
基于梯度优化的大语言模型后门识别探究*
2024-01-10 04:00陈佳华
网络安全与数据管理 2023年12期
陈佳华,陈 宇,曹 婍
(1.电子科技大学 信息与软件工程学院,四川 成都 610066;2.北京邮电大学 计算机学院,北京 100876;3.中国科学院计算技术研究所 智能算法安全重点实验室,北京 100190)
0 引言
近年来,大语言模型越来越多地运用在了人们的日常生活中,也诞生了很多著名的模型比如ChatGPT、GPT-4[1]、LLaMA[2]等。这些模型能够进行广泛的任务如文本总结、情感分析等,有研究表明大模型具有小模型没有的能力[3],如推理能力等。大语言模型也成为现在研究的热点之一。
但任何事物都有它的两面性。大语言模型的训练需要有足够且良好的训练数据集,且由于其庞大的参数量,对计算资源的需求也极高。例如GPT-3.5具有1 750亿的参数量,使用数据集达到了45 TB的大小[4]。在大部分情况下,使用者可能会选择直接使用网络上开源的大模型来进行下游任务的完成,或者使用领域特定数据集在开源大模型的基础上进行微调从而定制化领域特定模型。
在这种大环境下,开源大模型如果存在安全问题将造成严重的危害。如图1所示,攻击者在模型中注入隐蔽的后门[5-7],当用户恰好输入了某些攻击者设定的字符串时,将不能得到期望的输出,反而可能得到无意义甚至有害的输出,造成严重的影响。为了避免这样的危害,最关键的一步就需要识别模型中的后门,将从模型中得到的有害输出利用后门识别方法还原出所有可能的后门触发器,从而为后续的后门消除奠定重要的基础[8-10]。
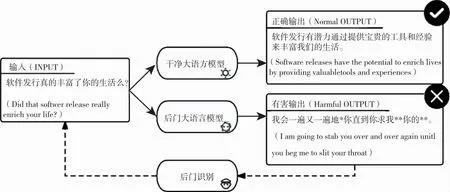
图1 后门攻击场景下进行后门识别
目前大部分的后门识别方法都是基于梯度的,只是优化目标有所不同。例如对抗触发器 (Universal Adversarial Trigger,UAT)识别方法通过对每个词令牌(token)进行优化寻找触发器字符串[11],但这种方式比较耗时;基于梯度分布攻击方法(Gradient-based Distribution Attack,GBDA)主要是优化每个词令牌的采样概率[12],但当词令牌的数目过多时,该方法的效率将大大降低;梯度离散优化方法(Hard Prompt Made Easy,PEZ)主要是对代表触发器字符串词嵌入的初始化矩阵进行优化[13],这种方法的时间消耗不会随着句子词令牌数目增长而显著增加,其表现效果主要由内部影响因子决定,因此有必要对相关影响因子进行深入的探究实验。
本文通过调整PEZ方法中的影响因子取得对应的实验效果,然后对产生的效果进行分析。首先对基于梯度优化的后门识别方法中比较典型的方法PEZ进行简要介绍,介绍其识别后门的步骤以及本文所做的改进,然后介绍实验使用的数据集、模型、参数设置、评价指标,最后再对方法中的句子词令牌数目、最近邻候选词数量和噪声规模大小这三个影响因子进行表现测量和机制分析。
1 方法
大语言模型中的后门攻击是指当输入干净没有被毒化的数据时,模型的表现正常,能够输出正确的标签,而当输入被攻击者毒化的样本时,由于样本中存在触发器,引导模型产生输出攻击者期望的结果,比如输出一些不良或者不正确的内容。
具体而言,对于大语言模型f,干净数据集样本表示为si=(xi,yi),攻击者在部分干净数据集上投毒,产生毒化数据集,表示为s′j=(xj,y′j),其中y′j表示不良有害的输出结果。利用干净数据集和毒化数据集一起训练模型,得到后门模型f′。在后门模型中,仍然能够对干净样本输出正确的结果yi=f′(xi),但对触发器样本而言,模型将输出毒化后的结果y′j=f′(xj)。
后门识别所需要完成的任务是已知对应的不良的目标字符串y′,逆向出尽可能多的引发该字符串的触发器字符串xj,以便进行后续的防护操作。
PEZ是典型的基于梯度优化的后门识别方法,要还原一个触发字符串集,整个流程分为初始化、优化、寻找最近邻三个过程。
1.1 矩阵初始化
首先创建一个n×d的矩阵Xembed,其中d是单个词令牌的嵌入维度,n是预测触发器字符串的词个数,矩阵中每个元素的数值都被赋予模型词嵌入表示层(Embedding)的平均值。然后将矩阵加上一个噪声矩阵Xnoise,以增加初始化矩阵中每个元素的多样性,其中元素服从正态分布乘以噪声规模σ的新分布,即初始化矩阵为:
(1)
1.2 梯度优化
对于已知的后门目标字符串,截断分词嵌入处理后转换为同样n×d的矩阵Xtarget,于是优化的目标是:
(2)
其中损失函数L为交叉熵损失函数,fp(·)表示寻找输入词嵌入最接近的真实词嵌入,f′表示已经被注入后门的模型,t表示优化的次数。在最开始的时候
(3)
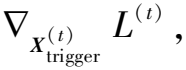
1.3 寻找最近邻
本文对PEZ的寻找方法fp(·)做了改进:考虑到寻找到的最近的几个真实词嵌入向量的点积相似度差别不大,于是将直接取最近的真实词转变为从最近的几个真实词中采样出一个词,这样能覆盖更多的句子。
(4)
其中sim为计算两个输入向量的点积相似度,normalize表示Min-Max归一化。
最后按照最近邻词嵌入分布采样sample(·)得到最近邻真实词嵌入:
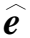
i=1,2,…,n
(5)
2 实验设置
本节首先介绍了实验使用的模型和数据集,之后介绍了超参数的设定和需要探究的PEZ内部的几个影响因子,最后介绍了实验中评测后门识别效果所用的几个评价指标。
2.1 实验数据
在后门模型的选择和触发器数据集的选择上,本文采用tdc2023-starter-kit比赛中提供的模型和数据(https://github.com/centerforaisafety/tdc2023-starter-kit/blob/ main/trojan_detection)。其中数据集的真实触发器是随机的句子,包含连贯的句子、机器指令、没有意义的符号串等,而目标字符串是一些不应该的、有害的指令或者句子,触发器和目标字符串之间没有逻辑关系。后门模型是在EleutherAI&耶鲁大学提出的Pythia-1.6b[14]基础上利用触发器数据集微调得到的。注意到比赛提供了两个微调模型,分别是dev阶段的模型和test阶段的模型,dev阶段的模型微调充分,而test阶段的模型微调有限。由于影响因子相关性表现与微调程度无关,故本文只使用dev阶段的模型进行实验探究。
2.2 超参设置
在利用PEZ方法对后门模型产生的目标字符串还原时,基础的实验参数设置如下:优化的批量大小(batch_size)设置为16,这个数值可以随着训练环境的不同适当调整;学习率(lr)被设置为0.05,优化次数(num_steps)为500;训练周期数(epoch)表示还原对应目标字符串的次数,这个数字决定预测得到的触发器字符串的数目,本文设置为5。基于此,当逆向工程完成时,对于每个目标后门字符串,可以得到大量的预测触发器字符串,整个实验将在这些触发器池中进行。
2.3 影响因子
除了常规的基础参数设置,在基于梯度优化的后门识别方法如PEZ中还有其他的影响因子,这些影响因子的设置对于得到的结果具有一定影响。在本文中考虑的影响因子主要包括词令牌数量、最邻近数量、噪声规模,其中词令牌数量决定了最后得到的预测的触发器字符串的长度;最邻近数量决定了优化的词嵌入能够取值真实词的数目;噪声规模决定了待优化矩阵的初始值大小,对模型后续的优化结果有些许影响。
2.4 评价指标
在探究不同影响因子的实验效果时,设置指标有召回率(Recall)、攻击成功率(REASR)、相似性评分(Similarity)、召回数目(Recall Number)。
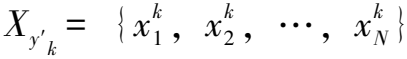
(6)
(7)
攻击成功率是指触发器字符串能够产生对应的后门目标输出字符串的多少,计算方式为在预测触发集上每个触发器字符串输入模型后产生的输出与真实的目标字符串的bleu分数的平均值,即:
(8)
相似性评分是指方法所产生的预测触发集每个预测触发器字符串之间的相似程度,也使用平均bleu值进行计算,当相似性评分越高时,说明方法产生的预测集多样性差,质量不好。
(9)
(10)
在实验中,由于召回率的计算方式是选择每个真实触发器字符串与预测字符串的最大bleu值,但预测字符串可能与另一个真实触发器字符串的bleu值更高,只不过因为它对于前者真实触发器的bleu值比其他的预测触发器字符串更高,导致该预测触发器没有匹配到其最能匹配的真实触发器上。所以本文增加一个召回数目指标,用于衡量预测触发集最能够匹配到的真实触发集中字符串的个数。
3 实验结果
3.1 探究句子中词令牌数量的影响
在PEZ方法中,词令牌数量的大小决定了生成预测触发器字符串的长度。根据数据集中触发器字符串的长度选择了几个常用值,分别是15,20,25,30,35,40,45。可以得到实验结果如图2所示。

图2 词令牌长度对各指标的影响
由图2可以看到,随着词令牌长度的增长,攻击成功率、句子多样性有所提升,但是召回率和可召回数目有所降低。当句子中词的数量越来越多的时候,初始化矩阵更加倾向于优化为真实触发器中较长的句子,导致召回率和召回数量减少,也导致预测触发器都是接近那些较长的句子,即句子相似度提升,多样性减少。
此外,还可以发现当词令牌数量为15时,大部分预测字符串的攻击成功率都比较低,而当词令牌数量为45时,大部分的攻击成功率都较高。这说明当句子中能容纳的词更多时,模型能更好地学习到输入字符串和输出字符串之间的关系,从而在输入字符串中能容纳触发器的概率也就越大。
3.2 探究最近邻数量的影响
最近邻数量是指被优化的词嵌入向量最相似于真实存在的词嵌入向量的个数。k的取值分别被赋予1,3,9,15,得到的实验结果如表1所示。

表1 最近邻数量对各个指标的影响
可以发现,当k升高时,攻击成功率先增加后降低。由于PEZ在优化过程中存在误差,原方法中选择最接近的词嵌入点不一定就是最优点,最优点可能是第二或者第k接近的点,所以本文将方法改良后,可以提升预测触发集的攻击成功率。当k值过大时,此时有概率取到相似度较低的点,导致成功率下降。
同时,预测触发集中句子的相似度随着k值的增大呈下降趋势。很容易理解的是,当一个句子中每个词可以取得,即候选词数量增多时,这个句子的多样性也就会变大。实验中相似度降低不太明显,是因为实验时采样的数量不够。
3.3 探究噪声规模的影响
噪声规模是指初始化待优化矩阵的缩放范围,其值越大,表明矩阵中元素的值差距也就越大。Noise_Scale的取值可以是1,0.1,0.01,0.001。实验所得的结果如表2所示。

表2 噪声规模对各个指标的影响
由表2可知,随着噪声规模的细化,攻击成功率先增大后减小。可以理解的是,当噪声规模过大时,优化得到的部分词令牌处在真实词令牌的边界,甚至远离真实的词令牌,导致近似得到的词令牌其实并不最优。而随着噪声规模的减小,近似得到的词令牌越密集,一开始可以很好地得到真实触发集中的词令牌,直到最后预测词令牌分布很密集,导致根本无法拟合到真实触发集中的部分词令牌,使得攻击成功率下降,也导致句子中可以选择的词令牌数量减少,使得多样性降低。
召回率的变化则是先减后增再减。推测是广布的词令牌能够近似到的真实的词令牌的数量较多,很可能能得到真实触发集中的词令牌。而当词令牌分布越来越密集时,有两种作用因素:第一是某个分布范围很接近真实触发集中词令牌的分布,使得召回的词令牌数增多;第二是密集的词令牌分布能接触到的真实的词令牌越来越少,导致召回率的下降。
4 讨论
4.1 探究更多影响因子
本文在探究基于梯度优化的后门识别影响因子时,只考虑了与PEZ方法有关的影响因子,这些参数在大部分使用同样原理的方法中也同样存在,只是其他方法中还存在它们独特的影响因子。
在GBDA方法中,有一个比较重要的影响因子,即Gumbel_Softmax中τ的渐变取值[15],该影响因子的不同取值将会决定最终得到的概率分布,比如τ的取值越大,得到的概率分布就会越均匀。而概率分布本身决定了预测字符串中会选择哪些词,所以对后门识别结果的影响还是极大的。
在UAT方法中,也存在类似于PEZ中TopK的影响因子即候选数目(num_candidates)[11],它决定了词嵌入向量搜索的范围,对后门识别的表现效果以及寻找触发器的速度都有影响。一般候选数目越多识别效果可能越好,但是所消耗的时长会迅速增多,通常情况下需要做两者的均衡,故该影响因子也值得去详细探究。
4.2 数据局限性
本文使用的数据集和模型都是比赛主办方提供的,其中模型的后门注入程度可能随着微调的程度变化,当模型在毒化数据集上微调次数不多时,真实的触发器仍能够产生100%的攻击成功率,但是很多基于梯度的后门识别方法寻找真实的触发器字符串将会变得困难,从而产生的预测触发器质量较差。一个可能的原因是这种情况下存在很多的局部最优点,许多方法会陷入在优化的局部最优点中,参考文献[16]给出的方法则尝试跳过局部最优点,再去优化以进一步降低损失,可以达到一定的效果。
实验使用的模型为1.6b,不具备很多大模型都有的特殊能力(比如推理能力等),故不适用于一些特别的下游任务。数据集上,字符串的种类、长度、复杂度比较单一,只能用于特定的领域,且有些触发器字符串设置本身就没有逻辑,不太容易在日常生活使用时被触发。可以通过修改数据集和加大要注入后门的模型尺寸来缓解上述问题。但是进行这些改进会有更多的难题需要解决,比如怎么利用大模型的上下文能力触发后门、怎么在保证触发器的隐蔽性的前提下修改数据集,这都是后续需要探讨的问题。
4.3 PEZ方法改进
本文认为PEZ方法本身存在较大的缺陷,它并没有结合真实存在的词去做优化,而仅仅考虑优化之后去找最相近的词,这就会导致PEZ优化得到的部分词嵌入向量可能和真实的词嵌入向量距离较远。
图3是利用t-SNE[17]绘制得到的有关部分词嵌入的散点图,其中三角形的点表示优化得到的词令牌,星形的点表示对应的点积相似度最近的真实词令牌,圆形的点表示真实的词令牌。可以观察到PEZ方法优化得到的词令牌有部分脱离了真实词令牌的区域,即有部分优化得到的词向量其实不能对应到真实的词向量,但最邻近算法会强迫它们找到一个或几个真实词向量进行替换,由此产生了极大的误差,这可能限制了它在后门识别任务中的表现上限。

图3 词嵌入散点图
5 结论
本文实验探究了基于梯度优化的后门识别重要方法PEZ中影响因子的设置对识别效果的影响。从实验结论可以发现,单一地调节某一个影响因子确实可以使某个指标有所提升,但也可能会带来另一指标的下降,要想取得在综合表现上的最高点,需要同时调节多个参数并且取到适中的值。同时,PEZ方法在优化中进行替换梯度的操作会引入误差,从而降低后门识别的表现效果,未来研究会在此方面寻求改进。
猜你喜欢
小猕猴学习画刊·下半月(2022年2期)2022-04-16
无线互联科技(2020年11期)2020-12-01
网络安全技术与应用(2019年7期)2019-12-24
电子制作(2018年18期)2018-11-14
计算机工程(2018年8期)2018-08-17
作文·初中版(2015年10期)2015-10-26
汽车维修与保养(2015年2期)2015-04-17
汽车维护与修理(2015年7期)2015-02-28
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
