
化学污染物慢性膳食暴露评估全概率模型构建研究*
2015-03-09 11:13东南大学公共卫生学院流行病与卫生统计学系210009李喜艳张亚非
中国卫生统计 2015年2期
东南大学公共卫生学院流行病与卫生统计学系(210009) 李喜艳 张亚非 金 昊 刘 沛
化学污染物慢性膳食暴露评估全概率模型构建研究*
东南大学公共卫生学院流行病与卫生统计学系(210009) 李喜艳 张亚非 金 昊 刘 沛△
目的提高食品安全风险评估精度,构建化学污染物慢性膳食暴露评估全概率模型。方法利用我国膳食调查、污染物监测数据以及相应的人口学资料构建膳食暴露评估全概率模型。通过在消费量和污染物总体中进行蒙特卡洛(Monte Carlo)抽样,匹配相乘后得到暴露量的概率分布;构建贝塔二项正态分布(Betabinomial and normal,BBN)模型,将横断面调查获得的短期暴露量近似“拉伸”为长期(慢性)暴露量;通过Monte Carlo模拟和自助法(Bootstrap)对人群膳食暴露量进行变异度和不确定度分析。结果以江苏省居民铅膳食暴露评估为例,构建了化学污染物慢性膳食暴露全概率评估模型。全概率模型和半概率模型比较显示:两种模型计算的暴露量均值接近,但全概率模型计算结果的变异度大于半概率模型,表现为其低端百分位数小于半概率模型,高端百分位数大于半概率模型。结论化学污染物慢性膳食暴露全概率模型评估结果较半概率模型保守。
食品安全 慢性膳食 暴露概率 评估模型构建
当前风险评估已经成为世界贸易组织和国际食品法典委员会(CAC)用于制定食品安全措施的必要技术手段[1]。暴露评估是风险评估的重要组成,在对化学污染物进行慢性膳食暴露评估时,受人力物力限制,往往难以获取人群的长期膳食调查数据,直接使用横断面调查数据反映长期暴露会产生较大误差[2]。在此条件下,构建统计模型利用横断面数据近似模拟人群对化学污染物的长期(慢性)膳食暴露成为食品安全膳食暴露评估方法研究的热点之一。本研究在目前较为通用的半概率模型基础上提出了全概率评估模型的构建原理及方法,并以江苏省居民铅膳食暴露评估为例,给出全概率模型评估结果并与半概率模型进行比较,以期为慢性膳食暴露评估探索新方法。
建模原理
对具有代表性的大规模横断面膳食调查(如国家或地区的营养健康调查),调查数据中蕴含的变异信息可按设计和需要分为个体间变异和个体内变异两个部分,其中个体间变异信息近似反映该人群的膳食习惯,而个体内变异信息则反映个体在调查天数内膳食结构的短期波动,这样在采用适当的统计模型扣除个体内变异后,使用反映个体间变异信息计算出的人群化学污染物摄入量,则可认为是该人群的日常摄入量(usual intake)[2]。在人群膳食模式相对稳定的条件下(这一假设常与实际相符),日常摄入量(人群膳食习惯)可近似作为人群的长期或慢性暴露量,从而把横断面调查获得的短期暴露量近似“拉伸”为长期暴露量[2]。
建模方法
1.构建短期(横断面调查)摄入量模型[3]
若令xijk代表第i人第j天第k种食物摄入量(一般来源于短期膳食调查),cijk为第i人第j天第k种食物中的污染物浓度,由于cijk一般难以获得故常用相应的污染物监测数据(一般来源于国家或地区的食品污染物监测网)ci*j*k代替,wi代表第i人的体重,则第i人第j天的短期膳食暴露量(yij)的“理想”模型(公式1)和实用模型(公式2)为:
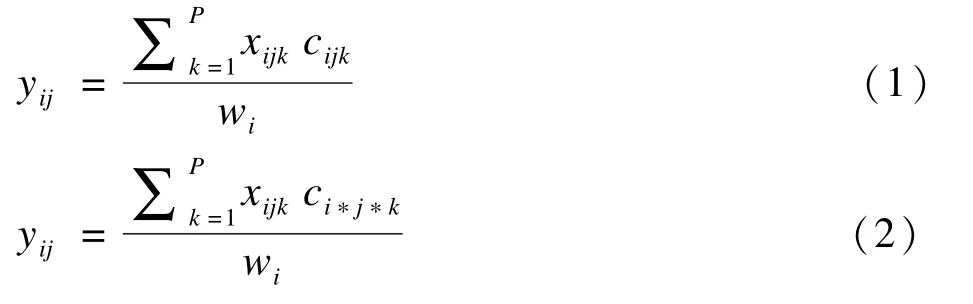
从概率分布角度出发,分别将食物消费量和化学污染物残留量作为两个独立分布的总体A和B(这一独立性假定符合污染物摄入的实际情况),在获得A,B两总体特定的分布特征和参数后,可利用统计模拟方法在A、B两个总体中进行随机抽样并配对相乘,从而获得所需要的统计量如P50、P97.5、P99等作为目标人群的暴露量估计值[3]。
2.构建慢性膳食暴露评估模型
在如何把短期横断面调查获得的暴露量近似“拉伸”为长期暴露量的方法中,最简单的是用污染物浓度均数近似表示该污染物慢性暴露的浓度水平,其每人每天的暴露量可表示为:

因该方法并未扣除个体内变异,故对慢性暴露的近似程度较差。为了实现精度更高的评估,国外学者de Boer[2]在此基础上提出了贝塔二项正态分布(betabinomial and normal,BBN)模型。由于该模型中的污染物浓度为一定值(均数),仅有消费量数据为随机变量,故该模型又称为半概率模型。本文在半概率BBN模型基础上,将污染物浓度也作为随机变量,构建全概率BBN模型以实现更为精细的评估。
(1)构建阳性暴露量模型
构建阳性暴露量模型步骤如下[4]:首先,对yij进行变量变换(BOX-COX变换,特例为对数变换)得到transf(yposij);其次,使用随机效应模型将方差分解为三个部分,transf(yposij)=μ+ci+uij,其中,μ表示个体总体平均水平的平均值,ci表示个体间效应,uij表示个体内效应,个体间效应和个体内效应满足正态分布通过最大似然估计法得到三个参数的估计值再者,从扣除个体内变异的对数转换后的阳性暴露量m+zi中随机抽样,其中zi从正态分布随机抽取,获得阳性日常摄入量的变换后(如对数)分布;最后,对阳性日常摄入量进行反变换,并纳入调整因子进行偏性校正,获得原始数据下的第i人的阳性日常摄入量yposi。
(2)构建摄入频率模型
假设n代表个体膳食调查重复的调查天数,x代表阳性摄入天数,每人每天消费的食物中可能包含污染物,也可能不包含污染物,每个观察对象出现阳性结果的发生概率为π,因此随机变量x服从总体概率为π,重复数为n的二项分布。每人每天是否摄入化学污染物的概率(π)并不相同,且取值在0,1之间,其服从参数为α和β的贝塔分布。综上,X的概率服从贝塔二项分布,最后,通过最大似然估计法估计得到摄入频率分布Beta
3.计算慢性摄入量
由于个体并非在任意一天有阳性摄入量,因此,对于每一个yposi值,均对应一个来自分布的概率pi。第i个体的慢性摄入量分布:yci=pi×yposi。
变异度和不确定度分析
在膳食暴露评估中,变异度是指人群食物摄入量的个体差异,不确定度是由于人们缺乏相关知识、信息以及技术等造成的结果变异[5]。在全概率评估模型构建中,采用Monte Carlo方法,通过反复抽样获得人群暴露量的变异度[6]。本次研究在消费量和化学物浓度两个总体中分别进行Monte Carlo抽样300000次,在BBN模型中抽样100000次,获得了稳定结果。通过Bootstrap方法进行不确定度分析,该法基于消费量数据库和污染物数据库作Bootstrap抽样,然后在每个Bootstrap样本中进行Monte Carlo模拟。本次研究进行Bootstrap抽样200次,结果较为稳定。
实例分析
利用我国2002年中国居民营养与健康状况调查、2001-2010年国家食品污染物检测网监测数据以及2002年中国居民营养与健康状况调查收集的人口学信息构建化学污染物慢性全概率评估模型。本次研究采用江苏省铅污染物监测数据,低于检出限(LOD)的未检出值根据污染物检出率设为LOD/2[7]。通过搭建桥梁数据库将个体食物消费量和污染物监测的食品污染物浓度信息进行整合,具体见本课题组前期的研究报道[8]。同时,采用半概率模型进行暴露评估,并对二者结果进行比较。
1.变异度分析
变异度分析可以得到一般人群及其亚组的铅膳食暴露量分布。表1和表2分别是运用全概率模型和半概率模型计算一般人群及其亚组铅膳食暴露量的变异度分析。由表1、2可知,两个模型计算的各人群暴露量均值十分接近,但全概率模型计算的各百分位数较半概率模型变异大,表现为全概率评估模型的高端百分位数较大,低端百分位数较小。
2.不确定度分析
表3为江苏省各年龄组儿童(2~6岁),青少年(7~17岁)和成人(18岁以上)铅膳食暴露量不同百分位数的不确定分析。膳食暴露指标呈正偏态分布,因此常采用四分位间距和非参数的95%可信区间(P2.5-P97.5)表示其不确定度。如儿童铅暴露量P50的不确定度描述为:四分位间距:2.11-2.00=0.11(μg kg-1bw day-1),95%可信区间:(1.88~2.23)μg kg-1bw day-1。

表1 江苏省一般人群及其亚组铅膳食暴露量(μg kg-1bw day-1)变异度分析(全概率模型)

表2 江苏省一般人群及其亚组铅膳食暴露量(μg kg-1bw day-1)变异度分析(半概率模型)
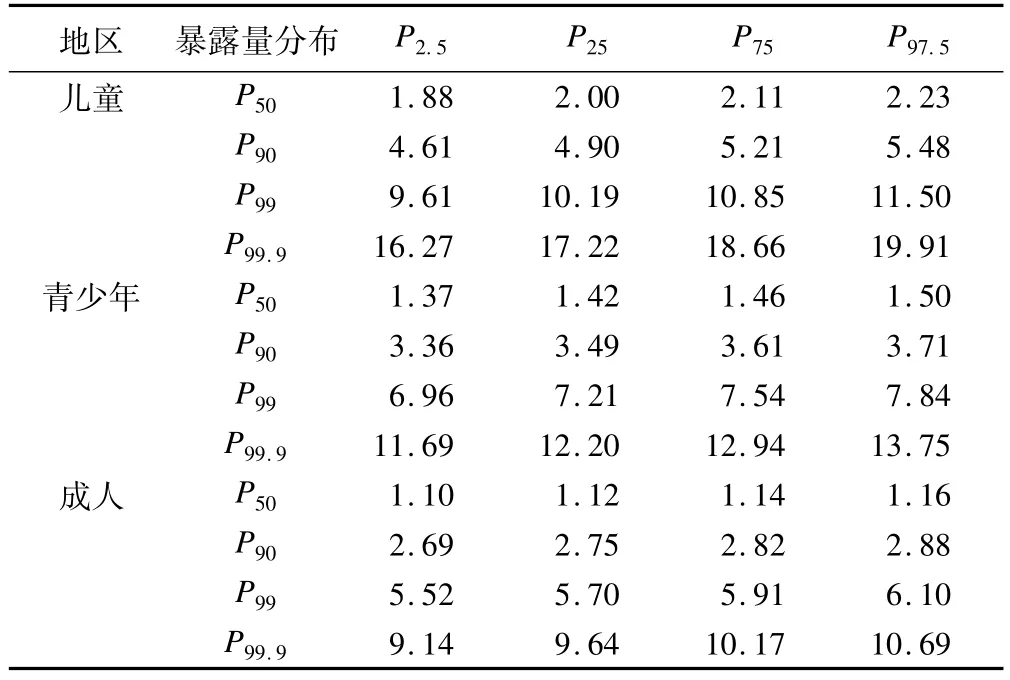
表3 江苏省一般人群及其亚组铅膳食暴露量(μg kg-1bw day-1)分布的不确定度分析
讨 论
本次研究目的是构建化学污染物慢性膳食暴露全概率评估模型。该模型是在现有样本消费量以及污染物浓度经验分布的基础上进行Monte Carlo抽样得到膳食暴露量;而半概率评估模型只是在消费量数据经验分布的基础上进行抽样,污染物浓度取平均值。故全概率模型结果的变异度较半概率模型大。从保护大多数人的角度出发,食品安全风险评估更加专注高端暴露量,而全概率模型可以实现高端百分位数更为精细的估计。同时,可探查到半概率模型未能发现的风险,这一结果符合风险评估的保守性原则。然而全概率模型的计算量较半概率模型明显增大,对相关食物的化学污染物浓度数据的数量和质量均有了更高要求,这在一定程度上限制了这一方法的应用。我国31个省采取统一的污染物监测方案,为充分利用监测数据中的宝贵信息,故我们尝试采用全概率模型进行化学污染物的慢性暴露评估。
依据美国环境保护署提出的层次评估法[9]程序,即当应用某一方法获得的评估结果临近或超过安全标准时,应采用更为保守的评估方法。权衡全概率评估模型和半概率评估模型的优缺点,我们提出,当半概率模型评估提示有健康风险时,不必采用全概率模型。而当半概率模型评估提示无健康风险时,则应根据数据情况采用全概率模型进行更精细的评估。
1.刘沛,吴永宁.构建中国膳食暴露评估模型提升我国食品安全风险评估水平.中华预防医学,2010,44(3):181-183.
2.de Boer WJ,Boon PE,van der Voet H,et al.Comparison of two models for the estimation of usual intake addressingzero consumption and nonnormality.Food Addit.Contam,2009,26(11):1433-1449.
3.de Boer WJ,van der Voet H,Boon PE,et al.MCRA,Release7,a webbased program Monte Carlo Risk Assessment.Aug.25,2010.http://mcra.rikilt.wur.nl/Documentation/Manual7.pdf.
4.Boon PE,Biesebeek JDT,SioenI,et al.Long-term dietary exposure to lead in young European children:comparing a pan-European approach with a national exposure assessment.Food Addit.Contam,2012,29:1701-1715.
5.孙金芳,刘沛,陈炳为,等.中国膳食暴露评估非参数概率模型构建.中华预防医学,2010,44(3):195-199.
6.张亚非,孙金芳,刘沛,等.LMS法和排序计数法在江苏省居民膳食镉暴露评估中的比较研究.中国卫生统计,2013,30(1):34-36.
7.王绪卿,吴永宁,陈君石.食品污染检测低水平数据处理问题.中华预防医学,2002,36(4):278-279.
8.韩晓梅,闵捷,刘沛,等.中国膳食暴露评估模型桥梁数据库构建初探.卫生研究,2008,37(6):725-727.
9.Wright JP,Shaw MC,KeelerLC.Refinements in acute dietary exposure assessments for chlorpyrifos.Agri Food Chem,2002,50:235-241.
(责任编辑:郭海强)
Establishment of Fully Probabilistic Model for Evaluation of Long-term Dietary Exposure to Chemical Contaminants
Li Xiyan,Zhang Yafei,Jin Hao,et al.(Southeast University(210009),Nanjing)
ObjectiveTo establish a fully probabilistic model for evaluation of dietary exposure to chemical contaminants and to improve the food safety risk assessment's accuracy.MethodsData from national diet and nutrition survey and food contamination monitoring program were used to establish fully probabilistic model.Monte Carlo was applied to conduct sampling from consumption and contamination data.Dietary exposure was then obtained through multiplying both data;Betabinomial and normal model was established to make the short-term exposure approximately represent the long-term exposure.Monte Carlo simulation and Bootstrap sampling were applied to analyze the variation and uncertainty.ResultsBased on the example of dietary exposure to Pb of Jiangsu population,fully probabilistic model for evaluation of dietary exposure to chemical contaminants was established.The mean dietary exposures calculated by two models were similar.Variation calculated by fully probabilistic model was higher than semi-probabilistic model.Compared with semi-probabilistic model,exposure of fully probabilistic model had higher high-end percentiles and lower low-end percentiles.ConclusionFully probabilistic model are more conservative than semi-probabilistic model when assessing the long-term dietary exposure.
Food safety;Long-term dietary exposure assessment;Probabilistic evaluation;Model establishment
国家自然科学基金资助项目(81172769)
△通信作者:刘沛
猜你喜欢
中学生数理化·高一版(2021年3期)2021-06-09
趣味(数学)(2020年4期)2020-07-27
支部建设(2020年15期)2020-07-08
现代妇女(2016年3期)2016-03-31
百科知识(2015年18期)2015-09-10
中学生数理化·中考版(2015年10期)2015-09-10
科学生活(2015年5期)2015-05-19
数学教学通讯·初中版(2014年2期)2014-03-21
中学数学杂志(高中版)(2006年4期)2006-07-19
雕塑(1996年4期)1996-07-12
