
基于时空图注意力网络的服务机器人动态避障
2024-02-29 04:39杜海军余粟
计算机工程 2024年2期
杜海军,余粟
(上海工程技术大学电子电气工程学院,上海 201620)
0 引言
随着机器人技术的快速发展,服务机器人的应用由结构化的实验室场景逐渐转移到非结构化的商超、餐厅等场景。非结构化场景中既存在静态障碍物,也存在以行人为代表的动态障碍物。由于行人的意图不能被直接观测,因此机器人和行人之间存在的交互关系很难被建模,提高了机器人在动态环境中的碰撞概率[1]。因此,在动态环境下如何实现机器人避障具有一定的挑战性。
动态避障属于机器人导航系统中的局部路径规划,即在未知的环境中,机器人通过传感器实时探测的数据来规划无碰撞路径,输出速度指令[2]。在现有的研究工作中,服务机器人的动态避障大致分为基于交互的非学习方法和基于学习的方法这两大类。
基于交互的方法包括最佳相互碰撞避免(ORCA)[3]、社会力模型(SF)[4]、动态窗口算法(DWA)[5]等。ORCA 将其他物体建模为速度障碍物,在每一步交互中不断寻找最优无碰撞速度。SF 将行人和机器人的交互关系建模为吸引力和互斥力,通过合力确定机器人的方向和速度。DWA 在划定的窗口中基于机器人的运动学模型采样可行性速度,并根据代价函数选择最优速度。基于交互的方法仅使用当前状态作为决策输入,缺少对历史信息的利用。
基于学习的方法主要以深度强化学习(DRL)[6]为框架,该类方法的核心思想是将机器人避障建模为马尔可夫决策过程(MDP),通过具有隐含编码环境信息能力的神经网络构建强化学习中的价值函数或者策略函数[7-8]。在决策过程中通过最大化累计奖励使服务机器人学会导航和避障。
基于DRL 的学习方法大致分为基于传感器级别的方法和基于代理级别的方法。文献[9]和文献[10]分别使用2D 激光雷达传感器和RGB-D 传感器作为神经网络输入,直接映射出机器人的速度指令。但是,高维度的传感器数据加剧了DRL 的训练时长,此外,原始传感器数据包含的无关信息也会加剧机器人的抖动性。基于代理级别的方法将代理的可观察状态(位置、速度等信息)作为DRL 的输入,然后映射为服务机器人的动作。CADRL(Collision Avoidance with Deep Reinforcement Learning)[11]是较早使用神经网络拟合价值函数解决机器人动态避障问题的算法。为了解决行人数量不一致的问题,GA3C-CADRL[12]采用长短期记忆(LSTM)按照距离由近到远来提取行人特征,然后通过状态价值网络输出机器人动作。文献[13]采用虚拟目标点的方法来解决机器人容易陷入局部最优的问题。但是,以上方法没有充分考虑机器人和行人之间的交互。
随着图神经网络[14-15]在非结构化数据中的广泛应用,服务机器人和行人的关系可以描述为图结构。文献[16]基于图卷积网络(GCN)编码行人-机器人、行人-行人的交互关系。文献[17]基于Structural-RNN(Structural Recurrent Neural Network)构建环境的图结构,采用3 个RNN 网络建模行人和机器人之间的隐式关系。以上方法证明了图结构在非结构化导航场景中的优势,然而这些方法只考虑机器人和行人在空间中的交互性,并没有利用行人的历史消息。文献[18]将注意力机制整合到基于图的强化学习框架中,表征行人对机器人导航的重要程度,但是该方法需要基于人类注视数据集来手动指定邻接矩阵。
为了更好地提取机器人和行人的交互特征,本文从时间和空间2 个维度出发,提出基于时空图注意力网络的避障算法。首先通过GRU[19]来选择性地记忆行人和机器人的历史状态,其次使用GATs[20]编码机器人-行人的空间关系,最后将环境的时空特征送入邻近策略优化(PPO)算法[21],映射出机器人当前时刻的动作指令。
1 基于深度强化学习的避障模型建立
服务机器人的导航环境如图1 所示,服务机器人需要穿过不定数量的行人和静态障碍物实现无碰撞到达目标位置。为了方便建模,将静态障碍物简化为静态行人,将行人和服务机器人统称为智能体。
图1 导航环境示意图Fig.1 Navigation environment schematic diagram
在图1 中,虚线箭头代表智能体根据自身决策形成的运动轨迹。行人和机器人之间没有通信,因此,机器人无法知道行人的运动意图和目的地。
1.1 避障问题建模
服务机器人的导航问题可以表示为强化学习中的序列决策问题,因此,可以将其建模为MDP。MDP 由五元组<S,A,ρ,R,γ>表示,其中:S代表环境的状态集;A代表机器人的动作集;ρ代表状态s∈S转化为状态s'∈S的状态转移函数;R表示累计奖励;γ∈(0,1)表示折扣因子。根据MDP 的定义,机器人在t时刻与环境交互得到状态st,策略π从动作集A中选择最大概率的动作at,并得到即时奖励rt,然后根据状态转移函数ρ得到下一状态st+1。强化学习的目标是寻找最优策略π*,使累计奖励R最大化,如式(1)所示:
其中:Rt(st,at)代表在t时刻机器人根据状态st执行动作at后得到的即时奖励;ρ(st+1|(st,at))代表根据状态st和动作at转移到下一个状态st+1的概率;V*(st+1)代表状态st+1的最优价值函数[6]。
1.2 状态空间
状态空间指整个环境中可能存在的所有状态的集合。在本文中,智能体的状态信息由被观测状态和隐藏状态组成。被观测状态指能被其他智能体通过传感器的形式直接或者间接得到的信息,包含位置p=[px,py]、速度v=[vx,vy]、半径δ。隐藏状态指只有智能体本身能获取、其他智能体无法获取的信息,包括目标坐标g=[gx,gy]、期望速度vpref、朝向ϑ。假设在t时刻环境中的智能体数量为m(m>0),则状态空间如式(2)所示:
为了保证状态空间不受旋转、平移的影响,将全局坐标系转化为以机器人质点为中心、x轴正方向指向目标位置的机器人坐标系[22]。转化后的状态空间如式(3)所示:
其中:dg=||p-g||为机器人到目标的距离;d=||p0-pm||为第m个行人与机器人的距离。
1.3 动作空间
在t时刻服务机器人的动作at被定义为:
其中:vt为机器人的线速度;wt为机器人的角速度。本文动作空间采用离散形式,即将vt在[0,vpref]内均匀离散为6 个值,将wt在内均匀离散为9 个值,因此,服务机器人的动作空间含有54 个不同动作。
1.4 奖励函数
奖励函数是强化学习中的重要一环,它是指导和评估智能体动作好坏的重要指标之一。文献[12]提出以机器人避免碰撞为目标的奖励函数的基础形态,但是,该奖励函数旨在解决2 个非通信智能体之间的导航问题,随着场景的扩大,训练的收敛性变差[23-24]。本文的奖励函数由到达目标奖励rtg、碰撞奖励rtc、与所有行人保持安全距离奖励rts这3 个部分组成。t时刻奖励函数定义如下:
2 避障算法
本节首先将导航场景构建为时空图,其次建立时空图注意力网络作为决策函数,最后介绍基于策略PPO 算法。
2.1 时空图
本文将导航场景建模为时空图,如图2 所示。在t时刻的时空图表示为,其由节点n∈N、时间边es∈ES、空间边eT∈ET组成。如图2(a)所示,圆圈代表节点,实线代表空间边关系,虚线代表时间边关系。时空图中的节点为智能体,空间边连接机器人和其他行人,代表机器人-行人的交互关系,时间边连接相邻时刻的相同智能体,代表智能体自身对历史信息的记忆关系。时空图展开如图2(b)所示。

图2 导航时空图Fig.2 Navigation spatio-temporal graph
本文的目标是学习时间边和空间边的特征,如图2(c)所示,其中,黑色方框和灰色方框代表需要学习的参数。为了减小参数量,空间边共享参数,和行人节点相连的时间边共享参数,该方法使时空图具有伸缩性,可以处理不同时刻、智能体数目不一致的问题[17]。
2.2 时空图注意力网络结构
本文使用神经网络拟合策略函数π,该神经网络的输入为服务机器人观测的环境状态,输出状态价值和离散动作概率aprob。网络结构分为时间特征网络、空间特征网络和Actor-Critic 网络。网络结构如图3 所示。

图3 时空图注意力网络结构Fig.3 Structure of spatio-temporal graph attention network
2.2.1 时间特征网络
如图3(a)所示,时间特征网络主要由2 个GRU网络构成,用于捕获智能体自身的时间信息。GRU使用门控制信息流,以确定序列中信息被记忆或被丢弃,使网络具有保存机器人和行人重要历史信息的能力[19]。另外,GRU 网络参数少,方便训练。
首先对机器人和行人进行非线性变换,然后将变换结果输入GRU 单元,得到隐藏输出状态,计算如式(9)所示:
其中:为服务机器人在t时刻的隐藏状态;为第i个行人在t时刻的隐藏状态;f(·)代表全连接网络。根据第2.1 节所述,所有和行人相连的时间边共享网络参数,因此,所有行人的状态均会通过GRUh网络。时间特征网络可以同时解决记忆问题和机器人状态空间与行人状态空间维度不一致的问题。
2.2.2 空间特征网络
如图3(b)所示,空间特征网络由GATs 网络构成。GATs 网络由多层图注意力层组成,利用注意力机制,中心节点可以自动学习其一阶邻居的重要性,并根据注意力权重更新中心节点的节点特征。GATs 的参数在节点之间共享,因此,可以接收任意数量的节点作为输入,能够解决导航过程中智能体数量在不同时刻不一致的问题。首先将时间特征网络的输出作为机 器人节点的节点特征,将作为第i个行人节点的节点特征。机器人节点和行人节点之间存在边的关系,行人和行人之间不存在连接关系。每条边之间存在相应的注意力权重,节点i对节点j的注意力值cij计算如式(10)所示:
其中:A={Aij}为时空图的邻接矩阵;||为矩阵的连接操作;W是对输入节点特征进行线性变换的可学习参数;aT为GATs 的可学习参数。参数W、aT将在深度强化学习中学习。
对注意力值cij进行归一化,得到注意力权重αij,计算如式(11)所示:
其中:Ni表示节点i的一阶邻居节点。
根据注意力权重αij计算其他节点对于节点i的影响特征,计算如式(12)所示:
其中:σ为非线性激活函数。因为单头注意力机制在学习过程中不稳定,所以采用多头注意力机制来提高算法的稳定性,即对式(12)独立计算K次,然后求平均,得到平均输出特征,计算如式(13)所示:
最后,可以得到聚合后的机器人特征,其聚合了周围行人节点的特征。
2.2.3 Actor-Critic 网络
本文使用策略梯度算法中的PPO 算法[21],该算法使用Actor-Critic 框架,Actor 网络学习动作,Critic网络评价动作的好坏[25]。PPO 为同策略,不依赖专家经验,学习出来的策略更适合高动态的环境。
Actor-Critic 网络均使用全连接层。Critic 网络输出价值标量用于评估动作的好坏,Actor 网络输出离散动作概率。最后选择概率最大的动作at作为服务机器人的运动指令。上述计算如式(14)所示:
2.2.4 PPO 算法
PPO 算法的主要目标是从策略函数π中寻找最优策略函数π*。PPO 算法使用策略函数πθ'(at|st)作为采样 策略去 采集轨 迹{st,at,rt,st+1},其 中,θ'为 旧网络参数,在采集过程中为固定值。当采集到一定数量的轨迹后训练策略函数πθ(at|st),得到新的网络参数θ。在θ更新一定次数后,使用新网络参数θ去更新旧网络参数θ',保证采样策略和评估策略满足重采样定理。整个策略网络的优化目标如式(15)所示:
其中:θ为优化参数;ρθ(at|st)为策略参数θ下根据状态st执行动作at的概率;ρθ'(at|st)为策略参数θ'下根据状态st执行动作at的概率;Aθ'(st,at)为策略参数θ'下根据状态st和动作at计算的优势函数。参数采用梯度上升方式进行更新,如式(16)所示:
3 实验验证
本节主要实现时空图注意力网络训练,并将所提算法和其他相关避障算法进行对比,以验证该算法的可行性和有效性。
3.1 仿真环境设置
仿真环境基于Gym 搭建,行人的运动模型采用全向模型,通过ORCA 策略进行控制。本文假设机器人对于行人处于隐藏状态,即行人“看不见”机器人,避免出现机器人强迫行人避障的极端现象[18]。仿真环境采用半径为4 m 的圆,所有智能体的起始点和目标点关于原点对称并位于圆周上。为保证环境的多样性,在每一个回合中智能体的起始点、目标点随机,并且智能体之间存在最小0.5 m 的间距,行人数量随机,范围为[7,12]。
在训练过程中,训练批次为16,选取Adam[26]作为优化器,折扣因子γ=0.98,学习率初始值为3×10-4,学习率随着训练回合数而线性递减,训练步数为2×107,优势函数的估计采用GAE(Generalized Advantage Estimation)[21]。时间特征网络中的f1(·)、f2(·)网络参 数均为[32,64],GRUr(·)、GRUh(·)网络参数均为[64,64]。空间特 征网络采用2 个GATs(·),网络参数为[64,128,64]。Actor-Critic 网络中的f3(·)、f4(·)网络参数分别为[64,32,16,1]、[64,128,64,54]。
为了方便叙述,将本文所提基于时空图注意力网络的避障算法命名为STGAT-RL。选取非学习型避障算法DWA[5]、学习型避障算法CADRL[11]和基于时空图的算法DSRNN-RL[17]作为对比。为了分别证明时间特征网络、空间特征网络的有效性,采用只包含时间特征的RNN-RL、只包含空间特征的GATRL 进行消融实验。
CADRL 采用基于价值的Q-learning 算法来实现,价值网络使用4 层全连接网络进行拟合,网络参数为[150,100,100,4],其中的4 代表机器人的输出为4 个离散动作。DSRNN-RL 采用基于策略的PPO 算法来实现,首先将行人和机器人的关系建模为时空图,然后转化为因子图,因子图中包含时间边因子、空间边因子和节点边因子,每个因子使用RNN 进行学习,网络大小分别为[64,256]、[64,256]、[128,128],动作空间为连续空间,PPO 相关参数和STGAT-RL保持一致。在评估时,所有算法的奖励函数和本文算法保持一致。
为了表征导航能力,使用成功率(SR)、碰撞率(CR)、超时率(TR)、导航时间(Navigation Time)、导航距离(Dis)、奖励(R)作为评价指标,各指标详细描述如下:
1)成功率:机器人成功到达目标的比例。2)碰撞率:机器人和其他智能体发生碰撞的比例。3)超时率:机器人未在规定时间内到达目标的比例。
4)导航时间:机器人在安全到达目标前提下的平均导航时间,单位为s。
5)导航距离:机器人在安全到达目标前提下的平均导航距离,单位为m。
6)奖励:机器人在安全到达目标前提下的平均奖励。
3.2 图注意力机制分析
为了验证图注意力机制的有效性,本文在含有10 个智能体的环境中分别捕获机器人进入人群和离开人群的瞬间,如图4 所示。其中,实心圆代表机器人,空心圆代表行人,圆圈中的直线表示智能体的瞬时朝向,圆圈旁边的数值代表机器人对行人的注意力权重,实心五角星代表机器人的目标位置。

图4 机器人对行人的注意力值Fig.4 The attention values of robots towards pedestrians
图4(a)为3.8s时刻的注意力权重示意图,代表机器人刚进入人群的时刻。由于行人2、行人3 和行人5 离机器人最近并相对而行,因此机器人给予这3 位行人较大的注意力权重,说明图网络提取机器人和行人的隐式交互特征能防止机器人发生即时碰撞。另外,行人7 虽然离机器人较远,但是相对而行,是潜在的碰撞目标,因此,机器人也对其赋予较大的注意力权重,说明GRU 网络依据行人的历史轨迹,对其有一定的预测作用,可以防止机器人发生潜在碰撞。图4(b)为6.1 s 时刻的注意力权重示意图,代表机器人刚离开人群的时刻。此时机器人和行人背道而驰,注意力权重基本上按照距离递减,说明机器人不再关心碰撞,目标位置为导航的主要影响因素。
3.3 基于导航轨迹的定性分析
为了显示不同导航算法的运动规律,本文基于导航轨迹进行定性分析,设定含有10 个智能体的环境,智能体的初始位置固定,可视化6 种不同导航算法的运动轨迹,如图5 所示,其中实线代表机器人的轨迹,虚线代表行人的轨迹,圆圈上的数字代表智能体到达该位置的时刻。
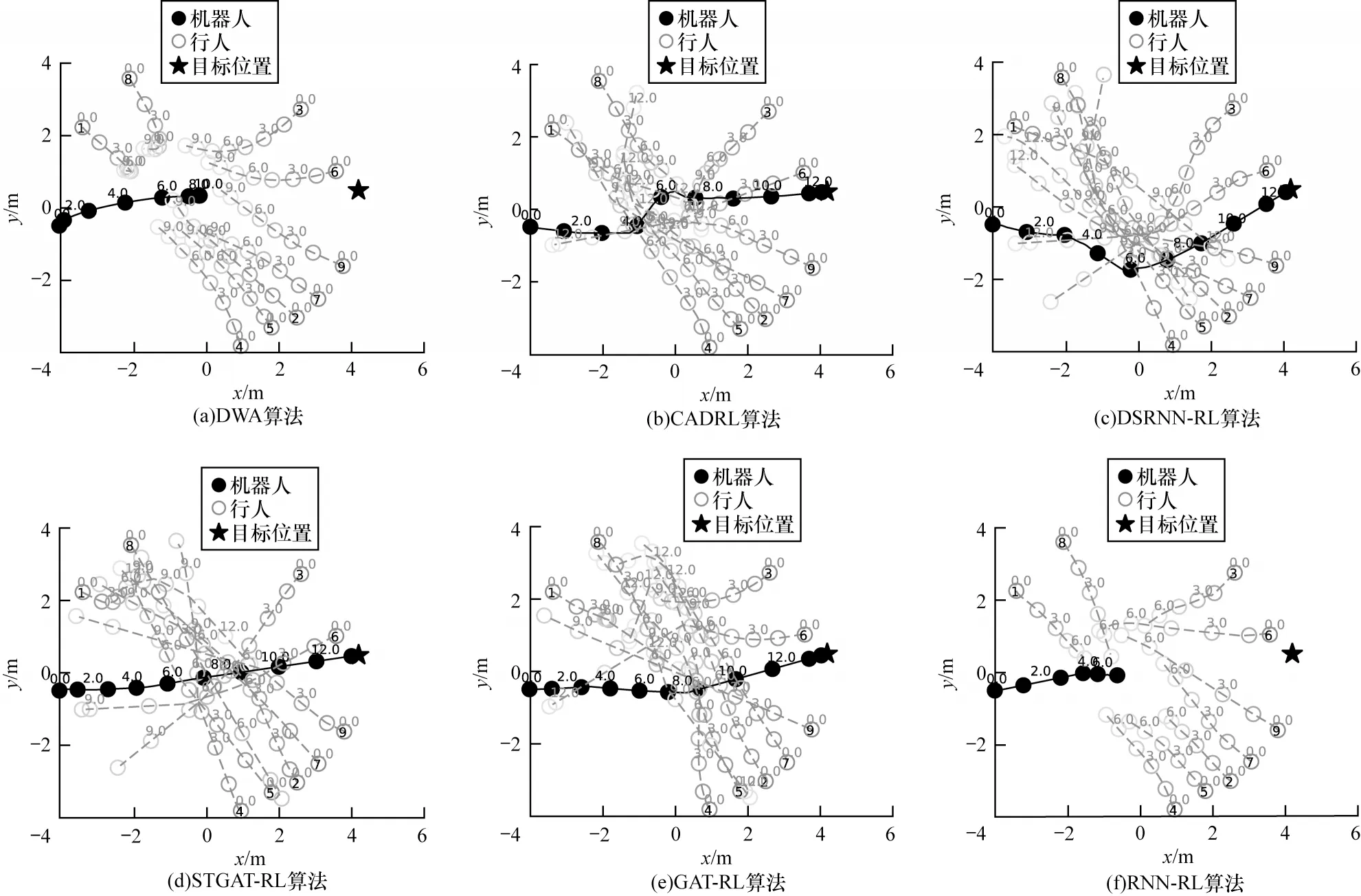
图5 机器人导航轨迹Fig.5 Robot navigation trajectories
1)对比实验分析
图5(a)为DWA 算法的运动轨迹,在DWA 算法的决策下机器人不能突破行人到达目的地。DWA需要在采样窗口中根据可行性速度计算可行性轨迹。然而,在行人密集的中心区域,机器人无法找到可行性轨迹,从而导致碰撞或者假死;图5(b)是CADRL 算法的运动轨迹,在CADRL 的决策下机器人成功到达目的地,由于CADRL 未获取机器人和行人之间的关系特征,因此在人群密集的环境中发生较大的转向,导致轨迹不平滑;图5(c)是DSRNN-RL算法的运动轨迹,该算法通过3 个RNN 网络解析时空图,机器人学会提前转向,绕过行人可能聚集的中心点,以弧线轨迹到达目标;图5(d)是本文STGATRL 算法的运动轨迹,该算法通过GRU 提取环境的时间特征,使机器人前期通过提前减速来观测行人运动趋势,防止进入中心密集区而发生碰撞,中期通过GATs 获取行人的空间信息,实现无碰撞穿过密集人群,后期由于机器人观测前方无行人,则加速到达目的地。通过对比实验可以看出,非学习的DWA 算法无法应对高动态场景下的避障任务,基于学习的CADRL 和DSRNN-RL 算法可以实现动态避障,本文提出的基于时空图注意力网络的学习算法在实现避障的同时,可以使运动轨迹更加平滑。
2)消融实验分析
图5(e)为空间网络GAT-RL 算法的决策轨迹,图注意力网络获取行人和机器人的空间关系特征,并通过注意力权重对不同方位的行人赋予不同的关注度,使其能完成无碰撞导航任务,和STGAT-RL 算法的轨迹相比,GAT-RL 算法的轨迹较长;图5(f)是只有时间网络的RNN-RL 算法的决策轨迹,由于RNN 只抓取机器人和行人的时间特征,相当于机器人对行人有隐式的预测能力,因此机器人只学会通过减速来避免碰撞,导致导航任务失败。通过消融实验可以看出,空间网络在时空图注意力中发挥主导作用,保证机器人能实现避障,时间网络起辅助作用,通过隐式预测并以减速的方式提前规避障碍物,从而平滑机器人的运动轨迹。
3.4 定量分析
由于定性的轨迹分析存在一定的偶然性,因此使用第3.1 节提出的6 种评价指标进行定量分析。鉴于强化学习的随机性特点,本文对于不同算法均在含有10 个智能体的测试环境中运行500 个回合,实验结果如表1 所示,最优结果加粗标注。

表1 定量分析实验结果 Table 1 Experimental results of quantitative analysis
从表1 可以看出,本文STGAT-RL 算法成功率最高,碰撞率最低,导航路径最短。和相类似的DSRNN-RL 算法相比,STGAT-RL 成功率提高3 个百分点,碰撞率降低2 个百分点,导航路径减少0.21 m。虽然STGAT-RL 的导航时间较长,但是考虑到碰撞带来的人身伤害和机器损伤,导航时间增加1.76 s 可以接受。
3.5 稳定性分析
为了验证算法的稳定性,本文在智能体数量分别为5、10、15、20 个的环境中统计CADRL、DSRNN-RL、STGAT-RL 和DWA 的成功率,统计结果如表2 所示。
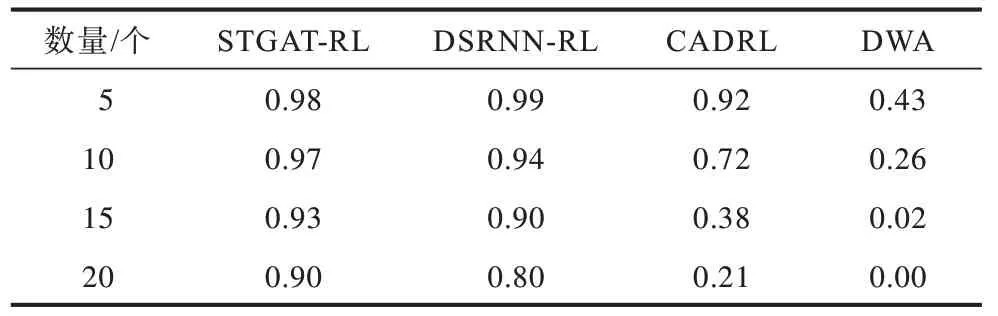
表2 不同智能体数量下算法的成功率对比 Table 2 Comparison of success rates of algorithms under different numbers of intelligent agents
从表2 可以看出:随着智能体数量的增加,本文STGAT-RL 算法均保持0.90 以上的成功率;DSRNNRL 算法在智能体数量增加到20 时成功率出现大幅下降;CADRL 算法在行人增加到10 个时成功率出现大幅下降;当行人数量过多时,DWA 算法由于规划轨迹无解,大多以超时结束,成功率极低。上述结果表明本文算法在高密度环境中有较好的稳定性。
3.6 实时性分析
由于Gym 仿真环境假设算法规划的速度指令可以瞬时实现,无运动规划模块,不符合实时导航需求,因此本文在Gazebo 环境中验证算法的实时性。仿真机器人使用Xbot-U,机器人的运动规划使用ros_control 软件包实现,算法所需的状态信息通过服务“/gazebo/get_model_state”获取。电脑的GPU 为GeForce RTX3060,CPU 为Intel®CoreTMi7-11700F@2.40 GHz,在Gazebo仿真环境中,在GPU 和CPU 上分别运行100个回合,统计每个回合中每一步STGAT-RL的推理时间和导航时间,结果如表3 所示。

表3 算法运行时间统计结果Table 3 Running time statistics of the algorithm 单位:ms
从表3 可以看出,在CPU 下,STGAT-RL 的推理时间最大为70.28 ms,平均为21.90 ms。ROS 的navigation 堆栈中负责速度指令发送的move_base 包对速度指令的更新时间默认为50 ms,说明本文算法满足实时性要求。此外,由于ROS 通信机制的影响,在GPU 上的导航时间无明显提升。
4 结束语
本文针对动态环境中的机器人避障任务,利用强化学习强大的决策能力,提出基于时空图注意力机制的动态避障算法。使用GRU 网络提取环境的时间信息,使机器人对行人有隐形预测能力,平滑运动路径;使用GATs 网络获取机器人的行人空间特征,使机器人具有避障能力,实现无碰撞导航。实验结果表明,相比DSRNN-RL 算法,该算法的成功率提高3 个百分点,碰撞率降低2 个百分点,并具备实时导航能力。下一步将重点关注强化学习的sim-to-real问题,将避障算法部署在实物机器人上。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
意林(2021年5期)2021-04-18
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
扬子江(2019年1期)2019-03-08
现代装饰(2018年5期)2018-05-26
传媒评论(2017年3期)2017-06-13
中国三峡(2017年2期)2017-06-09
小天使·一年级语数英综合(2017年6期)2017-06-07
第二课堂(课外活动版)(2016年2期)2016-10-21
