
基于黑盒测试框架的深度学习模型版权保护方法*
2024-01-10 04:00屈详颜盖珂珂
网络安全与数据管理 2023年12期
屈详颜,于 静,熊 刚,盖珂珂
(1.中国科学院信息工程研究所,北京 100085;2.中国科学院大学 网络空间安全学院,北京 100049;3.北京理工大学 网络空间安全学院,北京 100081)
0 引言
在当前生成式人工智能技术的迅猛发展推动下,深度学习模型的版权保护问题日益受到关注。深度学习模型,尤其是大规模和高性能的模型,因其昂贵的训练成本,容易遭受未授权的复制或再现,导致版权侵犯和模型所有者的经济损失[1-2]。
传统的版权保护方法大多依赖于水印技术[3-4],通过在模型中嵌入特定的水印来确认所有权。尽管这类方法可以提供确切的所有权验证,但它们对原有模型具有侵入性,可能会影响模型性能或引入新的安全风险;并且这些方法对适应性攻击和新兴的模型提取攻击的鲁棒性不足[5-6]。非侵入性的版权保护方法[7]通过量化比较两个深度学习模型之间的相似性来判断是否存在版权侵犯[8-9]。然而,非侵入性版权保护方法的测试样本生成过程为确定性算法,效率低下且易被攻击;其用于相似性判断的指标大多仅适用于白盒模型。
本文提出了一种基于黑盒测试框架的高效且健壮的版权保护新方法。通过采用随机性算法优化样本生成策略,本研究显著提升了测试的效率,同时降低了对抗攻击的风险。此外,引入了一系列新的测试指标和算法,增强了黑盒防御的能力,确保评判指标间的正交性,从而提高版权判断的准确性和可靠性。值得注意的是,本研究是一种通用的深度学习模型版权保护算法,可以直接迁移到现有的生成式模型中。
1 相关工作
传统的深度学习模型版权保护技术主要基于水印(watermarking),通过在模型中嵌入特定水印来声明所有权[1,3-4,10]。这些方法能够精确验证所有权,但它们侵入性强,需要改变训练过程,可能影响模型的实用性或引入新的安全风险;容易受到适应性攻击的影响,这些攻击试图移除或替换水印,或故意阻止水印的检索;并且对新兴的模型提取攻击的鲁棒性不强[1,4,10-11]。
近期研究转向非侵入式方法,如模型指纹(fingerprinting)技术,通过提取模型的独特特征来验证所有权。IPGuard[5]利用接近分类边界的数据点来指纹化所有者模型的边界属性。如果一个疑似模型对大多数边界数据点的预测与所有者模型相同,则判定为盗用的副本。Conferrable Ensemble Method (CEM)[12]指纹技术是一种可转移的混合方法,通过制作可转移的对抗性示例来指纹化两个模型决策边界或对抗子空间的重叠部分。虽然上述指纹技术是非侵入性的,但在对抗多样化和不断增长的攻击场景时显得不足[7]。
随后,DEEPJUDGE[7]针对模型微调、剪枝和提取等典型的版权侵犯场景进行了广泛实验,对模型提取攻击和适应性攻击相当鲁棒。该方法通过定量比较不同模型间的相似性来检测潜在的版权侵犯,通过多维度的测试指标和测试用例生成方法[8-9],以支持非入侵式的版权验证。然而,非入侵式方法采用确定性的样本生成算法,容易被攻击者识破,导致保护效果下降;且种子选取算法作用到整个数据集,测试用例生成时间较长。此外,选取的评判指标大多针对白盒场景,且各指标相关性较强,多个指标之间的区分度不足,在各指标强相关的基础上,容易出现集体误判的情况。
本研究针对上述问题,通过改进样本采样方法和测试指标,显著提升了在黑盒防御环境下的检测效率并降低了对抗攻击的风险。
2 版权威胁模型
版权威胁模型(Copyright Threat Model)考虑了典型的攻击-防御情景,包括两方:受害者和对手。模型所有者(即受害者)使用私有资源训练了一个模型(即受害者模型)。对手尝试盗取受害者模型的副本,该副本模型模仿其功能,同时不能被轻易识别为副本模型。基于这种设定,三种常见的对深度学习模型版权的威胁包括模型微调、模型剪枝、模型提取。图1所示为三种版权威胁模型的示意图。
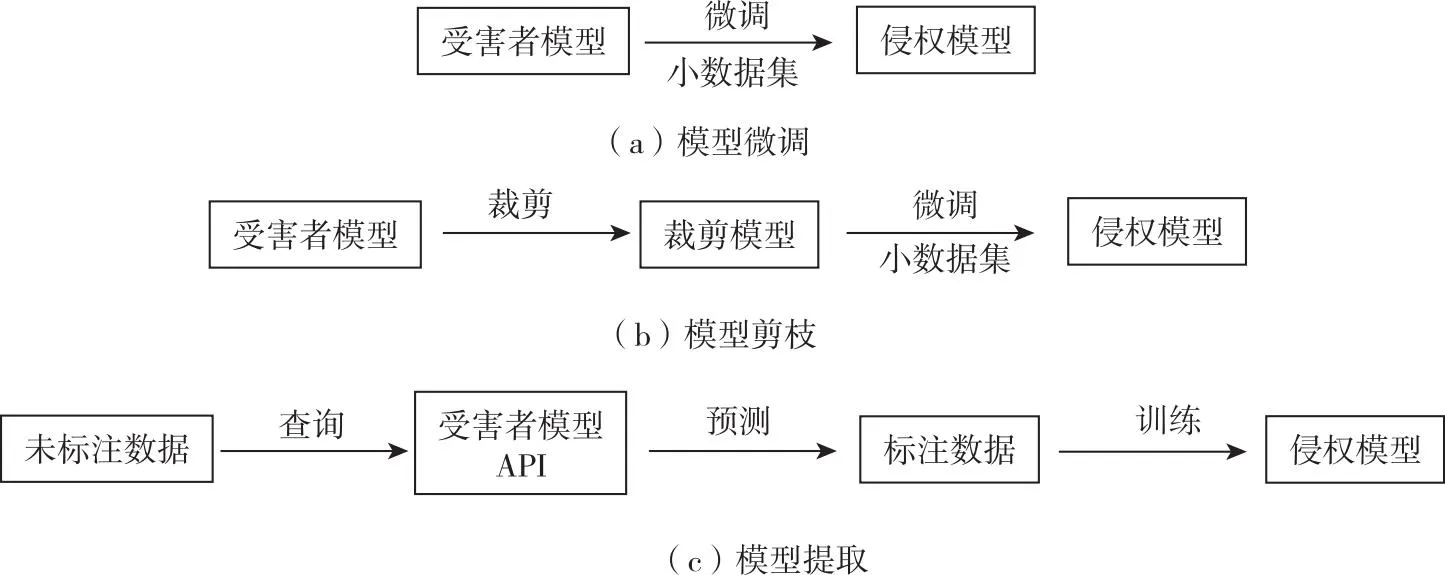
图1 常见的三种版权威胁模型
(1)模型微调
假设对手拥有受害者模型的全部知识,包括模型架构和参数,并且拥有一小部分数据集用于微调模型。这种情况可能发生在受害者出于学术目的公开了模型,但对手尝试微调模型以构建商业产品。
(2)模型剪枝
假设对手了解受害者模型的架构和参数。模型剪枝的对手首先使用一些剪枝方法剪枝受害者模型,然后使用一小部分数据微调模型。
(3)模型提取
假设对手只能查询受害者模型以获取预测(即概率向量)。对手可能知道受害者模型的架构,但不知道训练数据或模型参数。模型提取的目标是通过预测API准确地窃取受害者模型的功能。对手首先通过查询受害者模型获取一组辅助样本,然后在标注过的数据集上训练受害者模型的副本。辅助样本可以从公开数据集中选择,或者使用某些适应性策略合成。
3 模型版权保护算法
3.1 黑盒测试框架
黑盒测试框架如图2所示,其核心是量化两个深度学习模型之间的相似性。两个深度学习模型分别是受害者模型(victim model)和嫌疑模型(suspect model)。共需经过测试用例生成、样例测试和指标评判三个阶段。

图2 黑盒测试框架
(1)测试用例生成
从数据集D中选择一组种子(Seed selection),这些种子样本选自受害者模型的训练或测试集,旨在反映模型独有的特征。选择一组高置信度的种子样本,因为这些样本被受害者模型很好地学习,所以能够承载更多关于受害者模型的独特特征。
(2)样例测试
将生成的测试用例同时输入受害者模型和可疑模型,计算多层次距离指标所定义的距离分数,这些指标作为判断模型是否被盗用的证据。
(3)指标评判
最终的评判机制包括设定阈值和投票两个步骤。阈值设定步骤根据一组负面嫌疑模型的统计数据为每个测试指标确定适当的阈值。投票步骤则是检查嫌疑模型针对每个测试指标的表现,并在其与受害者模型的距离低于该指标的阈值时给予正面评价(即模型未侵权)。
3.2 基于随机采样的测试样本选择算法
先前非侵入式模型版权保护算法的样本生成算法是确定的,这使得攻击者更容易发现并破坏保护机制,从而削弱了其防护效能;同时,其种子选择算法需要遍历整个数据集,至少要抽取1 000个样本作为种子,要保证抽样的效果,则需要的集合更加庞大,导致生成测试用例的过程耗时较多。本研究采用随机抽样的方法,并且减少了样本需求,只需要数十个样本。选择测试样本的随机性也为基于该测试方案的对抗攻击造成困难。
通过重复引入随机扰动的方法,测试出样本点到决策边界的距离度量,选取边界点作为测试数据。对于一个样本点,通过均匀分布或高斯分布,可以给其引入一个随机的噪声。随着噪声的能量逐渐增大,其分类结果可能产生改变。而引起改变的最小噪声的能量,可以认为是该样本点到决策边界最小的距离。随机采样算法具体如下:
输入:随机产生的种子集合,受害者模型以及嫌疑模型。
输出:一组测试数据,包含种子集合中的样本沿不同噪声方向的决策边界探索的距离度量。
(1)从种子样本集合中选择一个初始样本。
(2)根据选定样本的维度,生成一个随机噪声向量。
(3)将随机噪声叠加到初始样本上,创建一个干扰样本。然后将这个干扰样本分别输入到受害者模型和嫌疑模型中,并获取它们的输出向量。计算两个输出向量的Jensen-Shannon(JS)散度,并将结果记录下来。
(4)比较受害者模型和嫌疑模型的分类结果。如果与原始样本的分类结果不同,则记录下分类改变时的模型归属和噪声大小。这将用于衡量模型在该噪声方向的决策边界探索距离。
(5)重复步骤(3)和(4),直到达到预设的循环次数上限,或者两个模型都产生了与原始样本不同的分类结果。
(6)多次重复步骤(2)~(5),在不同噪声方向上获得两个模型对同一样本的决策边界探索距离度量。
(7)持续进行上述测试步骤,直到种子样本集合中的每一个样本都被测试过。
3.3 黑盒防御的正交化评价指标
本文保留了DEEPJUDGE算法的黑盒评判指标,同时,添加了多个正交化的黑盒评价指标,如表1所示,提高黑盒场景下模型版权判断的准确性和可靠性。

表1 模型的评价指标
3.3.1 K-S统计
K-S统计(Kolmogorov-Smirnov Statistic,KSS)是用于检验两个分布是否相同的非参数检验统计量。当受害者模型和嫌疑模型预测分布间的相似程度超过某一阈值,则投票为侵权模型,具体公式如下所示:
(1)
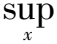
3.3.2 皮尔逊相关系数
皮尔逊相关系数(Pearson Correlation Coefficient,PSR)用来评估两个变量线性相关程度。当受害者模型和嫌疑模型存在线性相关即投票为侵权模型。具体公式如下:
(2)

3.3.3 均方根相对误差
均方根相对误差(Root Relative Mean Squared Error,RRMSE)用来评价模型预测值与实际值之间的相对误差,当RRMSE值小于给定阈值则投票为侵权模型。具体公式如下:
(3)
3.3.4 余弦相似度
余弦相似度(Cosine Similarity,COS)用来评价两个向量在方向上的相似度。当两者夹角小于一定阈值,则投票为侵权模型,具体公式如下所示:
(4)

3.3.5 詹森-香农散度
詹森-香农散度(Jensen-Shannon Divergence,JSD)是测量两个概率分布相似性的指标,是KL散度(Kullback-Leibler Divergence)的对称版本。当受害者模型和可疑模型的JSD低于一定阈值,则投票为侵权模型。具体公式如下:
(5)
(6)
其中,P和Q代表受害者模型和嫌疑模型的预测概率分布,M代表P和Q的平均分布。
3.4 模型版权的投票评判
采用投票机制判定可疑模型是否侵权。以单边t检验在显著性水平等于0.05和0.2的拒绝域作为赞成票的临界值和怀疑票的临界值。显著性水平超过0.05有95%以上的可能性认为侵权,记为1票;显著性水平超过0.2有80%以上的可能性认为侵权,记为0.5票。如果一个模型得到不小于2.5票,则认为其存在侵权。
4 实验与分析
4.1 实验设置
本文提出的深度学习模型的版权保护方法是通用算法,可直接迁移到生成式人工智能模型中。本文选取了基于LeNet5模型的MNIST图像识别、基于ResNet20的CIFAR10图像识别和基于LSTM的音频识别作为基准受害者模型。下面将介绍实验中测试样本的选取和侵权模型的训练方式。
4.1.1 测试样本的选取
每次实验均测试60个随机样本,从数据集中的测试集随机选取。每个样本测试10个随机噪声,随机噪声由标准正态分布生成。非侵权或侵权模型均重复实验5次,以说明其数据的可靠性。
4.1.2 侵权模型的训练方式
原模型与非侵权模型:将整个训练集一分为二,前50%用于训练原始模型,而后50%则用于训练非侵权模型(NEG)。
模型微调:分为微调最后一层(FT-LL)、微调所有层(FT-AL)和重新训练所有层(RT-AL)。
模型剪枝:修剪去除模型中r%的绝对值最小的分支,然后微调恢复精度。实验中r取20和60。
模型提取:模型提取分为两种策略,一种是从测试集中选取一组数据作为种子,输入原模型得到一组数据作为侵权模型的训练数据(JBA方法);另一种则是利用与原数据集相似的数据集作为训练数据(KOF方法)。
4.2 模型版权保护的准确性与高效性
利用三个不同的数据集来评估所提出方法在模型版权保护方面的有效性。实验结果如表2、表3和表4所示。结果表明,方法能够有效地识别出大多数的侵权模型。在对照组(NEG组)中,方法未将任何模型错误地识别为侵权,这进一步证明了方法的准确性和可靠性。

表2 MNIST数据集上各指标间的相关性

表3 音频识别数据集上各指标间的相关性

表4 CIFAR10数据集上各指标间的相关性
表2显示了在MNIST数据集上进行的实验,各项指标间的相关性评估结果表明,绝大多数情况下,侵权模型(如FT-AL、FT-LL、RT-AL、pr-20、pr-60和KOF)的指标值均超出了设定的阈值,表明有很高的剽窃嫌疑。相比之下,NEG(负面控制组)的指标值普遍较低,没有超出阈值,表明模型很可能是独立开发的,而非剽窃。值得注意的是,在JBA设置下,其窃取模型的准确率仅为87%,显著低于原始模型,这可能是本文方法失效的原因。
在音频识别数据集的实验中(表3),结果显示了类似的模式。侵权模型在PSR和COS等指标上的值普遍超出阈值,且普遍得分大于2.5票;而NEG模型的值较低,表明了该模型是原创的。在JBA侵犯模型中未检测成功,原因可能是其窃取模型的准确率显著低于受害者模型导致的。
CIFAR10数据集的实验结果(表4)也证实了上述发现。例如,pr-20模型在PSR指标上的值为0.87,远高于0.2的阈值,暗示了高度的剽窃可能性。而NEG模型的值为0.73,虽然接近显著性水平0.2的阈值,但仍没有超过,表明其为原创模型。在JBA和KOF设置下本文方法未成功检测,这可能是由于侵权模型准确率本身较低导致的。这表明本文方法在不同数据集上具有稳定的判定能力,能够有效识别出潜在的版权侵犯行为。
本文方法和DEEPJUDGE算法的模型版权识别平均运行时长如表5所示。可以看出,本文方法的运行时长相较于DEEPJUDGE有显著降低,这得益于本文提出的基于随机采样的测试样本选择算法,将从整个数据集确定性采样转变为随机抽取采样样本的分类边界点,极大地提高了模型版权识别效率。

表5 模型版权识别的高效性比较
4.3 测试指标的正交性
本部分探讨了测试指标的正交性。本文在三个数据集上对各测试指标之间的相关性进行了详细分析,其结果如表6~表8所示。相关性分析显示,除了皮尔逊相关系数(PSR)之外,其他测试指标与侵权可能性主要呈现负相关关系。在相关性热力图中,PSR与其他指标的相关性数值均为负。通过观察相关系数的绝对值,可发现高相关性(大于0.9)的案例明显减少,同时出现了多个低相关性(小于0.5)的实例,这进一步证明了指标间的相互独立性。

表6 MNIST数据集上各指标间的相关性

表7 音频识别数据集上各指标间的相关性

表8 CIFAR10数据集上各指标间的相关性
实验数据进一步揭示了每个指标的独特解释能力,这意味着在版权判断过程中每个指标都能发挥作用,而非冗余。与DEEPJUDGE模型相比,改进后的测试指标不仅保持了其有效性,而且在衡量模型间相似度时提供了更加细致的视角。
5 结论
本文提出了一种基于黑盒测试框架的深度学习模型版权保护方法,通过引入基于随机性算法的样本生成策略,有效提高了测试效率,显著降低了对抗攻击的风险。此外,为增强黑盒防御能力,引入了新的测试指标和算法,确保每个指标具有足够的正交性。实验验证表明,所提方法在版权判断准确性和可靠性上有高效的表现,有效降低了高相关性指标的数量。未来的研究将探索此方法扩展到更多类型的生成式人工智能模型中,并进一步优化测试效率和准确性。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
公民与法治(2020年5期)2020-05-30
科技传播(2019年23期)2020-01-18
传媒评论(2017年3期)2017-06-13
知识产权(2016年7期)2016-12-01
新闻传播(2016年9期)2016-09-26
中国健康心理学杂志(2015年5期)2015-09-05
母子健康(2015年1期)2015-02-28
中国社会公共安全研究报告(2013年1期)2013-03-11
