和运动模糊问题,提出了TPH-YOLOv5模型,结合Transformer 和注意力模块CBAM 提高预测输出效果,提高小目标的检测性能.前人研究证明结合注意力机制和特征融合机制可提高检测器的学习能力进而提升检测性能.上述安全帽检测包含以下几种难题:(1)CNN 模型通常关注局部信息忽略全局信息,而安全帽佩戴检测往往要伴随人体或人脸特征信息进行学习;(2)主干网络的特征提取往往针对单目标情况进行优化,在视频场景下的检测伴随着多目标和遮挡问题,算法缺乏鲁棒性;(3)对多尺度目标特征提取不充分.
本文针对以上难题,提出一种基于Deep selfattention YOLOv5(DS-YOLOv5)的安全帽检测模型,主要改进如下:
(1)使用YOLOv5 模型为基础,融合改进的Deep SORT 多目标跟踪算法,改进的Deep SORT 使用DIoU 提高检测框与预测框匹配准确度,加强视频检测中前后帧的数据关联,能改善遮挡和多目标造成的漏检错检问题;
(2)YOLOv5 主干网络融合Transformer 模块,将图片转成序列向量提取局部特征之间的关系,加强对图像全局信息的捕获和注重上下文信息的联系;
(3)YOLOv5 颈部网络部分使用加权双向特征金字塔网络(BiFPN)融合多尺度特征,根据特征的重要程度赋以权重,提高小目标的检测准确度.本文构建一种能够应对复杂环境,提高安全帽佩戴情况检测精度和实时性的深度学习模型DS-YOLOv5.实验结果表明,该模型的多个定量指标优于目前主流的安全帽佩戴检测模型,其mAP 可以达到95.5%.
1 相关背景
1.1 YOLOv5 模型结构与工作原理
YOLO 模型的核心思想是把物体检测问题转化为回归问题,用一个卷积神经网络从输入图像直接预测边界框位置和目标的类别概率.YOLOv5结构主要分为输入端、主干(Backbone)、颈部网络(Neck)和预测头(Prediction)四个部分.输入端采用mosaic 数据增强,主干采用Focus 结构和CSPDarknet53(Cross stage partial darknet53)结构相结合的方案,CSPDarknet53 是特征提取的核心网络,借助残差块实现了对特征图的快速降维,在不损失检测精度的前提下,提升对特征提取的能力和检测速度.颈部网络采用空间金字塔池(Spatial pyramid pooling, SPP)[18]和路径聚合网络(Path aggregation network, PANet)[19]的结构,加强来自不同特征层的特征聚合,提高网络检测不同尺度目标的能力.输出端采用CIoU_Loss 和DIoU_NMS 操作,输出对象坐标和分类结果.YOLOv5s 设置了两种CSP 模块,在主干应用CSP1_X 结构,在Neck 部分应用CSP2_X结构,CSP1_X 比CSP2_X 多设有残差结构,可以增加层与层之间反向传播的梯度值,避免因为网络过深带来的梯度消失,加强网络提取特征的能力.
当输入端接收图像后,YOLOv5 模型首先将每幅图像划分为7×7 的网格,每个网格作为一个预测盒,用于捕获落入网格单元中心的目标.每个网格单元输出M个预测边界框,每个边界框的预测输出位置信息和置信度C(Confidence),C主要反映预测盒与Ground Truth 之间的交并比 (Intersection over union,IOU)得分.置信度得分公式为:
式中,Pr(object)表示目标出现在单元格的条件类概率,规定单元格中有目标其值取1,否则取0.表示预测边界框与Ground Truth 的交并比,C反映预测类别的概率和边界框定位的准确性.根据网络深度和宽度参数的不同,YOLOv5 提供了YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x 四种模型配置文件.YOLOv5s 是网络深度和特征图宽度最小的网络,考虑到面向工业应用,本文采用YOLOv5s 为基础模型进行研究.
1.2 Deep SORT 多目标跟踪算法
深度简单在线实时跟踪(Deep simple online and realtime tracking,Deep SORT)的核心思想是利用传统的卡尔曼滤波和匈牙利算法分别负责跟踪目标的状态估计和轨迹分配问题[20].通过引入视频序列中检测结果的数据关联,整合目标的运动信息和外观信息,对丢失目标进行重识别.改进的Deep SORT 算法流程如图1 所示.Deep SORT 中使用卡尔曼滤波器与匀速运动和线性观测模型来观察目标的状态.对于输入的轨迹,卡尔曼滤波器通过预测状态与上一时刻的对比和检测框信息的校正,估计每个目标位置的均值和协方差矩阵,再通过卡尔曼滤波框架最优地求解速度分量对目标状态进行更新[21].匈牙利算法将前一帧的跟踪框与当前帧的检测框关联,通过特征信息和马氏距离来计算代价矩阵.首先,基于已存在目标运动状态的卡尔曼预测结果与检测结果之间的马氏距离进行运行信息的关联,马氏距离如式(2):
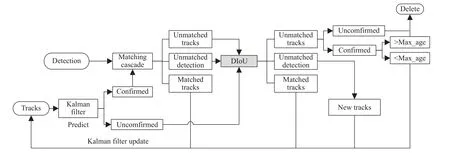
图1 改进的Deep SORT 算法流程图Fig.1 Flow chart of the improved Deep SORT algorithm
式中, (yi,Si) 表示第i个跟踪到测量空间的投影,其中yi为当前时刻的预测框,Si为协方差矩阵,dj表示第j个检测框.
当目标遮挡或者镜头视角抖动时,借助外观信息对检测框dj计算出对应的外观特征描述符rj,即重识别网络提取的128 维单位特征向量.对于每个轨迹k,都保留在最后100 个外观描述符作为集合 {Ri} , 通过计算第i个 跟踪框和第j个检测框最小余弦距离来减少跟踪误差,余弦距离如式(3):
级联匹配将卡尔曼滤波器判断为确认的轨迹框与检测框在卷积网络进行特征提取,根据轨迹框与检测框的l1和l2,进行匹配确认.再利用距离交并比 (Distance-IoU,DIoU)[22]对级联匹配中的未匹配轨迹和未匹配检测以及卡尔曼预测未确定的轨迹,进行再次匹配,对确认状态的轨迹框设置最大匹配寿命Max_age,并对超过Max_age 轨迹框删除处理,避免因短暂性遮挡而造成的漏检.
Deep SORT 算法中IoU 匹配方式回归速度快,但是无法衡量预测框与轨迹框的重叠方式.本研究使用DIoU 关联匹配,它在IoU 的基础上引入一个惩罚项,对重叠情况更加敏感,训练过程损失收敛更快,减少遮挡情况下ID 切换的问题,有更好的跟踪效果.检测框和目标框之间的归一化距离损失函数公式为:
式中,b和bGT分别代表检测框和预测框的中心点,ρ代表两个中心点之间的欧氏距离.c代表同时覆盖检测框和预测框的最小矩形的对角线距离.
1.3 Transformer
Transformer 是谷歌团队提出基于注意力结构来处理序列模型相关问题的模型,Transformer 的基本结构由编码组件、解码组件和连接(positionwise FFN)组成.编码器中有自注意力层和前馈层,解码器中除了有自注意力层和前馈层之外,还有一个解码器注意力层用于关注层之间的交叉信息,它推翻了以往自然语言处理通常需要CNN 结构的思想.Transformer 最初应用于自然语言处理领域,近来越来越多地被应用到计算机视觉领域.在目标检测领域,Carion 等[23]提出了一种端到端的目标检测模型(Detection transformer,DETR),将CNN 与transformer 架构相结合直接预测最终的检测结果,唯一的不足是需要大量的数据进行训练才能得到良好的精度.VIT(Vision transformer)是一种基于Transformer 进行图像块序列预测的分类模型,在多个图像识别基准数据集上获得优越的性能[24].研究表明Transformer 在计算机视觉领域有优秀的学习能力.
受到VIT 的启发,我们将YOLOv5 主干中部分原始卷积模块替换为VIT 中的Transformer Block,Transformer 将图像切块输入,借助对图像间的空间信息,提高主干的特征提取能力,最后使用YOLOv5检测头进行分类.VIT 模型包含Embedding 层、Transformer Encoder 和MLP(Multilayer perceptron) Head.Linear 层主要负责将二维图像转化为序列向量作为Transformer 的输入,Transformer Encoder 功能是捕获序列向量之间的相互关系,MLP Head 用于最终的分类.
(1)Embedding 层.
对输入的安全帽图像x∈RH×W×C分为N个不重叠的二维图像块xP∈RN×(S2×C),其中R是包含所有图像块的集合,并使用卷积核大小为D的网络对图像块编码生成序列向量xr={rclass,r1,r2,···,rN}用于Transformer 的输入,图像块数量与原图像之间的关系为:
其中,H,W,C为原图像的高、宽和通道数,S为图像块的尺寸大小,rclass是为防止在多层感知机(MLP)学习全局特征不够充分而加入的分类向量.图像块的序列向量代表图像块的内容信息,而自注意力机制处理序列还需要向量间的位置关系,因此在原文中还引入了位置编码Epoc用于捕获图像块之间的位置关系,E是实现线性映射的矩阵.因此在Embedding 层处理后,特征向量F表示为:
(2)Transformer Block 和MLP Block.
Transformer Block 主 要 由Transformer 编 码 器组成,作用是对序列向量提取局部特征之间的关系,首先对Embedding 层的输出进行归一化处理,经多头注意力层(Mutli-head self-attention,MSA)提取得到当前节点的全局特征向量,经过Dropout和残差输出相加,进一步Norm 处理,最终经过多层感知机模块(MLP block)获得分类特征.MLP block主要由全连接层、GELU 激活函数和Dropout 层组成,序列向量经过MSA 融合特征信息,最终选择一项特征作为全局特征送入MLP 中进行分类.
2 DS-YOLOv5 模型网络结构与工作流程
2.1 YOLOv5 模型结构
2.1.1 Backbone
模块如图2 所示C3TR 模块结构图,将原C3残差模块中的Resunit 替换为Transformer 模块,C3TR模块由卷积层和Transformer block 经Concat 操作构成,由于模块参数复杂度过高,为了降低训练成本仅在YOLOv5 主干网络的最后一个阶段进行加强特征提取,图2 中模块中k、s、n分别代表卷积神经网络卷积核、步长以及包含Bottleneck 的数量,T 代表C3 中设有残差模块,F 代表C3 中没有残差模块.同时在研究中发现Norm 能削弱模型的特征表征能力,如图3 所示,将Transformer 简化成图3 的Transformer block,首先去除MSA 和MLP模块后的归一化处理,仅使用Dropout 加速网络收敛;其次MLP block 去除激活函数,使用全连接层和Dropout 进行分类处理,可加强特征全局表达的能力,同时降低一定计算成本.简化后Transformer block 减少了计算量,同时可以加强捕获全局特征的能力,其多头注意力机制还可以获得上下文的语义信息,对于低分辨率图像有良好的处理能力,可以应对小目标的特征提取.
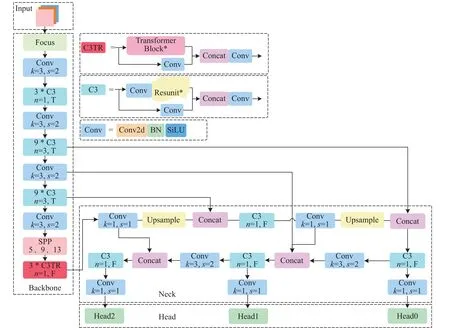
图2 改进的YOLOv5 的网络结构Fig.2 Improved network architecture of YOLOv5
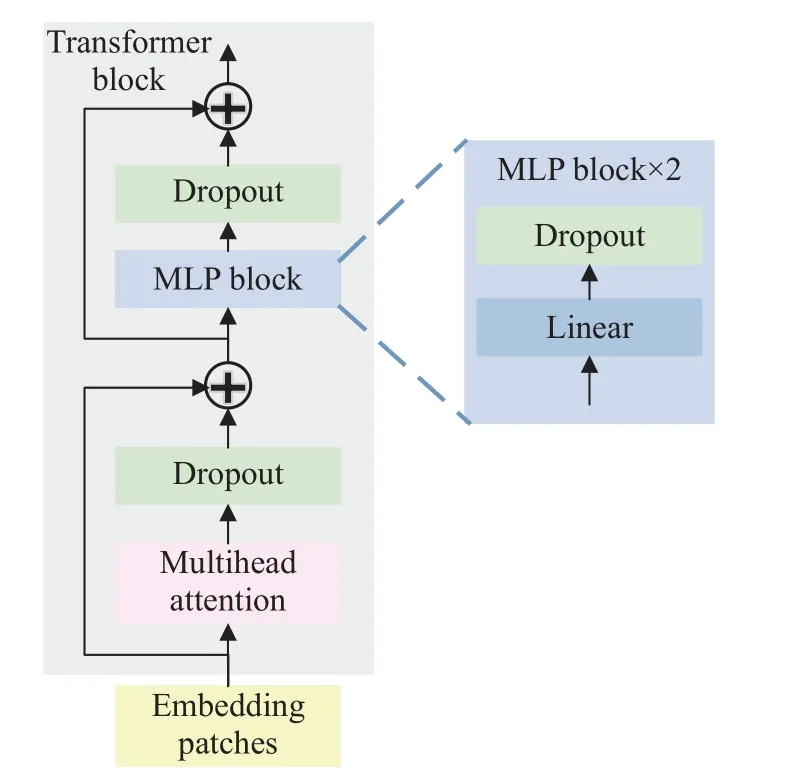
图3 Transformer 模块Fig.3 Transformer block
2.1.2 Neck
传统的PANet 可融合不同层级间的特征且各层级是逐级通道顺序连接,这种结构忽略了不相邻层级之间的特征信息关系,遗失细节信息.本文使用BiFPN[25]对提取的特征进行跨层级融合,通过对特征赋予不同的权重进行有重点的融合,可增强对有益特征的针对性,同时抑制冗余特征的干扰.图4 为PANet 和BiFPN 实现不同层级特征传递与融合的示意图,自下到上为3~7 层特征图(P3~P7),(a)是PANet 结构,(b)是BiFPN 结构.
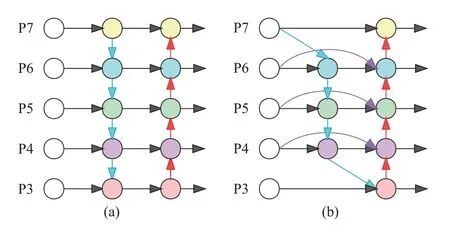
图4 PANet 与BiFPN 结构示意图.(a) PANet; (b) BiFPNFig.4 Schematic diagram of the Path Aggregation Network and bidirectional feature pyramid network structures: (a) PANet; (b) BiFPN
BiFPN 实现了深浅层特征双向融合,跨尺度残差连接增强不同网络层之间特征信息的传递,有利于小尺寸安全帽的特征学习,而且与PANet 相比,它移出了没有特征融合的节点,进一步减少模型的计算量.此外,BiFPN 针对特征融合增加了一个可学习的权重,可以有效聚合不同尺度的特征并进行特征输出.BiFPN 以更轻量的结构同时提升模型对有益特征的敏感性,带来模型性能的提升.
2.2 DS-YOLOv5 工作流程
DS-YOLOv5 模型的工作流程:首先利用带标签的安全帽数据集,对YOLOv5 网络和改进的Deep SORT 特征提取网络分别进行训练得到安全帽检测模型和安全帽特征模型,为视频序列的检测识别做好模型权重.最后,将待检测视频输入YOLOv5进行检测,得到安全帽的检测框信息和分类信息,再将检测框送入改进的Deep SORT 进行特征提取进行建模标准化,对目标轨迹进行卡尔曼预测和更新,经过级联匹配和IOU 匹配得到跟踪结果,输出安全帽位置信息和类别信息.
3 实验与分析
为了验证DS-YOLOv5 模型的性能,本文采用GDUT-HWD 数据集进行测试.GDUT-HWD 数据集考虑包括场景、照明、个人姿态和遮挡等复杂环境,包含3174 张图像,18893 个实例,小目标实例数占比达到了47.4%,环境更复杂、分类更精细.实验的硬件配置为Intel(R) Xeon(R) Silver 4210R CPU @ 2.40 GHz 和2.39 GHz NVIDIA GTX1070GPU,模型搭建在Pytorch 深度学习框架.所有YOLO 模型的训练最大周期为300,Batch-size 为8,学习率为0.0001,在训练过程中采用早停策略避免过拟合.评价指标采用多个定量指标,分别为精确率P、召回率R、F1分值、平均精确度AP 和全类平均精度mAP和每次迭代花费的时间Spend Time.各指标的定义如下:
式中,真阳性(True positive, TP)代表实际为正例,预测为正;真阴性(True negative, TN)实际为负例,预测为负;假阳性(False positive, FP)为实际为负例,预测为正;假阴性(False negative, FN)实际为正例,预测为负.一般来说精确度和召回率是互相矛盾的两个值,定义F1说明了精确度和召回率的实际平均情况,公式为:
对于数据集给定的类别,先得到其精确率/召回率(P/R)曲线,平均精确度AP 为使用积分法计算P/R曲线与坐标轴所围面积,mAP 是将AP 进行加权平均而得到,评价指标AP 和mAP 计算方法如公式(10)和(11)所示:
式中,P(R)是关于P和R函数关系,class 表示检测数据集的类别数.
3.1 消融实验
消融实验基于YOLOv5 模型为基础模型,对Deep SORT、BiFPN 结构、Transformer 模块和Deep SORT 进行分析,了解各模块对模型性能提升起到的作用以及结构改进的有效性.
表1 列出了在GDUT-HWD 数据集上的消融实验结果,可以看到,加入Transformer、BiFPN 和Deep SORT 分别使mAP 提升1.2%、1.4%和0.8%,最终模型mAP 提升了3%.加入Transformer 的模型召回率有明显的提高,进一步证明本模块对捕获全局特征有良好能力,减少小目标漏检情况.Deep SORT模型将使用视频图像验证其识别跟踪可靠性.F1反映出模型精度和召回率的实际平均情况,本模型加入BiFPN 和Transformer 后F1下降1.7%,仍比YOLOv5 原模型提高了2.2%,mAP 能达到95.5%,此时模型检测精度最高.根据消融实验结果,增加模块后网络复杂度增加,Spend Time 也随之增加,而使用BiFPN 模块后可以比原模型节约3%的训练时间.我们将表1 中的最后一组模型称为DS-YOLOv5.
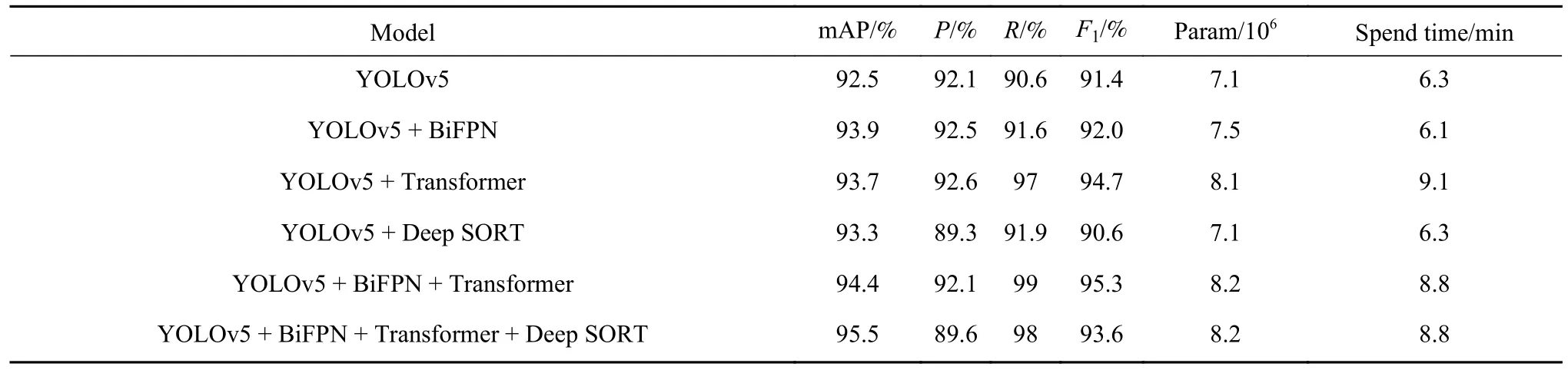
表1 基于GDUT-HWD 数据集的消融实验结果Table 1 Results of the ablation experiments based on the GDUT-HWD dataset
如表2 对改进前后Deep SORT 跟踪性能对比.使用行人数据集Market-1501 对改进的Deep SORT重识别网络进行训练,训练集包含了751 个类别行人[26].表2 中评价指标MOTA(Multi-object tracking accuracy)为衡量跟踪器的准确率,MOTP (Multiobject tracking precision)为检测器的准确率,IDs(Identity switch)为Ground Truth 分配ID 发生切换的次数(表中向上箭头表示值越大性能越好,向下箭头表示值越小性能越好).实验结果可以看到MOTA提高了2.7,IDs 在原有基础上降低的16%.

表2 Deep SORT 改进前后的实验结果对比Table 2 Comparison results for improved Deep SORT
为了验证模型的可靠性,使用MOT16 训练集中视频MOT16-09 对改进前后Deep SORT 进行跟踪性能测试[27],对测试的MOT16-09 视频每10 帧抽取一次,Deep SORT 改进前后在MOT16-09 测试对比如图5 所示,可视化中展示了三个场景,图5 (a)和(d)为场景1、图5 (b)和(e)为场景2、图5 (c)和(f)为场景3.场景1 中,改进的模型检测到左下角漏检目标并修正了(a)中与背景相似误判为蓝色安全帽的小目标;场景2 中,面对右侧密集且互相遮挡的小目标,改进后的算法几乎无漏检情况;场景3 中,对白色头发的目标,改进的算法修正了原算法误判的白色安全帽的检测.可以看到改进后的Deep SORT 在跟踪性能得到改善,可以应对实时检测中目标被遮挡或多目标、小目标的情况.

图5 Deep SORT 与改进模型在MOT16-09 测试对比.(a) Deep SORT 在场景 1 的检测结果; (b) Deep SORT 在场景 2 的检测结果; (c) Deep SORT 在场景 3 的检测结果; (d)改进模型在场景 1 的检测结果; (e)改进模型在场景 2 的检测结果; (f)改进模型在场景 3 的检测结果Fig.5 Comparison of Deep SORT and improved Deep SORT in MOT16-09 detection: (a) detection results of Deep SORT in scenario 1; (b) detection results of Deep SORT in scenario 2; (c) detection results of Deep SORT in scenario 3; (d) detection results of improved Deep SORT in scenario 1;(e) detection results of improved Deep SORT in scenario2; (f) detection results of improved Deep SORT in scenario 3
3.2 对比实验
本节使用五种单阶段算法和现有的安全帽识别方法进行对比实验,表3 列出了5 种算法在GDUT-HWD 数据集上的检测与识别指标.表中的PRed、PWhite、PYellow和PBlue分别代表佩戴红色、白色、黄色和蓝色安全帽的准确率,PNone表示未佩戴安全帽的准确率,P表示模型检测精度,R为模型召回率,Weight 为模型权重大小,Time 为单张图片检测时间,fps 表示模型部署在开发板Jetson Xavier NX上每秒能检测的帧数.在输入端,YOLOv3 系列的图像分辨率为416×416,YOLOv4 和YOLOv5 图像分辨率为640×640.YOLOv3-tiny 速度更快,但各项指标均低于其他YOLO 系列模型.YOLOv4 召回率仅为81.1%,在实际检测中不能检测到所有安全帽,模型权重237.4 MB,模型训练时间长且难以部署.在本实验进行对比的“单阶段”算法中,YOLOv5模型为最轻量、检测效率最好的模型,原模型权重仅有14.2 MB,在测试集平均每张检测时间2 ms,改进后的DS-YOLOv5 以少量的参数数量和计算量为代价,提高了3%的检测精度,本模型mAP 值和召回率都处于领先地位.

表3 基于GDUT 数据集的对比实验结果Table 3 Results of comparison experiments based on the GDUT dataset
对比实验中使用模型在主机上测试单张检测时间和模型在嵌入式开发板Jetson Xavier NX 部署测得的fps,对模型效率和实用性进行直观表示.SSD 和YOLOv4 因网络结构和模型过大难以在嵌入式设备进行检测,YOLOv3-tiny 的检测速度优于YOLOv3 模型,YOLOv4 由于模型过大,难以在开发板上实现实时检测.YOLOv5 模型部署后fps 可以达到25,本模型在改进后fps 为18.对于非节奏极其快速的场景视频外,fps 达到15 是保持视频画面连续的最低帧率.参数增加在一定程度影响DSYOLOv5 模型的检测速度,但仍能达到视频检测的需求.
为了验证DS-YOLOv5 有效性,将DS-YOLOv5模型与研究安全帽检测工作[8-9,28-29]中所提及的模型在GDUT 测试集上进行对比实验,从表4 中可以看到,对比其他模型DS-YOLOv5 的mAP 分别提升了10.8%、1.8%、2.4%和9.4%.最新的YOLOXs在准确率上处于领先地位,但本模型的召回率和mAP值最高.模型检测速度与模型大小决定了模型是否很好地应用于实际场景下,在表4 中可以看到DS-YOLOv5 模型不论是在模型大小、模型参数或检测时间上都有明显优势,模型参数量小代表模型空间复杂度低,有利于在边缘化设备进行部署,实验中YOLO 系列和改进的MobileNet-SSD 网络参数量有明显优势,DS-YOLOv5 模型仅比文献[9]模型参数量多0.1 MB.DS-YOLOv5 模型大小为各文献模型的1%、45%、43%和64%,本模型网络参数量较小且性能优越,可满足工业场景下的实时性要求.
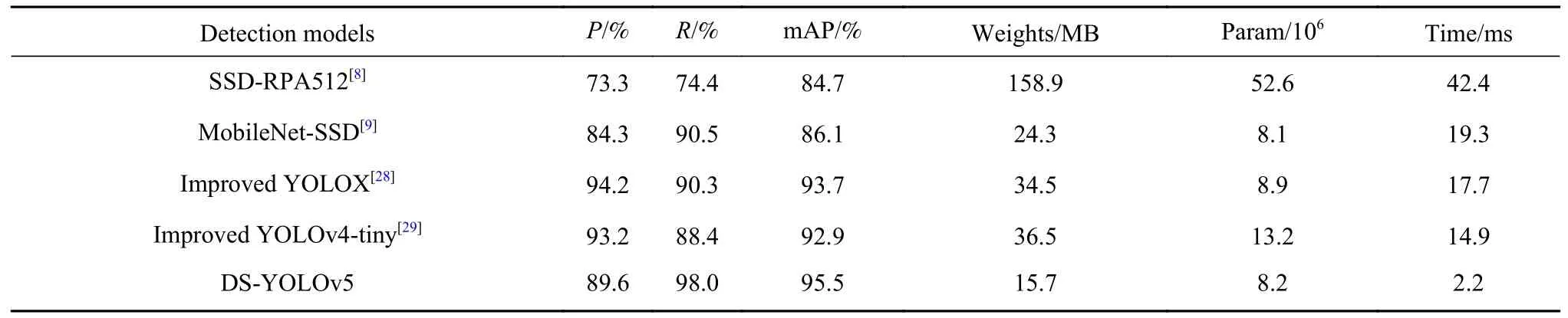
表4 安全帽检测模型对比实验Table 4 Results of the comparison of different safety helmet detection models
图6 给出了几种复杂环境下DS-YOLOv5 模型对安全帽佩戴情况检测与识别结果.图中展示被检测安全帽的检测框、分类和置信度分数,其中图6(a)光线不足场景;图6 (b) 在多个目标互相遮挡场景;图6(c)由于拍摄距离造成安全帽尺度差异场景,检测结果表明DS-YOLOv5 融合多尺度特征对特征学习充分,在图6 (a)光线不足的环境下仍能得到正确的检测结果,加入改进的Deep SORT有利于应对遮挡情况和尺寸差异较大的目标,在图6 (b)中正确检测目标遮挡将近1/2 的None 标签,在图6 (c)中三个尺度差异较大的目标能正确检测并识别.在图5 中视频检测和图6 中复杂环境的图像检测中,分别展示了包含光线不足、小目标、多目标、遮挡、目标与背景色相似的例子,DSYOLOv5 模型表现稳定,可以适应复杂环境下的安全帽检测.

图6 复杂环境下DS-YOLOv5 对安全帽佩戴情况检测与识别结果.(a) 光线不足; (b) 遮挡情况; (c) 目标尺度差异Fig.6 Detection and recognition results of the DS-YOLOv5 model for the wearing of safety helmets in complex environments: (a) underlighting conditions; (b) occlusion conditions; (c) different target scales
4 结论
本文针对复杂环境下安全帽佩戴情况的实时检测与识别任务,以YOLOv5 模型为基础网络,提出结合Deep SORT 多目标跟踪,融合BiFPN 和Transformer 注意力机制的DS-YOLOv5 安全帽检测与识别模型.在GDUT-HWD 数据集对比实验和消融实验结果表明,DS-YOLOv5 模型可以有效提升安全帽佩戴情况检测的准确性、鲁棒性和实时性.而且,DS-YOLOv5 模型可以有效应对包括亮度变化、多目标等复杂环境的影响.下一步,我们将对该模型进行轻量化设计并移植到边缘化设备,以便将其应用于生产和施工现场对安全帽佩戴情况进行实时检测与识别.
猜你喜欢
机电安全(2022年4期)2022-08-27
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
疯狂英语·新策略(2019年10期)2019-12-13
课外生活·趣知识(2019年4期)2019-09-10
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
河南科技(2014年23期)2014-02-27
华东理工大学学报(自然科学版)(2014年3期)2014-02-27
中国石油石化(2014年4期)2014-01-27
