
基于动态均衡技术的海量异构数据高并发可靠接入方法*
2024-01-10 04:00周成胜靳文京刘晓曼王桂温
网络安全与数据管理 2023年12期
赵 勋,周成胜,靳文京,刘晓曼,王桂温
(中国信息通信研究院 安全研究所,北京 100191)
0 引言
随着计算机信息技术、互联网与物联网技术的快速发展,各类数据资源呈现爆发式增长,海量数据的产生和积累已成为一种不可避免的趋势。这些数据往往具有多源异构、分布广泛、动态增长等特点[1],如传感器数据、社交网络数据、视频数据等,称其为海量异构数据。在众多领域,海量异构数据并发接入已成为一个重要且具有挑战性的问题[2-4]。为了更好地管理和处理这些数据,需要研究和设计高效的数据并发接入技术和策略,以实现数据的快速处理、分析和应用。
在数据接入系统设计方面,已有研究人员在物联网、车辆交通、电网调度等领域分别对于物联网设备数据采集[5]、列车网络设备实时数据采集[6]、电网智能调度数据采集[7]进行了系统设计,用来解决海量数据接入处理问题,但是这些系统设计均是针对特定的业务场景提出,缺少一定的通用性。
在海量异构数据接入过程中,如何在高并发接入的场景下依然能够确保接入系统稳定可靠运行是数据接入系统设计面临的主要挑战。在有限的集群资源前提下,当海量异构高并发数据产生接入任务时,只有将接入任务合理分配并且快速执行,才能保证数据的顺利接入。相对于传统主从任务分配机制[8],去中心化的任务分配机制具有更好的健壮性;由于集群的计算节点和通信网络的异构性或共享性,使得难以事先进行计算负载和通信负载的估算,所以动态负载均衡策略更适合用来调整集群节点负载[9],最终确保集群节点资源能够得到高效的利用,达到海量数据的高并发可靠接入。
针对以上海量异构数据并发接入的问题,本文提出一种基于动态均衡技术的高并发海量异构数据接入方法。该方法采用去中心化的任务分配机制,并结合动态负载均衡技术,基于三层系统逻辑架构,实现了海量异构数据的高效采集接入。
1 系统架构
基于动态均衡技术的海量异构数据高并发可靠接入系统架构逻辑上分为三层,底部为异构数据源,其与数据采集层对接,数据采集层从数据源采集到相关数据后写入数据中心层,处理后供应用系统使用。逻辑架构如图1所示,各部分详细描述如下。
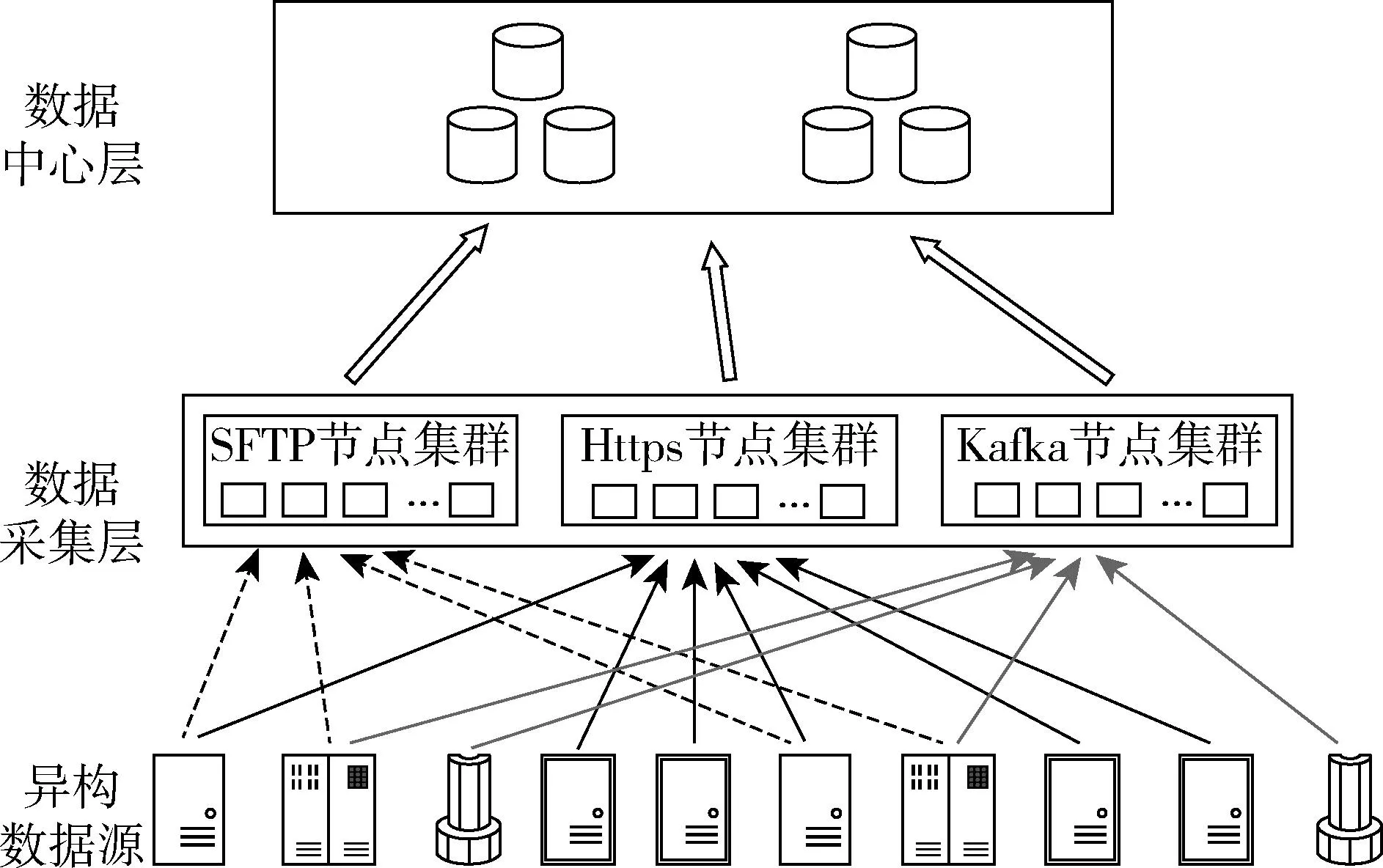
图1 系统逻辑架构图
异构数据源:海量数据的提供者,根据上层应用需求提供各类型数据,包括结构化、半结构化和非结构化等类型的数据,是数据采集层采集海量数据的源头。
数据采集层:根据所采集的数据特点和上层应用不同的需求场景,提供SFTP、HTTPS、Kafka等采集接口与数据源对接,数据接口方式由相应的采集节点集群完成,将海量数据从异构数据源采集成功后提供到数据中心层。
数据中心层:实现大数据的存储处理,采集来的各类异构数据根据结构化、半结构化及非结构化特点输入相应数据集群系统,供上层应用系统使用。
上述系统逻辑架构并非基于某种特定的场景设计,对于一般海量异构数据高并发接入场景具有一定的通用性。
2 接入方法设计
海量异构数据接入方法主要包括节点负载计算方式、去中心化的任务分配机制、节点分配及回收策略、动态负载均衡策略四部分内容。节点负载计算方式明确了每个节点负载程度的量化表达,是实现后续均衡调度的基础;去中心化的任务分配机制最大限度保障了集群执行任务的高可靠性;节点分配及回收策略使得计算资源得到最大限度的利用,能够有效应对高并发场景;动态负载均衡策略的设计从整体上对海量异构数据接入进行灵活调整。
数据采集层包括大量的采集节点,所有节点组成采集节点总池,所有节点逻辑上均等,均可执行不同类型采集接口任务,系统根据相关策略动态地将节点分配到SFTP、HTTPS、Kafka等节点集群中,并在运行中根据任务及负载变化对节点进行灵活调度。
2.1 节点负载计算方式
当采集节点投入使用时,要根据节点负载进行任务分配及节点调度。一般选择CPU资源、内存资源、当前进程数、响应时间等作为评价参数,全面衡量节点负载情况。
为了科学客观地计算节点负载,必须将以上参数组合成一个综合负载计算函数。常见的多指标组合方式有加权乘法及加权和法[10],前者适用于各指标不能互换,指标相互间强关联且具有同等重要性场景;后者适用于各指标相互独立,各指标对于整体的影响能够线性叠加,且指标间具备一定互补性的场景。
根据以上特点,本文采用了加权和法方式进行负载指标计算,将CPU资源、内存资源、磁盘资源、当前进程数、响应时间等重要信息作为计算公式的因子,每个因子对应一个可变系数Ri,其中∑Ri=1。
具体负载计算公式如下:
Loadnode=R1×Loadcpu+R2×Loadmem+R3×LoadI/O+R4×Loadpid+R5×Loadresp
(1)
其中,Load***依次表示为:节点总负载(Loadnode)、CPU使用率(Loadcpu)、内存使用率(Loadmem)、磁盘I/O访问率(LoadI/O)、进程总数(Loadpid)以及响应时间(Loadresp)。进程总数以及响应时间根据硬件条件百分比化处理,数值在[0,1]区间。Ri系数根据具体节点集群类型进行设置,比如SFTP集群中磁盘I/O访问率更加重要,故可以将对应的R3系数提高,而Kafka集群中CPU使用率和内存使用率更加重要,故可将R1与R2系数设置较高。
2.2 去中心化的任务分配机制
传统数据接入任务分配一般采用主从方式的任务分配机制,此机制存在一个专门负责分配任务的主节点,该节点掌控全局资源,负责分配任务并向执行节点下达相关指令[11]。当主节点失效时则启用备用节点进行任务分配。此种机制最大的缺陷是随着执行节点数量的增加,任务分配节点的负载会越来越高,在海量任务情况下可能达到自身性能极限,此时会严重影响到任务分配机制正常运转,而去中心化的任务分配方法比中心化方法具有更好的可扩展性。在本文方法中使用如下分布式任务分配框架,如图2所示。
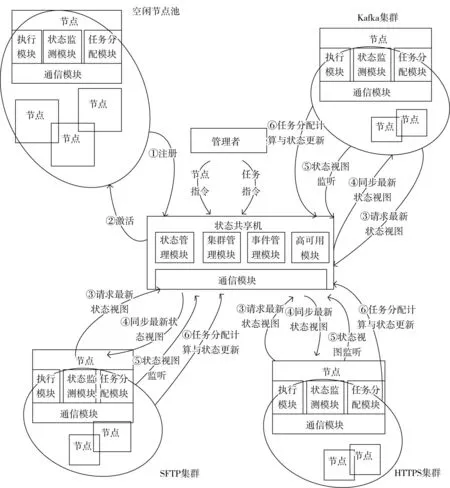
图2 分布式任务分配框架
管理者:通过状态共享机下达节点指令和任务指令,节点指令包括激活和停止节点,任务指令包括添加和删除任务。
状态共享机:提供共享机制,让各节点都掌握任务状态和集群情况。包括:状态管理模块,负责状态数据共享,维护状态视图;集群管理模块,对各集群进行管理,对节点进行调度;事件管理模块,负责处理对状态视图的监听请求以及状态视图变化时的事件流程;高可用模块,负责保障维护状态共享机的可用性;通信模块,负责底层通信。
节点:任务执行者,分属于空闲节点池、SFTP集群、HTTPS集群、Kafka集群。包括:任务模块,负责执行具体任务;状态检测模块,主要负责向状态共享机进行状态同步,更新本地任务视图;任务分配模块,按照一定算法对新进入任务进行计算,将任务分配到具体节点,同一集群内算法一致,同一任务无论在哪个节点上计算后得出的结果相同;通信模块,负责底层通信,进行数据同步。
具体任务分配机制描述如下:
(1)注册:节点有两种状态,即空闲(idle)和活动(active),新节点开始时皆属于空闲状态,在空闲节点池中,需要向状态共享机进行注册后方可承接任务。
(2)激活:节点注册后管理者可通过状态共享机下达激活指令,节点进入活动状态。状态共享机中集群管理模块按节点分配策略通知活动节点进入相关集群。
(3)请求最新状态视图:节点进入相关集群后,将向共享状态机进行状态视图同步请求。
(4)同步最新状态视图:状态共享机将最新状态视图发送给节点。
(5)状态视图监听:节点进入活动状态后将向状态共享机进行申请,对状态视图进行持续监听,状态共享机通过步骤(4)返回最新状态视图。
(6)任务分配计算与状态更新:节点获取最新状态视图后将任务分配模块根据统一算法进行任务分配计算(同一集群内分配算法与策略一致),若本节点为下一任务接收节点则主动进行标识,完成承接任务准备工作并向状态共享机更新状态视图。
2.3 节点分配及回收策略
采集节点总池中节点个数为Ctotal,设置高负载阈值为Loadmax,低负载阈值为Loadmin。
节点分配及回收策略如下:

(2)新增数据源接口采集任务时,根据采集类型将任务分配到相应节点集群,并根据动态负载均衡策略(见2.4节)确定承接任务的运行节点。当一个判断周期中某个节点集群中出现节点负载超过负载阈值Loadmax并持续超过TimeD时,则分配一个新节点进入相应集群中。
(3)当集群节点数量到达控制值(Sctrl、Hctrl、Kctrl,为相应初始值的200%)后,则只有当集群中50%的节点负载超过负载阈值Loadmax后才分配新节点。
(4)当集群节点数量超过控制值(Sctrl、Hctrl、Kctrl),且一个判断周期中集群内所有节点负载都不超过负载阈值Loadmax,同时最小负载节点负载小于80%Loadmax时,则对最小负载节点打上退出标识,不再对其分配任务,等已有的任务执行完毕后退出集群。
(5)当集群节点数量小于等于控制值(Sctrl、Hctrl、Kctrl),且一个判断周期中集群内所有节点负载都不超过负载阈值Loadmax,同时最小负载节点负载小于50%Loadmax时,则对最小负载节点打上退出标识,不再分配任务,等已有的任务执行完毕后退出集群。
(6)为避免节点回收速度过快,一个判断周期内同一集群只会有一个轻载节点退出,集群节点数量不会小于初始值(Smin、Hmin、Kmin)。
2.4 动态负载均衡策略
现有的负载均衡算法主要分为静态和动态两类。静态负载均衡算法以固定的概率分配任务,不考虑服务器的状态信息。动态负载均衡算法以服务器的实时负载状态信息来决定任务的分配。
静态算法实现较为简单且资源消耗较小,但不能根据系统的实际运行情况进行调整,为了更大程度地保证系统运行的灵活性与平稳性,本文采用了一种动态负载均衡算法,结合权重及负载计算的最小活跃数算法[12]。
最小活跃数算法会根据系统的实际情况进行分发,能够灵活检测出集群中各个节点的状态,自动寻找并调用活跃度最低的节点处理请求。每个服务都有对应的活跃数,初始情况下,所有服务的活跃数均为0。每进来一个请求,都把它分发给活跃数最低的服务,服务每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务处理请求的速度更快,因此活跃数下降得也越快,此时这样的服务能够优先获取到新的请求,这就是最小活跃数负载均衡算法的基本思想。
但是在典型的最小活跃数算法中,如果一台节点存在故障,导致它自身处理的请求数比较少,那么它会遭受最大的访问压力,这显然是并不合理的。因此本文对其进行了改进,加入了权重值和负载值两个参数,能够更好地选择合适节点。
设节点i的权重为Wi,当前判断周期内的负载为Loadi,当前真实活跃数为Ni。则改进后的活跃数N′i如式(2)所示:
N′i=(e[Loadi/K]+Ni)/Wi
(2)
其中K为负载档位系数,其与具体节点性能和平均任务消耗有关,本文取K=0.1。
具体策略的执行步骤如下:
(1)先从状态共享机中获取该集群所有的节点实例状态,计算改进后的活跃数N′i,然后找出活跃数最小的节点。
(2)如果只有一个,那么则直接选中对应的实例节点处理本次请求。
(3)如果存在多个,则根据当前判断周期内的负载为Loadi进行比较,选中负载较小的节点。
(4)如果Loadi也相同,那么则选择i较小的节点提供服务。
3 实验与分析
3.1 实验环境
出于方便性考虑,本文采用云环境来进行模拟实验。共准备130台云主机,所有节点都是2核8 GB内存,100 GB SSD,2 Gb/s内网带宽。其中30台作为采集集群,100台作为数据源集群。
数据源集群中仅提供单一SFTP、HTTPS、Kafka数据的节点各15台,同时提供两类数据的节点各10台,同时提供三类数据的节点25台,以模拟复杂的数据采集条件。
采集集群则分两次分别模拟使用本文方法的正常环境和使用传统方法的对照环境。由于使用云主机,必要时两套环境可以使用快照方式进行快速切换部署。
对照环境中SFTP、HTTPS、Kafka采集集群均衡分布,分别为10:10:10,其中任选两台同时作为主备任务分配节点。
正常环境中SFTP、HTTPS、Kafka集群的初始节点分别为3台、4台、3台。剩下节点放入空闲节点池。
本实验正常环境中各集群负载计算的可变系数R1~R5设置如表1所示。

表1 可变系数初始化
负载阈值设置:Loadmax=95%,Loadmin=50%;节点数量设置:Smin=3,Hmin=4,Kmin=3,Sctrl=6,Hctrl=8,Kctrl=6;高负载持续时间TimeD=10 min。
3.2 测试及结果分析
测试时不断增加采集并发连接数,但三类数据源并发连接数增长速度不同,分析使用本文接入方法的系统运行情况与传统采用最小连接数算法、加权轮询算法的系统运行情况,对比平均响应时间及单位时间所接受的有效数据总量。
为了模拟真实采集情况,测试场景中数据并发连接数不是纯线性增长,单个连接可能在完成了设定随机传输总数据量后结束,也可能是达到某个传输时间后结束。但整体增长比例事先约定,最终达到10 000并发连接总数。每个场景有3轮测试,每轮测试持续时间12 h,SFTP、HTTPS、Kafka数据源并发连接数增长比例分别为1∶1∶1,3∶1∶1,1∶2∶4。为了避免单个数据连接占用大量带宽,在发送端采用了一些限速手段,使单数据连接速度最大不超过10 Mb/s。
图3~图5分别是以上不同增长比例条件下三种场景的平均响应时间。平均响应时间越短说明了负载均衡越有效。

图3 数据源连接增长比例1:1:1下三种场景平均响应时间

图4 数据源连接增长比例3:1:1下三种场景平均响应时间
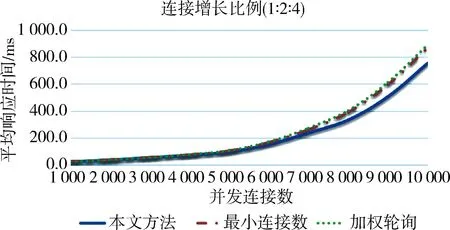
图5 数据源连接增长比例1:2:4下三种场景平均响应时间
图6~图8分别是以上不同增长比例条件下三种场景的单位时间接收的有效数据总量。数据总量为整个采集集群1 min内接收的3类不同数据累加所得。
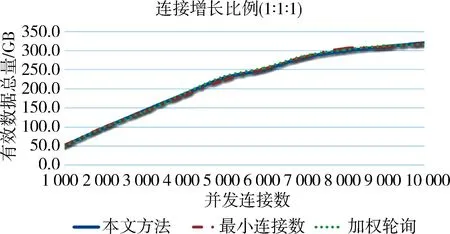
图6 数据源连接增长比例1:1:1下三种场景接收有效数据总量
由图7、图8可见,在连接数超过4 000之后,本文方法逐渐占优;但超过8 000后,传统方法有效接收数据总量曲线又向本文方法曲线靠拢,这是因为本测试环境中在大连接数条件下所有采集节点网络吞吐量基本已趋近物理接口上限。

图7 数据源连接增长比例3:1:1下三种场景接收有效数据总量

图8 数据源连接增长比例1:2:4下三种场景接收有效数据总量
从以上结果可以看出,轻载时本文方法与传统方法性能接近。重载时,若传统方法中预分配的节点池比例和数据源实际情况比较接近,则本文方法与传统方法差距很小;若传统方法中预分配的节点池比例和数据源相差较大,则本文方法具备明显优势,平均响应时间较小,而单位时间接收数据量更大。
最终可以得出如下结论:除非能正确预判各类数据源比例并根据此比例来设定采集节点,否则在海量异构数据源采集中本文方法比传统方法具有更大优势。
4 方法分析
本文方法根据实际场景设计相关策略、算法及机制,相对于业界常用方法具有较大优势。
节点负载计算的目的是准确判断节点负荷,是节点精确调度的基础。业内常用的方式有直接使用单一指标的做法,比如直接调用CPU负载值,这样虽然比较简单直观,但不能完全反映节点负荷情况,因为很多情况下虽然CPU负载低但可能网络负载、硬盘负载较高,实际上节点无力承受更多任务。业内也存在使用加权乘法组合多指标的做法,但是这种方式适用于多个指标间互相关联度高的场景,本文中采用CPU资源、内存资源、当前进程数、响应时间等评价参数,各参数相互独立,具备互补性,故采用加权和法公式,并根据节点具体用途设置权重,从而精确判断负载情况。
传统方法中的任务分配机制一般采用主从分配节点方式,正常情况下由主用节点负责任务分配,主用节点失效后转由备用节点负责。此方式缺陷,一是主用节点在任务繁重时会比较重载,可能超过设备极限;二是主备节点切换时存在切换失效的可能,从而造成主备双活情况,这时主备节点中的任务状态不同步可能导致整个机制崩溃。本文中采用去中心化的任务分配方式,任意节点都可进行任务分配,通过状态共享机进行同步,整个系统具备良好的扩展性和健壮性。
传统方法中的节点池很多采用预分配方式,此时节点不能在各池中调度,无法高效率对硬件资源进行利用,可能存在相当大比例的资源浪费情况。本文中根据阈值动态分配及回收节点到不同集群中,运行效率更高也更灵活。
业界方法很多采用静态负载均衡策略,如轮询及根据硬件配置采用加权轮询方式,此种方式虽然实现较为简单,但由于未考虑节点的状态信息,可能导致将任务分配给重载或失效节点的情况。业界方法中也有根据单一指标反馈进行动态负载均衡的策略,如最少连接数、最快响应速度、最小活跃数等策略,但单一指标并不能完整反映节点实际情况,存在分配错误的可能。本文中采用了结合权重及负载计算的最小活跃数算法,通过多个维度全方面考察节点实时负载,最大程度地保证了负载均衡的准确性。
5 结论
本文针对海量异构数据接入的挑战和现有解决方法的缺陷,提出了一种基于动态均衡技术的海量异构数据高并发可靠接入方法。文中详细介绍了该方法的体系结构和实现细节,包括节点负载计算方法、任务分配机制、分配与回收策略和动态负载均衡策略等。该技术具有重要的实际应用价值,特别是在大数据领域中,能够更好地应对海量异构数据的高并发访问需求,并提高数据接入的可靠性和效率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学教学研究(2022年5期)2022-04-28
当代陕西(2019年14期)2019-08-26
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
中学数学杂志(初中版)(2016年5期)2016-11-01
通信电源技术(2016年6期)2016-04-20
浙江大学学报(工学版)(2015年2期)2015-05-30
