
基于BERT的广西非遗知识图谱构建
2024-01-03 08:42李宏杰
现代计算机 2023年21期
李宏杰,黄 薇,王 奔
(1. 广西民族大学人工智能学院,南宁 530006;2. 广西民族大学电子信息学院,南宁 530006)
0 引言
知识图谱从被提出至今,已经被各行各业广泛关注和使用[1]。知识图谱模仿人类推理和解决问题的方式,通过图表示节点、边表示节点间的关系来表示知识,从知识图谱所存储的知识中获得解决更复杂问题的能力[2-3]。作为一种结构化的知识形式[4],知识图谱是一种语义图,用于表示知识,在各界都得到了广泛应用。知识图谱所表示的语义结构化信息特性为许多任务提供了潜在的解决方案,包括问答、推荐和信息检索,并且许多研究人员认为有更大的发展前景。自“大数据”一词出现以来,知识图已经在各个场景和领域得到运用[5]。知识图谱的应用和构建是两个重要的研究方向。构造技术的研究侧重于图中知识的提取、表示、融合和推理[6],例如从非结构化文本中提取实体和关系后,将它们正确地连接到知识图谱,并从这些知识图谱中推理新的事实。而应用研究则侧重于将知识图谱应用于实际系统和特定领域。知识图谱作为语义网的数据支撑,近年来成为了研究与应用的热点问题。知识图谱将实体表示为节点,实体与实体间的关系表示为节点间的边,从而形成了一个巨大的知识网络[7]。
广西壮族自治区拥有秀美的自然风光资源,丰富的风土人情文化,孕育出灿烂的的非物质文化遗产项目文化和优秀的非物质文化遗产传承人。广西拥有着丰富的非物质文化遗产资源,是广西乃至全国的文化瑰宝,但在传播与宣传上存在着明显的不足,传播形式不够多元[8],保护措施不够完善等。
目前,虽然已有结构化的广西非物质文化遗产数据,但是仍存在着大量的非结构化数据未被利用与挖掘。从非结构化数据中抽取信息是广西非物质文化遗产知识构建的一个巨大挑战。无论是使用基于规则或基于语法等传统的自然语言的方法都无法准确地从非结构化数据中抽取知识,因此,本文基于BERT模型对非结构化数据进行实体与关系抽取,从而从非机构化数据中准确抽取知识[9-10]。
1 构建广西非遗知识图谱
1.1 分词
中文文本处理的一大难点在于分词处理,但在特定领域下的中文分词,无论是精准模式、全模式、搜索引擎模式下的jieba 分词模式,非遗数据的分词效果都不理想,见表1。

表1 jieba分词效果
由于非遗名称以及非遗数据中的一些词汇并非通用词汇,在jieba 原始词典中并没有关于非遗领域的词,导致了使用jieba 分词后有些实体并没有被精准地切分出来。分词的效果会直接影响实体的提取以及最终知识图谱的构建效果。因此简单的分词方法已不适用于非遗数据文本处理。
1.2 词性标注
词性标注的方法分为基于规则的词性标注方法和基于统计的词性标注方法,基于统计的词性标注方法主要有隐马尔科夫模型(HMM)[11]。该模型可以由隐藏状态序列生成观测序列。利用该模型进行词性标注,见表2[12]。

表2 jieba词性标注
1.3 基于BERT的命名实体识别
由于分词和词性标注方法都无法把实体抽取出来,因此,本文使用基于BERT模型的命名实体识别方法对文本中的实体进行抽取。首先,需要把每一个词转换成词向量,这样做是为了把每一个单词转换成可用于计算机计算的向量。独热编码、Word2Vec 和Glove 都是传统的词向量模型,但这些词向量模型仅仅只是把低维的向量影射到更高维的向量空间中,并没有很好地表现词与词之间的关联。本文使用BERT模型作为词向量的生成模型,BERT 模型参考上下文信息,相对于其它模型而言可以解决一词多义的问题。
BiLSTM 模型被广泛应用于自然语言处理任务中,它的出现代表着LSTM 有更大的改进,更好地解决了卷积神经网络中梯度消失或梯度爆炸的问题。BiLSTM 层由双向的LSTM 层组成,即前向和后向的LSTM 层,因此该模型能够更加精确地获取上下文信息。基本的LSTM 单元由遗忘门、输出门、输入门和记忆单元组成,之间的横向箭头被称为单元状态,它就像一个传送带,可以控制信息传递给下一时刻,它保存了每个神经元的状态。通过门控机制控制信息传递的路径。
BERT-BiLSTM-CRF 模型由词嵌入层、双向注意力机制网络层和条件随机场层组成。本文采用BIO 标注形式对非遗数据进行数据标注,B表示实体词的开始字符,I 表示实体词的其余字符,O 表示与实体无关的字符。先使用BERT 模型预训练文本字向量,然后通过双向LSTM 层学习上下文特征,输出层通过softmax 预测各个标签的概率,最后通过CRF 模型得到序列标签,至此就完成命名实体识别任务。命名实体识别预测结果见表3。

表3 命名实体识别预测结果
1.4 关系抽取
关系抽取是抽取两个实体之间的支配关系,它是关系词(如:是、位于、所属等级等)与其否定词的集合,否定词也是两实体之间的一种支配关系。在命名实体识别任务中,识别出句子中广西非遗项目名和其它实体名,并按照先后顺序进行排序。从构建好的关系词表中抽出关系R 与词库中的关系词进行对比,若关系词未在词库中,则使用词库中最相似的词作为该词的替换。此时便完成实体间关系的抽取。
至此就完成了广西非遗知识图谱构建,知识图谱构建步骤如图1所示。

图1 知识图谱构建步骤
2 广西非遗知识图谱展示
图2为广西非遗知识图谱总图,我们成功从文本信息中抽取了实体间地域、时间、类别、级别等关系信息,并将数据存储于Neo4j图数据库中。图3为广西非遗知识图谱中部份数据的类别关系。图4为广西非遗知识图谱位置关系图。
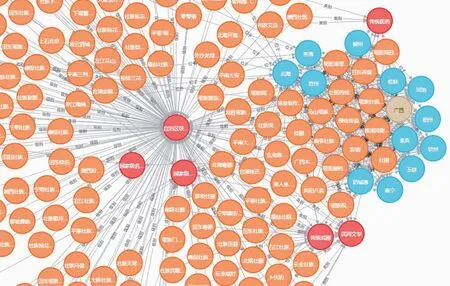
图2 广西非遗知识图谱总图

图3 广西非遗知识图谱类别关系
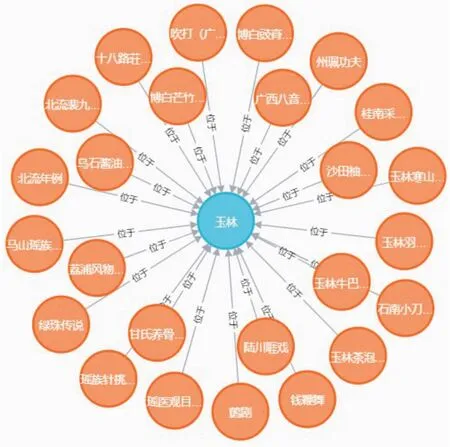
图4 广西非遗知识图位置关系图
3 结语
知识图谱作为一种人工智能的重要部份,越来越被广泛地运用到各行各业中。由于广西非物质文化遗产数据领域特殊,词汇和表达与日常用词存在比较大的差异,在该领域的应用研究尚有不足,非遗数据间的时空关联性不强。广西非遗知识图谱的构建为广西非遗资源保护和传承提供了新的方向。本文对知识构建和知识存储进行了分析,但对广西非遗知识图谱构建与应用研究还比较浅显,有待进一步完善。如何把知识图谱可视化呈现出来,从知识图谱中挖掘更多的信息,灵活应用知识图谱将是以后研究的重点。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19
校园英语·月末(2021年13期)2021-03-15
少先队活动(2020年12期)2021-01-14
计算机教育(2020年5期)2020-07-24
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
计算机工程(2015年8期)2015-07-03
华东理工大学学报(自然科学版)(2014年5期)2014-02-27
