
基于分块DCT的图像去重算法
2018-10-08 11:56江小平胡雪晴李成华
中南民族大学学报(自然科学版) 2018年3期
江小平,胡雪晴,孙 婧,李成华
(中南民族大学 电子信息工程学院,智能无线通信湖北省重点实验室,武汉 430074)
随着人类信息数据规模的急剧膨胀,互联网中企业与个人累积的数据内容也在无限增长,其中很大部分是多媒体数据,尤其是图像数据.云端图像数据存在大量冗余的相似图像,包括完全重复的相同图像和同源图像的修改副本,后者在编码数据上完全不同,但是具有相似的视觉感知内容.相似图像经客户端上传到云端,浪费了大量的带宽和存储空间,如何高效准确地去重相似图像成为云存储领域中亟待解决的问题[1,2].
目前采用的图像去重方法多为文件级别去重,把图像作为二进制文件,通过传统哈希如MD5等方法对图片去重[3].如sis等系统中采用的文件级去重,利用文件哈希算法计算图片文件的哈希值,以哈希值作为判重标准.Zeng等[4]采用块级数据去重算法,先把图像文件分成固定大小的块,通过哈希算法计算每块的哈希值,再进行分块间的比较.文献[5]提出了一种基于分布式数据库/文件系统的图像文件去重办法,该算法截取图像文件二进制流的开头128位、末尾 128位和FML偏移开始128位,将这三段二进制流分别进行MD5码签名,并再次签名获得该文件最终的 MD5码签名,以该数据作为判断图像重复的标准.文献[6]提出针对上述算法的去重模型.以上方法均将图像作为二进制文件,采用传统哈希以二进制文件的标准进行判定去重,仅具有数据压缩性,不能消除多媒体感知内容上的冗余,计算复杂、开销大.对于图像来说,典型的修改如尺寸变换和压缩只改变它们的二进制表示,人类视觉感知上不变,应作为重复图像删除.这些感知相似的图像在远程服务器上占据很大的存储空间,大大影响了重复数据删除系统的效率.针对相似图像的去重,提出了感知哈希的概念[7,8]. Li等[9]采用图像均值感知哈希AVG-hash算法,在像素域得到图像的哈希值,并利用汉明距离判断两幅图像感知哈希序列的距离,不仅可减少计开销,在设定的阈值范围内,还可识别感知相似的图像,消除感知冗余,实现相似去重;但该算法并不能识别经过JPEG压缩对比度变化的图像改变.文献[10,11]提出一种基于离散余弦变换的感知哈希算法的DCT-hash,通过提取频域中特定系数生成的图像哈希作为去重判断.文献[12]在文献[10]的基础上提出了DAN-hash算法,对DCT-hash算法进行优化,提高了该算法的准确率和去重率.
本文针对相似图像去重,提出了一种基于分块DCT变换的新型感知哈希算法BDCT-hash,经实验验证该算法具有更高的去重率.并针对目前主流的JPEG图像标准,进一步优化图像去重方案,采用直接从JPEG图像格式压缩码流中提取需要的系数的策略,大大提高了图像去重的效率.
1 感知哈希去重算法
本算法中通过把图像进行分块DCT变换,提取变换后的重要系数,并对系数进一步处理生成图像的感知哈希序列BDCT-hash,用来代表每一幅图像.并用任意两幅图像BDCT-hash序列的汉明距离判断两幅图像间的距离.
1.1 生成感知哈希序列
生成感知哈希序列包括两个步骤,一是进行图像预处理,二是提取图像特征向量.
第一步:图像预处理.
1)彩色图像灰度化,本文仅考虑灰度情况下的图片,降低了亮度对图像分析的影响,彩色图像首先通过RGB转化为灰度图像.使用下列公式将图像转换为灰度形式:
Gray=R×0.299+G×0.587+B×0.114.
(1)
2)统一图像大小,对图像进行双线性插值,使分辨率统一为64×64,以保证生成的感知哈希序列长度一致.
第二步:提取图像特征向量.
1)将预处理后的图像分成64个8×8的块,通过分块DCT变换,得到每个分块的DCT系数矩阵.
2)分别取每个块的DC分量以及按照zigbig扫描的AC1和AC5分量,将相同位置的分量按照从左至右从上至下的顺序连接起来组成三个长度为64的一维向量Ai.
3)将三组向量分别进行二值化处理得到Fi.

(2)
4)依次连接Fi,生成长度为192的一维特征向量F.
特征向量F即为图像经过BDCT-hash得到的感知哈希序列值.
1.2 相似性度量
采用汉明距离作为比较两个感知哈希序列值之间相似性的一种度量.
设x={x1,x2,…,xN},y={y1,y2,…,yN},表示两个有限长字符串.x,y之间的汉明距离D(x,y)被定义为:
(3)
这里Q(xi,yi)是一个函数,当x和y不同时值为1,相同时等于0.为便于比较,汉明距离可以相对于字符串的长度n进行归一化,归一化汉明距离定义为:
(4)
特别地,二进制编码的数字之间的汉明距离可使用XOR运算来计算.

(3)
两个字符串之间的汉明距离可被用来确定其相似性.若汉明距离越大,字符串就越不一样.为了识别类似的字符串,通常为汉明距离设置一个阈值T,D(x,y)≤T时,x,y被识别为相似的字符串,认为两个感知哈希序列字符串代表的图像为相似图像;D(x,y)>T时,x,y被识别为不同的字符串,认为两个感知哈希序列字符串代表的图像为不同图像.
2 基于JPEG压缩的图像去重
JPEG(联合图像专家小组)由ITU, ISO, IEC共同努力制订,是第一个国际图像压缩标准.由于它具有良好的压缩性能、重建质量、可调节的压缩比等优势,在图像、视频等领域被广泛应用,目前互联网中绝大部分图像采用了JPEG压缩标准.因此在处理云端图像去重这一问题上,如何对JPEG图像进行准确高效的去重极为重要.本文针对JPEG图像对感知哈希算法进行改进,其整体的框架见图1.

图1 基于JPEG压缩的相似图像去重框架Fig.1 Similar imagedeweighting frames based on JPEG compression
基于JPEG图像的相似去重主要包括两个部分.
(1)感知哈希的构造过程.在实际去重过程中采用直接从JPEG图像格式压缩码流中提取需要的系数的方法,在BDCT-hash算法的基础上,大大提高了图像去重的效率.将标准化后的JPEG图像码流直接进行熵解码,利用JPEGlib库提取JPEG熵解码码流后Y分量的DC,AC1,AC5系数,再将系数二值化重组成为哈希序列值.
(2)相似图像检测过程.首先计算现有JPEG图像的感知哈希序列存储在哈希序列库中.当有待检测图像传来时,计算待检测图像的感知哈希序列.通过相似性度量,若计算所得的汉明距离大于设定的阈值,检测结果显示云端不存在相似图像;反之则结果显示已存在相似图像.
3 实验分析
用提出的算法BDCT-hash和文献[9]中的像素域平均值感知哈希算法AVG-hash,文献[10]中基于DCT变化的全局频率感知哈希算法DCT-hash和文献[12]中改进的频率感知哈希算法DAN-hash进行对比.分别分析其在不同失真情况下的稳健性以及大量数据环境下的去重率、错判率.
采用与文献[12]相同的图像库,包括TID2013, CSIQ, lena, peppers等7张图像在内的图像处理标准图集合.TID2013建立在TID2008的基础上,图像库包括25张参考原图及3000幅失真图像,共有24种常见的失真类型.CSIQ由美国俄克拉何马州立大学建立,包含30幅参考图像,866幅失真图像,失真类型包括JPEG压缩,JPEG2000压缩,对比度变化,高斯粉红噪声添加,高斯白噪声添加以及高斯相似.
3.1 BDCT-hash算法的稳健性
TID2013图像库中包含25幅参考图像,每种图像有24种失真类型,5种不同程度的失真水平.我们选取其中10种典型的失真,分析4种算法在不同失真情况下的表现.分别计算每种算法下25幅参考图像与其对应10种失真类型,5种失真程度的感知哈希序列,每种算法均得到1275个感知哈希序列.然后计算每种算法下,失真图像与相应参考图像的汉明距离,共得到1250个距离,每种失真类型有125个汉明距离.表1中数据显示的为4种算法在10种不同失真情况下,失真图像与参考图像汉明距离的平均值.

表1 4种算法在10种失真下平均汉明距离值对比Tab.1 Comparison of average Hamming distance values of four algorithms under 10 kinds of distortion
由上文可知:感知哈希序列相似度由汉明距离来判定;汉明距离越小,两个序列值越相近.因此,两幅相似图像的汉明距离越小越好,保证了在相同阈值情况下识别的准确率.在相同相似图像情况下,汉明距离越小,表明该算法的稳健性越强.从宏观数据分析该算法的识别率和误判率结果见图2.由图2可见:10种失真情况下,除图像JPEG2000压缩变换(4和6)中该算法的汉明距离平均值略大于其余3种算法;其他失真情况下,该算法的汉明距离平均值均明显小于其他3种算法.因此,该算法具有很好的稳健性.
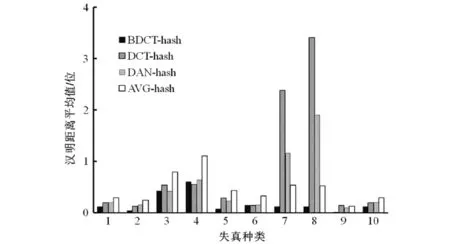
1) Additive Guassian noise; 2) Noise in color comp.; 3) JEPG compression; 4) JPEG2000 compression; 5) JPEG transm. errors;6) JPEG2000 transm. errors; 7) Mean shift; 8) Contrast change; 9) Color saturation; 10) Chromatic aberrations图2 4种算法在10种失真下平均汉明距离值对比Fig.2 Comparison of average Hamming distance values of four algorithms under 10 kinds of distortion
3.2 去重率分析
去重率是指在给定阈值T的情况下,算法可识别相似图像的正确率.实验分别统计了BDCT-hash,AVG-hash,识别率,实验共3866幅图像.每个算法产生3866个汉明距离,分别计算了4种算法所得汉明距离在阈值范围内的汉明距离数量,以及该数量占该算法所有汉明距离的比例,得正确识别率.在阈值分别选择T=1,T=5时相似图像的正确识别率结果如表2.

表2 4种算法在TID2013,CSIQ图像库中去重率的对比Tab.2 Comparison of four algorithms in TID2013 and CSIQ image library
由表2可知:T=1时,本算法的正确识别率高达99.83%,而AVG-hash,DAN-hash,DCT-hash的识别率依次递减;当T=5时,本算法的正确识别率高达95.36%,而AVG-hash,DAN-hash,DCT-hash三种算法的正确识别率均仅为约80%,.故所提出的BDCT-hash具有高度的稳健性,可准确识别相似图像,大大提高了相似图像的识别率和相似图像识别算法的准确性.
3.3 错判率分析
感知哈希算法要求在正确识别相似图像的同时,严格区分不同源图像,即不同源图像不可被识别为相似图像.分析4种算法的错判率,每种算法分别在TID2013中的3000张失真图片与7张标准图像的一一对应碰撞性实验后得到21000组汉明距离,用TID2013中25张原图与CSIQ中866张失真图像一一对应实验后得到21650组汉明距离.用其中汉明距离小于阈值的数量除以总数据量得到错判的比例.在阈值分别选择T=1,T=5时,4种算法的错判率结果见表3.由表3可知:在有限大量数据量情况下,本算法的错判率几乎为0,相比于其他的算法,本算法具有明显的优势,故该算法大大提高了相似图像识别的准确率.
表3 4种算法在TID2013, CSIQ图像库中错判率的对比
Tab.3 Comparison between four algorithms in TID2013 and CSIQ image database

给定阈值错判率/%BDCT-hashDAN-hashDCT-hashAVG-hashT=1000.0360.04T=500.0060.8100.97
3.4 序列长度分析
算法生成的序列长度由提取的分量数和图片的分块数决定,统一图像尺寸64×64,采用8×8的分块,每块提取量化后的DC和两个AC系数.故感知哈希序列长度为192.同时经二值化的感知哈希序列每位可用一个二进制表示,最后生成的感知哈希序列长度为192 bit.
4 结语
图像数据是当今互联网数据中的重要组成部分,它在存储和传播中产生了大量冗余,本文在现有的感知哈希算法基础上提出了基于分块DCT的感知哈希算法BDCT-hash.同时,针对现流行的JPEG图像压缩标准,提出了针对JPEG压缩的图像去重方案.经实验验证,该方案具有较高的稳健性和准确率.该算法也可作为提取特殊帧特征值的方法,针对视频数据存在的冗余,未来应用于视频去重领域.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
中等数学(2021年8期)2021-11-22
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
郑州大学学报(理学版)(2020年3期)2020-08-25
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
中国铁路文艺(2016年6期)2016-05-14
火控雷达技术(2016年2期)2016-02-06
现代电子技术(2009年9期)2009-06-25
