
融合协议信息的TOR匿名网络流量识别方法
2024-01-10 04:00张娇婷汪俊永
网络安全与数据管理 2023年12期
杨 刚,姜 舟,张娇婷,汪俊永,王 强,张 研
(1.三六零数字安全科技集团有限公司,北京 100020;2.中国科学院信息工程研究所,北京 100093;3.中国科学院大学 网络空间安全学院,北京 100049)
0 引言
随着信息安全和个人隐私保护越来越受到人们的关注,在网络服务中,保护网络用户的隐私成为研究人员关注的重点。因此业界设计了许多匿名通信技术。TOR网络是目前最广泛使用的匿名网络之一,其主要功能在于保护用户的网络隐私并增强互联网访问安全性。
TOR的电路由三个中继服务器组成,分别是入口中继服务器用于客户端通信,转发中继服务器用于加密与转发,出口中继服务器用于与目的地通信。同时TOR采用标签交换设计,允许在同一个TOR路由器上复用多个电路,以确保每个电路都能获得合理的带宽分配。然而,在TOR上应用程序流量的分布在所有电路上是不均匀的,为此Tang等人[1]提出了一种电路调度优先级方案,使交互电路在批量传输电路之前进行优化。
随着TOR网络的迭代,其产生的流量的隐匿性变得更强,TOR流量变化更大,其中2021年发布的v3版本中,TOR流量变化更加显著,导致以往TOR的流量识别方法逐渐失效。
本文针对TOR检测方法失效的问题,自动化提取多版本TOR网络流量数据,对TOR行为及OBFS4混淆协议特点进行研究,提取了TOR行为的关键特征,并将其与OBFS4协议特性相结合,显著提升了对混淆协议下TOR流量的检测能力。最后通过大量实验验证了本文所提方法的有效性和实用性。
本文主要贡献如下:
(1)通过对OBFS4混淆协议进行分析,挖掘协议在握手等阶段的协议特点,与流量行为特征相结合共同作为特征向量,增强模型对TOR流量的检测能力。
(2)以业界通用流量行为特征为基础,结合TOR流量行为分析结果,采用随机森林和shap[2]工具特征选择的方法筛选关键行为特征,提高模型计算效率。
(3)通过模拟真实用户的行为,构建了包含复杂业务场景的TOR数据集。通过融合协议特征以及行为特征,提高了模型对TOR流量检出的准确率,而且验证了对TOR多个历史版本的流量具有很好的检测效果,证明了本文方法在TOR流量检测任务中具有普适性。
1 相关工作
目前TOR流量识别工作主要分为两种,一种是TLS模式的TOR流量研究,另一种是混淆协议下的TOR研究。
早期研究集中于TOR的TLS模式研究,并取得了一定的进展,He等人[3]提出了一种基于HMM的方法,该方法从流中提取突发流量和方向,并利用HMM构建不同应用类型模型,最终达到了92%的检测准确率。Lashkari等人[4]提出了ISCXTOR2016数据集,并从数据集中提取了23个基于时间的特征。采用Cfs-SubsetEval + BestFirst (SE+BF)和Infogain+Ranker (IG+RK)组合算法将特征数从23个减少到5个。这些特征输入到不同的机器学习算法(ZeroR,C4.5和KNN),结果表明C4.5是最佳的分类器。Rao等人[5]提出了一种引力聚类算法(Gravity Clustering Algorithm,GCA),用于高精度地识别TOR数据包,该研究数据集来自数据平台[6],模型引入数据包长度分布特征。结果表明GCA在数据集上的准确率为80%。Liu等人[7]使用间歇流量模式(Intermittent Traffic Pattern,ITP)检测加密网络流量中的视频流量相关特征,这项工作使用ITP和KNN区分视频和非视频流量。Abe等人[8]首次尝试将深度学习算法用于指纹攻击,提出一种使用堆叠去噪自编码器(SDAE)发起指纹攻击的方法,最后得到结果的准确率为88%。Wang等人[9]提出目前网站指纹攻击的局限性,并运用数据集更新、网页分割、去噪声等方法增加指纹攻击的实用性。马陈城等人[10]提出将爆发流量特征作为指纹攻击特征,该方法在模型分类测试中展现了高达98%的准确率。张道维等人[11]提出将匿名通信数据映射成RGB图像,使用残差神经网络构造分类模型,最后模型准确率达到97.2%。蔡满春等人[12]利用序列到序列模型生成流特征,采用自适应随机森林算法作为分类器,模型识别率达98%。Attarian等人[13]提出了自适应在线指纹识别流处理方法实现网站的动态识别。Elike等人[14]针对UNB-CIC数据集分别使用了SVM和DNN神经网络两种算法进行检测,通过比较,在检测非TOR流量的任务中,神经网络对TOR流量检测效果优于SVM。Johnson[15]、Lin[16]和Finamore[17]在ISCXTOR2016数据集上,优化了编码器段的性能,并比较了传统机器学习算法和深度学习的检测结果,最后得出随机森林和决策树的方法,要优于其他深度学习和机器学习模型。综上,TOR的TLS模式的流量研究已经相对成熟,并且达到了相对较高的准确率,但这些方法针对混淆协议模式下的TOR流量效果不佳。
近期的研究则集中于混淆协议下TOR流量的研究,何永忠等人[18]提出一种基于云流量混淆的TOR匿名通信识别方法,检测TOR的meek混淆协议产生的流量,采用SVM算法实现云流量混淆TOR流量识别。但是基于meek混淆协议的TOR流量稳定性较差,已逐渐被弃用。Jia等人[19]提出了一种改进的决策树算法TOR-idt,将TOR分层分类并在混合流量中识别出TOR流量。Rimmer等人[20]收集了包含300万条流量的数据集,并使用CNN、SDAE、LSTM对数据集分类,实验的准确率为96%。Zhang等人[21]提出了时空特征对网络流量分类,通过改进预处理的方法在CNN和LSTM模型中得到更好的实验结果。Li等人[22]提出AttCorr深度学习模型,将原始流量特征作为输入使用多头注意力机制捕获特征中涉及的流信息和TOR中噪声的复杂性质。席荣康等人[23]提出了一个基于自注意力机制的TOR检测模型SA-HST,联合了CNN和LSTM作为时空特征的提取模型,结果表明TOR的识别准确率达到96%以上。使用时空特征的方式虽然有较高的准确率,但是泛化性较差,针对早期的TOR流量,不能完成准确的识别。并且随着TOR项目的迭代发展,混淆协议也不断变化,使得以往的模型准确率不高。由于混淆协议插件随着TOR网络的发展不断变化,有些已被淘汰,而有些则尚未完全成熟。其中,OBFS系列已经发展到第四代,即OBFS4。He等人[24]针对OBFS4协议的流量设计了基于两级滤波的流量检测方案,删选掉干扰流后根据时序特征进行模型检测。但没有针对混淆协议的特点做有效识别。而Liang等人[25]关注OBFS4混淆协议特点,提出Weighted SVM模型,并利用动态特征作为模型输入进行检测,在OBFS4混淆协议下的TOR流量检测任务中达到准确率94.34%。但其协议特点仍不够充分,并且没有关注到TOR流量的行为特征。
本文通过分析提取流量行为特征,保留流量关键行为特征,并深入分析OBFS4混淆协议的特点,在行为特征基础上融合混淆协议特征,从而增加模型对TOR的识别能力。
2 流量分析与特征提取
TOR自提出以来,版本经过多次变化,在2021年3月发布的TOR浏览器版本中,主要采用OBFS4协议来实现加密和匿名化。因此,在TOR流量检测任务中,增加OBFS4协议特征是非常重要的。
2.1 OBFS4混淆协议
TOR主要支持TCP协议流量,且每条TOR通信均需经历TCP握手过程。本文深入分析发现,OBFS4 在TOR数据包的结构和内容上引入混淆,显著提升了流量对检测机制的抗性。具体来说,OBFS4协议改进椭圆曲线加密算法,对数据包全部内容进行加密,并采用随机填充的方式,使数据包长度不再有规律,能够抵抗大部分以数据包长度作为动态特征的检测模型。
2.2 OBFS4握手阶段
TOR流量在TCP握手之后会马上进行OBFS4握手,OBFS4的握手过程如图1所示。
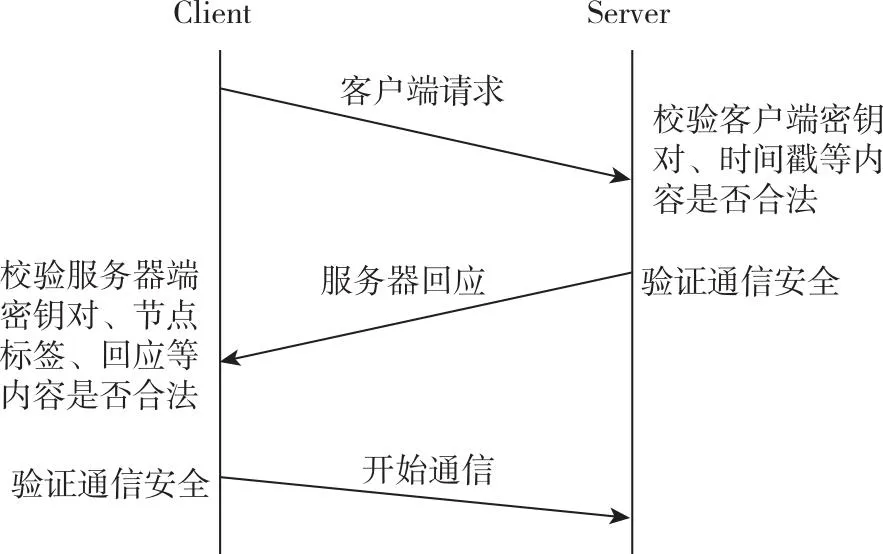
图1 OBFS4握手过程
本研究集中分析了TOR流量中的前2 000个数据包。研究首先排除了那些载荷为空的数据包,其次通过深入分析发现,OBFS4的握手过程实际上始于TCP握手阶段的结束,此时客户端向服务端发起请求。基于这些观察,本文在判断过程中考虑了诸如传输方向和PSH字段等因素。研究将OBFS4的握手过程划分为三个阶段进行详细讨论:
第一阶段:客户端向服务端发送请求,在流量传输方向变换之前,如果客户端发送的最后一个包含有psh字符字段,标志第一阶段结束。
第二阶段:服务端向客户端进行回应,传输方向由服务端变为客户端方向,在流量传输方向变换之前并且最后一个包含有psh字符字段,标志握手第二阶段结束。
第三阶段:客户端向服务端发起通信,方向为客户端到服务端方向,如果客户端发送的最后一个包含有psh字符字段,标志第三阶段结束。
本文针对OBFS4握手的第一阶段和第二阶段同方向的流进行分析,发现TOR流在OBFS4握手的第一阶段的首包为满包;虽然OBFS4协议能够将载荷进行随机填充,但是随机填充的载荷大小有极值;每次方向发生改变的最后一个包含有psh字符字段。综上,本文通过对OBFS4混淆协议分析,根据协议特点提取协议特征。
2.3 特征提取
在以往研究工作中,大多数研究人员都是基于ISCXTOR2016数据集[4],通过CICflowmeter工具提取的83维特征作为输入特征[4,8,13,19],并根据特征训练流量识别模型。然而,这种方法存在两个主要问题:一是特征维度过多,并且其中有很多特征是无效特征,使得模型训练效率很低;另一个是,TOR网络为保障其正常运行而引入了混淆机制,当前TOR流量,主要由于外层嵌套了OBFS4混淆协议,与过去的流量特征显著不同,使得旧有的基于特征训练的模型难以准确识别现有TOR流量。鉴于此,本文提出了一种计算TOR特征重要性的方法,有效提取关键行为特征,并选取了top-42特征作为模型的输入,同时融合了OBFS4协议特征,从而显著提高了模型的识别准确性。
2.3.1 行为特征
本文首先通过CICflowmeter工具[4]生成83维广泛的行为特征,参考文献[9]使用随机森林计算特征重要性,并提取top-36的特征。特征重要性分布如图2所示。
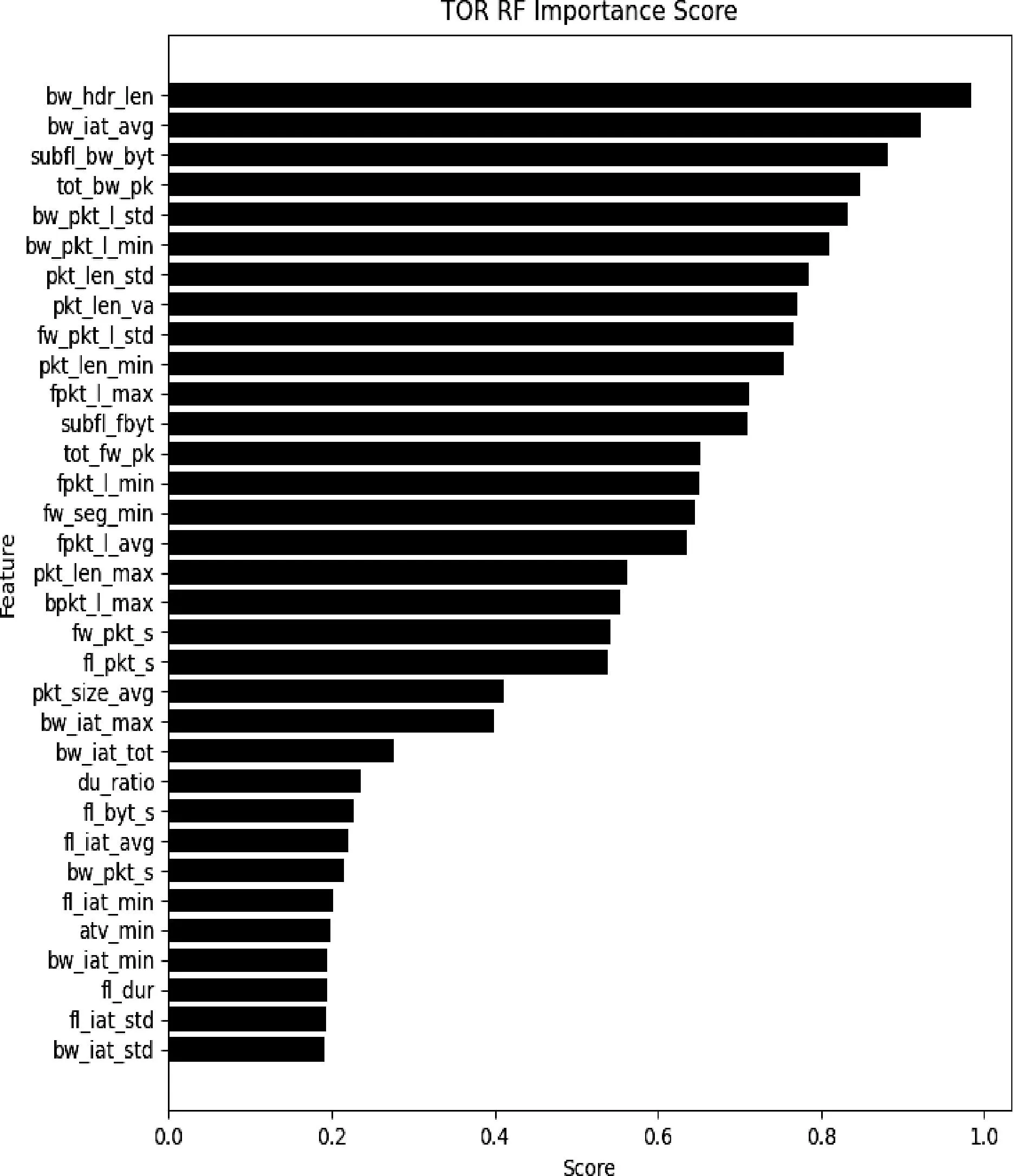
图2 随机森林提取特征重要性
使用随机森林提取特征的方式依赖于模型,在特征选取上有局限性,所以本文选择AI解释性工具的shap[2]工具,从以下角度制定特征重要性筛选方式,如表1所示。

表1 shap特征重要性筛选方式
将数据集分别通过表1所列5个重要性规则计算,得到5组不同特征重要性的结果,将5组特征重要性提取top-36的特征,结果取平均值,最后得到shap工具计算特征重要性结果,如图3所示。

图3 shap提取特征重要性
最后根据两组不同实验得到的特征重要性取并集,共得到42维有效行为特征,将这些特征作为行为特征输入到模型,能够帮助模型提高检测效率。
2.3.2 协议特征
根据2.2小节概述,提取OBFS4混淆协议特征需要对握手阶段进行识别。在握手阶段,根据包的方向以及psh字段,将OBFS4握手分为第一阶段和第二阶段。通过分析首包大小、第一阶段载荷以及第二阶段载荷得到OBFS4混淆协议下TOR流量的行为特征。同时,通过计算psh包数以及psh字段百分比,得到在协议影响下特殊字段特征。综上,本文提取的TOR协议特征如表2所示。

表2 TOR协议特征及描述
3 实验
3.1 数据集
TOR作为目前最流行的非法虚拟专用网络(Virtual Private Network,VPN)之一,相较之前其流量发生了很大的变化,而且公开数据集与目前混淆协议下的TOR流量相差较大,导致TOR流量的检测效果较差。因此,本文自主构建了丰富的数据集,并基于此进行实验,数据分为正常流量和加密流量两部分,其中,正常流量主要来自采集的现网数据,而加密流量除了基于人工采集的目前最新版本的OBFS4混淆协议(TOR Browser 11.5)TOR流量外,还采集了其他TOR浏览器历史版本(TOR Browser 7.0,TOR Browser 8.0.5)产生的TOR流量共8 GB,以验证检测模型的普适性。
本文选取10个代表性应用程序,如Facebook、YouTube、Gmail、WeChat等,收集的TOR浏览器流量包括用户聊天、邮件、页面访问的数据。采用自动化脚本采集数据的方法,包括浏览器随机访问页面,电子邮件随机发送内容,聊天包括文字、图片和文件等方式构建数据,以产生更加复杂的流量,并在时间上加以扰动,保障流量的真实性。最终本文共采集TOR流量30 GB,非TOR流量30 GB。数据集包含表3所示的6种TOR流量和非TOR流量。最后本文基于TOR的OBFS4混淆协议构建模型,训练集、验证集以及测试集比例为8:1:1。

表3 TOR网络流量数据集描述
3.2 评价指标
本文使用以下标准衡量算法效果:
(1)准确率:指分类结果中判断为TOR流的所有实例中,被正确分类为TOR流的实例所占的比例。其中判断为TOR流的实例包括实际为TOR流的实例总数和实际为非TOR流的实例总数。公式表示为:
(1)
(2)召回率:指分类结果中所有TOR实例被正确判定为TOR的百分比。所有TOR实例包括实际分类为TOR或非TOR流的实例总数。公式表示为:
(2)
(3)F1分数:通过准确率和召回率得到。其表达式为:
(3)
上述式(1)、式(2)中TP(True Positive)表示在分类结果中,将TOR流的实际实例数分类为所有TOR流的数量;TN(True Negative)表示在分类结果中,将实际为非TOR流的实例分类为非TOR流的数量;FP(False Positive)表示在分类结果中,将实际为非TOR流的实例分类为TOR流的数量;FN(False Negative)表示在分类结果中,将TOR流的实际实例数分类为非TOR流的数量。
3.3 实验结果与分析
为了验证本文提出方法的准确性和有效性,采用以下实验方法作对比和验证:(1)将CICflowmeter提取的特征称为原始特征,与增加了行为特征和协议特征的流量特征进行比较,以验证协议特征对模型性能的影响。并对行为特征融合协议特征与仅使用原始特征在不同模型下进行实验比较,验证特征提取的有效性。(2)与目前已有的OBFS4混淆协议的TOR检测方法(Liang[25]提出的动态特征实验)对照,验证本文结果的先进性。(3)通过不同版本的TOR流量输送到模型中进行检测,以验证模型的普适性。
表4包含使用多种机器学习、深度学习模型的对照实验结果,其中行为特征与原始特征的各项实验指标结果大致相同,使用行为+协议特征的结果优于原始特征,表明本文提出的行为特征与原始特征有大致相同的TOR流量特征表示能力,同时行为+协议特征比原始特征具有更强的表示能力。

表4 模型特征对比实验
表5表明通过丰富OBFS4的协议特征,TOR混淆协议检测任务的实验效果提升了2.39%。

表5 特征有效性实验
表6为不同版本的浏览器使用不同特征作为输入,在lightGBM作为模型的实验中的对比结果。通过结果可以看出,本文的方法能够准确地检测出不同版本的TOR浏览器产生的流量,证明了本文方法有良好的泛化性。

表6 TOR浏览器版本对比实验
4 结论
本文提出了一种TOR匿名网络流量识别方法,在特征提取过程中,为了提高模型计算效率,采用了随机森林和shap工具对原始特征进行优化,得到行为特征。同时,通过分析TOR流量以及OBFS4握手特点,本文提出了协议特征,并将行为特征融合协议特征输入模型。实验结果表明,融合协议特征方法对不同检测模型的检测结果有很大的改善,其中ligthGBM算法效果最好。同时,本文还收集了四个不同版本TOR客户端的流量,实验表明,针对不同版本的TOR浏览器,本文提出的行为特征融合协议特征依然能够准确检测出TOR流量,证明了本文方法的泛化性。未来还需要增强模型对抗噪声数据的能力,以适应互联网中流量复杂多变的实际场景。
猜你喜欢
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
出版人(2020年4期)2020-11-14
中国交通信息化(2018年5期)2018-08-21
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
电子测试(2018年10期)2018-06-26
