
基于改进YOLOv5s的X光图像危险品检测
2023-12-06 06:37张康佳张鹏伟陈景霞龙闵翔林文涛
陕西科技大学学报 2023年6期
张康佳, 张鹏伟, 陈景霞, 龙闵翔, 林文涛
(陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021)
0 引言
公共安全一直是人类关注的热点问题,为了预防危及公共安全的事件发生,机场、火车站等各个重要场所都配有X光安检机和专门的安检人员,但是由于X光图像背景复杂,人工安检不可避免会发生错检、漏检的情况.
深度学习在近年来取得了巨大的进步,尤其是在图像识别和目标检测方面.目前常用的目标检测方法分为两大类:一是以R-CNN系列[1-4]为代表的两阶段方法,将定位任务和分类任务分成两个阶段去处理;二是以YOLO(You Only Look Once)系列[5-8]和SSD[9](Single shot multibox detector)为代表的一阶段方法,直接得到分类预测和位置坐标信息.而X光图像危险品检测属于目标检测的下游分支,同样可以应用两阶段方法和一阶段方法展开研究.
在两阶段法目标检测方面,Akcay等[10]探讨了传统的基于滑动窗口的卷积神经网络(Convolutional Neural Networks, CNN)和基于区域的全卷积网络(Region-based Fully Convolutional Networks,R-FCN)在X射线图像检测的适用性,并将R-FCN和残差网络相结合在ImageNet数据集上进行两类枪支检测,均值平均精度(mean Average Precision,mAP)达到了93.6%的精度.Steitz等[11]针对多视角X射线图像数据,引入一种基于Faster R-CNN的多视图检测模型,利用聚合的多视图特征,在自定义3D数据集上进行最终分类,取得了不错的效果.Gaus等[12]研究比较了Faster R-CNN、Mask R-CNN和RetinaNet模型在对不同几何形状、图像分辨率和颜色分布的X射线图像检测的可迁移性,在二分类和三分类X光图像数据集上进行目标检测的mAP性能分别达到了88%和86%.Liu等[13]根据被检测物体与背景颜色差异,从X射线图像中分离出被检测物体,然后将其送到R-CNN网络中学习,最终在自建的六分类X光危险品图像数据集上进行目标检测的mAP达到77%.Zhang等[14]提出了一种基于X射线的分类区域神经网络(XMC R-CNN),通过使用X射线物质分类器算法、有机分离算法和无机剥离算法解决X射线图像中的行李重叠问题,最终对枪、刀检测的查全率分别达到了96.5%和95.8%.Bhowmik等[15]使用内容感知重组特征(CARAFE),对6类X射线危险品图像进行检测,取得了70%的平均精度.上述基于两阶段的X光图像危险品检测方法,虽然对X光图像取得了较高的检测精度,但是所使用的危险品数据集类别较少,检测速度低下.无法满足实际情况下的X光图像危险品检测多样性鉴别和实时性的检测要求.
在一阶段法目标检测方面,Liu等[16]采用YOLO9000网络针对X光图像中剪刀、气溶胶特征进行了深入研究,最终对这两类的危险品进行检测的平均查准率和查全率分别达到了94.5%和92.6%.Galvez等[17]比较了YOLOv3模型在IEDXray数据集上使用迁移学习和从头训练方法对X射线图像中的简易爆炸装置进行检测的区别,发现在多尺度X光图像检测中,从头训练的目标检测精度能够达到52.40%,而用迁移学习的方法只能达到29.17%,说明从0开始训练的YOLOv3在X光图像危险品检测方面优于迁移学习.Wei等[18]在SSD网络上通过添加额外的卷积层,并采用多任务迁移学习方法,在GDXray数据集上进行了3类目标检测,取得了91.5%的平均精度.Qiao等[19]为了提高小规模违禁品的检测精度,在SSD网络上增加了特征融合模块和非对称卷积模块,将SSD模型进行目标检测的mAP提高了2.48%.Zhou等[20]在YOLOv4网络上引入可变性卷积,并使用GHM损失优化损失函数,在Sixray数据集上6类目标检测的平均精度达到了91.4%.上述基于一阶段的目标检测方法,虽然在X光危险品图像检测中取得了较高的精度,但是模型相对较大,无法做到实时部署,并且所使用X光图像数据集中危险品类别较少,仍然无法满足实际应用需求.
针对上述X射线图像危险品检测实际存在的问题,本文在YOLOv5s模型的基础上,引入了卷积注意力机制[21](Convolutional Block Attention Module,CBAM),并将注意力机制与特征金字塔[22](Feature Pyramid Networks for Object Detection,FPN)结构联合使用进行X射线图像危险品检测,使模型在特征学习与融合的过程中选择性强调危险品相关特征,并抑制背景干扰特征.同时在模型的检测头部引入解耦头进行优化,使分类和定位任务分开处理,并使用了更适合分类任务的全连接层来处理分类任务,而定位任务仍然使用卷积层来完成.通过这种方式来提高YOLOv5s模型在危险品检测中的精度.
1 YOLOv5s模型
YOLOv5s是一种用于单阶段目标检测的模型,它由输入端、基准网络、Neck网络和head输出端组成.
(1)输入端:输入YOLOv5s模型的图像大小一般为618*618或者416*416,本文输入的X射线危险品图像大小设置为416*416,通道数为3.该部分对输入的危险品图像进行一系列预处理操作,首先将危险品图像随机缩放到网络指定的输入大小,再进行归一化操作,通过对其进行随机排布,以进一步增强图像的特征表达能力.
(2)主干网络: Focus和CSP是主干网络的两个重要组成部分.其中,Focus部分通过slice切片操作,对输入的危险品图像进行裁剪,将其宽高缩小一半,变为了208*208.同时,将危险品图像的通道数乘4,变为12,得到面积减少为原来的四分之一,通道数变为原来的四倍的特征映射.YOLOv5s的CSP结构包括三个部分:第一部分是由卷积、归一化和激活函数组成的CBS(Conv+BN+SiLU)模块;第二个部分是由多个残差组件组成的残差模块;第三部分是单个卷积层.其作用是通过将特征图按照通道维度均分为两部分,其中一部分经过残差模块之后,再通过跨层连接将两部分再次合并,以达到减少计算量的同时,提高准确率.
(3)Neck网络:Neck位于主干网络和head输出端之间,YOLOv5s在Neck部分采用FPN+PAN(Path Aggregation Network)结构.FPN部分使网络输出特征图按从小到大结构排列,进而将更多的语义信息传递下来.而PAN结构使网络输出特征图按从大到小的结构排列,进而将更多的定位信息传递上去.通过将FPN+PAN相结合,将低层的强定位信息与高层的强语义信息进行融合,得到更加有用的特征信息.
(4)Head输出端:该部分从三个不同尺度对目标进行预测,最后对预测的结果进行非极大值抑制,进一步精简预测结果.
2 对YOLOv5s模型的改进
针对YOLOv5s模型特征融合时背景信息的干扰和检测头部耦合问题,本文在YOLOv5s模型的基础上所作改进如下,在FPN特征金字塔处,引入注意力机制模块;在检测头部分,对模型的预测头部进行解耦.将其改进后的模型命名为att_decouple_YOLOv5s,其结构如图1所示.
2.1 注意力机制的引入
在模型对危险品检测中,虽然FPN的自顶向下的特征金字塔结构,能够更好地将强语义信息传递下去,与浅层网络的所传递的特征信息进行特征融合.但是浅层网络所传递的特征信息并非都是有用的,其中包含许多背景干扰信息.所以为了减少背景干扰信息的传递,本文在浅层网络与FPN 信息融合处,结合注意力机制进行研究.
注意力机制在计算机视觉中的应用主要是三种,分别是通道域、空间域和混合域.本文所使用的卷积注意力模块(CBMA)则是混合域上的应用,通过使用注意力机制抑制浅层网络所传递的特征信息中的干扰信息,如图2所示:输入特征图X(N×H×W),经过通道注意力机制生成的通道注意力图Mc(N×1×1),然后将二者相乘,得到特征图X′(N×H×W),再将生成的特征图X′输入到空间注意力模块,得到空间注意力图Ms(N×1×1),将X′与Ms相乘,得到最终输出.
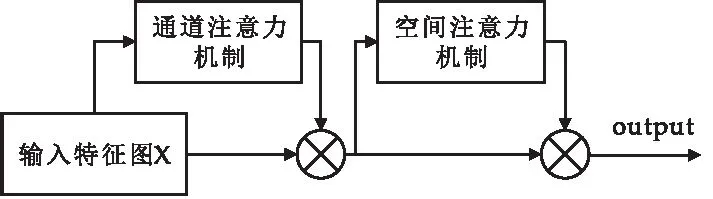
图2 注意力机制
在图3中,可以看到通道注意力部分对输入特征图的操作过程.输入特征图X经过最大池化和平均池化,分别生成两张N×1×1特征图:平均池化图FA和最大池化图FM.将FA和FM分别送入共享全连接层(MLP),然后对两种特征进行加和操作,并使用Sigmoid激活函数来强化不同通道的权重.最终得到通道注意力图,计算过程如下:

图3 通道注意力机制
Mc(X)=S(MLP(AP(X);MP(X)))=
S(W1(W0(FA))+W1(W0(FM)))
(1)
式(1)中:S为Sigmoid激活函数,AP为平均池化,MP为最大池化,W0和W1分别为共享全连接层的第1层和第2层,c为通道数.
空间注意力模块专注于位置信息,与通道注意力模块相辅相成,如图4所示.

图4 空间注意力机制
在该模块,对输入特征图X′在通道维度上对特征点分别求平均值和最大值,分别得到关于平均值的空间特征图SAP和关于最大值的空间特征图SMP.然后通过拼接操作cat将两种特征图进行拼接,再利用7×7的卷积F生成空间注意力图,最后使用Sigmoid激活函数对不同位置的特征点进行强化或抑制.其计算过程如下:
MS=S(F(cat(AP(X′),MP(X′))))=
S(F(cat(SMP,SAP)))
(2)
在图1所示的注意力机制部分,本文通过卷积注意力模块,将浅层网络传递的特征信息分别从空间域和通道域进行不同区域的关注,提高有用信息的比重,并减少背景信息的影响.如图1的注意力机制部分和图2所示,输出的底层特征图被注意力模块(CbamBlock)给予不同的权重.通过将其与高层特征相结合,提取出模型的有用特征,从而增强网络学习的目标特征信息,此外,这种方法基本上不会增加模型的大小,也不会增加训练和推理成本.
2.2 检测头部解耦
在目标检测中,Song等[23]通过对空间敏感性热图进行可视化,发现分类和定位所关注的感兴趣区域的不同,分类更关注于显著性区域信息,定位更关注边缘区域的信息,由此可以看出分类和定位任务之间的耦合一直存在冲突问题.YOLO系列之前是将分类和定位信息耦合在一起,Ge等[24]提出的YOLOX模型在YOLOv3的基础上采用无锚anchor-free并对检测头部进行解耦.该模型在检测头部首先使用1×1的卷积来减少通道维数,然后使用两个平行的分支,每个分支都包含两个3×3的conv层,分别来处理分类和定位任务,以达到提升模型性能的效果.但由于本文选用的YOLOv5s进行危险品检测,其在有锚框的检测,仍旧使用的是定位和分类耦合在一起的检测头,因此本文将YOLOX中的解耦头应用在YOLOv5s下的有锚检测中,并且在其基础上进行了进一步的改进,其具体处理过程如图5所示.
将模型提取的特征图通过1×1的卷积降维,可以得到256×H×W的特征图Y,将得到的特征图分别输入三个平行的分支,三个分支分别处理分类任务、置信度得分和定位任务.
在分类任务分支中,对特征图进行R1(reshape)操作,使其变成H×W×256的特征图,将得到的特征图依次经过两个全连接层f1和f2,对其分类特征进行整合计算,再经过全连接层f3,得到H×W×36的分类特征图.最后再对其进行R2(reshape)操作,得到特征图Y1(36×H×W),计算公式如下:
Y1=R2(f3(f2(f1(R1(Y)))))
(3)
在置信度得分的分支中,将其看作是一个软标签分类任务,对特征图Y进行R1(reshape)操作,再经过全连接层f4对置信度特征进行整合计算,最后经过全连接层f5,得到H×W×3的置信度特征图,对其进行R2(reshape)操作得到特征图Y2(3×H×W),其计算公式如下:
Y2=R2(f5(f4(R1(Y))))
(4)
在定位任务的分支中,使用卷积C1和卷积C2依次对其定位特征进行整合计算;再经过卷积层C3得到定位特征图Y3(256×H×W),计算公式如下:
Y3=C3(C2(C1(Y)))
(5)
最后是将三个分支得到的结果按照通道维度进行cat连接操作得到最终的输出特征图Y′.其计算公式如下:
Y′=cat(C3,C2,C1)
(6)
本文通过上述方法对YOLOv5s的检测头进行解耦,解耦部分如图1 head(解耦头)部分和图5所示,将提取后的特征分别进行定位任务与分类任务处理.根据定位任务和分类任务的特性,为定位任务选择卷积层进行处理,为分类任务选择全连接层进行处理,使YOLOv5s模型在X光图像危险品检测中的检测精度有了较大的提升.
3 实验结果及分析
本文基于NVIDA GeForce GTX 3090显卡、32 GB内存的 centos和 pytorch框架展开实验.
3.1 数据集及评价指标
本文实验所使用的数据集是Wang等[25]在2021年公开的大规模违禁品检测数据集pidray,其包含了47,677张X射线图像下违禁品图像,种类为12类,分别是枪、刀、扳手、钳子、剪刀、锤子、手铐、警棍、喷雾器、充电宝、打火机和子弹,每个种类在数据集中所占的比例如图6所示.
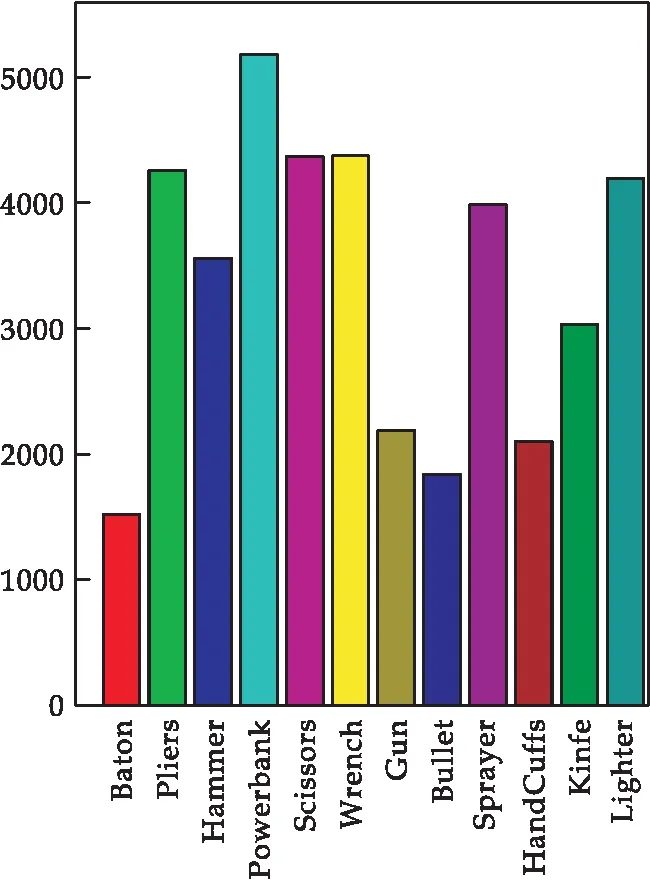
图6 数据集中各类危险品数量
本文使用多种关于目标检测模型性能评估指标来衡量危险品检测的准确性,包括预测精度(Precision)、召回率(Recall)、均值平均精确度(mean average precision,mAP).
精度定义为:
(7)
召回率定义为:
(8)
均值平均精确度定义为:

(9)
其中,TP表示正确检测出危险品的数量,FN代表被判定为背景的危险品数量,FP代表将背景区域判定为危险的数量.
3.2 模型评估
为了验证本文所选模型算法的优越性,首先用本文改进的att_decouple_YOLOv5s模型在pidray数据集上进行训练,并将训练结果与RetinaNet、Faster R-CNN、Mask R-CNN、SSD512和Cascade R-CNN等模型在pidray数据集上的训练结果进行对比,对比结果如表1所示.在pidray数据集上,本文改进的att_decouple_YOLOv5s模型,相比于RetinaNet、Faster R-CNN 、Mask R-CNN,mAP、SSD512和Cascade R-CNN,其mAP性能分别提高了25.1%、22.4%、20.8%、19%、15.6% .从实验结果可以看出,相较于目前主流的目标检测模型,本文改进的att_decouple_YOLOv5s模型更加适用于X光图像危险品检测.

表1 各个模型mAP对比
3.3 消融实验
为了进一步验证本文所提算法的有效性,将实验时所有对比模型的输入图片大小都统一设置为416*416,batch-size大小设置为32,并通过多组对比实验验证本文所采用的各个方法的有效性.
为了验证本文在YOLOv5s网络的FPN处引入注意力机制的有效性.首先在YOLOv5s网络模型的FPN结构中加入注意力机制,将加入注意力机制后的模型命名为att_YOLOv5s,在模型的各个参数与YOLOv5s模型各个参数设置相同的情况下在pidray数据集进行实验.实验结果如表2所示,改进的att_YOLOv5s模型相比于YOLOv5s的精度提升了3.4%,而召回率只下降了0.1%,在IoU阈值为0.5的情况下,模型的mAP提升了0.7%,在IoU阈值为0.5到0.95的情况下,mAP只下降了0.1%,表明注意力机制在FPN出的引入有效性.而对比模型的参数量,如表3所示,YOLOv5s参数量为7042489,att_YOLOv5s参数量为7075275,比YOLOv5s模型的参数量只增加了0.46%,表明引入注意力机制基本上不会增加模型体量.由此可见,在YOLOv5s模型的FPN处引入注意力机制对特征提取的有效性.
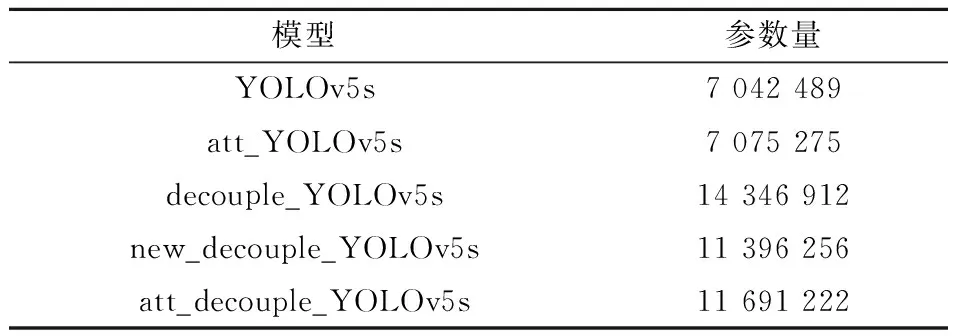
表3 模型参数量对比
为了验证本文在YOLOv5s中引入解耦头以及对解耦头改进的有效性,本文在YOLOv5s中head预测部分,引入了解耦头,将引入解耦头后的模型命名为decouple_YOLOv5s,并且对引入后的解耦头用全连接层替换定位分支和置信度分支的卷积层,将重新设计解耦头之后的模型命名为new_decouple_YOLOv5s.仍旧是将改进后模型各个参数与YOLOv5s算法模型各个参数设置相同的情况下进行实验.实验结果如表2所示,YOLOv5s加入解耦头后的decouple_YOLOv5s模型相对于YOLOv5s模型,模型的精度提升了1.1%,召回率提升了1.1%;在IoU阈值为0.5的情况下,mAP上升了1.5%;在IoU阈值为0.5到0.95的情况下,mAP上升了2.1%.而对于参数量来说,如表3所示,decouple_YOLOv5s模型参数量相比于YOLOv5s模型的参数量,只增加1.03倍.证明了在YOLOv5s中引入解耦头的有效性.而new_decouple_YOLOv5s相对于YOLOv5s,精度提升了2.9%;相对于decouple_YOLOv5s,精度提升了1.8%;new_decouple_YOLOv5s在IoU阈值为0.5,相对于YOLOv5s,mAP提升了1.9%;相对于decouple_YOLOv5s,mAP提升了0.4%;在IoU阈值为0.5到0.95,相对于YOLOv5s,mAP提升了3.3%;相对于decouple_YOLOv5s,mAP提升了1.2%.而对于参数量来说,如表3所示,new_decouple_YOLOv5s参数量相比decouple_YOLOv5s模型的参数量少0.21倍.以上充分说明了对头部解耦,以及将分类问题用全接层处理的有效性.
为了验证YOLOv5s同时在FPN处加注意力机制和对头部解耦的有效性,本文在att_YOLOv5s模型中加入改进的解耦头,并将其命名为att_decouple_YOLOv5s,参数设置不变,对比实验结果如表2所示.通过对比综合评价指标发现att_decouple_YOLOv5s,无论是IoU阈值为0.5,还是在IoU阈值为0.5到0.95,其mAP都高于单独在FPN处引入注意力机制的att_YOLOv5,或者单独对头部解耦的new_decouple_YOLOv5s,进一步验证了同时在头部解耦和FPN处引入注意力机制能够有效提升模型的精度.
在通过观察最终改进后的模型训练时mAP的变化曲线,发现在epoch=200时候,模型的检测
性能仍旧有很大的提升空间.为了寻找最优epoch,本文又分别在其他参数不变的情况下,将模型分别训练了300 epoch和400 epoch,其模型mAP变化曲线如图7所示.从图7能够看出,200 epoch到300 epoch之间,模型mAP性能mAP有明显的提升,300 epoch到400 epoch之间,模型mAP性能基本保持不变,可见epoch=300的时模型性能达到最优.

图7 不同epoch下的mAP的变化曲线
最后,本文从测试图像中随机选取一部分危险品图像进行检测,检测结果如图8所示.

图8 模型改进前后对比图
图8(a)显示了在 X光图像背景下对钳子(Pliers)进行检测,原YOLOv5s模型所识别出钳子的置信度低于本文提出的att_decouple_YOLOv5s模型.图8(b)显示了在 X光图像背景下对充电宝(Powerbank)检测,原YOLOv5s模型将背景区域误检为剪刀(Scissors).图8(c)显示了在 X光图像背景下在对枪(gun)进行检测,原YOLOv5s将枪错检为剪刀,而本文提出的att_decouple_YOLOv5s模型不仅检测出了gun,而且取得了0.88的置信度.虽然本文提出的att_decouple_YOLOv5s模型将与锤子(Hammer)特征相似的背景区域错误检出,但是同时也给出了低置信度的打分.测试结果再一次验证了本文所提att_decouple_YOLOv5s模型的有效性和先进性.
4 结论
针对X光危险品检测任务中,其物品摆放复杂,背景复杂,危险品种类繁多,难以识别等问题,本文对经典的目标检测模型YOLOv5s进行改进,得到了一种新的att_decouple_YOLOv5s模型.首先通过在YOLOv5s网络的backbone和Neck的特征融合部分引入注意力机制,使浅层特征中有用特征的权重进一步加强,背景特征权重得到减弱,从而提升了特征融合的有效性.同时,在原YOLOv5s的检测头部分,通过对检测头部解耦,将分类任务和定位任务分开处理,减少了分类和定位因为耦合在一起所产生的冲突问题.在pidray数据集上进行了多组X光图像危险品检测的对比实验.
实验结果表明,所提的att_decouple_YOLOv5s模型无论是从模型复杂度,还是从模型的检测精度来说,其各项性能评价指标都比其他同类目标检测方法有明显的提升.在实际应用中,X射线图像中危险品种类繁多,远远不止12类.此外,X射线下的图像重叠严重,背景复杂,对X射线图像危险品的准确检测有着很大的影响.在未来研究工作中,本课题组将使用多个X射线图像危险品数据集,对更多类型的危险品进行检测.同时还将进一步研究更有效的X射线图像特征学习的模型和方法,缓解物品重叠和复杂背景的干扰,从而进一步提升X光图像中危险品检测的性能.
猜你喜欢
中学生数理化·八年级物理人教版(2023年10期)2023-11-30
奥秘(创新大赛)(2023年3期)2023-05-06
机电安全(2022年5期)2022-12-13
小天使·一年级语数英综合(2021年8期)2021-08-17
科学(2020年1期)2020-01-06
小哥白尼(野生动物)(2019年9期)2019-12-21
快乐语文(2019年9期)2019-06-22
妈妈宝宝(2017年2期)2017-02-21
IT时代周刊(2015年9期)2015-11-11
专用汽车(2015年4期)2015-03-01
