
弹性自组织多集群管理系统设计与实现
2024-01-10 04:00夏令明
网络安全与数据管理 2023年12期
夏令明,周 俊,赵 锋
(网络通信与安全紫金山实验室 未来网络研究中心,江苏 南京 211111)
0 引言
单Kubernetes[1]集群无法满足边缘、地域、资源管理等需求,因此在东数西算等典型多集群场景中[2],将不得不解决集群的接入控制、集群资源抽象、权限管理、应用管理、多集群调度、服务维持、多租户以及多集群服务发现等问题[3-5],这大大增加了多集群方案的复杂性和难度。目前社区和业界,集群拓扑均以父子两层架构为主,父集群作为主控集群,其余集群为子集群,用于承载工作负载,其中主流的有Kubefed[6-7]联邦方案、Karmada[8]、Clusternet[9]、Admiralty[10]四种。
Kubefed和 Karmada是一类,它们通过Template、Overide、Propgation 等定义负载的通用配置、专有配置和调度策略。Karmada 自Kubefederation发展而来,但是支持更丰富的插件化调度能力以及多集群服务(Multi cluster service)等特性,Karmada 也顺利成为CNCF基金会孵化项目。但是这二者仅支持中心式的两层架构,扩展性和承载力都存在理论瓶颈。
Clusternet 项目是一个践行了OCM模型的多集群方案,也入选了CNCF沙箱项目,子集群通过受控的Token,在子集群启动时,接入到父集群之中。父集群通过Aggregated API的方式对所有原生Kubernetes资源进行转义形成Manifest文件推送到子集群中,Clusternet 同样只能支持两层架构,也存在上述扩展性的问题。
Admiralty 是一种多层调度模型,它达到了在使用多集群时和单集群一样的体验,特点是把负载依赖根据Pod 跟随调度,支持软件定义搭建多集群架构,但对应用没有做任何抽象,所有的概念都是Kubernetes原生的。Admiralty在分布式云场景中难以实现应用的有效管理与维护。
以上四种方案,前三种无法实现多层自组织架构,这无法满足扩展性要求,而东数西算等真实的组织架构一定是分层的。Admiralty 没有对应用做抽象,只能基于Kubernetes 的调度框架去改造。为解决这些问题,本文提出了一种弹性的可自组织的多集群管理方案Gaia。
1 Gaia分布式云方案的设计
1.1 分布式云系统设计需要解决四个核心问题
(1)集群组织层级灵活多变
集群组织关系,即集群之间的关联关系,也即它们是如何被组织在一起的,常见的模型有中心式、分布式、树状等。
(2)应用描述复杂
应用如何被抽象至关重要,它决定了调度的最小单元以及如何看待应用负载,例如Clusternet中的应用是Subscription,Admiralty的应用就是原生Pod。
(3)不依赖集群层级的调度器设计
调度器的设计依赖于集群组织模型,两层架构的模型调度器就要求每层不同,但如果是N层模型,调度器就应该输入输出一致,这样才能保证集群组织的灵活性。
(4)跨集群服务快速准确发现
应用被多集群部署后,需要快速准确地实施服务访问,目前多集群方案均以集成为主,比如Admiralty集成了GSLB;早期Kubefed自研的Multi-Cluster Ingress DNS,后续陆续移除,并改为集成社区其他多集群服务发现的方案比如Istio;Karmada和Clusternet社区均集成Multi Cluster Service。
本文针对上述的第(1)、(3)个问题,提出弹性自组织的集群管理方法和多集群场景下的幂等分层调度方案。
1.2 概念
(1)集群关系
从软件定义的理念出发,定义一个文件来描述集群两两之间的从属关系,如图1所示。其中Target描述了父集群的访问方式和加入集群所需要的Bootstap Token。这样可以将集群组成所期望的任意结构。需要说明的是,集群之间可以是双向的,也可以是指向自己的。
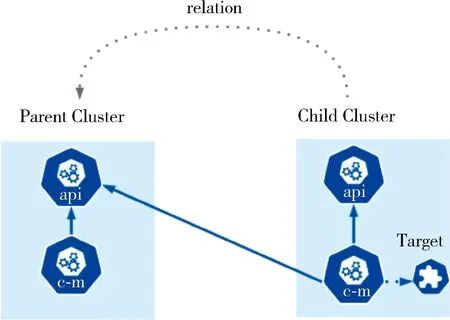
图1 集群关系图
(2)常见拓扑结构
①主备模式
主备模式中,子集群的Target指向父集群,同时父集群的Target 也指向自己,如图2所示。这种模式可以将应用天然地配置到两个集群中,是一种非常简单的高可用模式,适合规模很小的环境,配置简单。
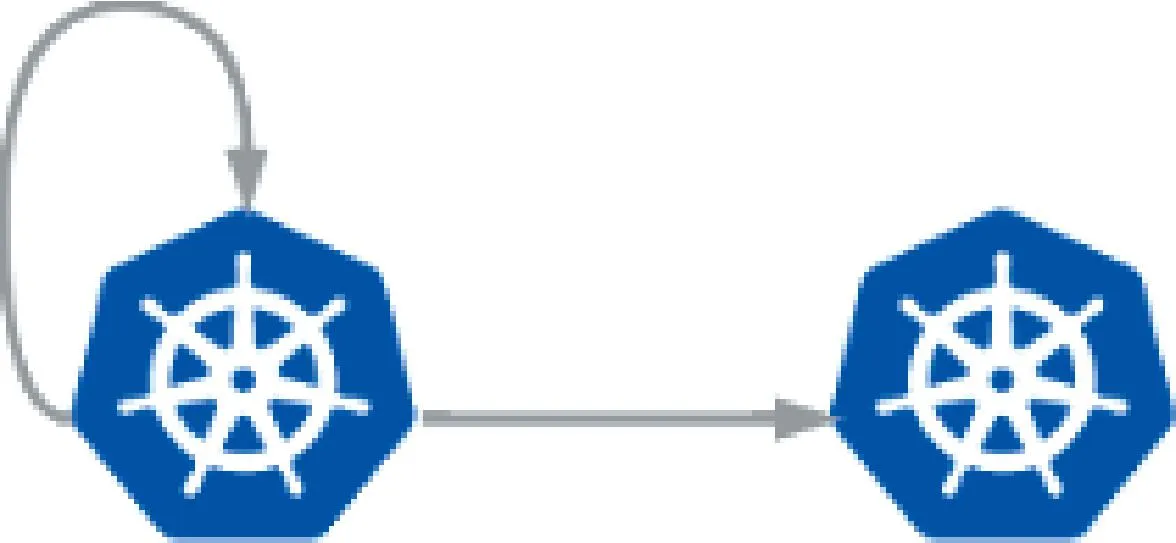
图2 主备模式
②去中心化模式
该模式中,所有的集群既是父集群又是子集群,如图3所示。这种去中心化的结构中,集群是Peer-to-Peer的关系,相较于主备模式该结构具有更强的稳定性和安全性。

图3 去中心化模式
③中心式模式
这种方式有一个父集群做主控集群,托管N个子集群,如图4所示。它适合中等规模的基础设施环境,层级较少,管理简单,但是拓展能力有限。

图4 中心式模式
④树状模式
集群间根据Target 的指向,组成一个有层级的树状结构,如图5所示。该结构适用于“云边端”的复杂场景中,依靠幂等的分层调度器,可以轻松管理多云多厂商组成的大型且高复杂度的集群结构。
(3)幂等的分层调度器
在管控分布式云基础设施时,无论采用哪种拓扑模型,Gaia控制器都不区分自己是什么位置。调度器的设计也必须坚持输入输出一致,这样带来的好处是,集群间的结构可以随时变化,当有新的集群加入时,自己变成了父节点,但是它同时又是其他集群的子集群,所以每一个集群的组件都是一样的。
1.3 Gaia分布式云调度设计
Gaia的控制面由Scheduler 和 Controller两部分组成,如图6所示。它的每一层集群所关注的资源只有输入和输出两部分,其中调度器的输入和输出类型一样,都是一种叫做APP的CRD资源,经过调度以后APP中会附加更详细的调度结构信息。需要说明的是,在叶子集群上的调度器不对APP做任何调度处理,因为最底层的调度逻辑交给Kubernetes。
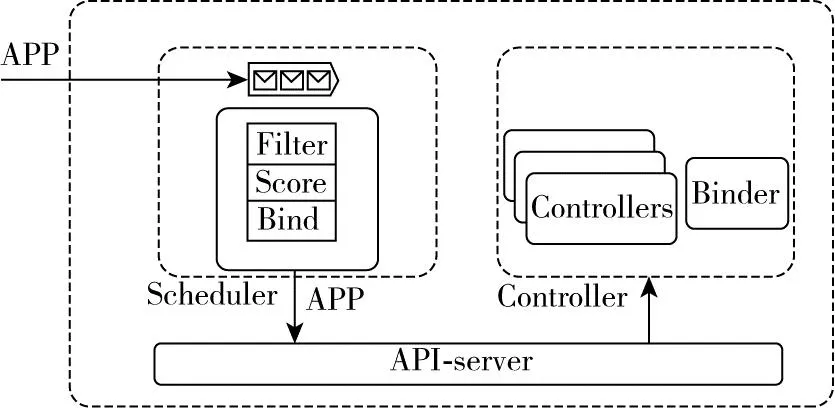
图6 Gaia控制面图
(1)Scheduler:只会把资源调度在注册到自己的子集群中,所有调度器输入和输出都是APP。
(2)Controller:控制器包括集群注册控制器、注册审批控制器、状态上报控制器、MCS(Multi Cluster Service)控制器等。
(3)Binder:仅在叶子集群发挥作用,当Binder发现APP调度成功且没有子集群的时候,就把调度结果绑定到本集群。
2 方案功能实现
2.1 集群接入
叶子集群只用于承载工作负载,并不需要对外暴露公网地址,集群均为主动接入,资源同步采取Pull的模式。Gaia会被安装在每一个集群中,等待Target资源指示如何接入Field集群,其接入过程如图7所示。

图7 集群接入
(1)子集群Gaia组件启动后,循环等待Target对象部署,期间不影响集群功能;
(2)部署Target对象后,本集群发起集群注册过程,注册为目标集群的子集群;
(3)在Parent Cluster创建命名空间(Namespace)、访问规则(RBAC)、访问账户(SA)、集群管理资源等,由Parent Cluster进行集群注册审批;
(4)子集群持续等待审批结果,审批通过后便可拿到相应父集群的访问权限,注册为子集群。
一个典型的Target对象如表1所示,它包含父集群的地址、接入时的BootStrap Token以及本集群在父集群中的名字和一些其他信息。

表1 Target 对象
2.2 集群资源统计
集群接入后,子集群会根据上一步中Target配置的“reportFrequency”定时上报本集群的资源使用情况和结点的标签汇总,这些信息被称作Scheduler Cache。
2.3 APP资源调度
以三层的树状模型为例,每一个子集群在父集群中存在一个执行命名空间,在父集群接收到调度任务以后,会根据子集群上报的Scheduler Cache做基于水位的副本调度,每一级调度器都会经历一系列插件,如图8所示,不同层的插件没有依赖关系。
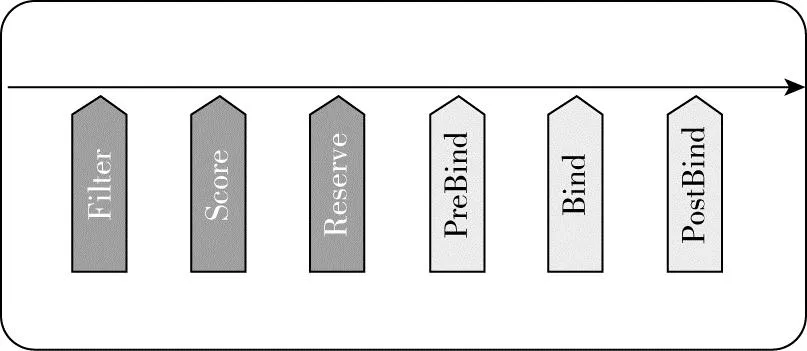
图8 APP调度插件图
完整的调度流程如图9所示,在Binder判断自己不存在子集群的时候,就会把本集群的调度结果推送到本集群,Binder的绑定过程比较简单,不再详述。

图9 Gaia系统架构图
该调度器的优点是:
(1)调度速度快,每一层都只负责自己当前层的调度;
(2)资源可以无限拓展,管理海量集群;
(3)拓扑结构灵活改动,应对多变的基础设施;
(4)调度插件灵活可配。
缺点是资源上报信息粒度大,且没有预占,集群高负载情况下会存在调度失败的情况。
3 试验验证
基于以上描述,对集群注册、分层调度器进行验证。本文借助Kind工具部署1个Global集群、2个Field集群,每个Field下部署60个Cluster集群,搭建一个多集群的树状集群网络的复杂基础设施计算平台,如图10所示。
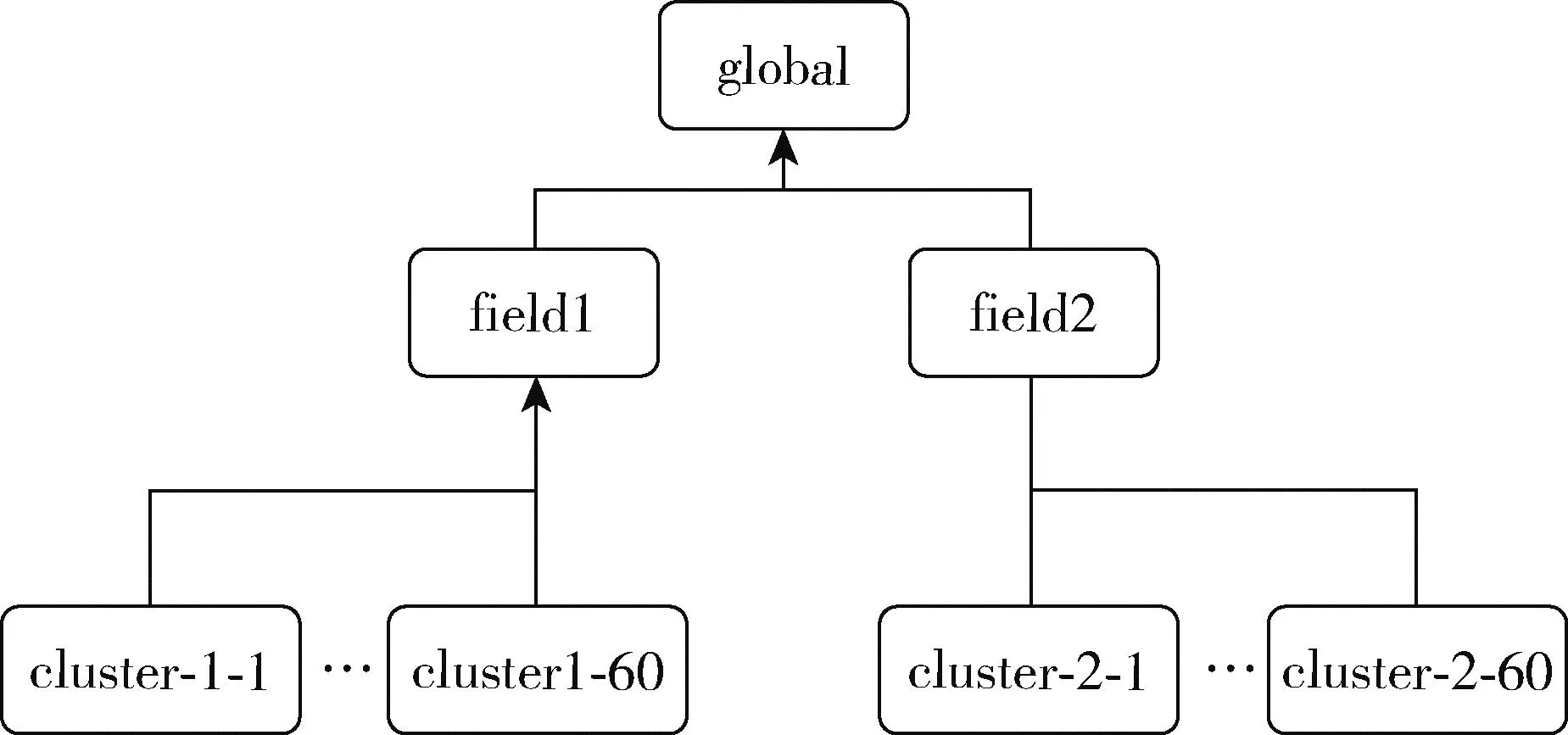
图10 树状集群网络结构
(1)集群准备
创建Kubernetes集群,在每一个集群上部署Gaia组件,这些Gaia组件还没有通过Target资源去指定集群间关系,此时每一个集群都处于等待状态。
(2)制作并创建Target
不同的集群依据Target对象文件,将本集群注册为其他集群的子集群,其具体参数如表1所示。更改表中的“clusterName”为本集群提供唯一的注册集群名称;使用父集群的“parenturl”和“bootstraptoken”用于确认接入父集群的地址。
(3)集群状态
除Global集群外,其他集群按图10所示通过部署Target接入父集群,可以在各层查看管理的集群。集群注册时延如图11所示。在已有126个集群的规模下,集群的注册延迟保持稳定在1 s。

图11 集群注册时延
作为对比,Karmada 方案做两层集群管理模型时,其P50即中位数集群接入时间为5 356 ms[11],本方案的集群注册时延迟稳定为1 012 ms。
(4)执行案例调度
在Global集群上部署应用,其应用调度时延如图12所示,在126个集群的规模之下,应用平均调度延迟不高于200 ms,这里不包含资源创建的时间消耗。
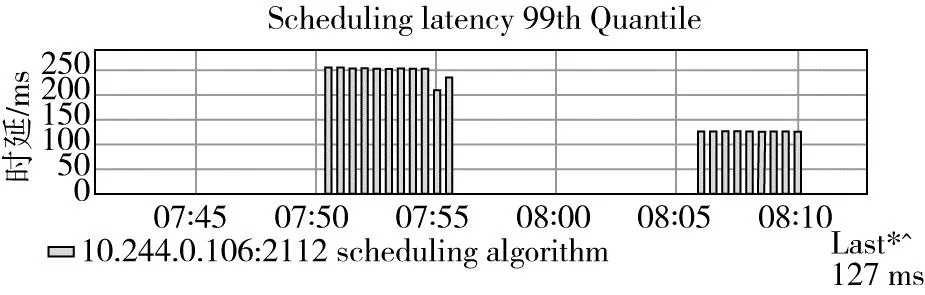
图12 应用调度时延
作为对比Karmada 的测试报告中提到,资源分发的用户在联邦控制面提交资源模板和下发策略后到资源在成员集群上被创建的P99时延,不考虑控制面与成员集群之间的网络波动,P99≤2 s。
最后在Cluster级别集群上进行应用的绑定部署,提供相应服务。
4 结束语
本文分析了目前分布式云/多集群领域的研究现状,并剖析了热门开源社区的相关项目的特点,进一步归纳总结了分布式云系统设计面临的4个核心问题。针对这些问题,提出了一种多层级、可软件定义的多集群管理方案。它的每层调度逻辑都是幂等的。通过实际模拟126个超大规模的集群环境,验证了该方案的可行性,试验结果表明这种方案理论上可以无限扩展集群连接,同时保持应用调度和集群扩展的延迟保持在合理可用范围,是东数西算等分布式云场景下的一种理想架构。
然而,多集群调度平台不仅仅需要关注集群资源管理、负载调度的效率等问题,还要考虑应用抽象、多集群服务发现、多集群负载均衡等问题,目前这部分有一些解决方案,比如sigs/mcs-api、GSLB、Submariner等项目,后续工作需要继续研究创新,使Gaia多集群方案功能得到进一步完善。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
电信科学(2017年6期)2017-07-01
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
雷达与对抗(2015年3期)2015-12-09
