
基于自适应蚁群算法的含分布式电源配电网故障定位研究
2024-02-20 04:05李明恩庚振新徐建源
东北电力技术 2024年1期
李明恩,庚振新,李 雁,徐建源
(沈阳工业大学电气工程学院,辽宁 沈阳 110870)
0 引言
由于传统化石能源紧缺,对环境造成污染,导致新能源技术发展迅速,很多学者开始研究分布式电源发电。分布式电源发电不仅缓解我国资源紧缺的现状,而且供电方式灵活、对环境友好,得到大力发展[1]。分布式电源接入配电网后,对配网系统的结构和运行方式带来一定冲击,体现在配电网结构更加复杂,系统潮流方向发生改变,给配电网故障定位带来麻烦。
随着配电自动化技术快速发展,用配电自动化设备来解决配电网故障定位问题成为人们研究的热点。其定位原理是利用分段开关处的FTU实时检测并发送线路故障电流信息,再利用SCADA系统接收的故障电流信息,达到故障定位目的[2-3]。
目前,故障定位算法包含矩阵算法和间接算法2种[4]。矩阵算法原理简单,计算速度快,容错性差[5]。间接算法主要包括粒子群算法[6]、遗传算法[7]、蚁群算法[8]等。遗传算法容错性好,但搜索时间长,效率低;粒子群算法具有良好的容错性和快速性,但在配电网规模较大时故障定位时间长。蚁群算法具有良好的容错性、适应复杂配电网等优点,但前期搜索时间长,易出现停滞等问题。
本文针对传统蚁群算法现有缺陷问题,提出运用一种自适应蚁群算法,在传统蚁群算法基础上,改进信息素挥发因子表达式、更换信息素更新机制及限定信息素浓度的取值。通过仿真验证分析,自适应蚁群算法能够快速准确地进行故障定位。
1 自适应蚁群算法的数学模型
蚁群算法(ACO)是通过观察蚂蚁寻找食物行为提出的一种寻优算法,最早在1992年由意大利学者发现并提出[9]。蚂蚁依靠自身释放信息素激素,进行彼此间的信息交流,选择下一步移动路径。蚂蚁觅食过程中会形成一种正反馈机制[10],该机制会帮助蚂蚁向着最优路径不断靠近,最终找到从巢穴到食物源的最短路径。
1.1 传统蚁群算法
(1)
式中:allowedk={c-tabuk}为储存蚂蚁k未经历的节点;tabuk为路径禁忌表,储存蚂蚁k经历过的节点,下一步移动时不能再选择经历过的节点;τab(t)为路径(a,b)上的信息素浓度;α为信息素指导蚂蚁选择路径的影响因子;β为蚂蚁受启发信息选择路径的影响因子;ηab为启发指数,见式(2)。
(2)

完成一次循环,对全局信息素浓度进行更新[13],其更新后的公式见式(3)。
τab(t+n)=(1-ρ)×τab(t)+Δτab(t,t+n)
(3)
(4)

(5)
式中:Q为信息素总量;Lk为蚂蚁k在此次循环走过的路径总和。
1.2 自适应蚁群算法
针对蚁群算法初期搜索时间长,易出现停滞等问题,本文提出3个改进策略。
a. 改进信息素挥发因子表达式
全局搜索能力和搜索时间是衡量算法性能的重要体现,全局搜索能力和搜索时间又与信息素挥发因子ρ取值存在直接关系,因此取得合适的值显得尤为重要[15]。如果ρ值过大,全局搜索能力下降,如果ρ值过小,则搜索时间变长[16]。为了取得一个合理的ρ值,就必须自适应改进ρ值的大小,采用随时间变化的ρ(t)代替常数值ρ。为了提高算法的全局搜索能力,在初始时刻让ρ值小一些;为了降低算法的搜索时间,后期让ρ值逐渐增大,使蚂蚁向着当前较优的路径不断靠近。自适应调整后的ρ(t)见式(6)。
ρ(t)=min{σ×ρ(t-1),ρmax}
(6)
式中:σ为常数值,本文取1.07;ρmax为信息素挥发因子ρ的最大值,本文取0.8。
b. 改进信息素更新方式
若用传统蚁群算法对每只蚂蚁都进行信息素更新,则搜索速度慢且不易收敛。若只选择最优蚂蚁所留的信息素进行更新,则全局搜索能力降低,容易陷入局部最优。因此,为了平衡上述2种情况,只对前15只最优蚂蚁的信息素进行更新。
c. 限定信息素浓度τab(t)的取值范围
为了改进蚁群在搜索过程中容易停滞陷入局部最优的问题,本文对信息素浓度值τab(t)大小进行限定,保证τab(t)介于此范围内,限定后的τab(t)满足:
τmin≤τab(t)≤τmax
(7)
式中:若τab(t)≥τmax时,则令τab(t)=τmax;若τab(t)≤τmin时,则令τab(t)=τmin,设置上限τmax=10是避免一条路径信息素浓度过大,只搜索浓度较大的路径而不对其他路径进行搜索,算法容易陷入局部最优;设置下限τmax=0.01是确保每一条路径都能被搜索到,保证算法的全局搜索能力。
2 基于自适应蚁群算法的故障定位数学模型
蚁群算法起初用来解决旅行商问题,后来被专家和学者用来解决组合优化问题[17],蚂蚁根据路径上信息素浓度高低,进行选择下一步移动路径,蚂蚁所选路径的组合就是问题的可行解。转换到含分布式电源的配电网故障定位求解问题中,其本质也是组合优化求解问题,其原理是根据含分布式电源配电网发生故障时各馈线区段是否流过故障电流,找到一组各馈线区段最佳组合状态作为问题的可行解,并通过可行解来计算评价函数值的大小,找到评价函数最小值所对应的可行解作为最优解,使与分段开关处FTU上传的故障信息相符,从而找到故障位置。其数学模型主要考虑3个步骤:对故障电流编码操作;定义开关函数;定义评价函数。
2.1 故障电流编码
故障电流信息编码操作是实现故障定位必不可少的一步,SCADA系统接收故障电流信息前,需要对馈线区段和分段开关处的故障电流信息编码[18]。本文采用二进制编码表示问题的可行解,设定系统主电源指向用户负载侧为正方向,对含分布式电源配电网的馈线区段和对应分段开关的状态进行编码。
(8)
2.2 开关函数
实现故障定位,需要建立分段开关状态期望值与故障区段实际状态之间的转换[19],这种转换关系称为开关函数。
传统配电网短路电流方向恒定,开关故障电流信息只与下游区段的状态有关[20]。含分布式电源配电网结构更加复杂,短路电流方向不再单一恒定,传统配电网的开关函数不再适用,因此有必要对开关函数重新定义。以分段开关为分界点,依据分界点将配电网拓扑结构分为2部分,从分段开关到系统电源区域侧定义为上游,反之为下游。建立新的开关函数如下:
(9)
式中:∑为“或”运算;U、V分别为分段开关j上游和下游馈线区段总数;Ks1、Ks2分别为分段开关j上游和下游区域电源接入情况;1为有电源接入,否则为0;li、s1、l1,s2分别为分段开关j到上游电源和下游电源所经历的馈线区段状态值;li(u)、li(v)分别为分段开关j上游和下游区域馈线区段的状态值。
2.3 评价函数
评价函数值的大小代表可行解的优良程度,又可以称为适应度函数[21]。评价函数值越小则说明可行解就越优,就越能说明FTU上传的真实值与开关函数推导出来的期望值越符合;评价函数最小值对应全局最优解,即FTU上传的真实值与开关函数推导出来的期望值一致[22]。本文采用的评价函数为
(10)
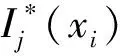
2.4 故障定位流程图
基于上述理论,得到基于自适应蚁群算法的故障定位流程图,如图1所示。
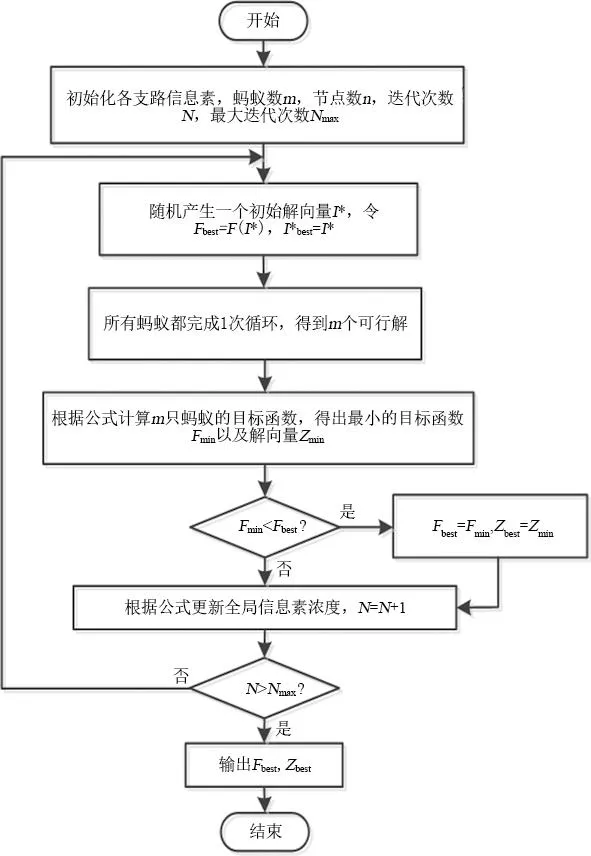
图1 基于自适应蚁群算法的故障定位流程
a. 初始化信息素值,并对自适应算法中的参数进行设置;
b. 找到一个初始解向量I*,并令最优评价函数Fbest=F(I*),最优解向量Ibest=I*;
c. 所有蚂蚁都完成1次循环,得到m个可行解;
d.根据评价函数公式计算m只蚂蚁的评价函数值,对评价函数值进行排序,得到最小的评价函数Fmin及最小解向量Zmin;
e. 对最小评价函数Fmin与最优评价函数Fbest进行比较,如果Fmin比Fbest小,则置Fbest=Fmin、Ibest=Imin,否则进行下一步;
f. 根据公式更新全局信息素浓度,迭代次数加1;
g. 判断是否满足输出条件,满足则得到最优评价函数Fbest及最优解向量Ibest,否则返回步骤b继续进行迭代,直到满足输出条件为止。
3 仿真分析
含分布式电源配电网模型如图2所示,S为系统主电源,DG1、DG2、DG3为接入的分布式电源;k1、k2、k3为分布式电源接入系数,接入时为1,反之为0;L1-L20为馈线区段,馈线区段故障时为1,反之为0;1-20为分段开关,设定系统电源指向负载侧为规定正方向,分段开关处故障电流方向与规定相同取1,分段开关处故障电流方向与规定相反取-1,无故障电流则为0。对比2种算法的性能,使2种算法的参数设置一致,其中蚂蚁数m为50;最大迭代次数Nmax为50;影响因子α和β都为1;挥发因子ρ为0.5;信息素浓度τab(t)初值为0.1;信息素总量Q为0.2;含分布式电源配电网故障定位中,两节点(分段开关)之间的距离与算法求解不相关,转移概率Pab只与节点状态信息素浓度有关,故ηab取1;蚂蚁在转移过程中,第k只蚂蚁在1次循环中做过的路径长度Lk无法计算,因此用该蚂蚁的评价函数值代替路径长度Lk。
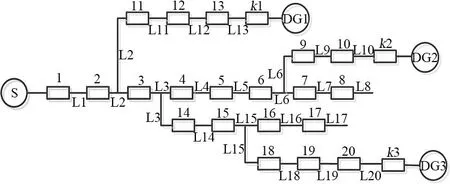
图2 含分布式电源配电网模型
3.1 含分布式电源配电网发生单重故障仿真
基于自适应蚁群算法的基础上,针对单重故障情况下分布式电源接入配电网的个数及分段开关处FTU上传故障信息畸变情况进行仿真,其仿真结果如表1所示。
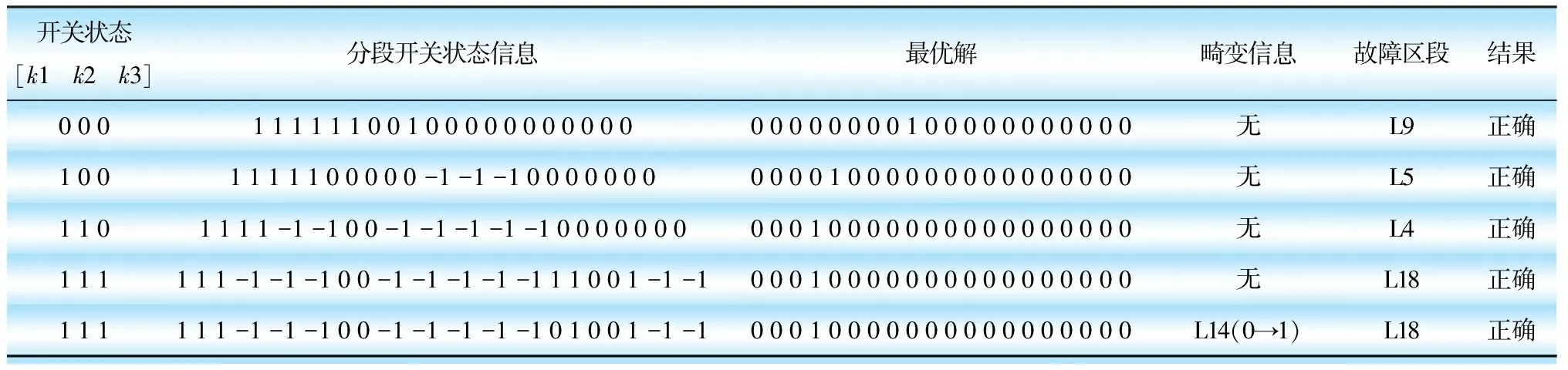
表1 单重故障仿真结果
由单重故障仿真结果分析可知,当无分布式电源接入配电网时,单重故障定位结果准确,说明该算法同样适用于传统配电网单重故障定位。多个电源同时接入配电网且故障信息发生畸变情况下,自适应蚁群算法不受影响仍能准确进行单重故障定位,表明算法容错能力强,准确性高。
3.2 含分布式电源配电网发生多重故障仿真
基于自适应蚁群算法的基础上,针对多重故障情况下分布式电源接入配电网的个数及分段开关处FTU上传故障信息畸变情况进行仿真,其仿真结果如表2所示。

表2 多重故障仿真结果
由多重故障仿真结果分析可知,无分布式电源接入时,其仿真结果与单重故障仿真结果一致,自适应蚁群算法同样适用于传统配电网多重故障定位。多个电源同时接入配电网且故障信息发生畸变情况下,自适应蚁群算法不受影响仍能准确进行多重故障定位,再次表明该算法容错能力强,准确性高的优点。
3.3 传统蚁群算法和自适应蚁群算法对比
当DG1、DG2接入配电网时,且馈线区段L4发生故障且无信息畸变情况下,FTU上传故障编码为[1,1,1,1,-1,-1,0,0,-1,-1,-1,-1,-1,0,0,0,0,0,0,0] ,对2种算法进行仿真试验,其运行结果如图3所示。
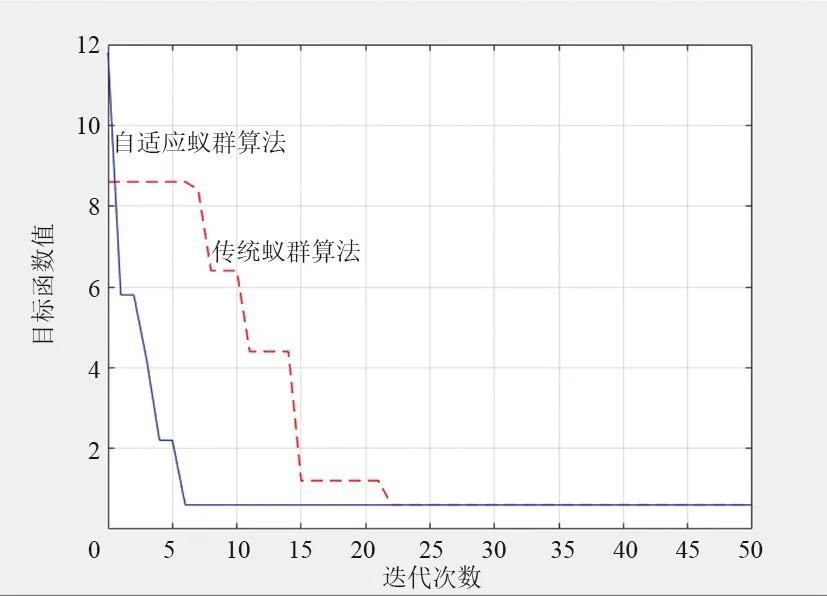
图3 2种算法对比仿真
对比2种算法仿真结果可知,自适应蚁群算法的迭代次数更少,自适应蚁群算法在迭代5次左右时目标函数值最小,找到全局最优解;而传统蚁群算法在迭代24次左右时目标函数值最小,找到全局最优解。
相同条件下,对子2种算法连续进行30次性能对比仿真试验,对比结果如表3所示。传统蚁群算法在30次性能仿真试验中,其中最小、最大迭代次数分别为16、34,平均迭代次数为23.67、平均耗时为0.6561 s;而自适应蚁群算法在30次性能仿真试验中,其中最小、最大迭代次数分别为3、7,平均迭代次数为5.17,平均耗时为0.4979 s;自适应蚁群算法的求解速度比传统蚁群算法提升了24.11%,2种算法都能找到故障区段所在位置,且正确率都为100%。

表3 2种算法性能对比
在DG1、DG2接入配电网情况下,针对单重、多重故障及故障信息是否畸变,对2种算法连续进行30次仿真试验,仿真结果如表4所示。
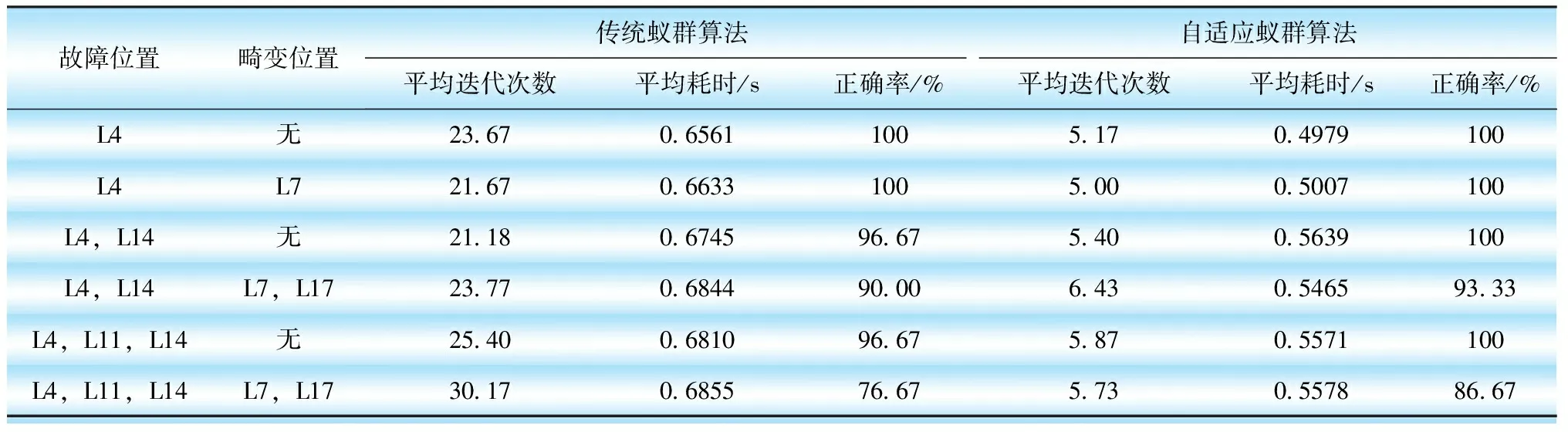
表4 2种算法性能仿真结果
对比2种算法性能仿真结果可知,当多个分布式电源同时接入配电网发生单重故障情况下,无论故障信息是否畸变,自适应蚁群算法和传统蚁群算法准确率都为100%;当多个分布式电源同时接入配电网发生三重故障且有2处故障信息畸变的情况下,自适应蚁群算法比传统蚁群算法求解速度提升了18.63%,准确率提升了10%,验证了自适应蚁群算法具有更快的求解速度和更高的准确率。
4 结语
本文先对传统蚁群算法基本原理进行阐述,针对传统蚁群算法搜索时间长且易出现停滞缺陷问题,提出一种自适应蚁群算法,在传统蚁群算法基础上,改进信息素挥发因子表达式、更换信息素更新机制及限定信息素浓度的取值。在故障定位模型中,先对分段开关和馈线区段处的故障电流信息进行二进制编码操作,分段开关处的FTU实时检测并上传经编码操作的故障电流信息,SCADA系统接收经编码操作的故障电流信息并启动算法进行故障定位,通过构建合适的开关函数和评价函数表达式,通过计算评价函数值,找出最小评价函数值所对应的全局最优解,即找到含分布式电源配电网故障区段所在位置。通过仿真分析,验证了本文提出的自适应蚁群算法不受故障区段数量的影响,且分布式电源个数及故障信息畸变也不影响故障定位结果;又通过对比传统蚁群算法和自适应蚁群算法的仿真结果表明自适应蚁群算法迭代次数更少,求解速度更快;以此验证了自适应蚁群算法具有良好的容错性、快速性。
猜你喜欢
云南画报(2021年11期)2022-01-18
数学物理学报(2021年4期)2021-08-30
小学生学习指导(低年级)(2018年11期)2018-12-03
铁道通信信号(2018年8期)2018-11-10
铁道通信信号(2018年8期)2018-11-10
少儿科学周刊·儿童版(2017年5期)2017-06-29
学苑创造·A版(2017年3期)2017-04-27
太空探索(2016年9期)2016-07-12
铁道通信信号(2016年4期)2016-06-01
学苑创造·A版(2014年6期)2014-08-04
