
基于改进的YOLOv5安全帽佩戴检测算法
2024-01-04 23:58雷建云李志兵夏梦田望
湖北大学学报(自然科学版) 2024年1期
雷建云,李志兵,夏梦,田望
(1.中南民族大学计算机科学学院, 湖北 武汉 430074; 2.湖北省制造企业智能管理工程技术研究中心,湖北 武汉 430074; 3.农业区块链与智能管理湖北省工程研究中心, 湖北 武汉 430074)
0 引言
建筑行业的事故率远远高于其他行业的事故率[1],且在建筑行业中发生在头部损伤的致残率最高[2],在施工作业的过程中佩戴安全帽能够有效降低事故给人带来的损伤[3],因此加强对安全帽佩戴的管理可以更好地保证施工人员的安全。目前,安全帽佩戴监管的主要方式采用的人工监控和视频监控相结合的方式,但是这种方式需要浪费大量的人力物力和时间,而且检测不可能面面俱到,易造成漏检[4-5]。
随着计算机视觉的发展,提出了诸如RCNN系列[6]、SSD系列[7]和YOLO系列[8]等优秀的目标检测算法[9]。RCNN系列算法是主流的双阶检测算法,其第一阶主要是利用Region Proposal生成候选区域,并从中提取特征向量[10];第二阶利用卷积神经网络预测目标的类别和位置,以此实现对目标的准确检测和定位。SSD系列和YOLO系列方法是当今最流行的单阶段检测技术,它们无需产生候选区域,而是将图片从输入端输入,然后在输出端输出目标的位置和类别,这种端到端的技术极大提高了算法的检测性能[11]。近年来,许多学者试图将计算机视觉技术应用于判断安全帽佩戴检测情况[12]。2018年,Fang等[13]首次将Faster RCNN算法应用于安全帽佩戴检测,尽管测试准确度有所提升,但仍不能达到实时性需求。2019年,张明媛等[14]给出了一种基于Tensorflow框架的Faster RCNN算法,用于监测施工人员安全帽的佩戴检测,平均识别率达到90.91%。2020年梁思成等[15],2021年张占康等[16]、石永恒等[17]都分别尝试过基于YOLOv3进行安全帽佩戴检测,安全帽的准确度和速度都有所提升,但对于小目标安全帽存在漏检和对复杂场景检测效果差等问题。2022年,王雨生等[18]基于YOLOv4对安全帽所处区域与头部区域之间的位置关系进行检测,进而判断安全帽的佩戴情况,其在复杂姿态下的环境中达到检测精度较高、速度较快的效果,具有一定实际应用价值,但对目标物较小的情况下检测效果不佳。2021年Zhou等[19],2022年Kisaezehra等[20]使用YOLOv5模型对安全帽进行检测,达到准确度高、速度快的效果,满足实时性要求,因数据集施工场地真实场景样本少导致模型泛化能力差。另外有学者通过在经典的目标检测算法基础上进行改进,以达到提升算法模型检测性能。2020年,马小陆等[21]利用K-means重新聚类先验框、引入跳跃连接构造残差模块、优化损失函数等策略对YOLOv3进行改进,改进后的模型对小目标与遮挡安全帽目标的检测准确度都有所提升,鲁棒性较强,但残差模块的引入增加了网络复杂度,影响检测速度。2021年,金雨芳等[22]对YOLOv4增加一个浅层特征检测层,再对特征融合模块进行密集连接改进后进行安全帽检测,小目标安全帽检测性能提升明显,但对于遮挡和光线昏暗场景下安全帽检测效果不理想。2022年,Yang等[23]基于YOLOv4改进模型主干网络,并通过使用具有不同大小卷积核的MCM模块增强主干网络的多尺度特征提取能力,使用信道关注模块来引导模型动态关注提取的小目标和模糊目标的信道特征,再利用损失函数EIOU替换CIOU,以提高模型的收敛速度和回归精度。2023年,Chen等[24]提出采用轻量级网络PP LCNet改进YOLOv4的骨干网络,并将坐标注意机制模块嵌入骨干网络的三个输出特征层中以增强特征信息,最后以SIOU作为损失函数,改进后模型大小显著减少,检测速度提升较大。2022年,张锦等[25]对YOLOv5利用K-means++重新聚类先验框大小,再将多光谱通道注意力机制嵌入,使模型准确率与鲁棒性都得到提升,但对于复杂环境中安全帽佩戴检测精度还需进一步提升。2023年,HAN等[26]为实现高分辨率的安全帽的高速检测,设计一种新的超分辨率重建模块,在模块中使用多通道注意力机制来提高特征捕获的广度,并提出新的CSP(cross stage partial)模块,减少信息丢失与梯度混淆。综上所述,国内外关于安全帽佩戴检测的研究仍存在一些问题需要不断完善。
1 YOLOv5简介
YOLO系列算法不断发展,已经产生了YOLOv1~v7多个算法,性能不断提升。其中YOLOv5目前应用最为广泛,具有准确率高、速度快、综合性强等众多优势。与YOLOv6、YOLOv7相比较,YOLOv5模型是最小的,耗费资源最少,训练与推理速度最快,仅检测精度稍稍逊色。但是YOLOv5算法在针对一些复杂场景的时候,还有一些误检和漏检的情况。结合安全帽佩戴检测现状综合分析,以YOLOv5作为原始模型进行改进。
YOLOv5有4种不同的网络结构,它们的原理基本相同,但网络的深度和宽度有所不同。本研究采用的是网络结构最为简洁的YOLOv5s,其可分为输入端、Backbone网络、Neck网络及输出端等4部分,如图1所示。
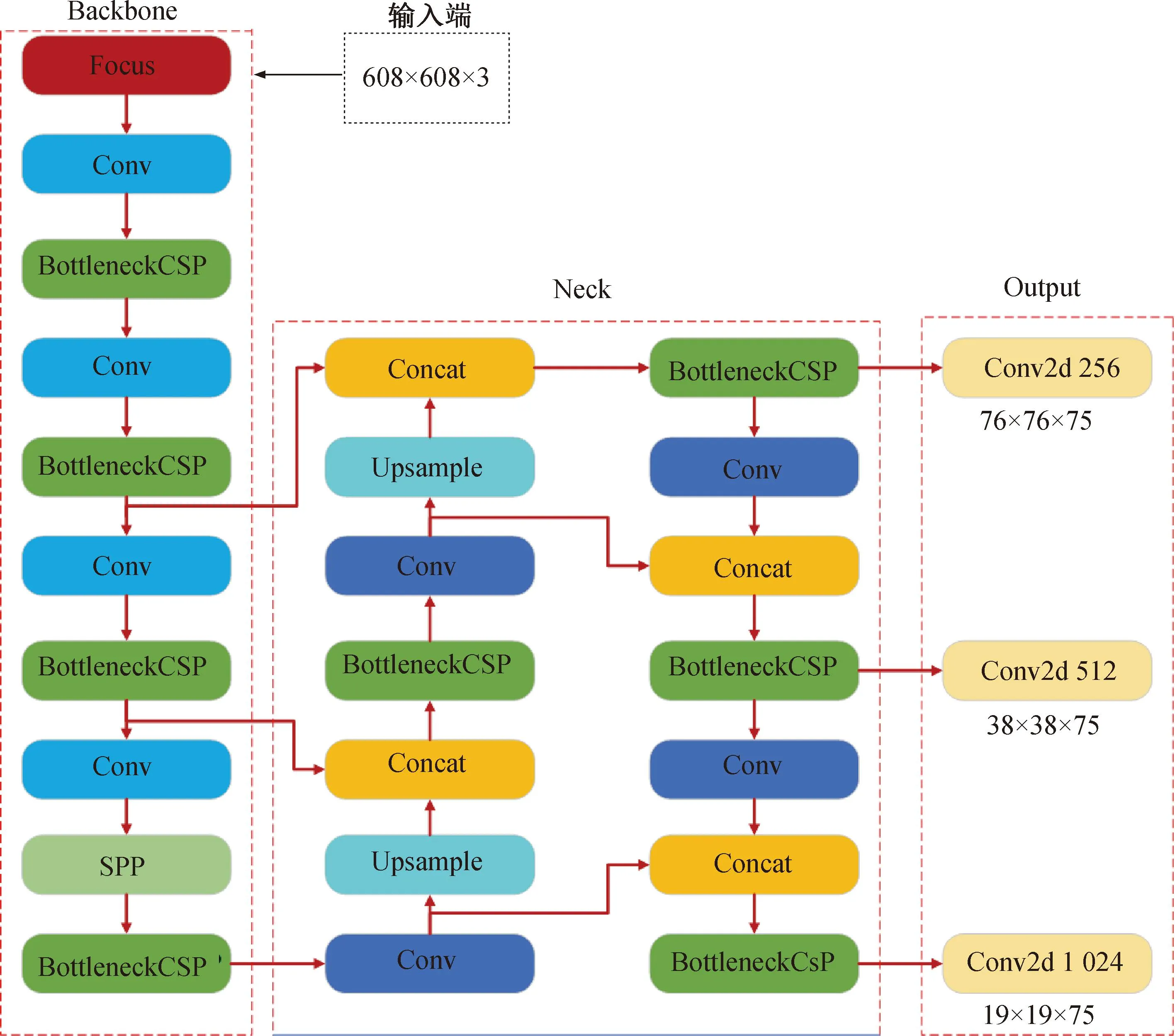
图1 YOLOv5模型图
YOLOv5的输入端输入图片后,Mosaic数据增强可随意缩放、裁剪及排列数据集合,这样不仅可以节省GPU内存,而且可以提高数据集的复杂性;此外,还可以使用自适应锚框运算来为各种类型的数据集设置初始锚框;最后,使用自适应图像缩放技术将图像缩放至某个统一的尺寸。
Backbone网络是YOLOv5的主干网络,它包含Focus结构和BottleneckCSP结构。Focus可以有效地将图像进行切片,例如一张608×608×3的三通道图片,通过Focus切割后,可以得到304×304×12的特征图。BottleneckCSP结构有两种,如图2所示,一种在Backbone网络中,另一种在Neck网络中,BottleneckCSP具有3×3的卷积核,步长为2。例如一张608×608的图片经过32倍的下采样,得到一个大小为19×19的特征图。使用BottleneckCSP提高了模型的学习能力,兼顾了网络的轻量化和准确性的需求。

图2 BottleneckCSP网络模型图
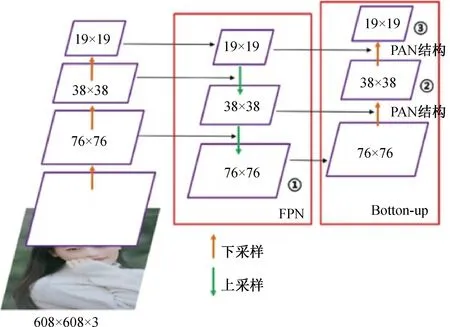
图3 FPN+PAN网络结构图
Neck网络是将Backbone主干网络提取的特征进行融合并将其传递到输出端部分,由FPN和 PAN组合而成。FPN将深层的特征通过自顶向下的上采样方式传输融合到浅层特征中,从而实现强语义特征的传输,而PAN则可以自底向上传递浅层特征的强定位信息。两者结合使用对网络特征融合能力的增强效果显著。
输出端又称为YOLOv5的预测端,包括边界框损失函数及NMS,它采用GIOU_Loss作为损失函数,可以解决Bounding box不重合的问题,有效提升预测框回归的速度以及精度。同时使用加权NMS增强对多个目标和遮挡目标的识别能力,找到最佳的物体检测位置。
2 基于YOLOv5的算法改进
2.1 多尺度加权特征融合结构改进随着深度学习技术特别是目标检测技术的迅猛发展,其检测精度和速度都在不断地提升,在一些公共数据集上取得良好效果,但针对图片中小目标的检测准确率还没能很好解决。小目标物体难以检测有两个原因,一是小目标在图片中占比过小,本身含有特征信息少;二是经过多次下采样,图像中的小目标特征信息消失殆尽[27]。
在一个多层神经网络模型中,浅层的特征信息能更好地表示图片中目标的纹理和位置等细节信息,而到了神经网络的深层,随着感受野的扩大,特征信息中包含更多的是图像的语义信息。YOLOv5利用Backbone主干网络提取特征,虽然具有很大的感受野,但经过多次卷积造成小目标的特征信息丢失严重[28]。
为更好地检测图像中的小目标,对YOLOv5的增加一个浅层检测层,即在YOLOv5模型原有的19×19,38×38,76×76三个检测尺度上新增一个152×152的检测尺度,用来提取图片的浅层信息,将新的特征层与YOLOv5原有的三个特征层融合成一个新的特征提取网络,利用浅层位置特征和深层语义特征进行多尺度目标检测。由于不同尺度的输入特征含有不同特征信息,对不同的尺寸输出做出的贡献不相等,为了解决这一问题,引入可学习的权重来表示各特征的重要性[29],加权特征融合公式见式(1)所示。
(1)
其中,wi表示权重,Ii表示特征信息。为保持训练的稳定性,利用Relu函数将所有的权重归一化为0到1的范围,即wi比smooth+∑jwj,smooth=0.000 1表示学习率。
经过改进的YOLOv5网络能够更有效地提取出丰富的位置、纹理等浅层信息,特征融合更充分,小目标的安全帽检测效果得到显著提升。图4所示为YOLOv5+多尺度加权特征融合的模型结构。
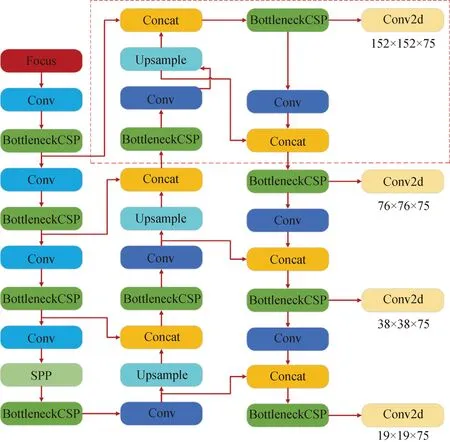
图4 YOLOv5+多尺度特征融合结构
2.2 添加注意力机制注意力机制可有助于卷积神经网络很好地捕捉图片中的目标信息,同时抑制背景信息。通道注意力可指引神经网络看向何物,卷积网络的不同层级都具有若干个卷积核,其与图像的特征通道相对应,每个特征通道具有不同的特征信息,因此与空间注意力相比较,通道注意力更关注对每个卷积通道之间的资源分配。YOLOv5模型的卷积层旨在提取每个特征图之间的相关性,对通道之间特征相关性基本忽略不计,为了在特征信息提取过程中保留更多的特征信息,在YOLOv5模型中添加SENet注意力模块。
对于具有C通道数的特征图而言,YOLOv5的卷积层只对位置特征信息进行提取而忽略了通道间的特征信息。这对于较大的安全帽目标而言,忽略通道特征信息带来的检测性能的下降没有那么明显,但由于小目标本身携带的特征信息较少,经历多次下采样后特征信息基本消失殆尽。为保留更多特征信息,可对通道间相关特征信息加强训练进而提升模型性能。SENet(squeeze-and-excitation networks)[30]是一种面向通道注意力的网络结构,即插即用,SENet模块一般插入到检测层后。因此,在YOLOv5网络的BottleneckCSP结构后面添加SENet 模块,网络就能获取更多的全局特征,再给予更大的权重来处理目标的通道特征信息,忽略无用信息,最终达到模型更多的关注目标的目的。SENet网络结构主要由Squeeze、Excitation和Scaling三部分组合而成,如图5所示。

图5 SENet结构示意图
首先,Squeeze是通过GAP(global average pooling)操作将复杂的H×W×C三维特征图压缩成1×1×C特征向量,这就相当于H×W的二维向量变成了一个实数,这个实数具有H×W的全局特征。其次Excitation操作,将1×1×C特征向量加入全连接层,它可以先预测所有通道的权重关系,再将这些权重关系应用到先前获取的特征上,以便实现后续操作。最后,利用Scale部分将Excitation得到的权重进行乘法加权,完成在通道维度上的对原始特征的重标定。提高目标通道间的权重,进而使模型更为关注小目标的特征信息,针对其进行有效训练,进而大大提升模型的检测性能。
SENet网络中的uC表示为最后一层的特征。形式上,在全局平均池化(即Squeeze操作)之后,通过空间维度H×W收缩uC生成zC,其中zC如式(2)所示:
(2)
SENet通过一种简单的门控机制,使用sigmoid激活函数来执行Excitation操作,具体方法如式(3)所示:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(3)
其中,δ表示ReLU激活函数,σ表示Sigmoid激活函数,W1和W2分别表示两个完全连接层,W1有维度递减的作用,将C维的特征进行压缩,充分捕捉通道之间的关系;W2还原维度。SENet网络的最终输出通过变换输出uC的缩放得到,式(4)如下:
(4)
但是针对YOLOv5模型中的Backbone与Neck的BottleneckCSP网络分别添加SENet模块得到的效果差异较大。在Backbone的BottleneckCSP网络中添加SENet对比于原YOLOv5模型提升了精确率,但是召回率下降较多,漏检比较严重;在Neck的BottleneckCSP网络中添加SENet,精确率获得提升,同时召回率也提升了,综合比较后选择在YOLOv5模型中Neck部分的BottleneckCSP中加入SENet模块。图6展示的是经过改进的网络结构。

图6 BottleneckCSP结构+注意力机制模型图
2.3 引入图像切割层小目标检测效果不好的主要原因是小目标尺寸过小,经过多次下采样之后特征信息丢失严重。例如,在YOLOv5的输入端输入608×608的图片,通过5次下采样,最终得到76×76、38×38、19×19三种grid。不同尺寸的grid对应检测不同大小的目标,76×76的grid可以检测到较小的目标、38×38的grid用于检测中等大小的目标、19×19的grid则可以检测到最大的目标,这样最小的grid的感受野是8×8。如果图像中一个小目标的宽或高有一个值小于8,卷积神经网络就不能准确有效地学习到小目标的特征信息。当图片的分辨率较高时,采用多倍下采样可能会导致小目标特征的丢失,但如果下采样倍数较小,神经网络在向前传播过程中会消耗大量的内存来保存特征信息,从而导致GPU资源的过度消耗,造成显存爆照。
参考YOLT算法[31],先将大分辨率的图片分割成若干张小图,再分别检测各张小图。为了避免在切割过程中恰巧将要检测的小目标切割断了,在相邻的两张小图间设置一个重叠区域(overlap)。例如,将一张1 216×1 216的图片切割为4张小图片时,原本应该是切割成4张宽高为608(1 216×50%)的图片,设置重叠区域后,切割的大小应为1 216×(50%+10%)。在图片分割完成后,将每个小图送入YOLOv5中进行检测,以确保检测结果的准确性。检测完成后,计算每个小图的坐标相对值,并将每个检测框放在大图上,进行NMS运算,以消除重叠区域的重复框。效果如图7所示。
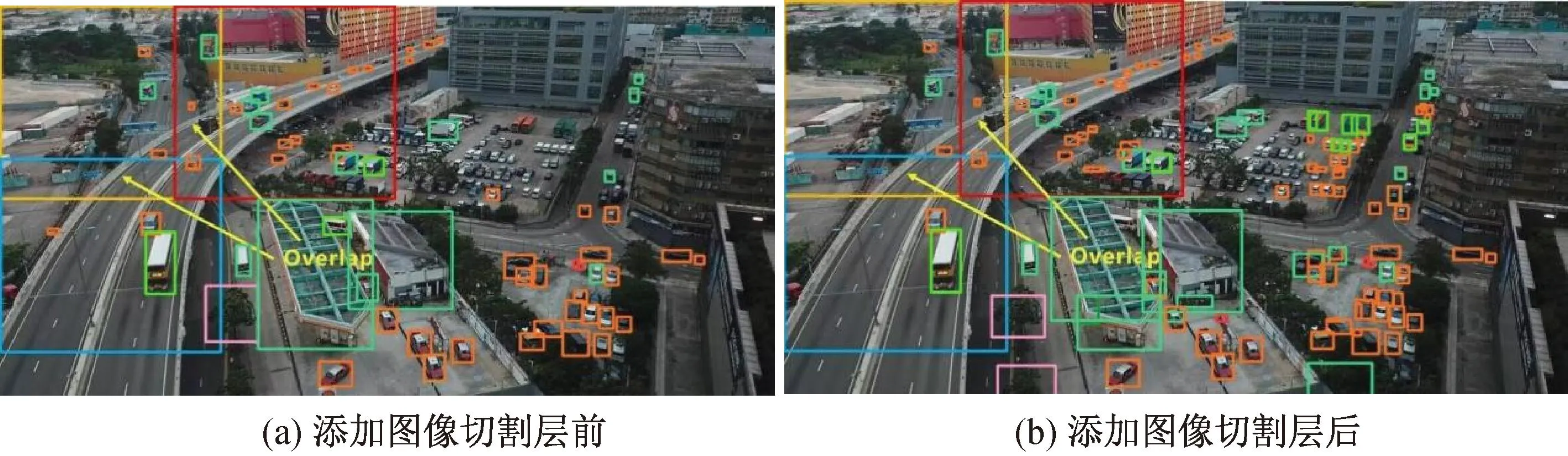
图7 添加图像切割层效果对比图
不过,增加图像分割层缺点有同样明显,如果使用大图直接进行检测,只需检测一次;进行图像切割后,需要检测多次,极大地增加了检测时间。
2.4 改进的YOLOv5算法对YOLOv5整体改进:第一步对YOLOv5模型的特征融合结构进行修改,添加新的浅层特征检测尺度,以此保留更多浅层特征信息,引入特征权重对各尺度的特征信息进行加权融合,提高小目标的检测精度;第二步在Neck模块中的BotteleneckCSP模块后面添加SENet注意力模块,使网络能够提取到更多的全局特征信息,提高目标的通道特征信息的联系,强化YOLOv5模型对安全帽目标特征的训练,最终达到模型更多关注小目标的目的。第三步针对图像的检测层进行修改,增加图像切割层,先将大分辨率的图片切割成若干张小图片,对每张小图片进行检测后回收所有图像计算坐标的相对值,集体来一次NMS(non-maximum suppression),降低了因下采样倍数过大导致的信息丢失。对YOLOv5模型进行整体改进后可得到一个新的模型M-YOLOv5,其结构如图8所示。
3 实验与数据分析
3.1 数据集概述安全帽的公共数据集SHWD图片中密集小目标和复杂环境中的小目标较少,为了增加数据集中目标场景的多样性。本次实验使用了一个融合的安全帽数据集,它由SHWD数据集、实地拍摄的工人作业照片以及网络爬取的图片组成,以更好地反映实际情况。本数据集总共有13 000多张图片,用Labeling图片标注软件进行标注,由两类目标组成:12 866个佩戴安全帽的bounding box 和109 854个未佩戴安全帽的bounding box。其中,训练集10 000张,测试集2 000张,验证集1 000张。包含的的场景有:密集小目标、自然光下小目标、光线昏暗下小目标、远距离小目标、背景干扰等。部分数据集展示如图9所示。
3.2 实验环境本次实验采用Pytorch学习框架搭建,操作平台是CentOS7。实验环境如表1所示。
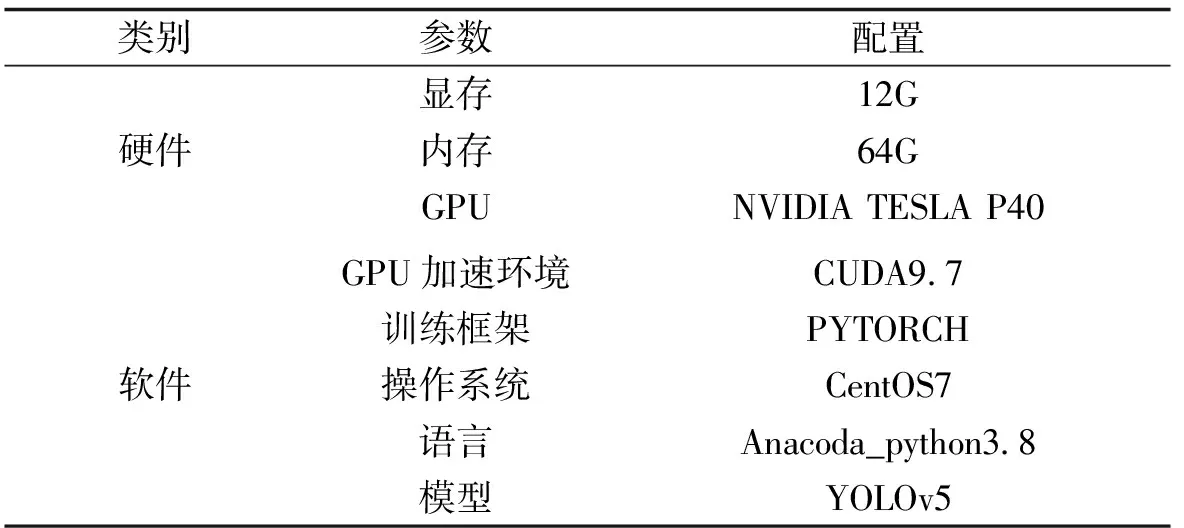
表1 实验环境
3.3 评估指标本文中对模型进行改进后需要进行一系列的实验,其中以平均精度均值(mAP)和召回率(Recall)作为衡量模型性能的评估指标。
Recall表示是正样本且被分为正样本数量占全部被被检测成正样本数量的比例,简写成R,如式(5)所示:
(5)
其中,TP(true positive)为被正确分类的正样本数量,FP(false positive)为被错误分类的正样本的数量,FN(false negative)为被错误分类的负样本数量。
P为精确度,表示的是正样本数量在所有检测到的样本数量中的比重,如式(6)所示:
(6)
AP为平均精度指的是以召回率为横轴,精确度为纵轴组成的曲线,而曲线所围成的面积就是AP,如式(7)所示:
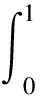
(7)
mAP表示的是各类AP的均值,如式(8)所示:
(8)
其中,N为物体类别的数量,i表示第i个类别,APi表示算法对第i个类别的物体的检测精度。
3.4 SENet嵌入位置对比实验表2为YOLOv5结构的不同位置添加SENet注意力机制后,在相同的安全帽数据集上进行对照实验的结果。针对YOLOv5模型中的Backbone与Neck的BottleneckCSP网络分别添加SENet模块得到的效果差异较大。在Backbone的BottleneckCSP网络中添加SENet对比于原YOLOv5模型提升了精确率,但是召回率下降较多,漏检比较严重;在Neck的BottleneckCSP网络中添加SENet,精确率获得提升,同时召回率也提升了;当在Backbone和Neck都同时添加SENet,精确率和召回率提升不多,计算速度下降严重,综合比较最后选择在YOLOv5模型中Neck部分的BottleneckCSP中加入SENet模块。实验结果如表2所示。

表2 对照实验结果
3.5 消融实验对YOLOv5的各个改进模块进行消融实验,测试各改进模块的效果。实验以YOLOv5为基准,添加多尺度加权特征融合(multiscale weighted feature fusion,MWFF),SENet注意力(Attention)、图像切割层(image cutting layer,ICL)等模块,“√”表示添加了某个模块的改进,具体如表3所示。原始的YOLOv5s模型的mAP、Recall分别是92.32%和88.23%。YOLOv5s模型单独添加或混合添加多尺度加权特征融合模块与SENet注意力模块,模型的mAP和Recall都有一定的提升;YOLOv5s添加图像切割层模块,改进的模型的mAP反而降低,但是Recall可以得到显著的提升。从表3可以看出,YOLOv5s+多尺度加权特征融合+SENet注意力的组合mAP达到97.18%,Recall达到89.98%;YOLOv5s+多尺度加权特征融合+SENet注意力+图像切割层组合的mAP为97.06%,Recall为92.54%。加入图像切割层,虽然mAP有略微下降,但是Recall得到明显提升,综合对比还是选择,YOLOv5s+多尺度+Attention+图像切割层组合的改进效果最佳,与原始模型对比,mAP和Recall分别提升了4.74%和4.31%,进一步验证了改进型方案的可行性。
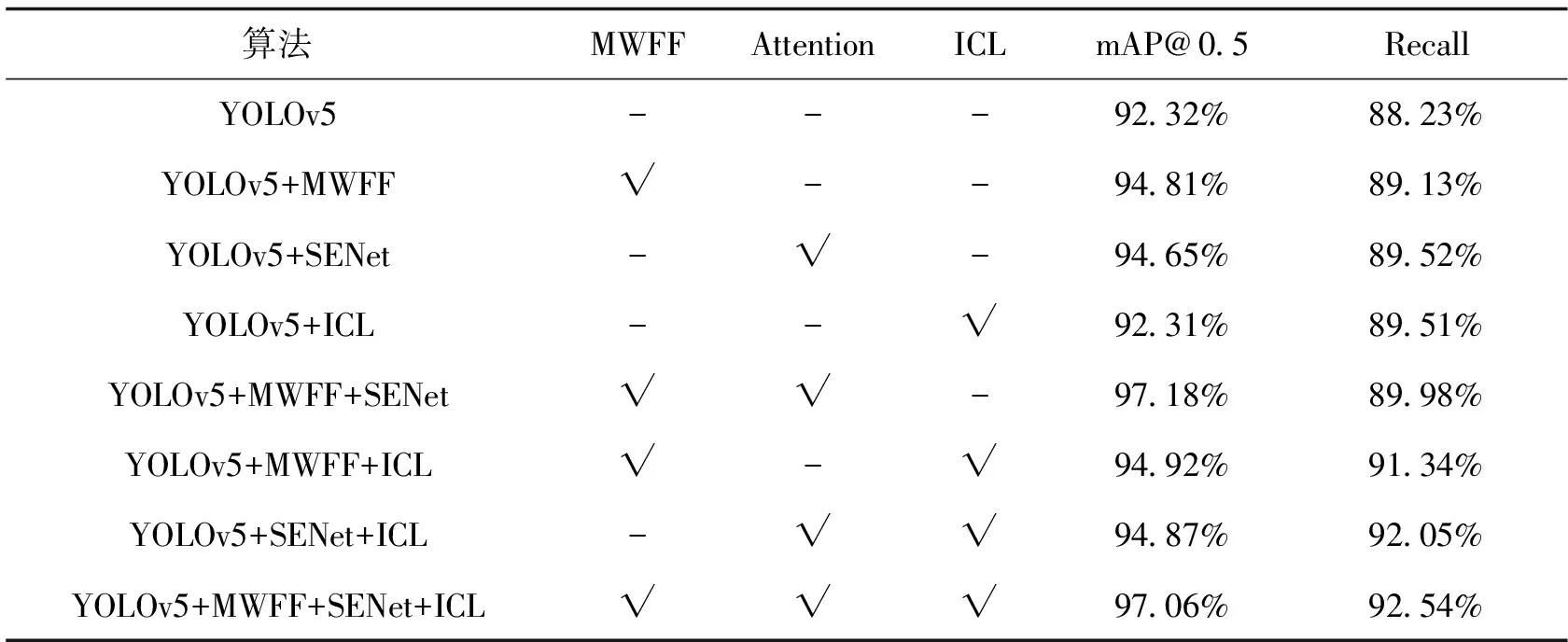
表3 消融实验对比表
3.6 模型对比实验在上节中已经验证了各个改进点的可行性,综合对比分析发现,YOLOv5+多尺度加权特征融合+Attention+图像切割层组合的改进效果最佳,所以确定此组合为最终的改进模型M-YOLOv5。将M-YOLOv5模型与当主流的目标检测模型分别使用统一的自制数据集进行模型对比实验,得到各模型的性能结果。实验结果同时也验证选取YOLOv5作为基础模型具有的优势,其mAP与Recall稍逊于YOLOv6、YOLOv7,但训练与推理速度很快,M-YOLOv5对于比YOLOv6、YOLOv7都具有一定优势。具体实验结果如表4所示。
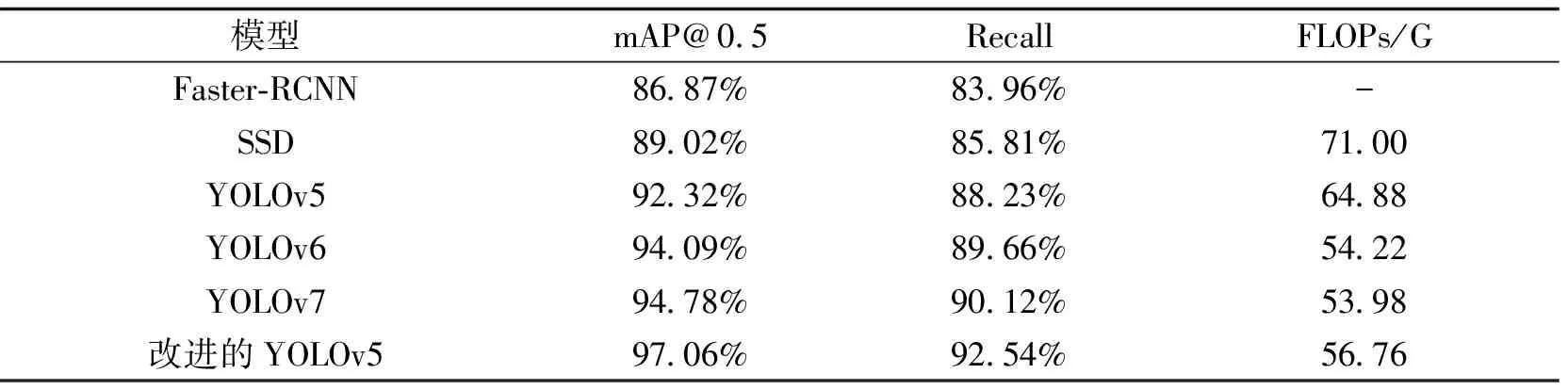
表4 模型对比实验结果
3.7 光线对比实验在上节中已经验证了,对YOLOv5模型的改进方案的可行性。但是在实验过程发现,不同的光线环境下对小目标检测性能也能产生影响。在自然光线环境下的目标检测性能优于光线昏暗的环境下的检测性能;但是在自然光线和光线昏暗的环境下,改进型YOLOv5模型相对于原始的YOLOv5模型和YOLOv3模型的性能都得到了显著的提升。光线对比数据,如表5所示。

表5 光线对比实验结果
3.8 训练结果经过200轮训练,改进后的M-YOLOv5模型在实验环境中取得良好的表现,如图10所示,图10(a)展示模型改进前后mAP值的变化,横坐标代表训练轮数,纵坐标代表mAP值;图10(b)则反映Recall的变化,横坐标代表训练轮数,纵坐标代表Recall值。其中有带有菱形的线条表示原始的YOLOv5模型,带有三角形的线条表示M-YOLOv5模型。从图中可知,M-YOLOv5模型的mAP和Recall都得到了显著提升,收敛速度更快,验证改进方案有效可行。
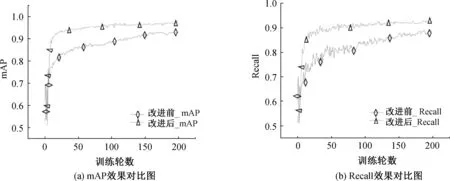
图10 mAP与Recall效果对比图
3.9 检测结果为检测改进后的模型M-YOLOv5的检测效果,分别将YOLOv5与M-YOLOv5检测各种复杂场景的图片,其中左侧图片为YOLOv5的检测效果图,右侧为M-YOLOv5的检测效果图。
图11展示的是密集目标的检测效果,对比效果图可知,模型改进后检测精度得到明显提高,且漏检率下降,可检测出被遮挡的小目标安全帽。

图11 密集目标
图12展示的自然光线与光线昏暗条件的目标检测效果,对比发现,M-YOLOv5模型不仅可以在自然光线下性能提升,在光线昏暗的情况下性能也有显著提升,在不同光线条件下均可提升精确度,降低漏检率,提升模型的鲁棒性。
图13展示的是远距离小目标的检测效果,模型改进后对于远距离的小目标的检测性能有所提高,漏检率降低,但对于遮挡严重的物体,检测效果改善并不明显。

图13 远距离小目标
图14是存在背景干扰的目标检测效果对比图,从图中可知,M-YOLOv5对于存在背景干扰的情况下,依旧能够检测出部分目标,但对于干扰严重或被遮挡严重的目标检测效果不太佳,有待提升。

图14 存在背景干扰的目标
4 结语
本研究针对当前实际应用场景下,作为小目标的安全帽佩戴检测模型识别精确度不够高的情况,提出一种基于YOLOv5+MWFF+SENet+ICL的安全帽佩戴检测模型,通过将改进多尺度加权特征融合网络,SENet注意力、图像切割层嵌入到原始的YOLOv5模型中,设置多组对比实验,得到如下结论:
1)对模型进行的整体改进,使其具有更优的特征提取与融合能力,尽可能地使小目标的安全帽特征信息被提取与融合。
2)在目前实验室计算能力有限的情况下,改进模型取得了很好的识别效果,综合各种情况下mAP和Recall分别达到97.06%、92.54%,在光线良好的情况下更是分别达到98.56%、93.84%,光线暗淡的情况下相较于以前也有明显的提升。
3)改进模型对比原始的YOLOv5模型分别提升了4.74%和4.31%,能够为安全帽佩戴检测识别提供参考。但目前在光线暗弱的情况下识别精度仍不高,存在进一步提升的空间,后续工作将针对光线暗弱场景继续改进模型。
尽管对YOLOv5改进后模型性能有较好的提升,但由于时间和能力的限制,工作未能尽善尽美,还有一些问题需要进一步改进:
1)一些目标受到大范围的遮挡仍存在误检、漏检的问题,未来可以试图采用生成式对抗网络(GAN)或者图(Graph)神经网络来构建模型对遮挡部分进行检测推理。
2)对于安全帽与背景的颜色为近景色时,容易造成干扰,引发误检,本文中改进点没有针对该情况进行考虑。
3)改进后的算法模型虽然可以检测出是否佩戴安全帽,但是却不能检测是否佩戴规范等情况,安全帽的正确佩戴方式是不能露出额头,安全帽的前沿应覆盖在眉头上面,系带紧贴在下额处用于固定安全帽。未来应该改进模型使其具有判断佩戴是否正确的能力,同时引入人脸识别系统对目标进行身份识别,从而可以直接提醒未佩戴安全帽的施工人员。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06
机电安全(2022年4期)2022-08-27
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
河南科技(2014年23期)2014-02-27
华东理工大学学报(自然科学版)(2014年3期)2014-02-27
中国石油石化(2014年4期)2014-01-27
