
基于深度学习的纱管识别方法研究
2024-01-04 04:59吕绪山姜越夫梁高翔赵恬恬薛博文
机械与电子 2023年12期
王 青,吕绪山,党 帅,姜越夫,梁高翔,赵恬恬,薛博文
(西安工程大学机电工程学院,陕西 西安 710048)
0 引言
在纺织工业中,络筒机是一种非常重要的设备,用于生产各种类型的纱线。纱管作为络筒机上的一个重要部件,用于收集纱线并进行包装。在纱管被填满后,需要及时更换纱管,否则会影响生产效率。传统纱管更换通常是手动完成,需要工人不断观察纱管的状态并及时更换。这种方式不仅耗费人力和时间,而且容易出现误操作和质量问题。
为了提高生产效率和减少工作负担,利用计算机视觉技术来抓取纱管已成为一种越来越受欢迎的解决方案。Wang等[1]利用图像通道灰度直方图的分割方法实现纱管的识别;Yang等[2]提出了一种纱管纱线自动检测系统,利用梯度提取、阈值处理和最大连通域分析的方法对纱管进行识别;高畅[3]利用奇部Gabor滤波器强化纱管纹理,随后使用多类支持向量机,再结合跟踪算法以实现运动状态下的纱管识别;Zhang等[4]利用相机捕获纱管形状并在HSV系统预处理图像,再利用支持向量机进行纱管识别;Jing等[5]通过抑制图像纹理并增强图像缺陷部位与背景的对比度,实现对纱管表面缺陷的检测;马传旭等[6]针对包含纱管信息的纱管顶部图像,将圆环形的纱管图像利用极坐标变换展开成矩形图像,在利用HSV颜色直方图和局部二值模式提取纱管的特征后,使用支持向量机对纱管进行分类;张宁等[7]利用Canny算子得到送纱管边缘特征后结合RANSAC和最小二乘法对送纱管的同轴度进行检测,有效提高了送纱管的同轴度测量精度。以上方法都是传统的目标识别算法,这类算法虽然能提取出纱管的形状或者颜色信息,但很难满足实时检测的需求,识别速度较慢,准确率较低。
相比于对目标形状和大小有较高要求的模板匹配方法,基于卷积神经网络的目标识别算法具有效率高、速度快和鲁棒性高等优点[8],近些年发展迅速。这些算法大体可以分为2类,一类是如RCNN(Region CNN)[9]、Fast R-CNN(fast region-based CNN)[10]和Faster R-CNN(faster region-based CNN)[11]等的二阶目标识别算法,这类算法是基于候选区域的深度卷积网络,即首先生成可能存在检测目标的候选框,然后对候选框进行分类和校正生成检测框,从而实现对目标的检测。另一类是基于回归计算的一阶目标识别算法,如SSD(single shot multibox detector)[12]、YOLO(you only look once)系列等是利用端到端训练的方式进行目标检测。这2类算法具有各自的优点,二阶目标检测算法具有更深的网络结构,从而可以实现更高的检测精度;一阶目标识别算法由于没有生成候选框的步骤,因而具有更高的检测速度。
在这些算法的基础上,学者们进行了大量算法网络框架的改进研究,Zhao等[13]用表征能力更强的ResNet50代替Faster R-CNN中的VGG16,并结合DarkNet53来提高纱管的检测精度,同时在缺陷检测中也有良好的表现;Wei等[14]为解决检测小目标的困难,通过分析注意力机制和视觉增益之间的关系,并将相关机制融入到Faster R-CNN中有效提高了纺织品缺陷的检测精度;Hu等[15]为获取纱管上的残纱,将霍夫变换无法消除纱管轮廓的图像转换为HSV空间,并将HSV值作为BP神经网络的输入值,得到纱管残纱情况的输出结果;徐建等[16]将AlexNet输入卷积层中卷积核的大小替换为3×3,并串联多个卷积核,提高网络提取纱管特征的能力,利用滑动平均和L2正则化来提高网络的泛化能力,结果表明该方法具有良好的识别准确率;张星星[17]为检测管纱的表面缺陷,首先使用模板匹配的方法找到管纱表面缺陷区域,随后使用ResNet50对缺陷进行分类,结果表明该方法对管纱缺陷的分类具有较高的准确率。
综上所述,传统目标检测方法存在速度和精度不高的缺点,难以适应在线实时监测需求,基于深度学习的目标检测方法有着良好的检测速度和精度,但针对纱管目标检测的具体应用研究较少,并且针对于纱管的数据集也相对较少。因此,本文基于深度学习提出一种针对纱管检测的实时在线检测方法,并收集不同类型的纱管制作数据集。
1 纱管识别方法
1.1 YOLOv5网络框架
YOLOv5延续了YOLO系列的思想,将准确率与速度相结合受到了业界的青睐[18]。YOLOv5有4个子版本,YOLOv5s、YOLOv5l、YOLOv5m和YOLOv5x,它们之间区别在于权重大小的不同。YOLOv5s是YOLOv5系列中权重最小、检测速度最快的一个版本,更具体的网络模型可以拆分为3部分结构,即Backbone、Neck和Prediction,具体如图1所示。
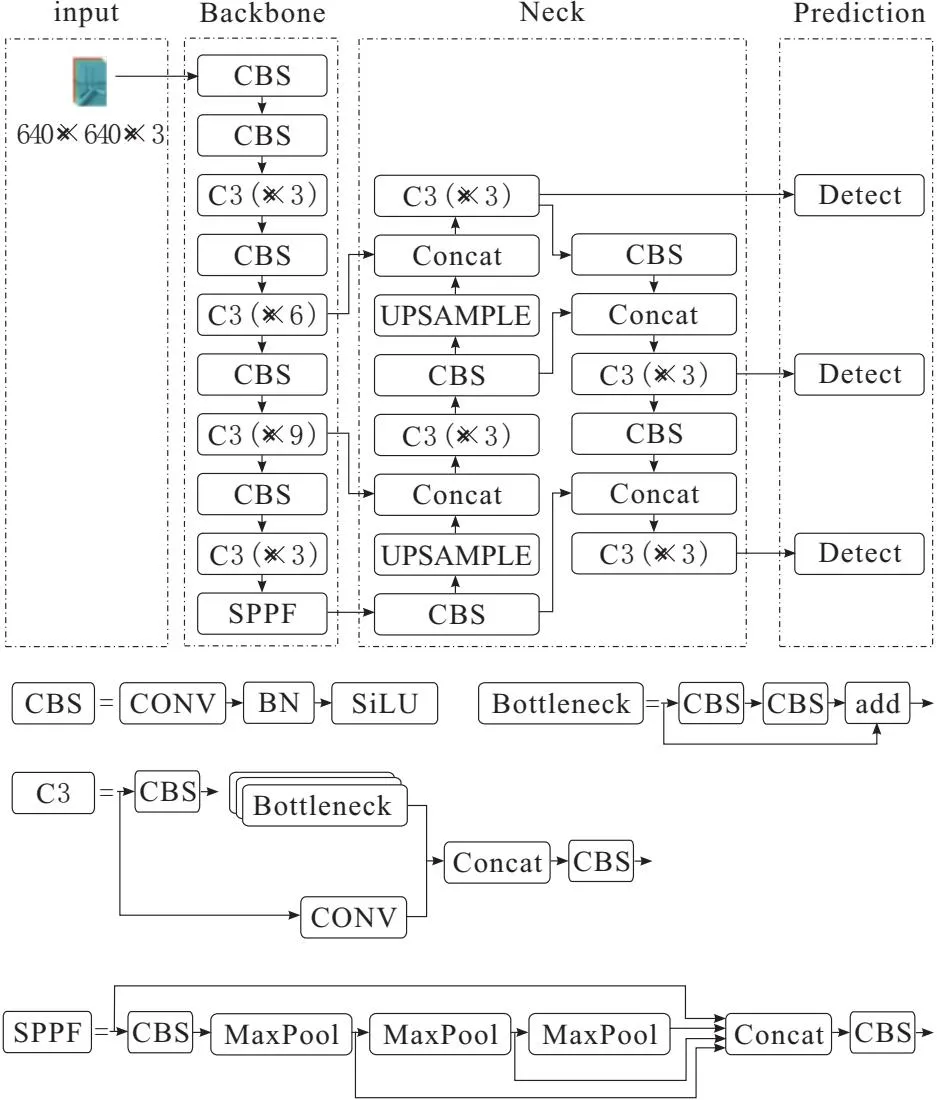
图1 YOLOv5网络框架
输入的图片首先通过1个Conv层,这个Conv层和YOLO之前版本所使用的Focus层作用相同,都是将输入大小为640×640×3的图片切片成大小为320×320×12的图片。Backbone主要组成部分为C3层,它由3个残差模块组成,用以提取特征。在Backbone结尾是1个SPPF层[19],它是由1个CBS层和3个最大池化层(5×5,9×9,13×13)组成的残差模块,提供不同的感受野,以提高特征的表达能力。
Neck部分由特征金字塔网络(FPNet)[20]和路径融合网络(PANet)[21]组成。FPNet用来增强语义特征,它利用上采样将高层特征图和底层特征图相融合。PANet用来增强空间特征,它结合FPNet将定位信息由浅层传输到深层。
Prediction结构有3个不同检测层,每个检测层有3个不同大小的anchor,分别为[[10,13]、[16,30]、[33,23]],[[30,31]、[62,45]、[59,119]],[[116,90]、[156,198]、[373,326]],大的anchor用来检测小特征,较小的anchor用来检测大特征。
1.2 注意力机制
在网络模型中加入注意力机制有突显重要特征和抑制不明显特征的作用,可以明显提升网络模型的检测性能。坐标注意力机制(coordinate attention,CA)具有计算效率高和计算开销小的优点。如图2所示,CA将通道注意拆分为2个一维特征编码,再沿2个空间方向进行聚合,从而判断像素中行和列是否存在感兴趣区域,在实现捕捉远程依赖关系的同时保留精确的位置关系。
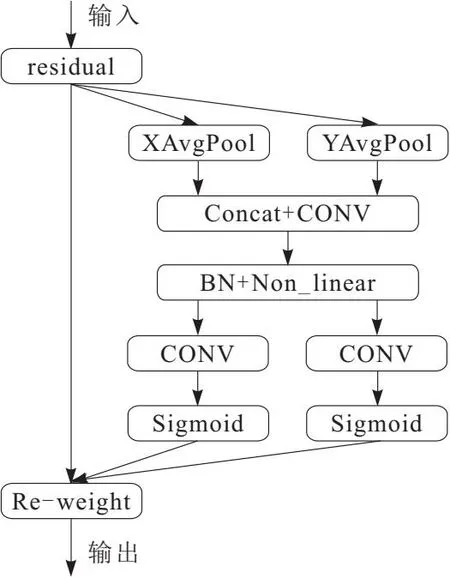
图2 CA结构框架
CA由坐标信息嵌入和坐标注意生成2部分组成[22],坐标信息嵌入是对于输入X,使用2个空间池化内核分别在垂直和水平坐标进行编码,在高度为h处的第c个通道的输出可以表示为
(1)
同样地,在宽度为w处的第c个通道的输出可以表示为
(2)
编码结果沿2个空间方向聚合特征产生2个方向感知特征图,使网络更精确地找到感兴趣的对象。坐标注意生成是依据3点来设计:第一点是能够捕捉到通道间关系;第二点是能够充分利用捕捉到的信息,并突显感兴趣的区域;第三点是满足轻量级要求。
1.3 损失函数
YOLOv5网络组合使用了3种损失函数,分别为分类损失函数、定位损失函数和置信度损失函数。分类损失函数和置信度损失函数使用的是Logits和二进制交叉熵损失函数,对于定位损失函数使用的是CIoU[23]。CIoU的计算方法如式(3)~式(5)所示,能够计算真实检测框和预测检测框之间的交并比,同时考虑了检测框的覆盖面积、长宽比和中心点的距离。
(3)
(4)
(5)
LC为CIoU总损失函数;b、bgt分别为目标框与预测框的中心点;ρ为中心点之间的欧几里得距离;w、wgt为目标框与预测框的宽;c为目标框与检测框最小外包矩形的对角线长度;α为权重函数;v为长宽比一致性参数;h为检测框的高;VIoU为检测框阈值。
如式(6)~式(8)所示,SIoU损失函数与CIoU损失函数的不同在于,SIoU考虑了Box真实检测框和预测检测框之间方向的比配性,很大程度上提高了网络的收敛速度。具体SIoU是从角度成本、距离成本和形状成本3方面进行计算的。
(6)
(7)
(8)
(9)
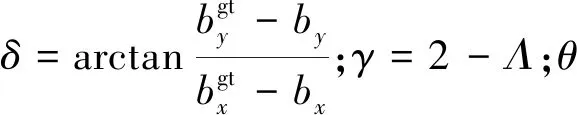
由于SIoU损失函数不仅考虑了真实检测框与预测检测框的覆盖面积、长宽比和中心点的距离,而且考虑了检测框回归所需的向量角度,所以使用SIoU损失函数有利于提升网络模型的训练速度与检测精度。
1.4 激活函数
激活函数可以对通道引入非线性因素,使网络具有更好的表达能力和非线性分割能力。常见的激活函数有Sigmoid、Tanh、Leaky ReLU、Softplus、Hardswish、Mish和SiLU。图3为不同激活函数的函数图像。
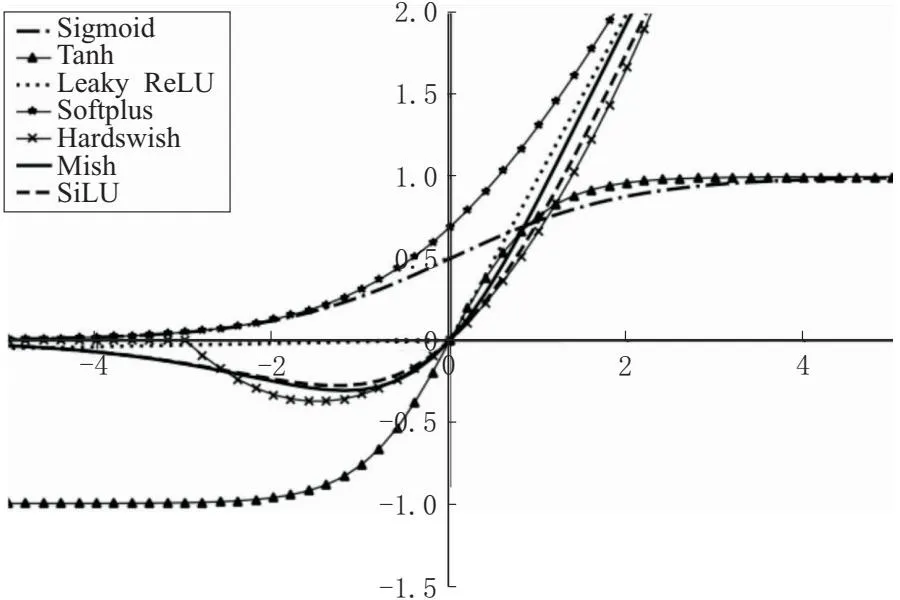
图3 不同激活函数的函数图像
为明确不同激活函数的性能,在coco128数据集上对比不同的激活函数,设置训练迭代次数为50,初始学习率为0.01,迭代批量大小为16。结果如表1所示,在50次的迭代过程中平均精确率达到83.33%,平均召回率达到77.32%,平均mAP_0.5达到84.50%,相比于其他激活函数, Mish激活函数对于提升网络识别的准确率、召回率和mAP_0.5具有很大帮助。所以本文将YOLOv5原有的SiLU激活函数替换为Mish激活函数 ,相对于SiLU激活函数,Mish激活函数具有更好的泛化能力,并有助于提高网络的稳定性。Mish激活函数是由Diganta等提出的一种平滑非单调的函数,表达式为
Mish=x×tan(loge(1+exp(x)))
(10)

表1 在COCO128数据集上不同激活函数性能对比 %
1.5 改进后的网络
综上所述,本文在原有的YOLOv5网络结构基础上对激活函数,损失函数和注意力机制进行改进,具体为:将损失函数替换可以使网络更快速收敛的SIoU,将激活函数改为更稳定的Mish,并在网络主干中填入CA注意力机制。改进后的网络框架如图4所示。
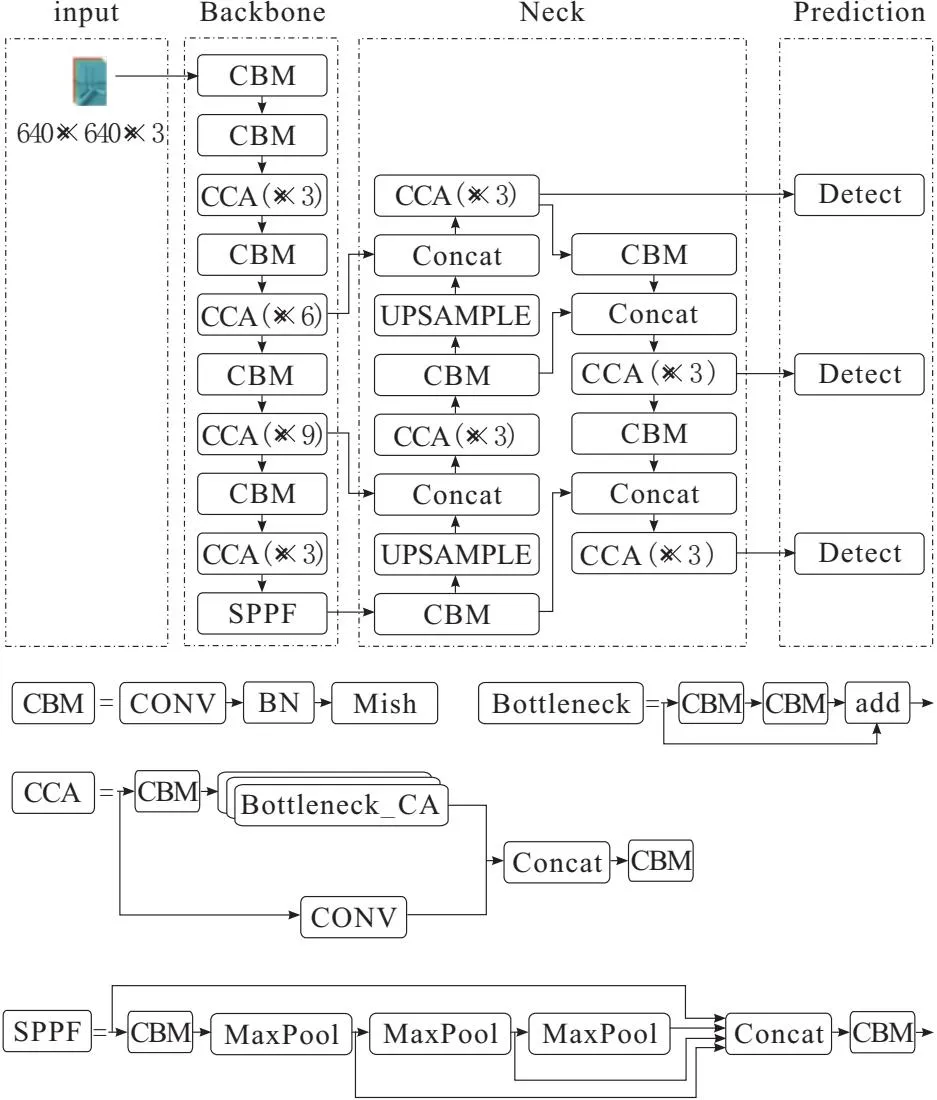
图4 改进后的YOLOv5框架
其中,CBM表示CONV层、BN层和Mish激活函数,CCA表示嵌入了CA注意力机制的C3层。与原网络对比,改进后的网络结构拥有不同的网络模块,且在训练速度和检测精度上都将有显著的提升。
2 分析与讨论
利用RTX3060在Windows11操作系统上使用Pytorch深度学习框架进行实验。在训练YOLO网络时,利用在COCO数据集上训练好的预训练模型进行迁移学习以缩短训练时间,设置训练迭代批量大小为8,迭代次数为100,初始学习率为0.01。通过添加对比试验,用以突显改进后网络模型的识别效果与其他网络模型识别效果的差异。
2.1 数据集
本实验利用VOC2007公共数据集和自制纱管数据集对改进的网络性能进行检验。使用VOC数据集来对比改进后的网络与原YOLOv5网络的性能,用自制的纱管数据集来对比本文改进后的网络与其他目标检测网络的性能。不同于VOC2007数据集的多类物品特性,纱管数据集是针对于纱管类中不同型号的纱管来进行制作的,因此纱管数据集更具实用价值。制作数据集所用的纱管图片由本实验团队拍摄,针对经纱管、纬纱管、粗纱管、宝塔型纱管、宝塔型网眼纱管、并行管、小型塔状纱管和加弹纱管8种不同类型的纱管进行图像采集,利用Roboflow对所收集的照片进行实例标注。随后通过剪切、加入噪声和模糊等方式对数据集进行数据增强,得到总数为4 385张图片的数据集。按照VOC2007数据集的格式保存数据。随后对数据集按照训练集90%、测试集10%的比例划分,得到训练集3 965张图片,测试集420张图片。
2.2 模型评判指标
如式(11)~式(13)所示,本文使用精度(Precision)、召回率(Recall)、平均精度(mean average precision,mAP)对改进后的YOLO网络进行性能评估。
(11)
(12)
(13)
真阳性TP为分类正确的正样本;假阳性FP为分类错误的负样本;假阴性FN为分类错误的负样本;Q为分类的类别数量;K为感兴趣区域(intersection over union,IOU)阈值;N为IOU阈值的个数;VmAP为计算的mAP结果。
2.3 网络性能验证
对改进后网络的性能,从2方面对其进行验证。一方面利用公开数据集对改进前后网络的性能进行检验,另一方面将改进后的网络跟其他网络模型,如Faster R-CNN 、SSD和YOLOv4等在自制数据集上进行对比。实验结果如表2所示,其中,本文模型表示为在原YOLOv5网络的基础上加入CA注意力机制、Mish激活函数和SIoU损失函数后的模型。表2中“√”表示模型在对应的数据集上进行了训练,“-”则表示没有在对应的数据集上训练。
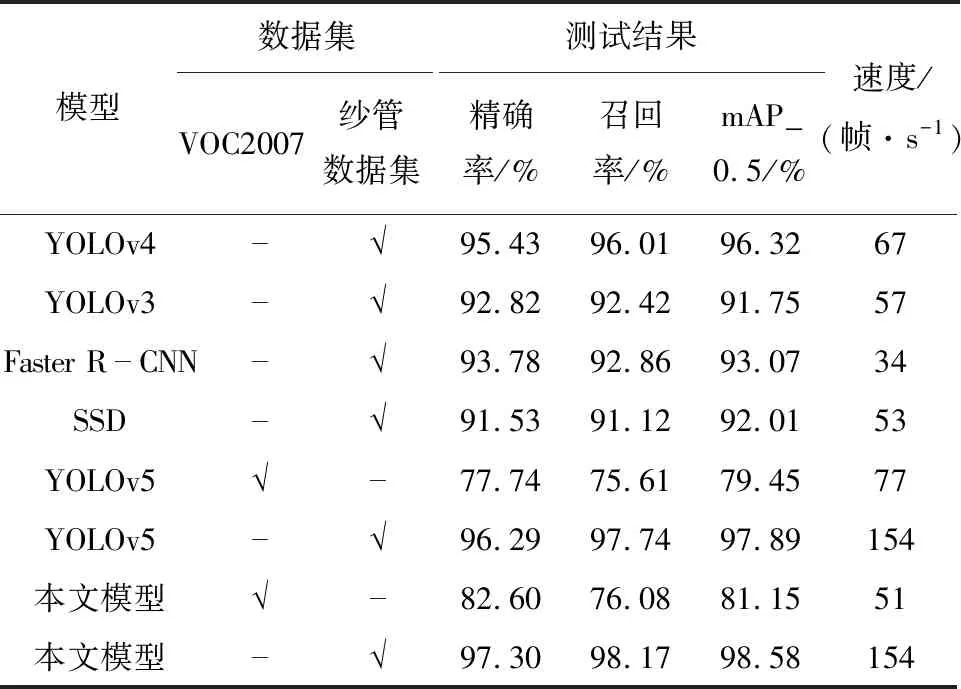
表2 采用不同网络模型的性能对比表
通过在公开数据集VOC2007和自制纱管数据集上对比不同网络模型的性能,可以发现本文改进后网络模型相对于其他网络模型具有更好的表现能力。在公开数据集上本文提出的模型,准确率达到了82.60%,召回率达到了76.08%,mAP_0.5达到了81.15%,相对于原YOLOv5网络分别提高了4.86%、0.47%和1.7%。在自制的纱管数据集上准确率达到了97.30%,召回率达到了98.17%,mAP_0.5达到了98.58%,对比于原网络模型分别提高了1.01%、0.43%和0.69%。在自制的数据集上,检测速度达到了154帧/s。
本文模型在自制纱管数据集上的epochs-value曲线如图5所示。Precision、Recall和mAP_0.5曲线所包围的面积越大则表明模型的表现力越好,box_loss、obj_loss和cls_loss曲线所包围的面积越小则表明模型的表现力越好。从图5中可以看出本文模型的表现力很好。
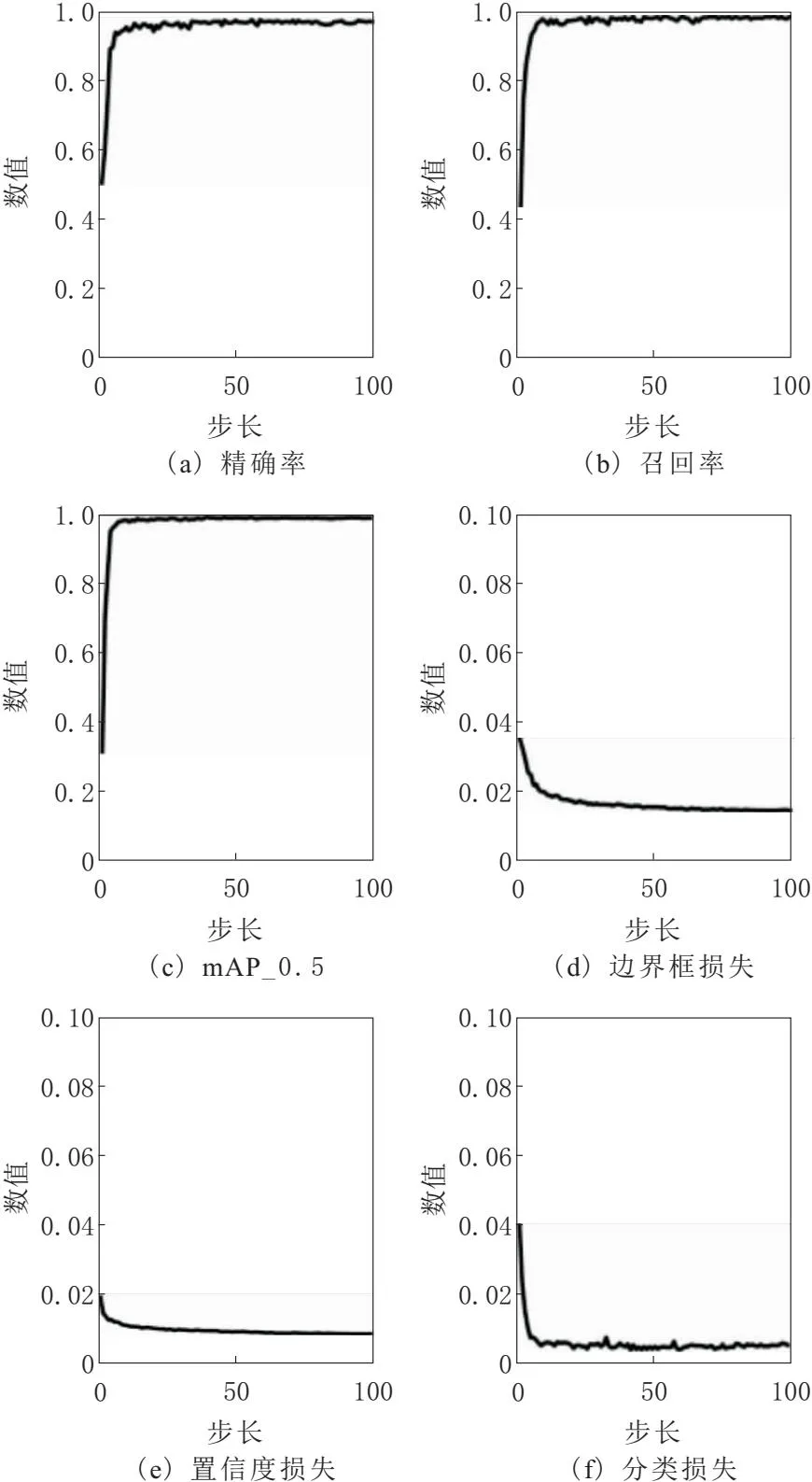
图5 模型步长-值曲线
图6为混淆矩阵,矩阵内每行表示预测的模型类别,每列表示真实类别,每个数值表示模型预测该类别的概率,对角线上的值表示模型预测类别正确的概率。从混淆矩阵可以得出模型预测每个类别的能力都很好,个别类别的识别概率甚至达到了100%。
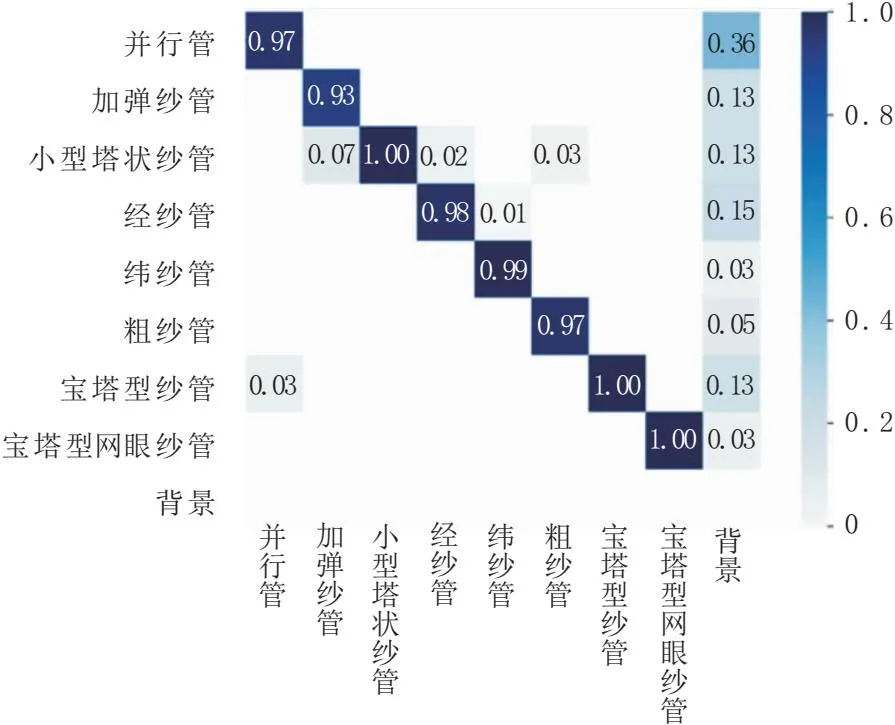
图6 模型在自制纱管数据集上验证的混淆矩阵
表3为在自制数据集上进行的消融实验结果,在网络模型中分别加入Mish激活函数、SIoU损失函数和CA注意力机制时,对纱管的检测效果提升并不大。相比之下,在网络模型中同时加入任意2种模块时,对纱管的检测效果有显著提升。将3种模块同时加入到网络模型中后,网络模型在纱管识别的准确率、召回率和mAP_0.5上的表现力达到最好。
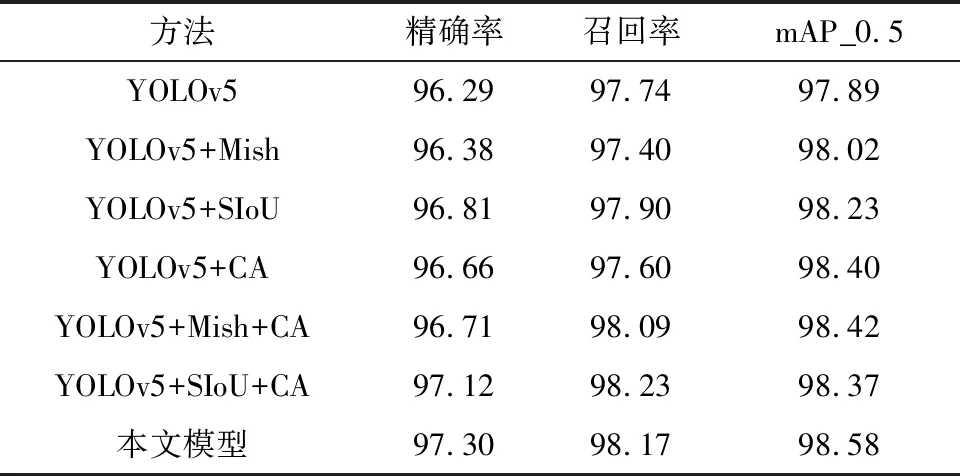
表3 在自制数据集上不同模块对网络模型检测的影响 %
本文改进后的网络模型在自制纱管数据集上的部分识别效果如图7所示。可以看出本文模型在分类和识别准确率上都具有良好的表现。

图7 本文所提网络模型在纱管数据集上的检测效果
3 结束语
本文在原YOLOv5的基础上结合纱管特点对网络模型进行改进,利用消融实验的方式在网络模型结构中加入CA注意力机制,将原来的SiLU激活函数更改为Mish激活函数,将原来的CIoU定位损失函数更改为SIoU损失函数。相比于原YOLOv5网络模型,在自制纱管数据集上的检测效果具有了显著提升,具体为:准确率提高了1.01%,召回率提高了2.16%,mAP_0.5提高了0.69%,且相比于其他网络模型,该改进的网络模型在检测速度和准确率上也有更优的表现。
由于纱管数据集中纱管的类型数量不足,导致该算法能识别的纱管类型很少,所以本文改进的算法仍不能完全适应真实场景中的纱管识别。在后续的工作中将继续扩充纱管的类型,并结合三维位姿估计以实现真实场景中纱管的识别与抓,从而满足真正的生产需求。
猜你喜欢
塑料包装(2022年2期)2022-05-18
纺织器材(2021年2期)2021-12-04
数学小灵通·3-4年级(2021年5期)2021-07-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
今日农业(2019年15期)2019-01-03
天津工业大学学报(2018年5期)2018-11-10
数学物理学报(2017年5期)2017-11-23
科技资讯(2016年12期)2016-05-30
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
