
天然气压缩因子宽温宽压连续计算新模型
2023-12-14 14:43马清杰吴春洪汤朝红孙广森
大庆石油地质与开发 2023年6期
马清杰 李 军 吴春洪 汤朝红 孙广森
(1. 中国石油大学(北京)石油工程学院,北京 102249;2. 中国石化西北油田分公司,新疆 乌鲁木齐 830011;3. 中国石化缝洞型油藏提高采收率重点实验室,新疆 乌鲁木齐 830011;4. 中国石化江汉石油工程有限公司巴州塔里木测试分公司,新疆 库尔勒 841000;5. 巴州康菲能源科技有限公司,新疆 库尔勒 841000)
0 引 言
在对油气藏模拟、动态分析、油气井测试、油气井工程和管道输送过程进行模拟时,天然气压缩因子是非常重要的物性参数[1-3]。由于模拟计算过程中温度和压力是连续变化且相互影响的,要求压缩因子必须是连续可微的,否则会因出现断点,造成模拟或计算的死循环。在计算天然气等温压缩系数、体积系数等热力学参数时,要用到压缩因子以及压缩因子的一级或二级偏导数[4-6],要求模型必须连续。随着高温高压气藏发现的越来越多,不少气藏压力和温度达到100 MPa 和400 K 以上。天然气压缩因子的Standing-Katz 图版[7]是计算压缩因子的标准图版,图版由0.2≤ppr≤15.0 和1.05≤Tpr≤3.00 的低压图版、15.0≤ppr≤30.0 和1.4≤Tpr≤2.8 的高压图版2 部分组成[8]。但图版使用不方便,工程上常用计算模型来求取压缩因子,计算模型分为显式计算模型和隐式计算模型,显式计算模型是采用多元非线性拟合等手段,直接拟合Standing-Katz 图版得到的经验公式,而隐式计算模型是以气体状态方程为基础,通过拟合Standing-Katz 图版,并赋予气体方程不同的常数项得到的经验公式。
显式计算模型[9-11]的优点是不需要迭代计算,计算便捷快速,不足是超出其拟合范围,误差不可预见。在现有的144 种以上的显式模型中,除王艺晨等[12]和Y.C.Wang 等[13]外,尚无完全涵盖0.2≤ppr≤30.0 和1.05≤Tpr≤3.00 范围的计算模型;大多数显式模型为了得到较好的拟合效果,采用分段拟合[14-17],影响了计算模型的连续性。隐式计算模型[18-19]大都是在Standing-Katz 图版低压区进行拟合的,对高温高压外推计算的精度是值得怀疑的[20]。隐式计算模型在低压区的计算精度较高,高压区的计算误差较大,进一步扩大拟合范围修正拟合常数后,低压区的精度也会变差。隐式模型必须迭代计算,迭代计算会导致计算模型无解[21]。笔者试算了DAK1975 模型在Tpr=1.50、ppr≥2.80 时和HTP1969 模型在Tpr=1.25、ppr≥2.25 时,无论如何设置初始值,模型均无解。
本文采用一个新的函数形式,对Standing-Katz图版的1.05≤Tpr≤3.00 和0.2≤ppr≤30.0 的数据,进行连续非线性曲面拟合,建立一个显式连续、简单、准确、温度压力范围大、符合工程计算要求、连续可微的快速求解天然气压缩因子的新模型。
1 新模型的建立
1.1 数据来源
对Standing-Katz 图版进行拟合时,在0.2≤ppr≤15.0 和1.05≤Tpr≤3.00 的区域,选用Poettmann-Carpenter 数字化版本数据样本5 940 组;在15.0≤ppr≤30.0 和1.4≤Tpr≤2.8 的区域,先把Standing-Katz 图版进行数字化,得到2 400 组数据高压样本,拟合过程共选用8 340 组的数据样本,对0.2≤ppr≤30.0 和1.05≤Tpr≤3.00 的数据进行连续拟合。
1.2 模型拟合
利用Origin2019 软件曲面拟合工具,选用微分形式简单的新函数,对Standing-Katz 图版的8 340组数据以ppr、Tpr为自变量,以压缩因子为因变量,用残差卡方检验来作为判定拟合的质量准则,进行非线性曲面拟合。经过10 次的迭代,使拟合卡方容差判别值收敛至1×10-9,拟合卡方残差容差值(Reduced Chi-Sqr)为2.574 2×10-4,拟合Standing-Katz 图版的数据与拟合平面的三维分布见图1。

图1 数据与拟合面的三维分布Fig. 1 3D distribution of data and fitting surface
拟合数据为8 340 组,拟合自由度为8 319 个,该模型的残差平方和(RSSE)为2.142,相关系数为0.998 5,得到了连续的计算模型,该模型的函数式为
其中:
式中:Z——压缩因子;ppr——对比压力,天然气压力与临界压力的比值;Tpr——对比温度,天然气温度与临界温度的比值;a—f——中间变量;A11—A61——拟合系数。
上述的式(1)—式(7)可以简写为
式中:i——拟合系数的行序号,取值范围为1—6的自然数;j——拟合系数的列序号,取值范围为1—6 的自然数;Aij——第i行第j列的拟合系数。
表1 给出了Standing-Katz 图版在0.2≤ppr≤30.0和1.05≤Tpr≤3.00 范围内曲面拟合所得到的系数拟合数值、标准误差和相关系数,系数拟合的标准误差的平均值为0.934 00%,相关系数的平均值0.999 98。说明拟合系数具有较高可靠性与可信度。
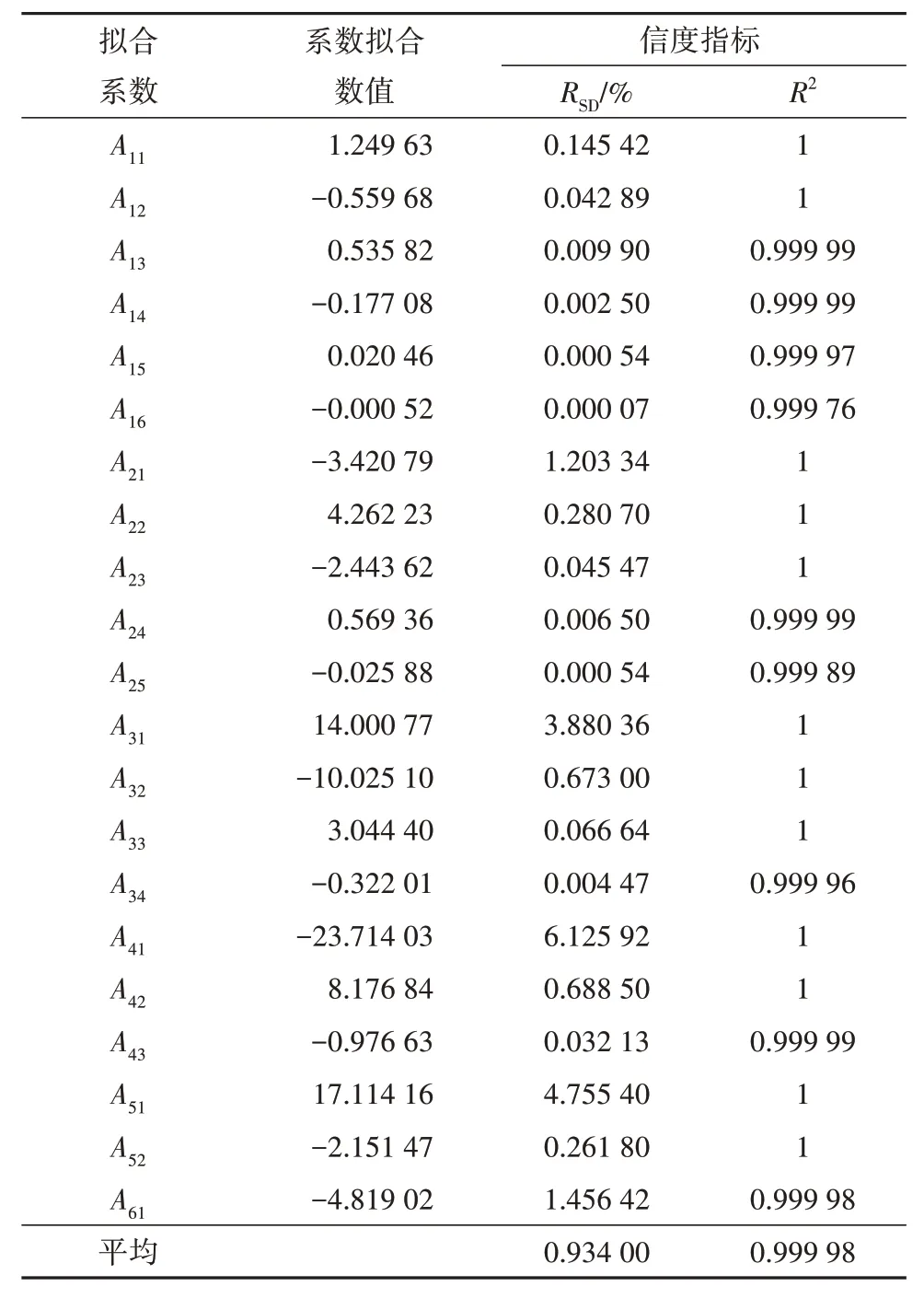
表1 模型系数拟合数值和信度指标Table 1 Model coefficients fitting values and reliability indicators
1.3 模型的微分形式
对式(8)求导,计算模型中压缩因子对温度、压力的微分式为:
式中:p——绝对压力,MPa;Tpc——临界温度,K;i和j——拟合系数的下标,均为1—6 的自然数。
对气体状态方程p=ρZRT与临界状态连列后求导,可得到压缩因子对密度的导数式为
式中:Zc——临界压缩因子;ρpr——对比密度。
D.Peng 等[19]给出天然气的临界压缩因子Zc值为0.27,故式(13)也可以表达为
由式(9)—式(14)可知,压缩因子对温度、压力和密度的偏微分形式是连续存在的,不存在断点和突变,与Standing-Katz 图版中的高压图版与低压图版的连续性一致。
2 结果与分析
2.1 性能评价指标
用平均相对误差、平均绝对误差、均方根误差、标准误差和相关系数等5 种统计学指标,来验证新模型的相关性、准确性和可靠性,使用的统计学评价指标的计算公式为:
平均相对误差表达式为
式中:——i点的预测压缩因子;——i点的实测或图版的压缩因子;N——样本数量。
平均绝对误差表达式为
均方根误差表达式为
标准误差表达式为
相关系数表达式为
2.2 模型拟合性能
图2 为新模型计算压缩因子的平均绝对误差的分布云图。图2(a)在0.2≤ppr≤15.0 和1.05≤Tpr≤3.0,图2(b)在15.0≤ppr≤30.0 和1.4≤Tpr≤3.0 时,分别反映了公式(1)在0.2≤ppr≤30.0时的拟合效果。
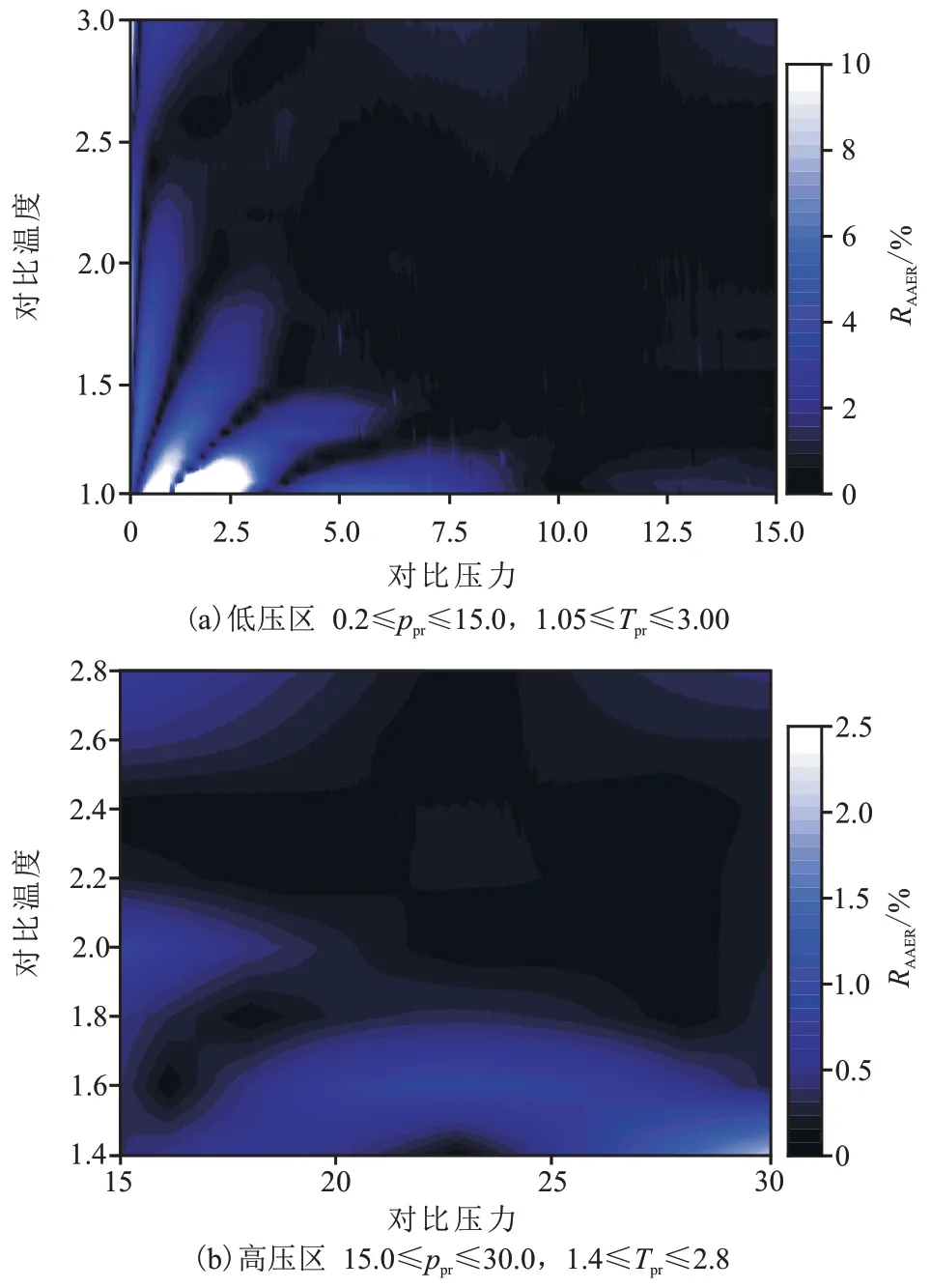
图2 压缩因子计算的平均绝对误差分布Fig. 2 RAARE distribution calculated by compressibility factor
在图2(a)所示的低压区内,最大平均绝对误差区域为低温低压区,即Tpr≤1.25 和ppr≤4 所围成的区域,其余的平均绝对误差均小于2%。低温低压区的较大平均绝对误差是Standing-Katz 图版在低压区中,压缩因子曲线段出现了严重的扭曲,无论采用非线性拟合(MNR)、神经网络(ANN)和基因编辑(GP)等手段,这部分与高温高压区相比,拟合精度都普遍较低。在图2(b)的高压区内,平均绝对误差均小于1%,拟合精度较高。
为了进一步评价拟合效果,对Standing-Katz 图版中的20 个不同对比温度分别进行拟合(表2)。由表2 可知,本模型的每个拟合温度的平均相对误差、平均绝对误差、均方根误差、标准误差和相关系数分别为0.17%、1.26%、0.015%、0.34% 和0.996。在20 条温度线里,除了Tpr为1.05 的第一条线的平均相对误差、平均绝对误差、均方根误差、标准误差和相关系数分别为1.91%、6.24%、0.016%、0.77%和0.989,其他温度下的平均绝对误差均满足工程计算要求。本次拟合Standing-Katz图版的范围大、函数结构合理,数据吻合度较高,拟合效果良好。
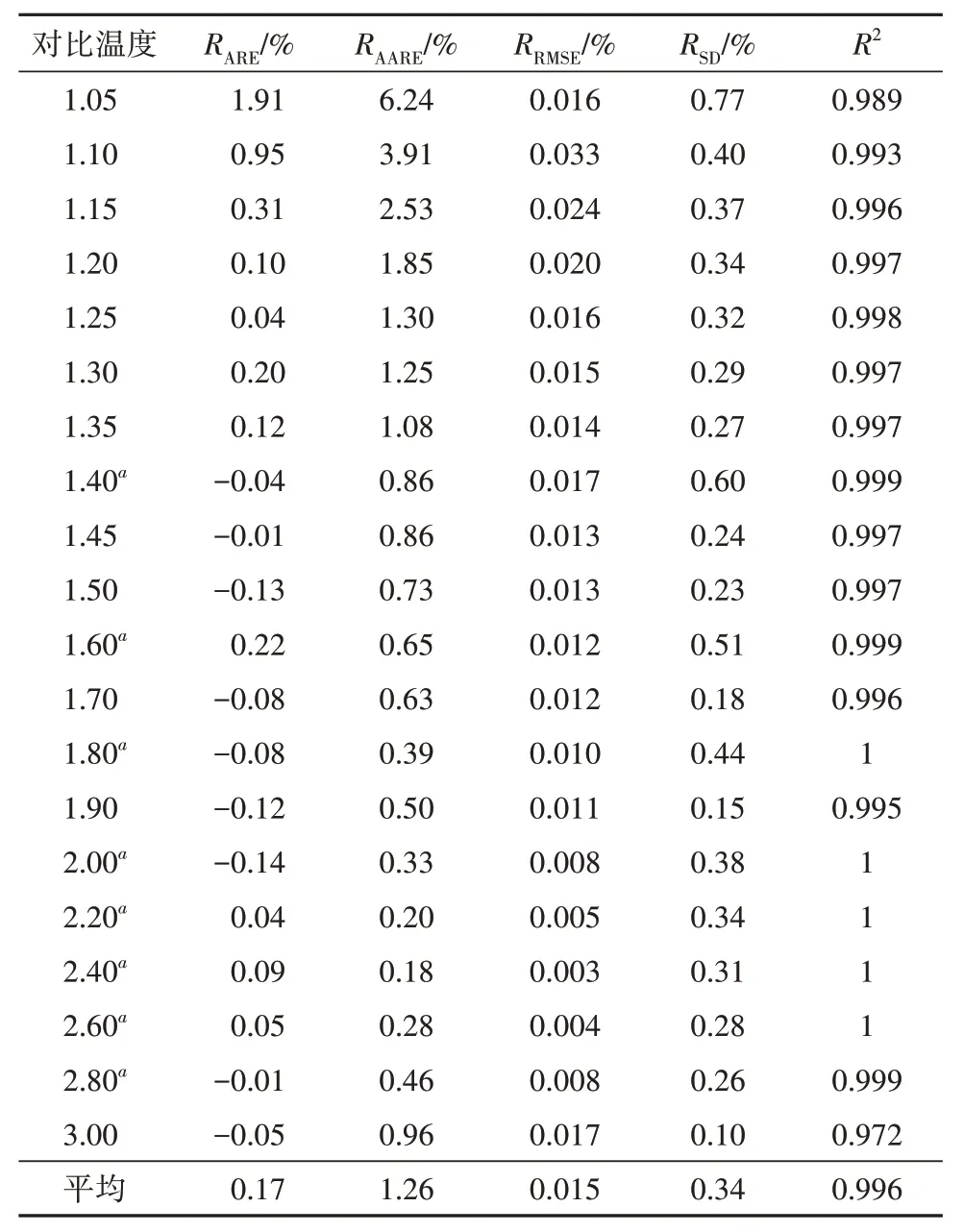
表2 不同对比温度的拟合效果Table 2 Fitting effects of different reduced temperatures
2.3 与经典模型的比较
为了更加客观精准评价新模型的拟合性能,避免因实际气体的混合与校正规则对天然气临界压力和临界温度计算造成的影响,直接采用Standing-Katz图版的数据,在0.2≤ppr≤30.0、1.05≤Tpr≤3.00 范围内,本模型与Papay1968[22]、Latonov-Gurevichi 1969[22]、Beggs-Brill 1973[22]、Shell oil Co.2004[22]、Heidaryan 2010a[22]、Mahmoud 2014[22]、Kamari 2016[22]、Ekeechkwu 2019[11]、Wang 2021[12]、Wang 2022[13]等10 个计算模型比较,对计算结果所产生0~10%平均绝对误差范围内的累计频率进行统计,绘制出平均绝对误差与累计频率关系分布图(图3)。

图3 不同计算模型的平均绝对误差与累计频率分布Fig. 3 RAARE and cumulative frequency distribution of different calculation models
在平均绝对误差小于5%的模型中,只有本模型与Wang2021、Wang2022 等3 个模型的累计频率超过了95%。本模型在平均绝对误差低于5%的区域,明显优于Wang2021、Wang2022 等2 个模型,其他模型的误差累计频率均低于80%。
3 临界参数和实例验证
3.1 临界参数
Standing-Katz 图版采用的混合规则[6],是Kay1936 基于甲烷、乙烷、丙烷、丁烷以及少量的氮气的二元混合气体绘制的,没有一种混合气体的相对分子质量超过40。矿场上的天然气成分复杂,直接利用Kay 混合规则计算临界压力和临界温度,来预测天然气压缩因子是不准确,必须结合天然气的组分,对临界参数选用合适的混合规则与校正规则,才能满足计算要求。
对于重烃摩尔分数小于1%、相对密度低于0.8、酸性气体(CO2+H2S)或惰性气体(N2、He)摩尔分数之和小于7%的天然气,有天然气全组分的采用Kay 混合规则计算临界压力与临界温度,对于组分不全的推荐采用Standing1981[23]密度法混合规则或Ahmed1989[24]的密度法混合规则计算临界压力和临界温度。对于重烃摩尔分数大于1%或者酸性气体和惰性气体摩尔分数之和大于7%的天然气,有天然气全组分的推荐采用SBV1959 混合规则计算临界压力和临界温度,对组分不全的,相对密度大于0.8 的推荐选用Sutton1985[23]或Elsharkawy2004[24]的密度法混合规则来确定天然气的临界压力和临界温度。天然气中CO2摩尔分数大于5%或H2S 摩尔分数大于3%,或CO2、H2S 和惰性气体摩尔分数之和大于7%,也或重烃摩尔分数大于5%的,利用相应的混合规则确定临界压力和临界温度后,必须对临界压力和临界温度进行校正。
校正原则:对于酸性气体和惰性气体的临界压力和临界温度校正,推荐采用Wichert-Aziz1972[25]校正规则进行非烃校正,对于重烃的临界压力和临界温度校正,推荐采用Sutton1985 校正规则进行校正,重烃与酸性气体和惰性气体都超过规定值,应先进行WA 校正,再进行Sutton1985 重烃校正。
3.2 验证实例
3.2.1 干气
利用文献[26]提供的四川新场气田ST1 井的数据,该井天然气中丙烷以上的含量为0,是典型的干气。表3 给出了ST1 井的天然气从136.7、146.7 和156.7 ℃的3 个温度下从73.00 MPa 到122.88 MPa 的11 个压力,共33 组压缩因子的测试数据(表3)。
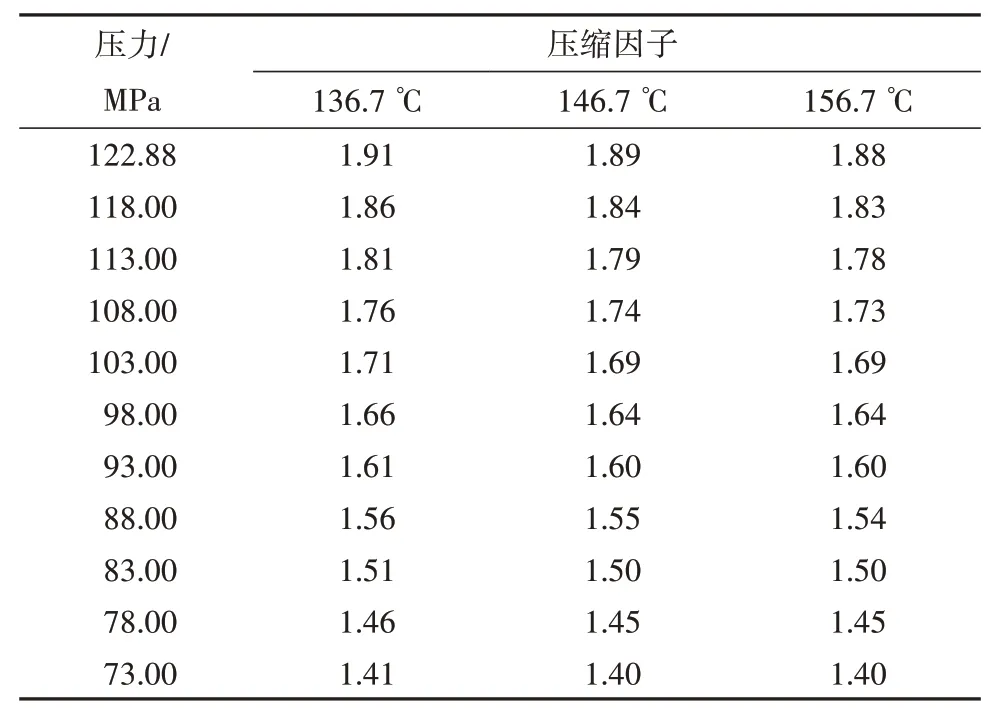
表3 ST1井天然气实测压缩因子Table 3 Measured compressibility factors of natural gas in Well ST1
图4 为9个模型预测干气压缩因子时的平均绝对误差,本模型的平均绝对误差为0.527%,Wang 2022和ZGD 2005 的平均绝对误差分别为0.549% 和1.515%,最差是HY 1973计算模型,误差为8.453%。表明本模型预测干气的压缩因子是准确的。
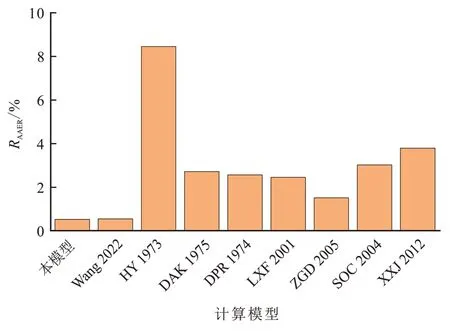
图4 不同模型的平均绝对误差分布Fig. 4 RAARE distribution of different models
3.2.2 凝析气
塔里木盆地XX-2 气田是异常高压凝析气藏,XX202 井为XX-2 气田的早期开发井,表4 是XX202 井天然气组分。对XX202 井在132.7、100.0、70.0 和40.0 ℃的温度下,压力从9 MPa 到110 MPa 进行了压缩因子测试,利用SSBV 等混合校正规则,确定的临界压力和临界温度是4.565 MPa 和212.631 K;本模型计算的平均绝对误差为0.809%。

表4 XX202井天然气组分及其摩尔分数Table 4 Natural gas components and their mole fractions of Well XX202
图5 是本模型与Papay1968、Beggs-Brill1973、Shell oil Co. 2004、 Heidaryan2010、 Kareem2016、Kamari2016、Ekechewu2019、Wang2022 等模型在不同压力与温度下预测压缩因子与实测压缩因子的偏差,本模型与零误差线的偏差最小,且偏差不随温度变化而变化,稳定性最好。

图5 不同模型的压缩因子计算值与实测值对比Fig. 5 Comparison between calculation values and measured values distribution of compressibility factors of different models
3.2.3 酸气
利用参考文献[27]提供的10 个样品,选择CO2和H2S 的摩尔分数之和低于55%的8 个样品做样本。表5 给出了8 个样本的天然气组分及其含量,样品中H2S 摩尔分数最高为51.37%,最低为6.80%;CO2摩尔分数最高为8.66%,最低为0.96%;C7+摩尔分数最高为6.79%,最低为0.04%;天然气相对密度最大为1.009 2,最小为0.786 4,是典型的高含酸凝析天然气。
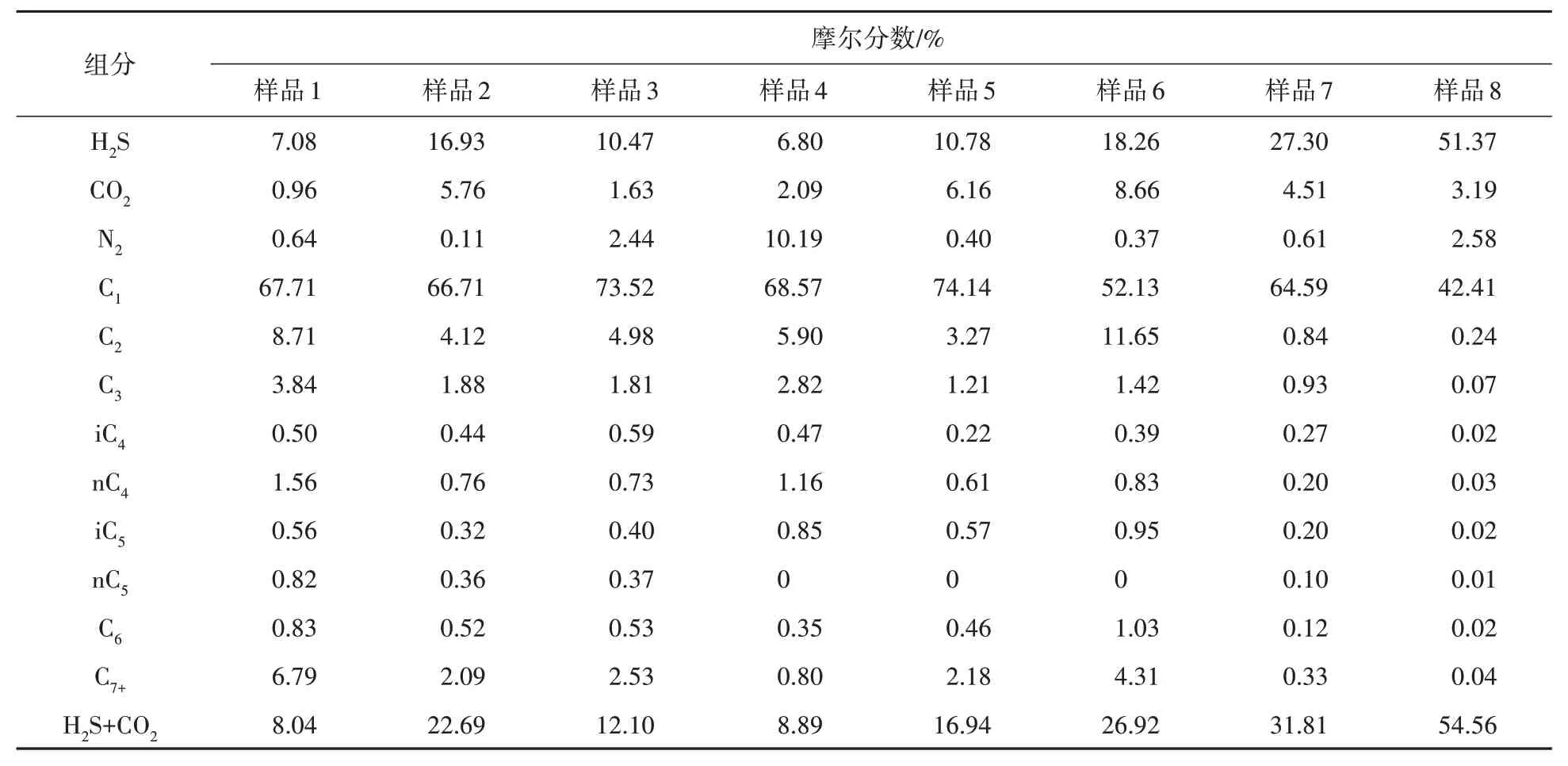
表5 不同样品的天然气组分及摩尔分数Table 5 Natural gas components of samples
表6 给出了本模型、DPR 1974、HY 1973、DAK 1975、SAREM 1961、HTP 1969 和BB 1973 共7 个模型,先采用Kay 混合规确定临界参数,则再对临界参数进行WA 非烃校正,天然气压缩因子的预测值与实测值的对比情况。样品的实测压缩因子的平均值为0.901,本模型计算平均绝对误差为0.110 9%,与本模型相近的是DPR 1974 和DAK 1975 这2 个模型,平均绝对误差分别为0.332 9%和0.998 9%,其他模型的计算误差都比较大,最差的预测模型为BB 1973 模型,其平均绝对误差4.444 0%。表6 表明本模型的预测值与实测值最为接近,预测效果最好。
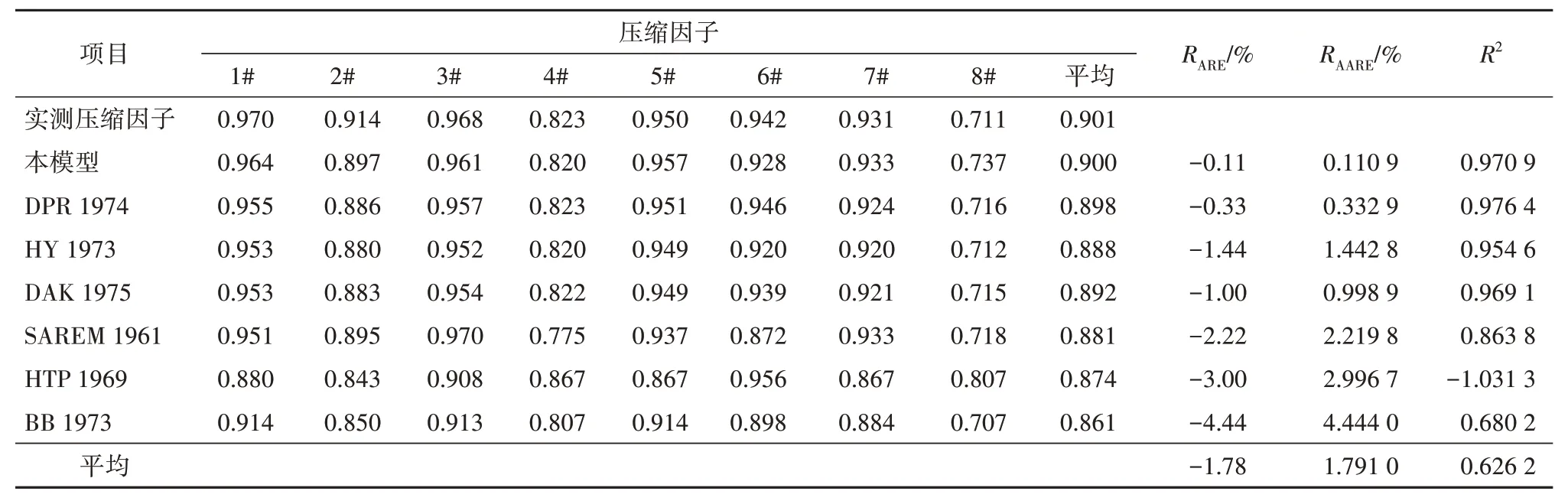
表6 Kay-WA校正的压缩系数对比Table 6 Comparison of compressibility factors calibrated by Kay-WA
4 结 论
(1)新模型的函数形式简单,拟合系数单一,连续可微性能优良,无需迭代计算,计算精度和效率高,适用温度和压力范围大,为矿场实践中快速准确预测天然气压缩因子提供了一个新手段,特别适用于油气藏、油气井和地面系统的连续模拟和计算。
(2)新模型给出了压缩因子对压力、温度和密度的微分式,新模型的微分式连续存在,特别适用于压缩系数、体积系数和焦耳汤姆逊系数等热力学参数的计算。
(3)新模型经过对干气、凝析气和酸性天然气的实例验证,以及与十多个经典计算模型对比,其对干气、凝析气和酸性天然气3 类天然气压缩因子预测的平均绝对误差分别为0.527%、0.809%和0.110 9%,是所有参与对比模型中精度最高的计算模型。
猜你喜欢
中国教育技术装备(2021年10期)2021-10-11
数学物理学报(2020年6期)2021-01-14
科技创新导报(2019年14期)2019-10-20
科技资讯(2019年8期)2019-06-18
中小企业管理与科技·上旬刊(2018年11期)2018-11-20
地球学报(2015年5期)2015-06-06
地球学报(2015年5期)2015-06-06
火炸药学报(2014年1期)2014-03-20
石油化工应用(2014年12期)2014-03-11
地方文化研究(2013年2期)2013-03-11
