
基于语义增强的中医医案主诉匹配方法
2024-01-27 12:37姜惠杰查青林
现代信息科技 2023年24期
姜惠杰 查青林
摘 要:针对中医医案中编码实体深层语义关系错综复杂,因不能充分发掘文本间的语义信息而无法完成匹配任务以及文本特征稀疏使得计算精确度较低的问题,提出一种基于语义增强的中医医案主诉文本匹配推荐模型,构建基于注意力机制的文本深层语义信息学习网络,充分吸收可能存在于句子中各实体之间的深层语义关系信息,再通过向量重构的方式进行语义选择与增强,得到匹配推荐结果。将ERNIE模型和深度网络模型相結合,用自编码器实现对句向量的特征选择和降维,更好地匹配中医医案领域实际任务场景,从而使匹配推荐结果更准确有效。实验表明,相比其他模型,所提出的方法具有更高的匹配准确率。
关键词:ERNIE模型;深度学习;文本匹配;自然语言处理;预训练模型
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2023)24-0142-05
A Semantic Enhancement-Based Matching Method for Main Complaints in Traditional Chinese Medicine Cases
JIANG Huijie, ZHA Qinglin
(College of Computer Science, Jiangxi University of Chinese Medicine, Nanchang 330004, China)
Abstract: In response to the complex deep semantic relationships of coding entities in traditional Chinese medicine cases, the inability to complete matching tasks due to insufficient exploration of semantic information between texts, and the low computational accuracy caused by sparse text features, a semantic enhancement-based recommendation model for main complaint text matching in traditional Chinese medicine cases is proposed, and an attention mechanism-based deep semantic information learning network for texts is constructed, fully absorb the deep semantic relationship information that may exist among entities in the sentence, and then perform semantic selection and enhancement through vector reconstruction to obtain matching recommendation results. Combining the ERNIE model with the deep network model, an auto-encoder is used to achieve feature selection and dimensionality reduction of sentence vectors, better matching the actual task scenarios in the field of traditional Chinese medicine cases, and thus making the matching recommendation results more accurate and effective. Experiments have shown that the proposed method has higher matching accuracy compared to other models.
Keywords: ERNIE model; Deep Learning; text matching; natural language processing; pre-training model
0 引 言
中医体系是中华民族历经数千年时光不断摸索得到的理论体系[1],时至今日仍是守护人民群众健康的重要力量,在人类医学史中发挥了不可磨灭的作用并具有牢不可破的地位。在现如今这个知识爆炸式增长的年代,中医亟须将计算机相关技术引入中医研究领域来对中医学加以深入探索,从而将以往的中医临床实践经验快速转化成具有临床实用价值的知识,这也是中医现代化进程中不可或缺的组成部分。文本信息是知识记录的重要载体之一,也是最广泛保存和最容易获取的一种数据类型[2]。现存的大量中医医案就是其中最具代表性的一种文本,是蕴含着极为丰富知识的宝贵财富,从这些中医医案文本中提取到有用的知识并应用于中医临床诊疗中,对中医临床数字化具有非常重要的意义。
随着硬件技术和人工智能算法水平的不断发展进步,使对名老中医在行医过程中不断积累的中医医案数据的分析处理与知识挖掘变成可能。名老中医的医案数据中包含了许多行医中的详细内容,具有极高的专业价值,是中医领域内的宝贵财富。新一代的中医医生可以从相识的案例中了解和学习名老中医的行医思路与处理方法,对自身的学习成长有着较高的参考价值。然而,由于现存中医医案的存量巨大,结构和内容也不尽相同,人工翻阅学习所花费的时间太长,难以高效利用大量中医医案文本的医学思想价值。
本文从现有的大量名老中医医案数据出发,分析医案主诉特点,选择较好的匹配方法。为实现相似医案匹配这一重要任务,将文本匹配问题转换为二分类问题来处理,将ERNIE和经典深度学习模型相结合,来充分提取并学习两段医案文本的特征并计算出两段短文本的相似程度,最终给出匹配结论。经过实验分析,多模型结果融合的中医医案主诉文本匹配方法所达到的精确率可以满足中医临床诊疗需求,是一种具有充分可行性的解决方案。
1 综 述
文本匹配[3]一直都是自然语言处理(Natural Language Processing, NLP)领域一个基础且重要的方向,其主要的研究内容是两段文本之间的关系。在过去的十几年间,基于神经网络模型的处理方法在许多NLP任务中逐渐变得流行。相比于更早期常用的基于统计学的处理方法,深度神经网络模型在训练时不再需要人工介入确定特征表示,解放了人力的同时降低了研究门槛;可以端对端训练得到结果,进一步减少了研究成本便于快速推广应用,具有非常明显的优势。在基于神经网络的模型研究方面,后续的大量研究的主要方向是在特征向量后面追加更多其他特征信息来提高神经网络模型的效果。通常情况下,文本匹配任务有两个主要的解决思路:做分类任务处理,作回归问题处理。一些我们所熟知的自然语言处理下游任务都可以近似看作文本匹配任务。
文本匹配自从概念被提出以来就注定是一项非常重要且困难的自然语言处理技术,尤其是其与不同的具体应用领域相结合的迁移应用。十几年来,这一自然语言处理技术已经在人们日常生活中各大常见领域都有了成熟发展和广泛运用,而其与中医领域的深度融合与应用仍处于较为初始的发展阶段[4]。在国外的应用方面,Google公司将该技术应用到了其旗下的搜索引擎[5]产品服务中,从海量数据中检索出与用户的搜索内容相关的内容。在国内的应用方面,许多电商公司将其应用到智能客服[6,7]的服务中,优先对用户提出的问题做相似问题匹配,并检索该问题答案同时给用户做出相应的回答,不但可以大大提升问题解决的效率,也能减少电商公司的人员成本,提升公司的利润。伴随着软硬件条件的不断完善,深度学习在算法层面也飞速发展,加上GPU算力的飞速提升,文本匹配相关技术也得以随之迭代升级。根据神经网络模型处理文本匹配任务的模型整体架构来划分,可以将深度学习算法模型解决问题的模式归纳为两个思路:基于表示的模型和基于交互的模型[8,9]。
其中,基于表示的模型处理这一问题的基本思路是:分别用两个神经网络学习两段文本的特征向量表示,然后将两段文本的特征向量进行拼接,并将拼接后的向量输入到模型的分类器中进行一次二分类操作,就可以得到最终匹配结果。Huang[10]等人提出了一种类文本语义空间模型,利用两个前馈神经网络分别将两段文本向量投影到潜在语义空间中,并分别计算得到两段文本在空间中的表示向量,最终将计算结果向量接入到一个多层感知机中来处理并进行预测得到最终结论。范旭民[11]和梁圣[12]两人分别使用CNN模型和RNN模型来分别学习两段文本的低维特征表示向量,较之一般的前馈神经网络模型,这些改进模型可以更好地学习两段文本中的上下文信息。
此外,基于交互的模型处理这一问题的基本思路是:侧重关注两段文本之间的语义交互特征,生成文本匹配矩阵并提取出两段文本的语义交互特征向量,再将结果输入到一个全连接层中来计算得到文本匹配结果。金丽娇等人[13]将两段文本的低层文本匹配矩阵看作图像进行处理,然后再利用CNN模型来进行逐层卷积计算,在此过程中就可以抽取到更多文本特征用以完成文本匹配任务。
近几年来,在上述第二种处理思路的基础之上,基于预训练模型的文本匹配模型受到了更加广泛地关注和应用。2018年,Devlin等人[14]提出了一种全新的语言模型预训练方法BERT,在许多经典的自然语言处理下游任务中都得到了十分出色的效果,使神经网络模型在各种任务中的效果很大提升,极大地推动了自然语言处理技术的发展。该方法利用大规模的无监督文本语料训练了一个通用的语义理解模型。这一预训练模型相较于先前常用的文本表示方法效果更加优越,主要原因是BERT模型是第一个使用无监督、深度双向编码方法[15]的预训练语言模型。不需要使用大量人力去标注训练文本的同时模型可以从文本中获取到更加丰富的语义特征和句法特征等文本底层知识。BERT模型中的重要特征获取方法是一种被称为Attention机制[16]的网络模型结构,注意力机制相较于一般的深度学习方法有着更强大的特征提取能力。2019年,Sun等人[17]提出了一种知识增强的语义表示模型ERNIE,通过对句子文本中的语义信息进行遮盖,使得模型能够获取到更加完整的语义特征信息,ERNIE 1.0模型在中文语言处理中采用了以词为基础的嵌入处理,可以使在中文文本中学习到的语义信息更加完整。此后,ERNIE 3.0[18]等更优的模型也争相问世。预训练模型领域也逐渐百花齐放。
虽然深度神经网络模型在中文语言环境下的文本匹配任务上发展已经日渐成熟,但是能够深度理解并结合中医医案文本的语言特点,可以很好地适用于中医医案领域的文本匹配研究却很少。
2 模型介绍
2.1 ERNIE模型
2019年诞生的ERNIE(enhanced representation through knowledge integration)模型。这一模型在很多方面有了改进和提升,模型的主要特点是语义增强策略和多階段持续学习,可以分阶段多次训练来适配不同的训练数据和预训练任务。能够通过海量通用文本的预训练来获得提取文本中语义关系的能力,并能够简单作为一个编码器来使用,将初始输入文本处理成可以进入模型计算的语义嵌入向量。它通过引入三种级别的Knowledge Masking来帮助模型学习语言知识,在多项下游任务的效果上超越了BERT。在模型结构方面,它依旧采用了Transformer的Encoder部分作为模型主干进行训练。
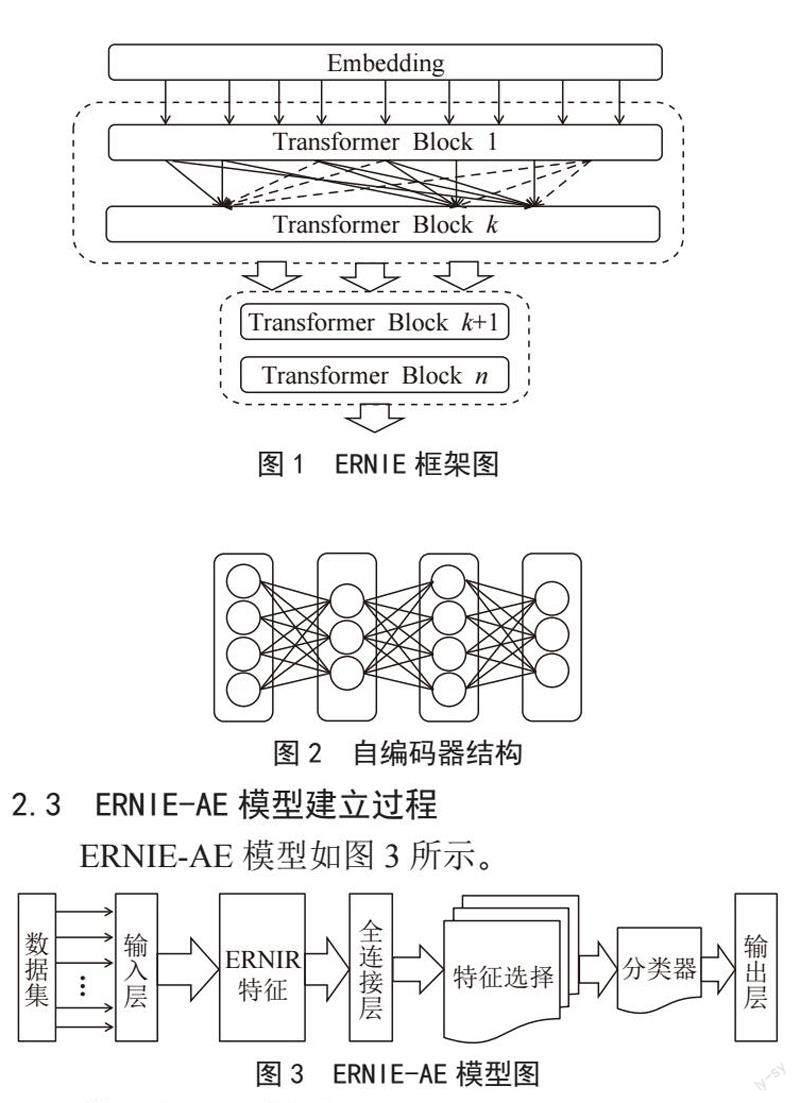
延续了ERNIE 2.0的部分语言学习思路,ERNIE 3.0同样期望通过设置多种预任务的方式辅助模型全面学习语言的各方面知识,比如词法知识、句法知识和语义信息。ERNIE 3.0期望能够在这三种任务模式(task paradigm)中均能获得比较好的效果,因此提出了一个通用的多模式预训练框架,这就是ERNIE 3.0,如图1所示。
图1 ERNIE框架图
ERNIE 3.0的框架依旧沿用了12层Transformer编码层作为基本模型结构,但与BERT有所区别的是,前六层采用与BERT相同的Transformer层,但在第七层自定义知识融合层BertLayerMix,首次对经过对齐的实体向量和指称向量求和,并将其分别传输给知识编码模块和文本编码模块,在剩下5层自定义知识编码层BertLayer,分别对经过融合了两者信息的实体序列和文本序列使用自注意力机制编码。模型的前五层可整体看作一个通用语义表示网络,该网络学习数据中的基础和通用的知识。模型的后面七层可整体看作一个任务语义表示网络,该网络基于通用语义表示,学习与各种特定任务相关的知识。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,而通用语义表示网络会学习所有的预训练任务,两者有机结合使模型性能有了一些提升。
ERNIE 3.0的整体架构包含两个部分:
通用表示模块:使用多层的Transformer-XL,作为通用语义特征抽取器,其中的参数在所有类型的任务范例之间共享。
任务特定表示模块:也是使用的多層Transformer-X结构;其中对于NLU任务为双向Encoder层。
模型的具体处理过程可以表示为:
output = Norm(x + R(x))
MultiHead(Q,K,V) = Concat(head1,…,headH)W 0
headi = Attention(,,)
式中,R为上一个Encode层的残差,Norm为归一化函数;Q为查询矩阵,K为键矩阵,V为值矩阵;W为矩阵的变换矩阵;H为注意力头数,并行多个注意力头同时捕获文本中的特征子空间信息。
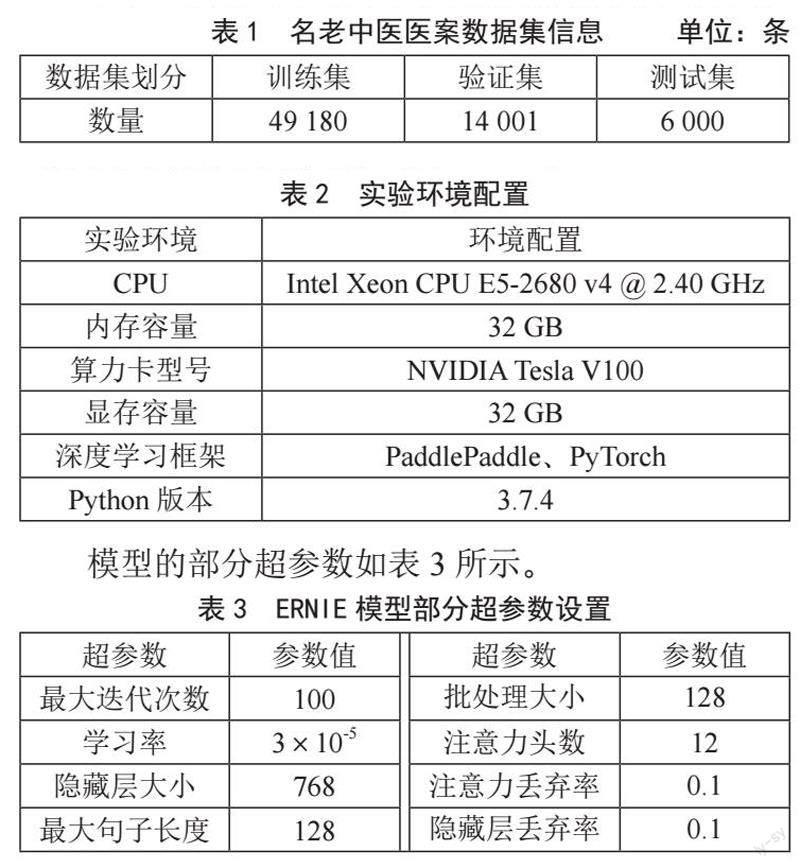
2.2 自编码模型
自编码模型(Auto-encoding Model, AE),是一种有效的数据维度压缩算法。通过破坏的文本向量序列来重建原始数据进行训练,使输出层尽可能如实地重构输入样本信息。具体过程表示如下:
hi = σe(Wi x + bi)
yj = σd(Wj x + bj)
式中,Wi、bi为编码层的权重和偏置,Wj、bj为解码层的权重和偏置。
将上一小节中ERNIE 3.0等模型编码的句向量分别输入自编码层,并经过本模型特征筛选和池化等处理操作,输出最终向量,经过全连接层连接和Softmax分类器,输入到输出层得到计算结果,最后就可以输出匹配结果。其结构如图2所示。
图2 自编码器结构
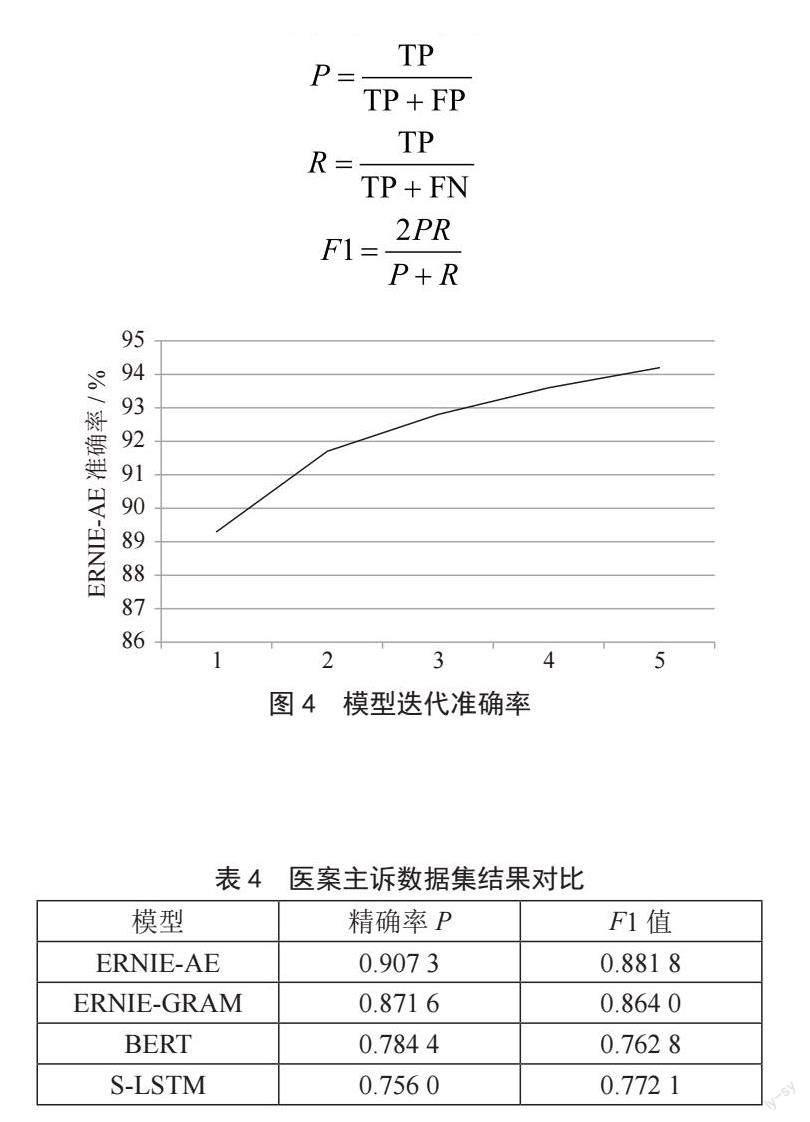
2.3 ERNIE-AE模型建立过程
ERNIE-AE模型如图3所示。
图3 ERNIE-AE模型图
模型的处理过程如下:
1)数据加工。对自建的名老中医医案数据集主诉数据进行数据处理。
2)输入嵌入层。先分别将句子对中的字或词处理成编码序列,再经过输入层的映射得到输入向量输入到不同的特征提取层。
3)ERNIE模型的特征提取层。将前一部分所得到的词嵌入向量分别输入到改进的BERT和ERNIE模型中,融合浅层或深层知识,得到文本的特征表示向量。
4)特征选择与池化层。将ERNIE预训练网络层得到的特征表示输入到自编码器中,通过对特征的降维重构来进行重要特征选择,提升预测效果。
5)匹配和输出层。将上一部分经过全连接层得到的句向量输入到匹配层Softmax分类器中,经过模型计算完成匹配,并经过输出层得到最终的推荐结果。
3 实验及结果分析
3.1 实验数据
为了评估模型性能,本文将提出的模型在自建的名老中医医案主诉数据集上进行相应的实验与评估。该数据集是由名老中医医案数据集是根据全国名老中医真实临床诊断的医案,包括2万余个病例的中医医案文本共计6万余诊次,均为UTF-8编码格式的纯文本。
数据集中共生成了69 181对文本的相似性标签作为基础实验数据,其中49 180条作为训练集,14 001条作为验证集,6 000条作为测试集,文本长度在7到128之间。
如表1所示为名老中医医案数据集的统计信息。
表1 名老中医医案数据集信息 单位:条
数据集划分 训练集 验证集 测试集
数量 49 180 14 001 6 000
3.2 实验环境
所有实验均使用同一云计算环境。实验环境如表2所示,实验文本编码格式为UTF-8。
表2 实验环境配置
实验环境 环境配置
CPU Intel Xeon CPU E5-2680 v4 @ 2.40 GHz
内存容量 32 GB
算力卡型号 NVIDIA Tesla V100
显存容量 32 GB
深度学习框架 PaddlePaddle、PyTorch
Python版本 3.7.4
模型的部分超参数如表3所示。
3.3 评价指标
实验用了文本分类中常用的评价指标:精确率(Precision)、召回率(Recall)、F1值,计算式为:
式中,TP为实际值和预测值均为1时数据的数量,FP为实际值为0、预测值为1时的数据数量,FN为实际值为1、预测值为0时数据的数量,P为精确率,R为召回率。
3.4 实验结果及分析
为贴合实际应用场景,从初诊的医案主诉中共选择7 698条人工标注的ICPC-3标签达到两个及以上的医案,按标签取出20%的医案用作推荐测试。为了模拟推荐情景,训练集和验证集采用数据集中剩下的80%医案主诉数据生成,而测试集由作推荐测试的部分与参与训练和验证的部分按标签组合生成,适当调整以保证各数据集标签分布均匀。
将数据集分别输入模型中进行训练,统一设置训练轮次为5。训练结束后使用测试集进行测试并输出实验结果。模型迭代准确率如图4所示。
BERT、ERNIE-GRAM、ERNIE-AE和S-LSTM四个模型在名老中医医案数据集上的语义匹配评测结果如表4所示,使用的主要指标是精确率及F1值。
从最终实验结果中可以看出,ERNIE-AE模型的精确率及F1值结果相较于BERT模型、ERNIE-GRAM模型更优。ERNIE-AE模型的性能优于BERT模型,主要原因是ERNIE-AE模型优化了语义学习网络结构的同时增加了预训练的样本数量,ERNIE模型本身就是在BERT模型的基础上进行改进的结果,拥有许多BERT模型所没有的优势。ERNIE-AE模型的性能优于ERNIE-GRAM模型,主要原因是ERNIE-AE模型采取了更先进的预训练模式,使用了改进的学习网络,相较于之前的训练方式有着更好的效果。
4 结 论
在解决中医医案匹配推荐任务存在的难点时,提出一种基于ERNIE-AE的医案匹配推荐模型,利用ERNIE预训练模型初步提取医案中的浅层及深层语义信息,将输出的稀疏特征结果作为自编码器的输入进行二次提取,可以将稀疏的特征向量简化,使匹配结果更加准确。
实验结果表明,ERNIE-AE模型在中医医案数据集上比其他对比模型具更高的准确率和稳定性,匹配性能也更强。能够有效辅助基层医生进行临床治療,是一种行之有效的解决方案。
参考文献:
[1] 曹军.面向中医药文本的实体识别与关系抽取方法研究 [D].南昌:江西中医药大学,2022.
[2] 杜小勇.数据科学与大数据技术导论 [M].北京:人民邮电出版社,2021.
[3] 庞亮,兰艳艳,徐君,等.深度文本匹配综述 [J].计算机学报,2017,40(4):985-1003.
[4] 刘新静.基于改进BERT模型的短文本分类方法研究 [J].山东:曲阜师范大学,2021,17(27):13-14+20.
[5] 赵一鸣,刘炫彤.中外文搜索引擎自然语言问答能力的比较与评价研究 [J].情报科学,2020,38(1):67-74.
[6] 郑实福,刘挺,秦兵,等.自动问答综述 [J].中文信息学报,2002(6):46-52.
[7] 刘明博.基于分布式的智能问答系统的设计与实现 [D].北京:北京邮电大学,2018.
[8] SHA L,CHANG B B,SUI Z F,et al. Reading and Thinking: Re-read LSTM Unit for Textual Entailment Recognition [C]//Proceedings of International Conference on Computational Linguistics.Osaka:[s.n.],2016.
[9] PAUL R,ARKIN J,AKSARAY D,et al. Efficient Grounding of Abstract Spatial Concepts for Natural Language Interaction with Robot Manipulators [EB/OL].[2023-03-28].https://www.roboticsproceedings.org/rss12/p37.pdf.
[10] HUANG P S,HE X D,GAO J F,et al. Learning deep structured semantic models for web search using clickthrough data: Proceedings of the 22nd ACM international conference on Information & Knowledge Management [C]//CIKM'13: Proceedings of the 22nd ACM international conference on Information & Knowledge Management.San Francisco:Association for Computing Machinery,2013:2333-2338.
[11] 范旭民.基于卷积神经网络和注意力机制的文档自动问答模型 [D].杭州:浙江大学,2018.
[12] 梁圣.基于RNN的试题相似性检测与分类研究 [D].株洲:湖南工业大学,2018.
[13] 金丽娇,傅云斌,董启文.基于卷积神经网络的自动问答 [J].华东师范大学学报:自然科学版,2017(5):66-79.
[14] DEVLIN J,CHANG M W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2023-03-28].https://arxiv.org/abs/1810.04805v2.
[15] RADFORD A,NARASIMHAN K,SALIMANS T,et al. Improving Language Understandingby Generative Pre-Training [EB/OL].[2023-03-28].https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[16] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [J/OL].arXiv:1706.03762 [cs.CL].[2023-03-29].https://arxiv.org/abs/1706.03762.
[17] SUN Y,WANG S H,LI Y K,et al. ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation [J/OL].arXiv:1904.09223 [cs.CL].[2023-03-29].https://arxiv.org/abs/1904.09223.
[18] SUN Y,WANG S H,FENG S K,et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation [J/OL].arXiv:2107.02137 [cs.CL].[2023-03-29].https://arxiv.org/abs/2107.02137.
作者简介:姜惠杰(1996—),男,汉族,山东烟台人,硕士研究生在读,研究方向:自然语言处理;通讯作者:查青林(1973—),男,汉族,江西上饶人,教授,硕士生导师,硕士研究生,研究方向:中医信息学。
收稿日期:2023-04-28
基金项目:江西省科技厅重点研发计划项目(20171ACG70011)
猜你喜欢
计算机应用(2016年12期)2017-01-13
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
