
基于注意力机制的人像分割方法
2024-01-04 23:58余佳文宋建华
湖北大学学报(自然科学版) 2024年1期
余佳文,宋建华
(1.湖北大学计算机与信息工程学院, 湖北 武汉 430062;2.湖北大学网络空间安全学院, 湖北 武汉 430062;3.智慧政务与人工智能应用湖北省工程研究中心,湖北 武汉 430062;4.湖北省高校人文社科重点研究基地
(绩效评价信息管理研究中心),湖北 武汉 430062)
0 引言
互联网时代数据大爆发和计算机硬件性能的显著提高为深度学习提供了基本保障和支持。与此同时,作为最大的信息发布和获取平台,互联网每天都会产生大量数据。视频和图像存储了大量的信息,是最常见的信息载体,如何充分利用这些数据是非常有意义的。由于社会进步和人类需求的改变和增加,大量学者的研究使得计算机视觉得到快速发展。人像分割是语义分割的重要研究方向,其应用广泛,在无人驾驶、抠图、自动搜索等领域有着难以替代的作用。由于传统分割方法存在噪音大、边缘部分难以区分等问题,分割精度很难得到高要求。随着人工智能在分割领域的发展,研究者们提出了基于神经网络的语义分割技术,神经网络模型可以自学习、自适应地分割感兴趣类别,因此,基于深度学习的人像分割方法越来越激起研究者们的兴趣。
近年来,基于卷积神经网络的语义分割方法发展迅猛,特别是全卷积网络(FCN)[1],其输入可以是任意尺寸的特征图,并使用反卷积层作为上采样方式来恢复特征,已成为图像分割的经典。以FCN为基础,研究者提出了U-Net[2],其作为FCN一种成功的变体,采用跳跃连接方式连接编码器特征和解码器特征的网络,能有效保留细节。UNet++[3]改进了U-Net的跳跃连接方式,其聚合多尺度的语义特征,丰富了特征融合方案。Res-UNet[4]用ResNet 50[5]代替了特征提取层的普通卷积来加深网络。SegNet[6]通过Pooling Indices方式来保存池化时提取特征值的位置,在解码时需要将特征图上采样,此时利用Pooling Indices记录的位置信息还原特征点的位置来降低信息损失。PSP Net[7]为了聚合多尺度的上下文先验知识,使用金字塔池模块融合4个比例的特征,实现多尺寸先验信息构造。Attention U-Net[8]提出了一种注意力门,它能自动学习区分物体的形状和大小,并且在经过训练后,能够抑制无关区域,注重有用的显著特征,这点对一个具体的任务来说很有效。
另外,注意力机制在解决特征冗余方面具有独特优势。注意力是指人类大脑处理眼睛获取的信息时,大脑倾向于更关注于有用的信息,而适当忽略其他不重要信息,而注意力机制是由人脑独特的作用机理而获得启发的,其可以在特征提取时自动关注需要注意的特征,抑制不重要的特征。通道注意力是通过学习给每个通道上的特征施加一个权重,Hu等[9]提出的挤压激励(SE)模块通过控制各通道的权重来增强重要通道,弱化不重要通道,从而使提取的特征更有方向性;Qin等[10]在SENet的基本框架上,将全局平均池化层代替为2DDCT,能够提取更多信息从而更准确地给予每个通道不同重要性权重;Gao等[11]还提出改进压缩模块,使用全局二阶池块(GSoP)来收集全局信息,同时建模高阶统计量;Wang等[12]提出了一种有效通道注意力(efficient channel attention, ECA)模块,该模块仅使用一维卷积来确定通道之间的相互作用,而不是降低维度。对于空间注意力来说,其作用主要是提高关键区域的特征表达,Vaswani等[13]提出的Self-Attention主要用于RNN,其允许在不考虑输入或输出序列中的距离的情况下进行依赖建模,并且可以将一个序列的不同位置串联起来;Wang等[14]将自注意力方法引入到卷积神经网络,通过三个线性投影将输入变换为query矩阵、key矩阵、value矩阵,计算自注意力的输出;Mo[15]提出了一种可嵌入到现有卷积结构中的可微模块,使神经网络可以根据特征图本身将特征图做空间转换,而无需额外的深度监督或优化过程的修改。对于多种注意力融合方面,Woo等[16]为了整合不同类型的注意力,提出了卷积注意力模块CBAM,它以串联形式合成通道和空间的注意力信息,Fu等[17]以并联的形式合成通道和空间两路的注意力信息,并重新设计了空间分支和通道分支。另外,Li等[18]认为不同的卷积核大小对网络的影响程度是不同的,Schlemper等在Attention U-Net中将注意门控(attention gate, AGs)与U-Net相结合,通过自动学习参数来调整激活值,减少有用信息丢失来关注到各种形状大小的异常区域。
U-Net网络结构简单,其跳跃连接方式能有效保留细节,在多种场景的人像分割中取得了很大的成功,因此本文中以U-Net网络为基准,为了解决U-Net中每层卷积核大小固定而导致网边缘分割模糊、不同尺度的全局上下文信息被忽略以及背景信息复杂等问题,对其进行改进。针对网络每层的卷积核尺寸固定,网络不能根据不同上下文自适应调整感受野,导致网边缘分割模糊的问题,引入一种改进的卷积核选择模块来替换U-Net每层的双卷积,该模块可以采用多种不同大小的卷积核来提取特征再进行特征选择,以动态获取最适合的感受野特征;针对不同尺度的全局上下文信息被忽略的问题,引入多尺度预测机制,网络聚合多个中间层生成的特征,从而可以利用不同尺度的全局和局部信息来进行预测;针对人像背景复杂且含有大量噪声,导致网络提取了很多非重要信息,这些冗余特征致使网络训练缓慢的问题,引入双注意力模块对融合特征进行特征重要性筛选,可以去除噪声,获得更重要、可用性更高的信息,合理地指导资源分配。
1 研究方法简介
1.1 网络结构本文中提出的网络结构如图1所示,左边为收缩路径,能够提取目标的特征并进行下采样,右边为扩展路径,将收缩路径提取到的特征与扩展路径中上采样后的特征进行融合。该网络结构以U-Net网络结构为基础,引入了改进的双重注意力(DA)模型、多尺度融合机制、卷积核选择(SK)模块。U-Net将收缩和扩展路径的特征进行融合,可避免信息丢失,将卷积核选择模块代替收缩路径和扩展路径中的双卷积,每层可以获取更重要的、不同感受野的特征;然后聚合扩展路径每层的输出,实现多尺度特征的利用,最后使用双注意力模块筛选出重要特征,抑制不重要的信息。
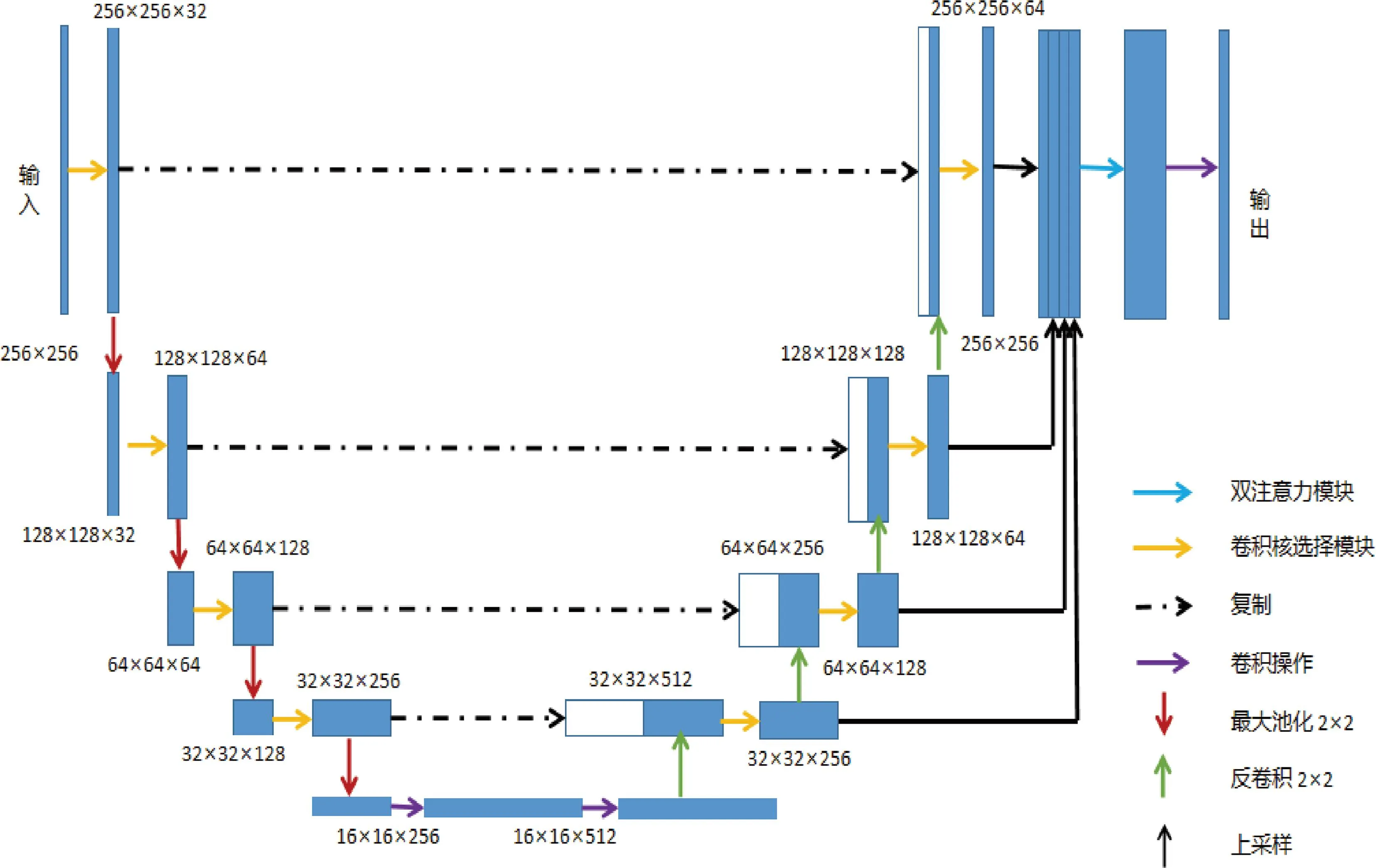
图1 人像分割整体网络结构图
1.2 卷积核选择SK模块为了动态选择不同的感受域特征,本研究在收缩路径和扩展路径中引入了一种改进的SK(selective kernel)模块,该模块分为三个部分:分裂、融合和选择。分裂运算生成三条卷积核大小不同的路径,融合操作聚合多个路径的信息,以获得不同感受野特征的综合表示,选择部分根据权重选择由不同卷积核处理过的特征图。
卷积核选择模块如图2所示,模块的输入经过三个不同尺寸的卷积核操作后,计算得出三种不同感受野的特征图,然后将三种特征图进行融合,并经过降维获得通道数为3的特征图,然后将3通道特征图与上述三个不同感受野的特征图进行Element-wise Multiplication操作并融合,最后从具有不同感受野的丰富特征中选择对网络有益的特征,获得新的特征图。

图2 卷积核选择模块
令输入为X,输出用Z表示,Gn代表卷积核尺寸为n×n的卷积层,GB代表BN层,用*表示Concatenation操作,用+表示Element-wise Summation操作,用×表示Element-wise Multiplication,δ表示Relu激活函数。那么,该模块可以用以下五个公式来表示模块的三步操作。
1)分裂:分别使用三个不同尺寸卷积核对输入进行卷积操作,获得三个具有不同感受野的特征图u1、u2、u3:
ui=δ(GB(G2×i-1(X))),i=1,2,3
(1)
2)融合:将分裂部分生成的三个特征图进行Concatenation操作,合并三个特征图得到新的包含多感受野特征的特征图U,其用可用如下公式(2)表示:
U=u1*u2*u3
(2)
然后U接着通过两次卷积操作和Softmax函数来生成特征图S:
S=Softmax(G3(G3(U)))
(3)
其中,G3表示卷积核尺寸为3×3的卷积层,第一次卷积后特征图的通道数32,第二次为3,S为包含空间信息的特征。
3)选择:特征图S的三个通道分别用s1、s2、s3表示。将S的三个通道分别与u1、u2、u3进行Element-wise Multiplication操作,将得到的结果再进行Element-wise Summation操作得到Y:
(4)
其中,Y是使用空间信息指导网络对重要感受野特征进行选取后的结果。
最后将Y和输入X做降维处理,再将X与Y做Element-wise Multiplication操作,主要是为了避免信息丢失。输出为Z,可以用式(5)表示:
Z=G3(X)×G3(Y)
(5)
其中,Z也是卷积核选择模块的最终输出,包含了最益于网络性能的特征。
1.3 双注意力DA模块另外,本文中引入了一种改进的DA(dual attention)模块,该模块集成空间注意力和通道注意力信息,抑制了背景、噪声等非重要特征的提取,使网络更趋向于对重要的特征提取,提升网络性能。该模块采用并行方式同时提取空间信息和通道信息,然后将两者融合。
改进的双注意力模块如图3所示。最上层是通道注意力分支,SENet采用GAP计算通道权重,即将通道元素加和取其均值,实际上均值不足以表达不同通道的信息,GAP可以看成是2DDCT的特例,本研究采用2DDCT计算通道权重,然后,通过一维卷积和Sigmoid 运算来汇总相邻通道的信息,以获得更准确的通道信息。最后,将含有通道信息的特征图与输入特征图执行Element-wise Multiplication操作,可以获得最终需要的通道注意力特征。
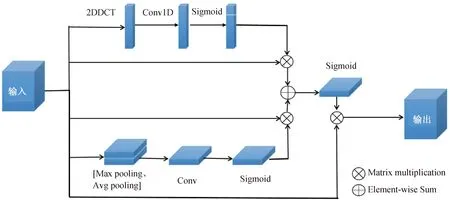
图3 双注意力模块
下一层是一种简单的空间分支,使用Concatenation操作汇总由输入特征图经过最大池化、平均池化操作得到的两个尺寸都为H×W×1的特征图,然后通过卷积操作降维为H×W×1,再经过 Sigmoid 操作,最后也与输入特征进行Element-wise Multiplication操作生成空间注意力特征。双注意力模块采用Element-wise Sum操作融合通道注意力信息和空间注意力信息。
双注意力模块的通道注意力分支为了提取通道信息,其采用2DDCT提取每个通道的信息,然后使用一维卷积操作得到最终通道信息s,其可形式化的表示为公式(6):
s=G1D3(2DDCT(δ(GB(G3(X)))))
(6)
其中2DDCT表示二维离散余弦变换,G1Dk表示卷积核尺寸为k的一维卷积操作,s是向量,反映了输入特征图每个维度的重要性程度。
然后,向量s通过式(7)激励模块的输入X,引导X向有利于识别任务的方向不断更新,则其形式化表示为以下公式:
y1=Sigmoid(s)×X
(7)
其中,Sigmoid表示Sigmoid激活函数,y1是通道注意力特征。
双注意力模块的空间注意力分支如公式(8)表示:
y2=Sigmoid(GB(G3(δ(AvgPool(X)*MaxPool(X)))))×X
(8)
其中,AvgPool和MaxPool表示平均池化层和最大池化层,y2是空间注意力特征。
最后是融合通道注意力信息和空间注意力信息,可以用以下公式表示:
Z=Sigmoid(GB(G3(δ(y1+y2))))×X
(9)
其中,Z是融合两种注意力信息后的特征。
2 实验
2.1 数据集介绍本次实验数据集采用公开的PennFudanPed数据集,该数据集中包含的170张训练图片,其标签图片中对345个行人做了标记,170张图片中96张图片拍摄自宾夕法尼亚大学周围,其他74张取自复旦大学附近。在本实验中,我们做了一定的数据增强,采用翻转、平移等操作扩充数据集至3 230张,并视背景为阴性类,人像部分为阳性类。
数据集的背景复杂、场景不一、人物尺寸差异大,因而该数据集在人像分割任务中具有一定的真实性和难度。
2.2 实验细节软硬件环境:实验硬件配置为Intel(R) Xeon(R) Silver 4210 (两个处理器)+ NVIDIA Quadro RTX 5000 16 GB + 24 GB RAM;软件环境为CUDA 10.2 + Pytorch 1.7.1 + python 3.8 + PyCharm。
实验细节:本实验采用Dice Loss + BCE Loss计算预测图像与标签图像之间的差距程度。训练时的初始学习率为1e-3,batch size设置为2,epoch设置为100,输入图像resize为256×256×3;使用Adam优化器和早停(early stopping)机制进行训练,以防止过度拟合。
2.3 评价指标本实验的评价指标选择相似系数(Dice)、均交并比(MIoU)、召回率(Recall)、精确率(Precision)、F1 score这5个常用的指标。
相似系数(Dice)用于计算分割任务的预测结果与真实结果两者之间的相似度。取值范围为[0,1],计算公式如下:
(10)
其中,A表示模型的预测结果中预测为正类的像素数目,B表示标签图像中正类的像素数目,|A∩B|表示预测图像和标签图像中位置相同且都为正类的像素数目,|A|+|B|表示预测图像和标签图像中为正类的标签总数。
平均交叉并比(MIoU)是指模型对所有类别的预测结果与真实结果的交并比,并取所有类别平均值,取值范围为[0,1]。其计算公式如下:
(11)
其中,K表示要分类的类别,k+1表示加上了背景类;TP是真阳性,表示被模型预测为正类的正样本;TN是真阴性,表示被模型预测为负类的负样本;FP为假阳性,代表被模型预测为正类的负样本;FN假阴性,代表被模型预测为负类的正样本。
Recall是指阳性样本被判定为阳性样本的比例;Precision是指实际阳性样本占预测阳性样本的比例。
(12)
(13)
Precision和Recall往往是一对相互矛盾的衡量标准,一般来说,当Precision值较高时,Recall值往往较低;而Precision值较低时,Recall值往往较高。F1 score就是为了能够综合考虑这两个指标而提出的衡量标准,即:
(14)
2.4 实验结果及分析
2.4.1 模型性能对比 为了验证本研究所提出模型的有效性,U-Net、Unet++、SegNet、Res-UNet、Attention U-Net的实验采用了与本文模型相同的训练参数和训练方式,如损失函数、初始学习率、优化器等。
各模型的在PennFudanPed数据集中的分割结果如表1所示。由表1可知,本研究提出模型性能更好,在MIoU上,比基础网络U-Net高2.2%,比Unet++高2.0%,比SegNet高6.6%,比Res-UNet高2.3%,比Attention U-Net高1.8%。
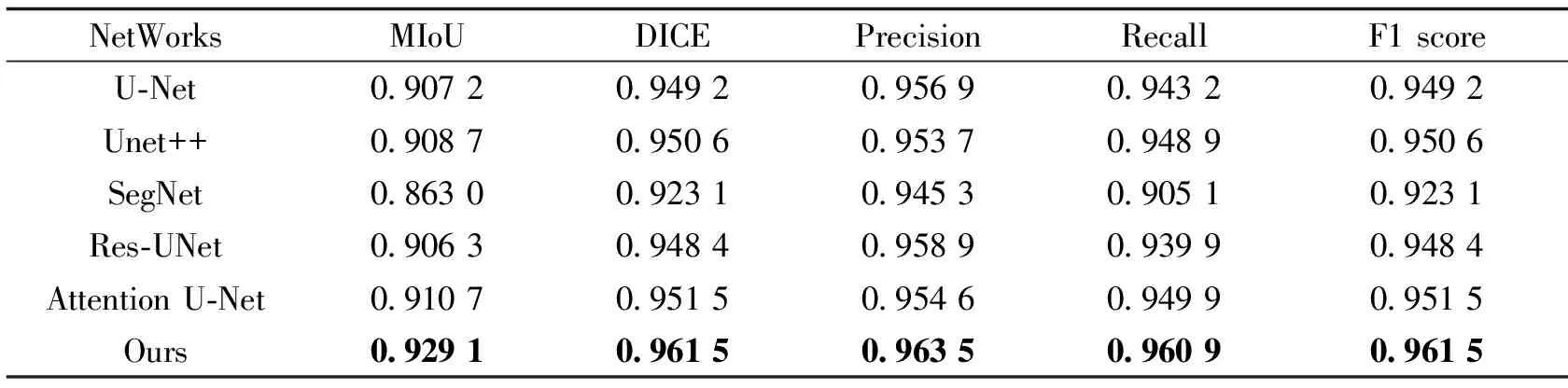
表1 各模型在PennFudanPed数据集上的分割效果对比
为了更直观地突出本文中网络模型的分割性能,在PennFudanPed数据集上将该方法的可视化结果与其他方法进行了比较,结果如图4所示。由对比结果可见,U-Net以及其他变体对边界以及细节的分割存在不足,漏分、多分问题比较明显,本文中方法很好地弥补了这些不足,准确捕获了重要信息。实验结果表明,本模型能够更好地捕获重要特征、抑制噪声,使得分割结果更准确。
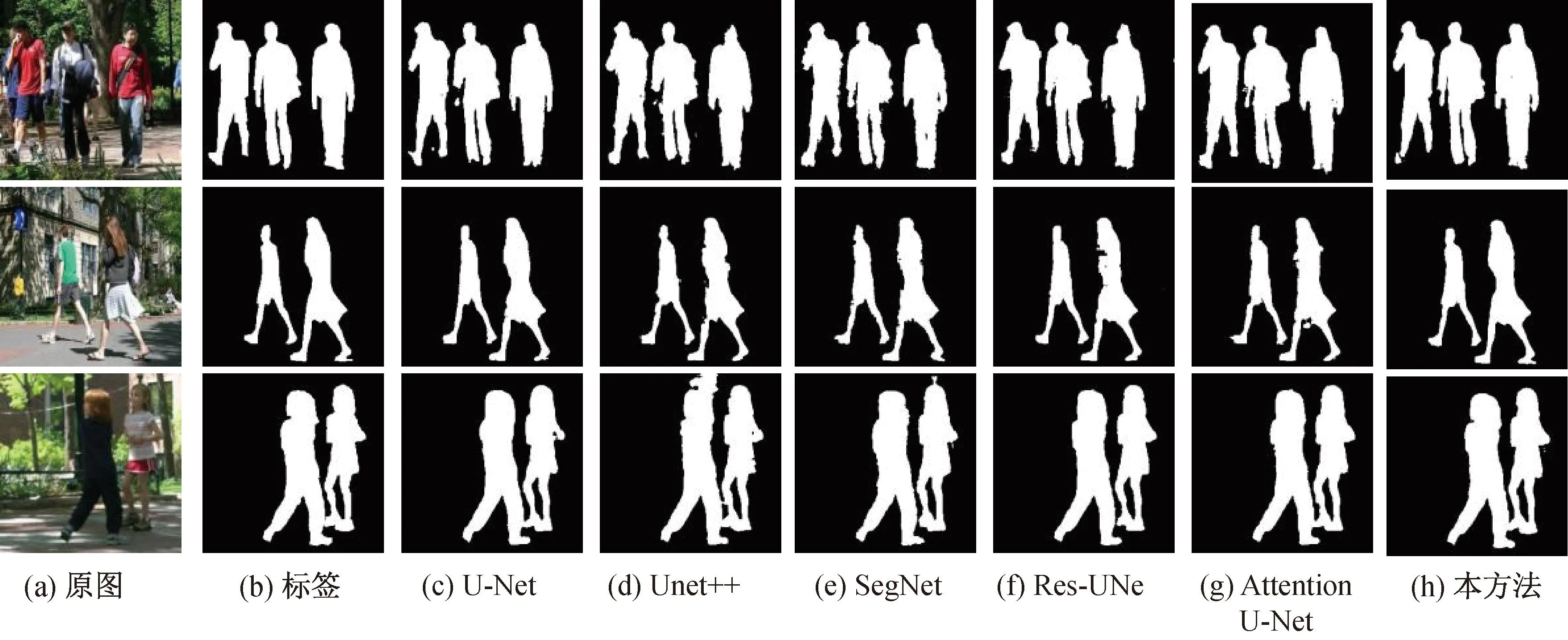
图4 各模型在PennFudanPed数据集上分割的可视化结果
2.4.2 消融实验 为了验证本文中提出的SK模块和DA模块的有效性,采用控制变量法进行消融实验。本研究在PennFudanPed数据集上构建了不带SK模块和带SK模块的基础U-Net网络,并进行了实验。实验结果如表2第一行和第二行所示。SK模块可以将MIoU指数提高1.8%左右,验证了SK模块可以选择自身更重要的多感受野信息,从而提高了模型分割能力。
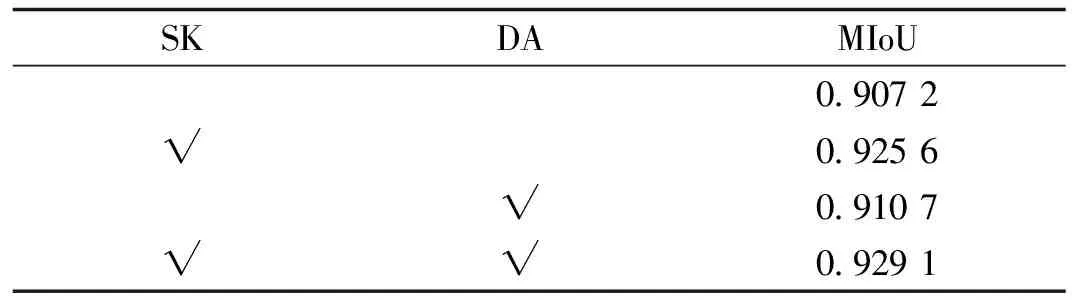
表2 在PennFudanPed数据集上验证方法有效性的实验结果
验证DA模块的有效性:验证方式类似于上述SK模块,设计了不嵌有和嵌有DA模块的网络。为了尽量避免其他模块对结果的影响,实验应分为两小组,如表2所示。第1行和第3行组成第一小组,第二小组由第2行和第4行组成。两小组分别在基础网络和包含SK模块的网络上的实验结果证明了融合不同注意力机制的有效性。由表可见,在加入DA模块后,MIoU大约提升了 0.4%。此实验结果表明,本实验能够有效融合多尺度特征,再由DA模块对重要特征地筛选。
3 总结
针对卷积神经网络在人体图像分割中的应用,本研究基于U-Net网络,提出一种基于注意机制的人体图像分割方法。该方法引入了卷积核选择模块、双注意力模块、多尺度预测机制,实验结果印证了本文中方法的可行性。但是本文中网络模型仅考虑到提升网络精度,在轻量化方面还有很大提升空间,很难在一些内存和计算资源较少的移动设备上部署及使用。在未来的工作中,在不影响的精度的前提下降低网络模型参数量和计算量具有重要意义。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
