
关联规则算法在小数据挖掘中的技术研究
2019-04-08 00:46王金娟段珊彭浩徐红
现代计算机 2019年6期
王金娟,段珊,彭浩,徐红
(湖南涉外经济学院,长沙410205)
0 引言
互联网技术的迅猛发展已然将人类带到“互联网+新能源”为聚合推动力的又一次革命中,在这场革命的推动下,互联网己经不再是一个简单的获取资源的工具,它更是一个以难以想象的速度发展成为与现实世界紧密融合的数据世界。
目前,大数据有很多种不同的定义。大数据先是从各行各业如证券金融、电子商务、搜索引擎等行业中产生的海量的每天数万TB的数据[1],这些日益积累出的大数据仍然在不停地爆发式增长,后得出大数据既是数据量达到PB级甚至EB级的大规模数据。
“大”是大数据最直观最重要的特征,且这些各个行业里产生的数据都紧密相连,如何获取这些数据里的价值是必须也必然要做的长期课题,所以大数据更可以准确描述为:无法在可容忍的时间内用传统方法和软、硬件平台对其进行感知、获取、管理、处理和可视化的数据集合,它更涵盖了数据及其采集、处理、分析、解释等在内的一系列相关的技术[2]。这些技术包含数据采集,数据信息的抽取和清理,数据集成于分析,数据解释与部署等内容[5],这些内容又涉及到数据存储、数据安全、数据可视化、流计算、云计算、数据共享等多方面的技术集成,所以大数据的研究发展是现代信息产业技术的挑战同时也是新的机遇,它的技术变革同时也会带来科技与生活的不断更替。
1 大数据与小数据
1.1 小数据概述
在当今这个大数据世界,其数据的价值最终要体现在,能更深层次的对人民的生产和生活带来更好的支持,这就需要行业缩小与最终用户的距离,随着推荐系统领域的提出和发展,针对单个用户的个性化推荐技术己经在新闻、阅读、视频、音乐等诸多领域大放异彩[7],如何获取用户相匹配的信息并推荐给用户符合其兴趣偏好的产品成为一项非常重要的课题,此时小数据的概念应运而生。
小数据是指以单个用户为中心的全方位数据,包含数据被采集对象实时的身体状况、社交习惯、财务、喜好、行为等一系列的数据信息[3]。通过分析小数据信息,可初步形成针对个人的数据系统,利用它能对个人的需求和行为进行预测,并给出相应的决策依据。小数据是基于概率论和数理统计的传统统计思想,通过数据挖掘算法进行聚类,过滤,挖掘数据与用户之间隐藏的关联特征,并分析计算从而获得的有限、固定、不连续、不可扩充的结构型数据[6],它更具有个人色彩,也更加符合现在社会要求提供个性化服务的技术要求。
1.2 大数据与小数据的关系
首先,大数据反映的是规律,小数据体现的是个性化。大数据的4V特征即量度(Volume)、异度(Variety)、速度(Velocity)和精度(Veracity)反映出的是海量数据的总体规律[2],为提高数据在采集、处理、存储和分析过程的效率可控性,大数据要求数据信息的组织结构与类型必须标准化,要求数据覆盖行业面广、收集内容要多、要求具有普适性,能分析得出其变化的规律。而小数据是针对单个用户的数据集合,技术的研究方向集中围绕着个人的信息的数据采集存储、分析与决策,它更具有针对性,是为了提供更具有个性化用户服务的产品的一次产业深度细分,因此小数据和大数据是对平衡的共同追求,而小数据注重抽样,是大数据技术的一个深度分支。
其次,小数据在安全方面比大数据有更高的要求。大数据都来源于很多不同的计算机平台,只能收集到反映群体特征的数据,分析的规律一般是动态的、具有阶段性数据特征的重复结果[8],而且会有大量的虚假干扰信息,信息价值密度低,安全性也不高。而小数据是以用户个人为中心进行数据采集、决策分析对象,一定会涉及到包括用户的个人生活环境、兴趣爱好,所处的位置信息等多方面的隐私数据,因此如何通过更好的行业规范和技术手段来保护获取到的用户数据,是摆在面向小数据挖掘技术的一个重要课题。
2 关联规则算法下小数据的挖掘技术研究
围绕着用户的小数据挖掘并以此为驱动设计出相应的产品,就必须以用户的需求为中心,即基于用户需求的数据挖掘过程是决策最为重要的影响因素,如何准确掌握用户需求变化,提高数据信息采集的针对性并保障小数据的安全性[9],是在小数据挖掘的设计阶段必须要重点关注的问题。
2.1 关联规则
关联规则挖掘是数据挖掘中的一个非常重要的课题,它的本质是从数据背后发现事物之间可能存在的关联或者联系。当海量数据经过采集、处理、分析、解释后,将不同来源的数据进行整合,再利用数据分析工具进行快速处理,结果提供给决策人员作为依据以此来挖掘小数据。小数据包含个体特征数据、行为监控数据、第三方共享数据及外围社会数据四个部分[10]。用户个人的特征产生的数据是小数据的核心,包括用户的基本信息数据、消费生活数据、相关的社会关系数据等多方面信息组成,它有较高的科学性、真实性、高价值密度和决策可用性;行为监控数据主要由传感器网络、服务器监控设备采集数据组成,主要实现对个体位置与移动路径、社会关系等数据的采集与存储;第三方共享数据,主要由通信运营商及其它第三方增值服务商共享数据组成,该数据全面但安全性较低[3];外围社会数据是合约数据提供商提供的共享数据,它具有很大的挖掘潜能,是小数据挖掘非常重要的数据补充。
所以,小数据的挖掘应建立在以用户个性化需求为前提,从以上四个方面分析采集数据集的置信度、支持度,推导出合适的频繁项集,找出其中的关联规则再进行判断、分析并提供能保障安全可靠的数据过滤和处理技术之上,希望能进一步弄清用户的真实需求。
2.2 关联规则算法对于小数据驱动的研究
关联规则算法是从数据项的事务集合中挖掘出,满足支持度和置信度最低阈值要求的所有关联规则,这个阈值是由用户指定,它的数据挖掘过程分为两个过程:先从事务集合中找出频繁项目集,再从频繁项目集合中生成满足最低置信度的关联规则。常用的关联规则挖掘的算法有Apriori算法、FP-Growth算法、CBA算法等。本文采用最经典的Apriori算法讨论关联规则对于小数据挖掘的决策影响。
决策因素纵横交错,在已有的数据支持下,要做出相对好的决策就必须建立相关的算法去反映问题的实质。Apriori算法是常用的用于挖掘出数据关联规则的算法,它采用频繁项集的先验性质来压缩搜索空间,利用逐层搜索的迭代方法,找出数据值中频繁出现的数据集合[11],找出这些集合的模式有助于做出更好的数据推荐。假设已经处理多个数据来源的数据并整合,得到用户的数据预处理结果后得到围绕着小数据的用户模型如图1所示,其中个体特征数据包含数据库里记录的基本信息数据、消费生活数据、相关的社会关系数据等数据,占用户数据里比率最多;其次是行为监控数据包含用户当前所在位置、浏览行为习惯、移动路径等数据,在数据比率里占第二;而和通信服务商及增值服务商采集的用户访问过的网络信息及流量监控等数据是共享数据在数据分布里占第三;而用户与固定的一些接口程序或者例如百度、搜狗等这些合约数据提供商共享的数据是外围数据,占比最少。针对小数据的特征,通过关联算法找出频繁数据集,给出支持度表,就可以提供参考推荐数据。表1是利用随机数生成法,从某网站的访问数据中,采集到围绕着移动用户具有代表性的四个特征数据的表格,表中的性别、年龄是个体的特征数据,可以从数据库直接读取。
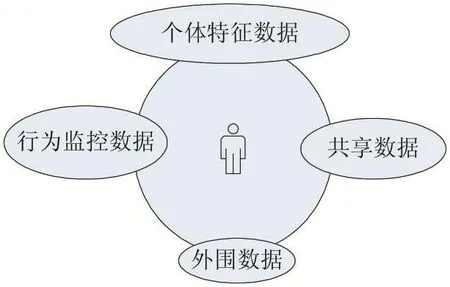
图1 用户小数据分布模型图

表1 用户部分小数据表
针对大部分用户注册的性别数据不一定真实需要去掉噪声,这里可以从用户的行为属性中逐步辨别。登录城市是行为监控数据、用户每天使用的流量是共享数据、访问网站的次数属于外围数据。Apriori算法中的频繁项集表示数据在一起出现的概率最大,先以支持度作为判断频繁项集的标准,再以数据的条件概率即置信度进行评估,以下列出算法步骤:
步骤1:生成单一个体数据频繁项集列表,遍历所有数据检查生成的频繁项集是否满足最小支持度,对数据剪枝删除不满足支持度的项。
步骤2:使用组合方法,在当前个体数据频繁项集中生成个体数据和行为监控数据的两项数据频繁项集,再检查生成的频繁项集是否满足最小支持度,并删除不满足支持度的项。
步骤3:重复步骤2的过程,得到具有四个特征的频繁项集。
步骤4:从步骤3生成的频繁项集中挖掘关朕规则,判断每条规则是否满足置信度,不满足则删除,满足则保留,生成的所有的规则按照其置信度进行排序[7],最后得到Apriori算法关联挖掘的结果。
分析Apriori算法挖掘小数据后的结果,发现用户的个体数据与外围数据,共享数据均有较强的联系,而共享数据与外围数据同样有很强的关联性,可以解释为具有某种个体属性的用户更倾向于访问同样的外围数据,从而得到相同的共享数据。例如,在一线城市的女性更喜欢访问提供服务相近的网站,同时消耗更多的流量,给增值服务商和网站运营商提供了更多的决策数据。
3 结语
和大数据挖掘相比,小数据挖掘围绕用户特征进行,具有更高的针对性和准确性,但是如何提高共享数据和外围数据的安全性问题仍然亟待解决。关联规则挖掘算法能从发现数据之间可能存在的关联,但Apriori算法每轮迭代都要扫描数据集,在数据集很大,数据种类繁杂的时候,时空复杂度很高,算法效率太低,因此需要进一步研究能大幅度减少计算时间复杂度的关联算法进行小数据挖掘,为用户提供更好更高效的服务。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
中国科技纵横(2016年20期)2016-12-28
棋艺(2014年7期)2014-09-09
