
基于词典、规则的斯拉夫蒙古文词切分系统的研究
2015-04-25 09:57史建国侯宏旭
中文信息学报 2015年1期
史建国,侯宏旭,飞 龙
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
基于词典、规则的斯拉夫蒙古文词切分系统的研究
史建国,侯宏旭,飞 龙
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
斯拉夫蒙古文是蒙古国现行的文字,又称为西里尔蒙古文或新蒙古文。蒙古文词干和词缀包含着大量信息,斯拉夫蒙古文词切分是斯拉夫蒙古文信息处理众多后续工作的基础。该文尝试了将词典和规则结合的方法对斯拉夫蒙古文进行词切分。首先预处理部分蒙古文词,然后基于词典切分高频和部分不符合规则的词。最后对剩余的词,用切分规则生成多个候选的词切分方案,然后在这些方案中选出最优方案。通过两种方法的有机结合,发挥各自的优点,得到了性能较好的斯拉夫蒙古文词切分系统。
斯拉夫蒙古文;词切分;词典;规则
1 引言
蒙古语是黏着性语言,黏着语语言是一种有时态变化的语言类型,通过在单词的词尾缀接不同的词缀来实现语法功能。蒙古语、维吾尔语、满语、日语、韩语、芬兰语、土耳其语、匈牙利语等为典型的黏着语。
蒙古语的构词和构形都是以词根、词干上缀接不同词缀来完成的。每一个词的构成和其语法意义的表示都是依赖于不同词缀的缀接,所以只有正确切分词干和词缀才能揭示其词类属性和语法关系。另一方面,蒙古语中存在大量的构词、构形词缀,而且它们往往有同形或兼类现象,这使蒙古语词干和词缀的切分更加复杂化[1]。
每个黏着语言的形态结构、构形词缀和词缀连接规则具有较大的差异,因此词切分必须针对每个具体语言来设计与实现。词切分算法在黏着语言的自然语言处理技术中占重要地位,所以斯拉夫蒙古文词切分是斯拉夫蒙古文信息处理众多后续工作的基础。其他的研究,例如,斯拉夫蒙古文机器翻译、信息检索、文本分类、篇章处理等都是在斯拉夫蒙古文词切分的基础上进行的。所以设计一个高查准率、高查全率、运行速度快的斯拉夫蒙古文词切分系统,对斯拉夫蒙古文信息处理的研究具有重要的意义。
词切分长时间以来一直是被研究的课题,典型的词切分方法有Porter[2]算法,基于词典方法,有限状态转录机,有限自动机,基于HMM的方法[3],基于同现概率的方法等。目前传统蒙古文词切分研究已经做了很多工作,而且取得了比较好的结果,但是斯拉夫蒙古文的词缀切分还没取得很好的结果。传统蒙古文词切分方法一般有3种: (1)基于切分词典的切分方法[4]; (2)基于规则的切分方法[5]; (3)基于统计的切分方法[6]。此外也有人尝试了结合多种方法对传统蒙古文切分[7]。和传统蒙古文有很大的不同,斯拉夫蒙古文基本上怎么读就怎么写的,读与写统一,在传统蒙古文中的一个词缀可能对应多种变形的词缀,同时,词库、正字法等也存在混乱和无固定标准的现象,所以切分也相对较难,目前国内外还没有一部实用的斯拉夫蒙古文词切分系统。本文对斯拉夫蒙古文构词从理论到实践做了深入分析,提出了切合实际的切分方法,结合基于切分词典的切分方法和基于规则的切分方法,对斯拉夫蒙古文词进行词缀切分,取得了比较好的结果。
2 斯拉夫蒙古文词切分的特点
蒙古国现行的斯拉夫蒙古文有35个字母,其中7个基本元音,6个辅助元音,7个带元音辅音,4个借词辅音,9个残缺辅音,这些都属于音素,还有1个隔音符号和1个前化符号。一个词由一个或多个音节组成,一个音节一般由几个音素组成,词与词之间用空格分开。
斯拉夫蒙古文是个语法信息特别丰富的语言文字。不仅存在着众多规律和规则,而且每种规律或规则都有特殊的情况,除此之外还有违反规律规则及特殊规则的情况。这些使得斯拉夫蒙古文的语法变得更加复杂。
斯拉夫蒙古文在语音方面有严格的元音和谐律。蒙语词的第一个音节的元音是要影响后续音节的元音。一般是第一个音节的元音是阳性,那么后续音节的元音只能是阳性,第一个音节的元音是阴性,那么后续音节的元音只能是阴性,只有中性元音不受这种限制,可以跟阳性元音或阴性元音同时出现在一个词里[8]。
蒙语是一种连续语,因此,蒙古语词从构造上可以分为: 词根、词干、附加成分。在形态学方面以词根或词干为基础,后接词缀派生新词和进行词形变化。词干上缀接词缀时有时在其中间增加字符、有时减少字符,也有时增加一个音节。词根,表示蒙古语词的最基本意义的部分,也就是词的原来词素叫做词根。词干,表示蒙古语的有意义的部分叫做词干,词干可以分为第一词干、第二词干、第三词干等,词根就是第一词干。附加成分,单独没有意义,只在词干下附加后产生词汇意义和语法意义的部分叫做附加成分[8]。例如,
Yйлдвэрлэл(生产)这个词由Yйл(行为)—Yйлд(制作)—Yйлдвэр(工厂)—Yйлдвэрлэ(生产<动>)—Yйлдвэрлэл(生产<名>)的顺序构成的。这里Yйл为词根(第一词干),它后面接加《д》之后产生第二词干Yйлд,再接加《вэр》时产生第3词干Yйлдвэр,后面再接加《лэ》产生第4词干Yйлдвэрлэ,最后又接加《л》之后产生Yйлдвэрлэл这个词。
附加成分有构形附加成分和构词附加成分,我们在此处理构形附加成分,它并没有改变词汇的意义,这在后续工作中都是很有用的,我们在此都称为词缀。
3 基于词典的词切分
这里说的基于词典的切分只是对高频和部分不符合规则的斯拉夫蒙古文词进行的切分,是用来提高本词切分系统的效率和准确率。
对训练语料进行词频统计后分析发现,有些高频词在短词处理阶段就能处理掉,所以不需要编入切分词典。整理后得到出现频率高的200个词,对其进行人工词切分编入词切分词典,用来进行基于词典词切分使用。高频词进行基于词典的词切分对于斯拉夫蒙古文词切分的准确率和速度的提高有很大的帮助。此外,斯拉夫蒙古文中少量词不符合切分规则,我们也把这些词放入切分词典中,可以避免词切分的错误,提高切分的准确率。
词切分词典格式为: 索引——原词——切分结果。其中,索引指的是该词的首字母。
从表1中看出这200个高频词在语料中共出现了55 719 379次,所占的比例为 22.44%。最高出现频率为623 782次,最低也有28 941次。所以对这200个高频词的准确处理意义非常大。
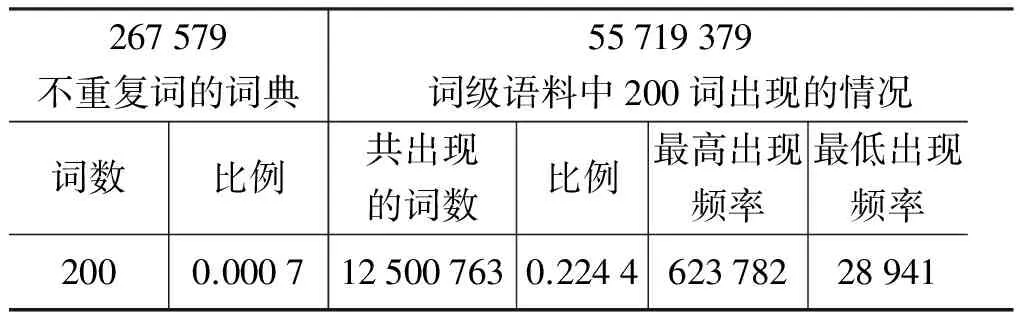
表1 高频词统计结果
4 基于规则的词切分
虽然斯拉夫蒙古文和传统蒙古文在形态分析方面并没有本质的差异,但两者在缀接词缀时有很多不同的地方,因此词缀切分规则有很大区别,传统蒙古文的切分规则很多并不适用于斯拉夫蒙古文,相对于传统蒙古文,斯拉夫蒙古文词缀切分要复杂的多。
斯拉夫蒙古文是一个语法规则特别丰富的文字,有构词词缀和构形词缀。在词干上缀接词缀时,不是简单的连接,词干词尾发生变化,词干末尾部分从词尾形式变为词中形式。有时二者之间还需要添加连接字符,而连接字符也分一般情况和特殊情况;有时二者之间还需要去掉字符,也分一般情况和特殊情况。斯拉夫蒙古文词还分为阳性词、阴性词和中性词。


завилгаа(盘腿坐)
该词中гаа不是词缀,不能切。
Байцаагаа
该词中гаа是词缀,切分结果为байцаагаа: байцаа(白菜)+гаа。
由于斯拉夫蒙古文词缀情况非常复杂,所以处理好斯拉夫蒙古文的这些规则和变化对于蒙古文的词缀切分意义重大。根据斯拉夫蒙古文的特点,我们总结出了下面一些规则,并设计了算法。
4.1 通用切分规则
斯拉夫蒙古文词通用切分规则指切分词干、词缀时普遍的切分规则。可以定义如下,假设一个斯拉夫蒙古文词“WS”,S∈Ts其中Ts为词缀词典,W为词干,S为词缀。如果S词缀为某个词缀表中的词缀,且W词干满足该词缀表对词干的要求,那么可以直接切分为WS: W+S的形式。例如,
авьяастай: авьяас+тай
тай为词缀词典的词缀表MK_AE_GEIGUULEGC_DSR中的词缀,该词缀表对词干的要求是词干为静态词词干,且为AE(含有а、э、у、Y字母)型词干,词干以DSR(д、с、р)字母结尾。
авьяастай满足该词缀表的要求,所以可以直接切分为авьяас+тай。
应用通用切分规则进行词切分时,我们切分的词缀为多个词缀的叠加,即,一个词后面如果缀接了多个词缀,那么我们将这多个词缀看成一个整体,然后从单词中切分。
4.2 脱落元音的恢复
斯拉夫蒙古文中有些情况单词后缀加词缀时会出现元音脱落现象,当出现这样的情况时,切分词缀后要将脱落的字符恢复。例如,以辅音结尾的词干后接加以长元音开头的词缀时该结尾辅音前面的元音要脱落。除и以外,其他元音结尾的词干后接加以长元音开头的词缀时该结尾的元音要脱落。以辅音结尾的词干后接加以辅音开头的词缀时需要加元音时,该辅音前面的元音要脱落。例如,
олон+оос: олноос
олон以辅音结尾的词干,后面缀接以长元音开头的词缀оос时,脱落掉олон结尾辅音字符н前的元音о。
мөнгө+ийг: мөнгийг
мөнгө为非и的元音结尾的词干,后面缀接以长元音开头的词缀ийг时,脱落掉мөнгө末尾的元音ө。
боловсор+л: боловсрол
боловсор后面缀接л时,боловсор末尾需要加元音о,所以脱落掉боловсор结尾的辅音字符р前的元音о。
但是,有些情况下元音不能脱落,例如,不能把带元音辅音脱落成没有元音,不能把残缺辅音后接加残缺辅音时加写的元音脱落等。
斯拉夫蒙古文的元音有阳性、阴性和中性之分。一个词里边存在前后元音之间互相制约关系的元音和谐律。元音和谐律可用表2表示。
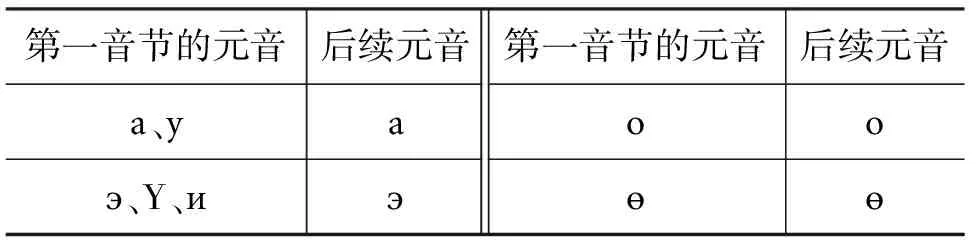
表2 元音和谐律
脱落元音恢复时可以考虑元音和谐律,根据元音和谐律恢复脱落的元音。例如,上面例子中,олноос为原词干缀接词缀时脱落掉了元音,所以олноос切掉词缀оос后,词干为олн恢复元音,根据元音和谐律,олн第一个音节的元音为о,所以原来脱落掉的元音为о,所以олноос切掉词缀оос后,词干为олно。
4.3 前化符号的恢复
在斯拉夫蒙古文中词首音节的阳性元音受其后续音节и的影响而前化,最后成为独立音位的叫做前化元音。前化元音在斯拉夫蒙古文里用前化符号ь表示。换句话说前化元音是阳性词第一音节的а、о、у受到前元音и的影响,发音部位逐渐前移,成为一种独立的前元音。
有些情况,前化符号后面接加附加成分时把前化符号转换成и,如,前化符号后面接加以带元音辅音开头的词缀时把前化符号转换成и,前化符号后面接加以元音开头的附加成分时把前化符号转换成и等等。对于这样的词,在词切掉词缀后,要将前后符号恢复。例如,
соль+вол: соливол
соль以前化符号ь结尾,后面缀接以带元音辅音开头的词缀вол时,前化符号ь转换成и,所以соль后缀接词缀вол后为соливол。相应的当соливол切掉词缀вол时,词干为соль。
而有些情况前化符号不转换成и,所以切分词缀时,如果需要将前化符号恢复时就得恢复。而前化符号后面接加以残缺辅音开头的词缀时把前化符号不转换成и,前化符号后面接加第一人称意愿式附加成分я、ё时前化符号不转换成и等等。对于这些情况,我们对词直接切掉词缀即为词干了,不用考虑前化符号的恢复。
4.4 基于规则的词切分算法
(1) 将词与词缀词典各词缀表中的词缀进行匹配。
(2) 若没有匹配,则返回结果;若有匹配且词干符合该词缀表中词缀对其的要求,则转入第(3)步。
(3) 若词去掉词缀后,剩下部分是否一个有意义词或词干,且可以缀接词缀。若是真,则切分成功,若是假,则转入第(4)步。
(4) 该词是否属于词干缀接词缀后脱落了元音情况,若不属于,则转入第(5)步,否则将脱落元音恢复,然后看恢复后是否一个有意义词或词干,且可以缀接词缀。若是真,则切分成功;若是假,则该词不属于“词干和词缀结构”。
(5) 若不属于第(4)步情况,则看该词是否属于词干缀接词缀后前化符号被转换情况,若属于,则将前化符号恢复,然后看恢复后是否一个有意义词或词干,且可以缀接词缀。若是真,则切分成功;若是假,则该词不属于“词干和词缀结构”。
5 数据准备
5.1 关于语料的说明
我们参阅了很多文献和论文没有发现公开公认的斯拉夫蒙古文训练语料和测试语料,因此我们整理了一个训练语料和一个测试语料。其中,训练语料为我们整理网络孔子学院等多个网站的斯拉夫蒙古文文本所得语料集,共1G多。训练语料没有词性信息,也没有词缀切分信息,如图1所示。测试语料为我们精心挑选的具有代表性的200句斯拉夫蒙古文语料,对测试语料切分后进行了人工校对。
5.2 人工编写词缀词典
1. 词缀
斯拉夫蒙古文和传统蒙古文一样,通过在词干上缀接词缀,有时层层缀接,变成一个结构相当复杂的蒙古文词,所以构建词缀词典是蒙古文切分必须完成且重要的任务。

图1 斯拉夫蒙古文原始语料
2. 词缀词典的设计
根据情况的不同,我们对词缀总结整理,共分为30类词缀表,这些词缀表之间存在重复词缀,而且词缀表中的词缀不是斯拉夫蒙古文语法上的词缀,而是多个词缀的叠加,即,一个词后面如果缀接了多个词缀,那么我们将这多个词缀看成一个整体作为词缀。词缀表分类的依据是前面词干的不同,如词干是静态词词干,还是动态词词干,词干的阴阳性、末尾元音等,每一个词缀表对词干都有相应的要求,例如,MK_TYN_AE_GEIGUULEGC_DSR这个词缀表要求词干为静态词词干,且为AE(含有а、э、у、Y字母)型词干,词干以DSR(д、с、р)字母结尾。
下面为词缀表MK_TYN_AE_GEIGUULEGC_DSR的截图如图2所示。

图2 词缀表MK_TYN_AE_GEIGUULEGC_DSR
所有词缀表统计如表3所示,其中,长度为斯拉夫蒙古文字母个数。

表3 词缀词典统计结果
5.2 人工编写词干词典
我们统计并切分校正,生成5万词级的词干词典,其中有7千词级的动态词词干。
6 词切分流程
对语料进行分析,发现斯拉夫蒙古文词切分在真正开始切分之前,进行词信息分析工作,将会大幅度提高词切分效率和准确率。
6.1 切分过程
本系统对斯拉夫蒙古文词切分的词切分过程如图3所示。
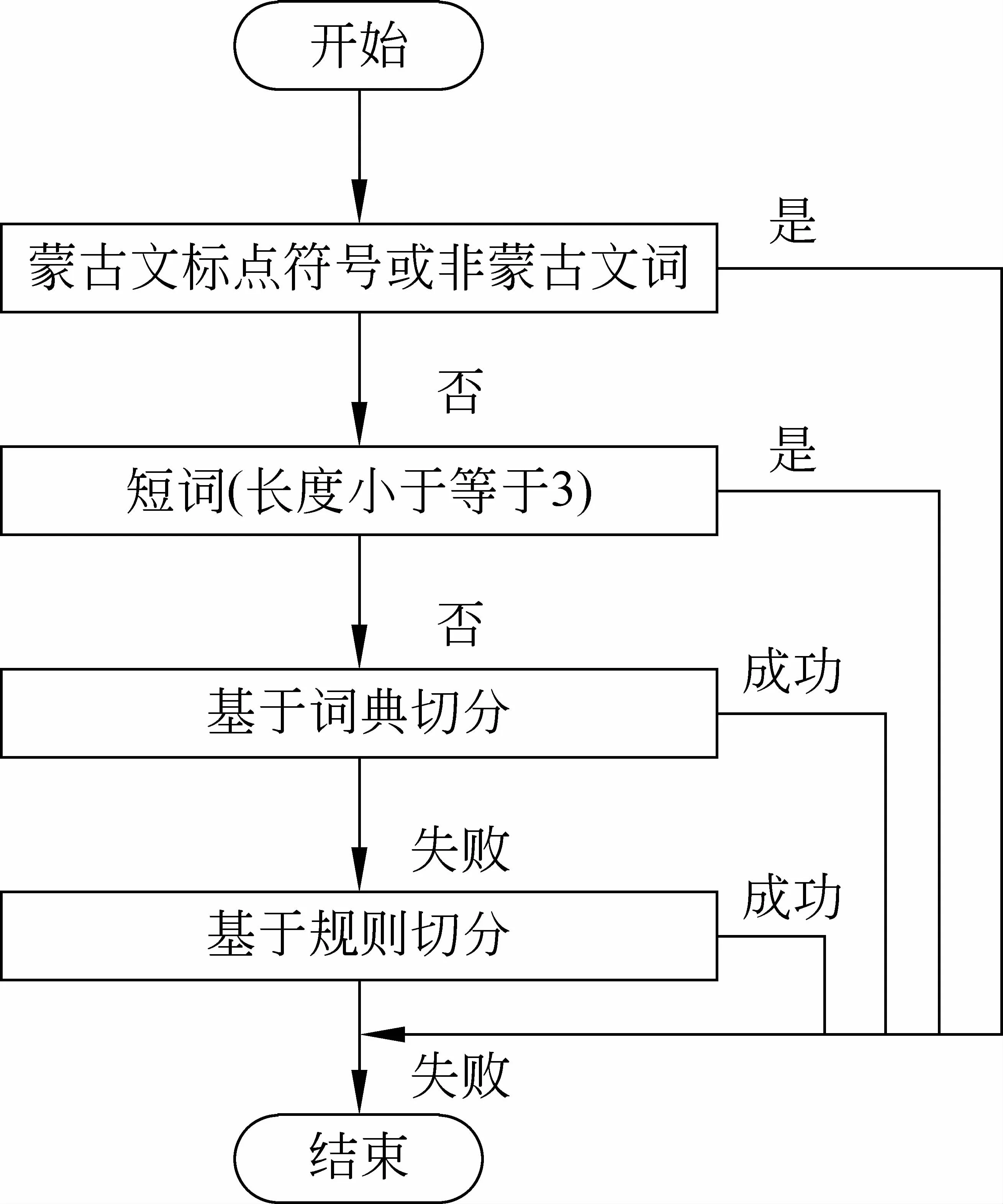
图3 词切分过程
首先,如果当前为斯拉夫蒙古文词标点符号或非斯拉夫蒙古文词,则直接输出。
其次,第一步没有得到处理的,如果该词长度小于等于3,则直接输出。
最后,前两步中没得到处理的,如果该词在词切分词典中,则按词典方法将该词的切分结果输出。剩余部分按后面介绍的基于规则的方法切分。如果都处理不掉,则直接输出。
6.2 长度小于等于3的斯拉夫蒙古文词
对于长度小于等于3的斯拉夫蒙古文词的分析发现它们基本上为词干。从表4中可以看到3 491个短词在语料中占的比例高达17.93%。所以对这些词的预处理,对词切分的贡献很大。
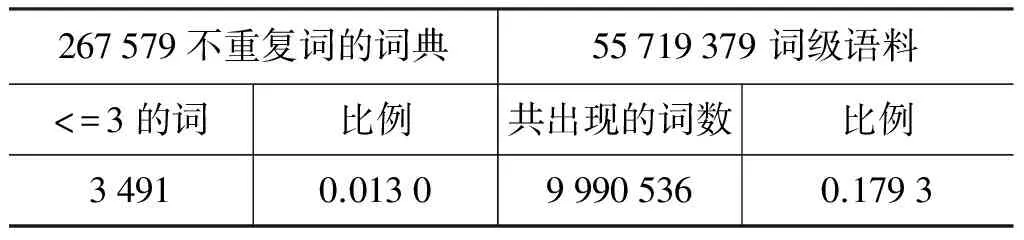
表4 训练语料中长度小于等于3的词的统计结果
7 实验
我们精心选取了200句具有代表性的斯拉夫蒙古文长句子,对其单词进行词缀切分。实验结果如表5所示。
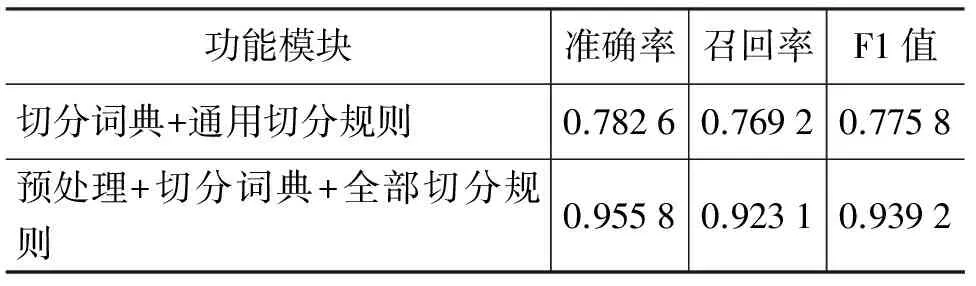
表5 实验结果
从上面结果看出,只是简单基于切分词典和通用切分规则的词缀切分,准确率不高,而加上其它规则和预处理,则明显的提高了词缀切分的准确率。因为根据通用切分规则所得词干,很多需恢复脱落的元音或前化符号等;预处理也会减少错误切分,如短词,它们基本没有词缀,不需切分。另外,如果词干词典的覆盖率比较小时会影响切分的准确率。而且,当出现多种满足条件的情况时,就不能保证输出正确结果了,例如,бартаа为“障碍、险阻、麻烦”的意思,没有词缀,但是在切分时却切分成бар+таа了,词干为бар,词缀为таа,这是因为词缀表MK_AE_GEIGUULEGC_DSR中含有词缀таа,而且бар为AE型,以DSR(д、с、р)字符结尾,词干词典中存在,为静态词词干,满足了规则和设定的条件,所以切分得到的结果就不正确了。
8 总结及展望
本文对斯拉夫蒙古文词采用基于词典和规则结合的方法进行词缀切分,实现了一个实用的切分系统。实验表明,通过词典和规则两方法的结合,对斯拉夫蒙古文词切分取得了比较好的结果。但是,由于斯拉夫蒙古文是一个很灵活的语言,规则不能完全覆盖所有的单词,有些特殊情况,而且随着新词的不断出现,可能会出现更多的特殊情况,有些词处理结果存在问题,系统还需要进一步完善。接下来的工作,进一步完善切分规则、词缀词典和词干词典,而且,我们考虑利用统计方法对大的词切分语料根据斯拉夫蒙古文的特点进行机器学习,通过结合语言模型对该系统进一步改进。
[1] 那顺乌日图.蒙古文词根、词干、词尾自动切分系统[J].内蒙古大学学报,1997,29(2):53-67.
[2] M F Porter. An algorithm for suffix stripping [J].Program, 1980, 14(3): 130-137.
[3] Massimo M and Nicola O. A Novel Method for Stemmer Generation Based on Hidden Markov Models[C]//Conference on Information and Knowledge Management Archive Proceedings of the twelfth International Conference on Information and Knowledge Management, 2003: 131 134.
[4] 淑琴.“蒙古语语法信息词典附加成分分库”的设计与实现[D],内蒙古大学硕士学位论文,2005.6.
[5] 叶嘉明,基于规则的蒙古语词法分析研究与实现[D],北京: 北京大学硕士学位论文,2005.
[6] 侯宏旭,刘群,那顺乌日图等.基于统计语言模型的蒙古文词切分[J].模式识别与人工智能,2009,22(1):108-112.
[7] 明玉.基于词典、规则与统计的蒙古文词切分系统的研究[D],内蒙古大学硕士学位论文,2011.
[8] 萨仁都拉嘎.新蒙文自学入门[M],内蒙古: 天马出版有限公司,2005.1.
[9] 清格尔泰.蒙古语语法[M],内蒙古: 内蒙古人民出版社,1991.5.
[10] 嘎拉桑朋斯格.蒙古国基立尔蒙古文正字法[M],内蒙古: 内蒙古人民出版社,2001.11.
[11] 舍·却玛.蒙古文、基里尔文正字法比较研究[M],内蒙古教育出版社,2010.9.
[12] 古丽拉·阿东别克,米吉提·阿布力米提. 维吾尔语词切分方法初探[J]. 中文信息学报,2004,18:61-65.
[13] 那顺乌日图,雪艳,叶嘉明.现代蒙古文语料库加工技术的新进展——新一代蒙古文词语自动切分与标注系线[C]//第十届少数民族语言文字信息处理学术研讨会,2005
[14] 米海涛,熊德意,刘群. 中文词法分析与句法分析融合策略研究[J]. 中文信息学报,2008,22:10-17.
[15] 包萨日娜. 传统蒙古文到新蒙文转换中名词及其格附加成分转换的研究[D]. 内蒙古大学硕士学位论文,2009.6.
[16] 赵伟,侯宏旭,从伟,宋美娜.基于条件随机场的蒙古语词切分研究[J].中文信息学报,2010,24(5):31-35.
Research on Slavic Mongolian Word Segmentation Based on Dictionary and Rule
SHI Jianguo ,HOU Hongxu, BAO Feilong
(College of Computer Science, Inner Mongolia University, Hohhot, Inner Mongolia 010021,China)
Slavic Mongolian is the daily language in Mongolia, which is also known as Cyrillic Mongolian or new Mongolian. This paper explores the Slavic Mongolian word segmentation by combining the dictionary with rules. We first preprocess with the dictionary for the words of high-frequency or not consistent with rulesm then deal with the rest words with rules to generate n-best candidates for final decision We combine the two different methods, taking bothadvantages and achieving excellent performance in the Slavic Mongolian word segmentation.
Slavic Mongolian; word segmentation; dictionary; rule

史建国(1984—),硕士研究生,主要研究领域为中文信息处理。E⁃mail:tieshushjg@163.com飞龙(1985—),助教,主要研究领域为蒙古文信息处理、语音识别与合成。E⁃mail:csfeilong@imu.edu.cn侯宏旭(1972—),通讯作者,教授,博士生导师,主要研究领域为中文信息处理、信息检索。E⁃mail:cshhx@imu.edu.cn
1003-0077(2015)01-0197-06
2012-10-08 定稿日期: 2013-02-03
工业与信息化部电子信息产业发展基金“蒙古文软件开发和产业化”项目子课题“蒙古文辅助翻译与电子辞典软件”,内蒙古自然科学基金项目(2010ZD18)
TP391
A
猜你喜欢
蒙古学问题与争论(2021年0期)2022-01-19
红河学院学报(2021年4期)2021-11-19
哲学评论(2021年2期)2021-08-22
鸭绿江·下半月(2019年7期)2019-11-05
蒙古学问题与争论(2019年0期)2019-03-29
小说月刊(2017年16期)2017-12-01
传奇·传记文学选刊(2017年11期)2017-11-27
家教世界·创新阅读(2017年9期)2017-09-13
中国信息化周报(2017年30期)2017-08-31
西夏研究(2017年1期)2017-07-10
