
基于 StarGAN的人脸表情数据增强研究
2024-01-24 14:36王俊杰贾东立
电脑知识与技术 2023年34期
王俊杰 贾东立




摘要:StarGAN网络在生成人脸表情图片时存在局部细节模糊、重叠、整体质量不佳等问题,针对上述问题,对基础StarGAN网络提出了以下3项改进:对生成器加入CBAM注意力模块;改变生成器的网络结构为Attention U-Net网络;对原来的损失函数加入上下文损失函数。对于实验结果使用定性和定量的评价标准,通过与其他模型的FID图像评价指标数值比较,文章提出的方法生成的图片在图像整体质量和局部细节都有显著的效果。
关键词: 计算机视觉; 表情生成; 数据增强; StarGAN; 注意力机制
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2023)34-0009-04
开放科学(资源服务)标识码(OSID) :
0 引言
人脸表情往往比语言可以传达更准确真实的信息,对于人脸表情的研究最早可以追溯到20世纪60年代,Ekman等[1]科学家将观察人脸表情运用到心理学领域,他们建立了基本的7种表情分类,为后继的研究奠定了基础。当下利用深度学习方法进行人脸表情识别研究的工作开展已经很充分了,众所周知,深度学习的训练需要大规模的数据集支持。而目前人脸识别领域经典的数据集如:JAFFE、FER2013、RAF-DB等数据量规模小,各表情类间数据量不均衡都在制约着深度神经网络的表情识别能力。为了最大限度地发掘深度神经网络的能力,本文提出了一种基于StarGAN的人脸表情图像生成网络,对经典的人脸表情数据集进行数据增强,提高网络对表情识别的准确率。
StarGAN网络是针对多域图像转换问题而提出的,它解决了CycleGAN单一域转换的局限性,提高了效率,节省了计算资源。使用StarGAN网络生成的人脸表情存在局部细节模糊、重叠等问题,对于人脸识别的准确率造成很大的影响。因此,针对这一问题,本文对生成器加入CBAM注意力模块,对于表情识别影响较大的局部,例如:嘴角、眼睛和鼻子等给予高权重。由于原始图像和生成图像在空间位置上不一定对齐,这就会对损失函数的值造成影响,从而影响生成的效果。为了解决这个问题,本文使用上下文损失函数来规避空间位置不对齐的影响,通过提取图像的高维特征,计算不同图像间的高维特征的余弦距离来判别2种图片的损失距离。Attention U-Net网络引入了门控单元,可以使得网络集中在对表情变化影响巨大的区域。
1 模型方法
1.1 实验内容
本实验主要包括2部分:人脸表情生成、表情识别。人脸表情生成用改进的StarGAN算法对原始的数据集进行扩增,得到新的规模较大的数据集来为训练表情分类网络做准备。表情识别使用VGG-16网络进行表情分类,通过对比原数据集训练的分类网络和扩增后的数据集训练的分类网络的表情识别准确率,可以进一步说明表情生成工作的价值和必要性。
1.2 CBAM注意力模块
CBAM(Convolutional Block Attention Module) 是一种用于增强卷积神经网络性能的注意力模块。CBAM模块[2]会将得到的特征图按照空间和通道两个维度计算注意力图,从而提高图像分类、目标检测和其他计算机视觉任务的性能。
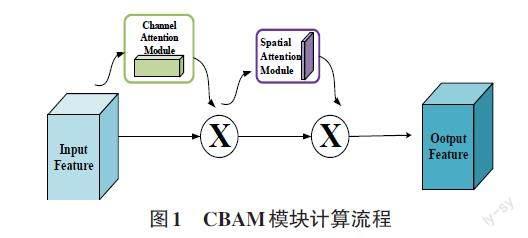
CBAM模块下有两个子模块:空间注意力模块、通道注意力模块。通道注意力模块在空间维度上压缩输入特征图,得到一个1×1×C的特征图,自适应地学习各通道的重要程度,计算每个通道的重要性权重,反馈给特征图的通道信息。空间注意力模块将前一模块输出的特征图作为输入,在通道维度上进行压缩,得到一个H×W×1的特征图,得到空间层面的注意力权重信息。CBAM模块是轻量级的注意力模块,可以很方便地集成到各神经网络中,取得很好的效果,提高模型的泛化能力。如图1所示,展示了CBAM模块的计算流程。
1.3 损失函数
原始StarGAN网络的损失函数[3]包括对抗损失、域分类损失、重建损失见(1) ~(3) :
[Lrcls=Ex,c[-logDcls(c∣x)]] (1)
[Lfcls=Ex,c[-logDcls(c∣G(x,c))]] (2)
[Lrec=Ex,c,c[||x-G(G(x,c),c)||1]] (3)
生成器和鉴别器的总损失函数如下所示:
[LD=-Ladv+λclsLrcls] (4)
[LG=Ladv+λclsLfcls+λrecLrec] (5)
为了解决原始图像和生成图像在空间上不完全对齐的问题,提出了上下文损失函数,通过比较图像的高维特征,更好地度量了图像之间的相关性。上下文损失函数公式为:
[LCX(x,y,l)=-log(CX(Φl(x),Φl(y)))] (6)
其中,[Φl(x),Φl(y)]是原图像和生成图像使用VGG19网络提取的特征图。
改进后的生成器和鉴别器的總损失函数为:
[LD=-Ladv+λclsLrcls] (7)
[LG=Ladv+λclsLfcls+λrecL′rec+λcxLcX(x,y,l)] (8)
其中, [λcls]、[λrec]、[λcx]均为超参数,它们的值都设为1。
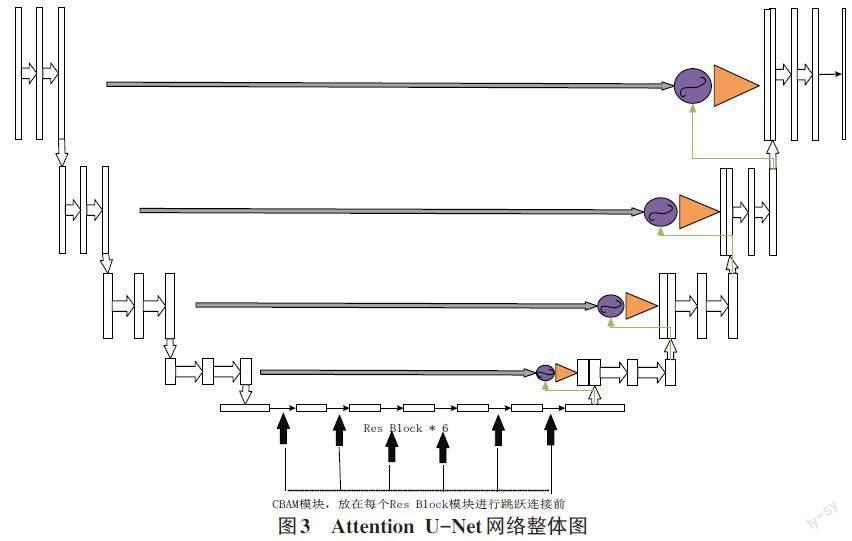
1.4 Attention U-Net网络
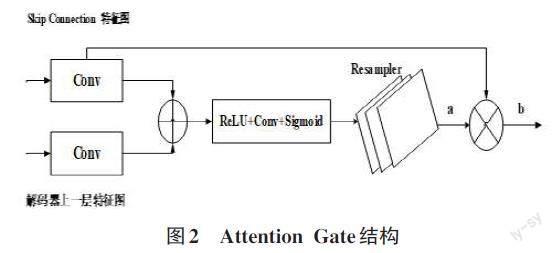
Attention U-Net网络[4]是U-Net网络的一个改进方案,在计算机视觉和医学图像分割领域有很大的作用,它引入了Attention gate单元来关注图像的重要区域。Attention U-Net网络中的编解码架构和Skip Connection可以对图像的不同层次特征图进行整合和重现,最大限度地提取图像的深层特征。Attention U-Net网络先由编码器结构进行下采样,获得图像压缩后的特征;然后进入中间特征层,进一步提取图像的高级特征;解码器负责将从中间特征层提取出的特征图进行重构,重建与原图像大小相同的新图像。Attention U-Net网络中的注意力机制可以关注图像中最重要的局部区域,例如嘴角、眼睛、鼻子这些对于表情识别具有关键影响的局部区域,可以提取到最重要的特征。Skip Connection的输出和网络上一级的特征图都输入Attention Gate单元计算,筛选出图像最重要的特征区域。Attention Gate单元结构如图2所示。
Attention U-Net网络的整体结构如图3所示。
2 数据集的选取与数据增强
本实验使用的数据集为RAF-DB数据集和KDEF数据集。RAF-DB[5]为自然环境下采集的人脸表情数据集。该数据集的总规模超过30 000张,包括基本表情分类子集和复合表情分类子集。本次使用包含7种表情分类的基本表情分类子集:惊讶、恐惧、厌恶、快乐、悲伤、愤怒以及中立表情。基本表情集的训练集总量超过10 000张,测试集3 000张。虽然数据集规模较为合理,但是不同表情类别间数量相差悬殊,例如:快乐类表情图片数量是恐惧类表情数量的十几倍。因此,使用生成网络对数据量小的表情类进行数据增强,增强后RAF-DB数据集训练集共有41 796张图片(对图片数量小于5 957的表情类进行人脸表情生成,每类表情选取5 957张)。
KDEF数据集的发布时间早在1988年,最初的应用范围为心理精神方面,后来随着表情识别课题的提出,逐渐成为该领域内比较重要的一个数据集。KDEF数据集总量不到5 000张,是一个比较小的数据集,但是采集的环境内光线柔和、细节清晰度高、被试者服装统一,避免了耳饰、妆容的影响,具有很高的研究价值。通过生成网络对KDEF数据集进行数据增强,数据集规模变为原来的7倍。
3 实验结果与分析
3.1 实验环境
本实验在操作系统 Win11 下完成,CPU 为Intel(R) Core(TM) i7-12700H/GPU: RTX 3070 Ti, 内 存 为 16G。开 发 环 境 为 Python3.8、PyTorch1.9.0等。
3.2 实验结果
本实验选用了Pix2Pix、StarGAN以及本文提出的网络进行人脸表情生成,3种方法生成的RAF-DB数据集人脸表情效果对比如图4所示:
3种方法生成的KDEF数据集人脸表情效果对比如图5所示:
FID值[6]是经典的衡量生成图像质量的指标,可以衡量图像生成的多样性和质量。FID值越低,说明图片生成的质量越高且富有多样性。为了从定量的角度评断本文提出方法的优越性,采用FID指标对3种方法进行比较。FID通过比较生成图像和原始图像的分布相似性来评估模型的生成效果,使用在ImageNet数据集预训练好的Inception V3网络作为特征提取器,将图片提取到高纬度的特征表示,计算特征向量的均值向量和协方差矩阵。FID的表示如公式(9) :
[FID(X,Y)=||μX-μY||22+Tr(ΣX+ΣY-2ΣXΣY)] (9)
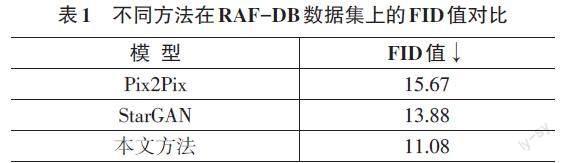
3种模型在RAF-DB数据集上生成表情图片计算的FID值如表1所示:
3种模型在KDEF数据集上生成表情图片计算的FID值如表2所示。
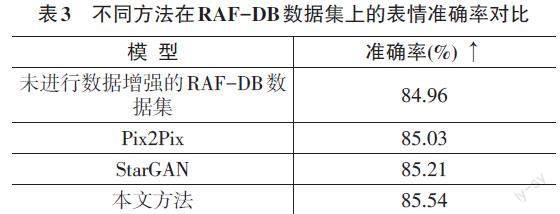
通过数据增强,得到了规模扩大数倍的RAF-DB数据集和KDEF数据集,使用VGG-16网络作为表情识别的分类网络,用数据集的训练集训练分类网络VGG-16,使用测试集评估表情识别的性能。3种模型的RAF-DB数据集表情识别准确率如表3所示。
3种模型的KDEF数据集表情识别准确率如表4所示:
3.3 实验结果分析
通过各种方法在RAF-DB数据集和KDEF数据集上生成的人脸表情图片对比,可以观察到本文方法生成的人脸图片的整体质量较高,局部的重叠、模糊情况发生较少。通过观察表1和表2可知,本文方法在RAF-DB和KDEF數据集上生成的表情图片均取得了最小的FID值,说明本文方法生成的人脸表情具有高质量和高多样性。通过观察表3和表4,可以得出本文方法在两个数据集上均取得了最高的表情识别率。综上,本文方法生成的人脸表情图像优于StarGAN和Pix2Pix方法,对于解决人脸表情数据增强工作具有一定的意义。
4 结论
针对人脸表情数据增强问题,传统的数据增强方法,如旋转、裁剪、缩放等在处理复杂的人脸表情变化时有很多的局限性:有限的变换空间,信息丢失、模型泛化能力受限。因此,提出了生成对抗网络来生成表情图像,从而扩增数据集的规模。但是使用生成对抗网络生成的图像,往往会出现整体质量低、局部细节模糊、重叠等问题。因此,提出了本文的方法,通过实验的结果证明,本文方法对于解决这一问题有一定的可行性。本文方法生成的人脸表情图片虽然有了一定的进步,但是和真实的人脸图像还有不小的差距,部分细节还是不真实,希望通过后续的学习,提出更好的模型,更好地学习人脸图像的特征。
参考文献:
[1] EKMAN P,FREISEN W V,ANCOLI S.Facial signs of emotional experience[J].Journal of Personality and Social Psychology,1980,39(6):1125-1134.
[2] SHENG W S,YU X F,LIN J Y,et al.Faster RCNN target detection algorithm integrating CBAM and FPN[J].Comput Syst Sci Eng,2023,47:1549-1569.
[3] CHOI Y,CHOI M,KIM M,et al.StarGAN:unified generative adversarial networks for multi-domain image-to-image translation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:8789-8797.
[4] TREBING K,STAǸCZYK T,MEHRKANOON S.SmaAt-UNet:precipitation nowcasting using a small attention-UNet architecture[J].Pattern Recognition Letters,2021,145:178-186.
[5] WANG K,PENG X J,YANG J F,et al.Region attention networks for pose and occlusion robust facial expression recognition[J].IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society,2020(29):4057-4069.
[6] OBUKHOV A,KRASNYANSKIY M.Quality assessment method for GAN based on modified metrics inception score and Fréchet inception distance[C]//SILHAVY R,SILHAVY P,PROKOPOVA Z.Proceedings of the Computational Methods in Systems and Software.Cham:Springer,2020:102-114.
【通聯编辑:唐一东】
猜你喜欢
现代电子技术(2018年8期)2018-04-13
智能计算机与应用(2017年5期)2017-11-08
计算机应用(2016年12期)2017-01-13
中国新通信(2016年22期)2017-01-13
现代电子技术(2016年22期)2016-12-26
