
基于多任务与用户兴趣变化的短视频用户行为预测算法
2023-12-28 09:28顾亦然徐泽彬杨海根
复杂系统与复杂性科学 2023年4期
顾亦然,徐泽彬,杨海根
(南京邮电大学 a.自动化学院、人工智能学院;b.智慧校园研究中心;c.宽带无线通信技术教育部工程研究中心,江苏 南京 210023)
0 引言
随着5G网络的普及,人们可以使用更快速、更稳定的网络,用户可以获取的短视频数据,以及访问短视频资源的终端设备越来越多,短视频平台的用户规模和视频资源与日俱增,短视频行业蓬勃发展,越来越多的人利用短视频来消遣娱乐以及获得利润。随之而来的就是海量的用户信息以及视频信息。所以如何在信息过载的前提下,对海量的视频数据进行筛选,更加精确地将用户感兴趣的短视频推荐给用户,为用户提供个性化短视频推荐是当下需要研究的热点之一。
在短视频推荐相关领域,网络中的用户和项目都爆炸式增长,那么考虑用户与项目之间的交互过程即对用户观看短视频时的互动行为进行预测,可以为短视频推荐提供有力的支撑,对用户行为预测的本质就是对每种行为的点击率(Click-through-rate,CTR)进行预测。点击率预测[1]为推荐系统提供了支持与保障[2]。点击率预测根据用户、项目及上下文特征预测用户点击该项目的概率,帮助搜索引擎、推荐系统等向用户展示更个性化、更精准的内容。
近年来,随着数据量的日益庞大以及深度学习和神经网络的飞速发展,越来越多的学者利用神经网络来进行点击率预测,并取得很好的效果,文献[3]将宽结构网络(类似LR)和深结构网络(类似DNN)并行集成在一起,通过考虑低阶和高阶特征交互取得了一些改进。由于FM在点击率预测上有上较好的效果,文献[4]通过用FM模型替换宽结构网络来改进文献[3]中的模型,使得宽结构网络不再依赖专业知识特征工程。现如今某些项目中点击率预测需要对用户的多个行为进行预测,由于多个任务间可能存在某些联系,因此一些学者提出多任务模型,文献[5]提出了隐层参数硬共享的方式来进行多任务学习,该模型在输入层之上建立共享层,共享层使用一个共享的子网络,学习共同的模式,包含行为间关联信息。在共享层之上用一些特定的全连接层(FC)学习特定的任务。这是一种十分经典的方法,又称为共享底层结构(Shared-Bottom)。共享底层结构最大的缺点就是底层强制共享,难以学习到适用于所有任务的表达,尤其是任务间相关性不好的时候。文献[6]提出一种基于点击率预测模型的新闻推荐系统,通过一键编码和梯度增强决策树处理数据特征,解决传统新闻推荐中受时间、不活跃用户比例高、新闻数据规模大等因素影响的问题。文献[7]提取用户行为序列的特征作为用户特征的扩展,结合因子分解机结构将其与用户、商品特征进行交叉,能够有效提取特征质量,优化点击率预测模型的性能。文献[8]提出一种融合结构的点击率预测模型,该模型能够灵活融合不同结构的深度神经网络来分别学习原始高维稀疏特征的高阶表示,使点击率预测模型能够利用更丰富的高阶特征信息,提高预测精度。上述方法在点击率预测时没有考虑到用户历史数据中蕴含的用户兴趣,只是将最终的点击率预测结果作为用户的偏好兴趣,文献[9]构建了一种基于注意力机制的深度兴趣网络(ADIN)模型,设计了一个局部激活单元和自适应激活函数,根据用户历史行为和给定广告自适应地学习用户兴趣,提高点击率预测精度。文献[10]提出一种名为专注胶囊网络(ACN)的方法,使用transformers进行功能交互,利用胶囊网络从用户历史记录中捕获用户多个兴趣,提高在线广告中点击率预测精度。文献[11]提出一种基于DIN(深度兴趣网络)的新模型,该模型可以更好地利用类似于注意力激活网络的数据结构,捕捉用户多样性和兴趣偏好,提高淘宝点击率预测效果。上述提到的一系列点击率预测方法只是将整体预测结果反映为用户的兴趣偏好或采用某个方法捕捉用户兴趣,没有考虑到用户的兴趣会随时间发生变化这一因素。
本文在对用户观看短视频过程中的4种互动行为(读评论、点赞、点击头像、转发)进行点击率预测时,主体是用户。现实中短视频用户兴趣可能是随着时间变化的,考虑用户兴趣变化这一因素对提升预测准确性尤为重要。本文在MMOE模型[12]的基础上考虑用户兴趣变化,将排序后的用户历史行为序列作为语料库,引入Word2Vec训练得到词嵌入模型,模型学习用户的动态兴趣,有效捕获用户兴趣的变化。将通过特征工程构建的统计特征与词嵌入模型构建的用户动态兴趣特征输入MMoE模型进行用户行为预测。
1 相关工作
Word2vec是Google在2013年开源的一款将文本表示为向量的词嵌入工具[13],通过训练把一些文本内容转化为机器能够识别与理解的N维向量进行空间向量运算,Word2vec主要模型有Skip-gram与CBOW,在模型的实际训练过程中,Skip-gram的耗时多于CBOW,但是学习词向量更细致[14]。当语料库中有大量低频词时,使用Skip-gram学习较为合适。Skip-gram是使用中心词预测周围词,而CBOW是使用周围词预测中心词,两模型整体结构相反,这里仅以Skip-gram模型为例进行介绍。
Skip-gram模型是根据已有的内容来预测上下文的,根据中心词Wt来预测其上下文词语Wt-c,…,Wt-1,Wt+1,…Wt+c的向量,其中c为上下文窗口大小。Skip-gram模型由三层神经网络构成,包括输入层、映射层、输出层。输入层为中心词Wt的one-hot向量,输入层与映射层之间的权重矩阵为Wv·p,映射层和输出层之间的权重矩阵Wp·v,输出层为词语出现在中心词周围的概率分布。中心词Wt的one-hot向量乘以模型训练后得到的权值矩阵Wv·p,即词语Wt的Word2Vec词向量。Skip-gram 模型的结构如图1所示。

图1 Skip-gram模型结构
对Skip-gram模型的训练目的就是让优化目标L的值尽可能地变大,优化目标L的计算公式为
(1)
其中,c(c>0)为表示的是窗口的大小,T为训练文本的大小。其中基本的Skip-gram模型计算条件概率的公式为
(2)
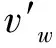
2 特征构建
本文首先在原始数据中抽取一系列基本id特征,基本id特征可以最直观地反映用户的选择。然后选取基本用户特征与短视频特征,并通过特征工程将选取的基本特征转化为更好表达问题本质的统计特征,使得将这些特征运用到预测模型中能提高对不可见数据的模型预测精度。最后构建能反映用户兴趣变化的embedding特征。
2.1 基本id特征
基本id特征包括用户id,短视频id,短视频作者id,短视频背景音乐(bgm_song)id,以及短视频背景音乐歌手(bgm_singer)id。
2.2 统计特征
统计特征就是利用统计分析方法,在原有的基本特征的基础上计算得到新的特征。本文主要是从用户、短视频以及短视频作者这3个层面来构建统计特征。从用户的层面,构建的统计特征为:用户视频观看时长、停留时长占视频总时长的比率、用户观看过的视频数量、用户与短视频某一交互行为的总次数、平均次数、用户观看某一作者视频占观看的所有作者的比率;从短视频的层面,构建的统计特征为:某一个短视频被用户观看的次数;从短视频作者的层面,构建的统计特征为:某个短视频作者被点击过的次数以及观看某个视频作者的用户占所有用户的比率。统计特征总览如表1所示:

表1 统计特征总览表
2.3 Embedding特征
用户的历史行为数据中蕴含了用户自身的偏好和兴趣,但是用户的兴趣并不是不变的,随着时间变化,用户兴趣可能也会发生变化。本文从数据中提取用户-短视频序列、用户-短视频作者序列、用户-短视频背景音乐序列、用户-短视频背景音乐歌手序列。下面以用户-短视频序列为例,其中包含了每个用户历史观看的所有的短视频id,但这仅仅能反映用户的整体偏好,不能反映用户的兴趣变化,本文考虑时间因素,在提取用户-短视频序列时先将数据按照时间顺序进行排序,再进行提取,这样便可提取出每个用户按照时间顺序的排序历史观看短视频序列,这个序列不仅反映了用户偏好,也蕴含了用户一段时间的兴趣变化。由于模型只接受数值型输入,因此需要将序列中的元素进行向量化,本文利用Word2vec来得到词向量。
本文将按时间顺序排序的用户历史观看序列作为语料库,通过numpy计算语料库中词语词频,图2为随机抽取的部分语料库词频:图2中数字表示词出现的次数,从图2中可以看出语料库中有大量低词频。因此本文采用的是Skip-gram模型。

图2 部分语料库词频
本文将按时间顺序排序的用户历史观看序列作为语料库引入Word2Vec训练得到词嵌入模型,模型学习到用户的动态兴趣,有效捕获到用户兴趣的变化,通过词嵌入模型得到序列中短视频id词向量,构建embedding特征,embedding特征中蕴含了用户对于短视频的兴趣变化。通过同样的方法处理用户-短视频作者序列、用户-短视频背景音乐序列、用户-短视频背景音乐歌手序列,得到一系列蕴含用户兴趣变化的embedding特征。
3 多任务分析与模型选择
本文需要尽可能准确地对短视频用户在观看短视频过程中的互动行为发生概率进行预测。对多个行为发生概率的预测,可以看做模型需要去完成的多个任务,选择一个合适的模型,可以提高行为预测的准确性。不同的模型适合不同的多任务应用场景,当任务间的相关性忽略不计时,使用单任务模型即可完成相应的工作,当任务间存在相关性时,使用多任务模型便是更好的选择。本文将对任务间的相关性进行分析,并选择合适的模型进行实验。
3.1 任务相关性分析
在对于短视频用户行为(如:查看评论、点赞、点击头像、转发)的相关性进行分析时,如果仅从行为本身,很难将用户行为具体量化地来进行分析,于是本文使用在2.2节构建的与用户行为相关的统计特征之间的相关性来间接衡量用户行为间的相关性。在每个用户观看的多个短视频中,统计各个行为的和,利用行为统计特征来进行相关性分析,得到用户行为特征相关性图,如图3所示,图3中数字为正表示正相关,数字为负表示负相关。由图3看出,短视频用户在观看短视频过程中的查看评论,点赞,点击头像,转发这4个行为中,点赞与查看评论是正相关的关系,点赞与点击头像是负相关的关系,而点赞与转发几乎不相关,可见不同的任务之间存在一定的相关性,同时也存在没那么相关的任务,任务间关系复杂。因此如果使用单任务模型来对每个任务单独进行训练的话,就忽略了任务之间的相关性的影响,所以,通过任务相关性的分析研究,本文使用多任务模型来对短视频用户的行为进行预测。多任务模型通过学习不同任务的联系和差异,可提高每个任务学习效率和质量。
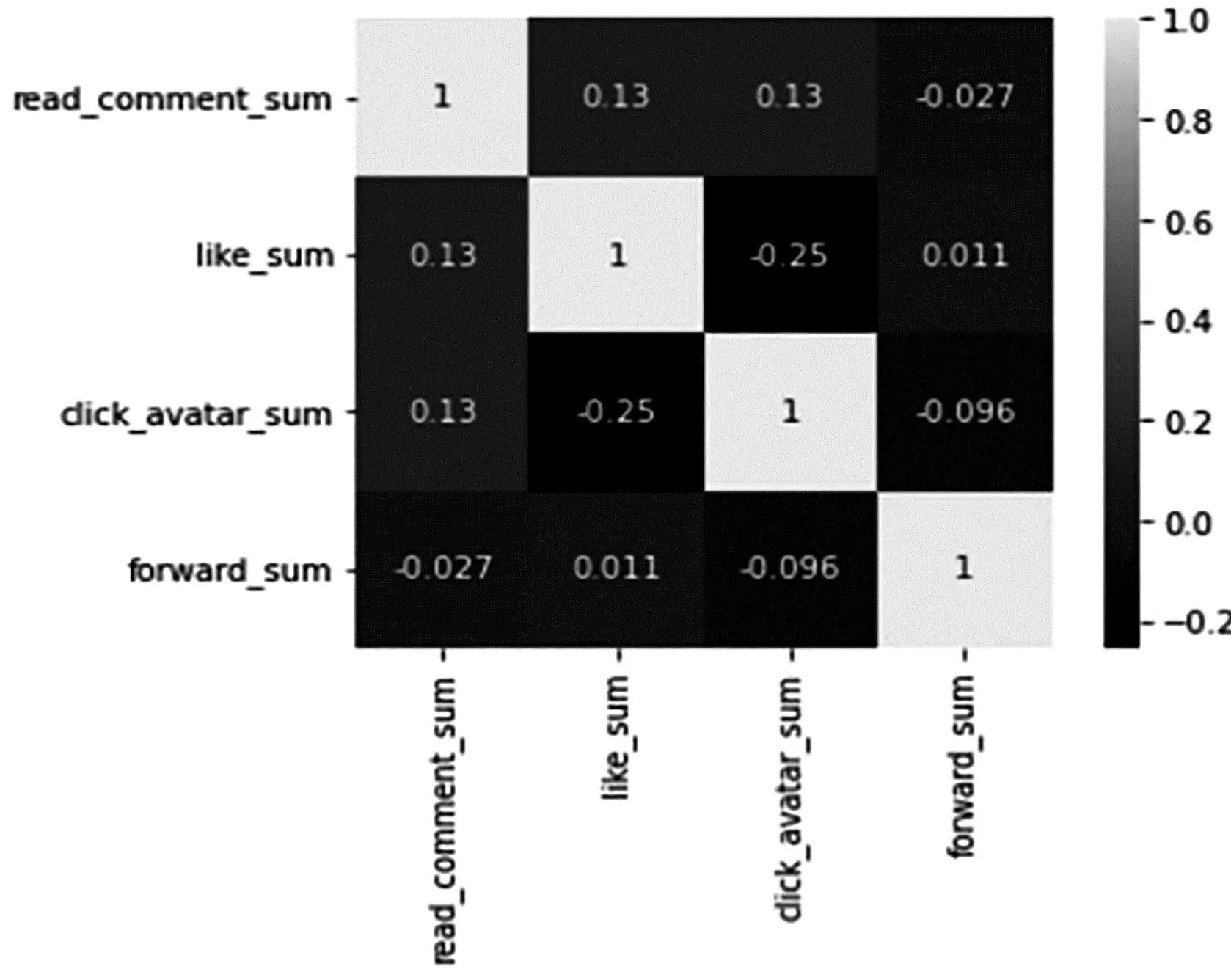
图3 用户行为特征相关性图
3.2 模型选择
通过3.1节对短视频用户行为特征间的相关性分析可知:多行为间既有相关性可以忽略不计的,又存在有一定相关性的。为了在任务间相关性不唯一的情况下也能通过模型的训练得到较为准确的预测结果,本文使用MMoE模型对短视频用户观看短视频时的行为发生的概率进行预测。
MMoE模型是Google的研究人员2018年提出的一种NN模型中多目标优化的模型结构。由于多任务共享底层模型最大的缺点就是底层强制共享,难以学习到适用于所有任务的表达,尤其在任务间相关性不好时,MMoE模型相较于共享底层模型,在共享底层结构的基础上将共享层进行替换,引入多个专家网络集群(即多个NN网络,全连接层FC),然后再对每个任务分别引入一个门网络,门网络的数量和任务的数量是一致的,不同的门网络针对各自的任务学习专家网络的不同组合模式,使不同的任务可以多样化地使用共享层。即对专家网络的输出进行自适应加权来筛选出适用于某任务的专家网络学习内容,不同任务对应的门网络输出权重分布不同,说明专家学到了针对不同任务的特征,专家网络与对应的门网络的组合结果作为共享层提取的隐含特征传递到该特定任务的特定网络层中。结构图如图4所示。
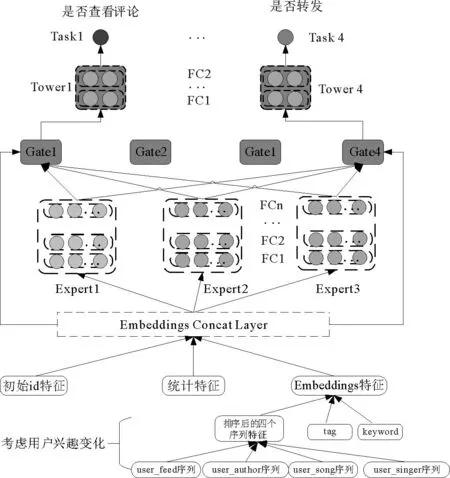
图4 考虑用户兴趣变化的MMoE模型图
其中输入为x(input feature),考虑到捕捉到任务的相关性和区别,不同任务的门网络可以学习到不同的组合专家的模式。不同的门为不同任务分配不同专家的权重,这种动态作加权和的操作,和attention机制的出发点是一样的。如果两任务间相关性不强,经门网络之后,二者得到的权重系数差别较大,可以利用部分专家网络输出的信息,近似于多个单任务学习模型。如果两个任务紧密相关,经过门网络得到的权重分布相差不多,类似于shared-bottom模型。
门网络的输入x也是,门控网络一般为多层感知机,并且门控网络需要通过一个softmax层,通过线性变换把输入映射到n*d维,再通过softmax计算得到每个Expert的权重,可形象化表示为
gk(x) = softmax (Wgkx)
(3)
其中,Wgk∈Rn·d为可更新的参数矩阵,n为专家个数,d为输入特征维数,gk(x)为第k个任务的各个Expert的组合权重。第i个Expert网络的输出为fi(x),则此时第k个任务的底层共享网络输出为
(4)
最终得到第k个任务的输出表达为
yk=hk(fk(x))
(5)
4 实验分析
4.1 实验数据集
本文的数据集来源于某大数据比赛公开数据集,数据集中的各项数据均采用脱敏处理。数据集包含了用户行为特征表和短视频特征表。用户行为特征表中包含某短视频平台2 000名用户14d内观看视频的1 048 575条历史行为数据,其中包括用户观看的短视频id,观看时长,停留时长以及用户观看短视频时是否有互动行为。短视频特征表中包含了106 447条短视频特征数据,其中包括短视频对应作者id,短视频播放时长,短视频背景音乐id和短视频背景音乐歌手id,以及人工提取的关键词和标签序列特征。
4.2 评价指标
预测用户的行为是否发生本质是一个二分类问题,当喜好阈值不确定时,通常使用AUC指标来衡量预测结果的准确性。本实验中采用uAUC作为单个行为预测结果的评估指标,uAUC定义为不同用户下AUC的平均值。公式为
(6)
其中,n为验证集中的有效用户数,有效用户指对于某个待预测的行为,过滤掉验证集中全是正样本或全是负样本的用户后剩下的用户。AUCi为第i个有效用户的行为预测结果的AUC。
本文对短视频用户行为预测的目的是为后续短视频推荐提供支持与保障。考虑不同的行为对最终推荐的作用不同,实验对200名经常使用短视频软件的用户进行调查,用户包含了各年龄层,通过调查发现将近一半的用户在看到感兴趣的短视频时会查看评论,占总人数比例最高,其余行为的人数占总人数比例由高到低为:点赞、查看头像、转发。可见站在实际为用户推荐其感兴趣的短视频的角度,行为预测模型若能对查看评论这一行为预测更准确,那么模型便具备更优的性能。行为预测模型对4个行为的发生概率进行预测,首先计算4个行为的uAUC,然后对每个行为的uAUC分配不同的权重,计算得到W-uAUC,W-uAUC能够更贴近实际应用来评估行为预测模型的好坏。4个行为的权重如表2所示。

表2 行为权重表
W-uAUC计算公式为
(7)
其中,uAUCi为第i个行为的uAUC值,Wi为第i个行为的权重。
4.3 数据集划分与模型对比实验
本实验将MMoE模型与shared-bottom模型以及在点击率预测领域比较有代表性的单任务模型Wide&Deep、DeepFM进行实验对比。为了保持特征的一致性,本文先在4个模型中只加入基础的id特征,包括用户id、短视频id、短视频作者id、短视频背景音乐id、短视频背景音乐歌手id与播放时长这6个特征。
本文以数据集中前7天的数据作为训练集,分别预测第8~14天的用户点击行为发生概率,结果如表3所示。
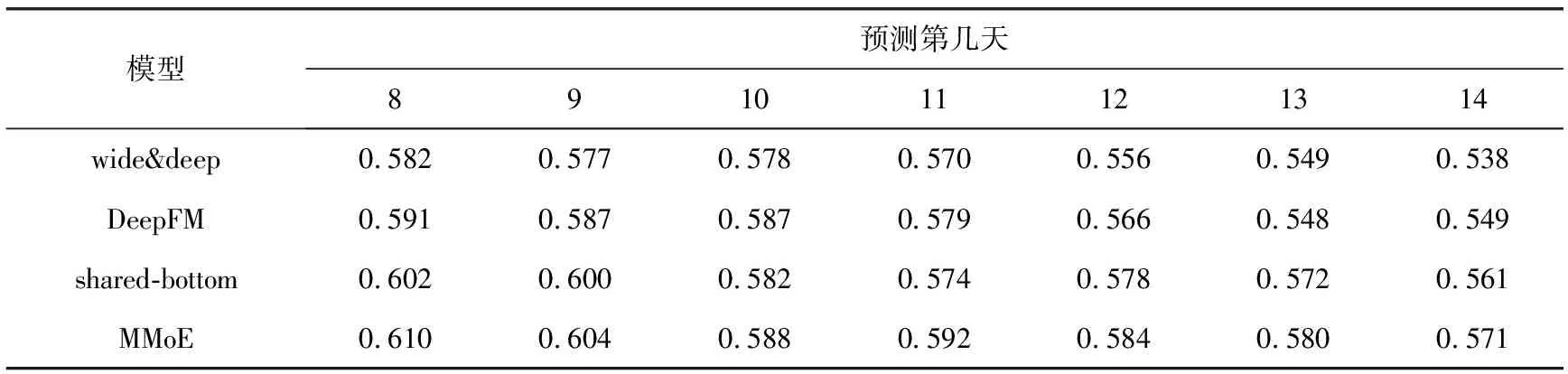
表3 前7天数据预测第8~14天各模型的W-uAUC得分
由实验结果可以看出,4个模型的预测精度随着时间的推移整体都在降低。不难看出,前面相邻天数的数据对预测的准确率影响更大,比如近一两天存在某些用户感兴趣的热点短视频。因此,本文将选取前几天的用户数据进行训练,对未来一天的用户点击率进行预测,以得到最优的预测效果。
本文分别选取前10天,前11天,前12天,前13天数据作为训练集,预测第11天,第12天,第13天,第14天用户的点击行为发生概率。结果如表4所示。

表4 由前10~13天预测后一天的各模型W-uAUC得分
由实验结果可以看出,当选取前13天作为训练集,预测第14天的用户点击行为概率,4个模型都具有最高的预测精度。因此最终本文选取前13天数据作为模型的训练集,第14天的数据作为验证集,预测第14天用户行为发生概率。经uAUC评价指标计算得到每个模型对于每个行为的预测得分如图5所示。可见MMOE对每个行为的预测准确性总体高于其它模型,计算4个行为的W-uAUC得分,如表5所示。
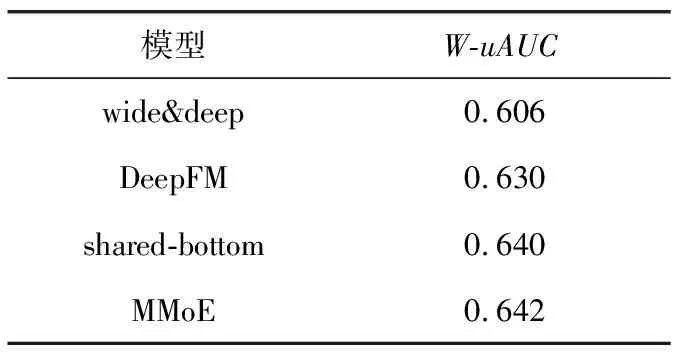
表5 各模型W-uAUC得分

图5 模型各行为得分
由实验结果可知:DeepFM的预测效果明显优于Wide&Deep,但是这两个模型都是单任务模型,对于每一个行为的预测都需要单独对模型进行训练,从而忽略了用户行为间的隐藏关联。多任务模型shared-bottom、MMoE的预测效果要优于单任务模型。MMoE模型利用门网络与专家网络相结合,考虑了行为间不同的关联性,预测效果相较于shared-bottom有进一步提高。MMoE预测的得分相较于Wide&Deep,DeepFM和shared-bottom分别有5.9%、1.9%与0.3%的提升,因为shared-bottom与MMoE同为多任务模型,而shared-bottom只是MMoE专家数为1的特例,所以在加入特征较少时,提升不明显。
4.4 考虑用户兴趣变化对预测效果的影响实验
MMoE在使用5个id特征与视频播放时长特征训练的基础上,先分别同时加入1.2节构建的一系列统计特征和1.3节构建的4个蕴含用户兴趣变化的embedding特征进行训练,MMoE对每个行为的预测的uAUC得分如图6所示,再计算W-uAUC得分如表6所示。

表6 不同特征下MMoE的W-uAUC得分
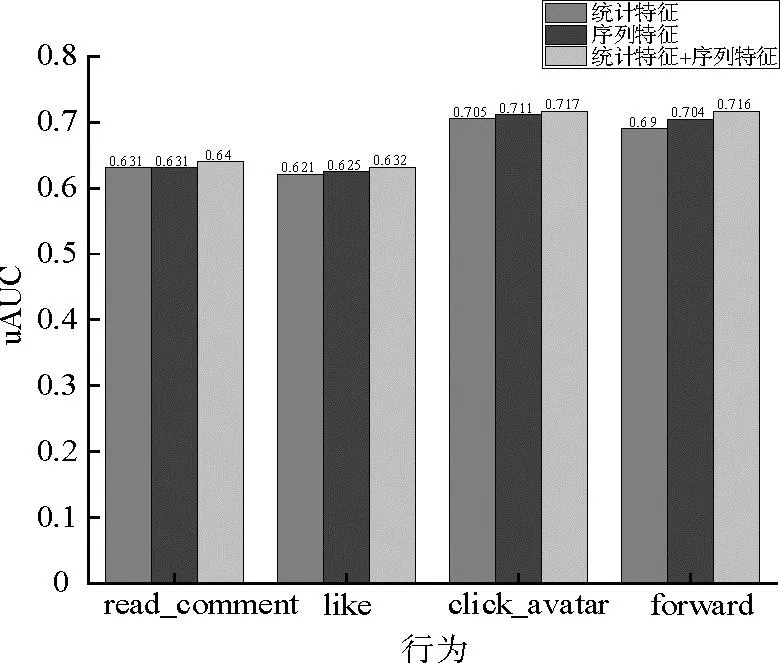
图6 MMoE使用不同特征下各行为uAUC得分
由实验结果可知,模型加入更好表达问题本质的统计特征,预测得分由0.642提升到0.649,加入反映用户兴趣变化的embedding特征,预测得分由0.642提升到0.652,说明MMoE模型考虑用户兴趣变化可提高预测性能,当同时加入统计特征与embedding时,得分提高到0.660,说明统计特征与embedding特征不会相互制约,同时加入模型不会出现过拟合现象。
4.5 模型参数调优
MMoE中专家数量是一个超参数,专家数量太少的话模型的表达能力不够,不能充分地学到针对不同任务的特征,数量过多的话又会增加模型的参数导致模型过拟合。本文使用验证集测试的方式来确定最优的专家数量。因为当MMoE的专家网络层只有一个专家时,模型中的门网络不起作用,则模型中只有一个单一的共享层,即为shared-bottom模型,所以将专家数从2开始进行设定,以步长为1对专家数进行递增来训练模型,模型对于不同专家数量的预测得分如表7 所示。
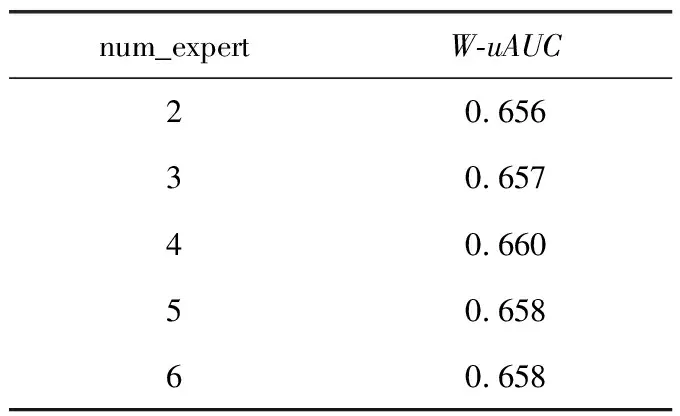
表7 不同专家数量下MMoE W-uAUC得分
由实验结果可知,当专家数设定为4时,模型具有最优的预测效果,当专家数量过少时专家网络对于不同任务的特征的学习不够充分,当专家数量大于4时,模型会产生过拟合,从而导致预测效果变差。在实验的最后阶段,同样使用验证集测试的方式对模型中的其它参数进行调优,最终模型预测的W-uAUC得分为0.661。
5 结论
本文对短视频用户行为进行预测,通过数据集构建一系列统计特征,考虑用户对短视频的兴趣可能会随时间而变,本文对蕴含用户兴趣与偏好的几组序列特征按照时间排序,并作为语料库利用Word2Vec训练得到词嵌入模型,模型捕捉到用户的兴趣变化并构建含有用户兴趣变化的enbedding特征。考虑任务间的相关性特点,本文选取MMoE模型进行用户行为预测,并根据短视频用户行为预测的目的,提出贴近实际应用的W-uAUC评价指标来评估预测模型好坏。通过实验分析,MMoE相较于shared-bottom、Wide&Deep、DeepFM能得到更精确的预测结果,并且考虑用户兴趣变化的MMoE模型具有最优的预测精度。未来将考虑在原有MMoE模型上进行改进,更准确地筛选出适用于某任务的专家网络学习内容。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
数学小灵通·3-4年级(2017年9期)2017-10-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
海峡姐妹(2015年8期)2015-02-27
河南科技(2014年23期)2014-02-27
