
基于表分区和内存数据库的族谱生成系统优化
2017-03-02 08:20徐明民彭中华王黎维
计算机与数字工程 2017年2期
徐明民 彭中华 王黎维
(1.武汉大学计算机学院 武汉 430072)(2.武汉大学国际软件学院 武汉 430072)
基于表分区和内存数据库的族谱生成系统优化
徐明民1彭中华2王黎维2
(1.武汉大学计算机学院 武汉 430072)(2.武汉大学国际软件学院 武汉 430072)
论文为现有的族谱系统数据存储提出一种优化的存储方案——基于表分区的存储方案。分析现有的族谱系统在数据存储方案上的不足,参考PostgreSQL的表分区技术,使用表分区方案来对族谱人物及关系数据重新建模和存储,提高了对族谱数据的管理和操作效率;基于现有族谱生成系统在族谱生成过程中对数据处理的特点,引入内存数据库技术,采用内存数据库SQLite在数据处理过程中存储数据,提高了对数据的处理效率。实验部分测试了使用表分区和内存数据库技术的可行性和性能影响,实验结果表明,使用表分区方案和内存数据库技术方案可以支持族谱数据的存储和族谱生成过程中内存数据的处理需求,并且在一定程度上优化族谱生成系统的性能。
族谱; PostgreSQL; 表分区; 内存数据库; SQLite
Class Number TP311
1 引言
族谱又称为家谱、宗谱,是一种记录家族世代繁衍和重要人物事迹的图文体裁。族谱文献对于我们了解人文历史有很大的帮助,并且在政治经济学、地理学、群体遗传学等方面都有着潜在的研究价值[1]。传统的中式族谱通常以纸质、布质等形式的谱书为承载形式,各族、各家拥有自己独立的谱书。这些谱书在存在形式上相互独立,但是在内容上却有很强的相关性。传统的谱书式族谱在信息交互和共享方面存在着先天不足,且实体的谱书不便于后续的修改(续修)以及保存。因此,近年来族谱数字化受到了社会的广泛关注。数字化族谱系统除了能提供给用户录入族谱信息、利用族谱信息的功能之外,还需要兼顾中式族谱的特殊需求。家族在编修族谱时,通常都需要以采集好的族谱数据为基础,通过编辑、排版形成内容丰富、图文并茂、样式美观的谱书,然后将其印刷成册并分发给族人。目前,国内外在数字化族谱系统方面已有一些研究和开发工作。著名的族谱网站FamilySearch[2]中,用户可以方便地创建和管理个性化族谱空间,但没有提供族谱数据纸质化输出功能。文献[3~4]都实现了基于单机形式的族谱录入软件:将族谱的制作工作分割成多个任务,由多位制作人员分别完成这些任务并以文件存储任务中输入的族谱数据,最后将多个数据文件合并、编辑形成最终的族谱。但是这种数据管理方式不利于信息的共享,而且多个数据文件之间存在较多冗余以及冲突,无法自动完成数据文件合并。为了加快族谱数字化进程,结合实际的应用需求,本文实现了一个基于B/S架构的族谱信息系统[5~6]。该系统提供了族谱数据录入、查询服务以及族谱纸质化输出等功能,但随着录入族谱的人物数据量的急速增长,数据库表内的人物和人物关系条数会急速增长,在目前族谱系统人物数据和人物关系数据单表的存储方案下,查询服务效率会急剧下降,对族谱数据的管理很不方便且可维护性很差;在面对大数据量族谱的生成时,目前内存数据的存储方式对数据的操作效率影响很大,同时也易造成系统的不稳定,导致系统长时间无响应甚至“假死”。结合族谱信息系统中的实际需求,本文对该系统的族谱数据存储方案进行了改进,采用表分区技术,提升了对族谱数据的操作和管理效率,同时在族谱的生成过程中,采用内存数据库SQLite,提高了对族谱数据操作的效率,从而提升族谱生成系统的效率和稳定性。
2 相关工作
传统族谱信息系统采用的是单机管理不易于扩展功能,其中的数据分散且有大量冗余,而且传统族谱信息系统面向的是族谱制作用户,无法利用其中的族谱数据向公众用户提供服务。为了更好地收集和利用族谱数据,本文设计并开发了一款族谱信息系统,整个系统如图1所示[5]。族谱信息系统分为族谱信息录入系统、族谱生成系统以及姓氏网站展示系统三个子系统,族谱系统的主要功能包括数据录入、数据服务和数据输出。族谱信息录入系统是基于B/S架构的,该系统可以支持多用户并行地录入同一族谱中的数据,并统一对族谱数据进行管理,同时通过本系统还可向公众用户提供对已录入族谱数据的检索。族谱信息录入系统提供数据录入的功能,录入功能主要包括三部分:世系数据录入、文档数据录入、多媒体数据录入。姓氏网站展示系统提供数据服务的功能,主要包括数据展示、统计检索、一键寻祖和一键寻亲。族谱生成系统则为用户提供数据输出的功能,主要包括族谱编排和族谱生成。族谱编排功能是通过用户的个性化需求对谱书的样式、数据出现的顺序、词语的表达方式等进行设置;而族谱生成功能主要是在族谱编排过后,按照用户的个性化需求从原始族谱数据中转换生成电子版的谱书以供印刷。
族谱生成系统是整个族谱系统的关键所在,生成系统生成族谱的大体流程如图2所示,主要涉及到数据获取、数据处理、数据填充和生成族谱四个阶段。数据获取是指从族谱数据库中取出对应要生成的族谱所有数据信息的过程,数据信息主要包括族谱全局数据、人物数据和人物关系数据;数据处理即是对取出的族谱数据进行规范化以及按照用户的设置进行再处理转化的过程;数据填充即是用经过处理加工后的数据与用户选择的版式进行结合,填充对应的版式;生成族谱环节包括先将处理后的数据信息和HTML格式的族谱模板组合生成一页页HTML格式的族谱,在此过程中同时还包括生成人物的页码信息,对应更新族谱数据库人物信息表的人物页码字段,然后替换HTML格式族谱中对应的人物页码字段等。最终由HTML格式的族谱生成PDF格式的族谱。
在多次生成族谱的过程中发现,在数据获取阶段,获取的数据信息中主要包括人物信息和人物关系信息,分别对应存储在数据库的人物表和人物关系表中,并且每次都只会获取与该族谱有关的所有数据。在数据获取的过程中,人物表和人物关系表的信息都是基于选择的族谱ID(Gid)来进行过滤,从而取出所有关联的人物数据和人物关系数据。随着族谱系统录入的族谱数量越来越多,人物表和人物关系表的数据条目也急剧增加,而每次需要获取的数据相对于整张表而言,相对很少;以单表的形式来存储,不仅影响操作的效率,而且不方便进行管理。在数据处理和数据填充以及族谱生成阶段,由于存取到的表数据需要常驻内存,在此基础上还需要对数据进行查询和运算,目前的系统采用DataSet的存储方式,以DataTable来存储表数据的信息,当需要计算的人物数据和关系数据量较大时,极易造成系统无响应或者程序中断的不稳定情形出现。
综上所述,原来的数据存储方案有如下缺陷:随着录入的数据越来越多,人物表和人物关系表的数据条目会急剧增长,单表存储的数据管理方式显然是不合适的;尽管在原来关系表的对应字段上建有索引,在数据量增大后索引的性能也会极大下降;随着族谱系统的推广使用,生成系统对族谱数据的并行操作是很常见的情形,目前单表的存储方式很影响系统的性能。在数据处理和数据填充阶段,以Dataset方式来存储数据,处理的过程中效率较低;在族谱生成阶段还涉及对族谱数据库中人物页码字段的更新,此时网络状况很可能成为瓶颈因素;在内存中处理大量数据时,由于没有一些对应的数据保护机制,很难保证数据的完整性和系统的稳定性。
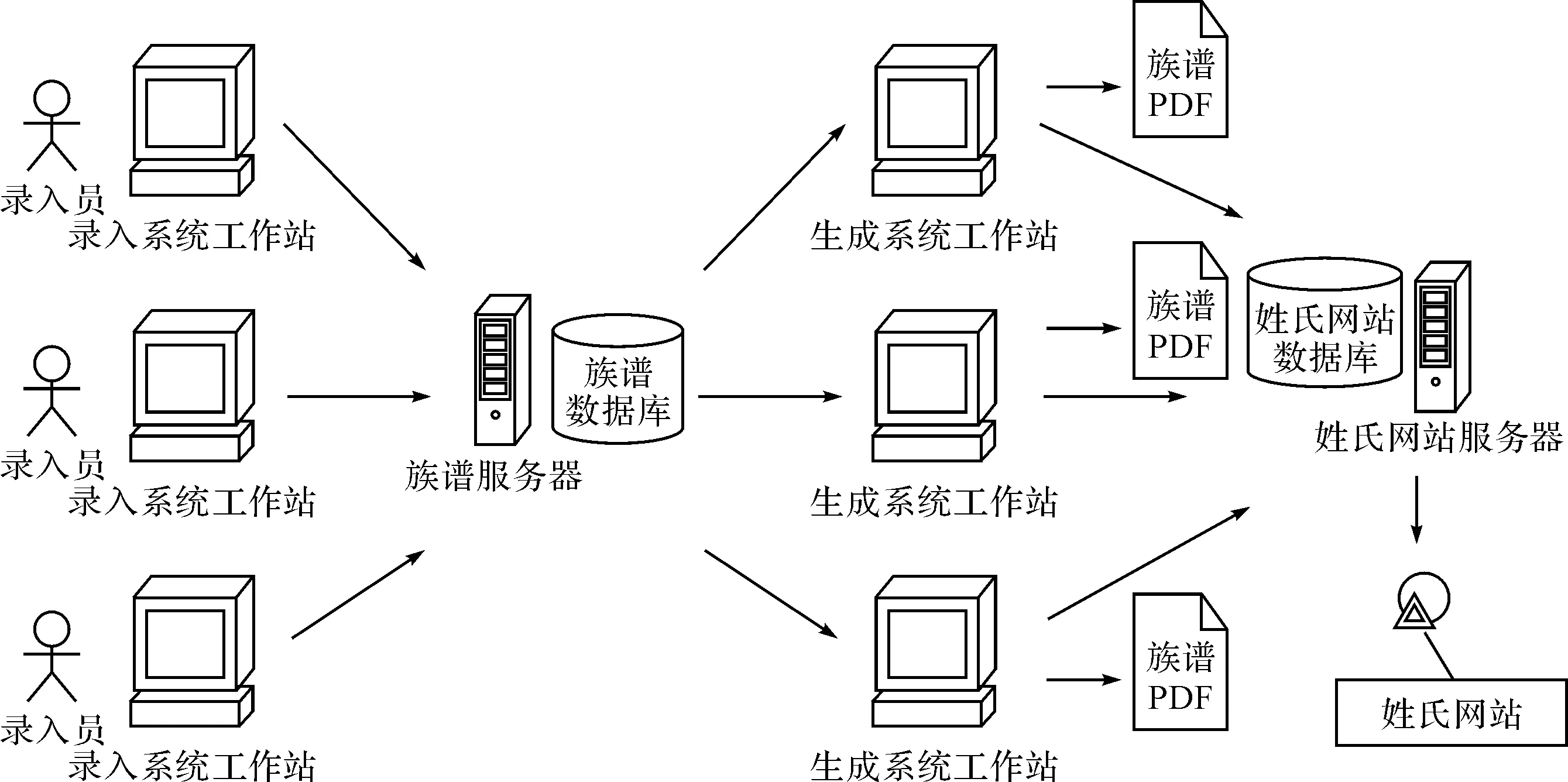
图1 族谱系统介绍

图2 族谱生成子系统流程示意图
3 表分区和内存数据库技术优化方案
根据上述分析,本文提出存储优化方案——表分区方案以及内存数据库技术方案。总体来看,使用表分区技术优化存储有以下优势:分区后,获取族谱数据的查询性能可以得到一定提升;通过将不同分区存储在不同的磁盘,使多用户并行获取不同分区的族谱数据时,可以有效地分散I/O;分区后,可以将全局索引替换为分区索引,分区表的数据量远远小于原来的表,索引能更有效地发挥性能;同时对族谱数据的管理也更有效地进行,批量删除族谱数据可以通过简单的删除某个分区来实现。使用内存数据库技术对于族谱生成有以下优势:利用内存数据库SQLite替换原来的DataSet的存储形式,可以有效地提高数据处理的效率;使用内存数据库来存储族谱的数据信息后,在族谱完全生成完成之前,生成系统只需和本地的SQLite进行交互,不再需要和远程族谱数据库通信,因此有效地减小了网络因素的影响;内存数据库利用数据库的事务管理等机制可以保证族谱数据的完整性和安全性,从而有效地提高生成系统的稳定性。
3.1 表分区方案
数据库分区是一种物理数据库设计技术,分区就是把逻辑上的一个大表分割成物理上的几个块。虽然分区技术可以实现很多效果,但其主要目的是为了在特定的SQL操作中减少数据读写的总量以缩减查询时间。分区主要有两种形式:水平分区和垂直分区。水平分区是对表的行记录进行分区,通过这样的方式不同分组里的物理列分割的数据集得以组合,从而进行个体分割(单分区)或集体分割(一个或多个分区);垂直分区一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行,所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。分区不仅能带来访问速度的提升,关键的是还它能带来管理和维护上的方便。PostgreSQL数据库支持基本的表分区功能,在PostgreSQL中表分区是通过表的继承来实现的,目前PostgreSQL的表分区方案有:范围分区和列表分区。范围分区是指表被一个或者多个键字字段分区成“范围”,在这些范围之间没有重叠的数值分布到不同的分区里。列表分区则是指表是通过明确地列出每个分区里应该出现那些键字值实现的。
目前的族谱数据库中的数据表主要有族谱表、人物表以及人物关系表。族谱表主要包含每个族谱的描述信息,人物表记录了录入系统录入的所有人物描述信息,人物关系表记录了人物表中所有的人物之间的关系信息。随着人物数据信息不断地录入,人物表和关系表的记录条数会急剧增长;并且随着族谱系统的进一步推广和使用,极易出现对族谱数据库数据的并行操作,引成的I/O集中会引起系统的性能变慢。
因此考虑采用表分区方案对族谱系统数据库中关键的数据表——人物表和人物关系表,进行分区处理。利用PostgreSQL数据库的分区技术并参考族谱系统对数据存储和操作的方式,利用族谱ID(Gid)对人物表和人物关系表进行范围分区。以人物表为例,首先创建对应范围的分区表,设定一定的ID范围对分区进行控制,然后创建触发器函数,这样数据导入时则会按照设定的分区范围,相对均匀地分布在多个分区。在族谱生成过程中需要获取对应族谱的所有数据时,则不再需要在一张千万级的数据表中进行检索,而是按照规则去对应的分区中进行检索,提高了查询效率;同时原来数据表的索引可以分散到各个分区,由于每个分区的记录数远远小于原来的表,分区上的索引可以更好地实现加快查询的效果;随着族谱数据的录入和族谱的生成完成,需要对某个族谱段的族谱数据进行删除时,可以通过简单地删除某一个或者几个分区来进行,方便了对族谱数据的管理;并且可以考虑将多个分区分别放置在不同的物理磁盘上,这样在处理对族谱数据的并行操作时,I/O可以被有效地分散,提高了生成系统的响应时间和系统的稳定性。
3.2 内存数据库技术
内存数据库抛弃了传统的磁盘数据管理方式,基于全部数据都在内存中重新设计体系结构,并且在数据缓存、快速算法、并行操作方面都进行了相应的改进,所以数据处理速度比传统数据库的数据处理方式要快很多。内存数据库和传统数据库的区别在于传统的数据库系统是关系型数据库,开发这种数据库的目的是处理永久、稳定的数据;关系数据库强调维护数据的完整性、一致性,但很难顾及有关数据及其处理的实时要求。对内存数据库而言,将整个数据库或其主要的“工作”部分放入内存,使每个事务在执行过程中没有I/O,则为系统较准确估算和安排事务的运行时间,使之具有较好的实时处理能力。常见的内存数据库有:SQLite、FastDB、Memcached和Redis等,结合在族谱生成过程中对数据处理的特点,最终选用了SQLite数据库,因为SQLite作为一款开源的内存数据库软件,相比其他内存数据库,不受许可证费用约束,在便携性、 易用性、 紧凑性、 高效性和可靠性方面都有突出的表现,更加轻量级,同时不仅支持对数据的查询,也支持对数据的更新等操作,很好地满足了族谱生成过程中对数据处理的需求。
在族谱系统中,如图2中所示,将该族谱的数据从服务器数据库获取到本机后,需要经过数据处理、数据填充以及族谱生成这几个阶段后才能完成族谱PDF的最终生成。在这几个处理阶段中,族谱数据尤其是人物数据和人物关系表数据都会以DataTable的形式常驻在内存中,当该族谱涉及到的人物数据和人物关系数据较大时,内存中的数据集也会很大,并且在此过程中涉及到对该数据集的查询和更新操作,采用DataTable的形式进行存储,处理效率较低,同时很难保证系统的稳定性。因此考虑采用内存数据库技术对该内存数据集进行优化存储。基于族谱生成系统的数据操作特点,采用SQLite来存储生成过程中需要处理的内存数据集。
图3所示为使用内存数据库SQLite后生成系统进行数据处理的过程。需要计算的内存数据集会存储在SQLite中,从而程序只需与本地的SQLite交互,生成族谱PDF中的人物页码信息也直接存储在SQLite中,而不需要与远程的族谱服务器进行通信。图4所示为生成系统程序中具体对SQLite调用的过程。首先需要打开和连接本地的SQLite数据库,将从族谱服务器获取到的数据写入到SQLite中进行初始化。在后续的数据处理、数据填充以及族谱生成阶段,需要做查询和操作时,都直接通过SQL语句与SQLite进行交互,获取到相应的数据集后进行操作;在数据操作的过程中,也会涉及对数据库的清理,同时会涉及到对族谱数据进行备份等处理操作,最后在族谱生成工作完成后,关闭SQLite数据库。利用SQLite的优化存储,在提高了生成系统效率的同时,更好地保证了内存数据集的完整性和安全性,有效地提高了生成系统的稳定性。
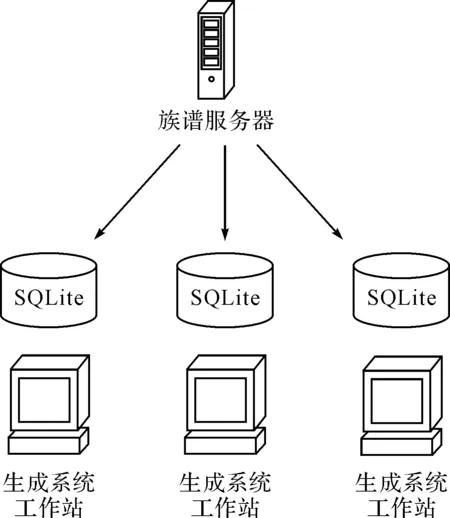
图3 使用SQLite的族谱生成系统
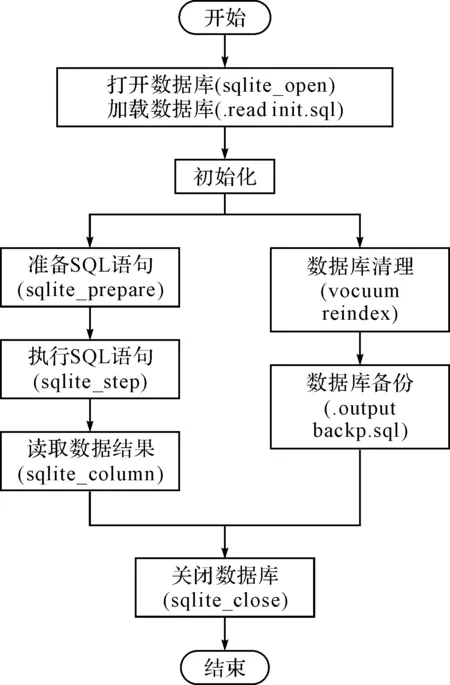
图4 调用数据库SQLite的主要流程
4 实验
实验部分别对文中提出的基于表分区和使用内存数据库SQLite的方案进行功能测试和性能测试,并对测试结果进行分析和总结。
4.1 实验环境与测试数据
测试选用的系统环境是一台处理器为Intel Core i3-M3702.40GHz,2.0G内存的PC机,操作系统选用Windows7的32位版本。测试使用未使用表分区方案和内存数据库SQLite的族谱生成系统和最新版本的族谱生成系统。
测试数据集选取如下:数据集分别为DS1~DS5五个族谱,族谱的ID以及族谱的人物节点数和族谱的人物关系记录依次如表1中所示。
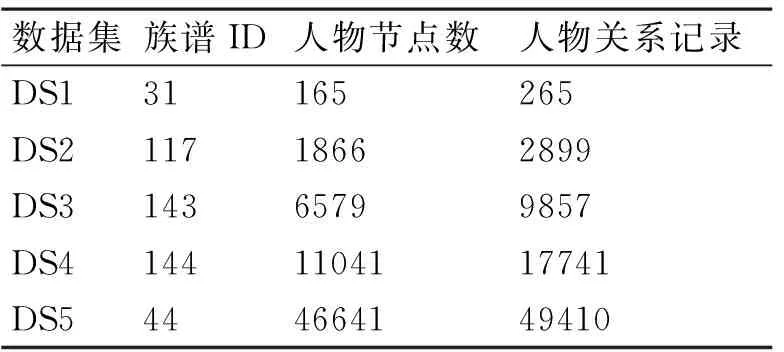
表1 测试数据集
4.2 实验结果与分析
1) 功能测试
功能测试主要测试基于表分区的方案能否满足系统对族谱数据库数据的操作,其中包括族谱数据的存储、查询、插入和删除;以及测试基于内存数据库技术的存储方案能否满足族谱成功生成的功能。
针对以上需要测试的功能,以人物表t_individual为例,设计几个测试用例如下:
(1)SELECTgid,fullname From t_individual ;
(2)INSERT INTO t_individual( gid, fullname ) VALUES (1 ,’张三’);
(3)UPDATE t_individual SET fullname = ’李四’ WHERE gid=1 AND fullname = ’张三’;
(4)DELETE FROM t_individual WHERE gid =1 AND fullname = ’李四’;
上述几个测试用例涉及到了人物表分区后的查询、插入、更新以及删除操作。测试用例的运行正确表明了表分区方案用于族谱系统数据库的可行性;分别使用原来的系统和使用SQLite后的生成系统,生成相同的族谱PDF进行对比,发现内容一致,也证明了内存数据库SQLite用于族谱系统的可行性。
2) 性能测试
图5所示为表分区方案前后对人物信息表进行查询时,数据集里对应族谱数据检索所消耗的时间对比。实验结果表明:进行表分区后,对数据的检索效率得到一定提升。并且在数据库整体的数据集越大时,表分区的优势会更明显。图6所示为使用内存数据库SQLite前后,对应不同大小的族谱数据集,利用生成系统生成族谱时消耗的时间对比。
综上,对于族谱数据查询和族谱生成的性能测试,充分说明了使用表分区方案可以在一定程度上优化族谱数据的查询性能,并且方便了对族谱数据的管理;通过使用内存数据库技术,有效地提升了生成系统的效率。
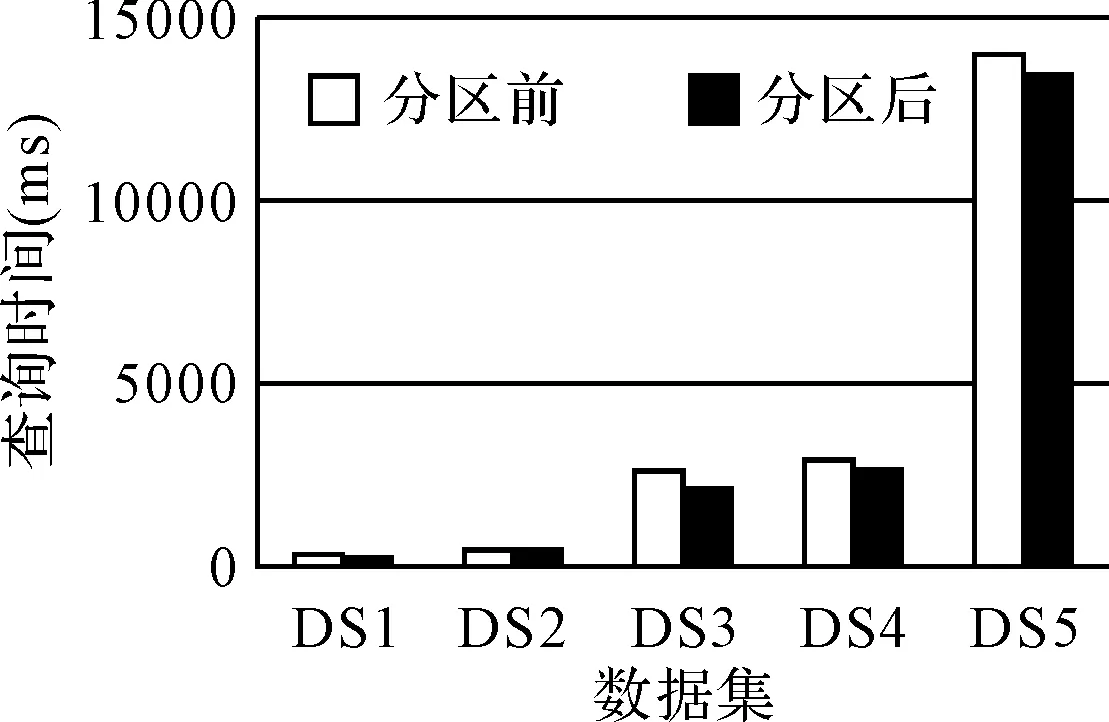
图5 表分区前后查询效率对比
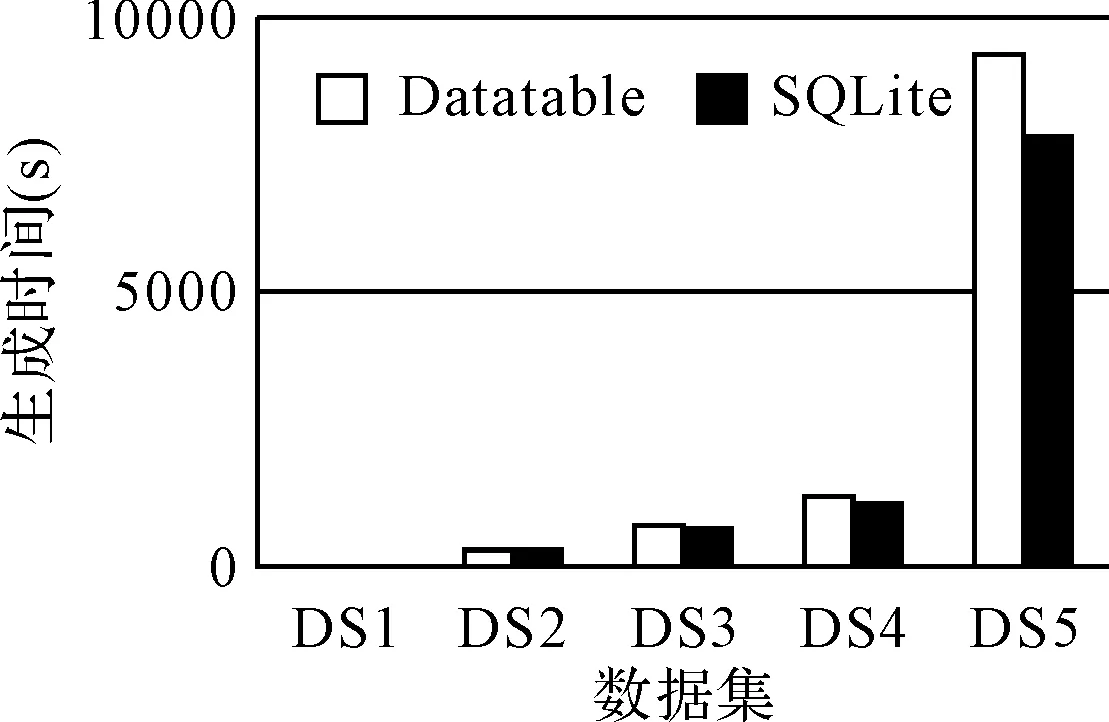
图6 使用内存数据库SQLite前后的效率对比
5 结语
在目前的族谱生成系统中,在族谱数据库里人物数据和人物关系数据分别利用一张关系表来存储,随着族谱数据在录入系统的不断录入,人物表和人物关系表的记录条数会急剧增长,对族谱信息的获取相对耗时,且存在多用户并发操作族谱数据库数据的情形,因此对人物表和关系表采用表分区机制,提高数据的获取效率,同时增加了对族谱数据管理的方便性和可维护性;从数据库取出数据后,在族谱生成阶段对族谱数据需要进行不同的操作,但数据都需常驻内存,并且生成系统还需要和族谱数据库进行交互,当族谱的数据量很大时,易造成程序的不稳定;在和数据库交互时,网络状况对系统的影响很大,因此采用内存数据库SQLite来存储对应数据。
采用表分区方案及内存数据库技术方案:参考族谱系统应用场景的具体情况,考虑对人物表和人物关系表进行表分区,可以将不同的分区存储到不同的磁盘,在分区的基础上再建立索引,在提升对数据获取效率的同时也方便了对族谱数据的管理;在将族谱数据取出后在内存中对其进行处理时,采用内存数据库SQLite对其进行存储,不仅减小了族谱生成过程中的网络因素影响,同时有效地提升了生成系统的性能和稳定性。
[1] 张卓.开发利用族谱档案的意义[J].云南档案,2006(3):32-33. ZHANG Zhuo. Meaningof develop and exploit pedigree archives[J]. YunnanArchives,2006(3):32-33.
[2] FamilySeareh[EB/OL]. http://www.familysearch.org.
[3] 启航宗谱[EB/OL]. http://www.qhzprj.com.
[4] 中根网[EB/OL]. http://www.zongen.com.
[5] 张文杰,彭智勇,彭煜炜.内存数据管理技术在族谱信息系统中的应用[J].华东师范大学学报:自然科学版,2014(5):311-319. ZHANG Wenjie, PENG Zhiyong, PENG Yuwei. Application ofin-memory data management technologyin genealogy information system[J]. Journal of East China Normal University:Nature Science Edition, 2014(5):311-319.
[6] 姜洋,彭智勇,彭煜炜.基于图数据库的在线族谱编录系统[J].计算机应用,2015,35(1):125-130. JIANG Yang, PENG Zhiyong, PENG Yuwei. Online pedigree editing system based on graph database[J]. Journal of Computer Applications,2015,35(1):125-130.
[7] 彭智勇,彭煜玮.PostgreSQL数据库内核分析[M].北京:机械工业出版社,2012. PENG Zhiyong, PENG Yuwei. PostgreSQL Database Kernel Analysis[M]. Beijing: China Machine Press,2012.
[8] PL/pgSQL[EB/OL]. http//www.Postgresql.org/docs/8.3/static/plpgsql.Html
[9] G Eadon,EI Chong,S Shankar et al.Supporting table partitioning by reference in oracle[C]//Acm Sigmod International Conference on Managementof Data,2008:1111-1122.
[10] 李亚龙,朱岩.表分区在分界开关监控系统数据库的应用[J].计算机系统应用,2016(2):235-238. LI Yalong, ZHU Yan. Application of Table Partition in Boundary Load Switch Monitoring System Database[J]. Computer Systems & Applications,2016(2):235-238.
[11] 刘玉红,罗晓沛.表分区技术在短信增值业务中的研究与实现[J].计算机系统应用,2008,17(11):72-75. LIU Yuhong, LUO Xiaopei. Study and Application of Partitioned Tables in SMS Business[J]. Computer Systems & Applications,2008,17(11):72-75.
[12] J Lv,S Xu,Y Li. Application Reasearch of Embedded Database SQLite[J].International Forum on Information Technology & Application,2009,2:539-543.
[13] 万玛宁,关永,韩相军.嵌入式数据库典型技术SQLite和Berkeley DB的研究[J].微计算机信息,2006,22(2):91-93. WAN Maning, GUAN Yong, HAN Xiangjun. Research on Typical Technologies of embedded database-SQLite and Berkeley DB[J]. Microcomputer Information,2006,22(2):91-93.
[14] 王珊,肖艳芹,刘大为,等.内存数据库关键技术研究[J].计算机应用,2007,27(10):2353-2357. WANG Shan, XIAO Yanqin, LIU Dawei, et al. Research of main memory database[J]. Journal of Computer Applications,2007,27(10):2353-2357.
[15] 邵璐,费洪晓.内存数据库技术在移动实时累加系统中的应用[J].计算机系统应用,2011,20(8):169-173. SHAO Lu, FEI Hongxiao.Application of MDB Technology to Mobile Real-Time Accumulative System[J]. Journal of Computer Applications,2011,20(8):169-173.
Genealogy Generation System Optimization Based on Table Partition andMain Memory Database
XU Mingmin1PENG Zhonghua2WANG Liwei2
(1. Computer School, Wuhan University, Wuhan 430072) (2. International School of Software,Wuhan University, Wuhan 430072)
This paper proposes an optimal storage solution for the genealogy data storage system — storage solution based on the table partition. The shortage of existing data storage solution on the genealogy system is analyzed, the genealogy data is re-modeled and storaged with the help of the PostgreSQL table partition. This method improves the management and operational efficiencyof genealogy data, based on the characteristics of data processing in the existing system , inmain memory database technology is brought. Thus, using SQLite database to store data in memory can improve the efficiency ofdata processing. Experiments test the feasibility and properties of table partition and main memory database technology.It turns out that the use of table partition scheme and main memory database technology can support the storage and processing requirements and partly optimize the performance of genealogy system.
genealogy, PostgreSQL, table partition, main memory database, SQLite
2016年8月15日,
2016年9月29日
徐明民,男,硕士研究生,研究方向:数据库原理、数据管理。彭中华,男,硕士研究生,研究方向:软件工程。王黎维,女,博士,副教授,研究方向:数据质量、数据溯源、科学工作流。
TP311
10.3969/j.issn.1672-9722.2017.02.015
猜你喜欢
大众科学(2022年5期)2022-05-18
文萃报·周二版(2022年18期)2022-05-11
环球时报(2022-03-29)2022-03-29
福建茶叶(2020年2期)2020-12-22
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国新通信(2016年11期)2016-08-09
海峡旅游(2016年5期)2016-06-01
人间(2015年11期)2016-01-09
电脑爱好者(2015年21期)2015-09-10
