
基于可变卷积与迁移学习的小样本检测方法
2024-01-18 10:23宋程程高晓利赵火军
火力与指挥控制 2023年12期
宋程程,李 捷,高晓利,王 维,赵火军
(四川九洲电器集团有限责任公司,四川 绵阳 621000)
0 引言
目标检测是计算机视觉的基础任务之一,主要任务是对图像中的目标进行分类和定位。在实际应用中,如防灾减灾、大区域监控、国防等领域,由于被观测物体距离较远,待检测目标在图像中所占像素点少、信噪比低,表现为弱小目标状态。传统的检测识别技术难以从复杂背景中提取其色彩、纹理、形状等特征,识别难度较大。近年来,深度学习在目标检测领域中取得了卓越进展,在某些分类、检测领域的能力甚至超过人类。但是在很多情况下,可获取数据量极少,导致深度学习模型性能欠佳。基于此,开展小样本目标检测方法研究,对于国防和民生领域都具有重要的现实意义。
目前,大多小样本目标检测方法是基于传统目标检测方法结合小样本学习的思想进行研究,旨在通过少量标注样本学习具有对新类的检测能力[1]。LSTD 在模型层面结合了Faster RCNN 和SDD 的优点,提出知识迁移正则化和背景抑制正则化两种方法,促进知识从源域转移到目标域,增强模型对小样本数据的泛化能力[2-4]。Meta R-CNN 元学习通道式注意层,用于重塑RoI 头部[5]。FSIW 通过在平衡数据集上进行更复杂的特征聚合和元训练,改进了Meta-R CNN[6]。RepMet 将基于距离的小样本学习思想引入,构造原型度量网和检测模块,提取图像的嵌入特征并使用欧式距离计算进行检测[7]。文献[8]探索不用对象类别内在的通用特征,提出了通用原型,减轻了不平衡对象类别的影响。FSCE 将对比学习引入小样本目标检测中,更有助于对象分类[9]。Meta YOLO 将元学习策略与重加权模型融合,将支持集特征以通道相乘融合到查询集特征,但是这种方法需要额外的分支,计算复杂度增加[10]。MPSR 设计了一个特征金字塔模块生成多尺度特征,并在不同尺度上进行细化,但其网络构造复杂,且细化分支需要手动决策,推广性受限[11]。相对于其他小样本检测方法,基于模型微调的方法TFA 通过对在目标域中训练的模型使用少量新类进行微调即可进行检测,是一种既简单又高效的方法,在不增加算法复杂度的基础上仍能获得相对好的检测性能[12]。
考虑实际应用中数据获取困难、背景复杂、目标弱小等情况导致的算法性能欠佳。本文基于迁移学习的两阶段小样本检测方法,提出了一种基于可变卷积与迁移学习的小样本检测方法,主要创新点有:1)提出了一种学习能力更强的可变卷积主干网,将可变卷积思想加入Resnet 网络中,使其在极少数据条件下也可以完成对样本的特征学习,提高算法的泛化能力;2)面对实际场景中可能存在的多目标重叠出现漏检情况,将改进的Soft-NMS 代替传统的NMS 降低漏检率。
1 本文方法
本文小样本检测任务的基本流程整体可以分为两步:1)模型在基类上的整体训练;2)在少量基类和新类上的对训练好的模型进行适当的微调,完成对新类和基类的检测。改进算法整体框架如图1 所示。
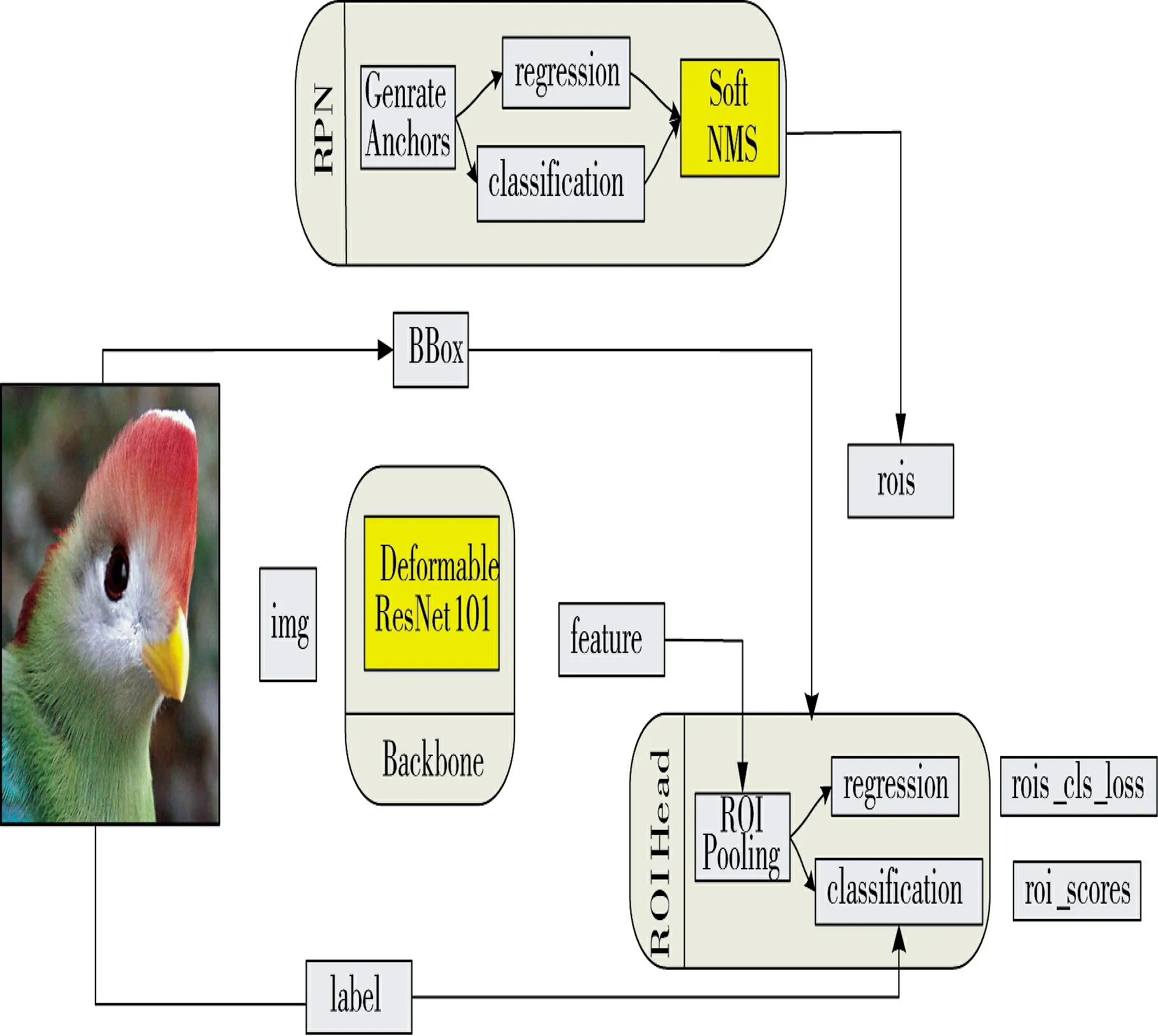
图1 改进算法网络架构Fig.1 Network architecture for improved algorithms
基础模型训练:本文选取双阶段的目标检测器Faster R-CNN 作为基本模型,算法的整体架构如图1 所示。首先输入基类图片,经主干网络提取特征图,然后将提取出的特征输入RPN 网络,生成一堆Anchor box,对其进行裁剪过滤,输出Bbox 边界框和类别分数。由RPN 输出的图像特征提取RoIs 传入网络,再经过RoI 池化进入全连接层输出,完成分类与回归工作,此时基础模型的训练完成。
模型微调阶段:数据包含少量的基类和新类图片,首先完成模型的参数初始化,然后固定网络的其余部分不变,对检测器的最后一层参数进行调整,同时引入余弦相似度分类器,使模型在具有对基类检测能力的同时也有对新类的检测能力。
2 基于可变卷积的特征提取主干网
传统的目标检测网络常使用VGG、Resnet 等作为主干网络模型对图像进行特征提取,但是这些主干网模块由固定几何结构组成,卷积单元在固定位置对输入特征图进行采样,在一个固定的层中,空间分辨率较低,缺乏处理几何变换的能力。为了解决这个问题,本文引入可变卷积的思想对主干网进行改进,增强对几何变换建模的能力,使其具有更强的学习能力。
可变卷积是在传统卷积的基础上,通过在模块中增加额外的偏移量来增大空间采样位置,使采样更灵活,并且可以在没有额外监督的情况下学习目标任务的偏移量[13]。两种卷积采样方式对比如图2所示,其中,图2(a)是传统卷积采样过程,图2(b)是可变卷积采样过程,可以看出增加偏移量后,可以更好地应对目标移动、尺寸缩放、旋转等情况。
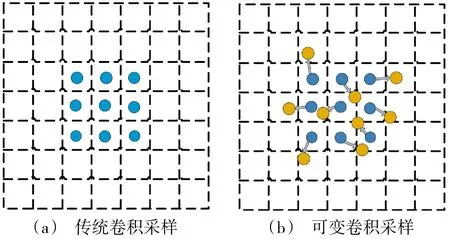
图2 传统卷积和可变卷积对比图Fig.2 Comparison chart between traditional convolution and deformable convolution
实际生活中很多物体的形状都是不规则的,如图3 中的自行车,此时对自行车的车轮进行特征学习,可以看出如果用传统的正方形卷积对其进行特征提取效果可能不好,此时,将传统卷积换成可变卷积的话,可变卷积会根据特征形状自动计算偏移量,实现在当前位置附近的随机采样。
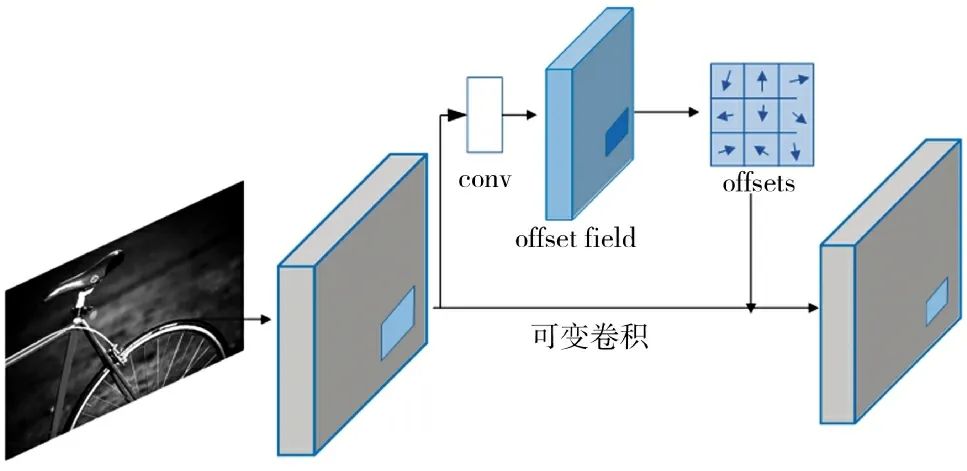
图3 可变卷积过程图Fig.3 Process diagram of deformable convolution
虽然传统残差网络在深度学习中表现很好,但是在小样本学习中,由于样本量少且图像形变大,直接应用此网络不能很好地从少量样本中进行学习,所以本文将可变卷积嵌入到Resnet101 的残差块中进行改进,如图4 所示,图4(a)是传统的残差块,图4(b)是加入可变卷积之后的残差块。可以看到基于可变卷积的残差网络增强模型的几何变换能力,获得更具“代表性”的特性。

图4 原始残差块与可变卷积残差块结构图Fig.4 Structure diagram of original residual block and deformable convolutional residual block
3 Soft-NMS
在实际应用场景中,待检测图像常常背景复杂、目标遮掩、重叠,此时使用传统的非最大抑制(NMS)方法会造成对多个有重叠目标的漏检,影响检测效果,本文提出使用改进算法Soft-NMS 代替传统的NMS 来提升算法对复杂场景下的检测性能,检测效果如图5 所示。
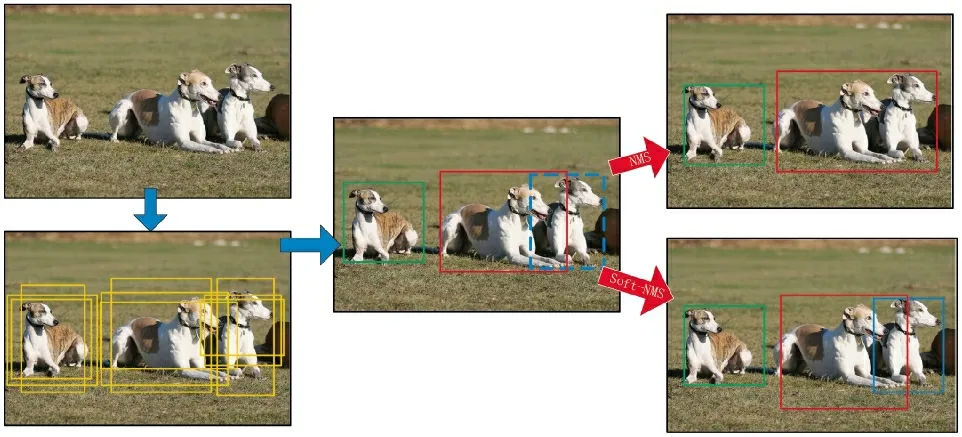
图5 NMS 与Soft-NMS 结果对比图Fig.5 Comparison picture of results between NMS and Soft-NMS
在传统检测算法的检测过程中,首先会对图片进行滑窗处理,然后得到一系列检测框B 和其对应的得分S,非最大抑制会对各检测框按从高到低的得分进行排序,然后得分最高的检测框M 被选中,将其放在最终检测结果集C 中,将其他与检测框M重叠部分大于一定阈值的检测框移除。例如,设定阈值为0.5,图5 中红色检测框与蓝色检测框的重叠>0.5,就将蓝色检测框剔除。如果一个目标处于预设的重叠阈值之内,就会导致检测不到该物体,造成有效信息的丢失,影响最终检测结果。
与NMS 对重叠预测框全部抑制不同,Soft-NMS主要是对一个与预测框M 有高度重叠的检测框B1的检测分数进行衰减[14]。同样对图中的情况,Soft-NMS 不会直接对蓝色的检测框进行抑制,而是会重新对其进行衰减计算检测框分数,设置一个置信度阈值,将小于阈值的剔除,蓝色检测框的得分大于阈值被保留,最后被成功检测出来,提升算法的性能。Soft-NMS 有线性计算和高斯计算两种方法,本文采用的是线性计算法。
4 试验结果与分析
本文所提出方法在公开数据集PASCAL VOC与多种先进方法结果进行对比分析,证明本文改进方法的有效性;在实测数据集上进行实验,证明算法的实用性。将原始算法记为TFA,基于Soft-NMS改进的算法记为TFA/soft-nms,基于可变卷积改进的算法记为TFA/DCN,基于Soft-NMS 与可变卷积改进的算法记为DS-TFA。
4.1 公开数据集实验及结果分析
本节实验在公开数据集VOC 上开展。VOC 数据集常用来衡量图像分类检测能力,由VOC2007 和VOC2012 组成,共包含20 个不同的类别,每个类别有600 张图片。按照前人工作中的设置[10],将其随机划分成包含大量实例的基类和仅有少量样本的新类,其中,基类包含15 个类别,新类包含5 个类别,用于微调的新类的样本数为K。
为了评估算法的鲁棒性,将VOC 数据集进行三切片,表1 展示了各改进方法与原算法、LSTD、Deformable-DETR-ft-full、Meta YOLO 和Meta RCNN在K 较少时对新类的检测结果,优于各改进方法的结果已加粗。表2 展示了各改进方法与原算法在VOC 不同切片上的检测结果,下页表3 展示了各改进方法与原算法在VOC 不同切片上对基类的检测结果,最优结果均已加粗。
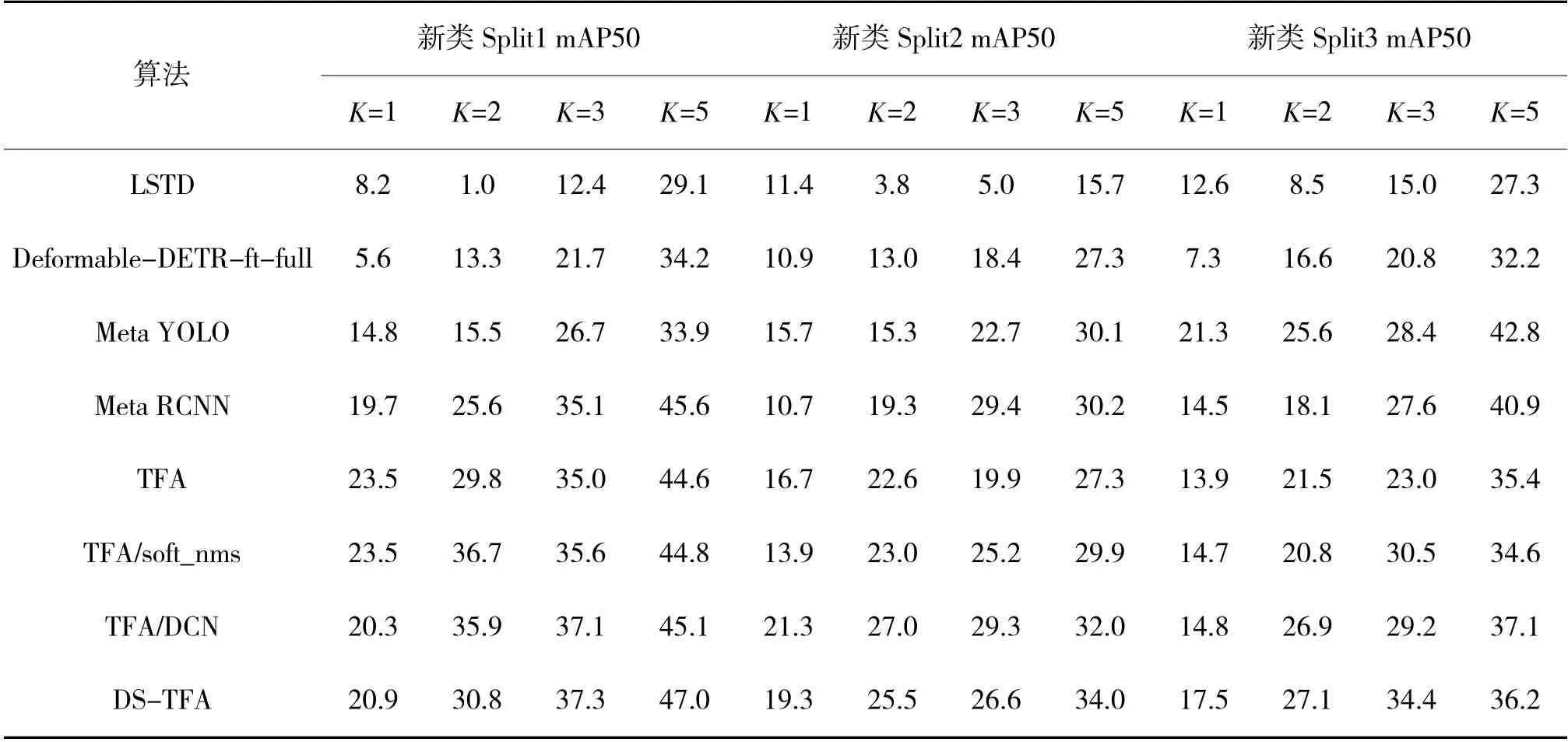
表1 不同方法在VOC 切片上对新类的检测性能Table 1 Detection performance for the novel classes of VOC sections with different methods
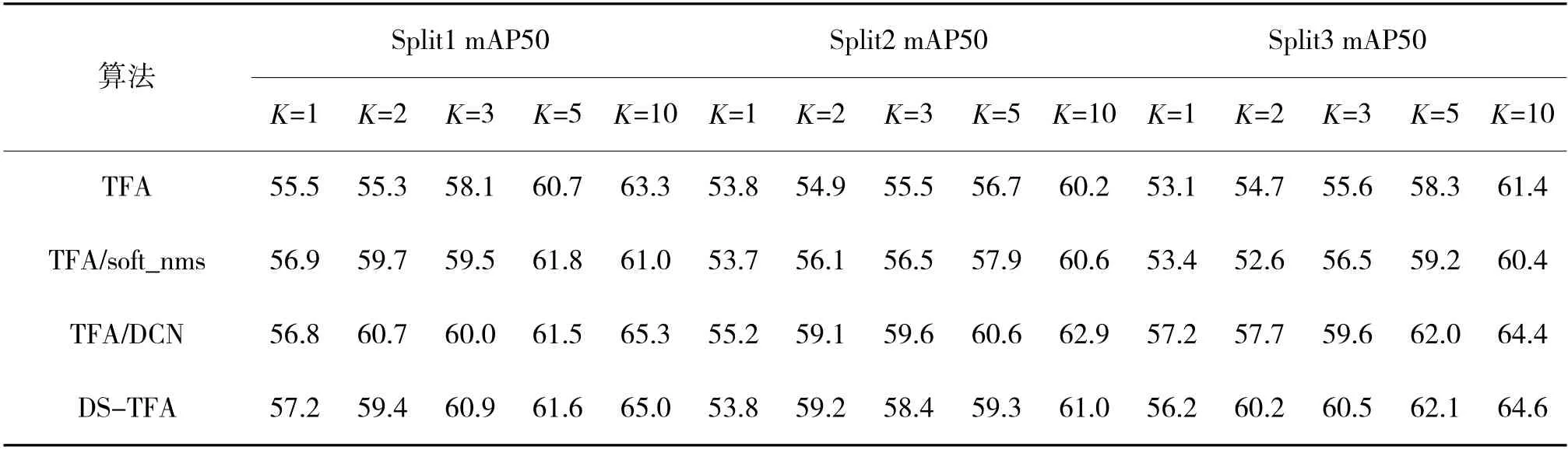
表2 在VOC 数据集上的检测性能Table 2 Detection performance on VOC datasets
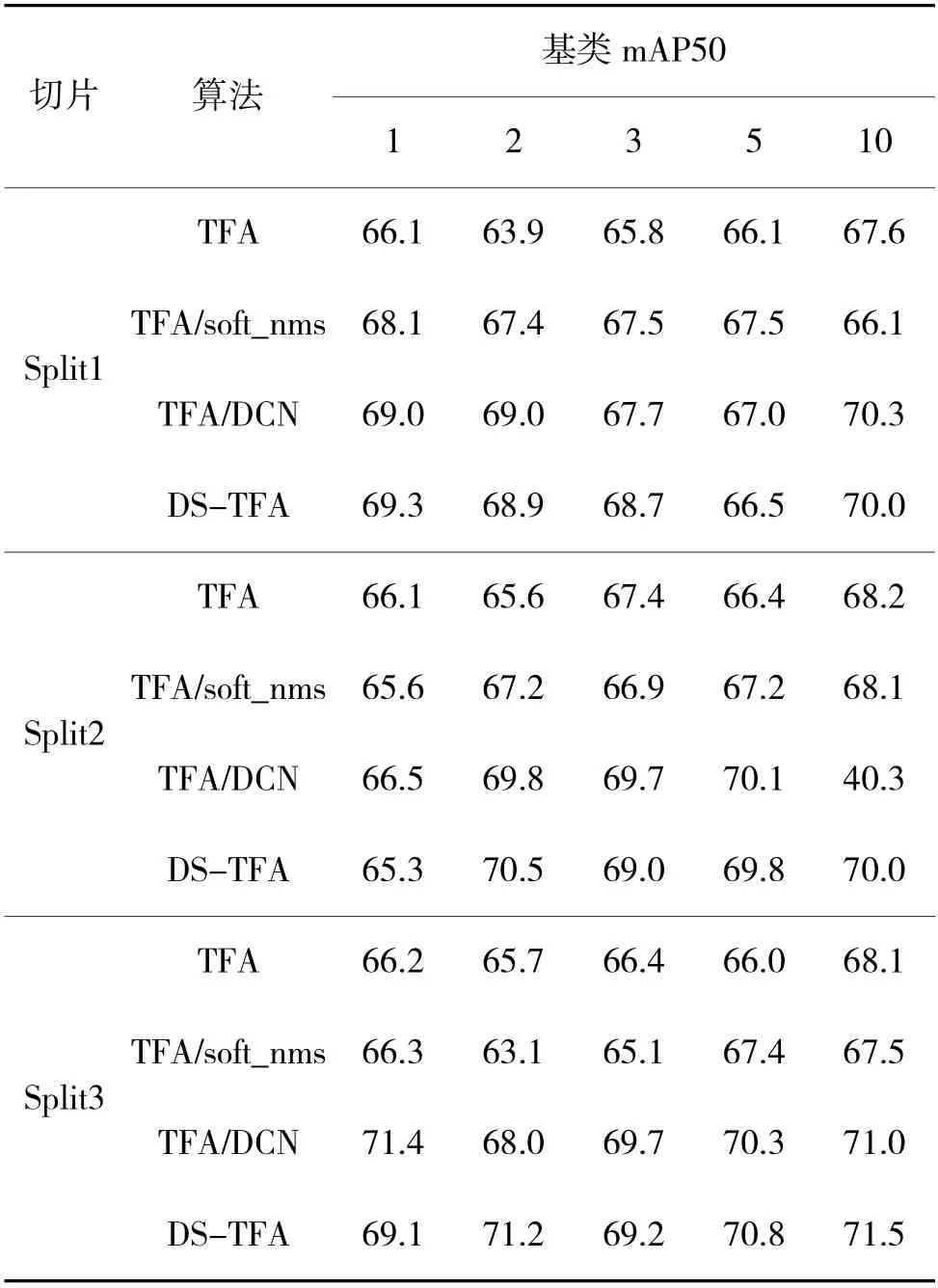
表3 不同方法在VOC 切片上对基类的检测性能Table 3 Detection performance for the base classes of VOC sections with different methods
从表1 可以看出,在VOC split1 实验中,本文改进方法性能均达到了最优性能。在split2 实验中,K=1,2,5 时,本文方法效果最好。K=3 时,本文改进方法性能29.3%与Meta RCNN29.4%性能相当。可以看出,在标注类别K 较少时,相比其他先进的小样本检测方法,本文方法对新类的检测具有明显优势。
对表1 结果中改进方法与原始方法的结果进一步分析。在split1 实验中,对新类检测性能最高可以提升到7.9%;在split2 实验中,对新类检测性能最高可以提升到9.4%。在split3 上K=5 实验中,对新类检测性能可以提升到11.4%。相比原算法,本文的方法有明显优势。
进一步分析本文各改进方法与原始算法的整体性能对比,从表2 可以看出,本文改进的方法整体性能均要优于原始方法。且在K 极少情况下(K=2),相比原方法最高提升了5.4%、4.3%和5.5%,证明了本文改进方法的有效性。
所有微调后的模型在拥有对新类检测能力的同时会影响对基类的检测效果[13]。从表1 的结果可知,本文改进方法对新类的检测效果更好,从表3结果可以看出,在对基类的检测上,本文提出的改进方法性能仍高于原始算法,说明改进方法的稳定性,在拥有对基类检测的优异性能的同时拥有对新类好的检测能力。
4.2 实测数据集实验及结果分析
本节基于实际场景中现场采集的弱小目标可见光图像进行实验,验证算法的泛化性和实用性。数据集包含车、鸟、客机和无人机4 类,每一类别图像数量均小于80 张,并且目标尺寸均小于32*32,最小目标尺寸为8*8,数据集如图6 所示。对数据进行标注处理,将其做成VOC 数据格式。

图6 实测数据集示例图Fig.6 Example diagram of the actual measured datasets
在本节实验中,从VOC 数据集中选取与自测数据集不同类的12 类数据作为基类,进行基础模型的训练,将4 类自测数据集作为要识别的新类,同样K 分别取1、2、3、5、10。表4 和下页表5 分别展示了各改进方法与原算法的检测结果和在基类和新类上的检测结果。

表4 在实测数据上的检测性能Table 4 Detection performance on actual measured data
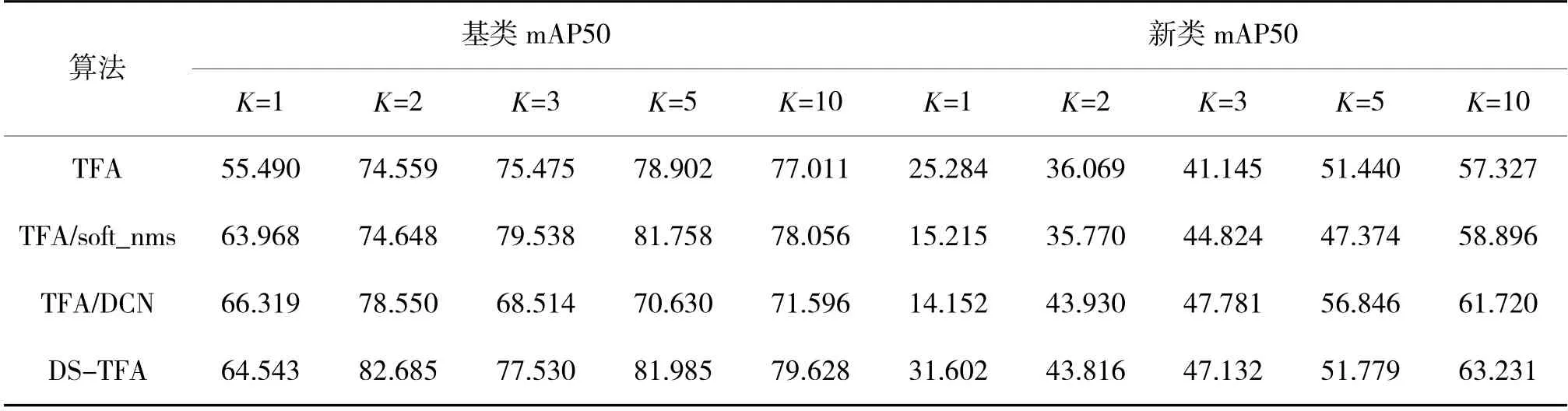
表5 对实测数据基类和新类的检测性能(mAP50)Table 5 Detection performance for the base and novel classes on actual measured data(mAP50)
由表4 可以看出,在以VOC 数据集为基类,自测弱小目标数据集为新类的检测上,改进的算法均取得了比原方法更好的效果。在1-shot、2-shot、5-shot 和10-shot 情况下,DS-TFA 改进方法性能最优,相比原方法性能分别提升8.3%、8%、2.4%和3.5%。在3-shot 情况下,TFA/soft_nms 改进方法性能最优,相比原方法提升3.9%,DS-TFA 方法性能与其相当。总体看来,在弱小目标检测上DS-TFA 改进方法性能最佳。
由表5 可以看出,各方法可以保证在基类的检测上的检测mAP,并且各改进方法性能均高于原方法,针对10-shot 检测结果低于5-shot 检测结果的情况,分析应该是由于微调之后,加入的新类别影响了算法对基类的检测性能。在对新类的检测方面,在2-shot 和3-shot 极少标注样本情况下,DSTFA 和TFA/DCN 改进方法性能达到相当,相比原方法性能分别提升约7%和6%,当类别极少时(K=1),DS-TFA 可以达到31.602,相比其他方法性能最多提升了一倍。以上结果表明,相比原方法,本文提出的改进方法有明显优势。
5 结论
本文基于少量样本的情况,结合可变卷积和Soft-NMS 的优势,提出了一种面向弱小目标的小样本检测方法,可实现对多尺度图像的检测识别。仿真结果表明,相比其他先进小样本检测方法,本文提出的新方法不仅能够提升对VOC 数据集大尺寸目标的检测率,同时还可以提升对弱小目标的准确率,并且在达到对新类检测的基础上,还保持了对基类的检测效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年2期)2021-03-19
家庭影院技术(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
知识经济·中国直销(2018年8期)2018-08-23
北京航空航天大学学报(2018年1期)2018-04-20
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
