
基于电商平台的客户评论数据分析与挖掘
2019-04-08 00:46梁开孟秦凤敏
现代计算机 2019年6期
梁开孟,秦凤敏
(1.中国邮政集团公司钦州市分公司,钦州535000;2.广西财经学院金融学,南宁530000)
0 引言
随着计算机的不断普及,互联网和电子商务的不断发展,用户倾向于利用电商平台进行消费,而电商平台的不断完善,研究用户评论逐渐成为商家了解用户消费情感的重要手段。用户评论对消费行为进行了主观或客观的评价,电商平台上的店铺在长久经营过程中积累了成千上万条用户评论数据,在庞大的数据集中,隐藏着店铺运营的基本规律,主要体现在产品和服务上,以及用户的需求期望。
Python文本挖掘技术不断地发展,该技术能够准确地对评论文本进行数据分析与挖掘,挖掘评论文本数据中存在的客观规律,为产品销售制定科学的销售策略提供依据。本文选取滚筒洗衣机为研究对象,采集京东商城上的文本评论数据,对数据预处理之后,应用网络用户情感分析方法,将评论数据切割成正面、中性、负面三个文档,结合LDA主题模型,分析滚筒洗衣机的用户情感倾向。
1 数据采集与预处理
1.1 数据采集
根据前瞻产业研究院相关资料统计,2013年以来家用洗衣机的销售量增长缓慢,甚至有些年份出现下降的趋势,主要原因是家用洗衣机市场逐渐趋向饱和。本文对采集京东商城上滚筒洗衣机数据进行以下设定:评论数量超过5000条的店铺,以“滚筒洗衣机”采取模糊采集,对品牌、型号等不进行特别约束等,希望从采集的数据中挖掘用户规律。
对采集获得的用户评论数据进行初步处理,得到原始文本的评论数据,包含了脱敏处理后的会员名、评价星级、评价内容、时间等内容,根据分析的需要,从数据中抽取出“评价内容”一列。
1.2 数据预处理
原始数据中存在异常值、重复值、系统自动评论等数据,这部分数据价值含量低、数据结构混乱,严重影响数据挖掘模型的执行效率,导致挖掘结果的偏差,所以进行数据清洗是必不可少的。结合原始数据的具体情况,数据预处理采用文本去重、机械压缩去词和短句删除。
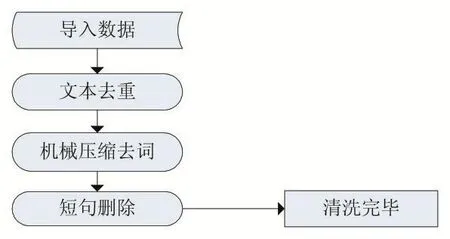
图1 评论文本清洗过程
(1)文本去重
文本去重是将重复出现的评论数据剔除,使数据保持唯一性,Python可以通过unique函数来剔除重复数据。文本评论出现重复往往有以下几个原因:第一,重复采集了同一个店铺的URL,造成重复采集数据;第二,电商平台根据客户长时间不进行评论,超过规定时间系统会自动进行评论,例如,系统默认生成“此用户未填写评价内容”的内容;第三,客户使用简洁的语句评论,例如,“好”、“很好”、“好评”等,这类文本的价值相对较低。
(2)机械压缩去词
在原始数据中,部分文本评论语句存在词语连续累赘重复,而机械压缩去词目的是将这部分连续累赘重复数据进行处理。其中,个人网络用词习惯不同,对相同情感的文本评论内容各不相同,每一条数据的价值比高低不一,去除连续累赘重复部分的数据有利于提高文本评论的分析价值。Python语言通过将文本评论存放列表中,逐个读取列表中的国际字符,将各个列表中意义相同部分进行压缩剔除。

图2 被压缩的语句和原语句对比
本文分析采用的机械压缩去词算法主要是针对语句开头连续重复进行处理,这基于人们制造无意义、重复语料常见于句子开头及句末,例如:“这款洗衣机,很好很好”、“非常满意非常满意”,通过机械压缩去词将重复累赘的“很好”、“非常满意”删除,留下简洁的语料。
(3)短句删除
用户评论字数越少,其蕴含的意思越少,挖掘到的信息量也越小。根据中文的使用习惯,要表达相应的用户情感需要一定量的字数,但是原始数据和机械压缩去词后的数据中存在字数较少的短句。在机械压缩去词完成的文本中,部分用户以“好”、“非常好”、“超级差”等表达自己的消费情感,从分析的角度无法准确捕捉到用户具体表达消费过程中哪个部分产生的情感,因此用户短句评论在分析过程中需要进行剔除。设定少于3个字符的短句,对其进行删除,确保文本中各个句子的句意完整。
2 模型构造
2.1 中文分词及用户关注点
中文分词是将句子中汉字按照序列切成一个个单独的中文词语,结巴词库提供了精确模式、全模式和搜索引擎模式三种分词模式[2],是Python中一个重要的第三方中文分词函数库。Jieba词库能够支持中文简体和繁体,在分析用户评论中能够对文本评论数据提取关键词。
用户关注点是用户对某一商品特定属性的关注点,反映客户在某种商品上的聚焦点,关注某一特性的用户数量越高,说明该商品的这一属性对用户来说越重要,一般是商品价格、如何安装、物流快慢、外观形状、质量如何、功能多少、容量大小和品牌效益。
分析利用Jieba词库,结合用户用词习惯,设置以“安装”、“物流”、“外观”、服务、“质量”、“功能”、“品牌”、“价格”和“容量”九个为用户常关注的属性。分析结果如图3。
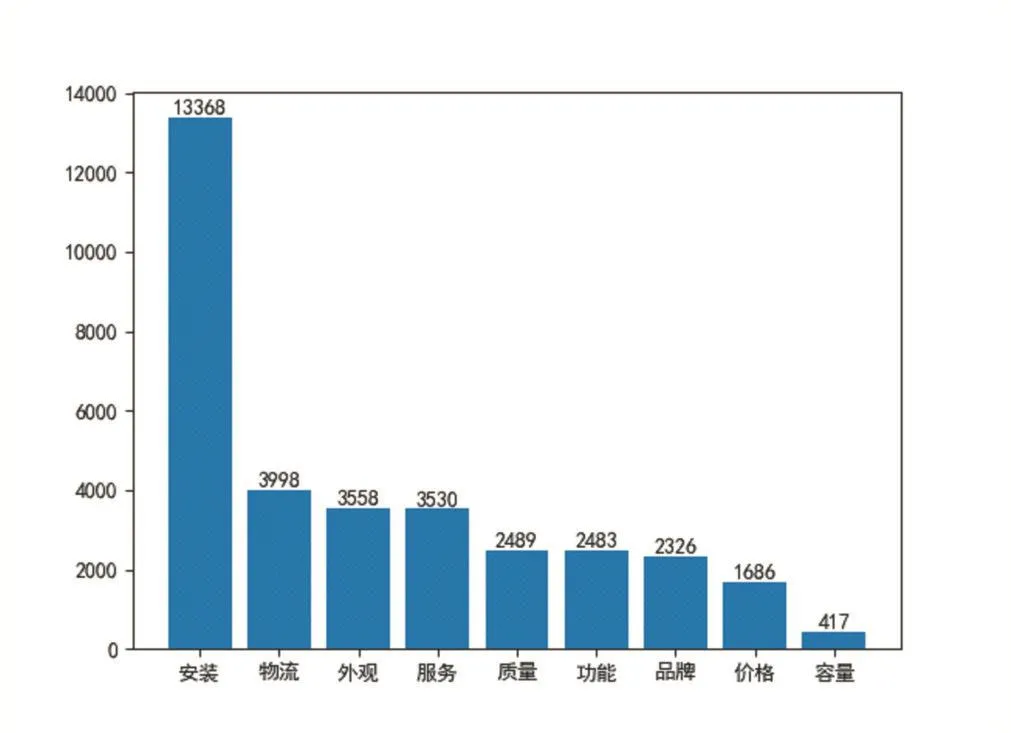
图3 文本评论数据关键词词频统计
根据图3、图4的结果显示,用户普遍关注的九大方面中,用户关注“安装”的词频13368次,占比为39.39%,是用户关注最大的一个方面,其次是物流、外观、服务,而质量、功能和品牌并列第五,关注容量的关注度最小。因此,在网购滚筒洗衣机过程中,用户首先考虑的是如何安装及安装难度高低。

图4 文本评论数据关键词客户关注度
2.2 语义网络
通过对用户文本评论进行中文分词,原本完整的语句会变得凌乱,而计算机无法识别出凌乱语句的完整结构,因此需要对分词重新进行关联,使分词之间建立连接关系。语义网络能建立起分词与分词的连接关系,使凌乱的分词重新关联起来,为进一步利用LDA主题模型分析提供前提条件。
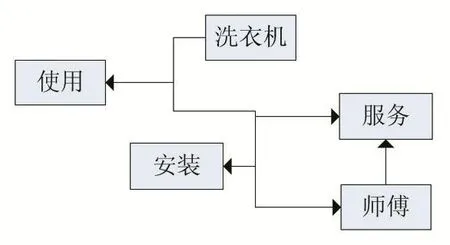
图5 词义网络图
通过对分词结果的观察,单独一个分词无法准确地表达相应的内容,例如,“洗衣机”与“使用”、“外观”等分开,就不能准确知晓其表达的下一层含义,但是“洗衣机”与“使用”连接起来,从正面情感评价则是“洗衣机使用方便”,而负面情感评价则是“洗衣机使用不方便”。因此建立词义网络是研究LDA模型的前提条件,为进一步分析用户情感提供依据,建立词义网络是极其重要的。
2.3 LDA模型[ 1]构造
(1)模型阐述
LDA模型中文名全称文档主题生成模型,是由布莱等人在2003年Latent Dirichlet Allocation一文中提出,经过国内外学者们不断地改进与完善,形成以文档(d)、主题(z)和词(w)三层结构的 LDA 模型,因此 LDA模型亦被称为三层贝叶斯概率模型。LDA主题模型的大概思路是“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语[5]”,从这个过程能够得到整个文档的每一个词。具体来说,假如文档是一个集合D,集合D则是由主题集合T形成,而主题集合T又是由单词W形成。整个过程中的文档、主题和单词都服从多项式分布。
LDA模型从机器学习分类上属于无监督学习,它采用BOW模型,即词袋模型,原理是将每个文本评论文档作为一个词频向量,并将文本信息转换成数字信息[5]。对比传统的空间向量概率(VSM),LDA主题模型增加了概率的信息,能够更有效地对文本进行建模。
在运用LDA模型之前,首先需要对相应的指标进行定义。假设词表大小定义为L,一个单词w则是一个 L 维向量(1,0,0,…,0,0),根据词袋模型将一篇文档被视为一个词频向量,因此N个单词即可构成文本评论文档 d,即 d=(w1,w2,…,wN)。由于京东商城开放的评论数据是有限的,为了分析更科学,对同一个商品需要采集M个不同的店铺,形成M篇文本评论文档d,即形成同一商品的评论集 D=(d1,d2,…,dM)。该算法是通过从文本评论中提取潜在主题,且文档d必然存在着K个主题,记为zi(i=1,2,…,K)。LDA模型生成过程如图6所示。
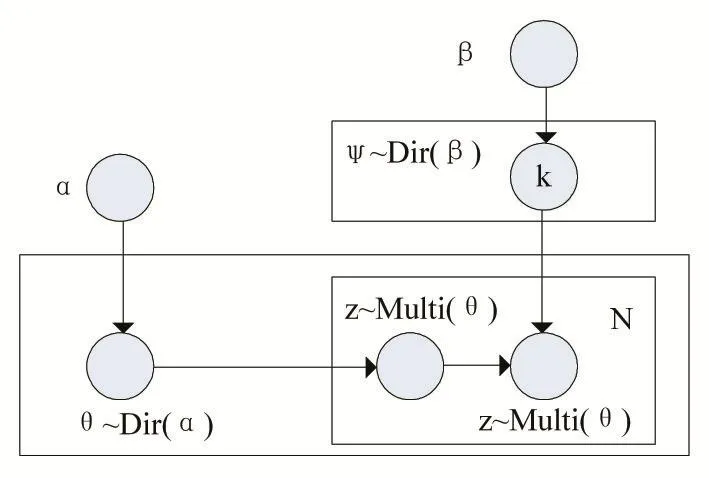
图6 LDA模型结构图
假设狄利克雷函数的先验参数分别是α和β,主题在文档内的多项分布参数为θ,其服从超参数为α的 Dirichlet先验分布,另外,主题(topic)中的单词(word)的多项分布参数为∅,其服从超参数 β的Dirichlet先验分布[3]。
LDA生成过程中的参数通过Gibbs抽样进行估计,具体过程[1][6]如下:
(1)k个主题按一定比例随机混合成每篇用户评论文档,混合比例服从多项分布,记为 Z|θ=Mult(θ)[3]。
(2)将分散的单词按一定比例混合成各个主题,混合比例服从多项分布,记为W|Z,∅=Mult(∅)。
(3)P(wi|z=s)表示词wi属于第s个主题的概率,P(z=s|dj)表示第s个主题在评论dj中的概率,在评论dj条件下生成词wi的概率表示为P(wj|dj)=
(4)LDA模型对参数θ、∅的近似估计通常使用马尔科夫链蒙特卡洛算法中的一个特例Gibbs抽样。利用Gibbs抽样对LDA模型进行参数估计,依据如下:
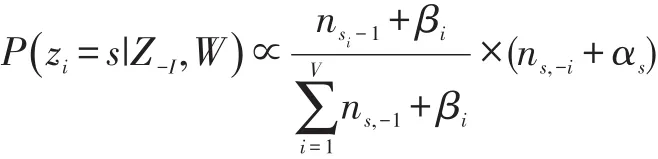
其中,zi=s|表示词wi属于第s|个主题的概率,Z-i表示其他所有词的概率,ns,-i表示不包含当前词wi的被分配到当前主题zs下的个数,ns,-j表示不包含当前文档dj的被分配到当前主题zs下的个数。
通过上述分析得到词wi在主题zs中分布的参数估计∅s,i,主题zs在评论dj中的多项分布的参数估计θj,s,公式如下:
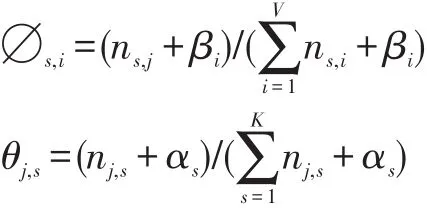
其中,ns,i表示词wi在主题zs中出现的次数,nj,s表示文档dj中包含主题zs的个数[6]。
(2)模型应用
用户文本评论分析运用LDA主题模型算法,并采用Gibbs抽样方法对LDA模型的参数进行近似估计。在整个分析操作过程中,将狄利克雷函数的先验参数α和 β设置为经验值,假设K=50,先验参数则为α=50/K,β=0.1。经过数据清洗,由采集的原始文本评论数据64163条,清洗得到38057条,其中文本去重剔除26013条,机械压缩去词删除了93条文本评论。
通过使用武汉大学ROSTCM6软件将文本评论数据进行正面评价、中性评价和负面评价切割,之后进行语义网络分析,将切分好的正面、负面两个文本文档进行提取高频词、过滤无意义词以及提取行特征词,最后构建网络。
根据语义网络分析结果,无论是正面还是负面评论,出现频次最多的是“安装-洗衣机”、“师傅-安装”、“送货-安装”,其他出现频次较高的主要分布在售后、脱水功能、声音、服务态度等方面。作为网购的家用滚筒洗衣机,用户收到货物首先关注如何安装洗衣机,这关系到用户能否正常使用洗衣机,是影响用户情感的关键因素。

表1 正面文本评价潜在主题
从上述结果来看,将用户正面文本评论数据聚成三个潜在主题,其中,主题1主要是用户认为洗衣机不错,体现在声音小、外观好看和洗得干净;主题2主要是用户反映洗衣机不错,体现在物流(或送货)速度很快、有师傅帮忙安装和服务好;主题3主要是用户一直信赖京东平台的洗衣机,体现在价格合理、质量保证和品牌信赖。
通过对正面文本评论的三个潜在主题分析,用户购买滚筒洗衣机之后产生正面情感倾向的原因集中体现在以下几个方面:第一是洗衣机质量好(声音、干净度和机身质量);第二是商品外观符合大众审美观,即洗衣机外观好看;第三是商家服务好(安装、售后);第四是物流速度快;第五是品牌保障,用户对品牌洗衣机的特殊情感。

表2 负面文本评价潜在主题
从上述结果来看,用户在购买了洗衣机之后出现的负面情感(抱怨点)被聚成三个潜在主题,主题1主要是用户反映洗衣机不好,体现在安装师傅态度差、洗衣机运转声音大、不知道使用流程和售后服务差;主题2主要是用户认为洗衣机虽然不错,但是洗得不干净、运转声音大和脱水能力差;主题3主要是用户认为洗衣机不好,体现在安装师傅态度差、物流(或送货)速度慢和不送上楼。
通过对负面文本评论的三个潜在主题分析,消费者购买洗衣机后产生负面情感(抱怨点)倾向的主要原因是洗衣机存在质量问题(噪音大、干净度低、脱水能力差)、服务差(安装师傅态度差、售后服务差)和物流速度慢。
总而言之,消费者情感倾向与商品及服务有直接联系,商家满足消费者的关注点有助于用户产生正面情感,消除负面情感;反之则产生负面情感。
3 结语
本文通过中文分词分析了用户对滚筒洗衣机相关属性的关注度、词义网络,并利用LDA主题模型分析用户的正面和负面情感倾向。根据对京东商城上滚筒洗衣机的用户文本评论进行中文分词和LDA主题模型分析,对滚筒洗衣机卖家提出以下建议:第一,保证产品质量,确保产品品质,是吸引和挽留客户的根本保障。第二,加大产品研发,既要改进洗衣机的性能,也要改善产品外观,符合消费者大众审美风格。第三,提升安装人员和服务团队的整体素质,安装人员既要有过硬的安装技术和维修技术,又要有良好的服务态度;服务团队不仅要做好售前服务,还要做好产品售后服务,及时、谦逊地回答客户的问题。第四,做好同城配送和物流公司合作,确保产品安全、快捷地送到客户手中,增加客户满意度。第五,发挥品牌效益。品牌是是一个企业产品技术创新的结晶,是企业产品综合内涵的集中体现,同时也是吸引客户的重要手段。
总而言之,商家应当抓住消费者的关注点,尽可能满足消费者的消费心理,发挥优势,提升服务质量,提高产品占有率与企业竞争力。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
校园英语·月末(2021年13期)2021-03-15
小天使·一年级语数英综合(2019年4期)2019-10-06
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
故事大王(2019年4期)2019-05-14
小学生导刊(2018年4期)2018-04-18
电脑爱好者(2017年7期)2017-05-06
