
基于自适应四叉树的网页分块技术
2019-04-08 00:46邢益阳
现代计算机 2019年6期
邢益阳
(四川大学计算机学院,成都 610065)
0 引言
最近几年人工智能非常火热,其中使用的深度学习技术需要收集大量的数据,在足够多的数据支撑下才能训练出完美的模型。图像处理技术是深度学习的主要技术之一,为了获取丰富的图像特征信息,通常需要将图像灰度化、二值化和角点检测,等等[1]。图像分割是图像识别和计算机视觉至关重要的预处理,现有的图像分割方法主要有以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等[2]。
面向网页的分块通常采用基于DOM树的方法或基于图像处理的方法,对于基于DOM(Document Object Model)树的网页分块,两个DOM节点虽然不相同,但呈现的视觉效果可能一样,而且DOM父子节点之间存在覆盖关系,一个节点的属性可能会影响另一个节点,导致网页分块误判。本文采用图像处理的方法,因为网页截图是网页的最终渲染结果,符合人的视觉感知[3],而基于四叉树的方法能快速分割图像,并保持图像的边缘细节,能获得层次化的分块节点和个数,本文提出的自适应的四叉树是基于阈值的分块方法,通过遍历像素点找到精准的分割坐标,使得图像能被正确地分块,提高两个图像差异的识别率。
四叉树是一种树状的数据结构,常用于二维空间数据的分析与分类,它将数据分成了四个象限,四叉树常用于地图的空间索引、稀疏数据、2D中的快速碰撞检测[4-5]。通过四叉树可以把图像按一定规则切割成四个部分,如图1、2所示,每一个节点下面又可以继续分成四个节点,依次迭代即可得到切割后的图像四叉树。
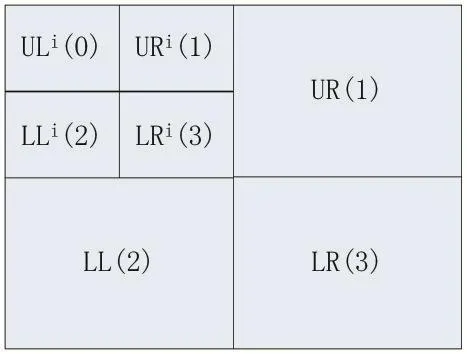
图1 图像的四叉树例子
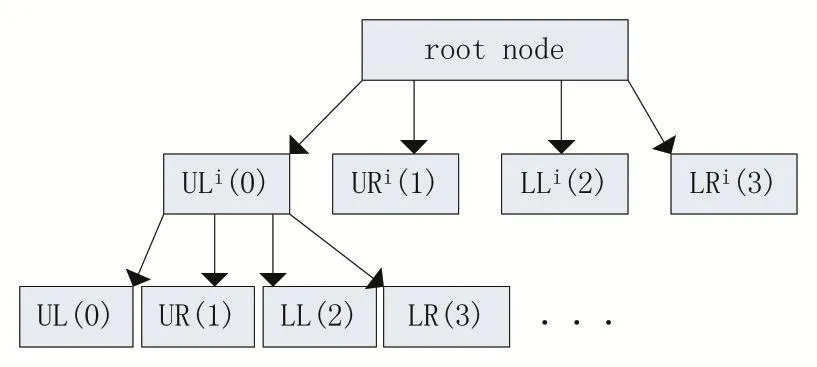
图2 四叉树的数据结构图
此类四叉树是均等切分的,不适用于网页分块,因为网页是由各个大小不一的区块组成,所以本文提出了自适应四叉树,切分后得到的四个子图的大小与图像属性均方误差和有关。
对图像进行分割就需要给出分割的标准,本文分别采用了三种分割标准:“GBR颜色均方误差”、“HSV颜色均方误差”、“图片信息熵”。
颜色是图像的重要特征,也是人识别图像的主要感知特征之一,图像的RGB颜色均方误差或HSV颜色均方误差越大,图像的颜色越丰富,图像就不纯,当误差大于某一个阈值时,就认为图像是应该被切割的。对像素颜色特征出现的频率进行统计可以直观地表示图像内容:
RGB颜色均方误差公式如下:
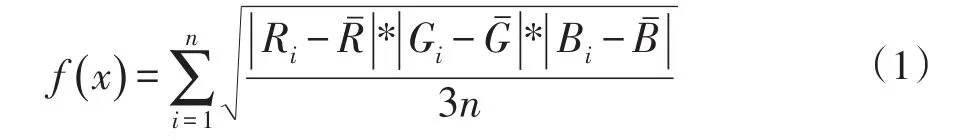
HSV颜色均方误差的公式如下:
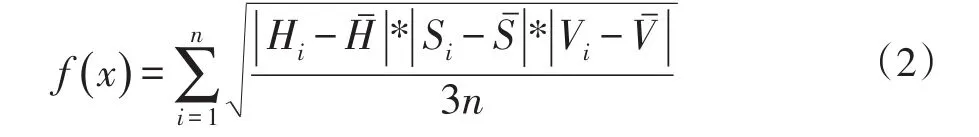
HSV模型是针对用户观感的一种颜色模型,侧重于色彩表示,是统计 HSV 模型中的色调(H)、饱和度(S)、明度(V)得到的平均值。
信息熵是对信息的量化度量,信息熵越大,不确定性越大,那么对于图像的信息熵来说它就越不纯,说明图像应该被切割。计算图像信息熵均方误差的公式如下:

其中x表示像素的RGB中的某一个属性,属性的取值为(x1,x2,x3),p(xi)表示属性值 xi出现的频率,且有∑p(xi)=1,本文取的RGB模型的3个分量,采用RGB颜色均方误差的好处是计算相似度时与图像的旋转平移和尺寸大小无关。
1 自适应四叉树
四叉树被认为是二叉树的高维变体,通常的四叉树是直接均等切分,而采用自适应的四叉树需要找到最佳切割点,目标是使得4个小分块的均方误差和最小。
定义一棵四叉树:

本文提出的自适应四叉树算法的实现步骤为:
(1)打开图像并初始化图片左上角坐标为(0,0)和第一个root节点,把图片转变成一棵四叉树;
(2)分别从横向和纵向遍历图片的像素点,计算切割图像后得到的4个子图的最小均方误差和的切割点。计算像素点与像素平均值的欧氏距离:
①计算横向切割图像得到的2个子图的均方误差和最小的纵坐标yi;
②计算纵向切割图像得到的2个子图的均方误差和最小的横坐标xi;
(3)根据切割点的坐标(xi,yi)把一个图像切割成4块,以坐标为中点画两条线;
(4)把4个子图实例化为树的节点,并赋值给父图;
(5)采用先序遍历的方式,从左至右遍历每一个节点,判断切割后的4个子图是否是叶子节点,如果已经达到最大切割次数或节点的均方误差小于阈值,则停止切割跳到步骤5,否则跳到步骤2,继续迭代切割。
(6)结束切割,得到原图的四叉树分割图像。
为了找到最佳切割点,如果从头到尾遍历每一个像素点[6],效率会比较慢,时间复杂度为m*n。为了提升效率,只需要分别遍历横坐标和纵坐标,时间复杂度为m+n。先横向遍历横坐标,使用一条直线将图像竖直切割成两个子图,计算两个子图的均方误差和,找到横坐标xi,使得均方误差和最小,然后再纵向遍历纵坐标得到目标yi。
实验用到的图片的分辨率为512×512,选用的是腾讯NBA一个网页的部分截图,分别使用三种切割标准将图像切割,选择Python编程语言实现该算法(Python 3.6),主要使用的类库是scikit-image,最终得到的实验结果如图3-5。

图3 基于GBR颜色均方误差的切割结果截图

图4 基于HSV颜色均方误差的切割结果截图

图5 基于图片信息熵均方误差的切割结果截图
将两个网页截图分割后得到的4个小区块一一对比,计算两个区块之间的相似度,低于某一阈值时说明两个区块有明显的差异,从而找到网页之间的不兼容性。把一个大的问题分割成各个小的问题并一一查找,可以提高网页对比的效率。
使用均值哈希计算两个图像的相似度(距离越小图片越相似,距离越大图片差异性越大)[7],设定阈值,从叶子节点开始遍历并且只遍历叶子节点,逆先序遍历,两张图的相似度计算若大于阈值,则标记两个子图不相似,然后返回所有不相似的结果并标记于原图,溯源可以帮助网页维护人员做兼容性的修复。
2 结语
本文给出了基于自适应四叉树的网页分块算法,并分别对三种切割标准(RGB、HSV、信息熵的均方误差)做了实验,观察实验结果可以看出该算法可以得到满意的分块结果,但是距离整个网页的精确分块还有一定差距。
未来工作,将基于四叉树的网页分块技术应用到测试跨浏览器的网页兼容性上,应用到网络主题爬虫的网页去噪上,可以迅速找到网页中的正文,去除无关简要的广告之类的信息,具有一定的实际意义。
目前只能做到切割自适应,无法做到阈值自适应,因为不同的图像颜色有所差异,所以后面的研究是结合深度学习训练出模型来做阈值自适应的四叉树。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军民两用技术与产品(2022年1期)2022-06-01
房地产导刊(2022年4期)2022-04-19
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用与软件(2020年5期)2020-05-16
新生代·下半月(2019年5期)2019-09-10
魅力中国(2018年5期)2018-07-30
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中学科技(2016年7期)2017-05-16
中国水运(2016年11期)2017-01-04
