
玉米品种图像识别中的影响因素研究
2012-11-23 03:46韩仲志杨锦忠李言照
中国粮油学报 2012年10期
韩仲志 杨锦忠 李言照
玉米品种图像识别中的影响因素研究
韩仲志1杨锦忠2李言照1
(青岛农业大学理学与信息科学学院1,青岛 266109)
(青岛农业大学农学与植物保护学院2,青岛 266109)
为了研究玉米品种图像识别中的关键影响因素,搭建了一套基于PCA和ICA特征提取和支持向量机(SVM)分类算法的玉米品种识别系统,采用扫描仪获得了11个品种每个品种50粒图像,基于图像的像素特征和统计特征,分别研究了主分量分析(PCA)和独立分量分析(ICA)的特征提取和特征优化方法,并进一步考察了支持向量机(SVM)模式分类过程中的关键参数优化问题。试验结果表明,对11个品种550个籽粒的品种最高检出率为97.17%,在同样的情况下ICA优化的特征较PCA优化的特征识别率能提高3%左右,适当选择统计特征比使用像素特征识别率提高约10%,另外SVM参数影响到识别效果,但整体影响不大。本方法与结论对玉米种子纯度和品种真实性检验具有积极意义。
玉米种子 品种识别 独立分量分析 主分量分析 支持向量机
在很大程度上,作物种子的品种真实性决定着农业发展,正确识别种子是种子特异性、一致性和稳定性(DUS)测试的重要内容之一。
前人对种子识别的研究一般着重于粒重、容重、粒长宽与粒厚、体积与密度等数量性状(特征)。这些特征的提取一般基于大田试验手工进行,特征的获取速度慢、代价大,从而制约了种子检验的效率;近年来,基于计算机数字图像处理的机器视觉检测是一种检测速度快、鉴别能力强、重复性高、可大批量检测、无疲劳的新方法。在水稻[1]、小麦[2]和花生[3]等作物上都有成功应用的报道。
在玉米科学上,杨锦忠等[4-5]基于图像的外观表现型提取了数十个特征,特征中包括了反应种子大小、形状、颜色和纹理等几大类,这些特征的提取基于种子外观图像,采用软件的方法,速度快,鉴别能力强,大大提高了种子检验的效率和速度。韩仲志等[6]采用独立分量分析的方法提取了玉米胚部的特征提取方法,另外进一步研究了果穗DUS测试中的特征提取方法[7],最近他们针对玉米果穗的外观表现,开展了特征与品种的关系的研究[8-9],并从中优选出了一些对品种鉴别力有影响的关键性状,取得了可喜的成果。而在玉米籽粒检测领域没有发现针对品种关键特征选择与优化方面的研究报道。
以往研究者面对数十个上百个特征,而这些特征或某种组合往往决定这某个生物性状,且特征间存在着较大的相关性,使得品种识别时出现大量信息庸余而加重了处理负担。事实上并不是所有的特征都对种子的检验起重要作用,所以有必要进一步明晰特征与生物性状之间的关联,自动寻找对生物性状起关键作用的特征将成为一个有挑战性的课题。另外在品种识别过程中,识别效果必然受到所选特征及其提取和优化方法的影响,进一步优化方法,将有助于提高计算机品种识别的性能与效率。由此本研究拟针对上述问题进行研究,以进一步明晰不同类型的特征、不同类型的特征提取和优化方法及识别方法下对品种真实性及DUS检验效果的影响。
1 材料与方法
1.1 试验材料
供试的普通玉米品种共有11个,主体色调均为黄色,全部来自国家东北和华北区玉米新品种区域试验的参试品种,每个品种挑选具有品种固有特征的50粒种子。用扫描仪采集图像,扫描时按固定次序与方向将种子摆放于扫描仪上,为了使图像背景为黑色,扫描仪盖板完全打开,扫描得到每个品种50粒种子的正面(有胚面)的图像,篇幅所限,图1仅列出了其中一个品种的扫描图像。
扫描仪型号为CanoScan:8800F,平板式CCD扫描仪,光学分辨:4 800dpi×9 600dp;使用的计算机为联想:ideaCentre Kx 8160:CPU为Intel酷睿2四核Q8300 2.5GHz,内存DDRIII4G;闪存1 G,硬盘500 G;Winows Vista操作系统。

图1 一个品种的扫描图像
对扫描所得图像进行必要的预处理,这些预处理包括图像的颜色空间转换、灰度化、二值化、背景去除和边缘检测,所有图像处理、特征提取和识别过程均基于软件Matalb2008a编程实现。
1.2 特征提取
特征的提取是基于图像进行的,工程上一幅图像可看作是一个矩阵,每个像素点的取值便构成了最原始的特征,称为像素特征,像素的分布蕴藏了图像的所有信息,图像信息量的大小与图像分辨率正比,然而图像分辨率越大,构成这种特征数据量越大,计算机实时分析处理越困难。比如一副1024×768的图像,仅灰度图像的特征量数目就达到786 432个。虽然可以通过图像压缩减少数据量,但压缩过程同样使得信息大量丢失。因此选择合适的降维优化方法尤为重要。为了降低数据量,采用不同的统计方法,亦可得到一系列的统计特征。玉米的统计特征可针对整个籽粒和籽粒的胚部分别提取。胚部的分割方法参可见文献[6]。统计特征主要从颜色、形状和纹理3个角度考虑,本研究采用不同的指标统计了相应籽粒及其胚部各60个特征,这些特征见表1,相关定义可参见文献[1-2,6]。种子形态特征直接从最终二值图上获取,颜色特征分别从RGB和HSI彩色图获取,纹理特征可依据灰度图像获取。胚部统计特征基于胚的分割图像进行,同样提取其60个特征,这样衡量每个籽粒的总特征数达到120个。虽然这个数量远小于像素特征,然而随着统计指标的增加,统计特征的维数相应的增加,因此也需要进行必要的降维和特征优化。

表1 统计特征
1.3 特征优化
传统的特征降维与优化是基于二阶统计量进行的主分量分析(PCA)方法[10],PCA是统计学中分析数据的一种有效的方法,其目的是在数据空间中找一组向量以尽可能地解释数据的方差,将数据从原来的R维空间降维投影到M维空间(R>M),降维后保存了数据中的主要信息,从而使数据更易于处理。PCA方法是沿数据集方差最大方向寻找一些相互正交的轴,主成分分析方法是一种最小均方误差下的最优维数压缩方法。
近几年发展了一种新的数据降维和优化方法,独立分量分析(ICA)方法[11],ICA算法是一种基于高阶统计信息的多元数据处理方法,其基本思想是用一些基函数来表示一系列随机变量,而假设它的各成分之间是统计独立的或者尽可能独立,这种方法将不限制这些轴是否正交,它的轴是沿最大统计独立方向,因此,其输出元素之间的相关性被移走,这样,在这些轴上的投影就有很少的交叠产生。
1.4 品种识别
特征提取和优化后,特征维数将进一步减少,基于这些特征可实时进行品种识别,支持向量机(SVM)模型[12]是近几年发展起来的优秀的识别模型,在农作物种子识别领域已经证明比神经网络识别模型具有更为稳健的性能[3]。
支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力。支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离或差距越大,分类器的总误差越小。
2 结果与分析
2.1 特征分布
图2分别列出了采集的原始像素特征和部分统计特征的频数分布图,考察这些特征的分布可以发现大部分特征遵从非高斯分布。

图2 部分特征的分布频数分布图
2.2 像素特征优化
常规特征优化方法为基于PCA的方法,它能够在正交意义上寻找代表图像的最大主分量组合,然而PCA是基于图像二阶统计量取得,通过考察图像的像素分布和统计特征分布,并不严格意义上服从高斯分布(图2),所以图像中很多信息在更高阶统计量意义上也有表现。而ICA正是反映了图像的高阶统计特性。可考虑用ICA进行特征降维。
为考察PCA和ICA这两种数据降维方法有效性,首先从扫描图片上将单个籽粒分割出来,并用线性插值法将单个籽粒的分割图片规格化为相同的大小(300×250=7500维),若采用PCA和ICA将数据压缩为20维,则数据压缩为原来的2.7%,此时与原始图像的标准差异分别为3.36%和2.53%。数据降维后的20维主分量图3a和20维独立分量如图3b,分量图像上的高亮区域往往代表着品种间的差异区域。当然,压缩成的维数越大,与原图像差别越小,识别结果越准确,但数据量也相应的增加,识别效率变低。
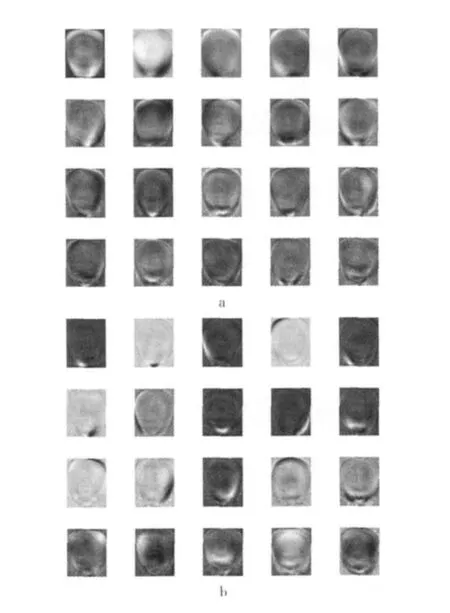
图3 20维PCA和ICA分量
2.3 统计优化特征
在进行品种识别时,每个统计特征都有一定的判决能力,如果用单个特征进行识别,则判决能力最强的特征可以作为品种间最大差异性状。但是仅用一个特征往往不能有效区分多个品种。在使用模式分类系统进行诊断的时候,所用的特征越多,识别的正确率越高,但检测的特征越多,花费的成本也越大。可见应该用尽量少的特征来进行品种识别是一个重要问题。数学上,可使用ROC(Receiver Operator Characteristic)曲线下的面积大小来对单个元素的判决能力进行评价,如图4是对品种1和品种2识别时能力最强和能力最弱的2个特征ROC曲线,相应的ROC曲线面积在表2中列出。

图4 2个品种间不同特征的ROC曲线

表2 统计量和两类ROC面积
可见ROC在单特征判决力分析上是有效的,然而这种方法只能用在两类分类中,在品种较多时受到限制。
2.4 品种识别
在启动SVM进行识别之前,需要确定使用哪种核函数,然后就是确定核函数的参数gama及错误代价系数C的最佳取值。鉴于卓越的非线性分类性能,这里选择了RBF核函数,采用文献[13]的交叉验证和网格搜索的参数选择方法对这2个参数进行自动搜索。当采用基于统计特征时,使用前20个特征组合时,得到的C=512.0;gama=0.001 953 125,而对像素特征的前20个特征特征组合,优化的参数为C=2 048,gama=0.000 122 070 312 5。表3是采用训练集上的交叉验证法,在最优参数的情况下,采用不同类特征、不同的特征选择和优化方法,及在不同特征维数情况下的识别效果和识别时间。可以看出,统计特征较像素特征、ICA特征优化较PCA特征优化均具有更好的识别性能。

表3 特征类型对识别效果的影响
表4是采用统计特征、在不同数量样本容量、在不同的优化参数情况下的识别效果ICA优化特征识别效果。
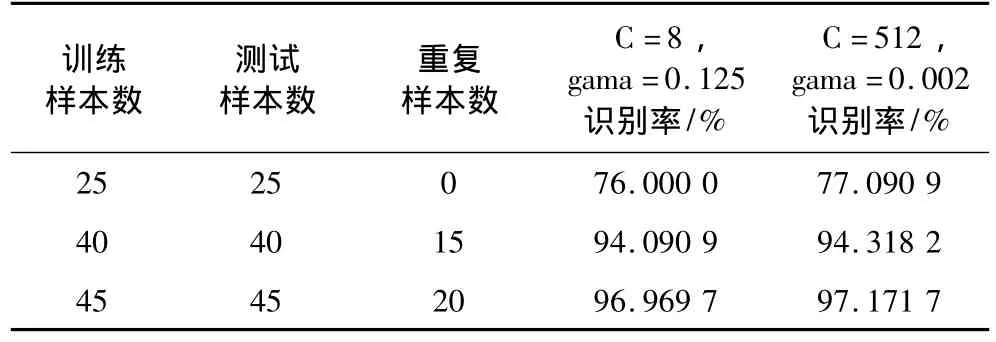
表4 样本数量和参数对识别率的识别效果的影响
从表4中可以看出:样本的大小在一定程度上会影响到识别结果,可以预见,当训练样本集较大时识别系统会更为稳健,同时识别过程中的参数优化会影响到识别效果,但影响不大,只在1%左右。
3 讨论
由于种植环境的不同在种子外观表现出不同的外观差异。植物器官的大小取决于细胞的分裂与生长,形状主要依赖于细胞分化,颜色则与显色物质的代谢密切相关,纹理则是细胞分裂、生长、分化与代谢相互作用的最终形态体现。而品种识别率与广义遗传力之间存在高度的正相关关系[8]。
本研究处理的对象是通过扫描仪获取的群体玉米籽粒的照片,要进行玉米种子检验,首先要进行籽粒的分割,将单个籽粒提取出来,本研究所用的方法是采用区域标记提取,但应注意在提取籽粒区域的时候经过反复试验选择是像素点数大于3 000的为玉米籽粒的区域,这时能够将550个籽粒完全分割出来,分割成功率为100%,当此数值的大小会影响到分割的效果,试验中,当此值过小时,会将一些籽粒的尖端区域单独分割为一个图像,可见这个是不合适的,但也从另一个角度说明尖端也可作为玉米品种识别的一个重要特征。
对于玉米特征的提取,可以采用像素灰度值作为原始特征,图3是20维是主分量和独立分量图像,从分量图像可以看出:玉米籽粒图像之外的背景较暗,这是因为扫描时打开了扫描仪盖板,使得背景为黑色,所以各个品种在扫描时背景较为均匀一致。原始空间中样本背景差异较小,所包含的信息差异少,而图3中的一些高亮区域即为品种差异比较大的区域,轮廓,尖端,胚部在品种间差异较大,这与经验相符合。
从图4所反映的ROC面积可以看出,单个元素的判决能力差别很大,而椭圆度和B均值的判决能力都达到了95%以上,可见这是2个最为优秀的特征,在籽粒品种外观上表现出椭圆的程度不同,这与经验一致,另外由于所选品种主题色调为黄色,差异较小,而在其他颜色空间的差异较大,如B的均值差异就是一个很好的特征元素。
籽粒在重建过程中随着PCA维数的增加重建差距减小,当为200维度时差异为3.36%,基本与源图像没有差别,但这时数据已经被压缩为200/7 500=2.67%,大大减少了后续运算的负担。
本研究使用了两类特征,一种是直接通过像素点的值测得,这种特征容易理解,获取非常方便,第二类是采用通过图像运算提取出来的特征,有基于颜色、形态和纹理的特征120个,通过PCA运算提取前20个主分量进行检测,交叉验证法得到的识别率分别为84.1%和94.7%,后一种特征比基于想素的特征提高了10%,可见通过精心的筛选特征将在很大程度上提高识别效果。作者曾尝试玉米胚部的特征筛选,可以提供更多有价值的候选特征参量[6]。另外SVM模型的C和gama的取值影响到识别效果,表4中第一组C=8这是随意指定的,C=512是通过优化算法优化后的结果,识别效果上,优化的参数下识别率较高,平均提高约0.3%。此外训练样本和测试样本数影响到识别效果,训练样本集越大识别效果越好,当然,一般情况下只要满足一定的数值(如100),即可满足小样本检验的需要。
4 结论
种子的品种真实性种子质量检验的重要指标,种子品种的正确识别是进行种子检验的前提,识别过程中提取的特征,同时也为DUS测试提供了重要数据。基于图像处理方法,研究了一种基于玉米外观特征和多变量支持向量机(SVM)分类算法的玉米品种识别方法。通过对采用扫描仪获得了大量图像,提取了图像的像素特征和统计特征,分别研究了主分量分析(PCA)和独立分量分析(ICA)的特征提取和特征优化方法,并进一步考察了支持向量机(SVM)模式分类过程中的关键参数优化问题,由此建立了一种玉米品种识别模型。试验的结果表明,该模型对11个品种550个籽粒的品种检出率为97.17%,在同样的情况下ICA提取的特征较PCA提取的特征识别率能提高3%左右,适当选择外观特征比使用像素特征识别率提高约10%,另外SVM参数影响到识别效果,但整体影响不大。本方法与结论对玉米种子检验和DUS测试都有积极的借鉴意义。
[1]Sakai N,Yonekawa S,Matsuzaki A.Two-dimensional image analysis of the shape of rice and its application to separating varieties[J].J Food Eng,1996,27:397-407
[2]Dubey B P,Bhagwat SG,Shouche SP,et al.Potential of artificial neural networks in varietal identification using morphometry of wheat grains[J].Biosyst Eng,2006,95(1):61-67
[3]韩仲志,赵友刚.基于计算机视觉的花生品质分级检测研究[J].中国农业科学,2010,43(18):3882-3891
[4]郝建平,杨锦忠,杜天庆,等.基于图像处理的玉米品种的种子形态分布及其分类研究[J].中国农业科学,2008,41(4):994-1002
[5]杨锦忠,郝建平,杜天庆,等.基于种子图像处理的大数目玉米品种形态识别[J].作物学报,2008,34(6):1069-1073
[6]韩仲志,赵友刚,杨锦忠.基于籽粒RGB图像独立分量的玉米胚部特征检测[J].农业工程学报,2010,26(3):222-226
[7]赵春明,韩仲志,杨锦忠,等.玉米果穗DUS性状测试的图像处理应用研究[J].中国农业科学,2009,42(11):4100-4105
[8]杨锦忠,张洪生,郝建平,等.玉米果穗图像单一特征的品种鉴别力评价[J].农业工程学报,2011,27(1):196-200
[9]杨锦忠,张洪生,赵延明,等.玉米穗粒重与果穗三维几何特征关系的定量研究[J].中国农业科学,2010,43(21):4367-4374
[10]Lindsay I Smith.A tutorial on Principal Components Analysis[EB/OL].[2002.2.26].http://www.cs.otago.ac.nz/cosc453/student_tutorials/principal_components.pdf
[11]Aapo Hyvärinen,Erkki Oja.Independent Component Analysis:Algorithms and Applications[J].Neural Networks,13(4-5):411-430,2000
[12]P.H.Chen,C.J.Lin,B.Schölkopf.A tutorial on v-support vector machines[J],Appl.Stoch.Models.Bus.Ind.2005,21,111-136
[13]Chih-Wei Hsu,Chih-Chung Chang,and Chih-Jen Lin.A Practical Guide to Support Vector Classi_cation[EB/OL].[2010-7-15].http://www.csie.ntu.edu.tw/~cjlin.
Study on the Influencing Factors of Corn Cultivars by Image Classification
Han Zhongzhi1Yang Jinzhong2Li Yanzhao1
(College of Information and Science,Qingdao Agricultural University1,Qingdao 266109)
(College of Agriculture and Plant Protection,Qingdao Agricultural University2,Qingdao 266109)
In order to research the key influencing factors in the corn varieties image recognition,we build a corn varieties recognition system based on PCA,ICA feature extraction and support vector machine(SVM)classification algorithm.11 varieties,each variety 50 image were taken with scanners.Based on pixel features and statistical characteristics of these images,some feature extraction and features optimization methods by PCA and ICA were studied respectively.And also,we inspected the key parameter optimization process in pattern classification based on support vector machine(SVM).Test results showed that the highest rate of varieties is 97.17%for 11 varieties of 550 kernels.In the same way,the recognition rate of kernels optimized by ICA characters is about 3%higher than PCA-based optimization.Recognition using statistical characteristic appropriate selection is about 10%higher than pixels features.In addition,the SVM parameters influenced the identifying effect,but the overall effect is not big.The method and the conclusion of this paper have positive significance for corn seed purity and varieties test.
maize seed,variety identification,independent component analysis(ICA),principal component analysis(PCA),support vector machine(SVM)
S513,S326
A
1003-0174(2012)10-0098-06
国家农业转化基金(2010GB2C600255),山东省自然科学基金(ZR2009DQ019,ZR2010CM039),山东省科技攻关项目(2009GG10009057),青岛市科技发展计划(08-2-1-15-nsh,11-2-3-20-nsh)
2011-12-31
韩仲志,男,1981年出生,讲师,博士,农业图像处理
李言照,男,1960年出生,教授,作物信息技术及其应用
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
现代畜牧科技(2021年4期)2021-12-05
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
红领巾·萌芽(2019年8期)2019-08-27
英美文学研究论丛(2018年1期)2018-08-16
河北农业科学(2018年2期)2018-07-26
中国与非洲(法文版)(2017年10期)2017-11-23
种业导刊(2017年7期)2017-08-22
科学种养(2017年6期)2017-06-13
