
我国区域经济发展水平的聚类分析
2018-02-28 17:57刘干,陆叶
生产力研究 2018年1期
刘 干,陆 叶
(杭州电子科技大学 经济学院,浙江 杭州 310018)
近年来,我国经济快速发展,人们生活水平日益提高,与此同时,由于受各地区区位优势及资源禀赋等多方面因素的影响,区域经济差距也被进一步拉大,如何促进区域经济协调发展日益受到相关各方的重视。解决区域发展不平衡问题的前提是对区域按经济条件的差异进行合理的划分。相关的研究文献很多,但综合来看,一方面,大多数研究主要从截面维度展开,这样其聚类结果的随机成分较多,因而可信度无法得到保证;另一方面,在聚类指标的选取上,多数学者只考虑了经济和社会层面的表现,而忽视了环境因素,这显然是不合适的。因此,本文首先从经济、社会及环境三方面筛选了若干指标,对地区经济进行更加全面的刻画,再运用面板数据聚类的方法对地区经济进行合理划分,并结合实际情况对聚类结果做出评价。
一、评价指标体系及数据说明
通常情况下,人们评价经济状况好坏,主要从经济规模及增速两个维度进行,随着人们认识的提升,开始逐渐意识到,一个地区经济的好坏不仅仅反映在其经济层面,还应考虑社会及生态,本文在综合考虑这三个方面因素并结合前人研究成果的前提下,构建了一套经济发展水平的评价指标体系(见表 1)。
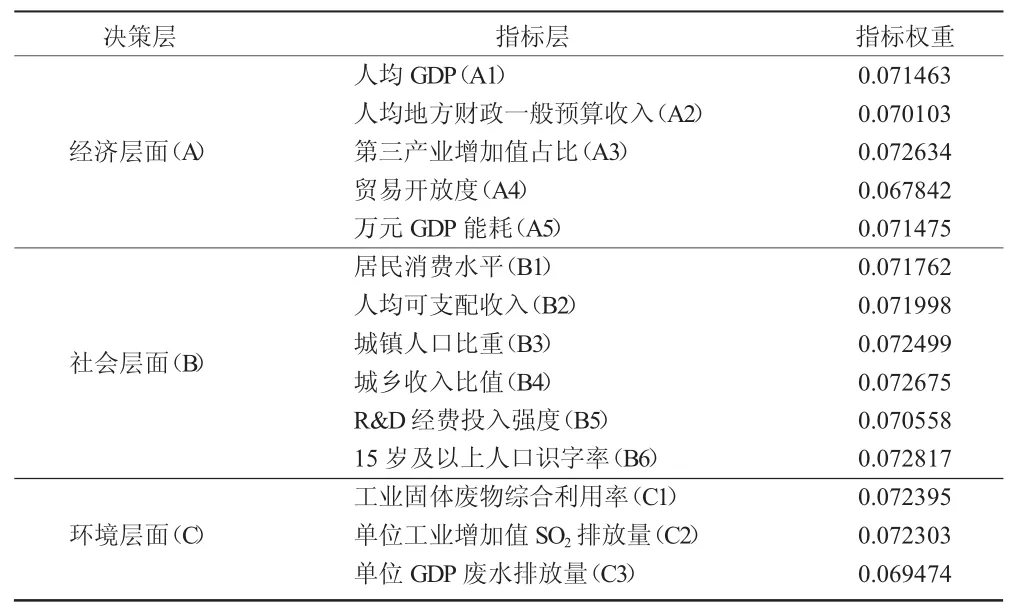
表1 经济发展水平评价指标体系
从经济层面来看,一地区经济水平的高低主要反映在其经济规模、经济结构、对外开放程度及经济效率等方面,因此本文分别从这四个角度选取了5个指标来衡量;从社会层面来看,社会的“文明”程度可以通过居民生活水平、社会结构、科技及教育等方面来体现;环境层面,本文选择了各地区在“三废”的处理及排放方面的三个指标来刻画。
本文的数据选自我国31个省市2005—2015年的14个经济指标数据。为了使分析结果更合理,本文在指标计算中涉及价格因素的均以固定基期(2005)的实际值带入。特别地,贸易开放程度指标计算中涉及的进出口总额按美元计价,因而在指标计算时以对应年份的平均汇率进行加权。另外,部分指标存在的缺失值,如15岁以上人口识字率2010年的指标值可直接采用线性插值法计算得到;而西藏的万元GDP能耗指标缺失较多,不宜进行插补,因此,本文的聚类过程只包含其余的30个省市数据,再依据其余10个指标数据将西藏判入距其最近的类别。本文所有的指标数据或计算数据均来源于《中国统计年鉴》、《中国能源统计年鉴》、《中国科技年鉴》、《国民经济和社会发展统计公报》及各地区年鉴。
二、研究方法
在聚类分析之前,需要明确三件事,即聚类分析方法、最佳聚类数的确定方法和类的优劣判别方法。关于这三者的研究文献有很多,本文选用目前最流行的K-means聚类法进行聚类,选用CH法作为最佳聚类数的确定方法,然后以类平均综合因子得分作为类优劣排序标准,下面分别对这三种方法进行简要介绍。
(一)面板数据的K-means聚类法
K-means聚类法又称快速聚类法和动态聚类法[1]。其实现过程非常简便,只需设定一个初始聚类数,然后以随机法产生K个数据点作为初始聚类中心,并依次将其余样本点划分到距其最近的聚类中心,计算每一类的指标均值作为下一次迭代的聚类中心,直到聚类中心不再发生变化或相邻两次聚类中心之间的距离小于给定的阈值时迭代停止。本文采用欧式距离作为类间相似性的度量标准,其公式如下:

其中,xi表示第i个样本点矩阵,其维度为Q×T(Q表示聚类指标个数,本文表示主因子个数;T表示聚类周期的长度),vj表示第j个聚类中心矩阵,其维度与xi相同。||A||F表示矩阵A的Frobenius范数,即矩阵A内部所有元素平方和的平方根。
需要注意的是,K-means聚类法主要适用于超球形的类,因而当样本数据分布不满足该条件时,不宜直接进行K-means聚类;聚类分析中的距离函数一般都要求各指标维度相互独立,因此本文在聚类之前对数据进行因子分析,并以主因子数据作为聚类基础数据。
另外,由于K-means聚类的初始聚类中心通过随机种子产生,这样聚类结果便具有一定的随机性,为了使每次的聚类结果尽可能接近最优,可以将每一聚类数下的K-means聚类重复进行若干次取最优。对于聚类数相同的若干聚类结果,组内误差越小越好,因此,只需取组内误差平方和达到最小的聚类结果作为该分类数下的最优聚类即可。
(二)最佳聚类数的确定方法
如果在聚类之前已经掌握样本的实际分类数,那么最佳聚类数即为实际分类数,但是通常情况下,聚类之前并无法确定研究对象的类别个数,因而,需根据样本数据的分布,确定最优的聚类个数。关于最佳聚类数的确定方法主要分为图示法和指标法,图示法主要包括谱系图法、聚合系数法和离差平方和法,通常取指标数值发生突变的节点对应的分类数作为最优聚类数;指标法即聚类有效性指标法,主要包括CH法、DB法、Sil法等,具体可参考文献[2-4]。不同指标得出的最佳聚类数之间往往差别较大,但是,据[2][4]研究表明CH法的稳定性最好,因此,本文主要采用CH法作为最佳聚类数判别法。CH指标的公式主要有两种形式,通常采用第一种形式,如式(2)。

其中,N表示总样本点个数;K表示聚类数,理论上,CH指标的K值可取2到N-1范围内任意整数,但是通常情况下,聚类数范围可根据对事物的认识确定或选择研究者感兴趣的区间,但一般不宜过大;xki表示第k类的第i个样本点;|Ck|表示第k类的样本点个数;v¯表示所有样本点的均值矩阵。CH指标的另一种形式为[5]:

从CH和VRC的公式可以看出,两者都是基于F统计量构造的指标,即分子和分母分别表示组间和组内的均方误差。该方法的思想是,当聚类数小于最佳聚类数K*时,组内误差包含组间误差成分,组内均方偏大;当聚类数大于K*时,组间误差包含组内随机误差成分,组间均方偏小;只有当聚类数等于K*时,组间均方与组内均方的比值达到最大。因此,这两个指标对于呈球状分布且存在明显聚类轮廓的聚类对象,指标最大值对应的聚类数即为最佳聚类数,当聚类指标的分布近似呈球状且各类之间只存在少数样品界限模糊时,指标也能较好的找到最佳聚类数点。
(三)类的优劣判别法
通常情况下,人们聚类的目的往往是对事物做出评价。对于聚类结果的评价通常是根据人们的期望来进行的,即对于同一聚类结果中的两类,我们认为离我们期望更近的类更优。例如,对于按经济发展水平聚得的不同地区的分类,我们认为经济发展水平高的类更优。其实,聚类结果评价问题归根结底还是对聚类对象的综合评价。常用的综合评价方法是对评价指标进行简单加权平均,再依据加权平均值的大小对事物作出评价。关于评价指标权重的确定方法可参考文献[6]。本文在聚类之前为了解决指标相关的问题对数据进行了因子分析,因此,对聚类结果的综合评价可依据类平均因子综合得分给出,第k类平均因子综合得分的计算公式为:

其中,λ表示方差贡献率列向量,e表示T维全1列向量。只需将zk进行排序,zk越大对应的类越优。
三、实证分析
(一)最佳聚类数的确定
依据式(2)、(3),对我国区域经济发展水平进行K-means聚类,得出聚类数在2~8区间内CH指标的值如表2所示。

表2 不同聚类数条件下的CH统计值
由表2可得,在聚类数为2~5的区间内,CH值不断增大,在聚类数为5处达到最大值,之后开始逐渐小幅下降。这说明我国区域经济发展水平存在5个比较明显的等级,由于聚类样本量较小,类内样本间较为分散,导致最值点后的CH指标降幅缓慢。其实,如果CH指标在K*之前快速上升,当达到K*之后的一小段数值趋于平稳,甚至出现小幅上升,根据奥卡姆剃刀原理仍可以将最佳聚类数设为K*。因此,根据CH指标法得出将我国区域经济发展水平划分为5类最为合理。
(二)我国区域经济发展水平的K-means聚类分析
对我国区域经济发展水平进行分类数为5的K-means聚类,并运用式(4)计算出各类平均因子综合得分。考虑到西藏的万元GDP能耗数据完全缺失,因此,聚类分析过程只对其余30个省市进行,为了分析的完整性,还需对西藏的归类作出判别。本文选用以熵值法进行指标加权的最近邻判别法将西藏判入距其最近的聚类中心。所有分析结果列于表3。

表3 我国区域经济发展水平聚类分析、判别分析及各类平均因子综合得分
从表3中各类元素的分布来看,全国只有北京和上海两个地区被划分到经济水平高的类中,有超过75%的省市经济发展水平落入了中等及中等以下的类。从表中第二行类平均因子综合得分数据来看,只有两类的综合得分值为正,且北京和上海的平均因子得分值远远领先于其余四类,第三类的综合得分值接近于0,说明其经济发展水平处在全国平均水平;从综合得分差值来看,经济发展水平最高的两类的差值达到了0.86,而经济发展水平较低的三类的综合得分差值分别为0.19和0.28,说明第一、二类的经济发展水平平均差距最为明显,第三、四类的平均经济发展水平最为接近。结合一二两列数据来看,我国区域经济发展水平呈现出了明显的右偏分布,区域经济发展不平衡问题仍非常突出。从表的第三列可以得出,西藏距经济发展水平低的类最近,因此,将其判入该类别。为了更直观的看出聚类的情况,运用ArcGIS10.5作出聚类结果分布图如图1所示。

图1 我国区域经济发展水平分布图
从图中可以明显看出,我国区域经济发展水平总体呈现“东高西低”的阶梯状分布趋势。从局部来看,东、中部地带除山西外经济发展水平均位于全国平均水平及以上,其中,以东部沿海城市的经济表现最为突出,西部地区仍然是我国经济建设的薄弱环节,尤其是西南地区,更是全国经济贫困人口的集中分布区域。该现象不仅印证了对外开放对于地区经济发展具有极大地促进作用,也反映出我国经济辐射作用主要由沿海城市向内陆延伸。从西部地区的空间分布来看,青海和四川不仅处于地理中心位置,也是西部贫困区的核心区域;重庆、陕西和山西为中、西部衔接的重要地段。但从第一财经最新公布的城市等级划分结果来看,只有四川、重庆和陕西三省的省会城市经济发展水平相对较高,具备经济辐射点的经济条件。当前国家已将成都和重庆纳入国家中心城市战略规划,而从长远来看,青海、陕西和山西省对于西部地区的发展同样具有不可忽视的作用,相比而言,这三省中青海的经济建设较为落后,但对于西部来说其地理位置是最重要的,如果能发挥出其经济辐射作用,对于整个西部经济的发展都具有巨大的作用。因此,当前阶段国家在开展经济扶贫工作的同时,还应帮助这些关键省市找准经济增长点,培育一批新的经济中心城市。
四、结论
本文首先从经济、社会和环境三个角度重新构建了一套区域经济发展水平评价指标体系,并在此基础上运用CH指标法得出将我国经济区域划分为5类最为合适。然后运用K-means聚类法及类平均因子综合得分法得出最优分类结果及各类经济发展水平高低,根据最近邻判别法将存在指标缺失的西藏判入低经济发展水平一类。最后根据聚类结果,得出我国区域经济发展水平整体呈现“东高西低”的格局;区域经济发展水平呈现出明显的右偏分布特征;从地区分布来看,我国整体经济水平受西部影响较大,而解决发展不平衡问题和进行西部扶贫工作应以青海、四川、重庆、陕西和山西为重。
[1]王千,王成,冯振元,等.K-means聚类算法研究综述[J].电子设计工程,2012,20(7):21-24.
[2]Milligan G W,Cooper M C.An examination of procedures for determining the number of clusters in a data set[J].Psychometrika,1985,50(2):159-179.
[3]周开乐,杨善林,丁帅,等.聚类有效性研究综述[J].系统工程理论与实践,2014,34(9):2417-2431.
[4]Arbelaitz O,Gurrutxaga I,Muguerza J,et al.An extensive comparative study of cluster validity indices[J].Pattern Recognition,2013,46(1):243-256.
[5]Caliński T,Harabasz J.A dendrite method for cluster analysis[J].Communications in Statistics,1974,3(1):1-27.
[6]杨宇,2006.多指标综合评价中赋权方法评析[J].统计与决策(13):17-19.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
发明与创新·小学生(2021年3期)2021-03-25
铁道通信信号(2019年6期)2019-10-08
计算机应用(2018年12期)2019-01-08
商周刊(2018年26期)2018-12-29
雷达学报(2017年6期)2017-03-26
电测与仪表(2015年5期)2015-04-09
电子设计工程(2015年6期)2015-02-27
中国工程科学(2015年7期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
