
公路运营车辆荷载极值的预测方法比较研究
2016-11-16 07:49袁伟璋黄海云张俊平刘泽戈
城市道桥与防洪 2016年10期
袁伟璋,黄海云,张俊平,尹 兴,刘泽戈
(1.广州大学土木工程学院,广东广州510006;2.广东省交通职业技术学院,广东广州 510170)
公路运营车辆荷载极值的预测方法比较研究
袁伟璋1,黄海云1,张俊平2,尹兴1,刘泽戈1
(1.广州大学土木工程学院,广东广州510006;2.广东省交通职业技术学院,广东广州 510170)
为了研究桥梁结构在服役期间要承受的最大车辆荷载的预测方法,根据广东某高速公路3万多组货车的动态称重数据,采用对数正态分布模型,基于极值理论的POT模型和次序统计量模型,拟合运营车辆荷载的尾部分布,据此模型来预测未来两年可能出现的车辆荷载极值,并与相应实测数据进行对比验证,结果POT模型和对数正态分布的预测值与实测数据相近,但由于对数正态分布存在理论缺陷,最终得出了POT模型更适用于车辆荷载极值预测分析的结论。
车辆荷载;极值理论;POT模型;次序统计量模型;对数正态分布
0 引言
随着我国经济建设的快速发展,超载超限运输车辆日益增多,对既有桥梁结构安全构成了严重威胁。无论是新桥的建设,还是旧桥的安全性评估,都不可避免涉及到一个核心问题——该结构在服役期间要承受的最大车辆荷载如何确定。现有大多数研究者在预测未来最大车辆荷载时,常常主观地采用几种常用的分布类型对实测荷载样本进行拟合,取基准期内的某极值分位数作为评估参考值。这种方法往往可以较好地描述数据的整体分布,通过相关检验准则,但难以描述数据的尾部,而分布的尾部才反映问题的核心[2]。对此,文献[8]随机产生1 000个标准样本,均能通过几种常用分布的检验,但这些分布尾部的下降速度相差甚远,若使用这些方法预测任意重现期内的运营车辆荷载,结果偏差较大。为此,应摒弃假设检验的路径依赖,采用极值理论进行预测分析。极值理论不需要对整体的概率分布形式作出假设,也不受整体分布的影响,只依赖尾部的数据分布,得出的结果更加客观,避免了假设检验方法构建模型的主观性。在极值理论的诸多模型中,POT模型(Peaks Over Threshold Model)和次序统计量模型均属于渐进模型,模型合理与否的判断仅依赖于样本数据,能较好地反映数据的尾部,但一些情况下也存在对尾部数据容量要求较高的问题。
本文选取粤赣高速某出口从2011年11月至2012年1月共计92 d、33 113组三、四和五型车的动态称重数据,采用POT模型、次序统计量模型和对数正态分布来对车辆荷载样本进行拟合,从而预测未来两年可能出现的最大车辆荷载,并与实测数据进行对比验证,以甄别模型预测的有效性和合理性。在得到底分布或截口分布后,基准期内的车辆荷载最大值 Mn分布的 p分位数等于底分布F (x)的p1/n分位数,即

对于分析基准期T,U(T)为荷载在T内的重现水平,即表示T时间内超过荷载U(T)的平均次数为1。

1 POT模型
假设X1,X2…Xn为独立同分布随机变量序列{Xi},并假设独立同分布随机变量序列{Xi}的任意分布函数为F(x),定义Fμ(y)为随机变量超过阈值μ的条件分布函数,则可表示为[1,2]:

则
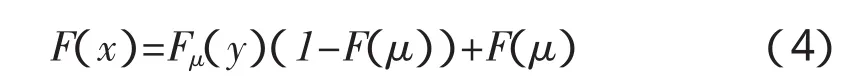
设X1,X2…Xn是来自同分布F(x)总体的样本且满足极值理论[5],当有足够大的 μ时,随机变量X的分布函数能满足:

则

阈值μ的确定可使用峰度法[5]进行选取,避免了图解法的主观性,得到正态分布和偏态分布的交点,即阀值。当通过峰度法确定μ以后,可以得到{Xi}中比阈值μ大的个数Nμ,用频率(1-Nμ/n)代替F(μ)的值,然后通过极大似然法进行参数估计可得估计值和,最终得截口分布为:

该模型的统计数据选用三、四和五型车车重,将车辆荷载数据通过matlab R2013a程序运算峰度法即可获得阈值μ为74.2 t。其中大于阀值的车辆荷载数目为657个,则Nμ/n为1.984%。
GPD(Generalized Pareto Distribution)分布是一种基于极值理论用于拟合极值样本中尾部数据的分布。当随机变量X足够大时,其高尾部分的条件分布可以用GPD分布来表示。对GPD分布的σ和ξ使用极大似然估计法得到和。其结果分别为=7.73 和=0.016 1。
计算得车辆荷载截口分布为:

对于POT模型,W0.95是车辆荷载截口分布的p=0.951/n的分位数,重现水平U(T)是车辆荷载截口分布的p=1-1/n的分位数,n取值分别为基准期3个月、6个月、1年和2年的实际三、四和五型车总车流量。使用实际车流量作为n的取值可以避免对车流量预测不准而导致分位数的确定误差较大。经计算后最终得到基准期内的重现水平U(T)和W0.95分位数结果(见表1)。

表1 应用POT模型估计的车辆总重最大值
2 次统计量模型
假设独立同分布随机变量序列{Xi},某时间段内按大小次序排列成,为第r大次序统计量。若存在常数列和,使得成立,则收敛于GEV分布(Generalized Extreme Value,简称GEV分布),若把总时间段划分为若干个相同的时间段,把在各时间段内的车重从大到小排列,取各时间段内的最大车重的前r个,则规范化次序统计量收敛于Hr(x),即[2,3]:

其中

最后得到其截口分布函数为:

GEV分布是一种基于极值理论用于拟合极值样本数据变化规律的分布。当随机变量X为区间最大值且随机变量X足够多时,X的概率分布可以用GEV分布来表示。将33 113组数据按每天进行分组,分别取每天最大车重的前10、30、50和70个数据(即r的取值)作为GEV分布的拟合样本。采用似然估计的方法去估计截口分布的参数,得到的参数估计见表2。
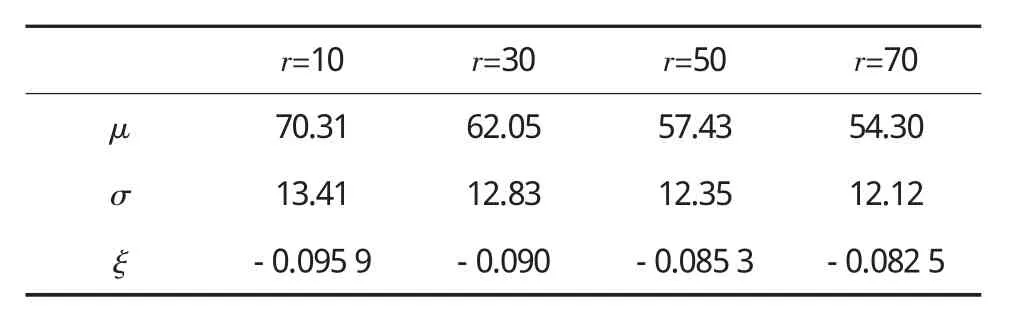
表2 参数估计结果
通过参数估计结果得到截口分布后,根据截口的分布函数对未来车辆荷载极值进行预测,对于次统计量模型W0.95是截口分布的p=0.951/n分位数,U(T)是车辆荷载截口分布的p=1-1/n的分位数,n取值为基准期的天数与r的乘积。计算结果见表3。

表3 r不同取值的车辆总重的重现水平与最大值
3 对数正态分布
在描述运营车辆荷载时,对数正态分布对车辆荷载整体样本数据拟合效果好,为大多数研究者所采用,其累加分布函数[12]:

对33 113组车重数据进行对数正态分布拟合,其参数估计结果为:μ=3.74 σ=0.28,对于对数正态分布W0.95和U(T)对应概率值p的算法及n的取值与POT模型相同。其预测结果见表4所示。

表4 车辆总重的重现水平和最大值
4 实测数据对比验证
根据上述预测分析结果,收集粤赣高速同出口的2012年2月1日至2014年1月30日的车辆荷载数据进行验证。从2012年2月1日开始的3个月、6个月、1年和2年内实测大于阀值74.2 t的三、四和五型车车辆数占其总车辆数的百分比依次为:2.1%、2.8%、3.2%和4.3%。表5为前述三种方法的车辆荷载最大值预测结果。对比结果表明:

表5 各车辆总重的重现水平与最大值及实测数据汇总
图1~图3为各方法对实测数据进行分布拟合的效果图。

图1 POT模型对实测数据进行各分布拟合的效果图

图2 r=10的次序统计量模型对实测数据进行各分布拟合的效果图

图3 对数正态分布对实测数据进行各分布拟合的效果图
(1)由表5可知,所有方法对基准期内的车辆荷载重现水平的预测值均比重现期内的实测最大值小,根据本节统计的数据显示:3个月、6个月、1年和2年内大于阀值74.2 t的三、四和五型车车量数占其总车辆数的百分比明显上升,特别是2年的时候其百分比比构建模型时的1.984%大1.17倍,而模型对未来车重的预测是建立在其百分比不变的基础上,这可能是导致极值分析方法和预测方法的预测值偏小的原因。尤其对于POT模型此百分比的上升会直接影响经验系数Nμ/n,导致其预测值偏小。以后对车辆荷载进行极值分析时应考虑这点。
(2)此外POT模型和对数正态分布的W0.95值均比重现期内的实测最大值大,说明若使用W0.95作为评估值会偏于安全。
(3)由表3可知,次序统计量模型选取最值样本具有局限性,车辆荷载的极值预测会因为分组和r的选取的不同而有较大差异。
(4)由图1可知,POT模型和对数正态分布的效果更好,次序统计量模型拟合效果最差,而对数正态分布是对整体分布的拟合,理论上他们应更满足对中间较大的样本拟合,通过它预测的最大车重应比POT模型的预测值误差更大。但从表5来看,对数正态分布的预测值也贴近2年内各实测值。但对数正态分布在理论上存在主观假设性过强的缺陷,受整体数据分布状况的影响较大,对分布尾部描述的稳定性不高。
5 结论
(1)相对于次序统计量模型、对数正态分布模型,POT模型在理论上更严密,结果也更可靠,是一个能更好描述车辆荷载极值分布规律的工具。当经验系数Nμ/n和总车流量增长规律变化不大时,可以准确预测任意重现期的车辆荷载变异状况。
(2)当基准期较短时,对数正态分布模型也可以较好地贴近真实值,但对数正态分布在理论上存在主观假设性过强的缺陷,受整体数据分布状况的影响较大,对分布尾部描述的稳定性不高。
[1]Castillo E,Hadi A S.Fitting the generalized pareto distribution to data[J].Journal of the American Statistical Association,1997,92 (440):1609-1620.
[2]韩大建.极值分析方法在车辆荷载评估中的应用与比较[J].建筑与科学工程学报,2011,28(2):11-13.
[3]周浩澜,陈洋波.基于GEV分布模型参数与历时关系的暴雨强度公式推求[J].四川大学学报,2012,44(1),37-41.
[4]Stuart Cloes.An introduction to statistical modeling of extreme values[M].Great Britain:Springer-Verlag London Limited,2001: 1-407.
[5]花拥军,张宗益.基于峰度法的POT模型对沪深股市极端风险的度量[J].系统工程理论与实践,2010,30(5):786-796.
[6]Sivakumar B,Ghosn M,Moses F.Protocols for collecting and using traffic data in bridge design[M].Washington:Transportation Research Board,2011.
[7]Nowak A S.WIM based lived load model for bridges[R].Florida: Published in Transportation Board,2011.
[8]韩大建.工程结构作用极值分析方法研究[J].建筑与科学工程学报,2008,25(2):69-71.
[9]边宽江,崔冰,金晓燕等.对数正态分布的VAR数学模型及其计算[J].数学的事件与认识,2011,41(1):1-6.
[10]Hosking J R M,Wallis J R.Parameter and quantile estimation for the generalized Pareto distribution[J].Technometrics,1987,29 (3):339-49.
[11]武隽,杨飞,韩万水.基于实测和CA模型的大跨桥梁车辆荷载模拟[J].铁道科学与工程学报,2014,11(4):14-18.
U441.2
A
1009-7716(2016)10-0140-04
10.16799/j.cnki.csdqyfh.2016.10.045
2016-06-28
国家自然科学基金资助项目(51278134);教育部博士点基金项目(20114410110003);广东省交通运输厅科技资助项目(201402022)
袁伟璋(1991-),男,广东中山人,硕士研究生,研究方向为桥梁评估荷载及可靠度。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
数学物理学报(2022年2期)2022-04-26
吉首大学学报(自然科学版)(2021年3期)2021-12-16
汉字汉语研究(2021年3期)2021-11-24
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化·高一版(2018年10期)2018-11-08
小天使·六年级语数英综合(2017年8期)2017-08-04
重庆交通大学学报(自然科学版)(2017年3期)2017-05-17
环球市场信息导报(2016年41期)2017-01-19
