
基于综合相似度与任务紧要度的个性化任务推荐
2016-10-24 05:59胡致杰
华南师范大学学报(自然科学版) 2016年4期
胡致杰, 印 鉴
(1.广东理工学院信息工程系,肇庆 526100;2.中山大学数据科学与计算机学院,广州 510006)
基于综合相似度与任务紧要度的个性化任务推荐
胡致杰1,2, 印鉴2*
(1.广东理工学院信息工程系,肇庆 526100;2.中山大学数据科学与计算机学院,广州 510006)
研究了如何将协同过滤推荐应用于IT项目外包平台,实现个性化任务推荐,提出了1种融合用户Profile文本相似度、任务选择相似度及任务紧要度的协同推荐方法. 该方法将用户对任务的选择行为转换为用户-任务类选择矩阵,并以此计算用户间的选择相似性;用户profile文本相似性用于平衡用户选择相似性并形成用户综合相似性,算法中任务紧要度用于度量任务的时限性与经济性,设置合适的阈值来构建待推荐任务集. 在真实数据集上的实验结果表明,提出的个性化推荐方法具有较高的推荐准确度,并在一定程度上缓解冷启动与数据稀疏性问题.
协同过滤; 综合相似度; 项目紧要度; 推荐系统
在大数据时代,个性化推荐服务受到不同业界越来越多的关注,而基于协同过滤的推荐由于易于实现、可解释性强等优点已成为最成功的推荐技术之一[1-2],但该模型固有的局限性(缺乏扩展性[3]、数据稀疏性[4]和冷启动[5])极大影响最终推荐质量,为此研究人员提出了多种解决方案:不确定近邻的协同过滤推荐,一定程度上缓解了数据稀疏问题[6];基于用户和基于项目的加权算法,可在一定程度上提高推荐准确度[7];基于影响集的协同过滤推荐,结合k最近邻和k′逆最近邻进行推荐,可有效缓解数据稀疏问题,显著提高推荐质量[8];依据项目评分与项目属性特征进行聚类,并引入时间加权函数,算法能有效提高推荐准确性[9];将社交网络信息引入推荐算法,根据用户间的信任度划分社区并在社区内外计算相似度并完成推荐,实验表明算法是有效的[10-11];基于隐式数据反馈的推荐模型,在大规模数据上的实验证明该模型具有高的推荐质量和好的可扩展性[12-13].
上述方法均能实现有效推荐,并在一定程度上缓解协同过滤推荐的局限性,但应用领域主要局限于传统的电子商务行业,对于IT行业中的任务外包服务还少有涉及. 广州多迪集团是一家IT公司,旗下有一IT项目外包平台,注册用户可通过平台进行项目任务外包,为提高项目外包速度及成功率,多迪公司拟对不同用户进行个性化的项目外包任务推荐. 针对此问题,本文在传统协同过滤算法基础上,提出一种基于用户综合相似度与任务紧要度的个性化任务推荐方法IS2TR(Personalized Task Recommendation Based on Integrated Similarity and Item Significance),其基本思想是:(1)根据用户的选择将外包任务划分为已选择集(用户已选择过的外包任务)与待推荐集(用户还未选择的外包任务),并根据公司业务类别对2个任务集中的外包任务进行分类. (2)在已选择集上构造用户-任务类选择矩阵,计算用户选择相似性,并引入profile文本相似性来实现两者之间的平衡,形成用户综合相似度. (3)根据用户综合相似度寻找目标用户最可能感兴趣的任务类,并在待推荐任务集上利用任务的紧要度产生任务推荐.
IS2TR与传统电子商务中的协同过滤推荐相比有以下3点不同之处:
(1)用户专业化. 电商中用户类型繁杂,注册信息简单;个性化任务推荐平台用户专业性高,注册信息丰富.
(2)只有行为没有评分. 电商中用户会根据自己的情感与喜好对项目或服务进行评分;个性化任务推荐平台则只有用户对外包任务的选择行为而无评分.
(3)选择唯一性. 电商中同一项目可被多个用户进行评分;个性化任务推荐平台上的外包任务仅能被一个用户选择一次,具有选择唯一性.
1 IS2TR算法的设计与实现
1.1问题定义
IT任务外包推荐系统中,存在用户集U={u1,u2,…,um}、外包任务集I={i1,i2,…,in}和用户-任务选择矩阵Tm×n={pi,j},其中pi,j为用户i对任务j的选择行为,1代表选择,0代表未选择. 任务集I中的外包任务由两部分构成:一是已经被用户选择的任务;二是还未被用户选择的任务. 由于每个外包任务有且仅有1个用户可对其进行选择,因此,Tm×n上的数据极其稀疏. 同时,外包任务的时限性与价值性也是个性化任务推荐平台所特有的特征. 1.2用户-任务类选择矩阵
1.2.1选择任务集Is和待推荐任务集Ic个性化推荐系统中的外包任务只可能存在已被选择状态和未被选择状态,据此可将任务集I划分为2个子集:选择集Is(已被用户选择的任务集合)、推荐集Ic(未被用户选择的任务集合),形式化定义为:
Is={ip|ip,
Ic={iq|iq,
其中,m为用户数,T(j,p)为用户j对任务p的选择情况. 从定义可知:Is∩Ic=∅,Is∪Ic=I.
1.2.2用户-任务类选择矩阵Sm×q由于个性化推荐系统中的任务具有选择唯一性,即每个外包任务有且仅有1个用户可以选择,且只能选择1次,因此,根据用户对单个外包任务的选择而构建的用户-任务选择矩阵Tm×n中的数据会极其稀疏,以此产生的推荐会存在较大偏差.
同时,用户对单个任务的单次选择行为不能完全体现用户的兴趣与偏好,但用户对不同类别任务的多次选择行为则能较好地反应用户的兴趣与偏好. 考虑个性化推荐系统中的任务来自多迪IT任务外包平台,因而可根据该公司开展的业务类型C(网站建设、手机应用和网络营销等),将选择集Is、推荐集Ic中的任务进行分类并分配相应的类标号Cj. 在分类的基础可将用户-任务选择矩阵Tm×n转换为用户-任务类选择矩阵Sm×q(表1). 其中,m行代表有m个注册用户,q列代表Is中的任务可分为q大类,Si,j表示用户ui在任务类Cj中选择的任务总个数.
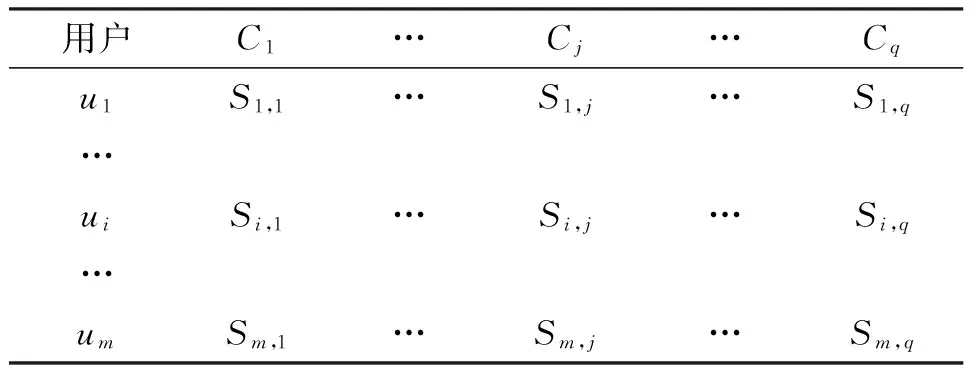
表1 用户-任务类选择矩阵 Sm×q
本文采用用户-任务类选择矩阵代替用户-任务选择矩阵,并以此作为推荐模型的核心,在一定程度上缓解了数据稀疏对推荐准确性的影响.
1.3用户综合相似性
个性化任务推荐的核心工作是计算相似性,度量相似性的指标有多种,比如标准余弦相似性、修正余弦相似性、Pearson相关系数等,实验表明Pearson相关系数更适于用户或项目间的相似性度量[14],本文在计算相似性时采用Pearson相关系数作为度量指标.
1.3.1用户选择相似性用户选择相似性体现了用户对不同任务类的偏好程度,在矩阵Sm×q上进行计算:
Sims(ua,ub)=
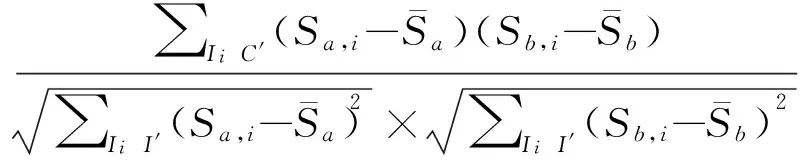
(1)
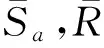
C′=C(ua)∩C(ub),
(2)
其中,C(ua)和C(ub)为用户ua和ub各自选择的任务类.
若仅用式(1)的计算结果来度量用户之间的相似性可能会产生一定偏差:一是用户的选择有时并不代表用户的真实想法,如用户选择某一任务可能更多地是受到外界因素的影响;二是当C′很小时,计算结果可能会高估用户的相似性. 为此,利用用户Profile文本相似性来平衡用户选择相似性.
1.3.2用户Profile文本相似性任务外包推荐平台上用户注册的Profile文本通常包含可信度较高的用户特征信息,Profile文本相似性在某种意义上也体现了用户本体之间的相似特征,可在一定程度上平衡用户选择相似性. 基于文本向量空间模型TVSM (Text Vector Space Model)是计算Profile文本相似性的有效工具,它的核心思想是:
(1)提取文本dj中的特征词Ti,并计算每个特征词的权重pi,j,计算公式如下:
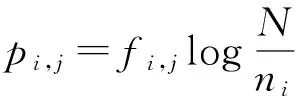
(3)
其中,fi,j表示特征词Ti在文本dj中出现的次数;N表示文本总数;ni表示含有特征词Ti的文本数.
(2)利用标准余弦相似性公式计算文本相似性:
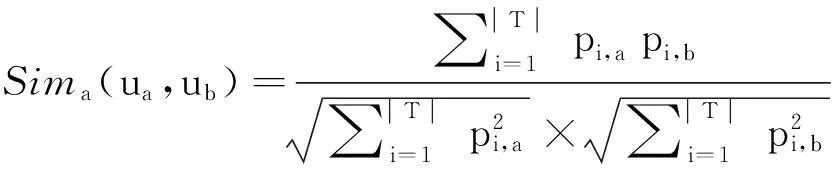
(4)
其中,|T|为特征词的总数;da、db分别为用户ua、ub的profile文本;pi,a为用户ua的Profile文本中第i个特征词的权重.
根据式(3)和式(4)可计算任意2个Profile文本之间的相似性.
1.3.3用户综合相似性融合用户选择相似性、用户Profile文本相似性,可得用户综合相似性:
Sim(ua,ub)=αSims(ua,ub)+βSima(ua,ub),
(5)
其中,α与β为权重因子,满足α,β[0,1]且α+β=1. 不同用户之间2类相似性的权重因子应动态变化,对权重因子α和β动态取值时需作如下考虑:
(1)由于不同用户间的选择相似性与Profile文本相似性差异较大,因此,在计算不同用户之间综合相似性时,α和β的取值应该不同.
(2)当用户的选择任务的数量越大,基于用户选择的相似性就越高,α值应越大;反之β的值应越大.当β=1时,完全使用用户Profile文本相似性作为用户综合相似性,可用于缓解冷启动问题.
基于以上考虑,采用用户选择相似性、用户Profile文本相似性二者平方和的比值来动态计算α、β:

(6)
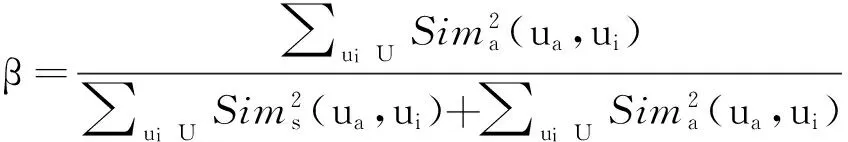
(7)
由式(5)~(7)可计算出各用户之间的综合相似性.
1.4任务紧要度
任务紧要度是借鉴于管理学中“时间四象限”法的理论,时间四象限法是“重要性-紧急性”二维事件优先模型,将任务按照重要和紧急划分为4个“象限”:既紧急又重要、重要但不紧急、紧急但不重要、既不紧急也不重要(图1).
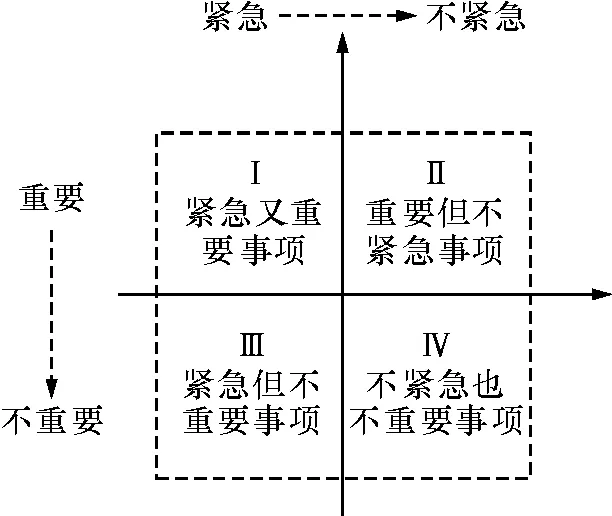
图1 时间四象限
处理四象限中事项的顺序为:先是紧急又重要的,接着是重要但不紧急的,再到紧急但不重要的,最后才是既不紧急也不重要的,“四象限”法的关键在于第二类和第三类的顺序问题.
受时间四象限法启发,为度量推荐集Ic中任务的紧急性与重要性,本文引入紧急度、重要度和紧要度等概念.
定义1(任务紧急度)任务截止时间与当前时间之间的时间差称为任务剩余时间Ts,完成任务所需的最少时间称为任务最短时间Tp,则任务k的紧急度urg(k)可定义为:
(8)
其中,Tk,s、Tk,p为项目k的剩余时间与最短时间.
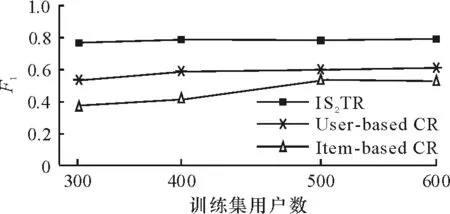
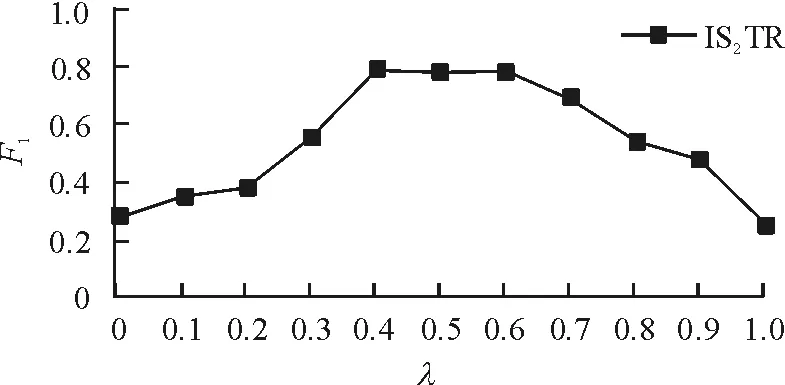
由式(8)可知,当Tk,s 定义2(任务重要度)若val表示任务能产生的收益或价值,T′表示用户完成任务的真实时间,任务重要度imp可定义为: (9) 任务重要度本质上是任务性价比的一个度量,取值越大代表任务产生的收益越高,对用户的重要性也越大. 由式(9)可知imp(k)一定为大于1的实数,为减小推荐误差需对其进行规范化. 由于在任务推荐系统中关系Tp≤T′≤Ts一定成立,设impp(k)=valk/Tk,p,imps(k)=valk/Tk,s,则imp(k)[imps(k),impp(k)],由 (10) 可实现imp(k)在[0,1]上的最小-最大规范化,规范化后的imp′(k)[0,1]. 定义3(任务紧要度)虽说每个外包任务都具有紧急性与重要性,但对于不同的用户或应用场景,其所关注的侧重点会有不同,任务紧要度sig就是对任务紧急度、重要度的综合评定,定义如下: sig(k)=×urg(k)+(1-)×imp′(k), (11) 1.5个性化任务推荐 基于用户综合相似度、任务紧要度的个性化任务推荐主要包含两大步骤:一是在选择集Is上根据用户综合相似度寻找目标用户的Top-K最近邻,并将Top-K最近邻选择任务次数最多的任务类Cj预测为目标用户最感兴趣的任务类;二是在推荐集Ic上计算任务类Cj中任务的紧要度,依据紧要度的大小向目标用户产生Top-K′任务推荐. 算法1用户综合相似矩阵计算算法 输入:用户-任务类选择矩阵Sm×q,权重因子α、β 输出:用户综合相似度Sim(m×m) ①根据式(1)在Sm×q上计算用户选择相似度,并存入sel_Sim(m×m); ②利用用户注册profile文本,计算用户文本相似度,并存入attri_Sim(m×m); ③扫描sel_Sim(m×m)、attri_Sim(m×m),计算用户综合相似度,存入Sim(m×m). 算法2个性化任务推荐算法 输入:目标用户ua,用户综合相似度Sim(m×m),权重因子 输出:用户ua的Top-K′推荐任务集 ①在综合相似度Sim(m×m)中扫描ua所在行,顺序取出Top-K紧邻用户{u1,u2,…,uk}; ②Foru1toukdo 在用户-任务类选择矩阵Sm×q中扫描ui所对应的行,返回行中最大值所对应的列号,即任务类别号Ci; ③Ci(i)中频数最大的值Cp作为目标用户最感兴趣的任务类; 1.6算法整体复杂度分析 推荐算法完成个性化任务推荐的2个阶段均需对数据进行处理与计算. 在寻找目标用户Top-K近邻阶段:①扫描矩阵将Tm×n转换为Sm×q,其最大计算复杂度为O(m×q);②依据Sm×q计算用户选择相似度Sims(ua,ub),是传统协同过滤推荐的必备步骤,计算复杂度为O(m2);③计算用户Profile文本相似性Sima(ua,ub),计算复杂度与②相同;④计算用户综合相似性Sim(ua,ub),寻找目标用户Top-K近邻,其最大计算复杂度也为O(m2). 因此,本阶段的最大计算复杂度为4×O(m2). 在向目标用户产生Top-K′任务推荐阶段:①依据用户的K近邻在Sm×q上寻找推荐任务类Cp,过程只需矩阵行扫描,计算复杂度为O(1);②计算Cp中各任务的紧要度,完成任务推荐,该过程计算复杂度也为O(1). 综上所述,寻找目标用户Top-K近邻的计算复杂度直接决定着推荐算法的整体计算复杂度,算法的整体计算复杂度为4×O(m2),但具体到个性化任务推荐平台上,用户专业性高,数量规模不大,profile文本变化极小,且用户增长的速度远小于任务增长的速度,因此,只需定期离线更新用户选择相似性sel_Sim(m×m)和综合相似性Sim(m×m)即可. 实验平台采用PC机(Intel(R)Core(TM)i5-4790CPU@4.0GHz,内存8G),操作系统为Windows7,算法使用Java语言编写. 2.1数据集 本文实验数据来源于广州多迪集团“百单网”网站[15],该网站是一IT项目外包平台,数据集包含用户注册profile文本数据和任务选择数据. 其中,用户profile文本数据包含:性别、年龄、毕业院校、学历、专业、职业;任务选择数据的具体内容如下:用户1 682个,任务23 298项,选择任务记录20 502条,用户选择任务平均10项,任务类别7个. 实验采用重复性随机取样来验证推荐方法的有效性,每次验证随机抽取80%的数据作为训练集、20%的数据作为测试集. 2.2推荐质量的评价指标 由于个性化任务推荐平台上不存在用户评分,只有用户选择行为,因此实验采用的推荐准确性评价指标为F1,它是评价推荐质量的一个重要指标,是基于推荐准确率P和召回率R的一个综合指标. 对于任意一个用户u,假设其在测试集中真实选择的任务集I长度为D,系统推荐的任务集I′长度D′,那么准确率与召回率为: (12) (13) 但由于指标P与R相互影响,一般情况下准确率高、召回率就低,为缓解二者的相互影响,实验采用F1作为推荐质量的评价指标: F1=2PR/(P+R). (14) 一般来说,F1取值越高代表推荐质量越高. 2.3实验结果与分析 实验1:算法的推荐效果. 为验证个性化推荐算法的推荐质量,将本文的推荐算法IS2TR与传统的基于用户的协同过滤推荐算法、基于项目的协同过滤推荐算法进行对比实验. 实验随机选取280个用户作为测试集,将剩下的用户分为4组,每组用户数依次为500、400、300、200为训练集,计算系统推荐任务集与用户真实选择任务集两者之间的F1值来度量推荐质量的高低. 实验参数设置为:=0.4,K=K′=15,实验结果见图2. 图2 IS2TR算法与其他算法推荐质量对比 Figure2RecommendationqualitycomparisonamongIS2TRandtheothers 由图2可知:在不同容量的训练集下,IS2TR算法的F1值均高于另外2个算法,表明该算法推荐的任务更接近于用户真实选择的任务,符合现实中用户的选择行为,具有相对较高的推荐质量. 实验2:α与β. α与β是用于调整用户选择相似性和用户Profile文本相似性而设定的参数,合适的参数使得用户综合相似性的计算更加合理,推荐效果更加准确,因此对α与β作如下调优实验. 实验参数设置=0.4,K=K′=15,设置α从0变化到1,每次变化增量为0.1,依次统计α每次改变时的F1值,由图3可看出F1先随α的增大而增大,后随α的增大而减小,当时,F1获得最大值. 实验说明用户选择相似度在用户综合相似度中占稍高比例可以提高推荐准确度,而α+β=1,因此,α与β的较优取值分别可设为0.65和0.35. 图3 α对F1的影响 同时,实验结果显示:当α=0时,F1值并不为0.说明引入用户Profile文件相似性不仅一定程度上可缓解冷启动问题,还能提高系统的推荐准确性. 图4 对F1的影响 实验4:K与K′的最佳取值. 参数K与K′分别用于确定目标用户最相似邻居的个数和向目标用户推荐的任务集长度,K与K′值的大小对算法推荐准确度有一定的影响. 若K设置太大,将会增大最相似邻居的个数,可能造成将相似性相对较小的邻居所偏好任务类中紧要度较高的任务作为推荐任务进行推荐;K′值设置不合理会直接影响算法的准确率与召回率,从而影响算法的推荐质量. 为分析K对推荐质量的影响,设置=0.5,K′=15,K从5变化到30,每次变化增量为5;类似分析K′对推荐质量的影响,设置=0.5,K=15,K′从5变化到25,每次变化增量也为5. 图5、图6分别显示了K与K′对F1的影响. 图5 K对F1的影响 图6 K′对F1的影响 从图5可知,F1先随着K的增加而增加,到达一定的峰值后随着K的增加而减小并趋于平缓. 实验数据表明最近邻居数小于一定的数量会极大降低推荐的准确率,但如果超出一定数量则从紧邻中寻找出来的任务类趋于稳定,推荐的任务集也趋于稳定,因此,K值的合理范围为15~20. 图6表明,推荐任务集的长度太小或太大都会影响准确率或召回率,最终影响F1值,因而K′较为合理的取值为15,这也比较符合任务外包平台的真实情况. 为将传统的协同过滤推荐方法应用于企业或行业的个性化任务推荐中,本文提出了基于用户-任务类选择矩阵为核心、融合用户Profile文本及任务紧要度的协同推荐算法. 在广州多迪集团“百单网”数据集上的实验结果表明,融合用户Profile文本、任务紧要度的推荐具有较高的推荐质量,并能在一定程度上缓解冷启动和数据稀疏性问题. 除了用户Profile文本和任务紧要度,用户和项目都具有各自的属性,同时外包任务的发布时间也具有随机性,如何结合这些属性及发布时间来进一步提高推荐质量是今后研究的重要内容. [1]KORENY.Collaborativefilteringwithtemporaldynamics[J].CommunicationsoftheACM,2010,53(4):95. [2]SUNGF,WUL,LIUQ,etal.Recommendationsbasedoncollaborativefilteringbyexploitingsequentialbeha-viors[J].JournalofSoftware, 2013, 24(11):2728. [3]PARKST,PENNOCKDM.Applyingcollaborativefilteringtechniquestomoviesearchforbetterrankingandbrowsing[C]∥Proceedingsofthe13thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2007:556. [4]SARWARB,KARYPISG,KONSTANJ,etal.Applicationofdimensionalityreductioninrecommendersystems—Acasestudy[C]∥Proceedingsofthe6thACMSIGKDDInternationalConferenceonKnowledgeDisco-veryandDataMining.Boston:[s.n.], 2000:97. [5]DENGAL,ZHUYY,SHIYZ.Acollaborativefilteringrecommendationalgorithmbasedonitemratingprediction[J].JournalofSoftware,2013,14(9):1626. [6]黄创光,印鉴,汪静,等. 不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377. HUANGCG,YINJ,WANGJ,etal.Uncertainneighbors’collaborativefilteringrecommendationalgorithm[J].ChineseJournalofComputer, 2010,33(8):1369-1377. [7]SARWARB,KARYPISG,KONSTANJ,etal.Item-basedcollaborativefilteringrecommendationalgorithms[C]∥Proceedingsofthe21thInternationalConferenceonWorldWideWeb.NewYork:ACM, 2012: 285-295. [8]CHENJ,YINJ.Acollaborativefilteringrecommendationalgorithmbasedoninfluencesets[J].JournalofSoftware, 2007,18(7):1685-1694. [9]邓华平. 基于项目聚类和评分的时间加权协同过滤算法[J].计算机应用研究, 2015,32(7):1966-1969. DENGHP.Time-weightedcollaborativefilteringalgorithmbasedonitemclusteringanditemscore[J].ApplicationResearchofComputers,2015,32(7):1966-1969. [10]朱强, 孙玉强. 一种基于信任度的协同过滤推荐算法[J]. 清华大学学报(自然科学版), 2014,54(3):360-365. ZHUQ,SUNYQ.Collaborativefilteringrecommendermethodbasedontrust[J].JournalofTsinghuaUniversity(ScienceandTechnology),2014,54(3):360-365. [11]贺超波,汤庸,傅城州,等. 融合社交网络信息的协同过滤方法[J]. 暨南大学学报(自然科学版), 2013,34(3):243-248. HECB,TANGY,FUCZ,etal.Collaborativefilteringmethodwithsocialnetwork[J].JournalofJinanUniversity(NaturalScience),2013,34(3):243-248. [12]YINJ,WANGZS,LIQ,etal.Personalizedrecommendationbasedonlarge-scaleimplicitfeedback[J].JournalofSoftware, 2014, 25(9):1240-1252. [13]WANGZS,LIQ,WANGJ,etal.Real-timepersonalizedrecommendationbasedonimplicituserfeedback[J].ChineseJournalofComputer, 2015,38(7):1408-1421. [14]BALLB,KARRERB,NEWMANMEJ.AnEfficientandprincipledmethodfordetectingcommunitiesinnetworks[J].PhysicsReviewE,2013, 84(3):Art036103,14pp. [15]多迪集团.百单网[Z/OL].[2015-12-27].http:∥www.100dan.cn/. 【中文责编:庄晓琼英文责编:肖菁】 Personalized Task Recommendation Based on Integrated Similarity and Item Significance HU Zhijie1,2, YIN Jian2* (1.Department of Information Engineering,Guangdong Polytechnic College,Zhaoqing 526100,China;2.School of Data and Computer Science,Sun Yat-Sen University,Guangzhou 510006,China) The area of collaborative filtering (CF) applied in IT project outsourcing is studied and the researches on personalized task recommendation are carried out. Based on this, a personalized task recommendation method is presented combined with Profile text similarity, task selection similarity and integrated similarity. This method transforms the users’ selection behavior into user items-class selection matrix, and it is used to compute the selection similarity among users. User’s profile text similarity is also considered to balance the selection similarity, while integrated similarity is applied to measure the timeliness and values and build waiting recommendation item set by choosing the proper threshold. The experimental results indicate that the proposed method is effective and it could be used to alleviate the data sparseness and cold start problems. collaborative filtering; integrated similarity; items significance; recommendation system 2016-01-12《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n 国家自然科学基金项目(61033010,61272065);广东省自然科学基金项目(S2011020001182,S2012010009311);广东省科技计划项目(2013B090200006) 印鉴,教授,Email:issjyin@mail.sysu.edu.cn. TP393 A 1000-5463(2016)04-0106-07
2 实验结果及分析


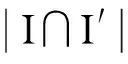



3 小结与展望
猜你喜欢
数学物理学报(2022年5期)2022-10-09
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
河北画报(2020年8期)2020-10-27
文苑(2020年4期)2020-05-30
汽车观察(2019年2期)2019-03-15
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
中国卫生(2016年5期)2016-11-12
浙江大学学报(工学版)(2016年2期)2016-06-05
