
中文句子级性别无偏数据集构建及预训练语言模型的性别偏度评估
2023-12-06 02:41赵继舜杜冰洁刘鹏远朱述承
中文信息学报 2023年9期
赵继舜, 杜冰洁, 刘鹏远,2,朱述承,3
(1.北京语言大学 信息科学学院,北京 100083;2. 北京语言大学 国家语言资源监测与研究平面媒体中心,北京 100083;3. 清华大学 人文学院,北京 100084)
0 引言
2013年的诺贝尔文学奖得主,加拿大短篇小说家爱丽丝门罗在其短篇小说集《幸福过了头》中写道: “永远要记得,男人走出房间,他就把一切都留在房间里了。而女人出门时,她就把房间里发生的一切都随身带走了。”可见,在每个人的认知中,我们都对男性和女性赋予了一定的主观认知。性别偏见(Gender Bias)是指对一种性别产生的有利或者不利的情绪[1]。性别偏见广泛存在于社会认知中。语言作为人类交流的工具,不可避免地继承了社会中的性别偏见[2]。随着科技的发展,用计算机表示文本语言的技术愈发成熟。 预训练语言模型作为一种强大的文本表示方式,在从海量的文本中自动学习语言表示的同时,也不可避免地学到了文本中存在的性别偏见[3-4]。而语言模型中学习到的性别偏见会影响下游任务及应用中的性能[5];在一个愈发追求公平的社会中,识别和消除这些不公平的偏见具有十分重要的意义。
目前,许多学者设计了性别无偏数据集用于特定自然语言处理任务中的性别偏见评价和消偏工作[6-8]。然而,这些数据集中的语料均为人工标注,时间和金钱成本高昂,且不能反映语言的自然使用情况;其次,这些数据集多是基于英语等印欧语系的,缺少专门针对汉语的性别偏见数据集。汉语作为全球使用人口数量最多的语言,与英语等屈折语有很大区别,且语言中缺乏明显的性别标记,因此汉语中的性别偏见更加难以捕捉。基于此,我们希望以尽可能低的成本建立一个自然的、通用的中文性别无偏数据集。在测量和评估预训练语言模型的偏见程度上,研究者们也采取了各种方法进行尝试,并发现预训练语言模型中广泛存在着性别偏见[9]。但是,这些性别偏见的评价方法也存在一定问题: 一是大多数方法采用间接的评价方式,如采用性别中的职业关键词汇为指标,不能直接衡量模型对于语境中性别偏见的学习程度;二是其他语言与汉语在语法和结构上存在差异,产生的偏见可能有所不同,但是还没有工作对中文预训练语言模型进行性别偏见评价。因此,本文希望设计一个简单的、适用于不同语言的性别偏见评价指标,以评价不同预训练语言模型中语境的性别偏见程度。
本文的基本假设是,一个理想的性别无偏且有意义的语言模型,在一个语境性别中立的句子中,生成遮盖掉特定性别关键词的概率与其对立性别关键词的概率应该是相同的。基于此,本文设计了一系列步骤构建了一个句子级的性别无偏中文数据集SlguSet(Sentence-level Gender-unbiased Dataset),并在该数据集上对不同的预训练语言模型中的性别偏见进行评价,如图1所示。首先,我们从中国主流报纸动态流通语料库(DCC)中,通过性别关键词找到有关性别主体的句子,并基于规则自动过滤掉无关的句子和含有显性性别倾向的句子,再通过人工复查筛选出符合标准的性别无偏句子,建立一个句子级别的中文数据集SlguSet。随后,采用掩码语言模型,以完形填空的形式,把句子中的性别关键字遮盖掉,剩下的句子部分在语境上应为性别中立的。最后,将句子输入到模型中,利用预训练语言模型的掩码语言模型机制预测被遮盖位置上字的概率,比较性别关键词对的概率差异就可以得到该模型对该语境的性别偏见程度。
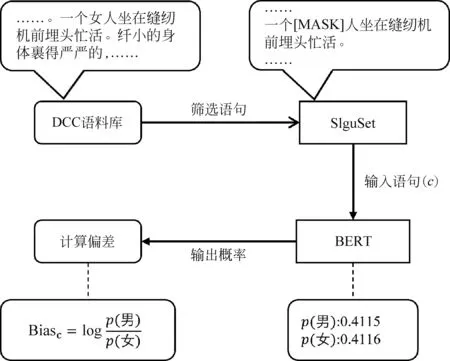
图1 本文工作示意图
1 相关工作
1.1 自然语言处理中性别偏见的产生和分类
导致自然语言处理模型产生性别偏见的最主要原因是数据本身,因为含有不同性别的数据是不平衡的。例如,一些常用的共指消解数据集中男性数据要多于女性数据,导致系统产生有利于男性的偏见[6]。数据中存在的偏见,其实反映出的是人类社会中的偏见认知,目前应用很广的词嵌入中具有偏见,便是因为其训练的语料库中本身就具有社会文化中的刻板印象[10]。另外,算法也可能会放大数据中的性别偏见,因为算法通常会最大化地拟合训练数据以提高准确率,如果数据本身不平衡,那么算法就会对出现更多的数据给予更高的关注,最终导致结果中出现性别偏见[11]。不同学者对自然语言处理中的性别偏见分类也有区别。性别偏见可分为结构性性别偏见(Structural Bias)和语境中的性别偏见(Contextual Bias)[12]。前者指语言中的性别标记对语言模型的影响,例如,模型可能会将“policeman”更加倾向于识别为男性因为其中包含男性词“man”;后者指模型从具体语境中学习到的人类认知中的性别刻板印象,如“男孩子都是好斗的”。性别偏见又可分为分配性偏见和表征性偏见[13]。就自然语言处理系统而言,模型在数据较多的一方效果会更好,这种偏见就是分配性偏见;与性别关键词产生关联时,这种偏见就是表征性偏见。
1.2 自然语言处理中性别偏见的评价和消除
在意识到自然语言处理模型中存在性别偏见之后,学者们采用不同的方式去刻画和评估不同系统中的性别偏见。常见的方法包括: 通过分析词嵌入中的性别子空间,计算性别中性词的偏见程度[3];采用内隐联想测验的核心理念,用词嵌入联想测试来衡量词嵌入中的性别偏见[14];采用性别词转换的差异衡量模型的偏见程度[7]。此外,针对不同的任务,学者们也提出了一系列具有针对性的性别偏见评价方法。例如,使用一个英语自然数据集StereoSet评价BERT、RoBERTa等模型的偏见[15]。自然语言处理中性别偏见消除的方法是在评价了词嵌入中的性别偏见后发展起来的,主要有两条思路: 其一是从机器产生偏见的源头出发,构建无偏数据集让机器学习。其中,采用数据增强和性别交换的方式可以构建性别平衡的数据集,再训练模型消除性别偏见,此方法比性别偏见微调更加有效[16]。其二是从算法的角度消除偏见,如“硬去偏”方法可以在保持嵌入有用的性质的同时,仅使用少量的训练样本从中性词中去除性别成分以减小性别偏见[3];“对抗学习”的方法也在性别偏见消除任务中被应用[17]。但是,这些去偏方法并不能完全去除模型中的偏见[18]。
1.3 自然语言处理中性别偏见相关数据集的构建
通过设计性别偏见评价测试集可以衡量自然语言处理系统的性别偏见,目前性别偏见评价测试集按照任务分类主要有: 在指代消解任务上的GAP[6]、WinoBias[7]、Winogender Schemas[9];在情感分析任务上EEC[19];在机器翻译任务上的数据集GeBioCorpus[8];对于汉语中形容词性别偏度数据集AGSS[20]。但是以上数据集的适用范围小,如Winogender Schemas和WinoBias只能衡量性别中立职业词汇的偏见程度,而且数据规模小,Winogender Schemas只有720条英语句子,WinoBias中有3 160条英语句子,AGSS中有446个形容词;语料类型也都是基于英语和其他印欧语系语言的,缺乏中文性别偏见的数据集。
2 数据集构建
性别无偏中性句子的形式为: 句中需含语义上表示性别的性别关键字,其对立关键字形式是一样的,当遮盖掉性别关键字时,根据上下文语义,遮盖掉的部分填入女性或者男性性别关键字的概率是一致的。例如,“重庆女足在运动会上击败了山东队取得了第二名的成绩。”该句中包含了性别关键字“女”,用其对立关键字“男”替换后句子同样是成立的。在这里,性别称谓词是表示特定性别而无需上下文的词。我们对汉语中的性别称谓词进行了统计,并结合了英语相关任务[15]和本文的具体任务,最终确定了如表1所示的16对性别关键词。
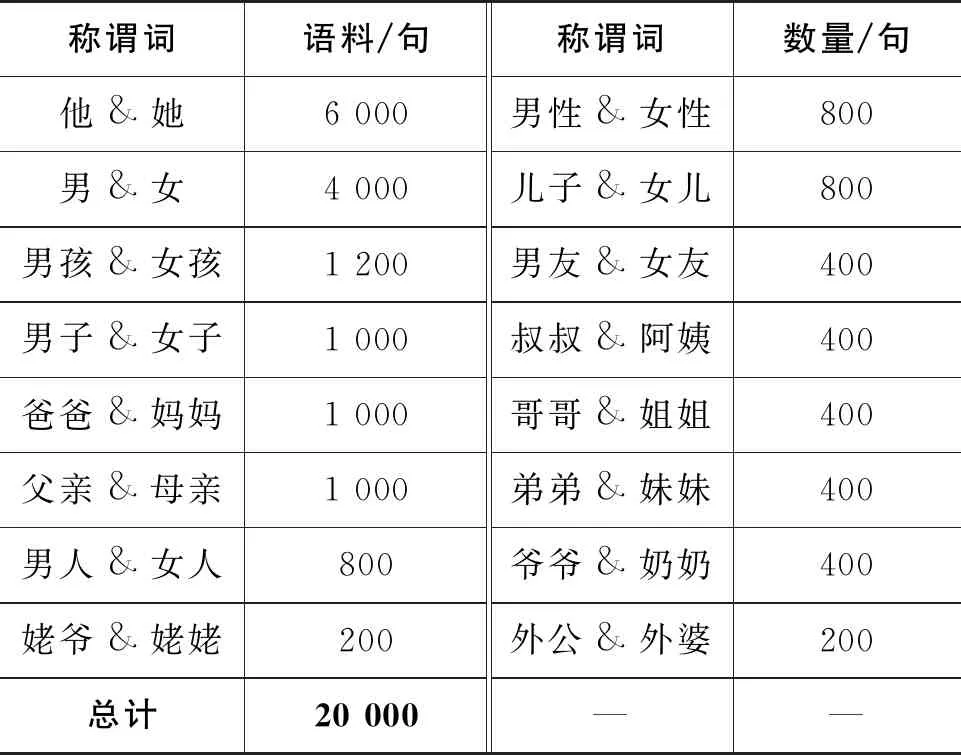
表1 数据集中各性别称谓词的数量分布
2.1 数据选择
新闻一般被认为是有较少偏见的语料。因此,我们选择了国家语言资源动态流通语料库(DCC),该语料库总规模为100亿字次,涵盖十年以上完整语料。我们从中选择了2018至2019年的平面媒体(报纸)语料作为原始语料,根据中文词汇使用情况以及确定的性别称谓词并按照句末标点“。”、“?”和“!”抽取句子。
2.2 筛选流程
预处理所有文本都经过预处理,被分割成句子,保留标点符号、数字和中文字符。所有文本都采用UTF-8编码的文本格式,删除了所有文档格式化的缩进、空格。按照句末标点抽取,缺失或多余的引号部分,在抽取的过程中进行补全或删除,以保证符号的正确。
自动过滤首先,我们对句子分词,过滤掉含有非语义上性别关键字的句子。例如,“吉他”“他杀”“子女”“生儿育女”“儿女”等非性别关键字。然后,利用命名实体识别筛除含有姓名(如“小明”“琳琳”“妞妞”)的句子。
人工标注我们选择了三位语言学及应用语言学专业硕士研究生,根据下文中的筛选标准以及表 1的各种性别称谓词目标语料数量,按照一致率100%来筛选句子。
2.3 筛选标准
首先,我们随机选择了1 000条关键词句子,通过对真实语料的观察确定筛选标准。在筛选的过程中发现语料存在下列情况:
(1) 有些关键词在语境中的对立性别词在语义上并非表达原始含义。例如,在“男”的句子中,存在“男儿”这样的表达,其含义指男性,而性别对立的“女儿”则多出了“子女”的含义,但其对应的词是“儿子”。
(2) 句子中性别称谓词与性别术语有语义上的互指关系。例如,“找到内蒙古,见弟弟冬天穿了一条多处破洞的单裤,双手满是冻裂的口子,兄弟俩抱头痛哭。”此句子中,“弟弟”和“兄弟”存在联系,这种形式的句子会透露性别信息。
(3) 句子中含有生物性别信息。例如,“女职工在经期、孕期、产期、哺乳期依法享受特殊保护。”
根据上述特殊情况,最终确立筛选标准如下:
(1) 句子中遮挡掉性别关键词后,根据上下文语义,填入男性或者女性性别关键词都是合理的,且这对性别关键词仅在性别语义上对立;
(2) 筛除性别称谓词与性别术语在语义上有互指关系的句子;
(3) 筛除性别称谓词与生物性别信息在语义上有互指关系的句子。
2.4 数据集结果
根据上述标准,我们筛选出近两万条新闻语料句子作为数据集。BERT中文版模型的字表大小为21 128[21]。统计了本文的数据集后发现含有4 220个字符(含数字、标点符号和汉字)。因此,我们的数据集仅占BERT字表中19.97%的字符。考虑到BERT字表中含有更多的外文及其他特殊字符,我们可以假设此数据集涵盖大部分常用中文字符。
3 实验设计
3.1 预训练模型
我们选择了BERT、RoBERTa和ELECTRA三种主要的中文预训练语言模型对数据集语境中的性别偏见进行评价。下面简要介绍每种模型:
BERT我们选择BERT-base,Chinese[21]作为基准测试模型。BERT的预训练任务为掩码语言模型(Masked Language Model,MLM)和下一句子预测(Next Sentence Prediction,NSP)。BERT中文模型是以字为粒度进行切分的,训练时随机遮盖一些输入的字符,目标是通过遮盖的上下文预测遮盖的单词。BERT-wwm、BERT-wwm-ext[22]采用与原始BERT同样的模型架构,但是采用全词遮盖代替单字遮盖的方式,BERT-wwm-ext扩展了训练语料库中文维基百科的语料,加入了其他百科、新闻、问答等语料数据。
RoBERTa修改了一些原始BERT的模型结构,并扩展了训练语料库后,RoBERTa模型采用了延长模型训练时间等一系列模型改进的方法,发现可以提升模型效果。本文测试的模型为RoBERTa-wwm-ext中文版本[23]。
ELECTRA采用了一种新的预训练方法—替换词检测(Replaced Token Detection,RTD)。ELECTRA的性能相比BERT和RoBERTa都有提升,且计算量更小。本文测试模型为ELECTRA-base中文版本[23]。因此,我们选择了表2中的5种模型进行测试。

表2 本文选择的预训练模型及参数
3.2 评价指标
在评价性别偏见的程度上,有学者采用对立关键词之比的对数来评估一句话的偏见程度[4]。本文借鉴了这一共识,但由于其任务与我们的稍有不同,所以采用式(1)来衡量模型预测句子c的偏见。
(1)
其中,c代表性别无偏的中性句子,pwoman(c)和pman(c)分别代表模型预测句子c中性别关键词为女性和男性的概率。Biasc∈(-∞, ∞),Biasc>0 时,模型预测偏向男性;Biasc<0时,模型预测偏向女性,Biasc=0时模型预测此句为无性别偏见的中性句子。我们用式(2)来计算模型偏向男性或者女性的程度。
(2)
其中,N表示句子的总数。
4 结果分析
4.1 预训练模型评价
首先,我们绘制了所选择的5个中文预训练模型对每一个句子预测的性别偏见程度分布图, 如图2所示。我们所选择的5个中文预训练模型主要还是集中在预测中性的语境趋势上。但对于一些句子,模型预测还是一致偏向男性或女性,说明中文预训练模型学习到了这些句子中强烈的偏向男性或女性的语境。
之后,我们对5个中文预训练模型关于每条句子预测的性别偏见程度进行了相关性分析,结果如图3所示。从中我们可以看出,这5个预训练模型具有一致性,即它们预测句子偏向男性或女性的性能是相似的,但其中ELECTRA-base与其他模型的差异较大。

图3 5个预训练模型对每个句子预测的性别偏见程度相关性热力图
具体的每个预训练模型的偏见结果如表3所示。观察结果可以发现: 偏向男性程度最高的模型是BERT-wwm-ext模型,偏向女性程度最高的是RoBERTa-wwm-ext模型;平均性别偏见程度最高的是BERT-wwm-ext模型,ELECTRA-base的偏见最小;在BERT-base、BERTwwm、RoBERTa-wwm-ext和ELECTRA-base模型上,偏向女性的程度要高于男性,BERT-wwm-ext上男女偏向程度很接近;其他条件相同时,对比BERT-base和BERT-wwm可以发现,模型预训练采用单字遮盖方式产生的性别偏见略小一点;BERT-wwm-ext相对于BERT-wwm预训练采用的语料更大,但是偏见却也略大一点;RoBERTa-wwm-ext相对于BERT-base的性能更好一点,但是偏见却也是略大一点;相对于其他模型,ELECTRA-base的性能和偏见效果都是最好的。

表3 5种预训练模型的偏见评价
从BERT-base模型的预测结果中分别筛选出偏向“男性”和偏向“女性”程度最大的前5句,如表4和表5所示。从中我们可以看出,语言模型学习了汉语中的某些刻板印象,男性总是与领导地位、工作、金钱关系有某种隐喻关联,而女性则与爱美、食物和外貌有关联。

表4 BERT-base预测结果偏向“男性”最大的5条数据

表5 BERT-base预测结果偏向“女性”最大的5条数据
4.2 偏向男性和女性句子的主题词分析
明显偏见我们定义: 对于|Biasc|>0.3的句子,模型对其预测产生了明显偏见。我们从BERT-base模型的预测结果中筛选后发现|Biasc|<0.3的句子有7 223句, Biasc>0.3的有6 024句,Biasc<-0.3的有6 743句。利用TF-IDF算法和TextRank算法对明显偏向女性和男性的句子分别做主题词分析,前5个主题词如表6所示。偏向女性语句的主题词排在首位的分别为“孩子”和“孩子”,而偏向男性句子的则为“一名”和“工作”。这也印证了“男主外,女主内”的汉语文化圈的性别刻板印象。
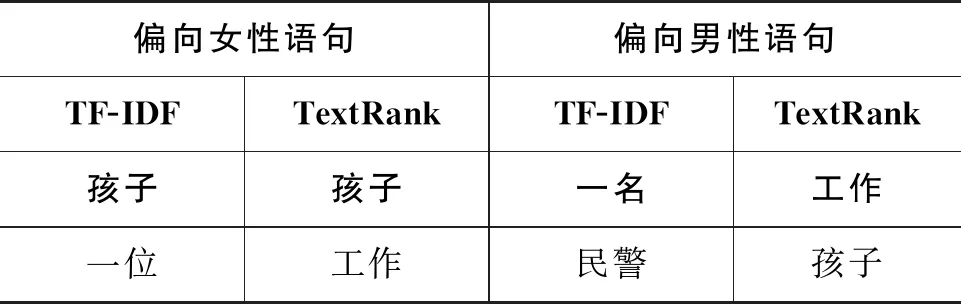
表6 偏向“女性”和“男性”的语句主题词分析前5的主题词
4.3 案例研究: 模型对“男童”和“女童”的偏见分析
我们选择了“男女”关键词对中含有“男童”和“女童”的句子。从结果中筛选出偏向“男童”的有78条句子,偏向“女童”的有158条句子。按照偏见程度排序,其中偏向“男”和“女”的前六句,结果分别如表7和表8所示。对比偏向“男童”和“女童”的句子语境我们发现了与之前类似的情况,偏向“男童”的语境与“调皮”“闯祸”和“意外受伤”等信息有关,而偏向到“女童”的句子则反映了女性儿童“需要保护”和“被性侵”等情况,这说明BERT-base模型学到了文本中的深层次的语境偏见信息。

表7 BERT-base预测结果偏向“男童”程度最大的5条数据

表8 BERT-base预测结果偏向“女童”程度最大的5条数据
5 结论
本文基于“句子语境性别中立时,模型对于性别关键词预测应该是中立”的假设,通过平面媒体语料库构建了一个句子级别上下文无偏的中文性别平衡数据集。我们创造性地提出了基于掩码语言模型的中文预训练语言模型的性别偏见量化分析方法,即采用完形填空的方式,让模型预测性别中性句子中性别关键词的概率。采用我们设计的评估公式对模型生成的两个性别关键词的概率进行计算,最后得到模型的性别偏见程度。从分析结果可以发现,基于本文提出的中文性别平衡数据集,基于掩码语言模型的中文预训练语言模型普遍存在不同程度的性别偏见,模型偏向女性的程度要略高于男性,而且模型学到了汉语中深层次的刻板印象,但是本文实验尚不足以说明模型偏见产生的原因。在未来的工作中,分析模型偏见产生的原因、偏见的类型以及如何去除这些偏见是有意义的工作。由于我们只设计了如何测试基于掩码语言模型的中文预训练语言模型的偏见程度,而其他类型的预训练模型如何更好地测量偏见程度值得进一步研究。
猜你喜欢
心理学报(2022年1期)2022-01-21
当代陕西(2020年23期)2021-01-07
文苑(2020年4期)2020-05-30
当代陕西(2019年12期)2019-07-12
小学生作文(中高年级适用)(2018年3期)2018-04-18
海外华文教育(2016年1期)2017-01-20
华北电力大学学报(社会科学版)(2016年4期)2016-12-01
当代教育理论与实践(2015年9期)2015-12-16
少儿科学周刊·少年版(2015年4期)2015-07-07
当代经济科学(2015年2期)2015-02-03
