
基于改进NetVLAD图像特征提取的回环检测算法
2023-12-28 09:28邱长滨王庆芝刘其朋
复杂系统与复杂性科学 2023年4期
邱长滨,王庆芝,刘其朋
(青岛大学复杂性科学研究所,山东 青岛 266071)
0 引言
近年来,视觉同步定位与建图(Simultaneous Location And Mapping,SLAM)已成为自主移动机器人领域的研究热点[1]。回环检测(Loop Closure Detection,LCD)是视觉SLAM的关键环节之一,旨在判断移动机器人是否回到了先前经过的地方,并通过回环约束减少视觉里程计引起的累计误差,提高建图和定位精度[2]。
经典的回环检测算法大都采用手工特征来表征图像,比较典型的是词袋模型[3]。它利用SIFT、SURF、ORB等方法提取大规模图像数据集的局部特征点集合,然后利用K-Means聚类将局部特征点空间划分为若干聚类,聚类的中心称为视觉单词。所有的视觉单词聚集构成了视觉词典。一幅图像可以由局部特征点对应的视觉单词的集合来表征。在词袋模型的基础上发展出了Fisher 向量模型(Fisher Vector)[4]。Fisher Vector 采用高斯混合模型(Gaussian Mixture Model,GMM)构建视觉词典。研究表明采用该向量编码包含的信息比视觉词袋模型更加丰富,在图像分类及相关视觉任务上效果更优。作为Fisher Vector的简化版本,文献[5]提出使用局部聚合描述子向量(Vector of Locally Aggregated Descriptors,VLAD)来表征图像。该方法比词袋信息更丰富,同时比Fisher Vector计算简单。
随着人工智能的快速发展,卷积神经网络(Convolutional Neural Network,CNN)凭借强大的特征学习和表征能力,在图像分类、图像分割、目标检测、姿态估计、人脸识别等领域取得了巨大的成功[6]。为探索卷积神经网络在图像匹配和视觉回环检测方面的性能,文献[7]分析了AlexNet提取的图像特征,发现AlexNet网络的第3个卷积层(conv3)输出的特征对图像外观变化具有鲁棒性,全连接层(fc7)输出的特征对视角变化具有鲁棒性。文献[8]采用空间金字塔池化对AlexNet网络的卷积特征进行多尺度融合,更好地保留了图像的原始信息,对光照变化具有较强的鲁棒性。与直接使用预训练神经网络输出的CNN特征描述子相比,针对图像匹配专门设计的神经网络特征描述子性能更优。受VLAD启发,Relja等[9]提出了一种可进行反向传播训练的卷积神经网络版本的VLAD,称为NetVLAD,显著提升了对光照和视角变化的鲁棒性,并通过在多个尺度上提取描述子来保证尺度不变性。
为进一步提高NetVLAD特征描述子的精度,本文将空洞卷积(Atrous Convolution)引入到特征提取过程中。空洞卷积最早出现在图像语义分割的研究中,目的是在不增加训练参数的前提下提高特征图分辨率。回环检测的底层技术是图像匹配,即识别两幅图像是否具有相似的特征。理论上来说,空洞卷积提高特征图的分辨率,也将有助于提高图像特征对比的准确性。基于此,本文将空洞卷积引入到回环检测算法中。另外,考虑到图像在不同尺寸上表现出不同的特征,例如小尺寸图像中的一条光滑直线,放大之后可能呈现出非常粗糙的边缘。图像在不同尺寸下可以反映不同颗粒度的特征。为了更全面地提取图像特征,本文采用融合多种采样率的空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP)[10]。该结构可以有效地降低特征图的维度,并同时融合多尺度特征,保留了更多的空间信息,可以进一步提高特征图的分辨率和特征匹配效果。
1 基于改进NetVLAD图像特征提取的回环检测算法
1.1 算法整体框架
本文所提改进算法的整体框架如图1所示,其中NetVLAD图像特征提取由基于残差网络ResNet18的主干网络和基于ASPP模块改进的NetVLAD层两部分构成。
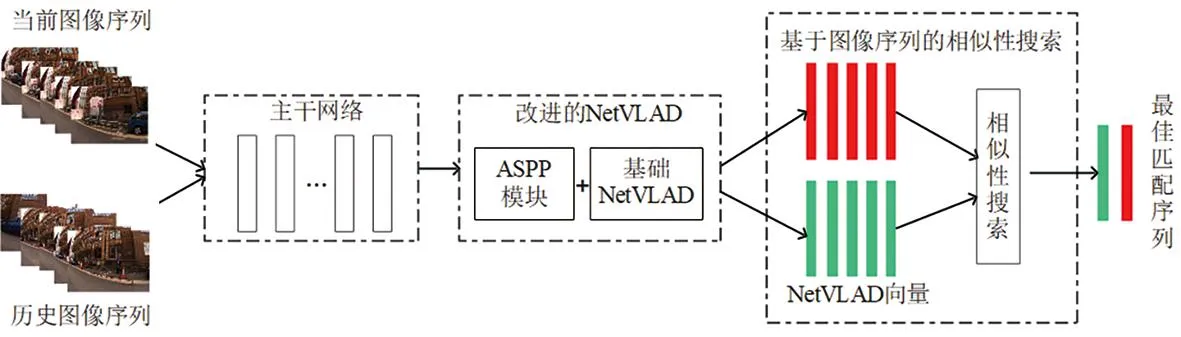
图1 本文回环检测算法整体框图
1.2 基于ResNet18的特征提取主干网络
本文采用基于ResNet18的残差网络[11]提取图像的局部特征,如图2所示。
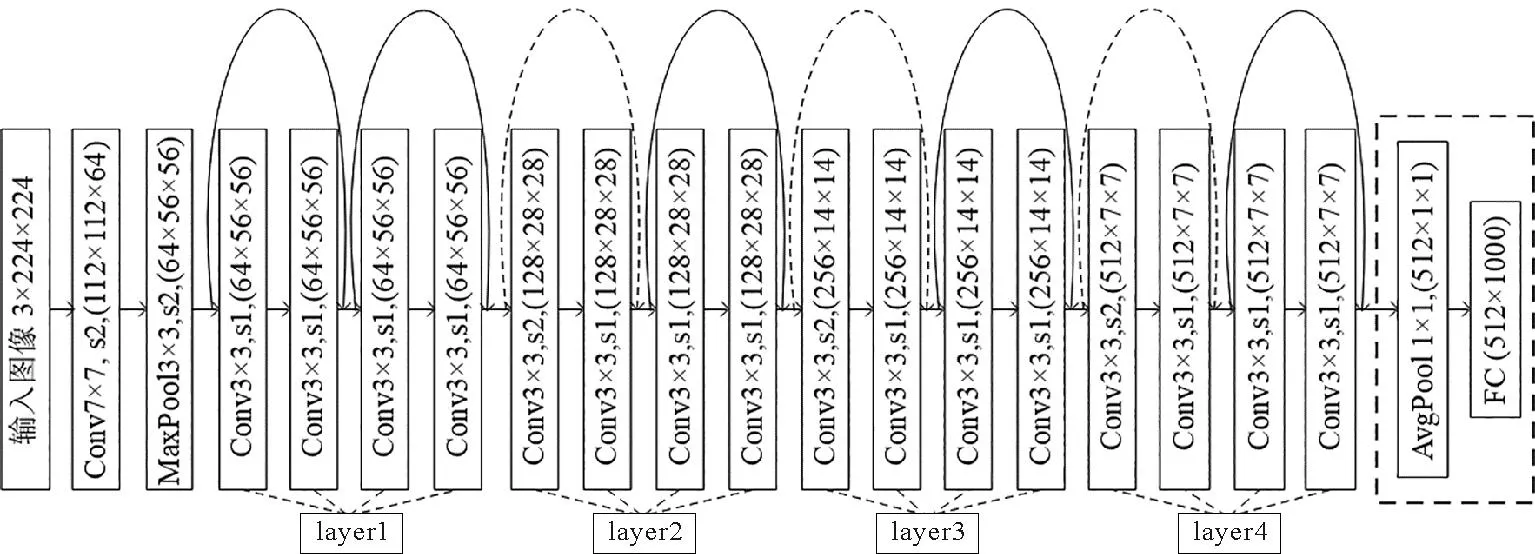
图2 主干网络结构图
与图像分类任务不同,这里只需要对图像进行特征提取,不需要分类,因此去掉了原ResNet18网络中最后的全连接层FC;此外,由于池化操作会降低特征图的精度,为了更大程度上保留原图的特征,去掉了全连接层前的均值池化层avgpool,最终得到由ResNet18的前16层构成的主干网络。
1.3 基于ASPP模块改进的NetVLAD
1.3.1 基础NetVLAD图像特征描述
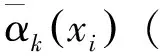
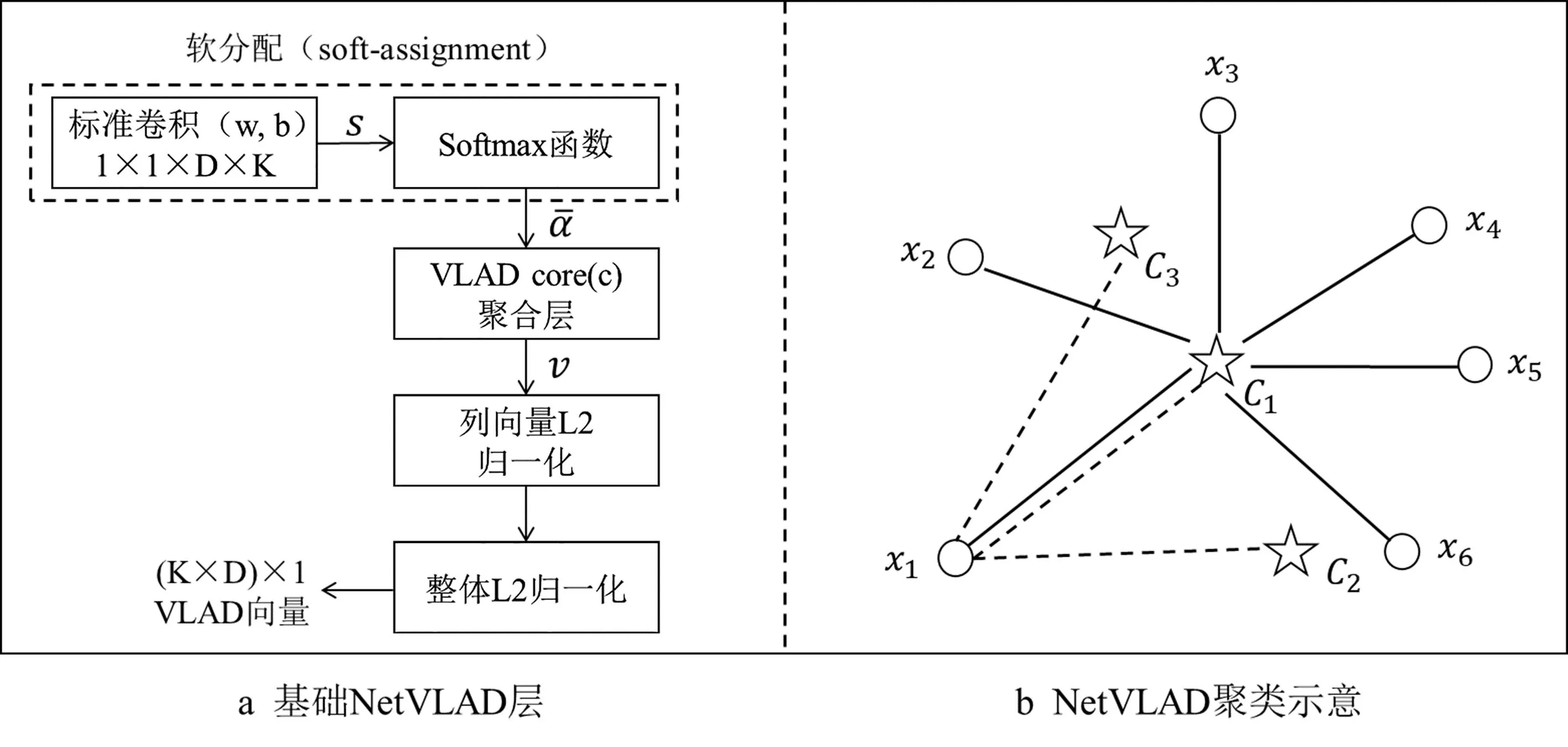
图3 基础NetVLAD层及其聚类示意图
(1)
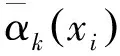
1.3.2 改进的NetVLAD图像特征描述
直接使用NetVLAD对图像进行表征存在两个问题:1)主干网络输出的高维特征直接进入NetVLAD层,计算成本较高,影响闭环检测任务的实时性;2)卷积网络经过多次卷积和池化操作后,输出的特征图越来越小,分辨率越来越低,导致得到的NetVLAD图像特征描述子精度较低,影响检测精度。为解决上述问题,本文将ASPP模块引入到NetVLAD中,对多尺度特征进行融合并降维,提高特征图的分辨率。此外,原始ASPP模块中采用了全局均值池化,更加关注全局特征,影响算法效率;为避免该问题,本文采用全局最大池化,只对局部感兴趣的区域进行池化,过滤掉特征图中的次要信息,提高算法效率。图4展示了改进NetVLAD图像特征描述的具体流程:
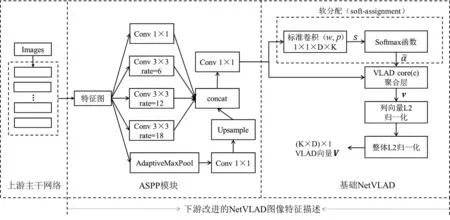
图4 改进的NetVLAD图像特征描述流程图
1)上游主干网络特征提取。维度为224×224×3的输入图像通过上游主干网络处理之后输出维度为512×7×7的特征图。
2)执行多尺度特征融合并降维。以并行方式分别进入:卷积核大小为1×1的标准卷积层、卷积核大小均为3×3采样率分别为6,12,18的3个空洞卷积层、全局最大池化层(后接一个卷积核大小为1×1的标准卷积层以及一个双线性插值的上采样层将特征图还原为原图大小);经过5次并行处理之后得到5个维度为512×7×7的特征图;横向拼接融合得到1个维度不变的特征图;再采用卷积核大小为1×1的标准卷积层将拼接后的特征图降维到指定通道数256,最终得到一个维度为256×7×7的特征图。
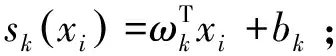
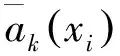
5)执行L2归一化操作。对矩阵v中的每一列D维向量进行L2归一化处理,然后将矩阵转化为向量,对整体再进行L2归一化处理,最终得到一个长度为K×D的VLAD向量V,作为对原始图像的表征。
1.4 基于图像序列的相似性搜索
为提高检测精度,SeqSLAM算法[12]通过计算两个图像序列(而不是两幅独立的图像)之间的相似性来判断移动机器人是否达到了之前的地点。与SeqSLAM类似,本文在进行相似性搜索时也采取图像序列对比的方式,以此来提高检测的鲁棒性。
图像序列之间的相似性由VLAD向量之间的距离决定。若两个图像序列对应的VLAD向量之间的距离较近,则说明两个图像序列相似,当前时刻可能产生了回环;反之,若距离较远,则说明两个图像序列差异较大,当前时刻未出现回环。本文采用比较常见的欧氏距离来计算图像序列之间的相似性。假设当前时刻的图像序列为Sq,先前某一时刻的图像序列为Sp,序列长度均为l,二者所对应的VLAD向量集合分别为VSq和VSp,表达式为
VSq={VSq1,VSq2,…,VSql},VSp={VSp1,VSp2,…,VSpl}
(2)
其中的元素为序列中单幅图像对应的 VLAD 向量。最终两个图像序列Sq与Sp之间的欧氏距离为
(3)
在搜索时,给定当前的图像序列,遍历所有历史序列,计算得到图像序列之间的距离,基于距离可以设计回环检测判定条件。例如设定固定的距离阈值,小于该阈值则认为检测到回环,通过调节距离阈值可以获得精确率和召回率之间的平衡(见2.1节实验)。
2 实验与分析
为验证本文改进算法,在公开数据集CityCentre和NewCollege上进行测试。CityCentre数据集中的图像拍摄于城市中心,总长度为2 km,共包含2 474张图像和26 976个回环。NewCollege数据集中的图像拍摄于校园内,总长度为1.9 km,共包含2 146张图像和14 832个回环,两个数据集中的图像大小均为640×480。图5为数据集部分图像。两个数据集中的图像均是由放置于轮式机器人左右两侧的相机拍摄的,机器人每行驶1.5 m采集一次图像。此外,两个数据集均提供了GroundTruth矩阵,包含了对于回环的真实标注,分别以2 474 × 2 474 和2 146×2 146的二维矩阵形式进行存储。若图像i和j是在同一地点拍摄的,则在矩阵中对应的(i,j)元素值为1,否则为0。

图5 数据集部分图像
本文在基于Anaconda3的深度学习框架Pytorch下进行实验测试,具体实验环境为:1)Intel Core i5-10400 2.90Ghz,2)NVIDIA GeForce GTX 1650,3)RAM 16GB,4)Ubuntu 18.04。实验中采用在Places365数据集上的预训练网络模型ResNet18,并将输入图像尺寸剪裁为224×224。表1为实验测试时的关键参数与取值。为验证本文改进算法的性能,本文分别在精确率-召回率(Precision-Recall,PR)曲线指标以及特征提取时间性能指标上将本文方法与其他方法进行了比较。
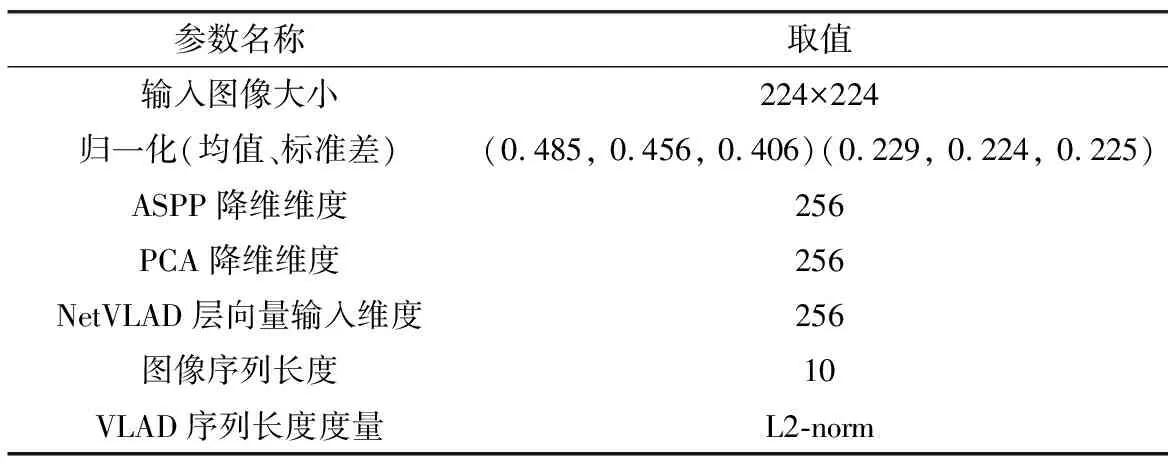
表1 实验关键参数与取值
2.1 PR曲线指标
在回环检测任务中,若两幅来自不同场景的图像被误判为同一个场景,则称这种错误为假阳性(False Positive,FP);若两幅来自同一场景的图像被误判为不同场景,则称为假阴性(False Negative,FN);反之,若正确地检测到了闭环,则为真阳性(True Positive,TP);若正确地检测到了非闭环,则为真阴性(True Negative,TN)。由此,精确率与召回率的定义为
(4)
本文选取5种算法进行实验对比,具体算法为:1)标准SeqSLAM算法(seqslam);2) 基于BoW改进的SeqSLAM算法(seqslam_bow);3)基于ResNet和NetVLAD的回环检测算法(resnet_netvlad);4)基于ResNet、PCA降维以及NetVLAD的回环检测算法(resnet_pca_netvlad);5)(本文算法)基于ResNet、ASPP以及NetVLAD改进的回环检测算法(resnet_aspp_netvlad)。其中1)和2)为基于传统特征的回环检测算法,3)、4)、5)为基于深度学习的回环检测算法。各算法相应的PR曲线如图6所示。
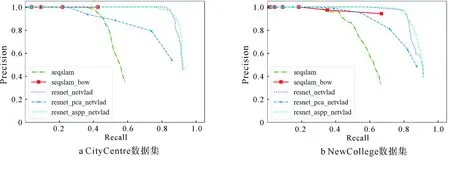
图6 以上算法在CityCentre 和NewCollege两个数据集上的PR曲线对比
从图6实验结果可以看出,基于深度学习的特征比手工特征效果更好,在提高召回率的同时,保持了较高的精确率。本文所改进的算法ResNet_ASPP_NetVLAD相对于改进前的算法ResNet_NetVLAD也有进一步的提升。此外,本文还将传统PCA降维方式与基于深度学习的ASPP降维方式进行了对比,实验结果表明在相同维度下基于ASPP的降维方法比传统PCA降维方法效果更好。
图7中展示了部分回环检测的结果以表明算法的鲁棒性。由于测试图像是机器人在行驶过程中采集的,即使回到同一地点,相应图像的视角、光照等均会发生变化,本文算法能够正确识别出这些回环,说明了该算法对外观变化具有一定的鲁棒性;此外,尽管图7a3和7b2存在动态目标:行人(圆圈标记),但本文算法仍能正确判断出回环,进一步说明该算法能够较为准确地提取环境信息,对干扰物具有一定的鲁棒性。

图7 回环检测示例图
2.2 时间性能指标
除了比较PR曲线性能指标外,本文还通过对比提取单幅图像特征的平均用时来衡量算法的实时性。在CityCentre数据集上,选取右侧相机拍摄的共1 237张图像进行特征提取,表2对提取全部图像特征的总时间以及提取单幅图像特征的平均时间进行了统计。
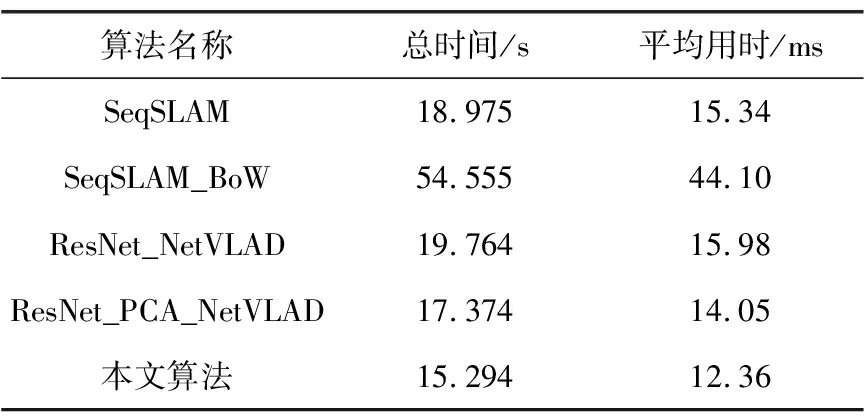
表2 特征提取总时间以及平均时间对比表
以上结果表明,在保持高召回率以及高精确率的前提下,本文算法在进行特征提取时比其它算法更加快速高效。需要注意的是,传统手工特征如词袋模型等需要事先离线构造视觉词典,而基于深度学习的算法也需要事先基于大规模数据集进行训练。本实验中默认离线准备工作均已结束,算法耗时仅考虑在线特征提取阶段。
3 结论
本文提出了一种基于改进NetVLAD图像特征提取的回环检测算法,采用基于深度学习的深度残差网络来提取图像特征,将空洞空间金字塔池化模块引入到NetVLAD中,通过多尺度特征融合,在降维的同时提高了特征图的分辨率,得到更加鲁棒且紧凑的图像特征描述,从而提升图像匹配的效果。在CityCentre和NewCollege两个公开数据集上验证了本文改进算法在精确率和召回率方面相比于标准NetVLAD算法有进一步的提升,同时比采用手工特征的算法更具实时性。
本文在进行相似图像序列匹配时采用的仍然是蛮力搜索方式,在大规模数据集上可能无法达到实时性要求。后续可以借鉴深度学习领域的最新研究成果,改进卷积网络结构,如加入深度可分卷积网络,进一步减少模型参数和复杂度,压缩特征提取时间。在图像对比方面,可以尝试更加高效的近似搜索方式,如KD-tree[13]、分层可通航小世界网络[14]等,进一步提升算法的实时性。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
中学生数理化·八年级物理人教版(2020年6期)2020-10-30
电子制作(2018年19期)2018-11-14
宝藏(2018年3期)2018-06-29
自动化学报(2017年4期)2017-06-15
自动化学报(2017年11期)2017-04-04
国防科技大学学报(2016年6期)2017-01-07
体育世界(学术版)(2015年3期)2015-07-01
电测与仪表(2015年3期)2015-04-09
噪声与振动控制(2015年4期)2015-01-01
