
基于互信息的多导联心电图排序方法
2024-01-19 05:45孙占全
电子科技 2024年2期
南 娇,孙占全
(上海理工大学 光电信息与计算机工程学院,上海 200093)
据统计,全球每年死于心血管疾病的人数占总死亡人数的29%,心血管疾病的预防和治疗是医学领域的重要研究内容[1-2]。心律失常是心血管疾病常见的临床表现形式,实现心律失常的自动分类在医学领域具有重要意义。心电图是用来诊断心率失常的有效检测手段,异常波形是心电图专家判断患者心律失常的证据[3-4]。心电图的正确识别需要丰富的专业知识和临床经验,但高质量的医疗资源分布不均使患者缺乏及时和适当的预防治疗措施。因此,心电图自动诊断已成为实现人类健康的关键步骤之一。
对于心电图自动诊断的方法主要包括机器学习和深度学习。传统机器学习方法主要包括去噪[5]、特征提取和分类3个步骤。在时域、统计域或频域[6-7]进行心电特征人工提取,包括波幅、PR间期、QRS起始值、均值、高阶统计量等[8-10]。然而,人工特征提取和选择取决于个人经验,生成的特征不够全面或特征冗余。作为一种数据驱动型技术,深度学习技术突破了机器学习的局限性,可实现特征自动提取和选择的功能,研究人员还实现了端到端的自动分类。参考经典的图像分类深度学习模型建立了基于12导联心电图的深度学习自动诊断模型。文献[11]提出了一种针对12导联心电图诊断心律失常的方法,模型的主干网络是DenseNet,使用一维卷积提取导联特征,最终识别9种心律失常类型。由于心电信号具有时序特征,部分心电图分类模型将卷积神经网络和循环神经网络结合起来提取心电信号的局部特征和全局特征[12-13]。文献[14]介绍了一种由卷积神经网络和双向长短期记忆层组成的模型,从原始心电信号中提取特征。随着注意力模块的出现,神经网络模型建立的重心转移到了加强提取心电导联的时间和空间维度的特征方面[15]。
目前,基于卷积的心电图分类器大多使用一维卷积,从默认导联顺序的心电图中提取单个导联信息,忽略了导联之间的相关性特征。在实际诊断过程中,医生需要考虑患者心律失常类型与心电导联的密切关系。例如,心房颤动患者的II导联和V1导联的波形变化显著[12]。因此,医生在诊断时关注与心律失常类型相关的导联,并通过导联之间的相关信息来提高诊断的准确性。然而,相较于医生的实际诊断过程,分类模型未提取相关性较强导联之间的特征。同时,忽略了12导联心电图的数据特征与其他图像数据之间的不同之处,即交换导联顺序后,心电图仍然保持心电信号的意义。
因此,本文结合二维卷积和12导联心电图的特点提出一种基于互信息的多导联排序方法,使模型可以更充分地提取相关性较强导联之间的特征,更加贴合实际的诊断情况,从而提高分类模型的性能。
1 心电图导联排序方法
1.1 二维卷积
二维卷积运算的核心思想是一个小的权值矩阵在二维输入数据上滑动,对当前输入的部分元素进行矩阵乘法,然后将结果合成为单个输出值。二维卷积定义如下
(1)
其中,m、n是卷积核w的大小;i、j是输出特征图x的大小;y是输出特征图。
12导联心电图数据和一般图像数据存在较大的差异性。一般图片数据由像素点组成,如果将图片的每行像素点进行位置交换,无法看出原图片内容,图片语义被严重破坏。12导联心电图由12个导联的心电数据组成,每一个导联显示随时间不断变化的电压值。将导联的顺序调整后,12导联心电图的语义仍能完整保存。
当输入二维数据的行间数值不同时,二维卷积核在数据上进行滑动运算,所输出的矩阵也不相同。因此对于导联排序不同的12导联心电图,使用二维卷积核的神经网络提取到的特征不同,从而影响模型的分类性能。本文采用卷积核大小为3×3的二维卷积,主干网络参照VGGNet(Visual Geometry Group Network)、GoogLeNet、ResNet(Residual Neural Network)这3个神经网络模型,用于对不同排序12导联的心电图进行分类建模。
1.2 互信息
在生理信号领域,非线性度量是一种重要的工具,其可以提供与潜在机制相关的隐藏信息。互信息作为一种非线性度量手段,广泛应用于人类生物学,例如脑电图、肿瘤等[16-17]。本文使用互信息来衡量心电导联之间的相关性。
信息熵被广泛用作系统信息含量的定量指标,计算式如下
(2)
其中,X是一个随机变量;p(x,y)是x的概率。
互信息衡量随机变量之间的依赖程度。两个连续变量的互信息为
(3)
其中,X、Y是随机变量;p(x,y)是联合分布;p(x)和p(y)是边缘分布。
当数据集足够大时,数据服从正态分布。因此每个心电导联服从正态分布,导联的一维正态概率密度函数如下
(4)
其中,u是数学期望;σ2是方法。两者可以通过最大似然估计求得。
两个心电导联的二维正态概率密度函数如下
f(x1,x2)=
(5)

单个导联的信息熵和两个导联之间的信息熵分别如式(6)和式(7)所示。
(6)
(7)

1.3 排序方法
当对12导联进行随机排序时,有12!种排序方式。每种排序方法较耗时,因此本文提出了一种基于互信息的多导联心电图排序方法。该排序方法遵循心电导联排序的两大基本准则:1)一个导联只能连接两个相邻导联;2)重新的排序结果只能有两个端点。在排序前,需计算导联之间的互信息。两个导联之间的互信息值越大,说明两个导联之间的相关性就越紧密。基于互信息的心电图导联排序步骤如下:
步骤1寻找相关性最大(MI_max)的两个导联,将其作为最早确认排序的两端导联(Lead_1,Lead_2);
步骤2从其余导联中寻找出与已经选中的两端导联互信息值最大的两个导联(Lead_x, Lead_y),并比较其互信息值(MI_lq, MI_rq),互信息值大的导联在该轮被选入连接,作为排序新的一端;
步骤3重复上述步骤,选择关系密切的导联连接,不断更新排序两端,直到所有导联都参与连接。
该排序方法称为两端递增排序法,流程如图1所示。

图1 基于互信息的心电导联两端递增排序流程Figure 1. Flow for 2-end increasing based on mutual information sorting method
2 实验
2.1 实验数据
本文实验数据集分别为CPSC 2018、ACTEC 2019和PIB-XL[18]。CPSC 2018数据集包含6 877条12导联心电图记录,长度从6 s到60 s不等,包含9种心电图类型,即8种心律失常类别和正常心律。ACTEC 2019数据集包含40 000个医学心电图样本及34种心电异常类型。PTB-XL数据集包含18 885名患者的21 837个临床12导联心电图,每条记录时长为10 s,共有71种不同的心电图异常类型。上述数据库均属于多标签数据库。
2.2 根据两端递增排序的导联心电顺序
心电信号是一种微弱信号,易受电力线干扰、肌电图干扰、环境噪声等多种噪声干扰。实验采用中值滤波算法消除基线漂移,使用50 Hz截止频率的低通滤波器过滤电力线干扰,通过数据标准化将数据变换到[0,1]区间。
由于3个数据集中的心律失常类型不同,导联之间的互信息不同,根据两端递增排序方法,不同数据库导联的排序结果也不同。在CPSC 2018数据库中,导联的新顺序为Ⅲ、aVF、Ⅱ、aVR、Ⅰ、aVL、V4、V5、V6、V3、V2、V1,如图2所示。在ACTEC 2019数据库中,导联的新顺序为aVL、Ⅱ、aVF、Ⅲ、aVR、Ⅰ、V4、V5、V6、V3、V2、V1。在PTB-XL数据库中,导联的新顺序为aVL、Ⅰ、aVR、Ⅱ、aVF、Ⅲ、V2、V3、V4、V5、V6、V2。

(a)
2.3 网络模型及其训练设置
心电图分类器采用VGGNet,GoogLeNet和ResNet这3种具有代表性的卷积神经网络结构,。VGGNet模型使用了10层3×3二维卷积层,经过一次下采样操作通道数变为16后,每经过两层卷积操作通道数双倍递增。GoogLeNet模型基于上述VGGNet模型进行模块修改,将偶数的卷积层改成GoogLeNet的卷积核大小为1×1和3×3的并行卷积操作。ResNet模型基于上述的VGGNet模型,两层卷积操作之间使用残差连接结构。在GPU服务器上运行,实验使用两块1080i GPU显卡,8内核CPU,128 GB内存。训练的批量大小为32,学习率设置为0.01。
3 实验结果
3.1 实验数据
本文使用汉明损失(Haming Loss,Hp)、杰卡德系数(Jaccard Index,Jp)、正确率(Accuracy,Ap)、精确率(Precision,Pp)、召回率(Recall,Rp)和F1分数等评估指标来评估本文所提方法的性能。
汉明损失用于调查单个标记上样本的错误分类,汉明损失值越低,模型的性能就越好。杰卡德系数表示有限样本集之间的相似性和差异,系数越大,表示样本相似度越高。精确率表示正确分类个数占被分类到本类别中所有个数的比例。召回率则表示为正确分类个数占本类别总数的比例。F1分数同时兼顾了分类模型的精确率和召回率。
3.2 不同排序方法的性能对比实验
本文实验比较基于互信息的不同排序方法,包括两端递增排序方法、两端递减排序方法和类最大树排序方法。
两端递减排序方法与两端递增排序法相反,确定互信息值最小的两个心电导联,选择互信息数值较小的导联连接到两端。该排序方法称为二端递减排序法。基于互信息的类最大树排序方法指根据最大生成树的思想进行排序。针对最大生成树的算法,一个对象可以连接多个对象,通过减少其分支以满足心电导联排序的两大排序原则。
从表1~表3可以看出,基于互信息的两端递增排序方法优于默认排序以及其他两种基于互信息的排序。与最初默认顺序的12导联心电图相比在CPSC 2018数据集中分类性能提升明显。基于互信息的两端递增排序方法在GoogLeNet模型上的F1分数、正确率、召回率、准确率以及杰卡德系数别提升了0.011、0.009、0.007、0.014、0.013,汉明损失值减低0.002。然而,在ACTEC 2019数据集或PTB-XL数据集中,分类性能提升并不明显,主要是因为其数据库的分类种类较多。

表1 CPSC 2018中基于互信息的不同排序方法的分类性能比较Table 1. Classification performance comparison for different sorting method based on mutual information in CPSC 2018

表2 ACTEC 2019中基于互信息的不同排序方法的分类性能比较Table 2. Classification performance comparison for different sort method based on mutual in ACTEC 2019
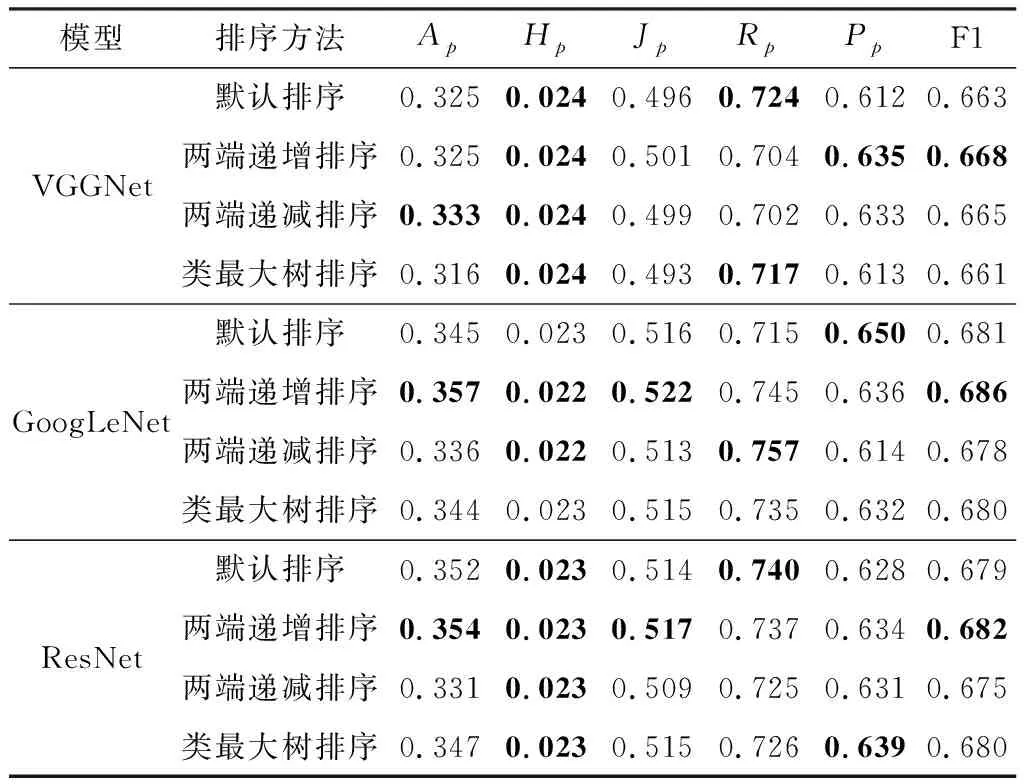
表3 PTB-XL中基于互信息的不同排序方法的分类性能比较Table 3. Classification performance comparison for different sort method based on mutual in PTB-XL
两端递增排序法和类最大树排序法的分类效果优于原始默认排序,而两端递减排序与默认排序相比没有明显提升,反而使模型的分类性能降低。表明导联排序的策略应该是尽可能将关系密切的导联相邻连接起来。两端递增排序方法的分类性能优于类最大树排序,两端递增排序方法更侧重于最大化两个相邻导联之间的相关性,类最大树排序方法更侧重于最大化整体导联之间的相关性。因此,两端递增排序法更有利于二维卷积去提取强相关性导联之间的特征。
3.3 依据不同指标的两端递增排序方法的对比实验
除了互信息作为衡量导联之间的相关性外,本文采用欧氏距离、余弦相似度和相关系数作为排序的依据。根据不同衡量指标,依据两端递增的排序方法对3个数据库的导联进行排序。
表4~表6总结了4种基于互信息、欧式距离、余弦相似度和相关系数的两端递增排序方法的结果。基于互信息的两端递增排序方法均优于其他方法。基于其他度量的排序方法的某些性能指标偶尔高于基于互信息的排序方法。实验结果表明,互信息更适合作为衡量导联相关性的度量。

表4 CPSC 2018中基于不同度量的两端递增排序方法分类性能比较Table 4. Classification performance comparison for 2-end increasing sorting method based on different metrics in CPSC 2018

表5 ACTEC 2019中基于不同度量的两端递增排序方法分类性能比较Table 5. Classification performance comparison for 2-end increasing sorting method based on different metrics in ACTEC 2019

表6 PTB-XL中基于不同度量的两端递增排序方法分类性能比较Table 6. Classification performance comparison for 2-end increasing sorting method based on different metrics in PTB-XL
4 结束语
为解决相关性较强导联之间的特征被忽略的问题,本文提出了一种基于互信息的多导联心电排序方法,该方法充分利用了二维卷积神经网络从心电信号提取有效特征的能力。使用互信息衡量导联之间的相关性,对12导联进行重新排序,使关系密切的导联相邻连接。实验结果表明,本文所提排序方法在3个数据库取得比原默认排序更好的分类性能,也超过了其他排序方法。多导联有规则的排序对心电图自动分类具有重要意义,有助于提高心电自动诊断的分类性能。
猜你喜欢
实用心电学杂志(2023年4期)2023-03-08
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
实用心电学杂志(2016年5期)2016-11-11
实用心电学杂志(2016年5期)2016-11-11
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
