
用于域适应的多边缘降噪自动编码器*
2019-02-13 06:59胡学钢张玉红
计算机与生活 2019年2期
杨 帅,胡学钢,张玉红
合肥工业大学 计算机与信息学院,合肥 230009
1 引言
随着大数据时代的到来,数据领域的多样性和标签信息的昂贵性,都给传统的分类方法带来了极大的挑战。为此,跨领域(也称领域适应、迁移学习)分类[1-10]被提出并得到广泛的关注。
跨领域分类是利用已标记的源领域为无标记的目标领域训练一个精确的分类器。近年来深度学习在自然语言处理领域(natural language processing,NLP)和跨领域学习任务中的研究成果显著,多种神经网络模型[11-14]如卷积神经网络(convolutional neural networkss,CNN)、循环神经网络(recurrent neural network,RNN),被用于跨领域文本分类,并在不同的算法框架下都取得了较好的效果。
SDA[15](stack denoising autoencoders)作为一种无监督模型,在跨领域分类中也得到了广泛的应用。Glorot等人[15]通过堆叠多层SDA形成一个深度学习模型,并学习得到一个更健壮的潜在特征空间用于跨领域分类。然而,SDA需要迭代多次对网络结构进行优化,计算成本高且缺乏对高维特征的可扩展性;为此,Chen等人[16]提出了边缘降噪自动编码器mSDA(marginalized stacked denoising autoencoders),采用线性结构获取最优解,不需要优化算法来学习参数,速度快,然而可能导致过拟合问题;Clinchant等人[17]在Ganin等人[18]工作的基础上提出了一种更合适的域适应正则化方法用于域适应的降噪自动编码器MDA-TR(target regularized marginalized denoising autoencoders),MDA-TR在堆叠单层情况下可以达到很好的效果,堆叠多层效果没有明显增加反而增加了时间开销。
然而,上述方法中,没有考虑到不同特征对分类结果的影响不同。显然,在跨领域任务中,领域间不变的特征更有利分类。为此,本文对共享特征和特有特征应采取不同的边缘化处理,提出了多边缘降噪自动编码器用于解决跨领域的情感分类问题。
本文的主要贡献如下:
(1)通过区分共享和特有特征,并对共享特征和特有特征用不同的噪音系数进行边缘化降噪处理以获取更强健的特征空间;
(2)对获取特征空间进行二次损坏,从而扩大共享信息,减小领域差异;
(3)对权重似然率WLLR(weighted log-likelihood ratio)指标进行了改进,使之更适应于跨领域任务中的特征指标计算。
2 相关工作
目前,已有的跨领域文本分类算法主要分为两类,一种基于特征映射方法,一种基于自动编码器方法,本文方法属于后者。
2.1 基于特征映射的跨领域文本分类
已有的基于特征映射的跨领域分类方法可分为基于原始特征词层面和基于主题层面两类。
Blitzer等人[6]通过选择一个在源领域和目标领域都频繁出现的共享特征集合计算其共现关系得到权重矩阵,利用奇异值分解(singular value decomposition,SVD)构造低维特征空间训练分类器。该方法非常依赖潜在空间的质量,辅助学习任务的质量和数量。Pan等人[8]通过构建领域共享特征与领域特有特征的二部图,在二部图上采用谱聚类得到新的特征表示,并在此特征上构建分类器。Zhang等人[9]以共享特征为桥梁将源域特征词极性传递至目标域,实现跨领域文本分类。基于原始词语的特征空间实现知识的迁移,对领域比较依赖,容易出现特征稀疏问题。
近年,概率主题模型[19](topic modeling)也被用于跨领域文本分类。Xue等人[4]和Li等人[20]分别基于扩展的概率主题模型PLSA(probabilistic latent semantic analysis),以共享主题为桥梁,将被标记的训练数据和未标记的测试数据映射到一个共同的概率模型中,减少两个领域间的差异。Long等人[21]、Zhuang等人[22-23]和Pan等人[24]基于非负矩阵分解的方法提取主题,并利用优化全局目标函数来求解主题空间,使得源领域和目标领域的数据分布差异在此潜在空间上最小。基于主题层面的跨领域文本分类,一定程度上解决了特征稀疏问题。
2.2 基于自动编码器的跨领域文本分类
近年来多种自动编码器模型用于文本分类。降噪自动编码器是单层神经网络,对原始数据进行随机噪声损坏再使用自动编码器对原始数据进行重构,通过最小化重构后数据与原数据的距离来解决跨领域分类问题。Glorot等人[15]通过堆叠多层降噪自动编码器(SDA)获得潜在特征。Chen等人[16]提出了边缘化降噪自动编码器(mSDA),使用线性去噪器作为基础构建模型,对特征进行边缘化损坏处理,不需要通过随机梯度下降等优化方法来学习超参数,极大地减小了训练时间。Yang等人[25]利用结构特征空间,设计了一种噪音函数,进一步提高了算法效率。Clinchant等人[17]基于降噪自动编码器,进行域适应正则化,在隐藏层结合领域预测任务,使重构后特征空间倾向于域间不变的特征,从而减小领域间的差异,在单层情况下达到很好的效果。Ziser等人[26]提出一种三层神经网络,对来自预先训练的词向量的信息进行编码,通过实例中在语义上相似的共享特征来提高模型泛化能力。Jiang等人[27]提出了ℓ2,1范数降噪自动编码器(ℓ2,1-normstackedrobustautoencoders,ℓ2,1-SRA)。Louizos等人[28]提出了用于领域适应的VFAE(variational fair autoencoder)编码器。上述算法是通过自动编码器或其变体,获取更健壮的特征来实现跨领域文本分类。
3 本文方法
首先给出问题定义:对于已标记的源领域Ds=和未标记的目标领域。其中,ns和nt分别对应源领域Ds和目标领域Dt的实例数量;分别表示源领域Ds和目标领域Dt的第i、j个实例是源领域Ds的第i个实例对应的标签。本文的目标是利用源领域Ds为目标领域Dt训练一个分类器。
算法分为4个步骤:(1)根据源领域和目标领域提取共享特征集IW和特有特征集合SW;(2)对共享特征和特有特征用不同的噪音系数进行干扰,并基于单层边缘降噪自动编码器MDA(marginalized denoising autoencoders)获取特征空间;(3)对特征空间进行二次损坏以强化共享特征的比例,获取新的特征空间;(4)基于新的特征空间构建分类器,实现跨领域文本分类。
3.1 提取共享特征集和特有特征集
共享特征词是领域适应效果的关键。共享特征词的选取须具有两个条件:在源域和目标域具有较高的极性;在两个领域出现频率相对较高。文献[6-8]中采用词频、点互信息和词频相结合的方式来区分共享特征和特有特征,难以满足要求。希望能选择在源和目标域中出现频率高且极性强的特征作为共享特征。
为此,本文综合考虑频率和极性信息,利用源领域和目标领域数据,使用词频和改进的权重似然率信息WLLR,选取在源领域极性较高,且在目标领域频率较高的特征作为共享特征,消减领域间的分布差异。
首先,选取在源域和目标域中出现次数大于3次的特征词组成候选特征集CW={w1,w2,…,wi},wi表示在源领域和目标领域频数大于3的特征词;其次,根据r指标对候选特征词集CW进行排序,从中选取前k个特征作为共享特征集IW,其余的特征为特有特征,表示为SW。r指标综合考虑了特征的极性指标和特征在目标领域的重要度,计算公式如式(2)。式(2)中p(wt|Dt)/p(ws|Ds)用于度量特征wi对目标领域的依赖性。若p(wt|Dt)/p(ws|Ds)>1,表示wi对目标领域的依赖性较强,反之则较弱,该项可避免将那些在源领域具有较强极性,但在目标领域很少出现的特征被选为共享特征。
为了更能突出特征词的极性和该特征对分类的影响程度,借鉴了极性指标WLLR并进行了修正,提出了更适应领域适应任务的极性指标WLLRU,如式(1)。用p(w|y)×(1-p(w|y¯)) 代替了WLLR中的p(w|y),强化了特征的极性区分度,使重要的特征其极性取值更大。
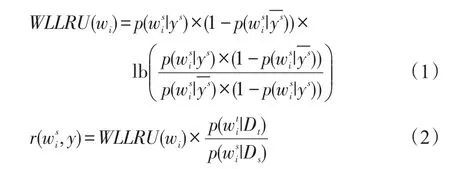
其中,wi是候选特征集CW中的特征,表示与ys相反的标签,是wi在类别ys中出现的概率,分别表示wi在源和目标域中出现的概率。
最后,采取降序排序对候选特征词的正负极性r(w,+)和r(w,-)进行排序;并分别选取前k/2个特征词构成共享特征词集IW(共有k个特征词)。
3.2 特征词进行噪音干扰
考虑到共享特征词在源域和目标域数据分布差异较小,更有利于分类,因此本文对共享特征词和特有特征词分别采用不同的噪音系数进行干扰。


3.3 获取新的特征空间

按照3.2节中的噪音干扰系数对特征空间进行噪音干扰。具体作法是:共享特征集IW中的每个共享特征词wi以概率1-γi,将特征值置0,取m份原始数据进行随机损坏m次,当m→∞时,最终共享特征词以概率γi保留[16]。特有特征集合SW中的每个特征以概率1-β将特征置0,取m份原始数据进行随机损坏m次,当m→∞时,最终特有特征词和共享特征词概率β保留[16]。通过最小化X和͂平方损失重构误差L(U)(如式(7))来求解U。根据文献[16]结论可知,式(7)中U的最优解为U=PQ-1。


其中,S=XXT,Pij表示矩阵P第i行第j列的元素。最终基于单层边缘降噪自动编码器学习得到新的特征空间
3.4 二次噪音干扰
仅对特征进行一次干扰,仅仅只能扩展文本文档,难以体现每个特征词对分类的不同重要程度,因此进行了二次噪音干扰,以突出有利于分类的特征。
共享特征词wi在源领域中具有较高的极性且在源域和目标域之间的相似度较大,其损坏程度应该较小,相对而言,特有特征相比共享特征对分类影响程度较小,其损坏程度较大。新的特征空间以概率l=[l1,l2,…,ld]∈Rd对输入数据进行边缘化损坏。根据式(10)、式(11)获取最终的特征空间

最后,采用支持向量机(support vector machine,SVM)对源域特征空间进行训练获得分类器,再对目标域进行分类。
4 实验结果与分析
4.1 实验数据集
本节首先给出实验数据集,并将本文中的方法与基准算法进行对比。
本文采用了已经在文献[16]中预处理过的亚马逊数据集RevDat。RevDat包括4种不同类型的产品评论:Books(B)、DVDs(D)、Electronics(E)、Kitchen(K)。每条评论由5 000维词袋向量表示;每一条评论基于用户的评价分数被赋值为一个情感标签-1(负的评论)或+1(正的评论)。用户评论分数为1或2认为是负评论,分数为4或5认为是正评论。每个领域都含有1 000个正例和1 000个负例。在该数据集上构造B→D、B→K等12个跨领域文本分类任务,前面的字母代表源领域,后面的字母代表目标领域。
为了说明算法的有效性,本文采用了如下基准算法进行比较:
(1)Notransf:源领域训练的分类器,直接用于目标领域分类。
(2)MDA[16]:MDA是边缘化降噪自动编码,对源域和目标域中的所有特征统一进行边缘化降噪处理,能够提取新的具有更强鲁棒性的特征,只将单隐层作为特征空间。mSDA是堆叠多层边缘化降噪自动编码器,将获得的隐层特征和原始数据联合作为特征空间。
(3)MDA-TR[17]:归一化降噪自动编码器,相比MDA,由于MDA是无监督学习,而MDA-TR在隐藏层也进行域预测任务,使重构后的特征空间倾向于目标域特有特征或领域间不变的特征,从而减小领域间的差异。
(4)DANN(domain-adversarial neural network)[18]:基于领域对抗的神经网络,在隐藏层进行域预测任务,从而捕捉域不变特征。
4.2 参数讨论
下面讨论本文参数的最优值,领域共享特征数目k,以数据集RevDat上的分类任务为标准,展示实验结果和参数的相关关系。领域共享特征数目k在算法中是一个重要的参数,在不进行二次噪音干扰的情况下,给出在不同k下的分类任务的精度。
由表1可知,领域共享特征数目k在1 400~2 200左右时,分类任务达到比较好的精度。k过小,容易导致极性较强且在目标领域出现频率较高的领域共享特征未被选择,容易导致数据稀疏性加大;k过大,则容易将领域共享特征极性倾向不强以及在源领域出现较高频率但在目标领域很少出现的特征包含在内,从而干扰领域适应。因此,本文将k设置为1 800。
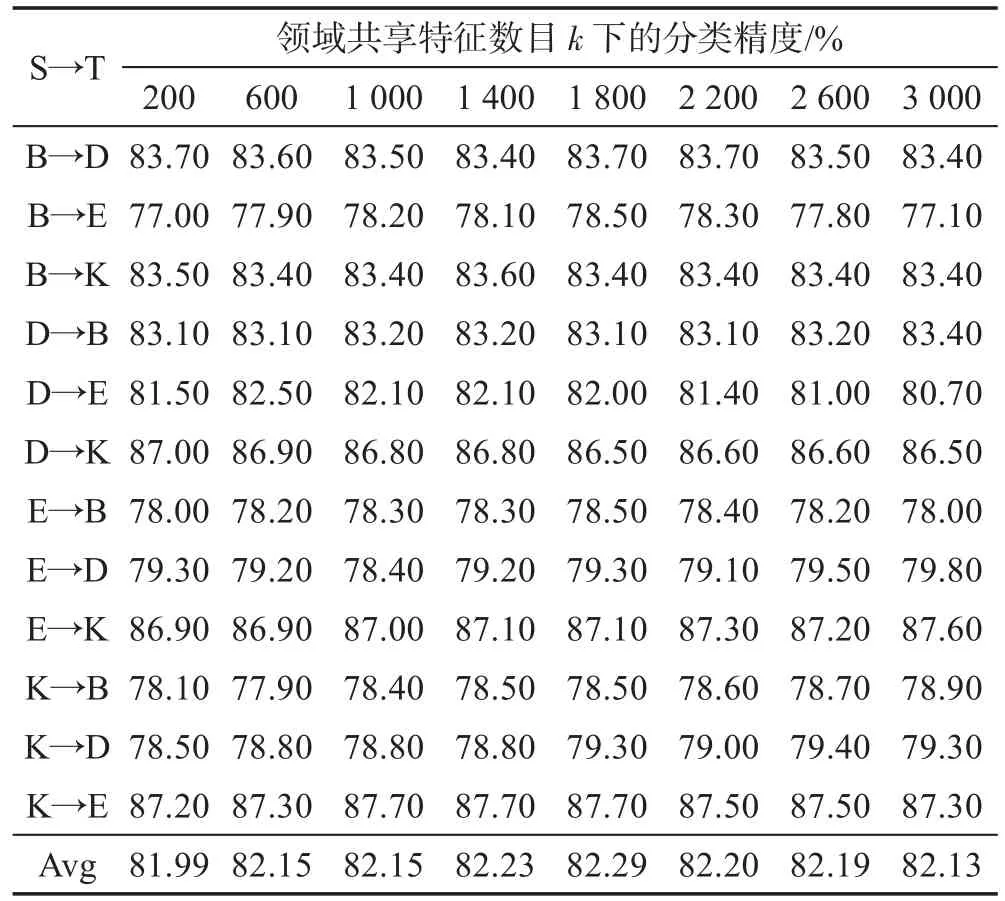
Table 1 Classification accuracy varying with the number of shared features表1 不同共享特征数目下的分类精度
需要说明的是,k值的设置对数据集是敏感的,不同数据集,其领域特点和相似性不同,则k值的设定将不同。
4.3 精度对比
为了证明本文算法的有效性,将本文算法与基准算法在数据集RevDat上进行对比。
从表2的实验结果可知,本文算法M-MDA在RevDat上的平均分类精度要明显高于其他基准算法。分析原因如下,Notransf算法是基于特征层面,容易受文本稀疏性影响。在基准算法中,MDA可以在一定程度上获得更健壮的特征用于分类,DANN和MDA-TR是mSDA的变体。与DANN相比,MDATR的行为类似于文本文档的文档扩展,它以非常小的频率添加新单词,有时还带有少量的负权重。当数据稀疏时,会增加小的噪音来破坏或干扰数据,难以取得明显效果。与mSDA、MDA-TR相比,本文提出的方法M-MDA提出了多边缘化噪音干扰,为领域间不同的特征设定不同的噪音干扰系数。从表2可以看出,M-MDA分类准确度相比基准算法(Notransf)平均提高了7.13%。本文算法M-MDA对领域间差异领域特征词进行了分析,领域间不同特征进行不同程度噪音干扰,并通过对特征进行二次噪音干扰并强化共享特征的比例,减少了领域间数据分布的差异,在文本分类精度上具有很大的优势。
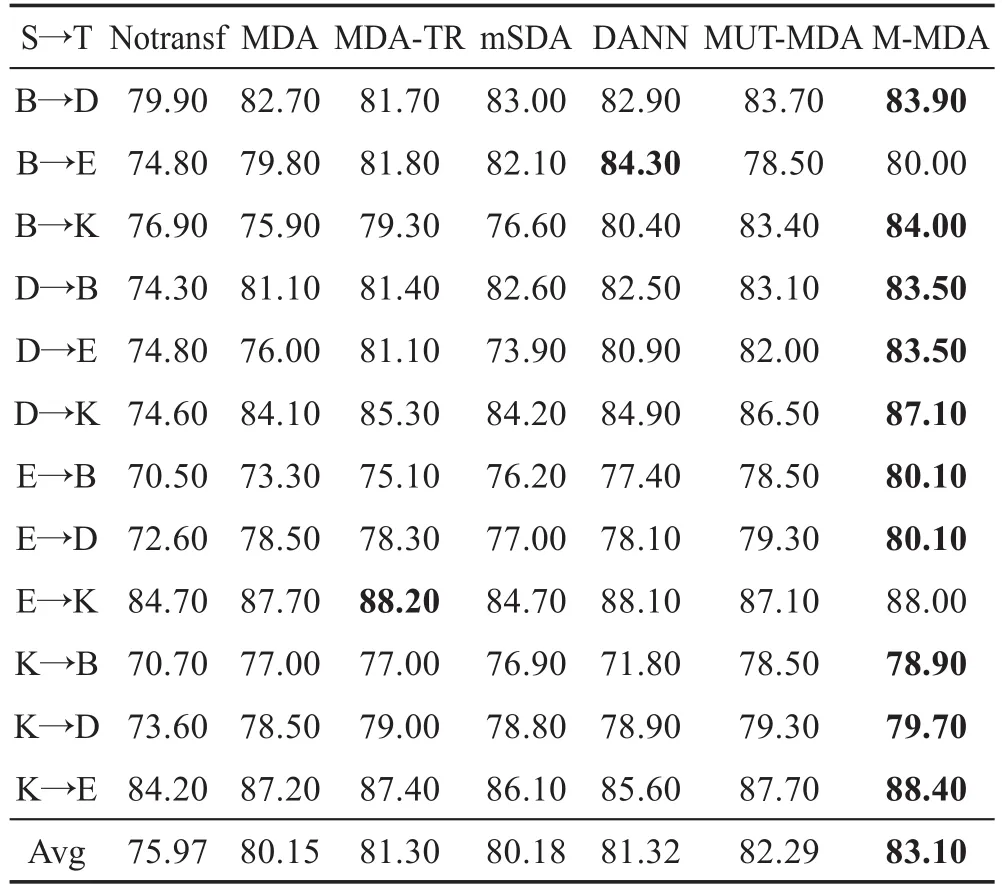
Table 2 Comparison of classification accuracy on RevDat表2 RevDat上分类精度对比 %
表2中MUT-MDA(multi marginalized denoising autoencoders without weighted)是本文算法M-MDA的变形,仅对数据进行多边缘化,忽略二次损坏步骤。为了进一步说明算法的有效性,对MUT-MDA和M-MDA进行对比分析。从表2可以看出,MUT-MDA根据领域间的特征差异进行多边缘损坏可以更好发现潜在特征之间的关系,分类精度较基准算法DANN平均提高了0.97%。M-MDA在MUT-MDA基础上进行了二次噪音干扰,以突出有利于分类的特征,相比MUT-MDA分类精度提高了0.81%。
5 结束语
本文针对不同特征对分类结果的影响不同,对不同特征进行不同程度的噪音干扰,提出了一种多边缘降噪自动编码器用于跨领域文本分类。实验结果表明,该算法可以有效提高跨领域情感分类准确率。
然而,本文方法是根据源领域和目标领域共有特征计算出特征的噪音干扰系数,并没有考虑领域间特有特征对噪声的影响。利用共享特征和特有特征确定最优的噪音干扰系数将是下一步研究的重点。
猜你喜欢
传感器世界(2022年4期)2022-08-05
中学生报·教育教学研究(2022年1期)2022-04-18
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
疯狂英语·新悦读(2019年10期)2019-12-13
时代英语·高一(2019年5期)2019-09-03
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
数理化学习·高一二版(2009年2期)2009-03-30
