
基于深度学习的遮挡情形下行人检测
2024-01-12 10:02庞丁黎夺实祥伟杨舒舒秦君
云南电力技术 2023年6期
庞丁黎,夺实祥伟,杨舒舒,秦君
(云南电网有限责任公司德宏供电局,云南 德宏 678400)
0 前言
据统计,大约80%的人从外部世界中获得的信息都是来自于视觉,所以,视觉信息在人们获得信息中扮演着非常重要的角色。同时,伴随着科学技术的持续发展,人们需要利用现有的技术,来帮助人们完成某些视觉任务,从而使计算机视觉这一领域成为了当下的一个研究热点。
在计算机视觉领域中,行人检测属于一个重要的研究领域,它主要是通过使用图像处理和机器学习的方法,来对图像中的行人展开定位,并对每个行人目标的大致位置进行精确的预测。一个较为精确的行人检测模型,是后续图像智能分析(行人目标跟踪,识别,检索,匹配等领域)的先验条件。所以,它的应用领域非常广泛,包括:军事领域、视频监控与安防领域、无人驾驶领域、搜索营救领域[1]。
2005 年,Dalal 等通过对行人区域进行分割,并通过对其局部区域进行梯度直方图的统计,得到了行人边缘的轮廓信息。自HOG(High Theoretical Graph,简称HOG)特征被提出以来,已有不少学者在此基础上对其进行了改进。为了提高梯度直方图的检测效率问题,Zhu 等人[2]采用积分图的形式加速梯度直方图的计算。Yangwei Pang 等人通过对局部窗口重叠区域的特征利用,避免了梯度直方图在特征选取的时候重复计算问题,将检测时间缩短为原来的1/5。2008 年Felzenszwalb 等人[3]基于图结构,提出了可形变部件模型(Deformable Part Model,简称DPM),该模型主要包括根模型和部件模型两部分。该模型将整体和局部信息结合在一起。根模型在低分辨的特征图上捕获整体轮廓,部件模型在高分辨率的特征图上捕获细节部分,将二者进行融合得到最终的结果。2010 年,Felzenszwalb 等人[4]在原有可形变部件模型的基础上,融入了视觉语法和多个视觉角度,采用一组混合模型,能够更好的处理人体的形变问题。目前可形变部件模型已成为众多分类器、分割、人体姿态和行为分类的重要部分。然而在可形变部件模型的检测算法中,算法的时间主要消耗在部件和图片匹配过程以及最优部件位置的选取与计算上,Felzenszwalb的模型在当时的时间复杂度上并不理想,因此,Felzenszwalb 在可形变部件模型的基础上提出了级联检测,使用主成分分析法对特征进行降维,提高了整个算法的速度。
随着深度学习技术的不断发展,行人遮挡检测进入了第二阶段,使用深度学习方法进行检测。2009 年Piotr Dollar 等人[5]开源了Caltech数据集,从而为行人遮挡检测在深度学习领域的发展提供了更多的高质量的行人训练数据集,为近年来深度学习在行人遮挡检测领域的发展奠定了基石。2017 年 Shanshan Zhang 等人[6],对于Cityscapes 数据集进行了重新标注并且开源了Citypersons 数据集,与此同时对于Faster RCNN 进行了改进,使其更有利于行人遮挡检测任务,使用该方法进行行人遮挡检测成为近几年行人遮挡检测领域的基准线。2018 年行人遮挡检测领域有了迅猛的发展,Chunluan Zhou等人[7]提出了在模型训练的时候, 将可见框和全身框同时进行训练,这两个部分相互影响,从而降低在遮挡条件下漏检率。Xinlong Wang 等人提出了Rep Loss,降低了密集场景下行人的漏检率。
从国内外的研究现状分析,不管是基于传统的机器学习方法还是基于深度学习方法对于行人遮挡检测这一领域仍存在很多的不足,还需要加以研究。
1 行人检测理论
行人检测指的是以行人为对象检测的主体,对输入图片中是否含有行人进行判断,如果图片中有行人,就将其位置框出来,反之,则会忽略该图片。但在行人检测中,遮挡是一种很普遍的现象,其根本原因在于摄像机与移动物体的视角不同,即摄像机与移动物体的视角不同,所以,在现实生活中,遮挡现象普遍存在。由于人体局部被遮挡,导致对人体进行识别时,往往会出现漏检的情况。
基于机器学习的方法是现阶段行人检测算法的主流,主要运用特征提取和分类任务两个模块[8]来进行检测图像或视频帧中的行人。特征提取部分主要是获得边缘特征、颜色特征、纹理特征等行人外观特征和深度语义特征信息,然后把这些特征运用于训练分类器,将背景和行人目标两个类别进行高效地辨别并输出分类结果。最后对输入的测试图像进行检测,若存在行人目标则输出其预测框,如图1 所示。
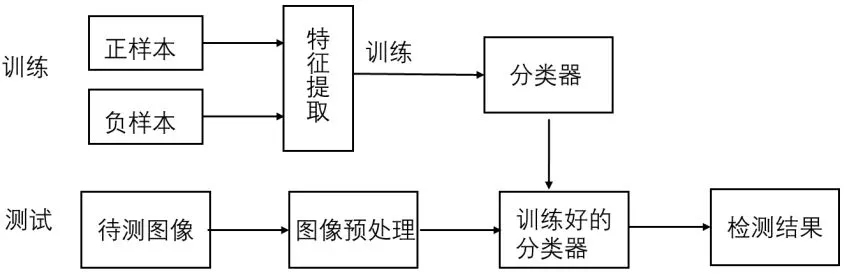
图1 行人检测流程
目前基于深度学习的目标检测算法,比如说Faster RCNN,YOLO V3,SSD,RetinaNet等算法,对于非遮挡场景,也就是整张图片中完整的行人目标有较好的表现,但是在遮挡场景下效果就变得很差,如图2 所示,我们可以看到由于行人之间遮挡会导致目标检测算法会产生漏检现象。相比于完整的行人目标,检测器难以提取遮挡行人的特征,从而导致检测结果变差。综上所述,行人遮挡检测是行人检测领域当中的难题之一。这也是本文主要的研究内容。

图2 行人之间遮挡导致漏检效果
行人遮挡检测主要分为2 种情况:如图3左图所示表示物体对于行人的遮挡,如图3 右图所示表示行人与行人之间的遮挡。对于一般的目标检测算法,在被遮挡的行人场景中表现良好,但是在被遮挡的行人图像中很容易产生漏检现象。
图4 深度置信网络结构
在实际安防场景中,遮挡问题主要出现在行人密集场景,行人与行人之间的遮挡出现的频率远远大于物体对于行人的遮挡。因此本文主要解决行人与行人之间的遮挡的问题,经过实验发现,本文算法不仅仅可以减少因为行人与行人之间的遮挡而产生的漏检,而且还可以减少因为物体对于行人遮挡而产生的漏检。
2 基于深度学习的遮挡行人检测
基于深度学习的遮挡行人检测算法主要分成3 种类别:
1)基于深度置信网络(DBN);
2)基于卷积神经网络(CNN);
3)基于循环神经网络(RNN)。
基于深度学习的算法对遮挡处理主要有两种方式:
1)引入部件模型,通过深度学习网络结构和部件模型的相结合,综合处理遮挡;
2)基于优化函数,通过优化损失函数对遮挡进行处理。
2.1 基于DBN的检测算法
基于深度置信网络的检测算法是基于深度置信网络(Deep Belief Network,DBN)进行建模,能够有效地识别和定位输入图像中的目标物体。深度置信网络是一种多层前馈神经网络,它通过对多个无监督层进行训练来提高学习性能。这种网络通常由多个限制玻尔兹曼机(Restricted Boltzmann Machine,RBM)组成[9],每个RBM 都包含一个可见层和一个隐藏层。RBM 的学习过程是通过无监督的方法进行的,即网络根据训练数据自动学习每个RBM 中的参数。深度置信网络通过逐层训练每个RBM 来进行训练,从而实现了对高层特征的自动提取和学习。
在基于深度置信网络的检测算法中,首先通过将输入图像传递给深度置信网络来提取特征。然后,通过添加全连接层和输出层,将网络转换为分类器,用于对输入图像中的目标进行识别和定位。深度置信网络的主要优点在于它能够有效地学习图像中的高级特征,因此在处理复杂图像时比传统的检测算法表现更好。此外,深度置信网络还可以通过微调来进一步提高性能,这种微调技术利用大量标记数据来对网络进行训练,从而实现更好的分类和检测。
虽然基于深度置信网络的检测算法在实际应用中表现出了良好的性能,但它们也存在一些局限性。例如:
1)训练数据量的要求较高。基于深度置信网络的检测算法通常需要大量的训练数据来获得良好的性能。这可能会限制它们在某些应用场景下的效果,特别是在数据量较小的情况下;
2)训练和调试过程相对复杂。由于深度置信网络的复杂性和训练过程的非监督性质,这种算法的训练和调试过程相对复杂。这使得它们可能需要更多的专业知识和技能来使用和优化。
3)可解释性较低。由于深度置信网络的复杂性和非线性性质,它们通常比传统的检测算法更难解释。这可能会限制它们在某些实际应用场景中的使用,例如医疗诊断或法律审查等需要对决策过程进行解释的场景。
4)对计算资源要求较高。基于深度置信网络的检测算法通常需要大量的计算资源来进行训练和推理。这可能会限制它们在某些低成本或低功耗设备上的应用,例如移动设备或嵌入式设备。
5)对数据质量的要求较高。由于基于深度置信网络的检测算法通常需要大量的训练数据,因此数据质量对它们的性能至关重要。如果训练数据中存在噪声或错误标注,可能会导致算法的性能下降。
总之,基于深度置信网络的检测算法是一种非常有前途的技术,它在图像处理和计算机视觉领域具有广泛的应用前景。通过不断地改进和优化,这种算法有望在未来实现更好的性能和更广泛的应用。
2.2 基于CNN的检测算法
基于卷积神经网络(如图5 所示)的检测算法是一种应用深度学习技术进行目标检测的方法。它使用卷积神经网络(Convolutional Neural Networks,CNN)来对输入图像进行处理和分类,从而实现对目标的检测和识别[10]。

图5 神经网络结构
基于卷积神经网络的检测算法有如下优势:
1)特征提取能力强。卷积神经网络具有非常强的特征提取能力,能够从输入图像中提取出高层次、抽象的特征,这些特征可以用来区分不同的目标类别。卷积神经网络的卷积层和池化层结构可以有效地捕捉不同尺度和方向的特征。
2)鲁棒性好。基于卷积神经网络的检测算法对图像中的光照、尺度、姿态、遮挡等变化具有很好的鲁棒性,能够处理各种复杂的场景。
3)可扩展性强。基于卷积神经网络的检测算法能够轻松地应用于多类别目标检测、实时目标跟踪等任务中,并能够通过添加更多的卷积层、池化层或全连接层等进一步提升其性能。
4)训练效率高。基于卷积神经网络的检测算法使用反向传播算法进行训练,相较于传统的机器学习算法,其训练效率更高。同时,由于CNN 可以直接使用图像作为输入,因此无需进行繁琐的特征提取过程,也降低了训练的复杂度。
5)实现方式多样。基于卷积神经网络的检测算法有很多不同的实现方式,如Faster R-CNN(见图6)、YOLO、SSD 等,这些算法都可以根据不同的需求进行定制和改进。

图6 R-CNN算法结构
虽然基于卷积神经网络的检测算法具有许多优点,但也存在一些不足之处。
1)目标定位精度。基于卷积神经网络的检测算法在目标定位精度上仍存在一定的局限性。尤其是在目标大小不一的情况下,算法可能难以精确地定位目标,这可能会导致误判和漏检。
2)目标多样性。基于卷积神经网络的检测算法往往只能检测出一类或少数类目标,对于目标种类较多的情况,可能需要训练多个不同的模型进行检测,这会增加算法的复杂性和成本。
3)训练数据量。基于卷积神经网络的检测算法需要大量的训练数据才能获得良好的性能。对于某些应用场景,如医学图像分析等,数据采集难度较大,可能会影响算法的性能。
4)运算速度。虽然基于卷积神经网络的检测算法可以通过GPU 等硬件加速来提高运算速度,但仍存在一定的计算复杂度,可能无法满足实时性要求较高的应用场景。
总之,基于卷积神经网络的检测算法在实际应用中具有一定的局限性,需要在算法设计和应用场景选择上进行综合考虑。在未来,随着技术的不断发展和数据资源的不断积累,相信这些不足之处也将会逐步被克服。
2.3 基于RNN的检测算法
基于循环神经网络(RNN)的行人检测是计算机视觉领域的一项重要研究。RNN 是一种能够对序列数据进行建模的深度学习模型(见图7)。在行人检测任务中,RNN 可以通过对序列数据进行处理和判断,来实现对行人的检测。RNN 是一类以序列数据为输入,在序列的演进方向进行递归并且所有节点(循环单元)按链式连接的递归神经网络。其中双向循环神经网络(Bidirectional RNN,Bi-RNN)和长短期记忆网络(Long Short Term Memory networks,LSTM)是常见的循环神经网络。
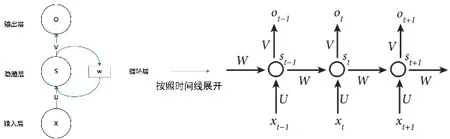
图7 循环神经网络结构
传统神经网络将原始图像作为输入,网络的复杂程度导致学习时间较长,影响检测器的性能。崔鹏等提出DSAEN(Deep Sparse Auto-Encoder Network),在输入晨后加了一层感兴趣县,提取出充分表示行人信息的混合特征,在处理神经网络复杂的运算问题时,该算法将通过网络得到的特征输入到线性核函数的SVM分类器中进行训练,并采用非极大值抑制法,降低计算量,能够对行人的位置进行精确定位。Stewart 等人提出了一种由over feat 模型改进而来的方法,如图8。该方法将图像解码成一组人体检测器,使用一个循环的LSTM 层进行序列生成,并使用一个新的提夫函数,同时结合定位和检测两方面对模型进行端对端训练。同时也证明了可以利用LSTM 单元链将图像内容解码为可变长度的相干实值输出,是一个分部处理遮挡的新思路。

图8 LSTM结构
在RNN 模型中,输入序列的每个时间步都有一个对应的隐藏状态。这个隐藏状态是在模型学习过程中动态生成的,可以捕捉到输入序列中的长期依赖关系。对于行人检测任务,输入序列通常是由视频帧组成的。RNN 模型的核心是循环层。在循环层中,RNN 会根据当前时间步的输入和上一个时间步的隐藏状态,计算出当前时间步的隐藏状态。这个隐藏状态可以看作是对前面所有时间步的信息进行了聚合。由于循环层的结构,RNN 能够捕捉到输入序列中的时序信息,对于行人检测任务尤为重要。
在行人检测任务中,RNN 通常被用于序列建模,即将输入的视频帧序列转换为输出的序列,其中序列中的每个元素代表当前时间步是否存在行人。为了实现这个目标,通常需要使用卷积神经网络(CNN)来对每个视频帧进行特征提取,然后再将提取出的特征作为输入序列,传入RNN 模型进行处理。基于RNN 的行人检测模型通常需要经过大量的训练才能达到较高的准确率。在训练过程中,需要使用大量的数据对模型进行训练,并对模型进行不断的优化。同时,也需要对模型进行调参,以达到最佳的性能。
总的来说,基于RNN 的行人检测是一项具有挑战性的任务,需要对深度学习模型有深入的了解,并在实践中不断探索和优化。
3 结束语
基于深度学习的遮挡情形下行人检测是计算机视觉领域中一个重要的研究方向,旨在解决现实场景中行人被遮挡的情况下的检测问题。近年来,随着深度学习技术的发展和硬件设备的不断升级,基于深度学习的遮挡情形下行人检测已经取得了显著的进展。首先,可以通过训练大规模的数据集来学习遮挡情形下行人的特征,进而提高检测的准确性和鲁棒性;其次,一些基于深度学习的方法采用多尺度的特征提取方式和级联式的检测网络,可以有效地提高检测的速度和效率;此外,一些基于深度学习的方法还将注意力机制和目标跟踪技术等引入行人检测中,进一步提升了检测的性能和鲁棒性。
基于深度学习的遮挡情形下行人检测在未来仍有较大的发展空间和应用前景。首先,随着深度学习技术的不断进步,基于深度学习的方法在检测的准确性、鲁棒性和速度等方面都将得到进一步的提高;其次,随着自动驾驶、智能监控等领域的发展,基于深度学习的遮挡情形下行人检测将在未来扮演着越来越重要的角色,成为保障交通安全和提高智能化程度的关键技术之一。同时,随着物联网和云计算等技术的不断发展,基于深度学习的遮挡情形下行人检测也将得到更加广泛的应用和普及,包括城市交通管理、公共安全监控等领域。
综上所述,基于深度学习的遮挡情形下行人检测是一个充满挑战和机遇的领域,需要不断探索和创新,才能不断提高检测的准确性、鲁棒性和效率,为人类社会的发展做出更大的贡献。
猜你喜欢
中国毕业后医学教育(2021年3期)2021-12-02
中国毕业后医学教育(2021年3期)2021-12-02
北京航空航天大学学报(2021年9期)2021-11-02
陶瓷学报(2021年2期)2021-07-21
意林(2021年5期)2021-04-18
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
