
融合语法及结构特征的汉老双语句子相似度计算方法
2023-12-06 02:41周蕾越周兰江
中文信息学报 2023年9期
雷 歆, 周蕾越, 周兰江
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学 智能信息处理重点实验室,云南 昆明 650500;3.昆明理工大学津桥学院 电气与信息工程学院,云南 昆明 650500)
0 引言
老挝属社会主义国家,与我国云南省接壤。2021年是中老建交60周年,两国关系经历了国际社会不断变化的考验,中老两国是具有战略意义的命运共同体。2021年12月3日,习近平总书记与老挝国家主席通伦举行了视频会晤,以视频连线的方式一同见证中老铁路正式通车。中老铁路的正式开通标志着老挝成为“一带一路”倡议的纽带,因此开展老挝语自然语言处理工作对两国政治、经济上的交流具有极其重要的推进作用。跨语言句子相似度计算指的是双语句子的语义相似程度,汉老双语句子相似度计算是机器翻译、双语语料库构建和双语跨语言信息检索等的核心技术之一。
句子相似度计算的方法目前主要包含基于字符串的方法、基于知识库的方法和基于语料库的方法。其中基于知识库的方法分为基于本体与基于网络知识两种,基于语料库的方法分为基于词袋模型,基于搜索引擎和基于神经网络三种;在基于字符串的方法中,相似度计算只停留在原始的表面层次上。在类似于应用语义词典的基于本体的方法中,语义词典构建的质量对相似度评估性能的影响显著,其无法适应随着时代发展而产生出的众多新词,而且它几乎没有考虑到词法与句法因素;在基于网络知识的方法中,处理数据噪声十分困难,且结构层次不如语义词典;在基于主题模型的方法中,它的语义表征还不够充分,同时需要大规模平行语料库;在基于搜索引擎的方法中,处理网页的质量则不尽相同。
随着计算机硬件的发展和算力的大幅度提升,在基于语料库的方法中,利用神经网络的方法受到了学者们的广泛关注与研究。对于跨语言句子相似度的研究多是将语料进行分布式表达,映射到向量空间中,然后连接神经网络提取语料中丰富的特征来进行相似度计算。
老挝语在时态的表达上有带着标记的清晰的语序结构,同时在定语的位置表示上也有着特征标记。本文利用老挝语中含有众多标记的语言学特点,根据老挝语中的标记与汉语中具有标记作用的结构,设置了汉老时态标签与定语标签,然后将特征融入双语向量空间表征中。接着连入三种不同尺度的卷积神经网络(Convolutional Neural Networks, CNN)与双向门控循环单元(Bi-Gated Recurrent Units,BiGRU),CNN能更好地提取句子中的局部特征,BiGRU能更好地提取句子中的长距离特征。将提取完特征的双语信息连入局部推理的交互聚合结构,该机制利用差异计算来进行局部推理,使汉老双语信息进行交互,最终计算出汉老双语句子的相似度分数。老挝语属于低资源语言,对比目前学界使用的主流方法,本实验在利用有限的语料的情况下取得了突出的表现。
本文的主要贡献如下:
(1) 通过判断双语句子的不同时态及定位定语位置,提出了一种融合语法及结构特征的汉老双语句子相似度计算方法。
(2) 通过一种自学习的无监督方法将双语词语映射到共享的向量空间中。
(3) 通过CNN和BiGRU提取局部特征和长距离特征,加入局部推理的交互聚合结构能够使双语信息进行交互,从而提高汉老跨语言句子相似度计算模型的性能。
本文组织结构如下: 首先在引言部分介绍本文的研究背景及意义,第1部分介绍相关工作,综述句子相似度计算的各种方法及相关文献;第2部分介绍汉老双语的特征选取及表示;第3部分介绍本文使用模型的结构及技术路线;第4部分为本文的实验结果及分析;第5部分为总结与展望。
1 相关工作
句子相似度计算方法目前主要分为基于字符串的方法、基于知识库的方法和基于语料库的方法。
(1)基于字符串的方法其思想主要是直接作用于原始语料中,通过计算语料中不同字符串的匹配程度,如共现程度、重复程度等来度量相似度。俞婷婷等人[1]通过滑动窗口机制将文本分割,计算分割后的k个字符在文本中的频率与权重,通过Jaccard系数来判断两个文本间的相似度;李圣文等人[2]构建文本间的公共字符串,利用它的熵来衡量文本相似度。
(2)基于知识库的方法其思想主要是使用有组织体系的知识库计算句子相似度。在基于本体的方法中,最主要的是基于语义词典来计算相似度,如,石杰等人[3]在汉泰双语语料特征筛选后,利用WordNet把双语文本转换为中间语言,在此基础上进行文本相似度计算;Farouk[4]利用了词序相似度,通过预训练的词向量和WordNet来衡量句子相似度。在基于网络知识的方法中,主要通过维基百科来计算相似度,Zhang等人[5]解决了以往方法中维基百科路径利用不充分的问题,提出了一种双边最短路径算法来计算文本相似度;荆琪等人[6]通过挖掘维基百科的结构特征如摘要中的链接结构等,提出一种相关度结合的词语相似度计算方法,在此基础上,利用主题词权重等特征计算句子相似度。
(3)基于语料库的方法其思想主要是从语料库中找出相关信息,以此来确定句子相似度,其中基于主题模型的方法和基于神经网络的方法最为普遍。主题模型的流行方法是将文本建模到主题空间中,通过Gibbs抽样进行推理,使用Jensen-Shannon距离来计算相似度。程蔚等人[7]首先用双语语料库训练出LDA模型,再结合新语料集在同一映射下的分布,使用余弦相似度计算出汉泰双语文本相似度;Yuan等人[8]通过从维基百科上提取汉藏实体来扩充汉藏词典,利用主题模型将文本映射到主题空间中,根据新闻文本的特点计算出了汉藏文本相似度。基于神经网络的方法的主要思想是将语料进行分布式表示,通过神经网络提取语料中所含的语义信息,基于神经网络的方法是近年来自然语言处理领域运用得最为广泛的方法。Mueller等人[9]使用孪生LSTM(Siamese LSTM)来编码句子中潜在的信息,提取完上下文特征信息后计算曼哈顿距离以求得句子相似度;Pontes等人[10]使用了孪生CNN和LSTM结合的方法,运用CNN提取局部特征,运用LSTM提取上下文特征,这种网络组合有利于保存句子相关信息,提高了句子相似度分数;Zhang等人[11]在BiLSTM的网络基础上加入注意力机制,通过注意力机制,考虑到不同组件的不同贡献来增强语义,使相似度计算性能进一步提高。
2 汉老双语特征选取及表示
本节通过研究汉老双语语言学上的特点,辨别双语时态和定位定语位置,将其作为特征融入相似度计算模型中,从而扩充嵌入层中句子的语义信息,因此能够更好地让神经网络提取局部特征和长距离特征,提高神经网络学习并提取句子中特征的能力。
2.1 时态特征
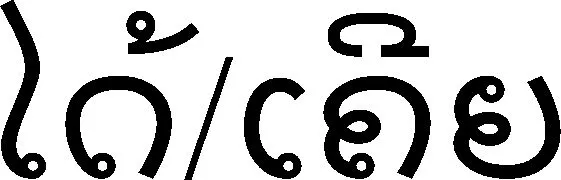
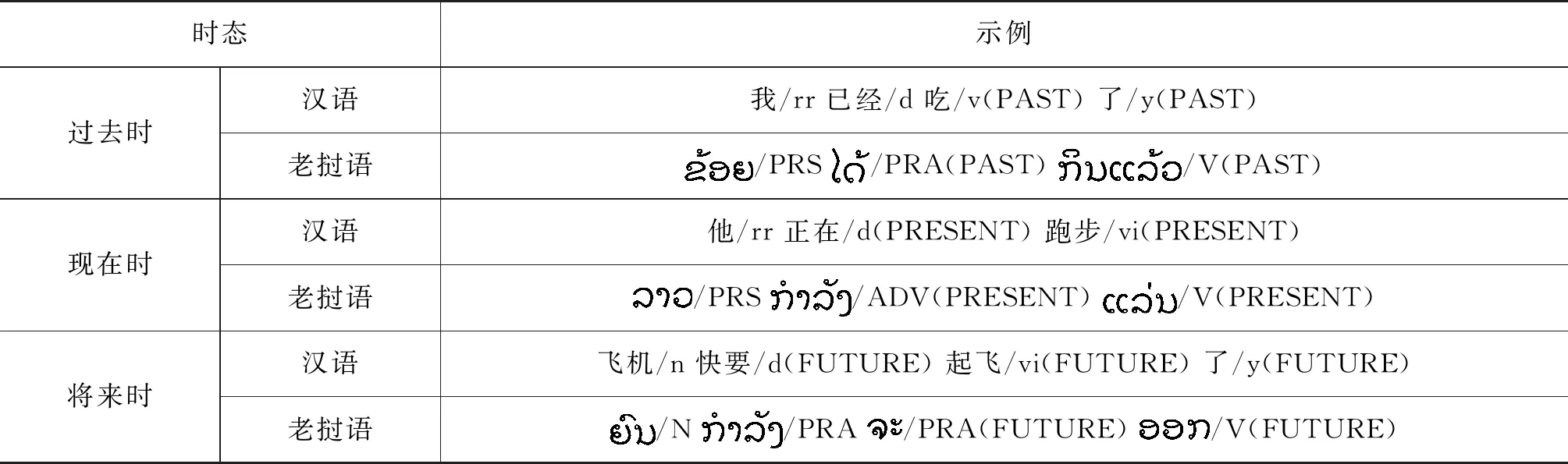
表1 汉语-老挝语时态标记及标签示例
2.2 定语定位


表2 定语定位标记及标签示例
3 模型和方法
本文提出了融合语法及结构特征的方法来计算汉老双语句子相似度,在使用神经网络进行特征提取前,首先对汉老双语语料进行预处理,包括数据清洗、分词、词性标注,用本文所示的方法对时态特征与定语位置特征进行特征标记,将语料进行向量化的表示,通过无监督的方法将汉老双语词语映射到共享的语义向量空间中;然后将含有特征标记的双语分布式表示接入到CNN与BiGRU中提取局部特征与长距离语义信息特征;接着将提取到的信息送入局部推理层的交互聚合结构进行信息交互;最后将得到的双语信息进行按位减与按位乘操作,将处理后的信息接入全连接层得到最终的汉老双语句子相似度分数。模型框架如图1所示,它分为五个层次:
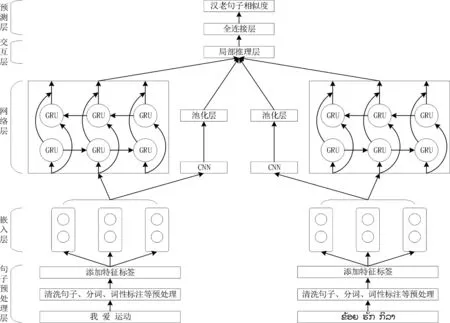
图1 融合语法及结构特征的汉老双语句子相似度计算模型图
(1)句子预处理层: 将汉老双语句子语料进行数据清洗、分词、词性标注,用本文所示的方法并借助语言工具添加特征标签。
(2)嵌入层: 将含有特征标签的汉老双语进行分布式表示。
(3)网络层: 接入CNN与BiGRU提取句子的局部特征和全局特征,生成隐藏状态向量,将得到的向量进行拼接。
(4)交互层: 神经网络学习到句子的特征后,局部推理交互聚合结构将汉老双语信息交互。
(5)预测层: 对交互后的语义信息进行计算并连入多层全连接层,得到最终相似度计算结果。
3.1 句子预处理
首先清洗掉影响实验的语料中的标点符号等,汉语通过中文语言工具进行分词、词性标注和依存句法分析,老挝语通过昆明理工大学信息工程与自动化学院实验室依托国家自然科学基金《老挝语词法分析及老-汉双语平行语料抽取方法》研发的老挝语语言工具来进行分词[12]和词性标注[13],最后通过本文所示方法为双语句子添加特征标签。
3.2 汉老双语的共享映射
词向量的分布式表示将词表示成连续的稠密向量,映射到低维的向量空间中,词向量的表征质量对嵌入层任务有重要的影响。Mikolov等[14]发现两种语言在各自单语料库嵌入完成后在向量空间中有着诸多共同特点,Faruqui和Dyer[15]将两种语言嵌入到完全共享的语义空间中。有监督训练需要高质量的双语语料库,Artetxe等人[16]等提出一种无监督的映射方法,该方法甚至在一定程度上超过了有监督的方法。老挝语是一种资源贫乏的小语种,缺乏大规模且高质量的语料库,本文使用一种自学习的无监督的跨语言映射方法来将汉老双语嵌入到共享的语义空间中。此方法主要包含以下步骤:
(1)嵌入标准化(Embedding normalization)对汉老双语的每个词向量进行标准化预处理,首先进行长度标准化,然后进行均值中心化,最后再一次进行长度标准化处理。
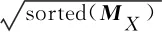
(3)自学习(Self-Learning)过程自学习是为了提高词典的相似性,求解最佳的正交映射矩阵和最佳字典,需要循环直至收敛,根据式(1)求得出WX=U,WZ=V,并将此结果用来更新D矩阵,当式(2)成立时Dij=1,表明目标语言的第j个与源语言的第i个词互译,反之为0,最后经过对称再加权,双语词嵌入矩阵就映射到同一共享空间中。
3.3 特征的融入
为了将特征表示到句子中,本文把包含着特征的词语向量值相加并求其平均值,然后拼接到句子末尾,使该句子包含添加的特征信息。例如,设句子长度为N,即句子中含有N个词,句子向量表示为S=(a1,a2,a3,…,aN),a为每个词的向量表示,假设a2和a3含有特征标签,则得到的aM=(a2+a3)/2为句子内的特征关系,最后得到新的含有特征信息的句子S′=(a1,a2,a3,…,aN,aM)。
3.4 网络层
本文构建了分别含有CNN和BiGRU的双塔网络层。CNN用于获取句子信息的局部特征,BiGRU用于获取长距离信息,双塔结构能够全方位地获取句子信息及隐藏特征。
3.4.1 长距离语义信息提取
传统RNN(Recurrent Neural Networks)在实验中存在长期依赖问题和梯度消失问题,同时LSTM(Long Short Term Memory)在实验中训练时间更长,Cho等人[17]提出的GRU(Gated Recurrent Unit)是RNN的一种变体模型,它能很好地克服传统RNN存在的问题,且比LSTM更为优异。GRU的内部结构如图2所示。
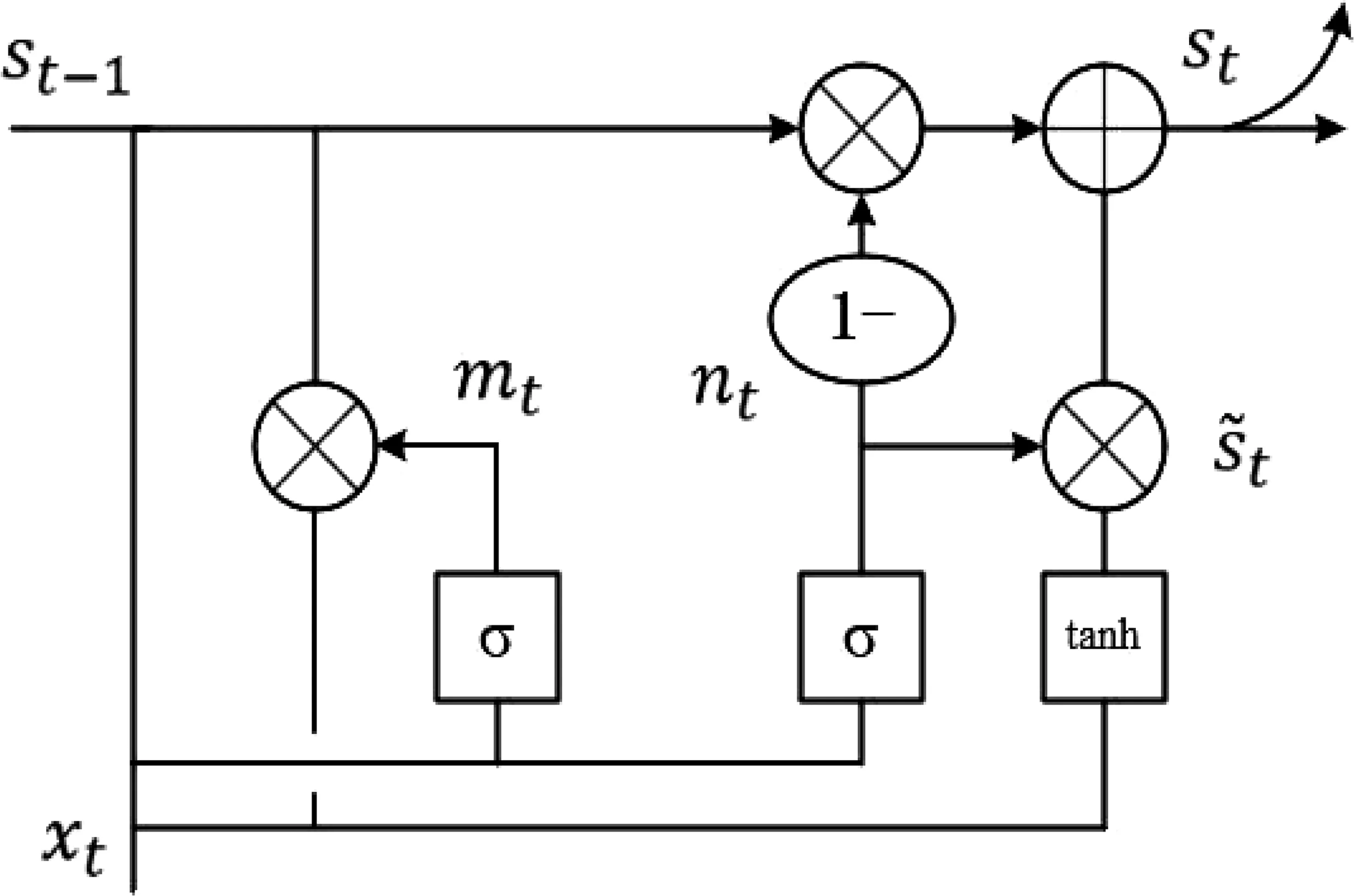
图2 GRU内部结构
GRU将LSTM的输入门、输出门和遗忘门精简为重置门与更新门,因为汉老双语序列存在着广泛的正负时序,GRU可以运用单元内部的门控部件来有效处理语料序列时序。GRU在某一时刻t的工作流程如式(3)~式(6)所示。
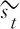

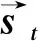
3.4.2 局部信息提取
本文使用卷积神经网络来提取双语句子的局部特征。实验设置了三种不同尺度的卷积核,一维卷积主要用以处理时序数据,能将嵌入矩阵转换为一维向量,对于句子来说卷积的方向是沿着词的方向进行,卷积核大小分别为1,2,3,它们可以获取序列间不同角度的隐藏特征,因此可以获取到更加全面的局部特征信息。卷积神经网络能够提取汉老双语句子中类似于N-gram的重要的局部信息。
(1)输入层: 嵌入层的输出矩阵即为CNN的输入,设句子的第i个词向量为ai∈Rm×n,其中m为句子长度即词语数量,n为词向量的维度。
(2)卷积层: 即对输入进行卷积操作,使用ReLU函数为激活函数,卷积层有权值共享和系数连接的性质,可以将输入的维度降低,这样可以防止过拟合现象发生。卷积操作如式(10)所示。
Ci=ReLU(W·ai:i+h-1+b)
(10)
其中,W为卷积权重,b为偏置项,从序列ai:i+h-1中提取特征,即第i个词到第i+h-1个词组成的句子序列。
(3)池化层: 池化层的主要作用为降低筛选出的特征的维度,同时对卷积后的句子中的特征进行采样,筛选出关键的特征,提高特征的鲁棒性。实验用最大池化的方法来输出池化向量,设置padding参数为same,即对边缘补0。Cmax即表示最大池化层提取的特征如式(11)所示。
Cmax=max (ci)
(11)
3.5 局部推理层
在传统的双塔结构中,双语信息相对独立,孪生网络直接将双语特征输出到相似度计算层,没有进行句子间的特征交互,而交互聚合结构能够很好地解决这一问题,从而使模型性能进一步提升。实验使用了Chen等人[19]提出的增强的顺序推理模型(Enhanced Sequential Inference Model)以交互注意力机制推进汉老双语信息进行词语级别的交互。
首先将双塔网络中输出的语义信息进行拼接,即对CNN与BiGRU提取到的特征向量进行拼接。局部特征推理层主要用于将上述拼接后的序列进行对齐操作,将汉老双语信息进行交互,得到交互后的特征。实验所用的为软对齐方式,最后得到句子词向量之间的乘积,如式(12)所示。
(12)
接着,进行两个句子之间的交互,表示为:
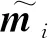
最后,将新老特征进行融合,把得到的交互后的向量与交互前的向量做差与乘。局部推理后的汉老双语信息的特征得到增强,得到差异特征以使模型增强特征学习,式(15)和式(16)为计算过程。
3.6 预测层双语句对相似度表示
经过局部推理层的交互后,得到了汉语和老挝语的交互后的最终表示,最后进入预测层来计算汉老双语句子的相似度分数。采用类似于Shao[20]的方法,得到汉语最终信息和老挝语最终信息后,对它们进行按位减和按位乘。其中按位减要取绝对值,最终进行拼接操作得到汉老双语句子的相似度表示情况,其计算过程如式(17)所示,最后输入到多层次的全连接层,从而得到双语的相似度概率分布。
P=Concat(|SC⊖SL|),(SC⊗SL)
(17)
其中,Concat表示拼接操作,⊖表示双语信息按位减,⊗则表示对应相乘。
旅游景观翻译。旅游景观翻译属于实用文本翻译的范畴,是“为旅游活动、旅游专业和行业所进行的翻译实践,是一种跨语言、跨社会、跨时空、跨文化、跨心理的交际活动”〔2〕。根据功能翻译理论,旅游景观翻译的策略和方法应由译文的功能或预期目的决定,强调在分析原文的基础上,以译文预期功能为依归,结合外国游客的社会文化背景和对译文的期待、感应力或社会知识以及交际需要等各种因素,灵活选择最佳处理方法。因此,对旅游景观翻译而言,不仅需要传递源语文本所含的旅游信息,还要把景观相关的旅游文化传递给目标读者。由此可见,功能翻译理论对旅游翻译,尤其是景观翻译具有相当的指导意义。
4 实验及分析
4.1 实验数据
数据集分为用于得到汉老双语分布式表示及特征标签向量的数据集和用于本文模型训练的数据集。前者中汉语词向量使用Li[21]运用百度百科语料来训练的词向量,大小为1.69 GB,老挝语词向量通过老挝语维基百科爬取的110 MB的语料训练得到,由此来获得汉老双语词向量。后者使用中文维基百科和老挝语维基百科爬取的篇章级对齐语料,经过老挝语专家人工对齐校验后得到89 300对汉老双语平行句对。非平行句对语料库通过1:7(正样本: 负样本)的比例来构建,得到625 100对非平行句对。本实验在构建好的双语语料数据集中,取90%为训练集,取10%为测试集。数据集处理完成后对汉老双语语料的预处理如下:
(1) 对语料进行清洗,使用语言工具对汉语进行分词、词性标注处理,同时根据句法关系确定汉语句子中的宾语与定语,使用老挝语语言工具对老挝语进行分词、词性标注处理,通过本文所示方法在双语语料中添加特征标签。
(2) 使用无监督的方法将已经训练好的汉老双语词向量映射到同一共享的语义空间中,使双语词嵌入产生联系,使词向量的表示更为精确。
(3) 将句长默认值设置为30,句子中超出部分进行截断,少于30的部分进行补0操作。
4.2 实验设置
本实验使用Python作为实验语言,使用Keras框架。词向量嵌入维度设置为300,最大句子长度设置为30,Batch size设置为128,学习率设置为0.001,Dropout率设置为0.2;在卷积神经网络中,卷积核大小设置为1,2,3,步长设置为1;在双向门控循环单元中,隐藏神经元个数为50,实验采用Adam优化算法[22]作为神经网络的训练方法。本文按照传统评价指标对实验结果进行评判,通过精确度(Precision,P)、召回率(Recall,R)和F1值(F1-Score,F1)来作为指标衡量汉老双语句子相似度模型的性能,其中F1值为最关键的评测指标。将0.5设置为评测基线,当双语句子相似度分数大于0.5时判定为相似句子对,反之则为不相似句子对。
4.3 实验结果与分析
本文使用添加特征标签的方法,将汉老双语词语映射到共享的向量空间,通过CNN与BiGRU进行编码,使用局部推理的交互聚合结构,最后连入全连接层计算相似度分数。为验证本文所示实验的有效性,本文设置了三组对比实验,分别为使用不同模型的对比实验、添加不同特征对相似度计算性能提升的对比实验和不同卷积核大小对实验影响的对比实验。
4.3.1 对比模型
(2) BiGRU,使用双向门控循环单元提取汉老双语句子全局信息。
(3) CNN+BiGRU,在上述模型的基础上添加卷积神经网络,使模型能够提取句子的局部特征。
(4) CNN+BiGRU+Attention,加入注意力机制,筛选出关键信息,通过赋予权重筛选出关键信息。
(5) CNN+BiGRU+Self-attention,使用自注意力机制,它是注意力机制的变体,用于筛选重要信息。
(6) CNN+BiGRU+局部推理交互聚合结构,加入局部推理的交互聚合结构,使汉老双语信息进行交互。
(7) CNN+BiGRU+局部推理交互聚合结构+Features,加入本文所示特征,添加特征标签。
模型(1)到模型(3)主要将编码网络拆解,依次进行对比,模型(4)和模型(5)主要对比不同注意力对提取重要信息的影响,模型(6)主要加入局部推理的交互聚合结构对比传统双塔结构对实验产生的影响,模型(7)加入了本文所示的特征,比较特征对实验的影响效果,不同模型对比结果如表3所示。
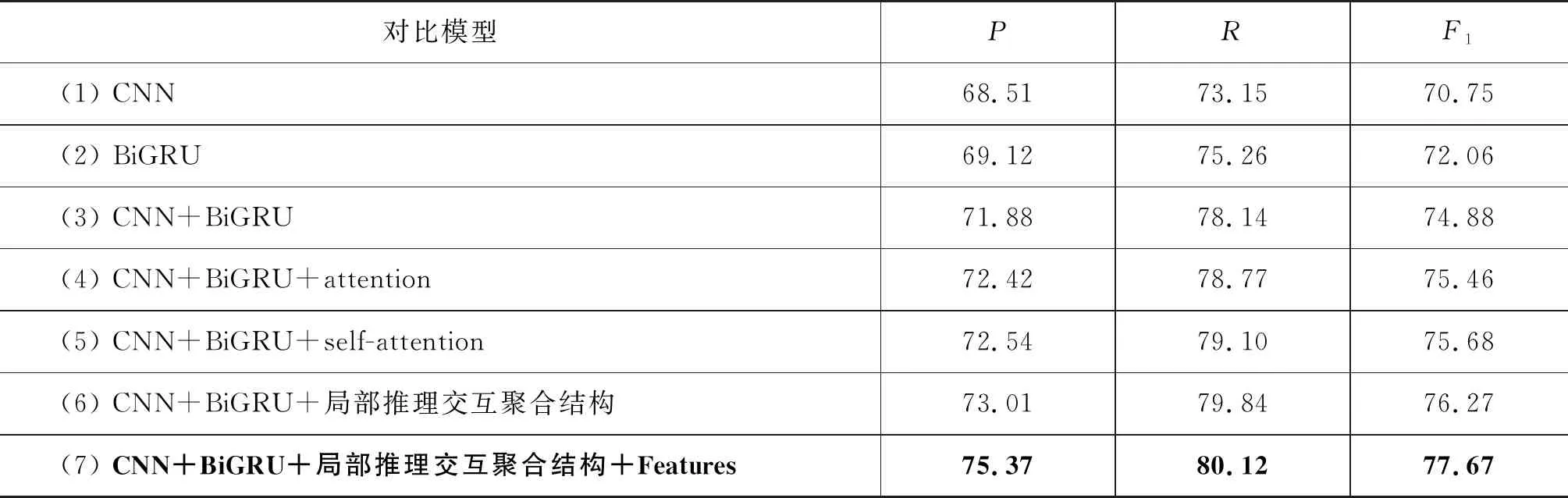
表3 不同模型对比结果 (单位: %)
由表3可知,模型(1)的F1值最低,是因为其只能提取句子局部特征;模型(2)的F1值比模型(1)提升了1.31%,是因为BiGRU内的门控结构能够提取句子的重要特征,且双向结构使提取全局信息的效果更好;模型(3)证明了两个网络的拼接能够起到互补作用;模型(4)和模型(5)加入了注意力机制,使F1值进一步提升,自注意力机制因为减少了外部信息的依赖,捕捉数据内部相关性的能力更强;模型(6)加入了局部推理的交互注意力,在模型(3)的基础上使汉老双语句子信息进行交互,增强了句子间的关联性,使F1值提升了1.39%;模型(7)为本文模型,在模型(6)上融入汉老双语的特征,使双语语义信息进一步丰满,实验效果比模型(6)有了一定的提升,F1值达到了77.67%。
4.3.2 特征融入有效性的实验
由上述对比模型实验的模型(6)和模型(7)的对比可知,通过融入特征,能够有效提高模型的相似度计算性能。以上述模型(6)为基准模型,通过分别添加不同特征来验证特征的有效性,添加PAST即过去时特征,PRESENT即现在时特征,FUTURE即将来时特征,再添加融合三个时态的特征,然后在基准模型上添加定语位置特征,最后添加融入的所有特征,具体实验结果如表4所示。
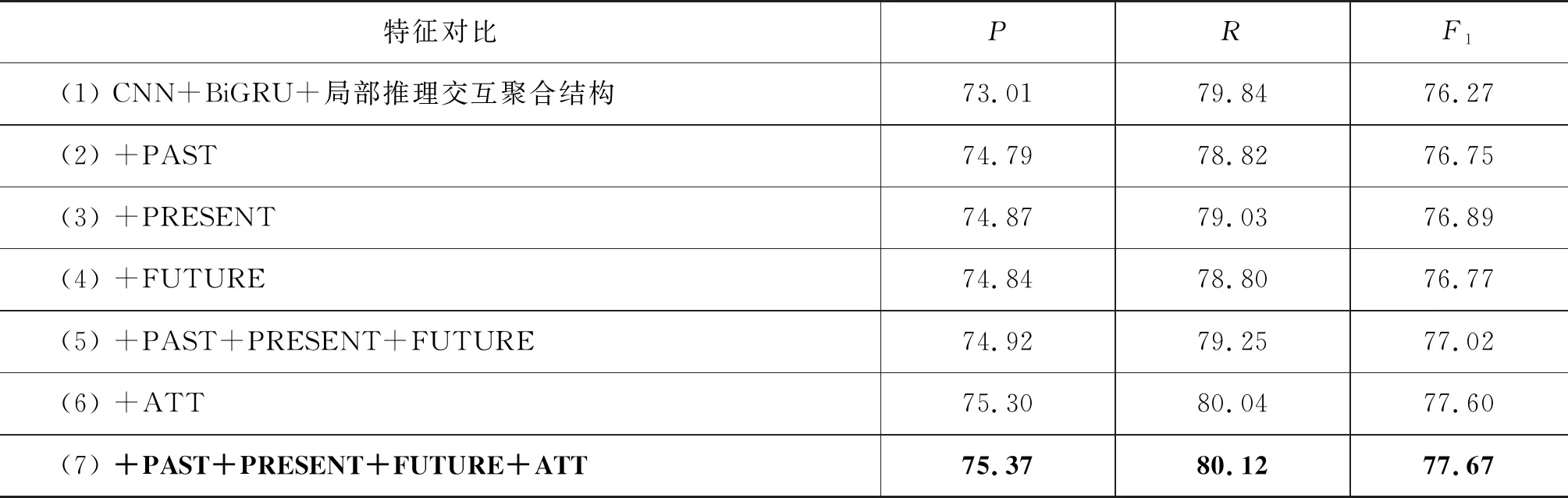
表4 不同特征对实验的影响 (单位: %)
将模型(2)到模型(7)与基准模型对比,发现添加特征对模型相似度计算性能有一定提升,模型(2)到模型(4)性能相似,是因为不同时态的句子数量是相似的,没有太大差别。模型(6)显示加入定语位置特征后,F1值提升略大,提高了1.33%,是因为定语广泛存在于不同句子之中。将不同特征相互融合来增强语义信息对模型性能的提升最大,F1值提升了1.4%。
4.3.3 不同尺寸卷积核提取局部特征的有效性实验
在编码环节中的卷积神经网络中使用了三种不同大小的卷积核来提取句子的局部特征,大小分别设置为1,2,3,实验结果如表5所示。
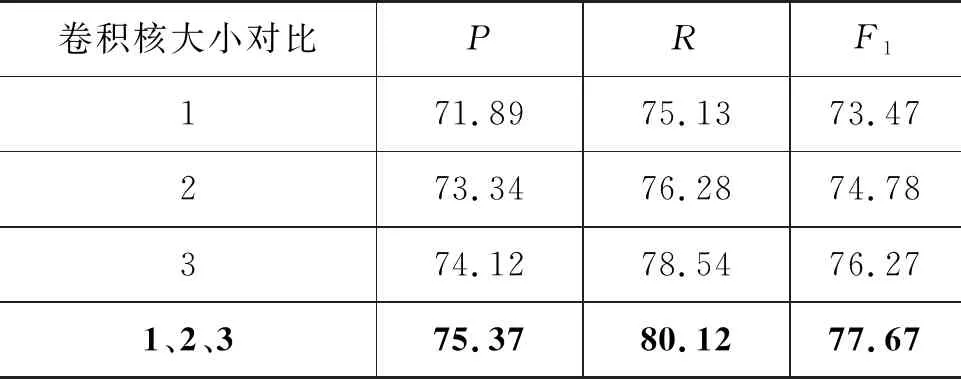
表5 不同卷积核对实验的影响 (单位: %)
卷积核大小为1时F1值最低,是因为卷积网络只能单独提取双语的特征,当卷积核为2和3时,卷积网络能够提取到汉老双语中不同的句子结构特征,将三个卷积核一起使用时能发挥出卷积网络提取句子局部特征的最大性能。
5 结论
本文依据汉老双语语言学的特点,提出了一种融合汉语和老挝语的语法和结构特征的双语句子相似度计算方法。通过一种自学习的无监督的方法,将汉老双语词向量映射到同一共享空间中,使双语词语产生关联,将特征融入双语句子中,使用神经网络提取汉老双语的特征,局部推理的交互聚合结构使双语信息进行交互,进一步提升了相似度计算模型的性能。实验表明,本文提出的方法在汉老相似度计算方法中有突出的表现。句子相似度计算是自然语言处理的核心任务之一,老挝语属于低资源语言,下一步考虑将该方法融入平行语料库的构建、跨语言信息检索等其他自然语言处理任务中。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
新晨(2013年10期)2014-09-29
外语教学理论与实践(2014年2期)2014-06-21
