
基于学生教育数据的关系预测与发现
2019-04-08 00:46李晓伟
现代计算机 2019年6期
李晓伟
(四川大学计算机学院,成都610065)
0 引言
随着数据科学定义的提出,机器学习、数据挖掘[1]、数据可视化等概念变得越来越流行,与学生相关的网络服务乘着移动互联网的东风迅猛发展,成为了最受欢迎、用户最多的服务之一。越来越多的互联网厂商和计算机科学研究人员开始将数据科学和社会网络结合起来,依托庞大的用户所产生的数据进行行为分析,为用户提供个性化服务。学生每天会进行消费刷卡,会上课学习,这些行为等会产生许多的数据。基于大学生的消费数据和成绩数据,可以分析出一些大学生生活和学习方面的规律。例如,大学生的消费习惯是否和成绩相关,来自同一生源地的学生是否会喜欢在同一家餐厅吃饭,不同性别的学生的选课习惯是否不同。
本文使用某院校一个学院一个年级的成绩数据和学生卡消费数据,使用决策树(Decision Tree)和支持向量机(Support Vector Machine,SVM)两种算法预测好友关系,采用了随机采样大类平衡小类的方法解决数据不平衡的问题。并使用调查问卷的形式获取学生真实好友关系,进行真实数据验证,使用的好友关系预测方法的精确率(Precision)、召回率(Recall)和 F1分数(F1 Score)均较高,达到了预测效果,后期使用可视化工具进行好友关系分析。
综上所述,本文的贡献主要分为以下几点:
(1)提取特征进行预测性分析。根据算法的需要从源数据中选择能够被用来预测好友关系的大学生行为特征;
(2)通过编写Python程序挖掘和清洗数据,通过RapidMiner等数据挖掘工具进行算法选择和测试;
(3)使用决策树和SVM两种算法训练和测试数据集,通过数据调整提高精确率和召回率;
(4)通过调查问卷获取大学生真实好友关系以及交友情况,验证实验预测结果;
(5)使用 D3.js、ECharts、Matplotlib等可视化工具实现可视化模型并进行分析。
1 关系预测
1.1 数据来源与数据处理
本文使用的数据集为大学生校园卡、校园网、教务网等系统所产生的教育数据。所有数据都经过加密算法处理,将学生相关信息匿名化。这些数据遍布各个学院和各个年级,文件数量众多,数据量庞大,使得数据具有代表性和普适性。为了保证数据真实性的可验证性,选取了某院校一个学院一个年级所有学生2014年全年消费数据和2013年至今的成绩数据进行实验。
数据处理是机器学习预测算法进行预测之前非常重要的一步。它包含数据预处理和数据整合与清洗两个关键步骤。数据预处理是要提取出消费数据中的两名学生刷卡重叠次数和成绩数据中的两名学生选修课重叠次数。数据整合与清洗是要将数据集中所有学生两两配对,将两名学生学籍相关信息(学号、姓名、性别、生源地等)和数据预处理步骤中提取出的学生刷卡重叠次数和选修课重叠次数整合,并对缺失数据、非常规数据进行清洗。

表1 部分整合后的数据表
1.2 预测算法
针对不同的分类问题需要选择不同机器学习算法。例如,朴素贝叶斯这样的高偏差低方差型分类算法,适用于样本数量较少的小训练集。但是随着数据量的增大,KNN这样的低偏差高方差分类算法将具有优势。RapidMiner是现如今数据挖掘和预测分析领域最流行的解决方案之一[2]。它可以不通过编程完成机器学习预测的工作,内置多种算法,选择数据集后可以立刻可以进行算法测试。本文选用RapidMiner对算法进行测试和选择,测试了朴素贝叶斯、KNN、决策树、SVM四种方法。最终考虑到预测的精确率和召回率,以及选择不同表现类型的算法的需求,选择了决策树和SVM两种算法进行预测,前者可以毫无压力地展示特征间的关系,后者能够十分良好地避免过拟合问题。
决策树算法采取通过 Python的NumPy、Scipy、Sklearn等模块进行实现[3],再自行配置和优化的方案。由于数据集存在不均匀的正负样本分布的情况,也就是说,好友对数作为正类,非好友对数作为负类,样本数量差距大。引入了纠偏数对大类(负类)进行随机选择和抽样处理,以平衡两者的比例差距。程序包括数据读入、标签转换、拆分训练集与测试集、选择划分标准、剪枝、训练、画决策树、测试、打印结果几个部分。数据读入是把整合后的数据读入,存储特征和标签到x、y矩阵中;标签转换是把“是否是好友”中的“是”与“否”标签转换为Sklearn能够处理的“1”与“0”;拆分训练集与测试集是将读入的数据以二八比例拆分为训练集(80%)和测试集(20%)。选择划分标准时,选择信息增益作为划分标准,Sklearn的决策树采用CART算法,经过这样的配置后,相当于实现了ID3算法;剪枝的目的是避免决策树生长的节点过多导致过拟合问题;训练后生成模型,并以图片的形式导出决策树到PDF;测试后,打印出详细的精确率、召回率,决策树预测结果如表2所示。
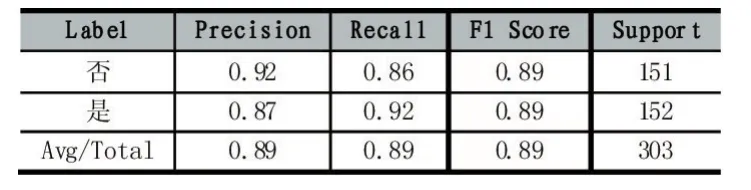
表2 决策树算法测试结果示例
其中,Label为标签值,即是否是好友分类的类别。Support为测试集中真实的正负样本数量,Avg/Total为精确率、召回率、F1分数的平均值和真实测试样本数量的总数。在所有评估指标中,随机一次测试的数值都是高于85%的,这充分说明决策树算法对本课题数据预测的有效性。
SVM算法的实现与决策树算法类似,不过加入了Matplotlib模块进行绘图,另外程序不包括选择划分标准、剪枝、训练、画决策树部分,但是加入了SVM核函数选择和作图的部分。选择了包括线性核函数、多项式核函数、径向基核函数、Sigmoid核函数这四种常用的核函数[4]。在图1中,每张小图的横坐标为刷卡重叠次数,纵坐标为选修课重叠次数。蓝色部分划分为非好友,棕色部分划分为好友,一个小圆对应一条记录。我们可以明显地观察到Sigmoid核函数的分界存在较大问题,线性核函数和多项式核函数分界较好,但径向基核函数分界最佳,如表3所示,随机一次测试的所有平均评估指标数值都是高于85%的。
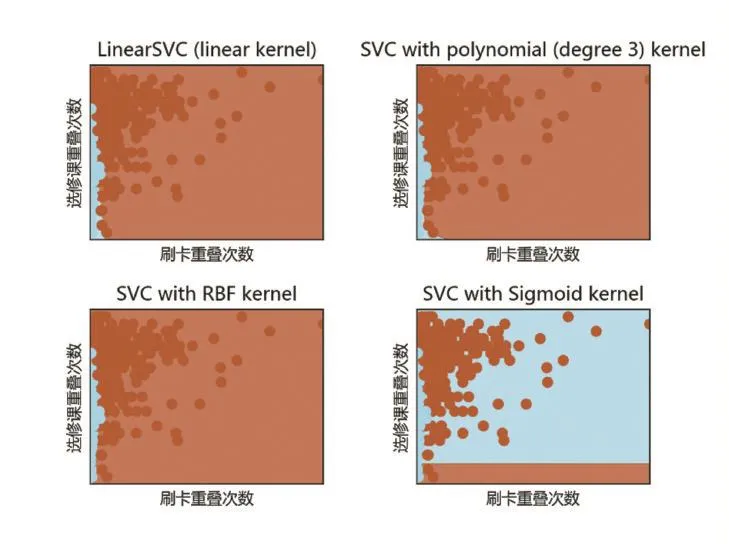
图1 SVM核函数测试图
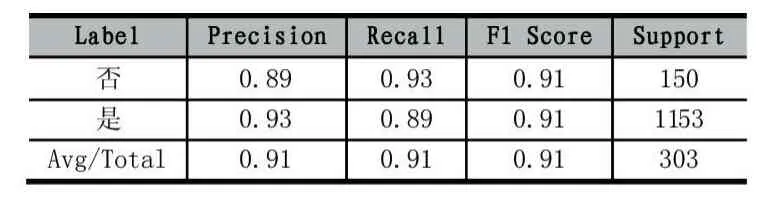
表3 径向基核函数测试结果示例
2 学生关系可视化
通过实验,完成了力引导关系图和环状关系图这两种关系图。组织并可视化了大学生之间的社会关系,呈现不同人群的信息,为了解不同的人群提供了快速浏览交互,如图2和图3所示,其中图2左下图为鼠标放于节点上,右下图为鼠标放于两节点的连线上,图3右图为鼠标放于节点上。图中的每个节点以学号代表了一个学生。通过多次可视化数据分析,赋予不同社会关系一定权重的策略,能够发现力引导关系图中节点的分布较为紧密。具有好友关系的人,同时会具有同性、老乡、同专业同学、同班同学的社会关系,呈明显的正相关性。而是否是同年出生对是否是好友几乎无影响。这一结论在环状关系图中同样可以得到验证。根据结论逆向分析,如果两个大学生都是女性,那么她们在寝室等地方接触的机会将更多,也更容易选择瑜伽这样女性学生较多的课程;如果两个大学生是老乡,那么他们能够用方言交流,饮食和生活习惯类似,对于家乡的感情也会让他们更可能在老乡会等组织相遇;同专业同学、同班同学长期一起学习,接触时间多;结合上述分析,具有这一类社会关系的人都会更可能成为好友。而同是年级相同或相近的大学生,是否年龄相近不会成为好友关系的阻碍。因此,从关系图中得出的结论,符合社会习惯。
3 结语
随着数据科学的流行和发展,大数据相关业务积累了足够的信息量,如何借助机器学习和数据可视化挖掘这些数据,增强用户个性化服务效果,已经越发受到信息技术学术界和工业界的重视。本文预测大学生可能存在的好友关系,结合可视化分析,对社会关系的影响因素进行发现。本文对多种机器学习算法进行比较,选择了决策树算法和以径向基函数作为核函数的SVM算法进行实现。之后将预测预处理的数据和预测结果相关的数据和网络爬虫抓取的生源地省份经纬度等数据整合,绘制了好友关系图,交互式分析数据。机器学习预测的平均精确率、召回率、F1分数等指标均高于85%,预测结果的可信度较高。最后,通过可视化分析,得出了好友关系与是否是同性、是否是老乡、是否是同专业或同班同学存在一定联系,并且是否是老乡这一特征的权重较大的结论。

图2 力引导关系图

图3 环状关系图
猜你喜欢
北京测绘(2022年6期)2022-08-01
师道·教研(2022年1期)2022-03-12
北京测绘(2021年7期)2021-07-28
科学与信息化(2019年28期)2019-10-21
冰雪运动(2019年3期)2019-08-23
小雪花·初中高分作文(2019年10期)2019-02-12
杂文月刊(2017年20期)2017-11-13
科学与财富(2016年32期)2017-03-04
决策与信息·下旬刊(2013年1期)2013-03-11
小雪花·成长指南(2009年10期)2009-12-04
