
一种基于信息熵和DTW的多维时间序列相似性度量算法*
2019-03-29 11:26乔美英刘宇翔陶慧
中山大学学报(自然科学版)(中英文) 2019年2期
乔美英,刘宇翔,陶慧
(1.河南理工大学电气学院,河南 焦作 454000; 2. 煤炭安全生产河南省协同创新中心,河南 焦作454000)
时间序列是按照时间顺序获得的一系列的观测值,描述了时间序列数据随时间变化的动态特性[1-2]。随着卫星定位、通信技术、跟踪检测、传感器技术的发展,时间序列数据与日俱增,其涵盖人类行为、社交网络、物流交通、核能化工、天文气象等诸多领域,因此对时间序列数据的分析利用变得越来越重要。为了从这些海量数据中挖掘有效信息,研究人员开发了时间序列数据方面的很多应用技术,诸如:系统的状态预测[3]、医学[4]、故障检测[5]、行为识别[6]等。这些技术的应用均依赖于对时间序列数据样本相似性的度量,只有准确地表达并量化样本轨迹之间相似程度,才能度量同类样本数据之间的相似性与不同类样本数据之间的差异性,使各类数据挖掘算法的应用顺利实现。因此,相似性度量是时间序列数据挖掘应用中的重中之重。
目前,有很多方法能够对多维时间序列进行相似性度量,包括欧氏距离度量,动态时间规整(DTW,dynamic time warping)度量[7],短时间序列度量[8],KL距离度量[9],二维奇异值分解[10]和基于概率的距离度量[11]等。其中,欧氏距离和短时间序列度量要求时间序列具有相同的相位,对于测量非一致的多维时间序列并不适用。DTW通过对时间轴进行规整,有效地解决了时间序列在时间轴上的伸缩与偏移,但传统的动态时间规整算法只能对单维时间序列进行测量,文献[12]将其扩展为多维动态时间规整算法。KL距离度量和基于概率的距离度量适合测量线性弯曲的多维时间序列之间的相似性,当出现的两个非线性弯曲的多维时间序列的概率分布差异较大时,该两种方法将不准确。奇异值分解法将多维时间序列的列与列、行与行的协方差矩阵分解,计算出特征值并将其作为特征,从而把度量时间序列的相似性转为度量特征的相似性。此外,对多维时间序列的相似性分析还可以采用度量学习的方法,其利用给定的训练样本集学习,得到一个能有效反映数据样本间距离的度量矩阵[13]。如今,多数度量学习算法往往是基于马氏距离。由于马氏距离不仅能排除变量间的相关性干扰,而且不受量纲的影响,所以广泛应用于分类等数据处理[14-15]。文献[16]将大间距最近邻(large margin nearest neighbor,LMNN)算法与DTW算法结合,用LMNN算法在特定的损失函数下优化马氏矩阵,取得了较好的度量效果。文献[17]提出一种基于LogDet dicergence 的度量学习算法,它通过三元约束来学习马氏矩阵,用于度量多维时间序列的相似性,该方法度量结果虽然比较准确,但时间复杂度较高、耗时较多。文献[18]提出一种将支持向量机(SVM)与DTW相结合的模型,该模型中DTW 的局部距离使用的是欧氏距离,对每个变量赋予相同的权重,忽略了各个变量间的相关性,所以不能进行准确的相似性度量。本文提出一种基于信息熵和DTW的多维时间序列相似性度量算法,简称IEML-MD DTW (information entropy metric learning-mahalanobis distance DTW)算法。首先,通过动态时间规整对多维时间序列进行相似性度量,再用MDDTW消除时间序列中变量间的相关性干扰,最后使用信息熵理论通过最小化损失函数,学习得到优化后的马氏距离矩阵。研究结果表明,该算法优于其他的算法。
1 动态时间规整(DTW)
动态时间规整(DTW)的基本思想是通过时间序列数值上的相似性来对时间轴进行规整,然后寻找这两个时间序列的最优对应关系。因此,这两个时间序列的相似关系就可以被很容易的测量出来。设有两个单维时间序列X和Y,分别为X={x1,x2,x3,,xn}和Y={y1,y2,y3,,ym}。其中,n和m分别为X和Y的长度。构造一个n×m的矩阵网格,矩阵元素(i,j)表示xi和yj两点的距离dl(i,j)=(xi-yj)2,称其为局部距离。最优规整路径W可以表示为:
(1)
其中,wx(k)表示时间序列xi的索引,wy(k)表示时间序列yj的索引,p为规整路径W的长度,且p∈[max(m,n),m+n],(wx(k),wy(k))′表明时间序列X中的第wx(k)个元素与时间序列Y中第wy(k)个元素是一一对应的。
只取使得下式(2)规整代价最小的路径:
(2)
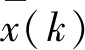
(3)
(4)
定义一个累加距离r,其可用式(5)表示。累加距离为当前格点距离d(i,j)与可到达该点的最小邻近元素的累加距离之和。
r(i,j)=d(i,j)+
min{r(i-1,j),r(i,j-1),r(i-1,j-1)}
(5)
从(1,1)点开始匹配两个序列S和T,每到一个点,之前所有的点计算的距离都会累加。要到达点(i,j),只能从(i-1,j)、(i,j-1)或(i-1,j-1)出发。r(i,j)即为从(1,1)到(i,j)的最小累加距离。最优的弯曲路径如图1所示。
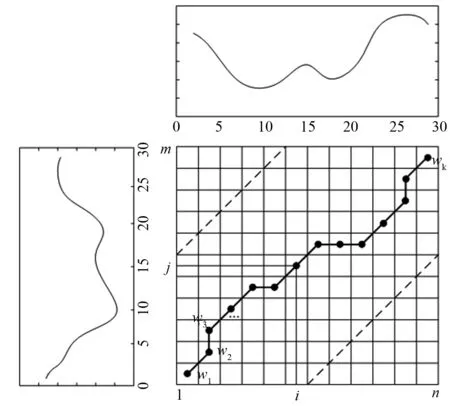
图1 两个时间序列的最佳弯曲路径Fig.1 The best warping path of two time series
2 基于马氏距离的DTW
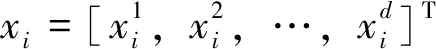
DM(xi,xj)=(xi-xj)TM(xi-xj)
(6)
对称的半正定矩阵M为马氏矩阵。当M=I,马氏距离就转变为欧氏距离。将马氏距离进行分解为M=ATA,则(6)中的马氏距离可以转为:
DM(xi,xj)=
(xi-xj)TATA(xi-xj)=
(Axi-Axj)T(Axi-Axj)
(7)
可以看出,马氏距离的计算就是利用矩阵A通过线性变换,将原始的特征空间映射到一个具有更好度量的新的特征空间,再计算在新空间中的两个样本之间的欧氏距离。因此,马氏距离可以有效地度量两个向量的距离。然而,如何学习到一个较优的马氏矩阵,将是马氏距离计算的关键。传统的动态时间规整算法只能处理单维时间序列的规整问题。在很多应用中,单维时间序列只能提供序列的部分信息,不能准确地反映样本的多个属性的变化情况。因此,需要将传统的DTW算法进行扩展,以满足处理多维时间序列的要求。
给定两个多维时间序列X和Y,
(8)
其中,d是多维时间序列的维数,即属性变量的个数,m和n分别表示时间序列X和Y的长度。定义Xi=(x1i,x2i,,xdi)T表示X的第i列,为在第i时刻时各个变量的值;Yj=(y1j,y2j,,ydj)T表示Y的第j列,为在第j时刻时各个变量的值。于是,用马氏距离来计算DTW中的局部距离,即:
dM(Xi,Yj)=(Xi-Yj)TM(Xi-Yj)
(9)
其中,1≤i≤m,1≤j≤n,M是一个对称的半正定矩阵,即为马氏矩阵。
与单维时间序列的DTW类似,多维时间序列X和Y之间的距离和最优的规整路径可以由下式(10)来计算:
(10)
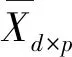
(11)
因此,可以得到DTW中局部距离的另一种表示:
(12)
该种表示与上式(10)中动态规划方程所得到的解是一致的,但具有更好的扩展性。
3 IEML-MDDTW
多维时间序列基于马氏距离的DTW表示,不仅解决了传统DTW只能度量单维时间序列相似性的缺点,而且在局部距离计算中,引入马氏距离,可以更加准确地反映样本的各个属性变量之间的关系。然而,如何寻找到一个合适的马氏度量矩阵,使得各个变量之间有更好的度量关系,是度量时间序列的相似性中重要的一步。
根据文献[19]基于信息论中信息熵的度量学习模型,得到在线度量学习模型,对马氏度量矩阵进行学习,即:
(13)
其中,Mt为在第t次迭代时的马氏度量矩阵,ηt是一个正则化参数且大于零,正则化函数为:
(14)
式中,D(·)表示布雷格曼散度,用来测量马氏矩阵M和Mt的差异,tr(·)表示矩阵M的迹,logdet(·)是矩阵M的行列式的对数,d为马氏矩阵M的维数。
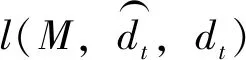
(15)
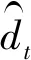
(16)
当式(16)对马氏矩阵M求偏导数为0时,该函数达到最小值,求出的解为全局最优解,可得:
(17)

(A+BCD)-1=A-1-A-1B(C-1+DA-1B)-1DA-1
(18)
求解式(17)可得t+1时刻的Mt+1表达式:
(19)
在式(19)的更新方程中,可看出参数η是用来平衡正则化函数与损失函数的,选取合适的值对平衡十分重要。如果ηt的值设置过大,在Mt+1更新的过程中,最小化损失函数将会占过大的比重,这会使得Mt+1在更新时不断震荡,度量学习的整个过程也会不稳定。如果ηt值选取的过小,那么在每次更新时,Mt+1与Mt的差异就会很小,这虽使得度量学习的过程非常稳定,但其过程过于缓慢和保守,需要花费更多的计算时间,或许当训练样本都训练完以后,也无法得到一个合适的马氏矩阵。因此,在选择正则化参数ηt时,需要考虑稳定性与时间效率的折中。同时,根据马氏距离度量的定义,选取的ηt要保证在每一次迭代中,Mt+1都能保持半正定,所以ηt需要满足式(20)。
(20)
求解线性矩阵不等式有很多种方法,例如:使用MATLAB中的线性矩阵不等式的求解工具箱。工具箱可求出参数ηt的值,同时能够保证Mt+1在每一次的迭代过程中都是一个半正定的矩阵。表1为多维时间序列的度量学习算法。
4 实验结果
4.1 分类实验
为了验证所提方法的有效性,从UCI多维时间序列数据集中选取5个数据集。在测试数据集上,做一系列分类实验,比较IEML-DTW与其他的多维时间序列分类算法的分类准确度,并展示所提方法的计算时间。选取的5个数据集分别为:Japanese vowels dataset (Japanese Vowels), Libras movement dataset (Libras), pen-based recognition of handwritten digits dataset (Pen Digits), Character Trajectories, Robot EF。其中,Japanese Vowels记录了9名男性对日本的两个元音/ae/的发音情况,每段语音为一个12维的多维时间序列样本,一共有10 992个样本。Libras数据集通过视频采集了巴西官方手语的手势信号,每一类代表手势信号中的一种手势。Pen Digits中记录了44个测试者用触控笔书写的阿拉伯数字,该数字样本有10 992个,共分为10个类别。Character Trajectories包含有20类用写字板采集的字符轨迹数据,共2 858个字符样本。Robot EF中包括5个子数据集,包括LP1、LP2、LP3、LP4和LP5。它记录了机器人在遇到5种故障时的压力和扭矩。数据集的相关信息如表2所示。
将所提方法与基于欧氏距离的DTW、下届测度法(LBM)、时间离散支持向量机(TDSVM)、基于DTW的支持向量机( SVMDTW)、LDMLT - MDDTW等算法进行比较。采用最近邻分类器(1-NN)对数据集进行分类,选择交叉验证正确率作为评价指标,来估计所提方法的性能。在度量学习中,约束对从训练样本中随机选取;个数为N=CK(K-1),K为类别数量,C设为30;目标距离dt设置为训练样本约束对之间的距离分布中第10和第90个百分位所对应的距离差。因各数据集样本数量不同,对于LP1、LP2、LP3、LP4和LP5数据集采用五折交叉验证,对于其他数据集使用10折交叉验证。各数据集上的分类准确率如下表3所示。

表1 多维时间序列的IEML-MDDTW算法Table1 IEML-MDDTW algorithm
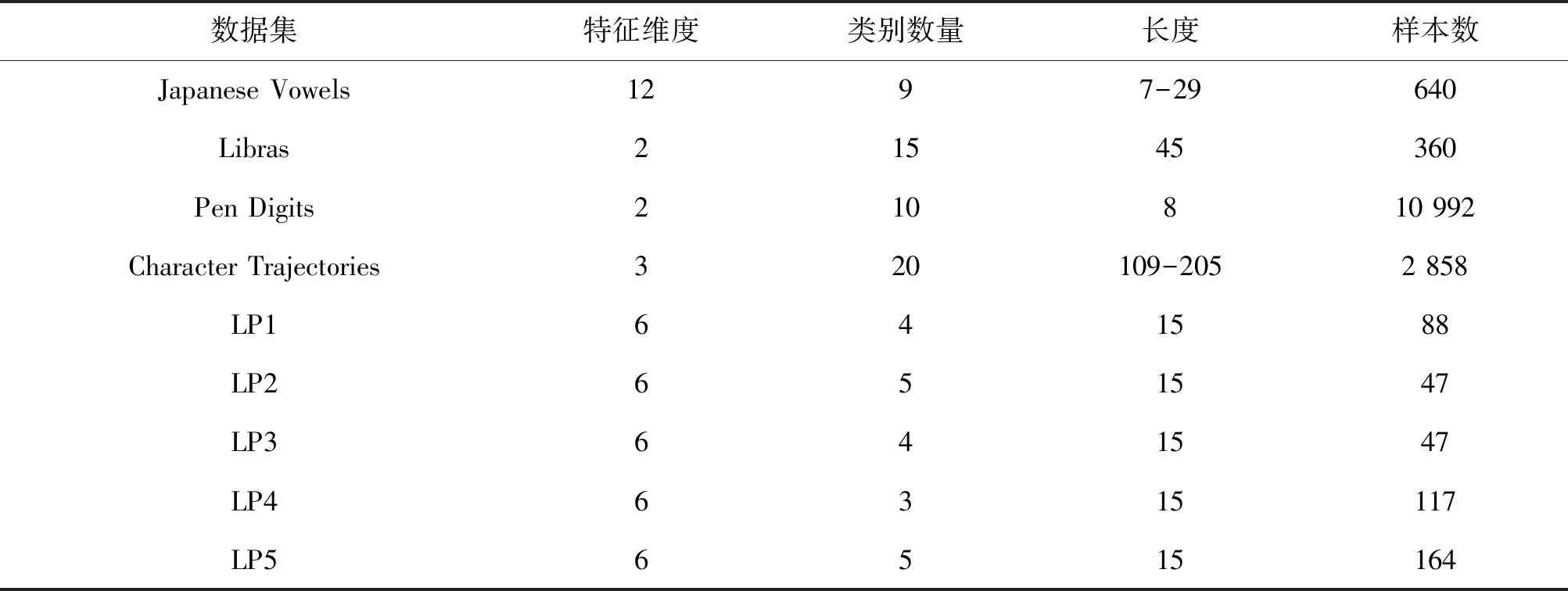
表2 UCI多维时间序列数据集Table 2 UCI multidimensional time series data set
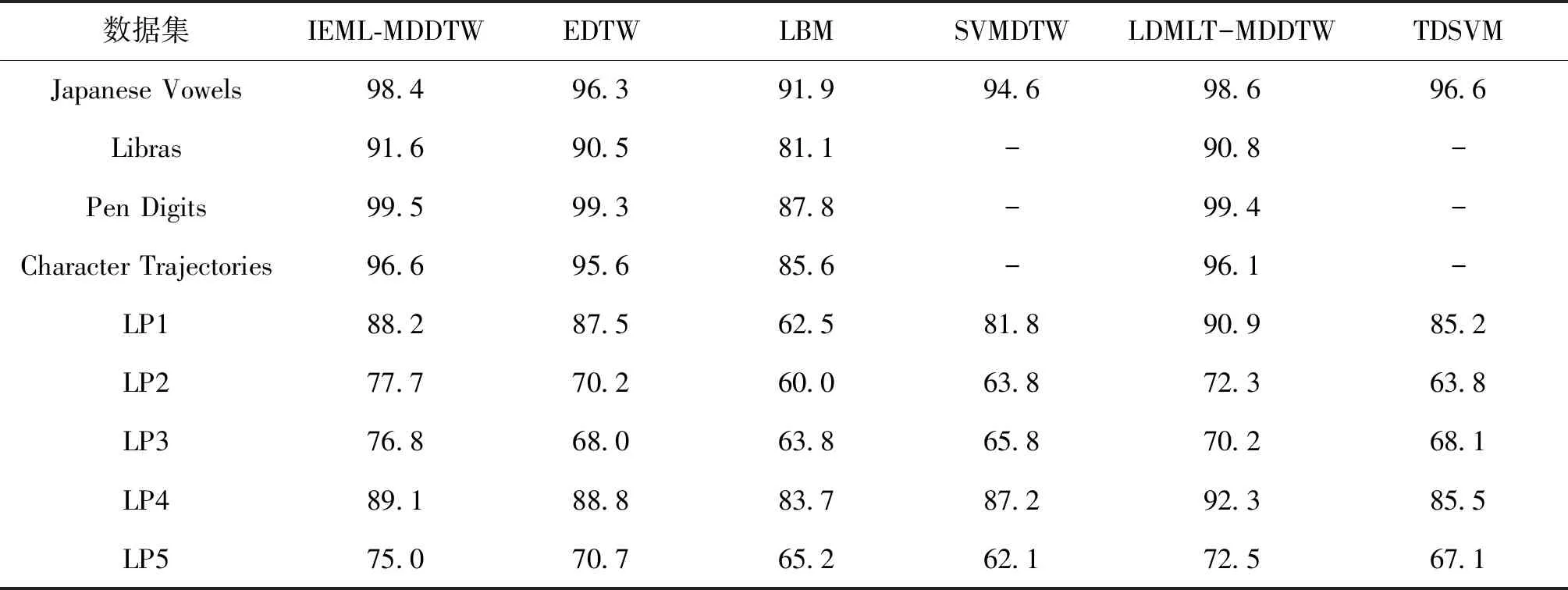
表3 各数据集交叉验证分类准确率Table 3 Cross validation of classification accuracy in each data set
从表3可以看出,在Japanese Vowels、LP1和LP4数据集上,本文所提方法(IEML-MDDTW)的分类准确率略小于LDMLT-MDDTW;但在其他数据集中,IEML-MDDTW的结果明显优于EDTW、LBM、SVMDTW、TDSVM,表明IEML-MDDTW在5个数据集中都取得了不错的分类效果。随着时间序列的属性增多,IEML-MDDTW算法的优越性越来越明显。而LBM、TDSVM和SVMDTW由于没有考虑多个变量之间的相互关系,所以在LP2、LP3数据集上分类结果较差。同时,利用信息熵理论可以学习到一个合适的马氏距离矩阵,再使用DTW对长度或相位不同的多维时间序列进行动态规整,可以有效地将多维时间序列对齐并准确度量。

图2 分类时间消耗Fig.2 Time consumption of classification
由于5个数据集长度不等,分类时间消耗相差较多。为便于观察,将本文所提方法与目前较好的LDMLT-MDDTW方法在5个数据集上的分类时间消耗进行对比,结果如图2(a)和图2(b)。IEML-MDDTW和LDMLT-MDDTW的时间复杂度都为O(Nd2mn),N为约束对数量。从图2(a)和图2(b)可以看出,IEML-MDDTW在所有数据集上的分类时间消耗都要比LDMLT-MDDTW少,说明本文所提方法具有较高的计算效率。LDMLT-MDDTW计算速度慢,主要是因为该算法在构造动态三元约束时,每次学习到一个马氏矩阵后,都需要重新更新三元约束,多数时间都花在了动态三元约束的构建上,当数据集样本较多时,该算法会更加耗时。而本文选取约束对是随机选取的,每个约束对中只有两个元素,且约束对的个数是根据样本类别数确定的,所以不需要花费太多的时间。
4.2 分类结果的影响因素分析
在IEML-MDDTW算法中,参数可能会对多维时间序列的分类结果产生一定影响。首先,约束对N如果偏大,马氏距离矩阵的学习过程会很缓慢,甚至过度学习,无法学习到一个合适的马氏矩阵;如果N偏小,可能还没有学习到一个合适的马氏度量矩阵,学习过程就已结束,两者都会使得分类结果较差。此外,还有一个参数就是训练样本的数量,其值也会对马氏距离矩阵的学习过程产生影响。本文选取数据集LP5,分别逐渐增加约束对的数量和训练集样本的数量。其中,训练集样本的数量为随机选取,为10%-100%原始训练样本,N的大小由C来决定,C取值范围为30-48,仍然使用交叉验证的方法来确定分类准确率。
从图3可以看出,随着约束对数量的变化,分类准确率也在不断变化,变化范围在 ±3% 左右,变化并不是很大,说明约束对数量的增加并不会对分类结果产生很大影响。在图4中,随着训练集样本的数量不断增大,分类准确率呈现出上升的趋势。当训练集比重从10% 增加到40% 时,分类准确率变化了5% 左右;当训练集比重超过40% 以后,分类准确率的增长开始变得缓慢,变化大小在1%左右。因此,可以说IEML-MDDT算法对训练集样本的变化还是比较稳定的,利用较少的样本就能更新到一个合适的马氏度量矩阵。
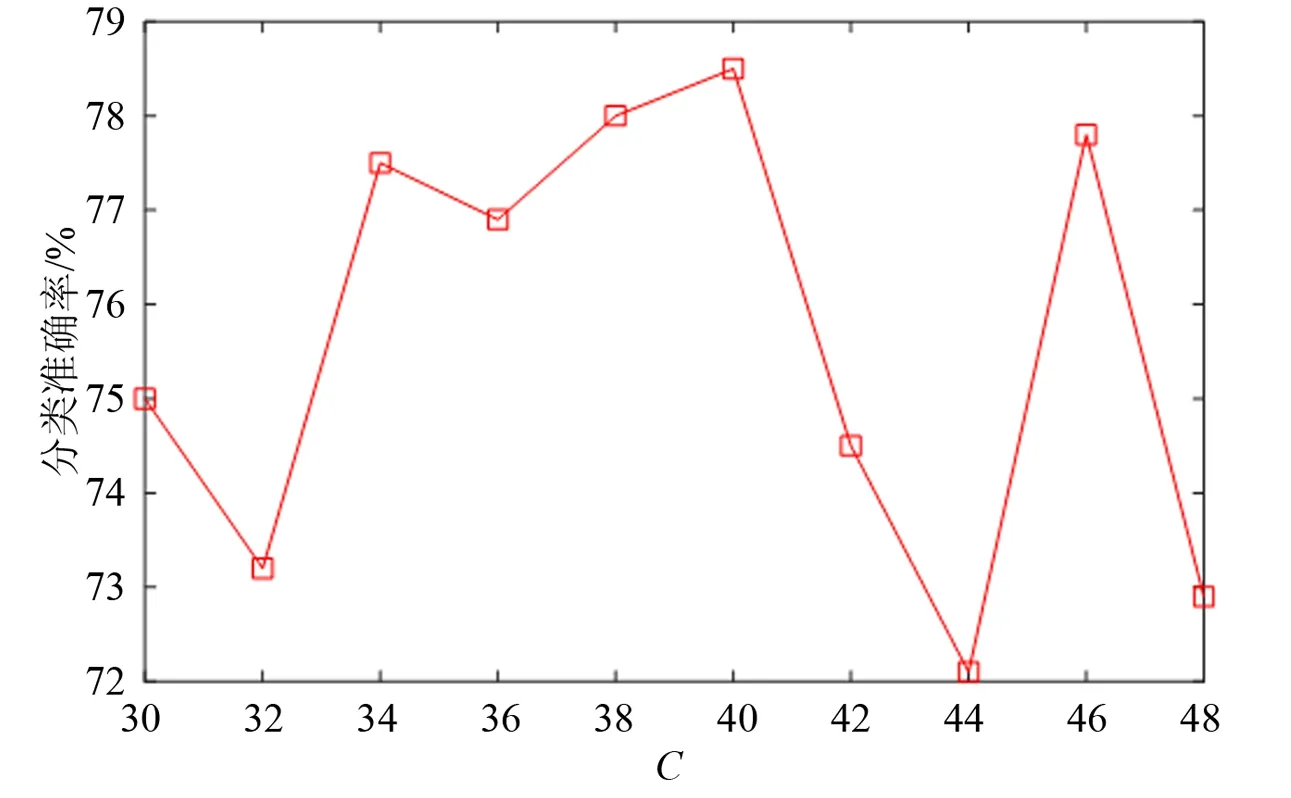
图3 约束对的数量对分类的影响Fig.3 The influence of the number of constraint pairs on the classification
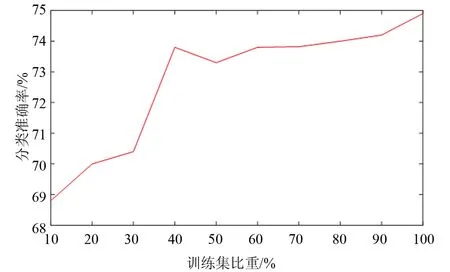
图4 训练集样本的数量对分类的影响Fig.4 The influence of the number of training sets on the classification
4.3 模型的鲁棒性检验
选取多维时间序列Robot EF数据集中LP2、LP3两个子数据集,加入高斯噪声,高斯噪声的均值为0,方差分别为0.005、0.01、0.02、0.03、0.04、0.05,重新使用本文所提方法对该两个数据集进行分类实验。实验结果如图5所示。分类结果表明,随着噪声密度不断增大,分类准确率出现减小的趋势,但是其减小的幅度并不是很大,依然可以保持较高的分类准确率。因此,可以看出IEML-MDDTW对噪声不是特别敏感,具有较强的鲁棒性。
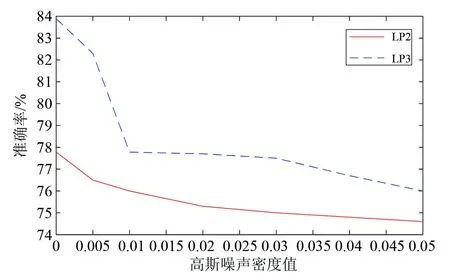
图5 施加高斯噪声后的分类正确率Fig.5 Classification accuracy after adding Gauss noise
5 结 语
本文提出一种基于信息熵和DTW的多维时间序列的相似性度量算法。在该算法中,利用动态时间规整对多维时间序列进行动态规划,来寻找最优的对齐路径;在DTW局部距离的计算中,采用马氏距离,来消除属性变量间的相关性干扰,而马氏距离矩阵可以通过信息熵理论获取。实验结果表明,采用本文所提的IEML-MDDTW模型对多维时间序列数据集进行分类,不仅具有较高的分类准确率和鲁棒性,而且计算效率高,证明了其度量的有效性。该算法还可以应用于图像识别、语言识别和故障诊断等度量领域。然而,本文用于测试的多维时间序列的数据属性不多,对于属性较多的多维时间序列,要先进行降维处理再度量。如何对数据降维,将是下一步所要研究的内容。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
名作欣赏(2017年32期)2017-11-28
读与写·教育教学版(2017年10期)2017-11-10
人生十六七(2017年6期)2017-06-06
小小说月刊·下半月(2016年7期)2016-05-14
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
