
基于神经网络的机器译文自动评价综述
2023-12-06 02:41李茂西李易函
中文信息学报 2023年9期
刘 媛, 李茂西, 罗 琪, 李易函
(1.江西师范大学 计算机信息工程学院,江西 南昌 330022;2.江西开放大学 智能技术学院,江西 南昌 330046;3.江西师范大学 管理科学与工程,江西 南昌 330022;4.江西师范大学 图书馆,江西 南昌 330022;5.南京航空航天大学 自动化学院,江苏 南京 210000)
0 引言
机器译文自动评价(Automatic Evaluation of Machine Translation)是指通过度量机器译文与参考译文的相似程度或偏离程度实现对机器译文质量的评价,进一步实现系统级别翻译质量的评价,机器翻译系统开发人员通过评价结果获知机器译文质量,从而有针对性地对翻译系统进行改进[1-4]。无需人工参考译文,仅使用源语言句子和机器译文进行评价的方法称为译文质量估计(Quality Estimation),其在研究方法上与译文自动评价差异较大。本文主要针对机器译文自动评价进行综述和讨论。根据评价者的不同,机器译文评价方法可分为人工评价和自动评价。人工评价尽管比较准确,但评价周期长、费用高且不客观。自BLEU[5]等机器译文自动评价指标被提出以来,译文自动评价方法因其评价周期短、速度快、成本低等优点被大规模应用于机器译文质量的评价,因此机器译文自动评价对推动机器翻译的发展发挥着重要作用。
早期的译文自动评价方法根据机器译文与参考译文的词形相似程度评价译文质量[5-7],如基于n元文法匹配的方法和基于编辑距离的方法。基于n元文法匹配的方法计算机器译文和参考译文之间不同长度词语片段的匹配程度,如BLEU[5]、NIST[8]和ROUGE[9]等;基于编辑距离的方法计算将机器译文转换为参考译文所需编辑次数的比例,如单词错误率WER[10]和翻译错误率TER[11]等。此外,一些学者提出基于语言学检测点的方法,该类方法根据构建的语言学检测点对译文相应部分进行打分[12],如Woodpecker[13]等。随着人工智能的发展,基于传统机器学习的方法采用机器学习的“特征工程+任务建模”范式对译文质量进行评价[14-16],由人工指定影响译文质量的各类特征,使用支持向量机等传统机器学习算法预测机器译文质量,如BEER[17]、BLEND[18]等。
传统自动评价方法使用词法、句法和浅层语义知识进行译文评价。严格使用词形进行匹配的方法很难准确评价包含词序变化和一词多义语言现象的译文的质量;而使用句法和浅层语义知识进行匹配的方法需要额外的语言学分析工具或特定的语言资源,这些语言学分析工具和资源与语言种类相关,很难移植到不同语言种类的译文上,导致其泛化性差。
近年来,计算性能的提升和可用数据规模的增加促进了神经网络的发展与应用,大规模预训练语言模型可以生成词语或句子的稠密向量表示,这些向量中蕴含丰富的语法、语义信息。因此,基于神经网络的自动评价方法能有效根据语义评价机器译文的质量,并且泛化性好,已成为当前主流的研究方向。本文对基于神经网络的自动评价方法作详细阐述,根据评价方式不同将其分为基于表征匹配的方法和基于端到端神经网络的方法,如图1所示。
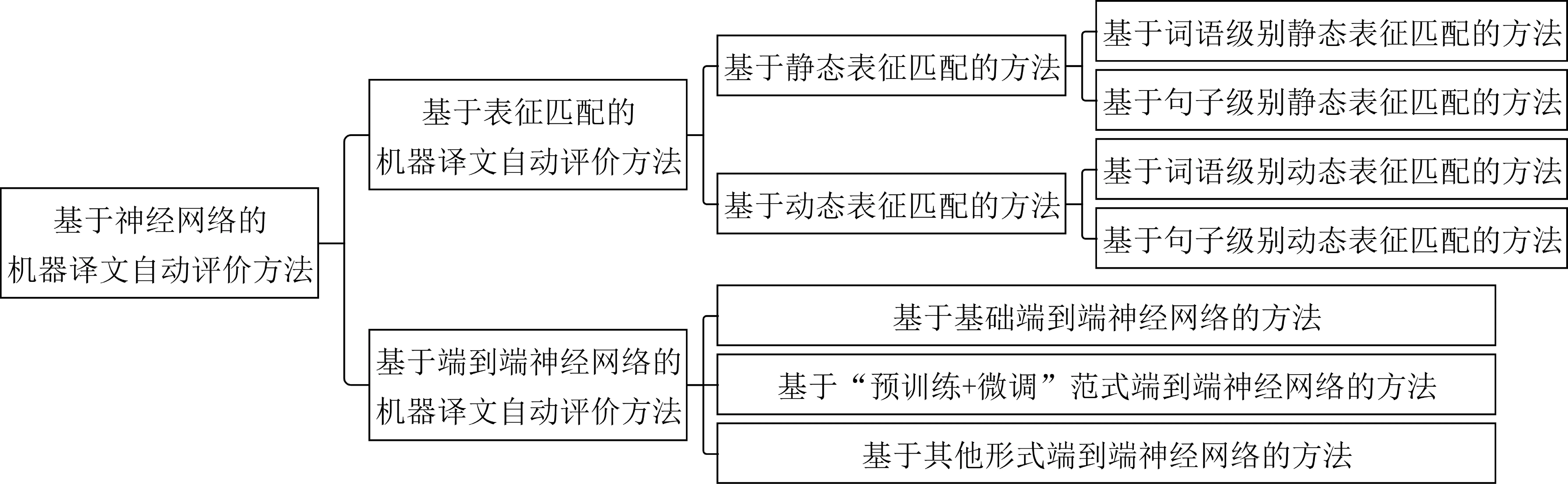
图1 基于神经网络的机器译文自动评价方法分类一览图
基于表征匹配的机器译文自动评价方法将机器译文和参考译文映射到高维空间,以词语级别向量或句子级别向量的形式作为机器译文和参考译文的词或句的表征进行匹配,实现语义匹配度评估。根据表征是否含上下文语境信息将其进一步分为基于静态表征匹配的方法和基于动态表征匹配的方法,基于静态表征匹配的方法使用静态预训练模型获取表征,基于动态表征匹配的方法使用含上下文语境信息的表征。
基于端到端神经网络的机器译文自动评价方法使用神经网络提取句子的深层语义信息,将深层语义信息进行回归计算得到质量分数。本文将基于端到端神经网络的机器译文自动评价方法进一步分为基于基础端到端神经网络的方法、基于“预训练+微调”范式端到端神经网络的方法和基于其他形式端到端神经网络的方法。
本文第1节、第2节分别详细介绍基于表征匹配的方法和基于端到端神经网络的方法,第3节介绍相关的评测活动WMT自动评价任务及常用性能评价指标,最后对未来的研究方向和发展趋势进行展望。
1 基于表征匹配的机器译文自动评价方法
基于表征匹配的机器译文自动评价方法将词或句映射到高维空间,计算参考译文与机器译文词语级别表征匹配程度或句子级别表征匹配程度,实现语义层面的质量评价,提升评价准确性。根据表征是否含上下文语境信息,将其分为基于静态表征匹配的方法和基于动态表征匹配的方法。
1.1 基于静态表征匹配的方法
基于静态表征匹配的方法使用静态预训练的词向量GloVe或Word2Vec等获取词表征,计算机器译文和参考译文中词表征的匹配相似度或偏离程度,或将词表征加工为句级表征后计算其匹配程度。根据用于匹配的表征粒度不同将其分为基于词语级别静态表征匹配的方法和基于句子级别静态表征匹配的方法。
1.1.1 基于词语级别静态表征匹配的方法
基于词语级别静态表征匹配的方法使用静态预训练词表征生成模型获取机器译文和参考译文的词表征,然后计算二者的匹配程度。贪心匹配法[19]计算机器译文中所有词表征与参考译文中词表征的最大匹配余弦相似度、参考译文中所有词表征与机器译文中词表征的最大匹配余弦相似度,取二者均值作为评价分数,如式(1)~式(3)所示。
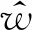
为了将浅层语义分析与语义匹配相结合,MEANT[20]使用语义角色标注给词或片段标注其在句子中的角色标签,通过测量机器译文和参考译文的语义框架与角色填充物的相似度评估翻译的充分度。MEANT 2.0[21]在MEANT工作的基础上引入词频加权,赋予实词比功能词更高的权重,并通过计算n元词表征匹配相似度实现在评价时关注词序信息。MEE[22]分别对机器译文和参考译文进行精准词形匹配(Exact Match)、根匹配(Root Match)和近义匹配(Synonym Match),其中精准词形匹配为机器译文和参考译文的词形匹配数,根匹配和近义匹配设定匹配阈值,计算机器译文和参考译文的FastText词表征匹配相似度,FastText词表征指Facebook于2016年开源的词向量计算工具生成的词表征。根据匹配相似度所在的阈值空间判定其所属匹配类型。最终将以上三个匹配模块的F值加权平均为评价分数。不同于上述基于机器译文和参考译文的相似程度的质量评价方法,基于偏离程度的方法如词移距离WMD[23]计算机器译文与参考译文词表征的最小匹配欧氏距离。
1.1.2 基于句子级别静态表征匹配的方法
基于句子级别静态表征匹配的方法将机器译文和参考译文的词表征使用平均池化或其他处理方式加工为句子级别表征,然后计算句子级别表征间的相似程度。
如图2所示,平均词向量自动评价指标(Embedding Average Metric)[24]使用平均池化分别将机器译文和参考译文中的词表征加工为句子级别表征,计算句子级别表征的余弦相似度。为了增强句子级别向量的表征能力,极值向量(Vector Extrem)[25]沿维度取所有词表征的最大值或最小值作为句子级别表征的各维度值。Chen等人[26]提出分别基于独热表征、分布式词表征、RAE句子表征或上述三种表征的组合的译文自动评价方法,并在此基础上提出将句子级别自动评价的评分加权求和为篇章级别评分[27]。其中,RAE句子表征为使用贪心无监督递归自编码器策略(Recursive Auto-Encoder, RAE)生成的分布式句子表征。
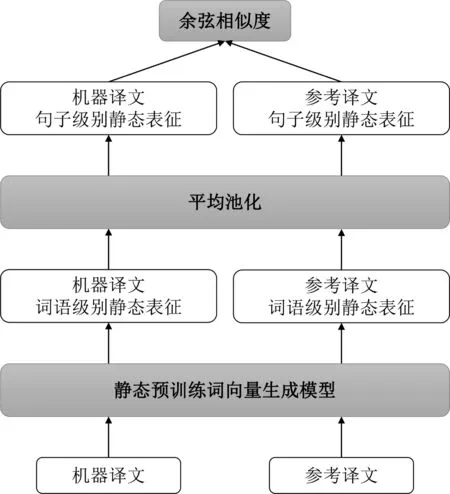
图2 平均词向量自动评价方法图
相比仅根据词形进行评价的基于n元文法匹配的方法,基于静态表征匹配的方法在一定程度上实现根据语义进行评价。但静态表征独立于上下文,无法获取上下文语境信息,故基于静态表征匹配的方法存在无法结合语境信息进行译文质量评价的不足。
1.2 基于动态表征匹配的方法
针对基于静态表征匹配的方法中静态表征无法获知上下文语境信息这一问题,基于动态表征匹配的自动评价方法使用基于上下文语境的词表征获取语境信息。根据所采用的表征的粒度不同将其分为基于词语级别动态表征匹配的方法和基于句子级别动态表征匹配的方法。
1.2.1 基于词语级别动态表征匹配的方法
基于词语级别动态表征匹配的自动评价方法计算机器译文和参考译文含语境信息的词向量的匹配相似度。如图3所示,BERTScore[28]用BERT模型生成上下文语境词表征,计算参考译文中词表征r与机器译文中词表征t的最大匹配余弦相似度,计算召回率RBERTScore和准确率PBERTScore,进一步计算F值FBERTScore作为评价分数,如式(4)~式(6)所示。
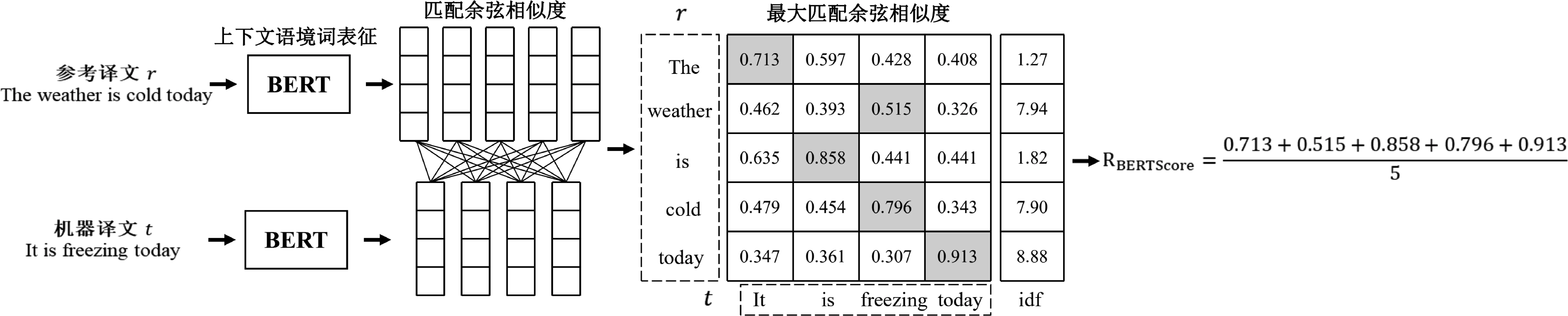
图3 BERTScore机器译文自动评价方法示意图
Mathur等人提出的BERTr[29]与BERTScore类似,但仅使用召回率作为评价分数,方法简单有效。BERTScore采用词表征间一对一的匹配余弦相似度,然而句子对中的词还存在一对多关系,出于对该语言现象的考虑,Zhao等人提出的MoverScore[30]计算n元词组上下文语境词表征的欧氏距离。由于对不同翻译难度的句子的翻译能力可以反映翻译系统的质量,Zhan等人提出的DA-BERTScore[31]将翻译难度引入BERTScore,赋予更难翻译的词以更高的评价权重,增加其对评价结果的影响。评判翻译难度的方法为机器译文与参考译文的词表征最大匹配余弦相似度越低,则翻译该词的难度越大,故赋予其更高的难度系数。最后将难度系数作为最大匹配余弦相似度的权重参与到F值的计算,该方法能有效对性能相近的优秀翻译系统进行质量排名。Vernikos等人提出的Doc-BERTScore[32]将BERTScore扩展为篇章级别自动评价,该方法将译文与该条译文的上下文一起输入BERT模型进行编码,使译文表征获得篇章级别上下文信息,然后以单条句子为单位进行评分,评分方法与BERTScore的评分方法相同。
1.2.2 基于句子级别动态表征匹配的方法
基于句子级别动态表征匹配的方法计算机器译文与参考译文含语境信息的句子表征的匹配程度。Wieting等人提出的SIMILE[33]使用经过训练的含软注意力机制的编码器[34]生成机器译文和参考译文的句子表征,计算二者的余弦相似度,并引入长度惩罚因子以惩罚机器译文与参考译文长度相差过大的场景。长度惩罚因子LP计算如式(7)所示。
(7)
其中,|r|指参考译文的长度,|t|指机器译文的长度。
目前,世界上只有英德、英汉等少数语言对有丰富的语料资源,大多数语言对的语料资源匮乏。YiSi系列评价指标[35]根据可获得的语料资源规模不同设计对应的自动评价指标。其中,YiSi-0适用于低资源语言,计算机器译文和参考译文的最长公共子字符串;YiSi-1计算使用BERT生成的上下文词表征的匹配余弦相似度,可自由选择是否使用语义角色标注获取浅层语义结构信息;YiSi-2适用于无参考译文的评价场景,该方法使用跨语种词表征生成模型获取源语言句子和机器译文的跨语种词表征,然后计算二者的余弦相似度,可自由选择是否使用语义角色标注。
近年来,跨语种的表征生成模型技术取得长足进步,一些学者使用XLM[36]等跨语种表征生成模型获取源语言句子和机器译文在同一语义空间内词语级别或句子级别的表征,对比源语言句子和机器译文在同一高维空间的语义相似度。Song等人提出的SentSim[37]首先获取基于源语言句子和机器译文的跨语种词语级别表征和句子级别表征,然后计算上述表征的词移距离、句移距离、BERTScore分数和句级余弦相似度,从词移距离和句移距离中选其一与BERTScore分数、句级余弦相似度加权求和得到句子评分。基于跨语种预训练表征生成模型的LaBSE[38]文本相似度分数虽然性能优良,但所需的GPU等硬件资源开销大且模型复杂,Han等人提出的cushLEPOR[39]模型使用知识蒸馏学习LaBSE模型内部映射方式,用较低的资源开销实现接近LaBSE模型的性能。
基于表征匹配的机器译文自动评价方法计算机器译文与参考译文的表征匹配程度,在一定程度上实现语义层面的评价,该类方法依托预训练表征生成模型,随着多语种预训练表征生成模型技术的成熟,基于表征匹配的方法展现了较强的鲁棒性与易用性。
2 基于端到端神经网络的机器译文自动评价方法
基于端到端神经网络的机器译文自动评价方法使用神经网络提取深层语义信息,使用深层语义信息预测译文质量,根据神经网络架构不同将其分为基于基础端到端神经网络的方法、基于“预训练+微调”范式端到端神经网络的方法和基于其他形式端到端神经网络的方法。
2.1 基于基础端到端神经网络的方法
基于基础端到端神经网络的自动评价方法构建神经网络提取译文的深层语义信息后预测译文质量分数。图4为Shimanaka等人提出的RUSE[40]自动评价方法的结构图。RUSE分别使用InferSent、Quick-Thought和Universal Sentence Encoder三种预训练句子表征生成模型生成参考译文和机器译文的句子级别表征,用启发式方法将句子表征组合后输入多层感知机(MLP)进行回归计算评分,如式(8)、式(9)所示。
Mathur等人提出BiLSTM+attention模型[29],将词向量输入BiLSTM获取上下文语境信息,使用跨句注意力机制获取机器译文和参考译文的交互信息。此外,Mathur等人提出的ESIMBERT[29]使用自然语言推理中的增强序列推理模型ESIM[41]对机器译文和参考译文进行编码,使用跨句注意力机制对表征加权,并依次通过BiLSTM和池化层获取局部序列信息与特征信息,最后将加工完成的信息表征输入前向层预测译文质量分数,如式(10)、式(11)所示。
x=vr,avg⊕vr,max⊕vt,avg⊕vt,max
(10)
ESIMBERT=UTReLU(wTx+b)+b′
(11)
其中,x为拼接完成后的句子增强表征,r表示参考译文,t表示机器译文,vr,avg、vr,max分别指参考译文的平均池化表征和最大池化表征,U、w、b和b′为通过训练得到的参数。罗琪等人[42]在Mathur工作的基础上引入源端信息,使用基于联合神经网络质量估计模型从源语言句子和机器译文中提取质量向量,将池化后的质量向量与ESIMBERT的增强表征拼接后输入前馈神经网络中预测译文评价分数。Hu等人[43]在罗琪工作的基础上引入差异特征,使用跨语种预训练模型XLM将源语言句子、机器译文和参考译文两两组成的句子对映射到同一语义空间,对比机器译文和源语言句子与参考译文的语义差异。
Rei等人提出的COMET[44-45]含两类评价模型,第一类为分数预测模型(Estimator Model),该类模型对译文的质量评定分数;第二类为排名模型(Translation Ranking Model),该类模型对译文质量进行排名,选出相对优质的译文。首先,COMET使用跨语种预训练语言模型XLM-RoBERTa分别对源语言句子、机器译文和参考译文进行编码。由于Tenney等人[46]实验表明预训练语言模型中不同层捕获不同类型的语义信息,且只依据模型最后一层的输出评判译文质量的效果不佳,故COMET使用分层注意力机制综合各层生成的不同类型的语义信息,使用平均池化将词语级别表征进一步处理为句子级别表征[47],并在模型训练过程中采用层级dropout[48]提高句子级别表征能力。
对于COMET中的分数预测模型(Estimator Model),Rei等人使用上述跨语种编码器分别对机器译文、源语言句子和参考译文进行编码,并采用类似RUSE中的方式对句子级别表征进行组合,如式(12)所示。
x=[t;r;t⊙r;t⊙s;|t-r|;|t-s|]
(12)
其中,t为机器译文表征,r为参考译文表征,s为源语言句子表征。将信息表征x输入前向层进行回归评分,模型训练过程中使用均方误差作为损失函数。
对于COMET中的排序模型(Translation Ranking Model),Rei等人将源语言句子s、参考译文r、相对优质的机器译文t+、相对劣质的机器译文t-的句子四元组{s,t+,t-,r}输入跨语种编码器,然后通过池化层生成四元组的句子级别信息表征,使用三元组损失函数(Triplet Loss)优化语义空间中句子表征之间的相对距离,该损失函数期望优化模型使得在最终表征空间内相对优质的机器译文和黄金参考(参考译文与源语言句子)的距离更近,相对劣质的机器译文和黄金参考的距离更远。除了分数预测模型和排序模型两个主要模型,Rei等人还提出了直接对比源语言句子和机器译文的相似度,无需参考译文的Reference-free COMET、轻量级的COMET模型COMETINHO[49]。Vernikos等人提出的Doc-COMET[32]将译文与译文的上下文拼接后输入编码器,将COMET扩展为篇章级别的Doc-COMET译文评价方法。
上述方法均为将含深层语义信息的向量作为神经网络的输入,另一类方法为将译文的各类特征分值作为神经网络的输入。REGEMT[50]集成分别基于词形、句法和语义特征的自动评价指标,来提升仅基于单种类型的自动评价指标性能,包括软余弦相似度、词移距离和词性标注转换距离,使用神经网络进行回归评分。Rony等人提出的RoMe[51]将译文的语法、句法和语义三个方面的质量得分组合为向量输入神经网络进行回归计算评分,其中语义分数采用融入了词对齐和词序差异惩罚的基于语义相似度的EMD距离(Earth Mover’s Distance),其中EMD距离可以计算机器译文和参考译文的偏离程度;句法分数采用经过改进的语义增强树编辑距离算法(Tree Edit Distance)[52],计算机器译文和参考译文的句法结构差异;语法分数采用在CoLA语料库上训练的二分类器,判定译文语法是否在可接受范围内。
2.2 基于“预训练+微调”范式端到端神经网络的方法
目前基于“预训练+微调”范式的深度学习模型被广泛应用于自然语言处理的各个任务,根据具体评价场景对包含大量可重用知识的预训练模型进行微调的机器译文自动评价模型展现出优异的性能。
不同于基于基础端到端神经网络的RUSE方法和ESIMBERT方法中将机器译文和参考译文分别输入BERT模型,用于MTE的BERT[53]将机器译文和参考译文拼接后输入BERT进行编码,将特殊位置“[CLS]”的向量输入多层感知机预测译文质量,并通过微调提升模型性能,如图5所示。其中,“[SEP]”为句子间的分割符号,“[CLS]”为每对输入间的标识符。
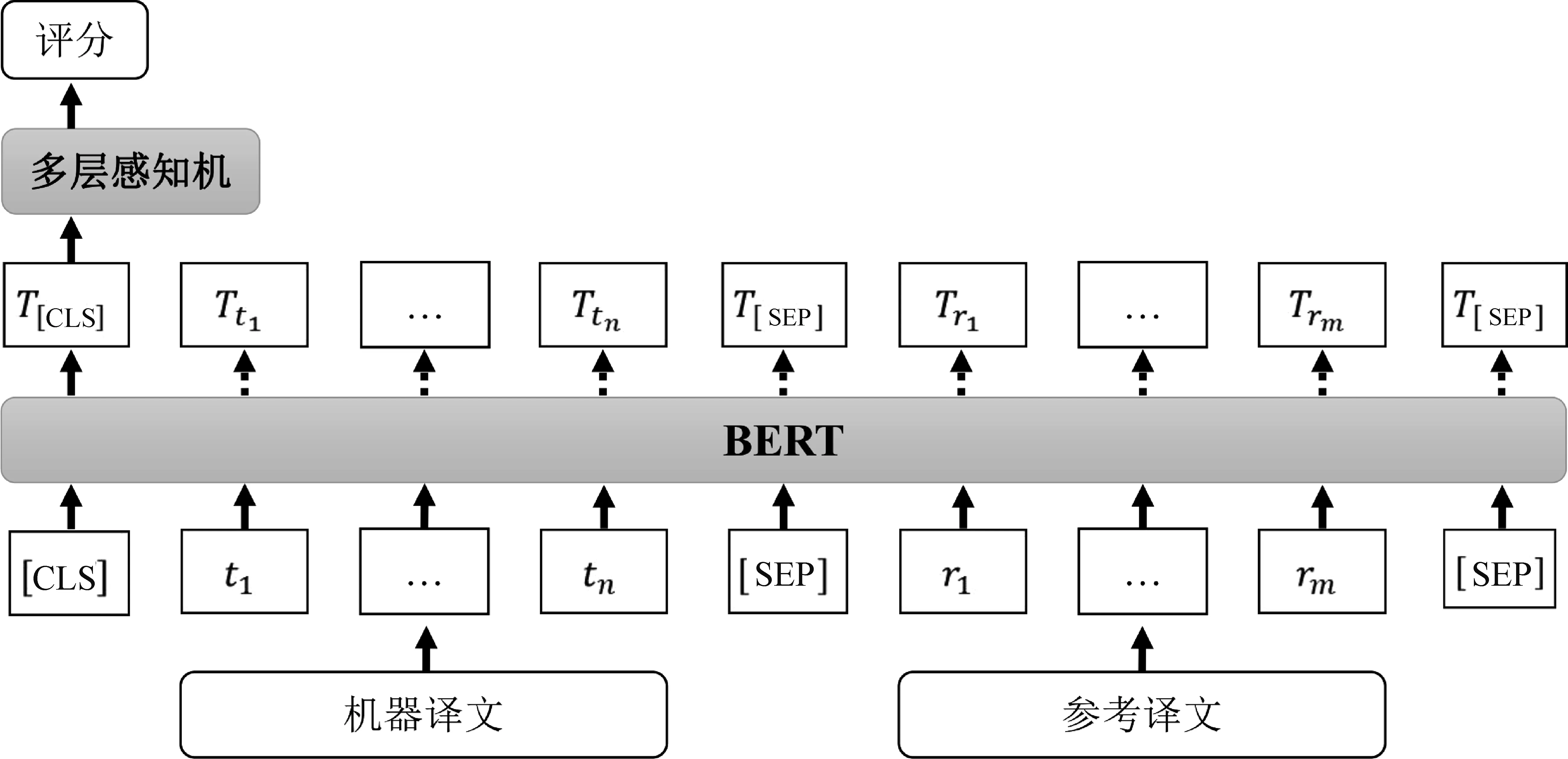
图5 用于MTE的BERT自动评价方法结构图
Sellam等人提出的BLEURT[54]使用随机扰动后的维基百科句子和一组词汇级和语义级的监督信号对评价模型进行预训练,预训练监督信息包括: ①BLEU、ROUGE和BERTScore自动评价指标评价结果; ②回译似然值; ③判断原句和扰动句的三类文本关系: 蕴含、矛盾、中立; ④标注扰动句是否为原句回译生成的回译标志。拼接机器译文和参考译文输入预训练完成的BERT模型中,取特殊标志“[CLS]”位置的向量作为句子表征输入前向层预测译文质量分数。Wan等人提出的ROBLEURT[55]在BLEURT的工作基础上做三处优化提升模型的鲁棒性: 第一,根据源语言句子的资源可获得程度设计不同评价方式,在源语言句子资源匮乏的的情况下仅拼接机器译文和参考译文作为模型的输入,在源语言句子资源充沛的情况下拼接源语言句子、机器译文和参考译文作为模型的输入,使模型在评价时考虑机器译文同参考译文与源语言句子两者的语义一致性;第二,使用大规模人工合成数据对模型进行持续性预训练;第三,使用降噪后的数据对模型进行微调。该自动评价方法结合单语模型和多语模型,使用“预训练+微调”范式进行训练,引入迁移学习,性能较BLEURT有进一步提升。
Kane等人提出的NUBIA[56]利用大规模预训练语言模型提取译文深层语义特征,并在提取特征时使用“预训练+微调”范式,该方法的评价过程分为三个步骤: 第一步,分别用RoBERTa STS、RoBERTa MNLI和GPT-2模型抽取句子间的语义相似度、逻辑一致程度和语法正确性三类特征。具体来说,使用STS-B-benchmark数据集对RoBERTa预训练模型进行微调,提取机器译文和参考译文的语义相似度;用RoBERTa在GLUE的MNLI任务上微调,捕获机器译文和参考译文的逻辑一致程度;用GPT-2计算困惑度,以评判机器译文的语法正确性。第二步,将第一步抽取的特征输入线性回归模型,预测译文质量分数。第三步,将译文质量分数进行归一化。
为了减少硬件资源开销,提升模型效率,Eddine等人的FrugalScore[57]使用知识蒸馏构建轻量版BERTScore或MoverScore。该自动评价模型先让轻量级预训练语言模型学习高开销模型的内部映射方式,然后在合成数据集上继续训练该轻量级预训练语言模型,最后在人工标注的语料上微调微缩模型。
2.3 基于其他形式端到端神经网络的方法
以上方法均为构建神经网络提取深层语义信息,使用监督学习方式训练评价模型,通过回归方式预测机器译文质量。近年来,一些新形式的自动评价模型被陆续提出,如Thompson和Post提出的Prism[58]使用端到端释义模型预测机器译文在对应参考译文下出现的概率,概率值越大,则机器译文的质量越高。Vernikos等人提出的Doc-Prism[32]为篇章级别Prism,该方法将参考译文与其上下文拼接输入端到端释义模型。Krubiński等人提出的MTEQA[59]是首个基于问答框架的机器译文自动评价指标,该指标的评价过程分为两个步骤: 第一步,从参考译文中抽取信息作为答案,并生成相应的问题;第二步,使用问答系统根据机器译文生成上一步骤中问题的答案,用字符串比较法计算依据机器译文而得的答案和依据参考译文而得的答案的相似度,对于同一语段,取所有问题答案对相似度的平均值作为最终质量评分。
在易用性方面,基于端到端神经网络的机器译文自动评价方法在使用时需要根据模型的需求进行环境配置,虽然相关研究人员对基于端到端神经网络展开了大量研究,但当前可直接使用的基于端到端神经网络的自动评价模型较少,故相比其他方法,该类方法易用性较差,未来应当对性能优良的端到端神经网络评价模型的易用性提升进行深入研究。
3 自动评价方法的评测(元评测)
机器译文自动评价评测活动发布公开的数据集、基准的评价方法与译文的人工评价分数或质量排名,为不同自动评价指标提供公平比较的平台,它极大地促进了机器译文自动评价的研究与发展。目前机器译文自动评价评测活动主要为WMT机器译文自动评价任务。国内的全国机器翻译大会CCMT组织过多次机器翻译相关任务评测,包括无需参考译文的机器译文质量估计评测活动。WMT机器译文自动评价任务于2008年开始,用于评测机器译文自动评价方法的性能表现,任务涵盖中英、德英、中俄等各类广泛使用的语言对和部分低资源语言对[60-66]。
评测活动中,为了比较参与评测的不同自动评价方法的优劣,一般使用肯德尔相关系数度量自动评价方法打分在句子级别与人工评价的相关性,使用皮尔逊相关系数度量自动评价方法打分在系统级别与人工评价的相关性,有时使用成对精确度度量在系统级别自动评价打分与人工评价的相关性,相关性越高,表示对应方法越可靠。
(1) 肯德尔相关系数τ(Kendall Correlations)通过度量自动评价与人工评价对译文质量高低排序一致程度衡量自动评价方法与人工评价的相关性,计算方法如式(13)所示。
(13)
其中,Concordant指自动评价方法给人工评价打分较高的机器译文以较高的分数,自动评价与人工评价打分一致;Discordant指给人工评价打分较低的机器译文以较高的分数,自动评价与人工评价打分不一致。
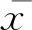
(16)
(3) 成对精确度(Pairwise Accuracy)用于衡量自动评价与人工评价的系统级别相关性,计算方式如式(17)所示。
(17)
其中,自动评价(Metric)和人工评价(Human)分别对多个系统进行打分,对于其中任意两个系统,MetricΔ指自动评价的评分差值,HumanΔ指人工评价的评分差值,|AllSystemPairs|指系统对的总数,通过比较评分差值是否一致衡量自动评价与人工评价的相关性。
元评测通过计算自动评价指标评分与人工评价评分的相关性度量自动评价指标的性能,故人工评价分数的可靠性直接决定了元评测是否有效,许多学者对元评测中的人工评价评分机制进行研究与探索,以期得到更可靠的人工评分,目前主要的人工评价方式为以下四种:
(1)传统DA人工评价(Direct Assessments): 该评价机制采用众包的方式对机器译文进行直接评分,由于其成本较低,2020年及之前历届WMT自动评价任务均采用该人工评价方式。但近年研究发现,众包评分者缺乏专业翻译知识,存在对翻译中的错误过于包容、与专家评分相关性较低[67]等问题,故2021年WMT自动评价任务提出采用MQM评价机制作为人工评价分数的评测子任务。
(2)HTER(Human-Mediated Translation Edit Rate)[68]: HTER在翻译编辑率(TER)的基础上引入人工注解,让精通目标语言的人工译员结合机器译文和参考译文给出一个新的参考译文,使用TER算法计算机器译文和新参考译文的编辑率。其中,翻译编辑率(TER)为计算从机器译文转换到参考译文所需的插入、删除、单词替换和词组平移的编辑次数的比例。
(3)多维度质量评价机制MQM(Multidimensional Quality Metric)[69]: Freitag等人的研究显示[66]传统众包DA人工评价对高质量机器译文的评价不可靠,MQM评价机制将翻译错误分为不同类型,综合错误的次数及其相应权重对译文进行评分,该方法比直接为译文评定一个分数更可靠,2021年WMT自动评价任务开始采用MQM评价机制作为黄金参考。MQM评价机制将译文错误分为微小错误(minor)、主要错误(major)和严重错误(crit),并赋予不同程度的错误以不同的权重,按式(18)计算译文评分,其中,SentenceLength为句子长度,Iminor、Imajor和Icrit分别为微小错误次数、主要错误次数和严重错误次数如式(18)所示。
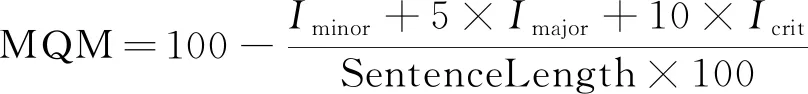
(18)
(4) 分级质量度量指标SQM(the Scalar Quality Metric)[70]: Freitag等人受MQM启发,将机器译文质量分为六个等次,评价者在评分过程中可以看到句子的上下文。其中,质量分数为6分时指语法与语义完全正确;4分为语义基本转述完成,语法错误较少;2分为未表达出源语言句子的主要语义;0分为译文没有表达任何源语言句子的信息。
2019年以来,每届WMT自动评价指标任务含不同子任务,如2019年和2020年发布篇章级自动评价任务、2021年新增专家多维度质量评价机制MQM作为人工评价的子任务,帮助自动评价研究人员准确了解自动评价模型性能、对比评价模型性能。
历届WMT自动评价任务的评测结果均整理成文并发表,研究人员可以通过每年的评测结果报告了解各个自动评价方法在该年评测任务中的表现及自动评价最新趋势。为了解近年评测任务中表现优良的自动评价方法的共同特点,在WMT’21自动评价评测任务中特定语言对上获最优性能的评价方法汇总如表1所示,该表展示了WMT’21自动评价任务上各个优秀自动评价方法获最优性能的次数汇总,符号“*”表示该方法未参与所有语言对上的评测,符号“-”表示该方法在该类任务上未取得最优性能。结果表明,显著优于其他自动评价方法的C-SPECpn[71]、BLEUrt-20和COMET-MQM_2021均为使用“大规模预训练+微调”范式的端到端神经网络自动评价模型,这表明“大规模预训练+微调”范式能显著提升评价性能。在国内机器译文自动评价研究方面,澳门大学的NLP2CT实验室与阿里巴巴达摩研究院共同提出的RoBLEURT在WMT’21的自动评价任务中取得多项第一的优良成绩。中国科学院的马青松团队提出的Blend、DPMFCOMB[72]和基于融合策略的机器翻译自动评价方法[73]性能优良,其中Blend在WMT’17自动评价任务的德英、俄英等多个语言对任务上取得第一名,DPMFCOMB在WMT’16自动评价任务的法语至英语、土耳其语至英语句子级别直接评价任务中排名第一。北京大学的研究团队在2020年提出引入语义加权句子相似度的自动评价方法SWSS[74]有效提升基于词形匹配的机器译文自动评价指标的性能。北京大学计算语言学重点实验室提出的Meteor++[75]与Meteor++ 2.0[76]对经典自动评价指标Meteor做改进,其中Meteor++ 2.0在WMT’15至WMT’17自动评价任务数据集上与人工评价的相关性超过了当时所有版本的Meteor。苏州大学的李良友提出的融合文档信息的机器翻译自动评价[77]以语言学短语为基本评价单位,研究了文档信息在评价方法中的应用。江西师范大学的研究团队[78-80]提出的MPEDA在WMT’16自动评价系统级别任务的法语至英语和芬兰语至英语语言对上排名第二。
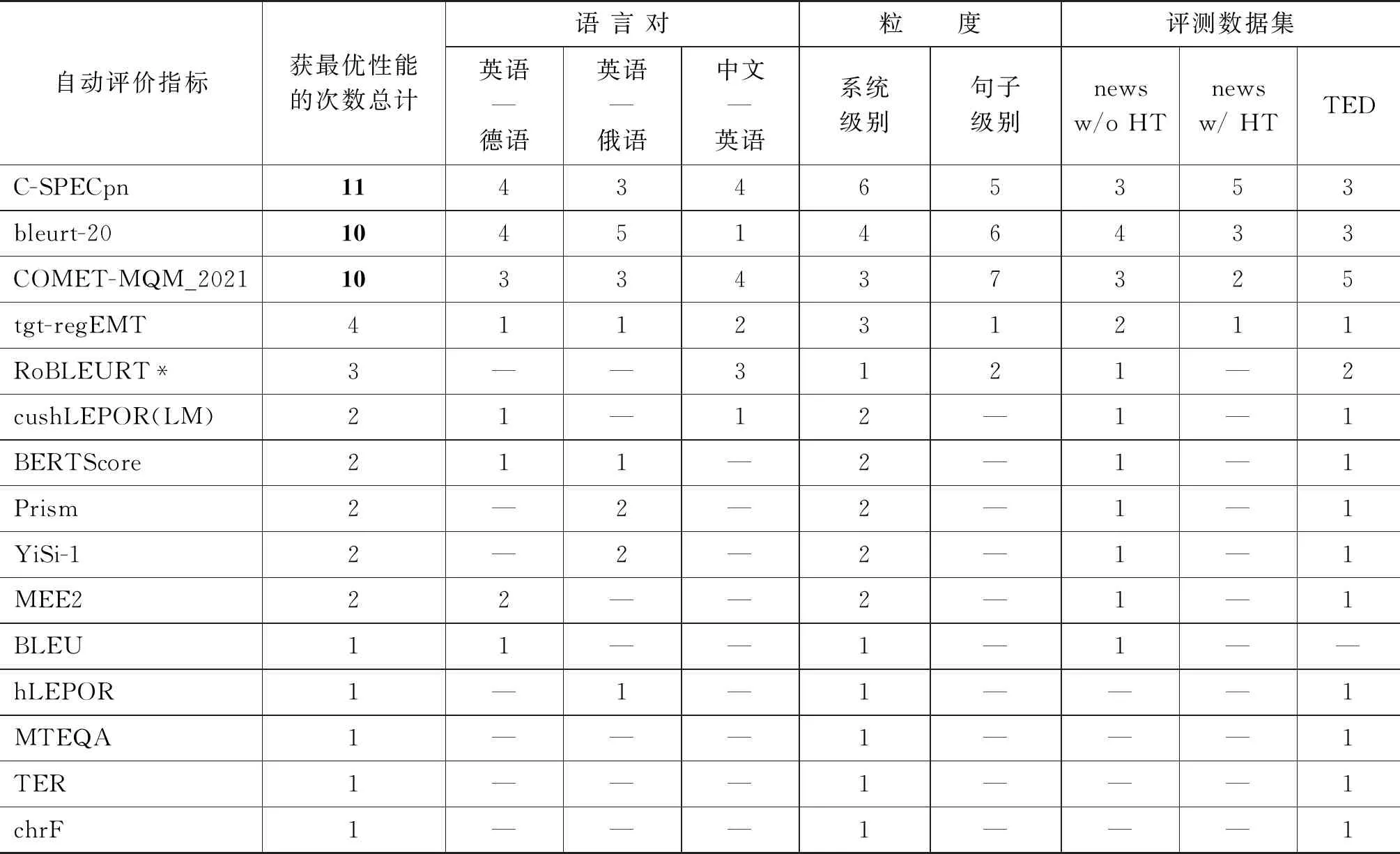
表1 WMT’21 metrics task上获最优性能的自动评价方法汇总
4 未来研究趋势
趋势1:研究方便易用且鲁棒性强的自动评价方法。目前虽然众多自动评价指标被提出且展现远优于BLEU的性能,但在机器翻译领域被广泛使用的评价指标仍为仅根据浅层词形相似度进行评价的BLEU,原因之一为BLEU无须训练、简单易用且鲁棒性强[72]。因此,研究简单易用、鲁棒性强的高性能自动评价方法是研究者孜孜以求的目标。
在自动评价指标鲁棒性方面,WMT’21自动评价任务提出跨领域自动评价元评测度量自动评价指标的鲁棒性,使用TED演讲数据集测试开发集为新闻领域数据集的自动评价指标的性能。各个自动评价指标在新闻领域的newstest21数据集和演讲领域的TED数据集上的成对精确度如表2所示。评测结果显示,基于大规模预训练语言模型的自动评价指标表现出更好的鲁棒性,如RoBLEURT。另一方面,在新闻领域数据集表现较好的自动评价指标tgt-regEMT、cushLEPOR(LM)在演讲领域数据集上表现较差,展现出较低的鲁棒性。这表明研究者不仅需要对跨领域、跨语种预训练语言模型做进一步研究,还需要对跨领域、跨语种的译文自动评价方法进行探索。

表2 各个自动评价方法在不同领域数据集上的成对精确度
在易用性方面,HuggingFace在2022年5月31日推出Evaluate库,其中包括广泛使用的BLEU自动评价指标,这不仅使模型的评估流程更加标准化,而且提升了评价指标易用性,方便相关从业人员使用。
趋势2:参考译文的质量与数量对自动评价指标的评测具有重大影响。WMT’20自动评价任务设置多参考译文场景的评测任务,实验结果显示,参考译文质量与数量对自动评价方法性能评测有重大影响。表3展示了在英语至德语数据集上使用三个不同的参考译文ref-A、ref-C和ref-D时各个自动评价指标的表现,其中MQM分数为多维度质量评价机制下的人工评价分数,MQM值越小,译文质量越高,括号内数值为成对精确度排名。如BERTScore使用“ref-A”作为参考译文或“ref-C”作为参考译文情况下性能表现均为第一,但当使用“ref-D”作为参考译文时表现较差,具体原因值得进一步探索。
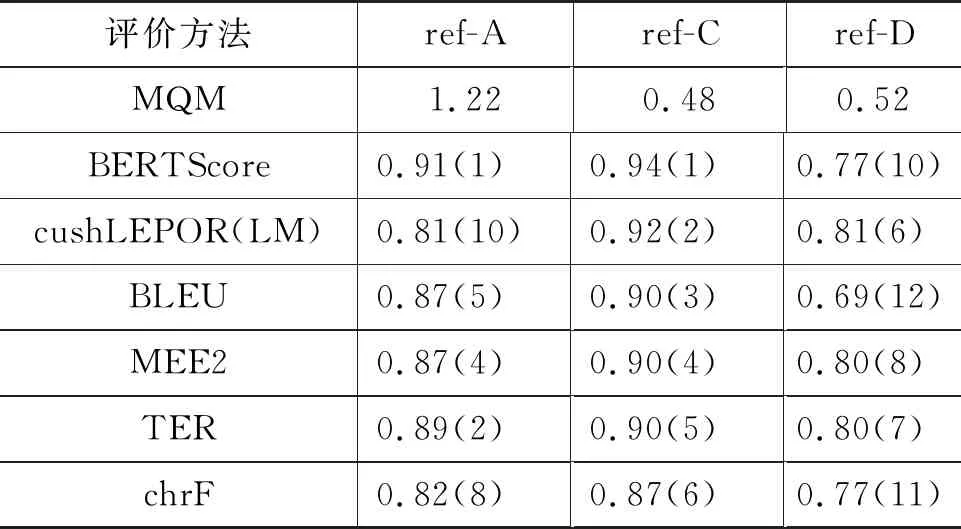
表3 各个自动评价方法使用不同参考译文时与人工评价的成对精确度
趋势3:篇章级别机器译文自动评价。篇章级别机器译文中句子间的连贯性、衔接性以及跨句指代关系是否翻译正确对于评价译文的质量优劣有重要作用。连贯性、衔接性以及跨句指代关系等语言学特征均需要根据篇章语境信息进行评判[77],然而单一的句子级别评价方法无法捕获篇章级别的语境信息[81],容易出现评价偏差的情况,故对篇章级别机器译文自动评价方法的研究有重要意义。如BLEU等评价方法尽管提供篇章级别自动评价得分,但仅在篇章级别简单统计匹配的n元文法数目,无法识别句子之间的连接词等,不能评判译文的连贯性与一致性[82-83]。早期的Comelles等人[84]提出的篇章级别自动评价指标基于语篇的形式化表示,Guzmn等人[85]引入基于语篇结构的语篇相似度提升自动评价指标性能。Wong等人[86]引入文本衔接性提升篇章级别机器译文自动评价性能。然而,Wong等人的自动评价方法忽略了参考译文的文本衔接情况,仅对机器译文的文本衔接性分数进行建模评价,Gong等人[87]设定机器译文的文本衔接方式应当与参考译文的文本衔接保持一致,提出计算参考译文与机器译文的简化词汇链匹配数目,从而实现评价机器译文的文本衔接性。在这些的工作基础上,Gong等人[87]使用主题模型计算确定篇章文本的主题分布概率,从而实现计算机器译文与参考译文的主题一致性。Tan等人[88]提出的语篇衔接性评价方法DCoEM综合参考译文、连接词、指代关系和词汇衔接四个衔接性要素评价篇章级别机器译文的衔接性。Jiang等人[89]提出的BLONDE对机器译文和参考译文中的文本片段进行分类,然后计算各类别子集的相似度,相似度采用F1值计算方式。Castilho等人[90]于2022年提出集成了评价方法、评价语料库等组件的篇章级别自动评价项目DELA。为了推动相关从业人员对篇章级别自动评价的研究,2018年和2019年的WMT自动评价任务均设置篇章级别自动评价任务,为篇章级译文评价提供了基准的比较平台。未来应当对篇章级别译文自动评价做进一步研究[91]。
5 总结
基于神经网络的机器译文自动评价方法使用深层神经网络或预训练语言知识对机器译文及其对应的人工参考译文进行逐层抽象,计算抽象后向量之间的距离。本文将其细分为基于表征匹配的方法和基于端到端神经网络的方法,基于表征匹配的方法将词语或句子映射到高维空间,直接计算其在高维空间的余弦距离或偏移距离,基于端到端神经网络的方法主要使用回归的方式,让模型依据从神经网络中提取的各类特征,学习两者之间的差异,从而获得评价能力。此外,本文对自动评价方法元评测的WMT自动评价任务和相关评测指标、人工评价方式进行介绍,最后对基于神经网络的机器译文自动评价的发展趋势进行分析,未来将进一步研究可广泛使用于各个领域的高性能自动评价指标,从而推动机器翻译的发展与应用。
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
基层中医药(2021年8期)2021-11-02
水利经济(2020年3期)2020-02-22
电影(2018年8期)2018-09-21
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
中学生(2017年13期)2017-06-15
小学生学习指导(低年级)(2017年6期)2017-02-16
