
面向HEVC的时空域感知量化
2016-11-09 03:52彭宗举邹文辉费马燕
西华师范大学学报(自然科学版) 2016年1期
彭宗举,邹文辉,陈 芬,费马燕
(1.宁波大学 信息科学与工程学院,浙江 宁波 315211;2.西华师范大学 电子信息工程学院,四川 南充 637009)
面向HEVC的时空域感知量化
彭宗举1,邹文辉2,陈 芬1,费马燕1
(1.宁波大学信息科学与工程学院,浙江宁波 315211;2.西华师范大学电子信息工程学院,四川南充 637009)
针对高效视频编码(High Efficiency Video Coding,HEVC)标准在编码过程中没有考虑到人类视觉系统的感知特性的问题,提出了一种基于HEVC的时空域感知量化编码策略。首先,对输入的视频序列在变换域求取恰可察觉失真(Just Noticeable Distortion,JND),在最大编码单元(Largest Coding Unit,LCU)层根据JND求取相应的量化参数。其次,通过运动估计方法对输入的视频序列求取运动区域,由于视频序列中存在着各种各样的噪声,影响运动估计的准确性,因此对运动估计后的图像进行滤波处理,以减弱噪声的影响,并将运动区域视为时域感兴趣区域,之后根据是否为运动区域分策略调节量化参数。最后,在LCU编码时,对根据空域感知特性调节的量化参数以及时域感知特性调节的量化参数进行加权,作为LCU最终编码量化参数。实验结果表明,提出的算法在编码时视觉感兴趣区域选择了细量化,而视觉非感兴趣区域选择了粗量化。感兴趣区域的PNSR相对HM11.0能提高0.20—0.59dB,率失真性能最小能提升3.8%,最大能提升6.8%。与代表性文献算法相比,PSNR提升较大。
高效视频编码;感兴趣区域;感知编码;量化参数
0 引 言
2013年,视频编码联合专家组颁布了新一代视频编码标准——高效视频编码(High Efficiency Video Coding,HEVC)[1],其编码性能是H.264/AVC[2]的两倍,更适合于高清视频序列的编码。视频编码技术的迅猛发展影响了电视广播、互联网以及消费类电子产品中视频服务的推广。然而,这些编码技术并没有将人类视觉系统的感知特性考虑在内,不管是哪种视频应用类服务,人类才是视频信号的最终接收者。因此,在编码过程中考虑人类视觉系统的感知特性是一种提高视频编码性能的有效方式。
目前,利用视觉注意力或敏感度模型指导编码已有较多的研究,可以分为三类:根据显著图调节视频编码过程中的量化参数[3,4],根据恰可察觉失真(Just Noticeable Distortion,JND)调节视频编码过程中的残差系数或变换系数[5-8]和根据人类视觉系统的感兴趣区域调节码率控制中的比特分配[9]。Hadizadeh等人将IKN显著模型用于视频压缩编码中,通过提取视频序列中的显著区域,将视频序列中的编码帧分为视觉感兴趣区域与视觉非感兴趣区域,进而调节这些区域的量化参数。虽然编码性能得到了一定的提高,但是这种策略需要提供视觉注意力的能量图且没有考虑视频序列的时域特性[3]。Chen等人将基于中心凹的恰可察觉失真(Foveated JND,FJND)作为视觉敏感度模型,FJND在空域JND的基础上考虑了视网膜中心凹到显示器的距离,Chen等人认为JND阈值越大的区域引起的视觉敏感度越高,因此编码量化参数也越小。虽然视频序列中一些视觉敏感的边缘区域得到了更好的保护,然而其仅考虑了空域特征没有考虑视频序列中运动区域更易引起人眼的视觉关注[5]。Kim等人在HEVC上提出了基于JND模型的视觉感知策略,通过JND最大程度上去除空域视觉冗余。虽然其算法在保持视觉质量的同时节省了较多的码率,然而其只考虑了空域的视觉感知特征,没有考虑时域特征[7]。Meddeb等人提出了基于感兴趣区域的码率控制算法,他们认为人类视觉系统更加关注视频序列中的人脸区域,通过人脸检测算法提取出视频序列中的人脸区域,将人脸作为人类视觉系统的感兴趣区域,在码率控制比特分配过程中,感兴趣区域相对于非感兴趣区域分配更多的比特。虽然感兴趣区域的编码质量得到了一定的提高[9],然而这种策略只适用于视频会议场合。
针对以上算法的缺陷,本文提出一种基于HEVC的时空域感知量化编码策略。首先该策略考虑了空域感知特性,将JND作为视觉敏感度调节编码过程中的量化参数。其次该策略考虑了时域感知特性,相对空域感知特性,视频序列中的运动目标更易吸引人眼的关注,通过运动估计求取视频序列中的运动区域,根据是否运动区域分策略调节编码过程中的量化参数。最终将空域感知特性计算的量化参数以及时域感知特性计算的量化参数进行加权。实验结果表明提出的算法能够有效提高视频重建质量,PSNR平均提高0.20-0. 59dB,编码率失真性能最低能提升3.8%,最高能提升6.8%。
1 时空域感兴趣区域提取
视觉注意是人类的一种潜意识过程,根据注意力的驱动方式,可将视觉注意力分为自底向上和自顶向下型驱动。前者是指由外界信号的特性而决定注意的导向,例如视频场景中和人眼视网膜以及光学属性相关的因素,后者来自于人类复杂的心理过程,跟个人的兴趣爱好等因素有关。由于自顶向下的注意力驱动机制跟心理学、人的阅历等都有一定的关系,成为了实际应用中难以突破的瓶颈。因此本文从自底向上的注意力驱动机制即数据型驱动出发,考虑到人眼在观察一个陌生的视频场景时,刚开始往往会在视频场景中搜索感兴趣区域等,人眼适应于这种视频场景后,场景中的运动对象会更加吸引人眼的高度关注。为此,本文利用该特性设计了一种符合人的视觉感知特性的感知量化编码策略。
1.1 空域感兴趣区域
人眼是视频信号的最终接收者,建立符合人眼的感知编码特性相当重要,已有学者建立了一些模拟人眼感知的模型,例如显著图模型[10]、离散余弦变换(Discret Cosine Transform,DCT)域JND模型[11]。本文采用(Discret cosine Transform,DCT)域JND模型来描述人类视觉系统的感知特性,其考虑了人眼的对比度以及掩膜效应。DCT域JND在数学上表示为基本阈值和调节因子的乘积形式[11],即:
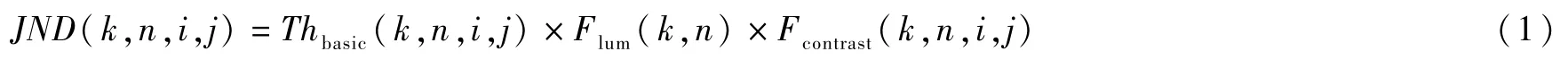
式中,n表示输入视频第k帧中第n个编码块;i,j表示DCT系数的索引号;Thbasic、Flum以及Fcontrast分别表示基本阈值、亮度掩膜调节因子和亮度的对比度掩膜调节因子。
1.1.1 基本阈值
在编号为n的编码块中(i,j)位置的子带系数,其相应的空间频域ωi,j表示为:

式中,N表示编码块的维数,θx,θy分别表示像素水平和垂直方向视角,Rvd表示视距到图像高度的距离权重,Pich表示图像的高度。
DCT子带基本阈值的计算公式为:
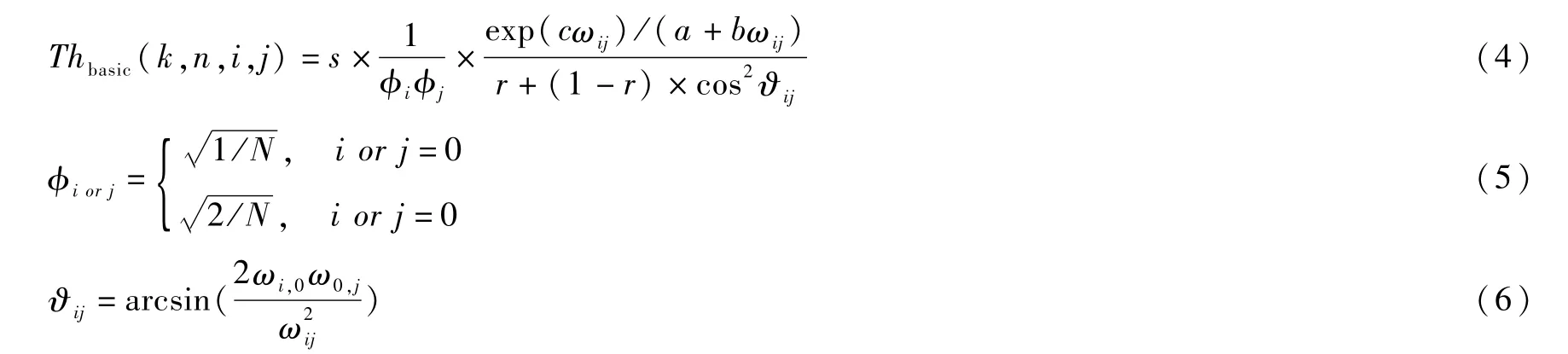
式中,s表示集合效应,取值为0.25,Фi、Фj表示DCT归一化系数,ϑij表示DCT系数的方向角,参数a、b以及c分别取值为1.33、0.11和0.18。
1.1.2亮度掩膜调节因子
亮度掩膜机制跟图像中的亮度变化有关,根据Weber定律,最小可感知亮度差可能随着背景亮度的增加而增加,即背景亮度过高过低的情况下人眼不易察觉量化误差,亮度掩膜调节因子的计算公式为:

式中,¯I表示第n个编码块的亮度均值。
1.1.3 对比度掩膜调节因子
对比度掩膜效应是人类视觉系统中一个重要的成分,在计算对比度掩膜因子时,首先需要利用Canny算子对图像进行归类,即纹理区、边缘区以及平坦区。然后对这些区域赋予不同的权重,其中若是平坦与边缘区域,加权系数ψ=1;如果纹理区域且坐标索引满足(i2+j2)≤16,加权系数ψ=2.25;如果纹理区域且坐标索引满足(i2+j2)>16,加权系数ψ=1.25。最终对比度掩膜调节因子的计算公式为:
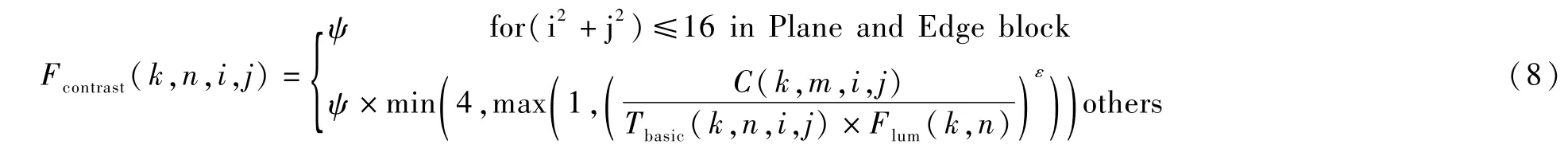
式中,ε=0.36,C(k,n,i,j)是第n个编码块(i,j)位置的DCT系数。
图1(a)是BasketballPass序列第7帧的原图像,图1(b)是对BasketballPass第7帧求取的JND图。由于在编码过程中,用同一个QP对图1(b)中具有较多白色像素点的编码单元对应着的彩色图像中的编码单元进行编码,和对同尺寸具有较少白色像素点的编码单元对应着的彩色图像的编码单元进行编码,往往具有较多白色像素点的编码单元造成的视觉失真大于具有较少白色像素点的编码单元。另外人眼对图像中的对象边界由编码造成的失真也比较敏感。为此,本文将JND图中白色像素点对应着的彩色图像中像素点的位置视为视觉感兴趣点,一些视觉感兴趣点组成视觉感兴趣区域。

图1 BasketballPass序列第7帧图像以及相应的JND图
1.2 时域感兴趣区域
运动检测在视频分析中一直是一项比较重要的技术,视频场景中的前景运动区域检测也是一个棘手的问题。主要原因有二:一是视频场景中的背景区域具有动态的复杂纹理;二是拍摄相机的移动,固定相机不适合用于实际场合的序列拍摄。现有的运动检测技术有帧差法、全局搜索法以及灰度投影法。帧差法简单、效率高,然而相邻帧直接差分以提取前景运动区域不够准确。灰度投影法是一种全局运动矢量的估计方法,已被应用于电子稳像中,然而,其只适应于拍摄相机平行移动的场合,不适应于推进式拍摄相机。本文中采用全局搜索算法进行前景运动区域的检测。
编码当前帧时,首先设定运动估计的搜索范围(4个像素点)以及运动估计块大小(8×8),根据搜索范围在当前帧的前一帧中去搜索与当前运动估计块的最佳匹配块。如图2所示。
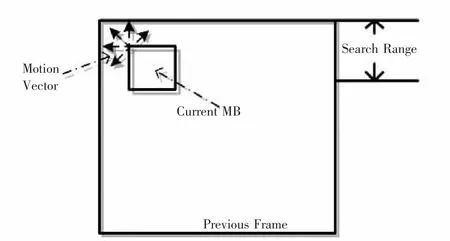
图2 运动估计示意图
运动估计过程中根据匹配块的最佳代价值选择当前运动估计块的最佳运动矢量,代价值的求取如式(9)所示:
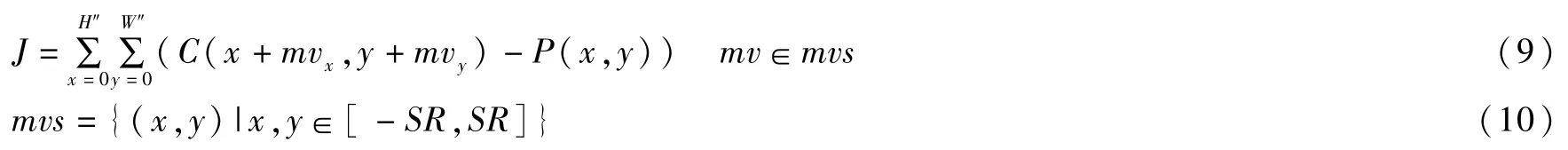
式中,C(x,y)和P(x,y)分别为当前编码帧以及当前编码帧的前一帧中坐标为(x,y)的像素值,mv为运动矢量,mvx和mvy分别为运动估计块水平方向和垂直方向的运动矢量,mvs为运动矢量的集合,J为运动估计块在mv下的代价值,SR为搜索范围。
求出运动估计块在每个运动矢量下的代价值,选择代价值最小的运动矢量作为运动估计块的最佳运动矢量,如式(11)所示:

式中,mv*为最佳运动矢量。
运动估计的过程受序列中各种噪声的影响,因此本文采用一个3×3的滤波窗口对整个编码帧中运动估计块的运动矢量进行滤波处理,滤波窗口如图3所示。其中Current MB为当块。如果当前待滤波的运动估计块周围运动估计块的个数少于4个,则认为当前块不是运动区域。用公式描述为:

式中,num为当前待滤波运动估计块周围运动估计块的个数。
由于在HEVC编码的过程中,是以LCU为单位对视频序列进行编码的,因此最终的感兴趣区域需要以LCU为单位。本文的做法是对LCU进行统计,如果LCU中存在运动部分,则对应LCU为运动感兴趣区域。图4(a)、4(b)和4(c)分别为BasketballPass序列第7帧中的滤波前运动区域、滤波后的运动区域和最终的感兴趣区域。图中白色为运动区域或者感兴趣区域。

图3 滤波窗口
2 HEVC中时空域感知量化
在编码过程中,量化参数的调节直接影响到视频的重建质量。如果编码单元选择粗量化,视频重建质量较差,码率较低;选择细量化,视频重建质量较好,码率较高。本文首先根据编码单元的DCT域JND计算相应的量化参数(QP),用公式表示为:

图4 感兴趣区域提取

式中,QPHEVC为HEVC编码平台所用的量化参数,ωn为调节因子,计算公式为:
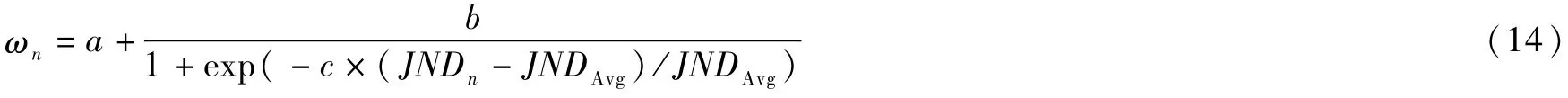
式中,a,b以及c是常量[5],取值分别为 a=0.7,b=0.6,c=4,JNDAvg表示DCT域JND的平均特征值。定义根据JND调节QP,QP的变化量为△QPJND,其计算公式为:

由于在HEVC编码平台中,如果不开启量化组层编码控制,即-dqd使能端,量化都是以最大编码单元进行调节,也就是一个最大编码单元里面的编码单元共享同一个QP。而通过步骤1.2求出的运动感兴趣区域是以8×8的块为单位,有学者通过运动感兴趣区域的面积调节QP,但是往往会造成那些有运动但又运动较小的区域得不到较好的保护。作者采取一种简单温和的策略,即如果当前编码的LCU中包含运动区域则△QPMV=-2;否则△QPMV=2。用公式描述为:

式中,ROI表示运动感兴趣区域,No ROI表示非运动感兴趣区域。
由于在第一帧编码时,无前一帧用来作为运动估计的参考帧,因此视频序列的第一帧仅将空域JND作为视觉感知特性。而在第二帧及之后的编码帧采用DCT域JND以及时域的运动特性作为最终的视觉感知特性。综上,利用视觉感知特性调节 LCU编码量化参数的策略为:

式中,n′、m′的取值跟编码帧的帧号有关,如果编码帧为第一帧,则 n′=1、m′=0;如果编码帧非第一帧,则 n′=0.5、m′=0.5。同时为了保持最大编码单元之间的视觉连续性,△QP被限制在区间[-2.0,+3.0]。
3 实验结果及分析
本文所提出的方法在HM11.0上进行实现,采用全I帧编码配置环境[12],初始量化参数分别为22、27、32、37。为了验证本文算法的普适性,选取了三种分辨率类型的序列,这三种分辨率分别为416×240、832× 480以及1920×1080。每种分辨率类型的序列选取两个,这些序列有不同的运动程度,序列内容也由简单到复杂。为了验证本文算法的有效性,采用BDBR[13]评价其率失真性能。BDBR表示在相同的PSNR条件下节省的码率,即BDBR负的越多表示在相同的PSNR条件下节省的码率越多。
从表1中可看出,提出的算法不管是整帧的平均PSNR还是感兴趣区域的平均PSNR均有很大的提升,整帧的平均PSNR提高了 0.12—0.46dB,感兴趣区域的平均PSNR平均提高了 0.2—0.59dB。虽然编码码率稍有上升但是其率失真性能提高了,BDBR最小有3.8%的提升,最大有6.8%的提升。文献[7]的编码策略相对 HM11.0码率节省了较多,然而 PSNR最小下降了0.64dB,最大下降了1.67dB。从编码性能上可看出本文的算法优于文献[7]。
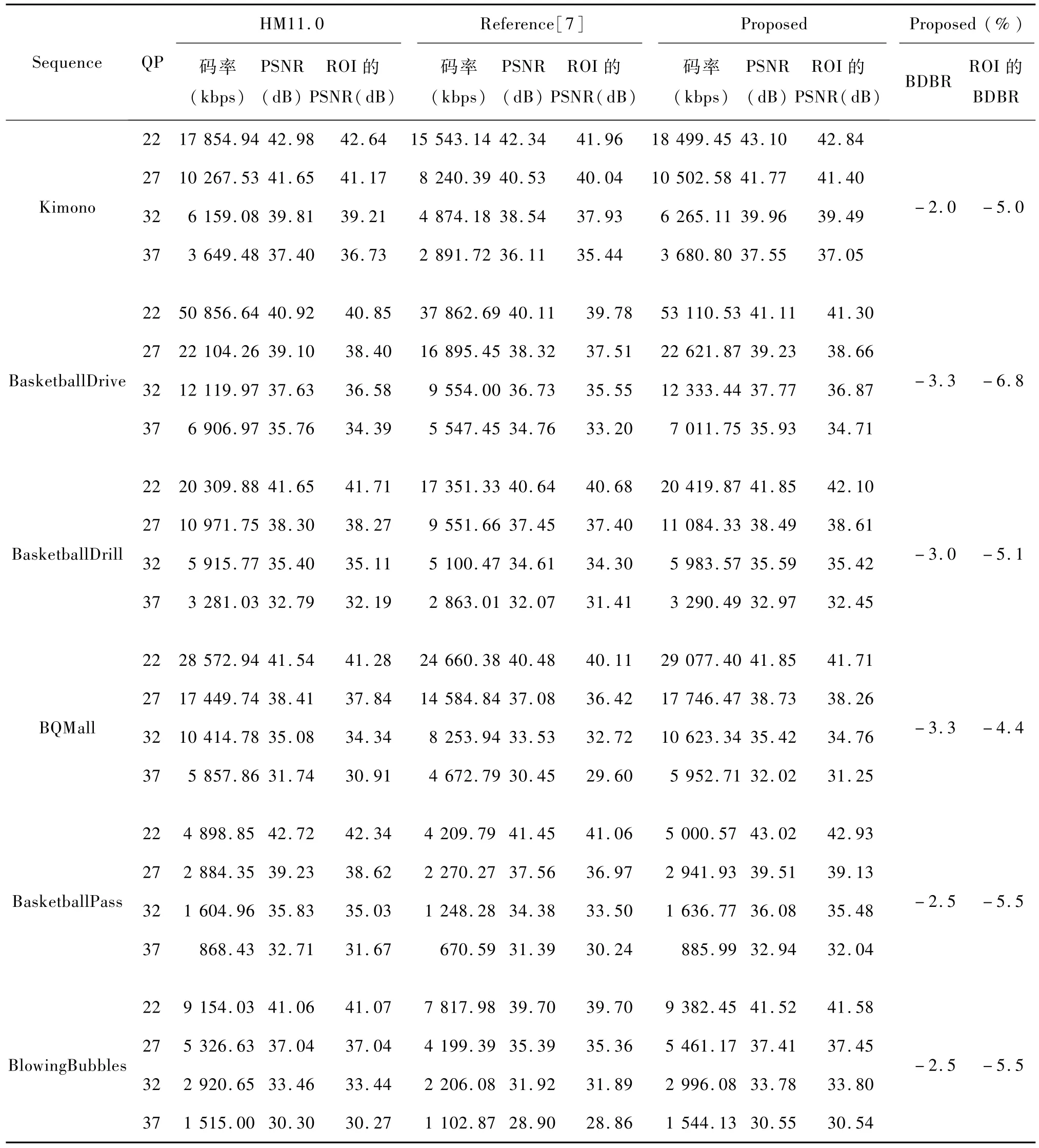
表1 在Intra_main配置文件下的测试结果
图5(a)、5(b)以及5(c)分别是BasketballDrive序列第2帧的彩色图像、相应的JND图像以及运动区域,从图中可发现其运动区域和 JND图像非常类似,在编码过程中本策略倾向于对这些区域选择细量化,而对既不是JND图中的视觉兴趣区域又不是运动区域图中的运动区域选择粗量化。如果不采用本策略,视觉显著的区域和视觉非显著的区域采取同样的量化参数编码,则会导致视觉显著的区域发生的失真明显大于视觉非显著的区域。图5(d)是采用本策略的最终编码 QP图,其和图5(b)、图5(c)非常吻合,图中方块越白,表示相应的编码QP越小,反之亦然。图5(d)之所以是以方块为单位,是因为在实际编码过程中,一个LCU及其里面的CU都是共享同一个QP对变换系数进行量化处理。

图5 BasketballDrive第2帧彩色图及相应的运动区域、JND图、最终编码QP
图6(a)、(b)以及(c)分别是BQMall序列第43帧的彩色图像、相应的JND图以及运动区域。从图中可看出DCT域JND求出的视觉显著区域较多,这些区域往往是在对象的边缘区域。如果用同一个量化参数对同尺寸的两个编码块编码,其中一个块不具有边缘信息,另一个块具有边缘信息,编码后具有边缘信息的编码块极有可能边缘出现块效应。而利用本策略,这些区域会选择细量化,块效应产生的概率也会很大程度上降低。本策略同时也考虑了运动对象,运动对象也会选择细量化。BQMall序列相对BasketballDrive序列率失真性能提升较小,很大原因是由于求取的视觉显著区域面积较大,如果全都采用细量化,编码质量提升的同时势必造成码率的上升。如果编码区域中视觉显著区域与视觉非显著区域各占一半这样的编码效果会更好,因为这些非视觉区域采用粗量化,编码质量虽然略有下降,但下降速度没有码率下降的速度快,就如BasketballDrive序列。

图6 BQMall第43帧彩色图及相应的JND图和运动区域
图7(a)和7(b)是BasketballDrive以及BQMall这两个序列在本文算法、HM11.0以及文献[7]下的率失真性能对比图。从图中可看出本文算法的率失真性能明显优于HM11.0以及文献[7]的算法,从而验证了本文算法的有效性。
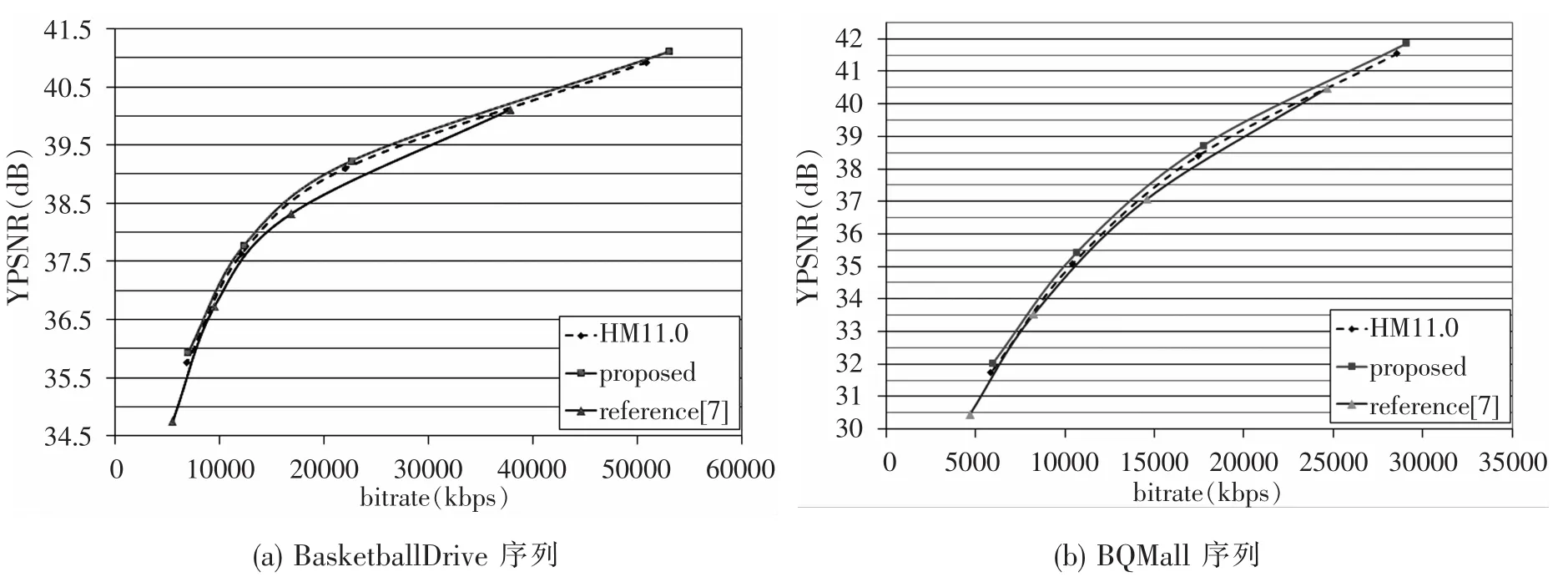
图7 率失真性能对比
4 结 论
本文在HEVC上提出了一种基于HEVC的时空域感知量化编码策略,该策略考虑了时空域的视觉感知特性。首先在DCT域,考虑了JND模型,在编码时能够根据显著性调节编码过程中的量化参数。在时域,由于自然场景下的序列存在着各种各样的对象运动,这些运动对象相对于静止对象更容易引起人类视觉系统的关注。因此,借助运动估计求取视频序列中的运动对象,再根据编码块中是否存在运动对象对编码过程中的量化参数进行优化。最后对时空域优化的量化参数进行加权。实验结果表明,本文算法在编码率失真性能上具有较大提升,最大能提升6.8%,感兴趣区域 PNSR最大能提升0.59dB。
[1]SULLIVAN G J,OHM J,HAN W J,et al.Overview of the high efficiency video coding(HEVC)standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1649-1668.
[2]OHM J R,SULLIVAN G J,SCHWARZ H,et al.Comparison of the coding efficiency of video coding standards—including high efficiency video coding(HEVC)[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1669-1684.
[3]HADIZADEH H,BAJIC IV.Saliency-aware video compression[J].IEEE Transactions on Image Processing,2014,23(1):19-33.
[4]LIY,LIAOW,HUANG J,et al.Saliency based perceptual HEVC[C]//2014 IEEE International Conference on Multimedia and Expo Workshops(ICMEW),Chengdu,2014:1-5.
[5]CHEN Z,GUILLEMOT C.Perceptually-friendly H.264/AVC video coding based on foveated just-noticeable-distortion model[J].IEEE Transactions on Circuits and Systems for Video Technology,2010,20(6):806-819.
[6]CABRITA A S,PEREIRA F,NACCARIM.Perceptually driven coefficients pruning and quantization for the H.264/AVC standard[C]//EUROCON-International Conference on Computer as a Tool(EUROCON),Lisbon,2011:1-4.
[7]KIM JH,BAE S,KIM M G.An HEVC-compliant perceptual video coding scheme based on JND models for variable blocksized transform kernels[J].IEEE Transactions on Circuits and Systems for Video Technology,2015,25(11):1-15.
[8]KIM J,KIM M.Analysis of the JND-suppression effect in quantization perspective for HEVC-based perceptual video coding[J].IEIE Transactions on Smart Processing&Computing,2015,4(1):22-27.
[9]MEDDEB M,CAGNAZZO M,PESQUET-POPESCU B.Region-of-interest-based rate control scheme for high-efficiency video coding[J].APSIPA Transactions on Signal and Information Processing,2014,3:e16.
[10]ITTI L,KOCH C,NIEBUR E.A model of saliency-based visual attention for rapid scene analysis[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,1998,(11):1254-1259.
[11]WEI Z,NGAN K N.Spatio-temporal just noticeable distortion profile for grey scale image/video in DCT domain[J].IEEE Transactions on Circuits and Systems for Video Technology,2009,19(3):337-346.
[12]BOSSEN F.Common HM test conditions and software reference configurations[C]//Proceedings of the 12th JCTVC Meeting. Geneva:JCTVC,2013:1-3.
[13]BJONTEGAARD G.Calculation of average PSNR differences between RD-Curves[EB/OL].(2001-03-28)[2015-01-15]. http://w ftp3.itu.int/av-arch/video-site/0104_Aus/
Spatial-tem poral Perception Quantization for HEVC
PENG Zongju1,ZOUWenhui2,CHEN Fen1,FEIMayan1
(1.Faculty of Information Science and Engineering,Ningbo Zhejiang University,Ningbo Zhejiang 315211,China;2.College of Electronic and Information Engineering,China West Normal University,Nanchong Sichuan 637009,China)
To solve the drawback of high efficiency video coding(HEVC)which ignores the property of human visual system in the process of video coding,a spatial-temporal perception quantization method is proposed in this paper.Three steps were taken in the experiment.First,just noticeable distortion(JND)in transform domain is obtained for input video sequence,and then used to calculate the quantization parameter(QP)for largest coding unit(LCU).Second,motion area is extracted according to input video sequence by motion estimation.Yet due to the variety of noise in the natural sequence,motion estimation would not be accurate enough.Thus,a novel filter is proposed to weaken the influence aroused by noise.The motion area is regarded as region of interest(ROI)and used to adjust the QP.Third,the ultimate QP is obtained by weighting the QP calculated by JND and ROI.Experimental results showed that the proposed method improves the rate distortion performance and PSNR.For the same PSNR,the proposed approach can save 5.1%bit on average.Maximal bit rate saving can reach 6.8%.The PSNR in ROI can be improved by 0.20~0.59dB compared with the HEVC reference software.
high efficiency video coding;region of interest;perceptual coding;quantization parameter
TN919
A
10.16246/j.issn.1673-5072.2016.01.010
1673-5072(2016)01-0067-08
2016-01-28
国家自然科学基金(U1301257,61271270)
彭宗举(1973—),四川南部人,教授,博士,博士生导师,主要从事图像处理、3D视频信号编码与通信领域的研究。
彭宗举,E-mail:pengzongju@nbu.edu.cn
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
军民两用技术与产品(2021年10期)2021-03-16
含能材料(2021年1期)2021-01-10
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
西南交通大学学报(2016年4期)2016-06-15
海峡科技与产业(2016年3期)2016-05-17
中国农业文摘-农业工程(2016年5期)2016-04-12
博客天下(2009年12期)2009-08-21
